
We start our evaluations with Java Database Connectivity (JDBC), not because it is an ORM framework, but because most of the other technologies we evaluate in Chapters 6 through 9 are or can be implemented on top of JDBC. Therefore, JDBC serves as the baseline for the side-by-side comparison we make in Chapter 10, “Putting Theory into Practice.”
We will start this chapter with a brief architectural overview—a discussion of the programming model and how you use that programming model to solve the basic issues associated with object-relational mapping (ORM). Then we will show how to build the common example services using JDBC in the context of the end-to-end process for developing that example.
The purpose of this section is to help you understand how JDBC relates to other Java persistence frameworks—by positioning it within history, but more importantly, within a taxonomy of types. These two perspectives illustrate why we are evaluating JDBC in the first place.
The JDBC library provides an application programming interface (API) to interact directly with relational databases using Structured Query Language (SQL). JDBC is not an ORM framework; its API requires the programmer to have intimate knowledge of SQL and of the database tables with which they interact to provide persistent data for their enterprise applications. The object-relational impedance mismatch becomes blatantly obvious when using JDBC.
Separation of concerns is a primary consideration when developing enterprise quality service-oriented Java applications. Therefore, most Java applications should not directly access data using JDBC, and should instead use a framework like the ones we evaluate in the next chapters. Unfortunately, developers who use JDBC in their applications will almost always build their own framework around it. The Spring JDBC Templates and Apache iBATIS open-source projects are examples of minimalist frameworks built around JDBC that can save a team from going down this treacherous path of reinvention. We will evaluate iBATIS in Chapter 6 to show the specifics of how it provides an ORM solution.
For the purposes of this book and chapter, we will avoid the temptation to invent a framework around JDBC—not only to show you the intricate details of how to use the JDBC API, but also so that you gain a greater appreciation for what a persistence framework must do. And hopefully, after exploring all the aspects that must be implemented, you will see how difficult it really is to build an enterprise quality framework, and you will tend toward a “reuse” versus a “build” decision.
The release of JDK 1.1 in February 1997 included the JDBC 1.0 API classes. This toolkit set the stage for the development of more complex frameworks and the eventual creation of Java Platform Standard Edition (JSE, or Java SE) and Java Platform Enterprise Edition (JEE, or Java EE). JDBC was originally based on database programming interfaces for other languages. In particular, JDBC was influenced by ODBC (Open Database Connectivity), as well as the X/Open SQL CLI (Call Level Interface) specification.
Since its inception, JDBC has been continually updated to address various enterprise-level concerns, including distributed transactions, connection pooling, and batch updates. Since version 3.0, it has been developed under the Java Community Process (JCP) under various Java Specification Requests (JSR). JDBC 4.0 is the current version at the time this book went to press, developed under JSR 221.
JDBC is designed to be as standalone as possible. This approach enables it to be used to provide access to persistent data in Java applications running under the basic Java SE platform.
In a Java SE application, the ACID properties of an application service are provided by delegation to the database. So in the programming model section, we will see how direct manipulation of transactions is an important part of your application code when using the JDBC API. If your applications need to access and update two or more databases in a single unit of work, we strongly recommend that you write the application to use services provided by the Java EE platform rather than inventing your own distributed transaction mechanism. Java EE includes numerous services you will find yourself needing for robust enterprise applications such as these (each followed by a reference to the specification, listed at the end of the chapter, for more details):
Unfortunately, we have seen too many development teams try to invent one or more of these services, especially their own version of Enterprise JavaBeans, to the detriment of their ability to focus on applications crucial to the success of their business.
Key Point
If you need to update more than one database or need other object services in a unit of work, you should code the service to exploit the standard features of JEE.
And as we will see in later chapters, a good framework for persistence will abstract the differences between Java SE and Java EE platforms from the programming model.
JDBC represents a specification and set of standards that JDBC library vendors must adhere to in order to be considered compliant. There have been four major versions, with each adding more function than the previous one:
JDBC 1.0—. Provided the basic framework for data access using Java via connections, statements, and result sets.
JDBC 2.0—. Added scrollable and updatable result sets, batch updates, SQL3 data types, data sources, and custom mappings.
JDBC 3.0—. Enhanced existing features and added some new functionality, such as savepoints, auto-generated keys, and parameter metadata.
JDBC 4.0—. Provides better code manageability (specifically in the areas of driver and connection management and exception handling) and more complex data type support, such as native XML.
We will focus on JDBC 4.0 in the remainder of this chapter; you can refer to the website for full details of the specification [JDBC].
Regardless of version, when we say JDBC, we really mean an implementation of the JDBC specification that adheres to (or conforms with) a specific version of the standard. This implementation is called a JDBC Driver, and there are four main types to consider, as shown in Table 5.1.
Table 5.1. JDBC Drivers
Type 1: JDBC-ODBC Bridge | Translates JDBC calls into ODBC calls and sends them to the ODBC driver. |
Type 2: A Native API Partly Java Technology-Enabled Driver | Converts JDBC calls into database-specific calls for databases. The driver requires that some binary code be present on the client machine. |
Type 3: Pure Java Driver for Database Middleware | Translates JDBC calls into a vendor-specific protocol, which is translated into the database-specific protocol through components installed on the database server. |
Type 4: Direct-to-Database Pure Java Driver | Converts JDBC calls into the network protocol used directly by DBMSs. The driver allows for a direct call from the client machine to the DBMS server. |
The JDK has the basic API (interface classes) and a JDBC-ODBC Bridge Driver bundled inside it. However, we have found that this default driver should be avoided (unless no alternatives exist), because it involves translating every database request from JDBC to ODBC, and then finally to the native database protocol. Furthermore, use of the JDBC-ODBC bridge typically binds one to a Windows platform.
In general, most applications should use a driver built specifically for the database used to store the enterprise data. In the early days when Java was still maturing, native Type 2 drivers were used to boost performance of database applications. But because they only enabled use from Java and were not implemented in Java, they were not portable across operating systems. Now that Java has matured and runs much faster, most drivers are Type 4 and can take advantage of Java’s write-once-run-anywhere feature.
The JDBC driver being used typically must be added as a JAR to the classpath. When you are dealing with non-Type 4 drivers or managed environments like Java EE, additional software installation or configuration may be required.
Normally, database vendors will provide an optimized Type 4 driver; and it is our experience that the best choice is to use that one. For example, DB2 provides a driver optimized for DB2 databases. That said, there are cases in which one may need to look at a third-party vendor. For example, some database vendors may provide only an outdated driver or none at all.
To make things a bit more complex, many database products have multiple JDBC drivers that application developers can use to interact with their database instances. For example, to interact with MySQL, a popular database among the open-source community, there are free JDBC drivers available as well as commercial options. Some JDBC drivers are optimized for a particular use (for example, reading as opposed to writing to a database).
The major licensing concern you will have when using JDBC revolves around the JDBC driver libraries used. As mentioned before, this is usually not an issue with Type 4 drivers provided by the database vendor. Further, some Java EE vendors provide the appropriate drivers for all the databases that they support as part of their implementation.
For convenience, Sun has collected a list of more than 200 JDBC driver vendors that can be viewed at their Developer Network (SDN) site that you should check [SDN].
If you will be selling your applications to others, you will need to ensure that your customers can get the appropriate drivers for their back-end databases. If you intend to ship drivers that you use with the installation package of your software, you should carefully scrutinize the licensing agreements of the JDBC drivers to ensure that this is allowed.
A web search on the subject of JDBC yields a huge number of whitepapers, tutorials, and other literature available for reading online. Furthermore, there are lots of books available for purchase online and from brick-and-mortar bookstores. Table 5.2 shows a sampling of the available resources regarding JDBC.
Table 5.2. Available JDBC Resources
Source | Description | |
|---|---|---|
JDBC Database Access Tutorial [JDBC 1] | Excellent introduction to JDBC by Sun Microsystems | |
JDBC API Tutorial and Reference, Third Edition[Fisher] | Great book to have for JDBC API reference | |
JDBC Technotes [JDBC 2] | Great collection of links aggregated by Sun regarding the JDBC API | |
A.5.1 Getting Started with JDBC 4 Using Apache Derby [A.5.1] | A developerWorks tutorial on JDBC 4.0 features | |
A.5.2 Understand the DB2 UDB JDBC Universal Driver [A.5.2] | www.ibm.com/developerworks/db2/library/techarticle/dm-0512kokkat/ | Good discussion on the difference between Type 2 and Type 4 drivers |
In a nutshell, programming with JDBC involves registering a driver by loading a database driver class through a DriverManager class or getting an instance of a DataSource. An application then proceeds by obtaining an instance of a Connection from the DriverManager or DataSource. Using this Connection, the application can obtain Statements for performing actual work with the underlying database. This work includes CRUD (create, read, update, and delete) operations. Many Statement methods, especially queries, return a ResultSet object that provides access to the individual rows and columns associated with the result. Figure 5.1 shows the classes we will use while describing the programming model.
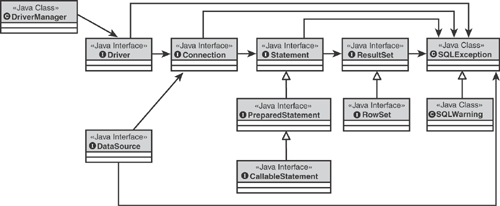
Throughout this section, we will show snippets of code based on the example we introduced in Chapter 3, “Designing Persistent Object Services,” to illustrate the basic programming model steps.
Historically, the earliest mechanism for getting a Connection was to use the classloader to bootstrap an instance of a DriverManager. You can simply load the DriverManager class into the runtime environment using a single line of code invoking the Java class loader as shown in Listing 5.1.
The DriverManager class referenced in the statement must be in your classpath, or a runtime exception will occur.
A connection can then be obtained using the DriverManager class. The DriverManager class contains static methods for getting connections. One of these static getConnection methods is used in the example of preparation work to obtain a connection shown in Listing 5.2.
The method takes the form getConnection(String url, String user, String password). As seen in the URL used in Listing 5.2, the URL takes on the form of jdbc:subprotocol:subname:port. In the case of interacting with Apache Derby, specifying a subprotocol of derby in the URL tells the driver manager which driver to use. The subname of //localhost:1527/PWTE tells the driver where to look for the database instance we want to use. It is assumed that the database instance is running locally. Depending on whether authentication is required with your database instance (which will be the case for any real production deployment), database username and password information might need to be provided to obtain a connection.
In the early days of Java Applications, using a DriverManager was quite common. However, there are several limitations to this approach. The most glaring one is that you make one connection to a database at a time. Obviously this does not scale within an enterprise application. These applications typically need a mechanism to manage a pool of connections. The JDBC specification came up with an interface called a DataSource that abstracts how you get a database connection. When using a DataSource, the DataSource object takes on the responsibility of connecting an application and the JDBC driver. In Listing 5.3, this role is assumed by a DataSource.
Example 5.3. Obtaining a Connection Using a DataSource and JNDI
//DataSource in a Java EE Environment
InitialContext ic = new InitialContext()
DataSource ds = ic.lookup("java:comp/env/jdbc/Derby/DataSource");
Connection con = ds.getConnection();
//DataSource in a Java SE Environment
DataSource ds = (DataSource) org.apache.derby.jdbc.ClientDataSource();
ds.setHost("localhost");
ds.setUser("myUserName")
ds.setPassword("myPassword");
Connection con = ds.getConnection();In Listing 5.3, we show how a DataSource is used in a Java EE and Java SE environment. In a Java EE environment, the JNDI interface abstracts the DataSource type. Typically, in an Application Server, one would configure a DataSource administratively. Consequently, the need to worry about the connection URL, host, port, username, password, and other database configuration is eliminated from the application. DataSources can be used outside a Java EE environment, as also shown in Listing 5.3. Today, most JDBC drivers provide some implementation of the DataSource interface. Additionally, there are open-source implementations of the DataSource interface offered by the Apache Commons Project (DBCP component), as well as c3p0 (a SourceForge.net project). DataSource objects can provide for such enterprise-level facilities as connection pooling, the capability to participate in distributed transactions, and prepared statement caching. Using the DataSource approach as opposed to the DriverManager approach in Java SE applications makes it easier to use the same code in a Java EE and Java SE environment.
As shown in Listings 5.2 and 5.3, the onus of obtaining a connection is left up to the Java application programmer, thus constituting an explicit connection model. To minimize the overhead of creating, maintaining, and releasing database connections, connection pooling should be used, effectively avoiding the overhead of creating and destroying database connections. Fortunately, as of JDBC version 2.0, using connection pooling does not require much effort on the application developer’s part. The process involves using two objects: ConnectionPoolDataSource and PooledConnection, both of the java.sql package. As can be seen in the code snippet in Listing 5.4, a ConnectionPoolDataSource is looked up. From the object, a PooledConnection object is obtained using the getPooledConnection method. In turn, to obtain a connection from the pool, the getConnection method of the PooledConnection object is called. After work is performed using the pooled connection, the connection is returned into the pool by calling the Connection object’s close() method. It is important to note that not all vendors require the explicit use of the ConnectionPoolDataSource object to reap the benefits of pooling. Some application servers abstract a programmer from having to explicitly use the PooledConnection and ConnectionPoolDataSource objects. Listing 5.4 shows an example of code using the PooledConnection and ConnectionPoolDataSource.
Example 5.4. Obtaining a Pooled Database Connection
InitialContext ic = new InitialContext()
ConnectionPoolDataSource ds = ic.lookup(
"java:comp/env/jdbc/Derby/PooledDataSource"
);
PooledConnection pooledConnection = ds.getPooledConnection();
Connection conn = pooledConnection.getConnection(
); // get the connection from the pool
// work with the pooled connection
conn.close(); // release the connection back to the poolSetting the database connection pool size is usually an administrative function and varies according to what type of setup is being used. Some vendors may provide an administrative user interface or a scripting interface to configuring connection pools.
After obtaining a connection, the next step is to create a Statement object. There are three types of JDBC Statements:
Statement—. The simplest type of SQL operation, where you can pass any SQL String to execute SQL.
PreparedStatement—. A subset of the Statement object; unlike a plain Statement object, it is given an SQL statement when it is created. The advantage to this is that in most cases, this SQL statement is sent to the DBMS right away, where it is compiled. As a result, the PreparedStatement object contains not just an SQL statement but an SQL statement that has been precompiled. This means that when the PreparedStatement is executed, the DBMS can just run the PreparedStatement SQL statement without having to compile it first. Although PreparedStatement objects can be used for SQL statements with no parameters, you probably use them most often for SQL statements that take parameters. The advantage of using SQL statements that take parameters is that you can use the same statement and supply it with different values each time you execute it. Examples of this are included in the following sections.
Callable Statements—. A specialized subclass of PreparedStatement used to call stored procedures.
Transactions are handled differently depending on whether your code is inside or outside of a Java EE container. When the code is working outside of a Java EE container, transaction control is provided in JDBC via the Connection class of a JDBC driver. Users can demarcate their own transactions, or alternatively opt for the Connection to be in “auto commit” mode. By default, when you obtain a Connection (whether it be from a DriverManager, a DataSource, or a ConnectionPool), the Connection has auto commit enabled. This essentially means that each SQL statement will be treated as a single transaction. When each statement is executed by the database, it will be committed. Sometimes, database transactions consist of multiple statements that must be regarded as a single, atomic transaction. Therefore, after obtaining a Connection, auto commit mode should be turned off, giving control of the transaction to the developer, who can explicitly commit or roll back the transaction. To turn auto commit off, you can call the setAutoCommit method of the Connection class with an argument of false, as demonstrated in Listing 5.5. Grouping statements into a single, user-defined transaction is relatively straightforward. After calling the setAutoCommit method with a false argument, the programmer is not required to explicitly demarcate the beginning of a transaction (in fact, there is no way to do so). But it is up to the developer to end a transaction by issuing either the commit or rollback methods on the Connection object.
Example 5.5. Explicitly Managing a Transaction by Setting Auto Commit to “false”
try
{
Connection connection = DriverManager.getConnection(
url, username, password
);
connection.setAutoCommit(false);
//operations...
conn.commit();
}
catch (SQLException e)
{
conn.rollback();
}Attention should be made to the process involved in closing the resources (PreparedStatement and Connection objects). Improper cleanup of JDBC resources is often a root of problems in applications leveraging JDBC. This is why so many people use frameworks such as iBATIS or Spring JDBC Templates, which can provide automatic cleanup of these resources.
JDBC is also extensively used in Java EE environments in conjunction with the Java Transaction API. In such settings, where, for example, different EJBs might be involved in a distributed transaction that spans multiple datasources, the responsibility of determining how to commit and/or roll back changes is given to a transaction manager. Classes involved in a distributed transaction are strictly prohibited from calling the setAutoCommit, commit, and rollback methods when using container managed transactions, wherein the EJB container sets the boundaries of transactions. This disparity in transaction management in Java SE and Java EE environments often makes it difficult to use the same code between environments.
In Chapter 2, “High-Level Requirements and Persistence,” we discussed isolation levels. Databases handle isolation levels in different ways. Which isolation levels are supported by JDBC is all dependent on the JDBC driver and the underlying database. One might dig through the JDBC driver documentation to see which isolation levels are supported. Alternatively, the DatabaseMetaData interface can be leveraged to report the transaction support of the database and JDBC driver being used. After a Connection object is obtained, the getMetaData method of the object can be called to yield a DatabaseMetaData object. It is from this object that general support for transactions and specific support for the various isolation levels can be ascertained. Table 5.3 shows the methods of the DatabaseMetaData object that can be used to determine isolation level support.
Table 5.3. Checking for Isolation Levels
DatabaseMetaData Method | Usage |
|---|---|
| Reports whether transactions are supported by the database and/or the JDBC driver |
| Reports whether the database and/or the JDBC driver supports a particular isolation level |
The different isolation levels are delineated as static constant integers of the Connection interface and are listed in Table 5.4.
Since JDBC 3.0, an application developer can mark one or more places in an atomic transaction and perform a partial rollback of the transaction if deemed appropriate. This partial rollback facility is realized with JDBC savepoints. JDBC 3.0 and higher compliant drivers implement the java.sql.Savepoint interface, which facilitates savepoints. To use savepoints, the application developer uses the methods (shown in Table 5.5) of the Connection object.
Table 5.5. Savepoint Related Methods of the Connection Object
Connection Method | Usage |
|---|---|
| Creates a savepoint with a provided name and returns a Savepoint object that will represent it |
| Creates an unnamed savepoint and returns the Savepoint object that will represent it |
| Rolls back all the changes made to a database to the point where the specified savepoint was demarcated |
| Removes the specified savepoint from the current transaction (effectively invalidating the savepoint) |
After having a Connection properly initialized, you can create, retrieve, update, and destroy data in the associated tables.
Creating data involves issuing an SQL Insert statement. For purposes of an example, assume you have a simple Java object populated by a web application as shown in Listing 5.6.
To persist this object, one approach is to manually transfer its contents into the parameters of a PreparedStatement obtained from the Connection. Listing 5.7 shows how each “?” in the SQL is associated with an ordinal number that can be used with a “set” method on the PreparedStatement.
Example 5.7. SQL Insert
String insertCustomerSQL =
"insert into CUSTOMER (NAME, RESIDENTIAL_HOUSEHOLD_SIZE," +
"RESIDENTIAL_FREQUENT_CUSTOMER, CUSTOMER_ID, TYPE ) values " +
"( ?, ?, ?, ?, ? )";
PreparedStatement insertCustomerPS = conn.prepareStatement(
insertCustomerSQL
);
insertCustomerPS.setString(1, customer.getName());
insertCustomerPS.setInt(2, customer.getHouseholdSize());
if (customer.isFrequentCustomer())
insertCustomerPS.setString(3, "Y");
else
insertCustomerPS.setString(3, "N");
insertCustomerPS.setInt(4, customer.getCustomerId());
insertCustomerPS.setString(5,"RESIDENTIAL");
insertCustomerPS.executeUpdate();
conn.commit();Listing 5.7 also shows how ORM logic is embedded in the code, “mapping” the Java Boolean value to a “Y” or “N” accordingly.
To read data, you can use a PreparedStatement object to issue an SQL Select. The results of an SQL Select are stored in a specialized object called a ResultSet, which will hold a table representation of your results. The ResultSet interface provides methods for retrieving and manipulating the results of executed queries; ResultSet objects can have different functionality and characteristics. These characteristics include type, concurrency, and cursor holdability.
The type of a ResultSet object determines the level of its functionality in two areas: a) the ways in which its cursor can be manipulated, and b) how concurrent changes made to the underlying data source are reflected by the ResultSet object.
These behaviors are determined by the ResultSet type, of which there are three to consider:
TYPE_FORWARD_ONLY—. The ResultSet is not scrollable; its cursor moves forward only, from before the first row to after the last row. The rows contained in the ResultSet depend on how the underlying database materializes the results. That is, it contains the rows that satisfy the query either at the time the query is executed or as the rows are retrieved.TYPE_SCROLL_INSENSITIVE—. The ResultSet is scrollable; its cursor can move both forward and backward relative to the current position, and it can move to an absolute position. However, the ResultSet does not reflect any changes made during the transaction.TYPE_SCROLL_SENSITIVE—. As is the case forTYPE_SCROLL_INSENSITIVE, the ResultSet is scrollable; its cursor can move both forward and backward relative to the current position, and it can move to an absolute position. However, the ResultSet reflects changes made during the transaction.
Most SOA applications use TYPE_FORWARD_ONLY, because services are stateless. Listing 5.8 illustrates a simple query.
Example 5.8. A Simple SQL Select Invoked Through a PreparedStatement
// 2. Retrieve Customer
PreparedStatement customerPS = conn.prepareStatement(
"SELECT * FROM CUSTOMER"
);
customerPS.setInt(1, customerId);
customerResultSet = customerPS.executeQuery();
while(customerResultSet.next())
{
Customer c = new Customer();
customer.setName(customerResultSet.getString("name");
customer.setAge(customerResultSet.getInt("Age");
...
customerList.add(customer);
}ResultSet objects require that a session has to be maintained while data is manipulated programmatically; furthermore, a ResultSet is tied to the Statement and Connection that created it. Seeing a need for ResultSet objects to be decoupled from these constraints, the javax.sql.RowSet interface was introduced to the Java language in J2SE Version 1.4 as part of JSR 114.
One implementation of the RowSet interface is the CachedRowSet, which shipped as part of the Java 5 SDK. The CachedRowSet object lets you connect to a database, grab data in the form of a ResultSet, release the Connection, manipulate the data locally, and then, when appropriate, reconnect with the database and persist the changes made to the data.
The default implementation of the CachedRowSet object that ships with Sun’s SDK assumes optimistic locking. If the data that a client is trying to manipulate was not changed by another application interacting with the database server, the updates will be accepted by the database. If, however, something has changed with the target data in the interim, a synchronization exception will be thrown.
The RowSet specification does not mandate a particular concurrency model. However, the CachedRowSet implementation that ships with the SDK adopts an optimistic concurrency model. Listing 5.9 shows an example of using a CachedRowSet. Notice that it is similar looking to a ResultSet, except it can be disconnected.
Example 5.9. Using a CachedRowSet with a Dynamic Statement
Connection dbconnection = dataSource.getConnection(); // use a statement to gather data from the database Statement st = dbconnection.createStatement(); String myQuery = "SELECT * FROM CUSTOMER"; CachedRowSet crs = new CachedRowSetImpl(); // execute the query ResultSet resultSet = st.executeQuery(myQuery); crs.populate(resultSet); resultSet.close(); st.close(); dbconnection.close();
After a CachedRowSet object has been created, the connection to the database can be severed as was done in the code snippet in Listing 5.9.
Updating a database table requires that an SQL Update statement be issued against the database. Much like the SQL Insert, you can issue an SQL Update using a PreparedStatement as shown in Listing 5.10.
Example 5.10. Updating Data
// 4. Persist the new quantity and amount
updateLineItemPS = conn.prepareStatement(
"UPDATE LINE_ITEM SET QUANTITY = ?,
AMOUNT = ? WHERE ORDER_ID = ? AND PRODUCT_ID = ?");
updateLineItemPS.setInt(1, quantity);
updateLineItemPS.setBigDecimal(2, updateAmount);
updateLineItemPS.setInt(3, orderID);
updateLineItemPS.setInt(4, productID);
updateLineItemPS.executeUpdate();Alternatively, when using CachedRowSet, you follow a different pattern to update data. After you have the RowSet loaded, you use its update methods, and then synchronize the changes using the acceptChanges method as shown in Listing 5.11. This pattern allows for a client-side application to update a number of rows at once, eliminating the need to “hydrate” and manipulate domain-specific Java objects. Listing 5.11 shows the relevant code to populate a CachedRowSet with a query; then how you can manipulate the CachedRowser; and finally, synchronize it back to the DB.
Example 5.11. Synchronize Changes to the Database
CachedRowSet crs = new CachedRowSet();
String myQuery = "SELECT * FROM ORDER where ORDER_ID = 3";
CachedRowSetImpl();
// execute the query
ResultSet resultSet = st.executeQuery(myQuery);
crs.populate(resultSet);
...
//other logic
if(crs.next())
{
//update row
crs.setFloat("total",crs.getFloat()+newQuantity);
}
//Synchronize changes
crs.acceptChanges();Much like an Update or Insert, deleting involves using a Statement object to issue an SQL Delete, as illustrated in Listing 5.12.
Example 5.12. Invoking an SQL Delete Using a PreparedStatement
// Remove line item
productDeletePS =
conn.prepareStatement(
"DELETE FROM LINE_ITEM WHERE PRODUCT_ID = ? AND ORDER_ID = ?"
);
productDeletePS.setInt(1, productId);
productDeletePS.setInt(2, orderId);
productDeletePS.executeUpdate();
productDeletePS.close();
conn.commit();JDBC allows for the invocation of stored procedures on a database server. Calling stored procedures is made possible by the CallableStatement object described earlier. Listing 5.13 shows a call to a hypothetical swap_customer_order stored procedure.
The use of curly braces (“{...}”) in the code in Listing 5.13 is an escape syntax that tells the database driver being used to translate the escape syntax into the appropriate native SQL to invoke the stored procedure named swap_customer_order. Setting the parameters for invoking the stored procedure is similar to how the parameters of a PreparedStatement object are populated (that is, via setter methods).
JDBC allows for batching SQL statements into a Batch Statement to be shipped to the database as one network call. Listing 5.14 shows an example of updating a list of orders in a single batch statement, assuming the IDs to be changed and associated status to change is in an array.
Example 5.14. Calling Batch Statements
try {
...
connection con.setAutoCommit(false);
PreparedStatement prepStmt = con.prepareStatement(
"UPDATE ORDERS SET STATUS=? WHERE ORDER_ID=?"
);
for(int I = 0; I < orderIds.length;i++){
prepStmt.setString(1,orderStatus[i]);
prepStmt.setString(2,orderIds[i]);
prepStmt.addBatch();
}
int [] numUpdates = prepStmt.executeBatch();
for (int i=0; i < numUpdates.length; i++) {
if (numUpdates[i] == -2)
System.out.println("Execution " + i +
": unknown number of rows updated"
);
else
System.out.println("Execution " + i +
"successful: " numUpdates[i] + " rows updated"
);
}
con.commit();
}
catch(BatchUpdateException b) {
// process BatchUpdateException
}As mentioned earlier, JDBC is the foundational technology of most of the ORM frameworks studied in this book. JDBC is at the heart of most proprietary ORM frameworks as well. The JDBC API has a number of interfaces that can be implemented by vendors or even enterprise application developers when they would like to augment the functionality of the JDBC libraries. The Java Community Process openly publishes the JDBC specification, which vendors can use to build their own, specification-compliant implementations of the JDBC libraries.
Exceptions generated by the Java runtime and DBMS should be printed (or better yet logged) in an associated catch block. Executing the getMessage method of the SQLException object can often yield revealing information about what is going awry. However, sometimes you needs more information to diagnose and troubleshoot what may be going wrong. The SQLException object provides three methods: namely, getMessage, getSQLState, and getErrorCode. Vendor error codes are specific to each JDBC driver. Consequently, to determine what the meaning of a particular error code is, you need to reference the driver documentation. Sometimes vendors return multiple exceptions that a developer will iterate through. Listing 5.15 shows an example of a catch block dealing with an SQLException.
Sometimes when accessing a database via JDBC, SQLWarning objects (a subclass of SQLException) can be generated. Such database access warnings do not halt the execution of an application as would exceptions. This lack of halting execution can sometimes be dangerous, because application developers might not account for such warnings. An example of a warning that might arise is a DataTruncation warning, which indicates that there was a problem when reading or writing data that involved the truncation of data. JDBC warnings can be reported by Connection objects, Statement objects, and/or ResultSet objects by use of the getWarnings method. As with the SQLException, the getMessage, getSQLState, and getErrorCode methods can be used to gather more information about the SQLWarning.
The preceding section shows that JDBC is nothing more (or less) than an API for invoking SQL and processing the results. Using the API itself is relatively simple. The complexity emerges when we try to bridge the gap from this purely relational view of data to concepts that programmers using object-oriented languages like Java have come to expect—objects, attributes, relationships, inheritance, and so on. This complexity is due to the ORM impedance mismatch problem described in Chapter 3.
Although JDBC should not by any stretch of the imagination be considered an ORM framework, Table 5.6 shows that it is relatively straightforward to “simulate” concepts from the object domain using those from the relational world.
Table 5.6. Object Domain to Relational Domain
Object Domain | Relational Domain |
|---|---|
Object | Row in a table |
Inheritance | Root-leaf tables or union/discriminator |
Object Identity | Primary key, query |
Attribute | Column of various types |
Contained Object | Mapped columns, LOBs |
Relationship | Foreign key, join |
Constraint | Limited, such as |
Derived Attribute | Limited built-in functions, like |
We will look at each of these “mappings” in turn and how the JDBC programming model concepts can then be employed to bridge the gap.
Table 5.6 shows how a row in a table can be considered as a representation of an “existing” object instance. That said, the mapping is not always one-to-one depending on the approach to normalization used in the database as described in Chapter 3.
Sometimes the data needed to populate a given Java object is spread across more than one table. Hopefully, each table stores data needed by particular applications’ functions that are not needed by others. When these logical units of data are separated into their own table like this, the amount of contention on a particular row is reduced. The downside is that when data from two or more tables is needed in a single unit of work, either (a) a relatively expensive join operation must be done, or (b) a separate query must be issued.
But regardless of whether one or more tables are joined, or one or more statements are executed, your job is to transfer data from these objects into the attributes of the associated domain-specific POJO classes. Listing 5.16 shows a code snippet to illustrate.
Example 5.16. Manual Mapping of Product Object from a ResultSet
int productId = 1234;
PreparedStatement productPS = null;
productPS = conn.prepareStatement(
"SELECT * FROM PRODUCT WHERE PRODUCT_ID = ?"
);
productPS.setInt(1, productId);
ResultSet productResultSet = productPS.executeQuery();
Product product = new Product();
product.setDescription(productResultSet.getString("DESCRIPTION"));
product.setPrice(productResultSet.getBigDecimal("PRICE"));
product.setProductId(productResultSet.getInt("PRODUCT_ID"));When creating a new instance of a persistent object, the ORM mapping problem is reversed—you will use the properties of the newly instantiated Java object to populate the Insert statement values as shown earlier in the “Programming Model” section of this chapter. The main difference here is that if the attributes from the object are maintained in more than one table, an Insert will need to be executed for each table. Remember that to maintain transactional integrity, multiple updates will require autocommit to be turned off, or that you employ batching, as described in the Programming Model section.
Table 5.6 shows how it is possible to simulate inheritance in various ways, and builds off of the discussion of ORM design issues described in Chapter 3.
For example, one popular approach is called root-leaf inheritance, which employs a relationship very much like that of inheritance in a UML diagram. When the root-leaf approach is used, the common attributes “inherited” by all subtypes (including the key fields) are maintained in a root table, which also includes a column describing the actual type of the row. This type is mapped to a leaf table, which in turn maintains the additional persistent attributes of the subtype. The leaf table includes the key field(s) to enable relating the two tables.
Another approach to simulate inheritance is to employ a “union” in which there is only one table with a discriminator describing how to redefine the remaining columns of the table. BLOBs (binary large objects) are sometimes used for the variant data, which are deserialized (when reading) and serialized (when writing) by a Java application based on the type.
The benefit of union over root-leaf style inheritance is that union style does not require a join or multiple updates, as is required in root-leaf style.
That said, root-leaf style inheritance minimizes unused columns in the database, which can occur in union style inheritance when certain subclasses have more attributes to store than others. And whereas BLOBs are used in union style inheritance to minimize the number of table accesses, a root-leaf style is preferred because it does not require serialization or deserialization of the attributes. Additionally, accessing a single table for all attributes as in done in union style inheritance involves a lesser level of normalization than when root-leaf inheritance is used, and can actually cause contention as a negative side effect. Furthermore, when using root-leaf inheritance, most services that operate on “superclasses” do not need to access “leaf” tables; conversely, many behaviors that are unique to the subclass do not need to access the superclass data. Consequently, costly joins can sometimes be avoided in root-leaf inheritance. Finally, it is easier to add additional levels to the inheritance hierarchy when using a root-leaf style—by simply adding new tables with the additional data—whereas modifying the hierarchy with union style inheritance requires modifying existing table definitions.
For these reasons, we tend to prefer root-leaf style inheritance as the mapping strategy.
There is still some controversy in the object domain concerning the subject of identity. Should each instance have some kind of a generated ID? Or should the key simply be a set of attributes that when taken together uniquely identify an object? This discussion is interesting because it has some interesting ramifications on ORM, especially when coming “from the bottom.”
SQL/JDBC queries can refer to any columns (or derived attributes), and return zero or more rows as a result. Indexes on various columns can be declared, which make these queries more efficient. However, it is also possible to declare in the DDL that for a given table, a column or set of columns uniquely identify the row (that is, you can declare key constraints). Doing so serves as a “hint” to the database runtime so that it can, for example, provide a special index to make access to the matching row very efficient.
Unfortunately, when inserting a record into a database table, JDBC does not automatically generate a key field in the database that uniquely identifies that row. Generated keys are a commonly used approach that simplifies building relationships between objects. For example, we require such functionality when we place an order in the ORDER table of the common example described in Chapter 3. To address the requirement for a generated order key, the DDL of the ORDER table was changed to institute auto key generation (see Listing 5.17).
With this modification, every time a row is inserted into the ORDER table, a unique ORDER_ID (the key) is generated with an auto-increment. However, it is important to note that not all databases support this type of auto key generation.
Whereas, as mentioned earlier in Table 5.6, a single row of a ResultSet (that was produced by issuing a SELECT query spanning one or more tables/views) can be thought to represent a domain object, the attributes of these domain objects are persisted as “columns” in tables. The attributes are declared as part of the DDL describing a table. Normally, table columns are retrieved into a ResultSet using the SELECT clause of the SQL statement. They also appear in the WHERE clause (for queries) and ORDER BY clause (for sorting). Similarly, these columns are used in UPDATE and DELETE statements.
Table 5.7 shows the mapping between types of the Java programming language and the corresponding SQL types.
Table 5.7. JDBC Type Mapping
Java Type | JDBC Type |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Certain complex attribute types can be persisted directly as columns by JDBC/SQL. As illustrated in Table 5.7, Dates and Timestamps get converted automatically into and out of Java types by the JDBC Driver implementation.
Other complex types are only supported indirectly through arbitrarily long VARCHAR, BLOB (Binary Large Object) and CLOB (Character Large Object) column types. These column values must be parsed by the Java application—sometimes through the use of common utility functions (like Java serialization). Say, for example, you would like to persist a domain object into the database “as is.” You can do so by leveraging the BLOB type, serializing the domain object when you want to persist it, and deserializing the object when the time comes to gather the domain object. The danger of persisting complex types this way is that an SQL database cannot query within a BLOB.
The most popular approach to handling “contained” objects is to store them as separate fields in the same table, with some naming convention that makes it clear that they are subfields of the same contained object. And, of course, if the back-end database is properly normalized, the “contained” object is maintained in its own table, with the key from the “containing” object being used to identify the contained one. This approach can work well with “contained” objects that are contained in multiple objects, and possibly even many times within the same object—such as when both a billing address and a shipping address are associated with a customer. In this case, a discriminator field is sometimes used in the normalized table to indicate the “role” that the contained object plays—similar to using a field with root-leaf inheritance to indicate the subtype in the common superclass table. This role descriptor can identify the table/class of the containing object as well so that uniqueness of the role across the application domain is guaranteed.
Objects can have bidirectional relationships, which can only be simulated in the relational domain as foreign keys. A one-to-many relationship is normally simulated with a foreign key from the “many” side back to the “one” side. For example, where an Order might have many line items, the foreign key back to Order is stored in the LineItem. No update is required to the Order side when a LineItem is created, because there is no column that contains the keys for all the items.
Where a relationship is one-to-one, then, relating the two tables requires updates on both sides, unless the relationship is unidirectional. Updating two tables in the same unit of work will require explicit transactional control or batch updates. We will discuss “preloading” related objects in the upcoming section, “Tuning Options.”
In the database realm, adding primary and foreign keys to tables is considered an application of a constraint. But these are not the same constraints as those we have in the object domain—which are more related to the cardinality of relationships, ordering, and so on.
In relational database design, a primary key (often referred to as a unique key) is a candidate key that uniquely identifies each row in a table. The primary key comprises a single column or set of columns (that is, a composite primary key). On the other hand, a foreign key is a referential constraint between two database tables. The foreign key identifies a column or a set of columns in one (referencing) table that in turn refers to a column or set of columns in another (referenced) table.
Beyond the constraints of primary and foreign keys, SQL/JDBC also enables a limited set of constraints on columns. These constraints are declared in the DDL. Examples of such constraints include (but are not limited to) the following: indicating that a given column cannot be NULL, indicating that a given column’s value must be within a certain range of values, and indicating that a given column should be of a certain type (for example, a DECIMAL type with a precision of four digits and a scale of two digits). The constraints are checked prior to insert, update, or delete operations.
In the SELECT and WHERE clause of an SQL/JDBC query, certain operators like +, -, *, and / are allowed to return “derived” (or computed) results. Further, certain functions on rows and columns can be executed, like COUNT, SUM, and MAX. For example, the COUNT function returns an integer that is the number of rows returned by an associated SELECT clause. The SUM function returns the sum of the indicated numeric column. The MAX function returns the highest value of a selected column, while MIN returns the lowest. There are others that vary per database flavor, but the point is that “out of the box” the set is relatively limited. For all intents and purposes, these functions can be treated like virtual columns of the table.
It is important to note that many databases, such as IBM DB2 Universal Database, allow for database developers to supplement the built-in functions supplied by the database with their own functions to, in effect, customize their shop requirements. Case in point, DB2 allows for user-defined functions (UDFs) to be written in Assembler, C, COBOL, PL/I, and Java. For example, let us say that you need for a function to calculate a logarithm of a given number to a given base. You could do so by creating a Java UDF. These UDFs run on the database server. DB2, for example, has its own JVM that could power the hypothetical logarithmic function just mentioned.
And where the database does not have the exact functions desired, stored procedures are sometimes used to allow the database to handle the computation. This is an interesting trade-off to consider and should take into account the amount of data that would have to be passed back to the Java application to compute the data versus the amount of CPU used on the database server.
The kinds of trade-offs discussed in the previous sections with respect to mapping Java objects to relational tables are exactly what makes programming in JDBC interesting for the developer. The persistence layer of an application is typically the layer that can easily become a performance bottleneck. Consequently, it is paramount that the persistence layer be scrutinized to improve performance where possible. In this section we will examine various tuning options, such as query optimization, caching, loading related objects, and locking.
Optimizations can be achieved in different areas. SQL statements themselves can be optimized by doing things like reordering the WHERE clause. Some optimizations can be achieved in the database, for example, by creating indexes on criteria that is often queried on. JDBC has various knobs and whistles you can use to improve query performance, such as lowering isolation levels on certain use cases, using Prepared Statements, and using various cursors. The JDBC API can also control the amount of data fetched from the database. The JDBC fetch size gives the JDBC driver a hint as to the number of rows that should be fetched from the database when more rows are needed. For large queries that return a large number of objects, you can configure the row fetch size used in the query to improve performance by reducing the number of database hits required to satisfy the selection criteria. Most JDBC drivers default to a fetch size of 10, so if you are reading 1,000 objects, increasing the fetch size to 256 can significantly reduce the time required to fetch a query’s results. The optimal fetch size is not always obvious. You can control the fetch size programmatically by setting properties on the ResultSet.
To minimize access to the database, caching facilities might be leveraged. After the due diligence of transferring data from a ResultSet into a domain object has been performed by an application developer, the domain object can be cached using a caching layer of choice. Domain objects must be cached using the prescribed approach of the caching facility of choice.
Two forms of loading the data are needed to populate a graph of related objects and normalized attributes: “lazy” and “aggressive.” Lazy loading generally waits until the objects or properties are accessed to fetch the data with the appropriate query as needed. Of course, this trade-off works well in cases where most of the properties or related objects are never accessed. It does not work so well otherwise, as multiple requests to the database server are made.
Aggressive loading typically is done by issuing SQL joins across various tables to minimize the number of trips to the database server. These joins can be quite complex. Listing 5.18 shows the implementation of a four-way join that demonstrates aggressively loading the data necessary to completely populate an open order associated with a customer. It shows “outer joins” that will load conditionally, so the query will return the data necessary to populate a customer with no open order, a customer with an open order and no line items, or a customer with an open order that contains LineItems. Without a left outer join, you cannot do such a conditional loading. The LineItem, however, has a regular join with the Product because a LineItem will always load with its Product.
Example 5.18. A Complex Four-Way Join to Get Customer and Order Data
customerPS = conn.prepareStatement(
"SELECT c.CUSTOMER_ID,
c.OPEN_ORDER, c.NAME, c.BUSINESS_VOLUME_DISCOUNT,
c.BUSINESS_PARTNER, c.BUSINESS_DESCRIPTION,
c.RESIDENTIAL_HOUSEHOLD_SIZE,
c.RESIDENTIAL_FREQUENT_CUSTOMER, c.TYPE,
o.ORDER_ID, o.STATUS, o.TOTAL,
l.PRODUCT_ID, l.ORDER_ID, l.QUANTITY, l.AMOUNT,
p.PRODUCT_ID, p.PRICE,p.DESCRIPTION
FROM CUSTOMER c
LEFT OUTER JOIN ORDERS o ON c.OPEN_ORDER = o.ORDER_ID
LEFT OUTER JOIN (
LINE_ITEM l
JOIN PRODUCT p ON l.PRODUCT_ID = p.PRODUCT_ID
) ON o.ORDER_ID = l.ORDER_ID
WHERE c.CUSTOMER_ID = ?"
);The complexity of this SQL query should speak for itself. However, sometimes this level of control is necessary to meet the response time and throughput requirements of a system.
In the transaction section, we discussed isolation levels supported by JDBC. The proper locking is achieved by setting the desired isolation on a Connection object. Listing 5.19 shows an example.
A word of caution: Setting the isolation levels can affect performance and data integrity, as we discussed in Chapter 2. Often, these settings can be done at the database or configured on a connection pool from within a Java EE Application Server.
One example of the benefits of development with JDBC is that there is not much you need to do before rolling up your sleeves and coding. All that is really necessary is to have the JDBC driver in your classpath. The rest of the dependencies are fulfilled by the Java Development Kit (JDK), which includes the JDBC APIs. We will be showing relevant portions of our common example. You can download the code and read the instructions in Appendix A to run it. In this section, we will show how we implemented our example introduced in Chapter 3.
As mentioned earlier, the definition of objects in JDBC is left up to the application developer and must be done programmatically. When using the JDBC approach, you will often apply the Transaction Script Pattern, which avoids mapping to domain objects for the most part and uses simple POJO objects specialized for each request to pass data in and out.
This pattern is often simpler than the Domain Model pattern because the more complex the domain model, the more tedious the code is needed to map object data into and out of Statement parameters and ResultSets.
For purposes of comparison with the other persistence mechanisms, we will use the Domain Model pattern. Listings 5-20 through 5-25 show only the internal property definitions from the Java objects. These properties are all that are necessary for you to understand the code in the next sections, assuming that each property has an associated getter and setter method. The full Java object definitions can be found in the downloadable code on the companion website.
Listing 5.20 shows the essential properties of the AbstractCustomer superclass.
Listing 5.21 shows the properties defined in the ResidentialCustomer subclass.
In addition to the ResidentialCustomer class, we have a BusinessCustomer class that extends the AbstractCustomer class. Listing 5.22 shows the properties associated with the BusinessCustomer class.
Listing 5.23 shows the essential properties of the Order class. Notice its association with a Set of LineItem objects as well as with an AbstractCustomer, indicating the customer to which the order belongs.
Example 5.23. The Order Class
public class Order implements Serializable
{
protected int orderId;
protected BigDecimal total;
public static enum Status
{
OPEN, SUBMITTED, CLOSED
}
protected Status status;
protected AbstractCustomer customer;
protected Set<LineItem> lineitems;
//getters and settersLine items of an order are realized via the LineItem object, the properties of which are shown in Listing 5.24. Notice how the LineItem object has a reference to the Product in it.
The last of the domain objects is the Product object. Listing 5.25 shows the Product class definition and associated properties.
This section shows enough relevant code segments for the service implementation for you to see the complexity that gets introduced into your business logic when using the JDBC API. These code listings assume use of a simple wrapper method to handle the code associated with initialization and getting a Connection as described previously in the “Programming Model” section. See the downloadable code for the details of this wrapper method.
Loading a customer leverages the four-way join we introduced earlier in Listing 5.18. Listing 5.26 shows only a subset of the logic needed to populate an object graph from the result of the joined data.
Example 5.26. Load Customer
public AbstractCustomer loadCustomer(int customerId)
throws CustomerDoesNotExistException, GeneralPersistenceException
{
PreparedStatement customerPS = null;
ResultSet customerResultSet = null;
AbstractCustomer customer = null;
Connection conn = null;
try
{
// 1. Setup connection
conn = getJDBCConnection();
// 2. Retrieve Customer
customerPS = conn.prepareStatement(
// See Listing 5.18 for the 4-way join
);
customerPS.setInt(1, customerId);
customerResultSet = customerPS.executeQuery();
if (customerResultSet.next()==false) {
throw new CustomerDoesNotExistException();
}
String customerType =
customerResultSet.getString("TYPE");
if (customerType.equals("BUSINESS")) {
BusinessCustomer businessCustomer = new BusinessCustomer();
String volDiscountEval = customerResultSet.getString(
"BUSINESS_VOLUME_DISCOUNT");
if (volDiscountEval.equals("Y"))
businessCustomer.setVolumeDiscount(true);
else if (volDiscountEval.equals("N"))
businessCustomer.setVolumeDiscount(false);
String businessPartnerEval = customerResultSet.getString(
"BUSINESS_PARTNER");
if (businessPartnerEval.equals("Y"))
businessCustomer.setBusinessPartner(true);
else if (businessPartnerEval.equals("N"))
businessCustomer.setBusinessPartner(false);
customer = businessCustomer;
}
else if (customerType.equals("RESIDENTIAL")) {
...
//Continue to POPULATE 4 Levels of objects...In the implementation of the openOrder, we first check to see whether an order exists by reusing the loadCustomer method and checking whether the Order is loaded into the graph. Assuming no exceptions, we insert the new Order into the Order table. Because the Order table uses a generated ID strategy, we must immediately query the Order table for the new ID, and we update the Customer table with that ID. Listing 5.27 shows the relevant code.
Example 5.27. Open Order
AbstractCustomer customer = loadCustomer(customerId);
Order openOrder = customer.getOpenOrder();
if (openOrder != null) throw new OrderAlreadyOpenException();
order = new Order();
order.setCustomer(customer);
order.setStatus(Order.Status.OPEN);
order.setTotal(new BigDecimal(0.00));
PreparedStatement insertOrderPS = conn.prepareStatement(
"insert into ORDERS (CUSTOMER_ID,STATUS,TOTAL)
values (?,?,?)"
);
insertOrderPS.setInt(1, customerId); // set customerID
insertOrderPS.setString(2,"OPEN"); // set status
insertOrderPS.setBigDecimal(3,new BigDecimal(0.00)); // set total
insertOrderPS.executeUpdate(); // execute update statement
insertOrderPS.close();
PreparedStatement retrieveOrdersIdPS = conn.prepareStatement(
"select ORDER_ID from ORDERS
where CUSTOMER_ID=? and STATUS = 'OPEN'"
);
retrieveOrdersIdPS.setInt(1, customerId);
ResultSet rs = retrieveOrdersIdPS.executeQuery();
if(rs.next()){
int orderId = rs.getInt("ORDER_ID");
order.setOrderId(orderId);
}
else {
throw new GeneralPersistenceException(
"Could not retrieve new order id"
);
}
PreparedStatement updateCustomerPS = conn.prepareStatement(
"update CUSTOMER set OPEN_ORDER=? where CUSTOMER_ID=?"
);
updateCustomerPS.setInt(1, order.getOrderId());
updateCustomerPS.setInt(2, customerId);
updateCustomerPS.executeUpdate();
updateCustomerPS.close();
conn.commit();This routine first checks to see whether the Product exists by querying the Product table. It then queries to check whether a LineItem already exists, and updates the quantity if it does. Otherwise, it creates a new instance by inserting a new line item into the table. Listing 5.28 shows the relevant code fragments.
PreparedStatement productPS conn.prepareStatement(
"select PRICE,DESCRIPTION from PRODUCT where PRODUCT_ID=?"
);
productPS.setInt(1, productId);
productResultSet = productPS.executeQuery();
if (productResultSet==null)
throw new ProductDoesNotExistException();
customerPS = conn.prepareStatement(
"select OPEN_ORDER from CUSTOMER where CUSTOMER_ID=?"
);
customerPS.setInt(1, customerId);
customerResultSet = customerPS.executeQuery();
if (customerResultSet == null)
throw new CustomerDoesNotExistException();
customerResultSet.next();
Object openOrder = customerResultSet.getObject("OPEN_ORDER");
if (customerResultSet.getObject("OPEN_ORDER") == null)
throw new OrderNotOpenException();
int orderID = (Integer)openOrder;
if (!productResultSet.next())
throw new ProductDoesNotExistException();
BigDecimal productPrice = productResultSet.getBigDecimal("PRICE");
BigDecimal additionalCost = productPrice.multiply(
new BigDecimal(quantity)
);
BigDecimal lineItemAmount = new BigDecimal(0.0);
lineItemPS = conn.prepareStatement(
"select QUANTITY, AMOUNT from LINE_ITEM
where ORDER_ID = ? and PRODUCT_ID = ?"
);
lineItemPS.setInt(1, orderID);
lineItemPS.setInt(2, productId);
lineItemResultSet = lineItemPS.executeQuery();
boolean lineItemsCheck = lineItemResultSet.next();
if (!lineItemsCheck) // check if any line items already exist
{
//Insert new LineItem
}
else
{
//Update Existing LineItem
}For removing a LineItem, we check to see whether the associated Product exists; if so, then we check whether the associated Order is open. If the Order is open, we delete any LineItem for that Product. We do not check whether the LineItem exists in the table before removing the LineItem because technically, you can examine the value returned by the executeUpdate method to see whether the delete occurred. Listing 5.29 shows the relevant fragments of code.
Example 5.29. Remove LineItem
PreparedStatement productPS = conn.prepareStatement(
"SELECT * FROM PRODUCT WHERE PRODUCT_ID = ?"
);
productPS.setInt(1, productId);
productResultSet = productPS.executeQuery();
boolean productExists = false;
productExists = productResultSet.next();
productResultSet.close();
productPS.close();
conn.commit();
if (!productExists)
throw new ProductDoesNotExistException();
AbstractCustomer customer = loadCustomer(customerId);
Order openOrder = customer.getOpenOrder();
if (openOrder == null)
throw new OrderNotOpenException();
int orderId = openOrder.getOrderId();
PreparedStatement productDeletePS = conn.prepareStatement(
"DELETE FROM LINE_ITEM
WHERE PRODUCT_ID = ? AND ORDER_ID = ?"
);
productDeletePS.setInt(1, productId);
productDeletePS.setInt(2, orderId);
int deleteCount = productDeletePS.executeUpdate();
productDeletePS.close();
if (deleteCount == 0)
throw new LineItemDoesNotExist();
conn.commit();The example code for submitting an order using JDBC is shown in Listing 5.30. We check again to ensure that we have an open Order. We also check to see whether we have any LineItems. You cannot submit an order otherwise. If both conditions are met, we update the status of the Order and we set the OPEN_ORDER column on the Customer table to null.
Example 5.30. Submit Order
AbstractCustomer customer = loadCustomer(customerId);
Order openOrder = customer.getOpenOrder();
if (openOrder == null) throw new OrderNotOpenException();
if ((openOrder.getLineitems() == null) ||
(openOrder.getLineitems().size() <= 0))
throw new NoLineItemsException();
PreparedStatement updateOrderStatusPS = conn.prepareStatement(
"update ORDERS set STATUS ='SUBMITTED'
WHERE ORDER_ID=?"
);
int orderId = openOrder.getOrderId();
updateOrderStatusPS.setInt(1, orderId);
updateOrderStatusPS.executeUpdate();
updateOrderStatusPS.close();
customerCloseOrderPS = conn.prepareStatement(
"update CUSTOMER set OPEN_ORDER = NULL
where CUSTOMER_ID=?"
);
customerCloseOrderPS.setInt(1, customerId);
customerCloseOrderPS.executeUpdate();The packaging of components will depend on your deployment environment. JDBC applications on a Java SE platform may require nothing more than specifying the proper JDBC driver JARs in the classpath. Java EE applications may require you to configure a DataSource on an application server by defining references to that DataSource inside a deployment descriptor. Depending on the implementation, you may package your driver with your application or install the driver on a server.
As we discussed in Chapter 3, we are using JUnit and DbUnit to test our code. The downloadable source contains a test project for each technology. Figure 5.2 shows the Unit Test Project for the JDBC version of the common example.
Usually the database URL is different in production than in any of the testing environments. If a DataSource is used, this can be a simple matter of changing the binding; otherwise, don’t forget to change the property used to specify the JDBC URL in your configuration file. If you are using a DataSource, you may configure connection pool settings and such as part of a testing process; these settings will likely differ in production.
JDBC has been part of the Java language almost since its inception. JDBC libraries allow application developers to directly interact with databases by invoking SQL statements within their Java code.
Using JDBC as your persistence mechanism may simplify your dependencies on other components; but, unfortunately, the object-relational impedance mismatch is quickly realized as a developer is forced to try to bridge the chasm between the disparate world of tables, rows, and SQL and the world of objects, classes, and Java.
This assessment does not diminish the importance of JDBC. JDBC 4.0 has become very functional for both online and batch applications, and will continue to evolve to meet the changing requirements of Java applications.
The fact of the matter is that JDBC is the foundation that supports most homegrown, open-source, and commercial ORM frameworks, including those we will study in the rest of this book.
Getting Started with JDBC 4 using Apache Derby | |
This is a DeveloperWorks Tutorial on JDBC 4.0 Features. | |
A.5.2 | Understand the DB2 UDB JDBC Universal Driver |
This is a good discussion on the difference between Type 2 and Type 4 Drivers. | |
www.ibm.com/developerworks/db2/library/techarticle/dm-0512kokkat/ |