
Imagine that you are an IT architect at a leading retailer that has been in business for over 150 years. From the beginning your company innovated by augmenting their in-store sales with mail-order catalog sales to serve those customers living on the frontier. Later, when telephones became commonplace, they were one of the first retailers to institute call centers to decrease the turnaround time on orders and increase customer satisfaction. In the 1990s, when the World Wide Web became ubiquitous, they were one of the first retailers to develop applications to enable customers to enter orders and check on their status wherever they could connect to the Internet.
Unfortunately, your company’s innovations in customer service have not been matched in their IT infrastructure. The majority of the mission-critical business logic is encapsulated in batch applications and legacy terminal-based applications written in COBOL. Newer web applications are C programs invoked from the web server through CGI connecting to these back-end functions through a gateway. These applications have proven to be extremely difficult to modify, slowing down the improvements in customer service.
Your newly hired CTO has decided that now is the right time to modernize the legacy systems—so that she can start a legacy of her own, we suppose. She chose Service Oriented Architecture (SOA) and Java-based applications on top of existing and new relational databases as the best way to provide for maximum flexibility in the new systems. SOA will facilitate declarative assembly of new applications from a set of reusable services. Java will provide write-once-run-anywhere service implementations that will provide more options for deployment. And you are charged with making the decision about which persistence mechanism to use within your Java-based services.
You may be wondering why we are telling you all of this background. One reason is that just as we work with our clients in the context of concrete scenarios to ensure that we focus on the issues necessary to be successful, we want to scope this book to a particular point of view (an architect), style of Java application (object-oriented in general, and SOA in particular), and underlying database (relational). Another reason we start with this background is related to this adage:
Those who do not study history are doomed to repeat it.
Even worse, in our opinion, is that those who do not study history may not be able to repeat the successes of the past. They usually only stumble onto an enterprise-quality solution through a long period of trial and error. The result is that most simply reinvent the wheel, at great expense.
Therefore, the purpose of this chapter is to bring you up to the present moment with a brief (and admittedly incomplete) history lesson of relational database persistence mechanisms associated with object-oriented languages.
Since the invention of object-oriented programming, developers have faced a problem. Although they can build elegant and complex object models in their development environments, the data that corresponds to those object models is often locked away in relational databases. There are good reasons for this: Relational databases are the most common in the world; the relational model is mathematically based and sound; and relational database products, from industry leaders such as IBM, Oracle, and Microsoft®, as well as open-source products like MySQL, are mature and well-known.
But when a developer first sits down and considers how to connect this relational data to his objects, he begins to understand what has been termed the “object-relational impedance mismatch.” In short, this refers to the problem of the world of tables, rows, and SQL not being the same as the world of objects, classes, and Java. Anytime a developer looks at bridging this gap, there will always be little things to overcome, such as
How can inheritance be represented in a relational database?
How do types map from a relational database to the different type system of Java?
How can it be handled when an object model structure looks nothing like the relational model that its data is stored in?
As the German Philosopher Friedrich Hegel once said, “The only thing we learn from history is that we learn nothing from history.” Unfortunately, this is true in many aspects of life. To understand the best ways to deal with this impedance mismatch and what a modern application developer should do to take advantage of the right patterns and tools for handling the common issues, we need to take a brief look back at how this problem has been handled in different languages and toolkits over time. By studying the evolution of the solutions, it’s possible to better understand and compare the current solutions.
There was a time not too long ago when the developer landscape was fractured among a number of competing object-oriented (OO) languages. Although the introduction of Java changed the language landscape, it didn’t alter the basic patterns and approaches to handling object-relational (OR) persistence. In fact, in a moment of history repeating itself, it’s possible to see the same lessons learned in Smalltalk and other languages learned again in Java.
Although this history lesson will be very brief and not altogether complete, it should at least give you a sense of how the problems in object-relational mapping (ORM) were originally discovered, when they were discovered, and what the proposed solutions have been.
In the early days of the OO language wars, it was unclear which languages would survive and become the dominant players among OO developers. One of the early leaders, which did not gain the wide adoption of some other languages like C++ and Java, was Borland’s Delphi. Delphi was based on Object Pascal, and first released in 1995. By 1996, Delphi featured a set of database programming tools that encouraged more of a Transaction Script approach than a true object-relational mapping. Programmers would query for and manipulate Row objects that represented the rows in a relational table. Delphi featured forms-based programming and nonvisual relational database management system (RDBMS) components that would plug into its visual form builder tooling.
Because C++ had wide adoption, many libraries attempted to address the relational mismatch. Rogue Wave is still one of the most popular C++ library providers around. Their DBTools libraries attempted to address the object relational problem by overloading the stream inputs and outputs to accept SQL. SQL queries could then be projected onto objects and vice versa. Although programmers would write their own SQL, it allowed one to think about object representation of their domain. Today, many developers still feel comfortable writing SQL, and modern frameworks like iBATIS take advantage of this fact.
In 1992 the developers at NeXT (founded by Steve Jobs) released their first stab at addressing the issue of connecting objects written in Objective-C, the primary programming language of the NeXT and NeXTStep, to relational databases. This effort resulted in the DbKit, which was an abstraction layer that allowed access to different relational databases without the need to write database-specific code. This approach presaged many later efforts such as JDBC and similar frameworks. In time (and after at least one complete rewrite), the NeXTStep developers released the Enterprise Object Framework (EOF), which eventually became a complete object-relational mapping framework.
Our story really begins in 1995, however, with the release of the initial version of the TopLink object-relational mapping tool by The Object People, a small Canadian Smalltalk consulting company [Smith]. At the time, an advanced object-oriented development community of professors and students had formed at Carleton University, resulting in the creation of a number of small but important companies in the history of OO development. TopLink wasn’t the first OR mapping tool for Smalltalk (for instance, the ParcPlace ObjectLens toolset, which was included as part of the ParcPlace VisualWorks development environment for Smalltalk, was released in 1993), but it differed from some of the earlier tools for Smalltalk in that it contained nearly all the features now expected in an ORM tool. For instance, TopLink 1.0 contained the following:
The capability to map database fields to object attributes, and to perform type conversions between the two.
The capability to represent 1-1, 1-N, and N-M relationships in the object model as relations between database tables.
The capability to map a single row in the database table to multiple objects.
An implementation of the Proxy pattern, by which a proxy object “stands in” for an instance of another class that has not yet been fetched from the database.
Object caching to reduce the number of repetitive database queries.
Support for multiple database vendors.
This toolset was the standard by which other Smalltalk relational database tools were judged, and it implemented many of the patterns that are now standard practice in Java object-relational mappers as well.
But TopLink wasn’t the only game in town, even in Smalltalk. IBM had begun supporting the Smalltalk language with the purchase of Object Technology International, another small Canadian company founded by students and professors from Carleton University. OTI developed Smalltalk technology—which became the basis of IBM’s VisualAge® for Smalltalk product. Seeing the need to provide relational database connectivity to its Enterprise customers, IBM developed its own object-relational mapping tool for VisualAge for Smalltalk, which was internally used with several customers before it was released as part of VisualAge (called the ObjectExtender) in 1998. Even though IBM was a late entry into the Smalltalk persistence game, their experience is important to the story, as discussed later. The ObjectExtender contained many of the same types of features as TopLink:
Full support of mapping Smalltalk fields to relational database columns
Full support of 1-1 and 1-N relationships
Transactions support
“Lite” (proxy) collections
But for the purposes of this book, the release of TopLink for Smalltalk wasn’t the most interesting thing that happened in 1995. In May 1995, Sun announced the Java programming language, and in January 1996 Sun released the first public version of the Java Development Kit (JDK). Java didn’t catch on immediately for enterprise development because it was initially targeted as an Internet programming language, so many of the initial libraries were specifically designed to work within a browser. In fact, connecting to a relational database was one of the things that applets could not easily do, because the Java security sandbox limited outgoing connections to the same machine that the applet was downloaded from.
People began really becoming interested in database access through Java with the release of JDK 1.1, in February 1997, which included the JDBC 1.0 classes (which allowed access to relational databases, although they didn’t provide object-relational mapping). This toolkit began to open developers’ eyes to the possibility of Java in the enterprise, and set the stage for the development of more complex frameworks, and the eventual creation of Java 2 Enterprise Edition (J2EE).
Using the Java Database Connectivity API (JDBC) is often a person’s first exposure to manipulating a database with Java. JDBC 1.0 introduced most of the ideas that are still found even in the most recent JDBC 4.0 specification. Note that these are not new concepts first introduced in JDBC; JDBC is itself based off of Microsoft’s ODBC API, which was in turn based on the X/Open SQL CLI (Call Level Interface). In short, there are three major concepts:
The basic object for manipulating a database is a Connection. A Connection represents a link to a relational database process running somewhere (either on the same machine as the JVM or on a different machine).
Connections are used to obtain Statements. Statements are the Java representations of SQL code. You can either provide a SQL string to a Statement immediately prior to execution (using the
Statementclass) or provide the SQL string at the creation of the Statement (using thePreparedStatementclass). ThePreparedStatementis unique in that the SQL string can be parameterized; that is, it can contain macros whose values can be replaced at statement execution time.Statements that represent SQL queries, when executed, return a ResultSet. A ResultSet is a Java object that represents the set of rows that are returned from the SQL query to be processed one row at a time. You can access the data from a ResultSet either through the name of a column or through its position in the row currently active.
In JDBC 1.0 you could only move forward through a ResultSet. JDBC 2.0 (released with JDK 1.2 in December 1998) expanded this to allow backward movement through a ResultSet, and also allowed changes to the values of the ResultSet (which result in implicit SQL UPDATE statements). Simultaneous with the release of JDBC 2.0 was the release of the first JDBC Standard Extension, which introduced concepts such as database pooling, accessing named pools through the Java Naming and Directory Interface API (JNDI), and support for two-phase commit transactions through the use of the Java Transaction API (JTA) or Enterprise Java Bean components (EJBs).
Given their experience with TopLink for Smalltalk, in 1996 the TopLink team began work on a version of TopLink for Java. The product officially came available in 1997. The TopLink ORM for Java contained all the same types of features as TopLink for Smalltalk, and over the years it would also come to support multiple application server vendors as well as working standalone. TopLink was acquired by WebGain in 1999 and became part of Oracle in 2002.
In late 1997 and 1998, engineers from Sun, IBM, and many other companies began working together and releasing early versions of what would become the first Enterprise Java Bean (EJB) specification. The EJB specification was an ambitious project to redefine the way in which distributed applications were built. The EJB specification attempted to build from the foundation laid by the CORBA specifications and the lessons learned from the Java RMI specification to result in a framework for building enterprise applications that would combine distribution, persistence, and two-phase commit cross-datasource transactions.
From a persistence point of view, the EJB 1.0 specification introduced the idea of an entity bean, which was an EJB component that exposed information contained in external datasources as first-class Java objects. There were two flavors of entity beans described in the first EJB specification: those with “bean-managed” persistence (BMP), and those with container-managed persistence (CMP). In a BMP, logic implementing persistence would be explicitly coded by the developer, using facilities like JDBC, within the methods of the entity EJB. A CMP made the logic associated with persistence implicit, with the promise that vendors would provide tools and frameworks to provide object-relational mapping.
The initial EJB specification left a lot of implementation details open to interpretation for the vendors to fill in. Somewhat representative of the very early EJB persistence implementations was the VisualAge Persistence Builder (or VAP), released in 1998. This product was the first IBM toolkit for creating persistent Java objects similar to EJB components. It was developed by the same team that developed the ObjectExtender framework, and shared a number of the same design principles and goals.
VAP occupied an interesting niche that differentiated it from some other early EJB 1.0 implementations; it wasn’t part of a full EJB container, but instead was a standalone EJB runtime environment designed to be upward-compatible with the architecture of IBM’s EJB server environments. Like several other persistence solutions that followed, it was a server environment that could be plugged into a Servlet or EJB container to provide persistence.
The way in which VAP achieved this “amibidextrous” nature is by beginning with a set of tools built in the VisualAge for Java Enterprise Edition environment that were capable of generating objects (that were, in fact, Plain Old Java Objects or POJOs). These POJOs implemented the entity bean interfaces, together with other objects that implemented the EJB Home interfaces, and the other parts of its persistence implementation. VAP code would be packaged into a JAR file that would then run on top of the VAP runtime framework, which, as noted earlier, could run inside a Servlet or EJB 1.0 container, or could also run within a Java application.
VAP supported almost all the standard ORM features, such as these:
Caching support
Transaction isolation policies and concurrent and nested transaction support
Full support for database relational integrity (RI), including statement ordering
Full relationship support for 1:1, 1:N, and M:N relationships
Full support of inheritance with single-table, parent-child, and separate-table inheritance
Prefetching of rows in 1:N relationships (joins)
However, the very strength of VAP (its relationship support) hid a number of issues that developers soon discovered with the EJB 1.0 specification. For example, the specification did not include details of how relationships were to be described for CMP entity components. As a result, each vendor’s approach to capturing this important information in a “deployment descriptor” was different. Another issue that people soon ran into with the EJB 1.0 specification was that EJBs were always considered remote objects. This made it possible, for instance, to access the individual attributes of an entity EJB (which represented a single database table row) one-at-a-time across the network, something that was neither efficient nor scalable. These drawbacks, among others, led to the EJB specification being significantly revised in EJB 2.0.
EJB 2.0 [EJB 2] was finally released in 2001 (after a long revision process that included two separate final drafts that differed significantly from one another). Although EJB 2.0 introduced a number of new features such as Message Driven Beans that do not concern this story, a major portion of the revised sections of the specification dealt with persistence. In short, EJB 2.0 attempted to improve the poor portability situation of EJB 1.0 by describing relationship support directly within the specification. EJB 2.0 accomplished its relationship support by substantially enlarging the role of the XML deployment descriptor that had been introduced as a class in the EJB 1.0 specification, and then changed into an XML file in the EJB 1.1 specification (1999).
At the heart of this was the simple idea that a substantial portion of the description of how the Container-Managed Persistence Entity bean is implemented can be described in an XML file. EJB 1.1 had introduced the idea that the persistent fields of an Entity bean can be described in the EJB-JAR.xml deployment descriptor using the <cmp-field> element. EJB 2.0 extended this idea by giving the responsibility for generating the actual concrete classes that implemented those persistent fields to the EJB container, which used the field-level information in the deployment descriptor (plus the information in the EJB Entity abstract class) to build the persistence layer. It was in representing links between Entity classes that the EJB 2.0 spec took a step forward. By introducing the <ejb-relation> element and <ejb-relationship-role> element, the EJB 2.0 spec allowed the definition of relationships with varying multiplicity (1:1, 1:N, or M:N) between entity classes.
The second major element added in the EJB 2.0 specification that was applicable to persistence was the introduction of the Local EJB interface. As noted previously, in EJB 1.0 and 1.1 all EJBs were remote—a feature that makes sense for large-grained Session beans, but not for fine-grained Entity beans. By introducing Local EJB interfaces, EJB 2.0 allowed the developer to declare his Entities to be local only—and thus accessible only within a transaction controlled by an external Session bean. This approach made explicit some of the best practices and patterns that had been developed for EJB 1.0 and 1.1—most notably how Distributed Façade in Fowler [Fowler] was applied to EJB components and known as Session Façade by Deepak Alur [Alur] and Kyle Brown [Brown] in their books on J2EE design patterns.
However, the EJB 2.0 specification stopped short of a number of features that many developers had been asking for. For one, it left the problem of mapping of Entity attributes to relational database tables to the vendors. Also, it left the issue of how to transfer data out of an Entity bean into application contexts beyond the EJB container to the realm of best practices and patterns (specifically the Value Object pattern—again see [Alur]). But finally, there was something about the EJB specification as a whole that began to rub many developers in the wrong way. A substantial and vocal minority of Java developers began to complain in conferences, on blogs, and on forums like TheServerSide that the EJB specification was too heavyweight to be of use to the average business developer. They expressed a desire for a simpler persistence solution, one that would be based entirely on POJOs and that would not require an EJB container at runtime to complicate the architecture. In looking for a solution to their perceived problems, many practitioners began to turn to second-generation Java solutions such as Hibernate and iBATIS.
The Hibernate story begins in November 2001 when Gavin King started a SourceForge project to build an open-source object-relational database mapping system for Java. Given the dissatisfaction with the EJB 2.0 specification at the time, and the paucity of other cheap object-relational mapping solutions, the Hibernate project began attracting a significant amount of interest. By mid-2002 the project was well-established enough to announce a 1.0 version with considerable fanfare on sites like TheServerSide. Almost a year later, in June 2003, Hibernate 2.0 was released, which was a fully featured, robust system that was on par with commercial ORM offerings and that also featured tooling available on several open-source frameworks such as NetBeans and Eclipse. In October 2003, Hibernate “hit the big time” when the lead Hibernate developers were hired by JBoss.
Several simple principles underlie the success of Hibernate and its influence on later ORM specifications and frameworks. Chief among them is the fact that Hibernate is extremely lightweight, and that the programming model is very simple—Hibernate is based on a POJO model, and you do not have to implement special interfaces or extend special classes to render your classes persistent.
Some of its design principles we have already seen in the development of the EJB 2.0 specification—for every persistent class in Hibernate, there are corresponding entries in an XML mapping document that (for instance) lists the names and types of the persistent attributes of that class. Likewise, to represent collections (a 1:N relationship), you would simply add an element in the mapping document that declares a set, list, or other collection. However, one unique part of the Hibernate mapping file is that it contains all the information necessary to determine the mapping to a relational database. Table and column names are defined along with class and attribute names. This “all in one” approach made it possible to implement persistent objects quickly and easily. Another key aspect is that Hibernate can run inside or outside of an EJB container. Because of this, Hibernate is less restrictive and more complete in mapping object-oriented concepts to relational databases.
Perhaps the most important contributor to Hibernate’s success was its price—free. Because it was an open-source project, Hibernate was easy and cost-effective for developers to try first and then decide they liked both it and the idea of object-relational mapping. Although the EJB spec did much to make object-relational mapping acceptable to the Java development community, it was Hibernate that popularized it among developers.
The iBATIS framework took a different route than Hibernate. Rather than hiding SQL, iBATIS created a persistence framework much like Rogue Wave’s DBTools, in which SQL statements were projected to and from POJOs. The iBATIS framework grew out of a JPetStore Demo in response to an early 2002 Microsoft published paper claiming that .Net was 10 times faster and 4 times more productive than J2EE. Realizing that this was simply not the case, the iBATIS project (which previously had been focused on cryptographic software solutions) quickly responded with the JPetStore 1.0 release. Based on the same Pet Store requirements, JPetStore demonstrated that Java not only could be more productive than .Net, but also could do so while achieving a better, more open architecture than was used in the Microsoft implementation.
JPetStore made use of an interesting persistence layer that quickly captured the attention of the open-source community. Shortly after JPetStore was released, questions and requests for the SQL Maps and Data Access Object (DAO) frameworks spawned the project that would become known as iBATIS Database Layer. The iBATIS Database Layer includes two frameworks that simply happen to be packaged together: SQL Maps and DAO.
Today the iBATIS project is still heavily focused on the persistence layer frameworks known as SQL Maps and Data Access Objects (DAO). JPetStore lives on as the official example of typical usage of these frameworks.
So far this survey has examined the route that was taken by the traditional ORM vendors and open-source groups as they developed their systems for mapping objects to relational database tables. However, another group of companies took an entirely different approach to persisting objects. These companies held the view that the mapping of objects to relational tables should be avoided completely; that the right way to store objects was directly within the database as objects. To achieve this goal, they needed to rethink the idea of a database, specifically to build an object database.
An early adopter of this object database approach was a company originally called Servio Logic Corporation, which later changed its name to GemStone Corporation. Their product, the eponymous GemStone Object Database, provided direct persistence of Smalltalk objects in an object database. Not only did they support persistent Smalltalk Objects (accessed as persistent Collections), they also introduced many ideas in server-side object programming that were adopted within Java-based services, such as Remote Method Invocation (RMI) and EJB.
The object database counterculture began to move toward standardization in 1991 with the formation of the Object Data Management Group (ODMG, later the Object Database Management Group). This group released the ODMG 1.0 standard in 1993, and concluded its work in 2001 with the release of the ODMG 3.0 standard [ODMG].
Some key technical ideas were taken from object databases and the ODMG standards that became important in later standards. In particular, these important ideas were included:
Transparent persistence; that is, a developer shouldn’t have to be aware that he is making an object persistent. In practice, this means that the developer shouldn’t be responsible for writing mapping classes or writing SQL code.
Persistence by reachability; meaning that an object becomes persistent when it is related to another persistent object. So you would, for instance, make an Address persistent by adding it to an already-persistent Customer. This process begins with a collection of what are called Persistent Roots that are declared within the Database system itself.
Portability; that is, the standard should be portable across a number of different implementations—not only pure object database systems but object-relational mapping systems and hybrid object-relational systems as well.
After the release of the ODMG 3.0 standard, the ODMG was disbanded and its work was taken over by a working group within the OMG [Object Management Group]. However, one of the products of the ODMG continued its lifecycle when the ODMG 3.0 Java binding was submitted to the Java Community Process (JCP) as the basis for the Java Data Objects (JDO) specification [JDO].
JDO took much of its inspiration from the notions of object databases, and in particular, the ODMG specifications. The JDO 1.0 specification was completed and released through the JCP in April 2002 as JSR 12. Its primary API included the following concepts:
Any class that implemented the PersistenceCapable interface could be made persistent.
You can make instances of classes explicitly persistent by invoking a PersistenceManager, or implicitly by relating them to other persistent objects.
You fetch objects from a PersistenceManager either by object id or through a query. You can also obtain all the persistent instances of a class by asking a PersistenceManager for the extent of the class.
The release of JDO 1.0 resulted in multiple implementations of the JDO interface, with companies like Versant and Xcalia releasing commercial projects that implemented JDO 1.0, and several open-source projects including Apache OJB and JPOX adopting it as well.
As discussed earlier, by the time EJB 2.0 started to make its way into products, yet another counter-current was building in the Java community that was looking for alternate ways of providing access to persistent data within Java applications. When the EJB 3.0 committee began meeting, it became clear that revisiting persistence would be a key feature of the new specification. The opinion of the committee was that something significant needed to be changed—and as a result, the committee made the following decisions:
The EJB 3.0 persistence model would be a POJO-based model and would have to address the issue of “disconnected” or detached data in a distributed environment.
The specification would support both annotations (Introduced in Java 5) and XML descriptors to define the mapping between objects and relational databases.
The mapping would be complete—specifying not only the abstract persistence of a class, but also its mapping to relational table and mappings of attributes to columns.
So, the EJB committee combined the best ideas from several sources such as TopLink, Hibernate, and JDO to create a new persistence architecture, which was released as a separate part of EJB 3.0 specification and dubbed the Java Persistence Architecture (JPA) [EJB 3 Spec].
There are several vendors with open-source initiatives that have implemented the JPA specification, including JBoss (Hibernate JPA), Oracle (TopLink Essentials), and Apache (OpenJPA). OpenJPA is backed by IBM and BEA.
Even though the JPA represents the closing of another chapter in the history of ORM by merging a number of threads, approaches to IT and exploiting Java technology have not stood still. Specifically, the introduction of Service Oriented Architecture (SOA) has changed the way we look at application architectures as well as the way we develop them. For example, more applications are using XML as a canonical form for messages representing requests and responses passed between components of the system exposed as services.
Applying the SOA paradigm to persistence has resulted in a recent advancement that treats “information as a service.” This thought shift aims to free information from the application silos in which it typically resides. With this approach, information is delivered as a service. Applications needing access to the data interact with the service; and the information is exposed via open standards leveraging Web services and XML. Applications can access their data via language neutral technologies such as XQuery and XPath. Because of the use of open, language neutral standards, more applications (even those not based on Java) can have access to the information they need.
IBM’s DB2® has been extended to include native storage for XML. This makes DB2 Version 9 the industry’s first database designed with both native XML data management and relational data capability. In the past, XML data had to be reformatted or placed into large objects—character or binary large objects (CLOBs or BLOBs). With this approach, data is stored as a single unit or continuous byte string. Such a storage approach unearthed performance challenges when querying for data within the XML document or when one had to update even just a small portion of the XML document. The entire XML document had to be read and parsed before a query could be processed. Another approach commonly used to deal with storing and querying XML documents is the practice of document shredding, in which an XML document is mapped to one or more relational columns. However, this approach does not leave the XML document intact.
The information as a service technology stores XML in a direct form, as a preparsed annotated tree. XML is stored in the database as using a hierarchical node-based model. In this model, each node is linked not only to its parent, but also to its children. This “pure XML” storage capability is an efficient method for accessing and storing entire XML documents, presenting major performance benefits to the consuming application. The capability to deliver information as a service that can be efficiently accessed makes the technology particularly enticing for SOA environments.
DB2 9 allows for the creation of hybrid tables that consist of both relational and XML data. The database supports a new XML data type. Such a hybrid table can be accessed via industry standard extensions to SQL named SQL/XML that allow for SELECT statements to retrieve XML documents in whole or in part. Additionally, DB2 supports the XQuery language, which allows for one to use path expressions to navigate through a stored XML document’s hierarchical structure.
In contrast to large companies that could afford to host their own web sites, many smaller companies prefer to outsource their web sites to external companies that provide the infrastructure, such as Yahoo hosting. These external companies relied on scripting languages, like PHP and Perl, with embedded SQL, that provide a quick and easy way to build web sites. These facilities reduced the amount of code one had to write to create a web site, but were not focused on developing reusable business components. Further, with the emergence of AJAX in the browser for rich dynamic content, and community web sites like MySpace and FaceBook, the need to quickly combine web data sources to create new applications came to the forefront. This focus on rapid development led to a new paradigm called “Situational Applications.”
Enterprises are now looking to take advantage of this paradigm to create new business opportunities. As such, exposing data through scripting languages using embedded SQL has become popular with enterprise web developers. With the advent of Information as a Service and Web 2.0, companies are looking to exploit these techniques within enterprise Java applications.
To meet this need, pureQuery is an IBM solution for Java data access designed for performance and exploiting SQL. As with iBATIS, the goal is to embrace SQL rather than hide it. But unlike iBATIS, SQL can be bound statically in a mapping file as well as directly in the Java code. pureQuery also embraces the notion of tools to greatly increase developer productivity. pureQuery can be used with a set of Eclipse Java plug-ins that can provide SQL assist inside Java programs. Besides having its own API for direct programmatic access, pureQuery can be layered underneath another framework, such as Hibernate or OpenJPA.
One example of layering on top of pureQuery can be found within ProjectZero. ProjectZero is an IBM incubator project focused on agile development of Web 2.0 applications following the SOA. Web 2.0 applied to SOA allows web artifacts to extend the reach of SOA. This can be thought of as Web Extended SOA.
In this brief historical survey of some important ORM frameworks (see Figure 1.1 for a graphical timeline view), we’ve seen how a common set of features evolved through various language-specific frameworks, such as Borland’s Delphi (Pascal), Rogue Wave’s DBTools (C++), and The Object People’s TopLink for Smalltalk. Then we saw how lessons learned from these pioneering efforts came to be part of the “first generation” Java standards, such as JDBC and EJBs. We saw how open-source initiatives like Hibernate emerged to quickly fill the gaps in these standards, and how the object database perspective led to an alternative standards body (ODMG) and approach to Java persistence (JDO).
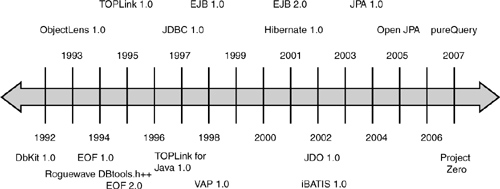
Fortunately, we saw that these paths converged within the JPA standard, proving that a complete, metadata-driven object-relational mapping framework can be defined in such a way that multiple vendors and community development projects like OpenJPA can provide compatible, fully featured implementations. At the same time, newer simplified approaches that don’t require a full ORM framework, such as iBATIS and the evolution of information as a service and pureQuery, mean that new ideas will continue to keep the field active and growing.
For the purposes of this book and our architects’ point of view, this history lesson helps us to answer this question:
Which mechanisms did you evaluate and why?
From this history, we chose the following five frameworks as representative of various approaches to persistence:
JDBC—. Though not really an ORM, JDBC serves as a baseline for comparison as an API used to directly access relational databases with SQL upon which many of the other frameworks are built.
iBATIS—. iBATIS serves as a data point for simple frameworks that separate the SQL from the Java code so that it can be easily tuned.
Hibernate—. As one of the first, and by far the most popular open-source OR mapping frameworks in existence, and as a major contributor to JPA, Hibernate serves as another good baseline for comparison.
OpenJPA—. This demonstrates the JPA standard in an open-source framework that can be tested side by side against the others.
pureQuery—. pureQuery provides an early look at one possible future of Java persistence in the context of SOA, Web 2.0, and information as a service.
One chapter is devoted to each of these five frameworks later in the book. First, though, Chapter 2, “High-Level Requirements and Persistence,” discusses business and IT requirements around persistence that you should consider; Chapter 3, “Designing Persistent Object Services,” covers detailed ORM design issues that will likely impact your choice of persistence mechanisms; and Chapter 4, “Evaluating Your Options,” gives a systematic questionnaire-driven approach you can use to evaluate each framework.