
In Chapter 1, we gave you a brief overview of the history of the most popular persistence mechanisms. Understanding the history of popular persistence mechanisms should help guide your choice of which ones to evaluate. Ultimately, understanding your requirements will drive the selection of which mechanisms to use in your projects.
But we recognize that in today’s more “agile” development world, it is not often possible to fully understand all your requirements at the beginning of a project. Thus, the purpose of this chapter is to help you quickly hone in on the most important requirements as they relate to persistence so that you are in a great position to answer this question: Which mechanism(s) do you use to provide access to persistent data in your SOA-style Java application programs and why?
You may be tempted to skip this chapter altogether. Many software architects feel that they already have a solid understanding of how to capture IT requirements. However, it seems that some software architects feel that the needs of the business are not directly associated with the application code, and therefore those requirements will make little or no difference in which persistence framework is chosen.
But nothing could be further from the truth. Imagine that you have been asked by your CTO to make a build-versus-buy (or even borrow-or-steal) decision about the approach to persistence for a major project. In our experience, you will need to be able to articulate compelling reasons for your choice to various stakeholders in the company who are interested. These stakeholders fall roughly into two groups (as shown in Figure 2.1):
Business Executives, who will want to understand how the technology decisions, including the choice of persistence mechanism, will impact their ability to support the needs of the business.
Technical Leaders, who will be wondering how the choice of a framework will change their best practices for designing and implementing enterprise quality solutions.

It is worth a few pages to get an overview of the requirements that are near and dear to those roles with which you (as an architect) may not be so familiar.
It is likewise worth noting that there are various techniques to gathering requirements—ranging from traditional waterfall to more modern agile methods. We will not delve too deeply into comparing approaches because there are many good references in the literature on these topics. For example, Robertson & Robertson [Robertson] is a good reference on requirements gathering in the context of traditional methods, whereas [Cohn] or [Ambler] are good references on agile methods.
For the purposes of this book, we think of an approach as “waterfall” if it is phase (or activity) centric with respect to its releases. For example, Figure 2.2 shows an approach in which you gather all the requirements for a release before starting the subsequent design, code, test, and deploy phases in turn after the other completes.
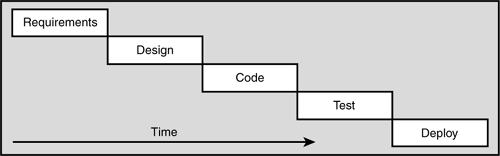
Likewise for this book, we consider an approach “agile” if it is function (or service) centric with respect to the releases. For example, Figure 2.3 shows an approach in which each function (Fn) is developed in a “depth first” fashion and held until a critical mass of function is ready for final testing and release (Rn).
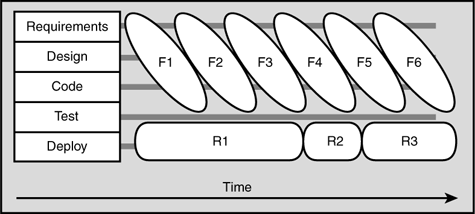
The common aspect to both approaches is that you first must gather the requirements, then design the solution, then code the design, then test the code, then deploy the application. The real difference is in how much of one activity you complete before going on to the next.
The reasons we prefer agile approaches over waterfall are many. One reason is that we are all part of an organization called IBM Software Services for WebSphere (ISSW), where we help customers exploit IBM WebSphere products and technologies in their enterprise applications—and as quickly as possible. This leads us to prefer short-term projects that lend themselves well to agile approaches. Another reason is summed up in the following “truism”:
Think before you act—just don’t do all of your thinking before acting.
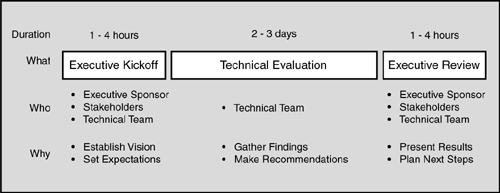
When we in ISSW are asked to make recommendations on major architectural components like persistence mechanisms, we like to engage in an evaluation workshop with technical leaders across the organization to gather findings and make specific recommendations.
We also like to “bookend” this workshop with executive participation: first at the beginning with a kickoff session to show commitment by setting the vision and expectations, and then at the end with a review session to have them receive the results. Figure 2.4 shows the timeline of a typical technology evaluation workshop.
And where a choice of persistence mechanisms is concerned, those frameworks that can be shown to have the minimum total cost of ownership (TCO) with a maximum Return on Investment (ROI) will usually win over those that do not.
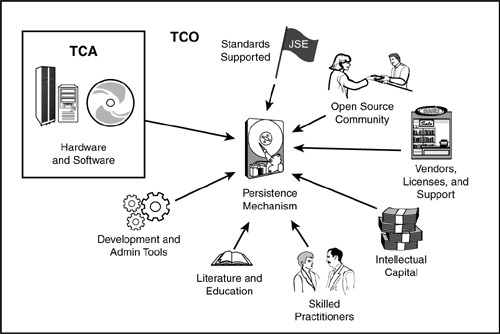
In general, total cost of ownership looks at expenditures and is defined as an aggregate of all the costs incurred in the life cycle of an asset investment, from acquisition to disposal. For example, when considering the TCO of a car, you need to consider not only the purchase price (part of the total cost of acquisition, or TCA), but also the expenses you will incur throughout the life of the car—including expected costs such as gas, tires, oil, and regular maintenance, as well as unplanned expenses such as engine repair and insurance claim deductibles (see Figure 2.5).
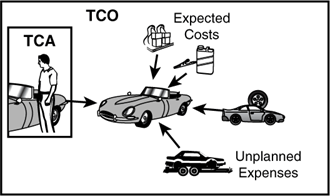
Unfortunately, many enterprise architects fail to grasp the need to consider TCO when choosing technologies such as persistence frameworks, and instead myopically consider only TCA. Of course, the cost of acquiring a given persistence mechanism should be considered as part of the TCO calculation, but by no means all of it.
And computing TCO for a technology choice such as a persistence mechanism is not always simple because some of the factors that impact TCO are hard to assign specific cost numbers. For example, while hardware and software dependencies are factors you should consider that are somewhat easy to compute, you should also consider intangibles about the framework like those shown in Figure 2.6, such as
Standards supported
Number of open-source and community-driven activities
Number of vendors, types of licenses, and options for support
Intellectual capital considerations
Availability of skilled practitioners
Literature and education
Development and admin tools
Often the cost of selecting your persistence technology may be impacted by choices for other important architectural aspects of the system. For example, you may choose a particular application server runtime that ships with a persistence technology, and therefore reduce the overhead of support.
Before we discuss some of the specific factors to consider, we want to point out that there are downsides to focusing purely on minimizing TCO. For example, although it might seem more cost-effective to use a single vendor for everything, you must also take into account that a particular application will likely outlive the hardware and software platform upon which it is deployed—so you have to factor in the capability to embrace change. In short, it is important to remember that requirements analysis always involves trade-offs.
One question we almost always hear when presenting a proposal for a persistence framework is this: Do you have to buy additional hardware or software to use it? The reason this question usually gets asked relatively early is that the capital expenses required for new hardware and software make up part of the total cost of acquisition, which tends to get more focus.
Mechanisms that run on existing or multiple platforms are therefore going to be more attractive than those that don’t.
Two software platforms that are ubiquitous to most SOA applications based on Java are Java Platform Standard Edition (JSE) and Java Platform Enterprise Edition (JEE). Because Java is a hardware-neutral technology, it allows you to deploy to various hardware platforms. In addition, Java EE platforms provide a full range of enterprise features, such as messaging, clustering, and security. Often platforms are chosen based on the end-to-end architecture, so having your persistence technology integrate with that big picture is important.
A.2.1
Sometimes it is necessary to have a particular persistence mechanism run on both Java SE and Java EE platforms. For example, most companies do not have the resources to install fully configured Java EE platforms on every developer’s working environment. These are normally deployed only on QA and stress-test servers, as well as production systems. So the capability to unit test on a Java SE platform (or scaled-down Java EE platform) can help minimize the costs without sacrificing software quality. Figure 2.7 illustrates this approach to testing. Keys Botzum [A.2.1] wrote an excellent in-depth article on this subject that you should read.
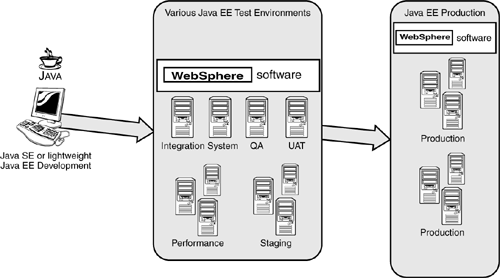
It is worth noting that there are risks in this approach to testing. For example, certain types of application bugs may not show up on Java SE application servers, and therefore may not be found until later in the QA or stress-testing stages, when they are likely to be more expensive to fix.
Adherence to standards is an equally important high-level requirement to consider. Support for an industry standard indicates that the framework’s specification has been scrutinized by a large number of IT professionals who have a vested interest in making sure that it meets their basic requirements. We are big believers in the idea that “two heads are better than one” because synthesizing multiple points of view can result in a whole greater than the sum of the parts, as illustrated by the blind men and the elephant analogy (see Figure 2.8).

As we mentioned in the preceding section, “Hardware and Software Dependencies,” standards often allow vendors to create ideal development testing environments separate from their production environment by stubbing out the implementations behind a particular component (allowing for quick and automated execution of test and debug cycles).
Some standards of interest to Java programmers needing access to persistent data include JDBC (Java Database Connectivity), EJB 3 (Enterprise JavaBeans), and JPA (Java Persistence API), the history of which was covered in Chapter 1.
However, there are some downsides to considering only the standards supported by a framework. Standards can be slow to evolve when there are many participants driving a cumbersome consensus-based voting process. And after a consensus has finally been reached, it can take a significant amount of time for reputable vendors to support the new standards—even if just a new version of existing ones. As such, standards almost always lag behind the requirements of cutting-edge-type applications.
The existence of standards increases the likelihood that a community of practitioners will spring up to create methods and best practices on how to properly exploit the associated technology. And sometimes “open source” projects start up to collectively fill gaps in the standards and associated tools. For example, the Spring Framework often used with Hibernate (another open-source project in its own right) provided “dependency injection” (DI). DI is the capability to proxy dependent services without explicit coding so that the components can be moved easily from one environment to another—such as when unit testing and then stress testing a component.
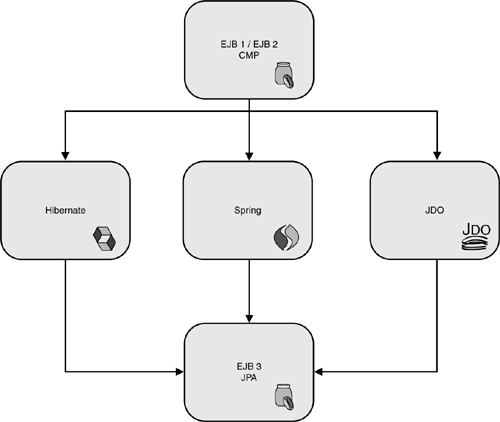
Thus, open-source software and community-driven development is another aspect that should be considered by executives. It is often the case that a vibrant community can drive certain technologies into “de facto” standard status. And de facto standards will just as often drive an industry standard committee to change direction. For example, the vibrant community behind frameworks like Hibernate drove the Java EE standard to drop the Container Managed Persistence aspect of Enterprise JavaBeans in favor of a new persistence standard called JPA (see Figure 2.9 for a “family tree”).
But relying on open-source communities has its own risks, especially if it is one of the “one man” projects that abound, or the community behind it suddenly dies out. The reality is that many standards which appeared to be popular have died out as a new approach wins the hearts and minds of the community. For example, there have been two versions of entity Enterprise JavaBeans components that provided an ORM framework for applications. Unfortunately, “betting on the wrong horse” can cause a great deal of churn in your approach to persistence in the enterprise.
Another measure of a vibrant community is whether there is a market for the technology. Specifically, how many vendors provide (and support) the framework? Usually it is “the more the merrier” when it comes to vendors or open-source communities involved with a given technology, because no one wants to be locked into a single source or (maybe worse) an unsupported framework. And open-source communities with big vendors behind them to provide “support for fee” usually do better than others. For example, JBoss owns Hibernate and BEA supports OpenJPA—opening us up to a classic chicken-and-egg situation when considering whether it is the vibrant community that attracts the vendors or vice versa. Regardless, these are definitely strong, active communities.
Most persistence technologies fall under either commercial licenses or open-source licenses. With commercial software licenses, a user pays a fee to obtain a license to use the software. This license defines the terms and conditions under which the user may or may not use the software. For example, some commercial database server software licenses are coupled to the number of processors running on the machine that hosts them. It is paramount that an enterprise be intimately aware of the licensing agreements that they have accepted, because violation of these agreements can be quite costly.
If the persistence technology is backed by a commercial firm, you need to consider whether the commercial vendor charges for support. Also, you must consider (even if it is remote) the possibility of the commercial provider closing shop. Many enterprises often choose a commercial firm for accountability. If there is a bug in the persistence framework, the enterprise typically wants someone to fix it right away.
With some open-source solutions, code fixes and updates can be “philanthropic” with little or no accountability. As such, the enterprise must hope that their own development staff can fix any blocking bugs or that someone in the open-source community can solve the problem at hand. However, the license may restrict you from making changes without contributing that change back to the original source.
Licensing and intellectual property considerations will, of course, vary from project to project within your enterprise. For example, if you are an independent software vendor who specializes in making software to sell to other companies, your ability to patent and sell an application you build that leverages open-source persistence technologies can be greatly affected by the open-source license you are dealing with. On the other hand, if you are using a persistence technology for an in-house application and do not plan on selling or patenting it, your IP staff will likely have less concerns about the license agreement associated with the open-source persistence technology.
Complicating the matter, there are more than 50 types of licenses associated with open-source software to understand. Popular open-source licenses include the General Public License (GPL), Limited GPL (LGPL), the Berkeley Software Distribution License (BSD), the Apache Software License, and the Mozilla license. Many critics of the GPL refer to GPL-style licenses as “viral,” in that GPL terms require that all derived works must in turn be licensed under the GPL (see Figure 2.10 for a graphical view, showing how eventually everything becomes “infected” by the GPL). This restriction can be a major concern for enterprises trying to protect the internals of the software applications that they build.
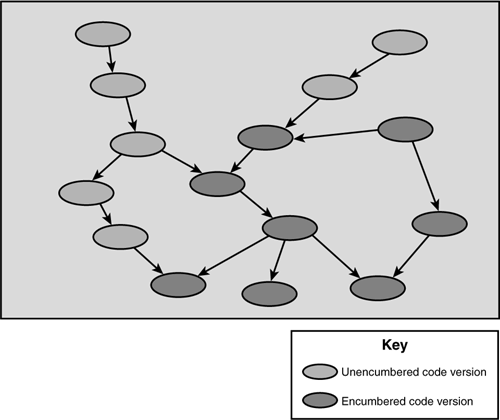
There is a philosophical difference between GPL- and BSD-style licenses; the latter put fewer restrictions on derived works. Other licenses, such as an “Apache” license, have very few restrictions on derivative works, and are usually more popular because of it.
Another interesting IP issue that arises when using a persistence framework based on open-source software is that you are typically dealing with a “product” developed by a community of programmers from around the world. It can be difficult to ascertain whether the open-source code infringes on third-party patents.
Therefore, an enterprise may need to involve their legal staff to closely analyze the license agreement before selecting a framework based on open-source projects—and this expense should be considered part of its cost of acquisition.
We have found that one of the biggest reasons to like frameworks based on standards and vibrant open-source communities is the higher probability that there are enough skilled people available inside the company to design and build applications using that particular persistence technology and approach.
A related question we are often asked is how much skill is needed to successfully use the persistence framework(s) being proposed. Those mechanisms that require a great deal of specialized skill in order to master them are less attractive than those that are simpler to understand and learn.
So before you adopt a new persistence technology, the current skill set of your development team needs to be considered. For example, has anyone on the team worked with the persistence technology being considered? An informal survey to understand what skills you already have in-house can help in the decision-making process.
Many persistence frameworks are considered similar to others; therefore, the learning curve of a developer who is familiar with a similar persistence technology might be less steep than that of one who has never been exposed to similar technologies. The skills survey should perform a gap analysis of the current skill set of the development staff compared to the skills needed to be successful with the technology on an actual enterprise project. For example, developers skilled in a technology such as Hibernate will make an easier transition into another technology like OpenJPA.
When there is a lack of skill regarding a persistence technology in-house, it is a common practice for enterprises to hire outside services—either as temporary consultants or as permanent employees to augment the development team. And a resilient development team should also be able to recover quickly from the unpredicted loss or absence of a development team member. The realities of people getting sick (or just plain sick and tired) and deciding to leave the company need to be considered. Project managers and executives need to consider “what if” scenarios in regard to losing development team members and being able to recover from such losses through hiring of new team members.
An assessment of how easy it is to find skills from outside sources provides yet another measure of the strength of a persistence mechanism with respect to the technical community. This analysis might include a survey of how many resumes are returned in a search of an Internet job search engine for a particular persistence technology.
The lesson here is that picking a brand-new or esoteric technology for your persistence needs can be a costly decision in the long run by making it harder to staff your projects.
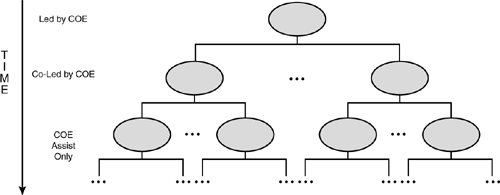
To jump-start the learning process and close relatively narrow skill gaps, you should consider providing literature and training about how to best use a particular technology in the context of your enterprise. We have helped many client firms to institute Centers of Excellence (COE) to help evaluate technologies and customize the best practices to better fit with the overall architecture, and then train the development team on how to apply them.
Figure 2.11 shows how these Centers can play a direct role in bringing the rank-and-file developers onboard with a new technology—through mentoring in the context of actual projects. This on-the-job and train-the-trainers approach has proven itself to be “viral” as well, quickly spreading expertise exponentially throughout the organization. With each subsequent “generation,” the roles of the COE and development team leads are gradually reversed, until the development team becomes self-sufficient.
Therefore, another gauge of the vibrancy of a persistence technology is the availability of good books or technical articles on the subject. Although not necessarily a measure of simplicity, nor a substitute for having one or more skilled practitioners on the team to serve as mentors, the availability of literature documenting proven best practices can help steer a project toward success even when staffed by novices. The availability of conferences (even if just a track in a more general-interest conference) and education associated with the persistence framework is another good indicator of vibrancy within a technical community that is useful to consider when making your choice.
Modern-day programmers typically use integrated development environments (IDEs) and agile approaches to both speed their development efforts and reduce the complexity (and educational requirements) of using the technology.
Sophisticated visual object-relational mapping (ORM) tools are often available in these IDEs, depending on which persistence technology is adopted. Therefore, an enterprise should consider what ORM tools are available for a particular persistence technology when making a choice.
Of course, building a persistence framework around an ORM tool can cause dependency on the tool and, more problematic, can mask the complexity of the underlying mechanism. We find that the best persistence technologies usually have an easy-to-understand programming model, in which case the ORM tools accelerate development by automating tedious tasks.
Another important tool that is useful for persistence in the enterprise is one that enables tracking the end-to-end path of data during runtime from the application code into the database and back again. For example, sometimes a poorly written SQL statement is tracked down through monitoring tools in the database. Being able to help a developer quickly change the component that issued the SQL could be important to resolving a serious performance issue. And programming models for persistence that separate the SQL from the code so that only a configuration change is required are even better.
End-to-end monitoring is an important aspect of what is now being referred to as Data Governance. Figure 2.12 shows the full life cycle that an architect should be considering with respect to data management.
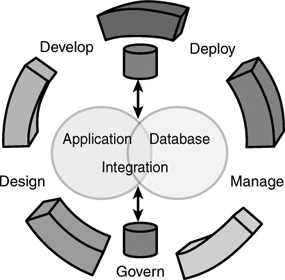
The availability of end-to-end monitoring and other Data Governance tools should be factored into your evaluation of a new persistence mechanism.
Rather than adopting an existing persistence technology, many enterprises decide to roll out their own persistence frameworks; they, in effect, reinvent the wheel. In our experience, this is a practice that should be avoided because what may seem like a bargain in the short term ends up costing extra in the long run.
Enterprises typically have core competencies in an industry-specific domain, and it is disheartening to see (for example) a financial firm spinning its wheels creating yet another half-baked ORM framework from the ground up when it could be using those same cycles to innovate solutions critical to its core business processes.
What these teams fail to realize (and their enterprise architects fail to point out) is that all the factors contributing to TCO discussed in this section come into play when developing a framework—in addition to the extra TCA expense of building the basic runtime components of a homegrown mechanism. In other words, the need for standards, tools, processes, education, and support do not go away, so the costs just keep adding up. In fact, these costs are often made worse by the fact that when you invent a proprietary framework, you have only a limited community to support the technology and develop these assets crucial to a reasonable TCO.
So unless you are a middleware or database vendor, we strongly recommend that you focus your development team on writing high-quality applications that support the mission-critical business processes of your enterprise.
Assume that during the evaluation workshop kickoff, the business executives have (wisely) decided against building a persistence framework. They want your team to choose one or more existing mechanisms that best meet the TCO requirements of the business and the IT requirements of typical applications that will be built over the next two to three years.
It is worth mentioning here that regardless of the time frame, an evaluation of “fitness of use” of a given technology like persistence for a given project should be done on every project. So, what are the technical requirements related to persistence that determine fitness?
Our view is that IT requirements describe the technical constraints within which a software system must operate. So with this in mind, we strive to understand these constraints as objectively measurable characteristics that can be tested. This “test first” approach is essential to agile methods that have you design the simplest thing that can possibly work—and thus avoid the analysis paralysis that can occur with waterfall approaches.
This discussion about the approach to gathering requirements does not directly answer the question about which technical requirements you should consider when choosing a persistence mechanism, except that the focus on testing allows us to recast the question a bit: What is a good way to classify the objectively measurable characteristics of a system?
This recasting helps because the ISO 9126 standard [ISO9126] classifies measurable software quality characteristics into the following six categories:
Functionality—. A set of attributes that bear on the existence of a set of functions and their specified properties.
Reliability—. A set of attributes that bear on the capability of software to maintain its level of performance under stated conditions for a stated period of time.
Usability—. A set of attributes that bear on the effort needed for use, and on the individual assessment of such use, by a stated or implied set of users.
Efficiency—. A set of attributes that bear on the relationship between the level of performance of the software and the amount of resources used, under stated conditions.
Maintainability—. A set of attributes that bear on the effort needed to make specified modifications.
Portability—. A set of attributes that bear on the capability of software to be transferred from one environment to another.
We have found these categories very useful, not just because they can be used to define relatively precise requirements, but also because each category can be considered separate aspects (or domains) of the system that can be independently modeled and combined into an enterprise solution. Figure 2.13 shows how these different aspects combine.
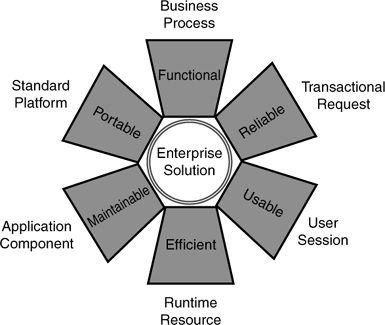
We find this factored approach to requirements more suitable for service-oriented applications and agile methods because it follows the world’s first recorded best practice: “Divide and Conquer.” In keeping with Divide and Conquer, we will look at each category separately in terms of its ramifications on the persistence requirements of applications.
Functionality can be the most important requirement to consider because if an application does not support some aspect of your mission-critical business processes, it is not much good for the enterprise.
One way to capture functional requirements of your business processes is with “use cases.” A use case is a fundamental feature of the Unified Modeling Language (UML). UML is a very broad graphical language; because we do not have the space nor the inclination to provide a complete tutorial, we recommend [Booch].
For the purposes of this book, assume that a use case identifies “actors” involved in an interaction with the system and names the interactions so that they can be explored in detail. Figure 2.14 shows an example of a use case diagram.
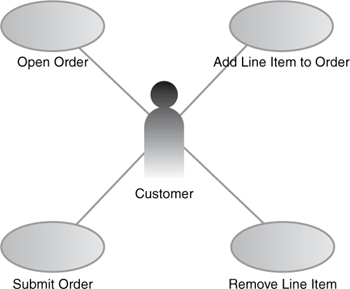
At this extremely coarse level of granularity, a use case diagram does little more than serve as a graphical index into more precise descriptions of the functional requirements. Good use case descriptions at any level have pre- and post-conditions that specify the state of the relevant components of the system before and after the case, along with functional steps that occur to make the state change. [Cockburn] is a good reference. For example, here is the detailed description of the Open Order Activity of the Place an Order use case:
Precondition:
The user is logged into the system.
The user triggers a new order use case by one of the following methods:
By performing Add Line Item Use Case (#x) when no Order exists.
By the submission of a batch order request.
Steps:
The system looks up the customer record by using the customer ID stored in the User Authentication Credentials.
The system checks whether the user exists.
If the user exists, continue to the next step.
If the user does not exist, a customer exception is thrown to the UI and activity ends.
The system checks whether User contains a current Open Order.
If the user does not have an open order, continue to the next step.
If the user has an existing open order, an exception is thrown to the UI and activity ends.
Create a New Order Record with the following information:
New generated ID (nonfunctional requirement #xx: must use database generated key facility).
Customer ID.
Status set to OPEN.
Postcondition:
A current open order is assigned to the user.
For all but the finest granularity use cases with a few linear steps, it can be useful to graphically show the activities that can occur within the use case. These steps can be shown using activity diagrams or state diagrams, depending on the nature of the use case. In our case, because we are operating on a single passive object like an order, it is best to use a state diagram that shows the life cycle. Figure 2.15 shows the state diagram for an Order.

And just as the steps can be graphically documented using state or activity diagrams, one can show the pre- and postconditions of the use case with class diagrams capturing the relationships among domain objects essential to the processing steps. The pre- and postconditions can be considered “states” of the application, and often represent the data that needs to be stored persistently. One reason we like state diagrams is that these states are often common across different functions and use cases.
The transitions in the state diagram usually include one or more persistent actions in your applications. For example, the open order transition in Figure 2.15 will translate to some create operation that is later realized by an API call to your persistence framework and ultimately some type of SQL Insert. Chapter 3 describes these best practices for domain modeling in more detail, and how these models become the functional endpoints for the OR mapping problem to be tackled during detailed design (with the database schema representing the other endpoint).
Reliability is considered the next most important requirement because it is not enough to show that your system can perform critical functions only under ideal conditions. If an application system does not work reliably under load or when its subsystems fail, then it doesn’t really matter whether it supports the business processes. It is important to ask yourself some tough questions; but we recommend that you ensure they document measurable characteristics of system performance. Here are some examples of such questions, with some slight rephrasing if necessary to get to measurable requirements:
Can this system run reliably even when there are hardware failures? How much failure can you tolerate?
What about replication and failover scenarios? How quickly do you need the system to come back up?
Is manual intervention acceptable, or must the system failover automatically?
Reliability and persistence go hand in hand with transaction management. When you are choosing a persistence framework, it is important to consider how the framework works with the transaction management system you are using. For example, can your persistence mechanism allow persistent actions to run under a “Container Managed Transaction” of your EJB container?
We will not go over transactions in detail, but we will briefly discuss some concepts. A good reference on transactions can be found in [Little]. For the purposes of this book, a transaction is a unit of work that accesses one or more shared resources maintaining the following four basic “ACID” properties:
They must be Atomic: An atomic transaction must execute completely or not at all.
They must be Consistent: Consistency refers to the integrity of the underlying data store and the transactional system as well.
They must be Isolated: The transaction must be allowed to execute without interference from other processes and transactions.
They must be Durable: The data changes made during the course of a transaction must be written to some type of physical storage before the transaction is successfully completed.
Most database systems are specifically designed to maintain the ACID properties of units-of-work accessing the database within a transaction. The persistence mechanisms associated with a given database will have programming model components geared toward starting and committing transactions, and providing basic “CRUD” functions (create, retrieve, update, and destroy functions associated with objects representing persistent data).
If your application does what you want and does it reliably, but your application’s users cannot easily access its functions from the channels they have available to them, then what good is it?
In this context, usability requirements can be characterized by describing the type of session through which a user interacts with the system. There are at least two interesting design patterns associated with user sessions to consider when evaluating persistence mechanisms: (a) online and (b) batch.
Online applications have very different application characteristics than batch applications with respect to a persistence mechanism. For example, batch applications typically perform the following actions:
Execute a “batch” of functional requests in a single transaction (often a very large number of requests).
Access the input requests or output results as a “stream” (for example, a DB cursor) for efficiency.
Emphasize reducing round trips to DB in order to process large amounts of data in as short a time as possible, such as through sorting the input stream.
Execute the batch application usually by some kind of scheduling scripts like cron.
Figure 2.16 shows the overview of a batch application, in which a batch controller component handles the looping and outer transaction management and invokes business logic that is sometimes shared with online applications.

A good persistence mechanism will enable applications to bulk-read and bulk-update persistent objects mapped to an underlying relational datastore. Also, to get the economies of scale, the framework should enable sorting the data in the batch stream.
The most functional, reliable, and usable system will ultimately fail if it does not make efficient use of its resources (such as processors, memory, and disk space)—mainly because TCO and possibly user satisfaction will suffer.
For the purposes of persistence, we will examine two strategies that help minimize response times and maximize throughput, the primary measures of efficiency, by trading one resource for another:
Isolation (an object locking strategy) enables multiple transactions to run concurrently and yet maintain the ACID properties, thus getting better throughput by fully utilizing CPU resources.
Caching (an object preloading strategy) minimizes accesses to external systems by preloading objects in system memory, thus getting better response time at the expense of system memory.
These design strategies require understanding both the response time and throughput requirements and the amount of resources available to the system.
Isolation is especially important to understand when you are dealing with persistence mechanisms. Developers often must choose the correct isolation levels for each use case to enable the application server to balance CPU utilization and integrity (reliability) requirements. The level of isolation controls how data being accessed is locked from other transactions.
To understand isolation levels, we first need to define conditions that happen when two or more application functions operate on the same data:
Dirty reads occur when a transaction is able to read changes made by another transaction before the second transaction has completed.
Phantom reads occur when a new record added to the database is detectable by another transaction that started prior to the
INSERTthat created the record.Repeatable reads occur when a query is guaranteed to return the same result if read again during the same transaction, even if another transaction has modified the data.
To ensure the preceding conditions, relational databases normally use several different locking techniques. The most common techniques are these:
Read locks—. Prevents other transactions from changing data read during a transaction until the transaction ends. This prevents nonrepeatable reads.
Write locks—. Meant for update. Prevents other transactions from changing the data until the current transaction is complete but allows dirty reads by other transactions and by the current transaction itself.
Exclusive write locks—. Meant for updates. Prevents other transactions from reading or changing the data until the current transaction is complete. It also prevents dirty reads by other transactions.
Therefore, the programming model for a good persistence mechanism will allow developers to specify a functional isolation level, either through some configuration option or programmatically in their application code. This isolation level can be passed to the database so that the proper locking strategy is applied. The following terms are often used to describe isolation levels:
Read uncommitted—. Transactions can read uncommitted data (data changed by a different transaction that is still in progress). This means that dirty reads, nonrepeatable reads, and phantom reads can occur.
Read committed—. The transaction cannot read uncommitted data; data that is being changed by another transaction cannot be read. This prevents dirty reads; however, nonrepeatable reads and phantom reads can occur.
Repeatable read—. The transaction cannot change data being read by a different transaction. Dirty reads and nonrepeatable reads are prevented, but phantom reads can occur.
Serializable—. The transaction has exclusive read and update privileges; different transactions can neither read nor write to the same data. Dirty reads, repeatable reads, and phantom reads are prevented.
The type of isolation is determined by the functional requirements. The stricter the rule, the less performant the application can be. The looser the rule, the greater your chance for data integrity problems. You must have a correct understanding of all the use cases associated with a particular data component so that you can make the correct choice.
Even with the weakest isolation levels, you may not be able to meet the response time requirements for accessing your data. Applications may need to cache data in order to minimize the path length. How you cache data will be driven by your IT requirements, including available memory and servers. Certain use cases may require more sophisticated caching solutions than others. Some important questions to consider are these:
How many users need to access the same data at the same time?
How many units of work are invoked per user session?
What data is accessed in each unit of work?
How often is a given data item read versus being updated?
How many application servers are available?
How much memory is available per application server?
The answers to the first four questions help determine how long to cache your data. Specifically, a good persistence framework will provide the capability to bind cached data to one of at least three different scopes:
Transaction (unit of work). For example, as a user submits an order, the product quantity data is cached only for the duration of the transaction because it’s frequently updated by other application functions and users. The unit of work performs all of its update operations on this data against the transaction cache and then sends all the changes to the database at transaction commit time.
Session. For example, the related order entry application allows users exclusive access to a “shopping cart” which contains line items that represent a pending (open) order. As long as the user is logged in, the session cache is valid, and the shopping-cart data can be accessed without going to database. When the session ends (through either an explicit logout or an implicit timeout), any changes are committed to the database.
Application. For example, as the order entry application allows users to add line items to the shopping cart, the rarely updated product catalog data is accessed from the cache for as long as the application server is active. When the server is restarted (or catalog entries are programmatically invalidated), the product catalog cache is reloaded.
The amount of data and its access pattern will often have more impact on caching strategy than the life cycle scope. For example, a given banking application allows users to access their account history as part of their session. This history data is unlikely to change after it has been created (unless you have found a way to change the past). If most of these banking functions access large amounts of history data that prevent it from being effectively cached within a single application server context, then the database itself may become the bottleneck as every request goes to the back end data store.
In this case, you may need a more sophisticated caching solution that partitions the data across hardware and servers based on some mapping associated with the cache data key (for example, user ID). This approach usually requires some equally sophisticated grid-based caches such as Object Grid [A.2.2].
A good persistence framework allows a programmer to custom-manage the data maintained in a cache, such as through a pluggable interface point that allows you to integrate with a grid-based cache.
Some use cases may benefit from caching to meet response-time goals, even though the data may periodically change. This scenario is sometimes referred to as “Read Mostly,” which requires the mechanism to provide a means to invalidate the cache (as described earlier in the discussion on application scoped cache entries. Of course, you have to be careful—if the data gets updated often, the overhead of asking whether the data is in the cache is valid coupled with the reduced amount of memory available for other purposes begins to outweigh the benefit of occasionally finding valid data in the cache.
Consider also that there are opportunities to cache outside of the scope of the persistence mechanism. For example, you can cache data inside network proxies that sit in front of the application server. Further, you can choose to cache the data inside the user’s browser (as is the trend with modern Ajax applications). Although these caches are normally outside the scope of Java-based persistence mechanisms, they should be considered in the context of your end-to-end architecture (and may make those persistence frameworks that support “information as a service” more attractive).
Now assume that your application reliably does what you want through the access channels you want, and also assume that it properly balances your available system resources to minimize response time and maximize throughput. In practice, we find that it is usually through numerous iterative cycles of deployment and test that the system matures to this level of stability.
A recent, even more agile, trend in development approaches has emerged in the Web 2.0 world. This approach is a concept called “Perpetual Beta,” in which users are providing constant feedback about an application’s functions. Based on this feedback, the application is in a constant state of change.
The Perpetual Beta approach allows the quality of the software to drastically improve very quickly based on real-world input. Enterprise applications, such as Yahoo Mail, are beginning to adopt this model, and as such, are choosing frameworks that help adapt to change quickly.
So a good persistence mechanism will enable changes to be made through configuration options without modifying the application code. A great framework will include tools to accelerate definition of persistent objects as well as development, testing, and deployment of services needing access to it. For example, suppose a DBA determines that a particular query will perform much better if you switch the order of the tables being joined. Being able to quickly change the query associated with a given unit of work and deploy the delta to production is essential in this new super-agile business environment in which we find ourselves.
Although last on the list, portability is certainly not the least important of the IT requirements we’ve explored—especially in the context of all the changes likely to come in both the requirements of an enterprise quality application and the platforms on which they can be hosted. Specific questions concerning portability requirements relate to how easy it is to install, replace, or adapt components of the application.
To put portability into a practical general context, imagine that your company has a division charged with selling basic order entry services to partner product vendors. Of course your company wants to sell these services to as many partners as possible; and to support that goal they want to make as few restrictions as possible on the hardware and software platforms that host the services. By implementing the services in Java that adhere to the Java EE (or even the more lightweight Java SE platform), your company has maximized the potential sales by enabling partners to run the services on IBM WebSphere Application Server, JBoss, or WebLogic, to name just a few of the biggest players.
Can we put the portability of a persistence mechanism in a similar practical context? To answer this question, we like to first separate the portability concerns of (a) the application’s business logic, and (b) its data access logic. The earliest EJB specifications separated these two types of logic into session and entity EJB components, respectively.
The session EJB component specification (at least the stateless one) was very successful and still remains in wide use today. Even the EJB 3 specification leaves the concept relatively unscathed, mainly adding the capability to annotate Java POJOs that capture business logic and reduce the number of artifacts needed to code a Session Bean. One reason for this success is that the programming model for the business logic is basically Java, which has proven to be truly write-once-run-anywhere platforms.
Unfortunately, the entity EJB component specification (even the Container Managed Persistence, or CMP, one) has not been nearly so successful. In fact, entity EJB components have fallen into such disuse that the Java Persistence API (JPA) has totally revamped the approach to persistence within a Java SE or Java EE platform. One reason for this lack of success is that CMP components did not deliver on the promise of portability between Java EE platforms. We believe one root cause is that the specification never defined a standard mapping between the object and data layer. Although entity EJB components are designed with the best of intentions to remain database agnostic, this looseness in the specification required a complex and tedious remapping whenever a different vendor or open-source implementation of the platform was chosen.
So while the EJB marketing literature touted the capability to “easily” persist a CMP component in just about any type of persistent store, from relational database tables to flat files, the practical reality was that almost no one needed this high degree of “portability.” For the most part, almost all entity EJB components in production use today are stored in relational databases. The portability that most need is the capability to move from vendor to vendor across application servers and relational databases.
Another practical reality is that most entity EJB components have no real data access logic in them anyway. In fact, the EJB 2 specification made it even easier to eliminate any semblance of implementation logic by making CMP “implementations” abstract classes that get converted to concrete classes at deployment time. The implication is that the “real” data access logic associated with an entity CMP component was contained in the vendor-specific mapping files—which were not portable. It forced programmers to use a heavyweight component (even when Local interfaces were introduced) that made it much more difficult to unit test CMP components in an automated fashion.
These unfortunate practical realities left an opening for frameworks such as Hibernate and Kodo Solarmetric to gain in popularity. They could run portably inside both Java SE applications and Java EE applications because they, among other things, defined a standard mapping to relational databases with which any platform providers are expected to comply. Further, they could easily generate data access logic to “hibernate” simple POJO classes through the use of deployment-like tools, greatly simplifying the end-to-end development process.
Taking these lessons to heart, we have learned that good frameworks need to consider varying requirements, from running on JSE, to optimizing access paths. Figure 2.17 enumerates some of these concerns plus a number of others related to maintainability and portability.
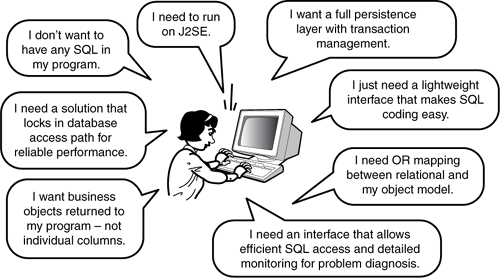
You will likely have to compromise on certain decisions and not necessarily expect a mechanism to meet all of these portability requirements. However, rest assured that portability between Java EE and Java SE is achievable, and so should be expected of any persistence framework that you consider.
We have found that very few applications are implemented totally “from scratch.” Most, if not all, development projects we have seen are centered on making various legacy systems communicate with each other and a few new ones (usually providing the “glue”) over a network. This network of solution components may also include systems that are hosted in completely different data centers, application server platforms, and data store types. So, in essence, how you share data across applications and domains has a large impact on all the IT requirements discussed in this section from functionality to portability. Figure 2.18 shows an example of two separate applications exchanging data using XML as a standard canonical form for interoperability.
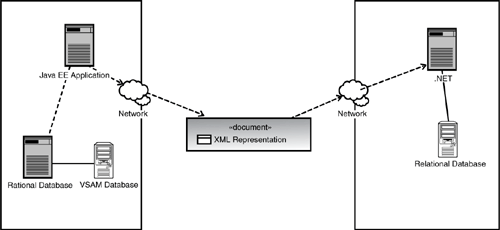
These same kinds of interoperability requirements and solutions designs apply to persistence frameworks. For example, your persistence framework may need a way to transform data into other formats besides Java Objects. You may need to create an XML representation for a third-party consumer to invoke your service. You may also need a way to have your data render into multiple formats like an ATOM feed to be displayed in your Wiki or JSON (JavaScript Object Notation) to be displayed in some Rich Internet Ajax-based application. We have already discussed standards adherence in the section on TCO as one major aspect of interoperability that should be considered when evaluating persistence mechanisms. This discussion therefore brings us full circle.
This circular reference is appropriate given that we like to illustrate the ISO 9126 software quality characteristics (shown earlier in Figure 2.13) as spokes radiating from a circle representing an enterprise solution that integrates each of these aspects. It implies that each factor is an independent domain of requirements that should be considered when developing an enterprise quality application—and a persistence mechanism can be thought of as a very specialized enterprise application whose “business logic” is to provide persistence for other applications.
In this chapter, we discussed how both business drivers and IT requirements are the key to defining the needs of your persistence layer, even though most practitioners consider only the IT requirements. Therefore, we stressed that you should consider total-cost-of-ownership issues such as standards adherence, platforms required and other dependencies, vendors and licenses, and available skills and literature.
We then focused on the IT requirements in the context of measurable software characteristics, such as those defined by the ISO 9126 standard. We showed how the pre-/postconditions of use cases and states capture the details of domain objects likely to need access to persistent data, and how these functional requirements need to be considered along with quality of service requirements such as reliability, usability, efficiency, maintainability, and portability requirements when evaluating a given framework.
We looked into the details of ACID properties of transactional requests, isolation levels and their use in tuning applications for concurrent access control, the high throughput requirements of batch applications, and an approach to using XML as an interoperability layer to integrate applications developed according to different standards and hosted on separate runtime platforms.
In the next chapter, we discuss domain models and object-relational mapping as part of detailed application design, and how these detailed programming model aspects also need to be considered when choosing a persistence framework.
A.2.1 | The Ideal WebSphere Development Environment. |
This article by Keys Botzum and Wayne Beaton serves as a great guide on designing development environments for enterprise applications. | |
www.ibm.com/developerworks/websphere/techjournal/0312_beaton/beaton.html | |
Build a scalable, resilient, high performance database alternative with the ObjectGrid component of WebSphere Extended Deployment. | |
This article by Alan Chambers is a great guide for understanding the basic features of the ObjectGrid. | |
www.ibm.com/developerworks/websphere/techjournal/0711_chambers/0711_chambers.html |