
 CHAPTER 24
CHAPTER 24
Experimental Study of GA-Based Schedulers in Dynamic Distributed Computing Environments
Universitat Politècnica de Catalunya, Spain
24.1 INTRODUCTION
In this chapter we address the issue of experimental evaluation of metaheuristics for combinatorial optimization problems arising in dynamic environments. More precisely, we propose an approach to experimental evaluation of genetic algorithm–based schedulers for job scheduling in computational grids using a grid simulator. The experimental evaluation of metaheuristics is a very complex and time-consuming process. Moreover, ensuring significant statistical results requires, on the one hand, testing on a large set of instances to capture the most representative set of instances, and on the other, finding appropriate values of the search parameters of the metaheuristic that would be expected to work well in any instance of the problem.
Taking into account the characteristics of the problem domain under resolution is among the most important factors in experimental studies of the metaheuristics. One such characteristics is the static versus dynamic setting. In the static setting, the experimental evaluation and fine tuning of parameters is done through benchmarks of (static) instances. An important objective in this case is to run the metaheuristic a sufficient number of times on the same instance and using a fixed setting of parameters to compare the results with the state of the art. To avoid a biased result, parameters are fine-tuned using instances other than those used for reporting computational results. This is actually the most common scenario in evaluating metaheuristics for combinatorial optimization problems. It should be noted that among many issues, the generation of benchmarks of instances is very important here since we would like a benchmark to be as representative as possible of all problem instances. Examples of such benchmarks of static instances are those for the traveling salesman problem [28], quadratic assignment problems [6], min k-tree [18], and the 0–1 multiknapsack problem [12].
Simple random generation of instances, for example, could fail to capture the specifics of the problem. The interest is to obtain a rich benchmark of instances so that the performance and robustness of metaheuristics could be evaluated. One such example is the benchmark of static instances for independent job scheduling in distributed heterogeneous computing environments [5,20]. In this problem a set of independent jobs having their workload are to be assigned to a set of resources having their computing capacities. The authors of the benchmark used the expected time to compute (ETC) matrix model and generated 12 groups of 100 instances each, where each group tries to capture different characteristics of the problem. Essentially, different scenarios arise in distributed heterogeneous computing environments, due to the consistency of the computing capacity, the heterogeneity of resources, and the heterogeneity of the workload of jobs. For example, we could have scenarios in which resources have a high degree of heterogeneity and jobs have a low degree of heterogeneity. The aim of the benchmark is to represent real distributed computing environments as realistically as possible. This benchmark has been used for the evaluation of metaheuristic implementations in a static setting [5,23,24,25] and metaheuristic-based batch schedulers [29,30].
The state of the art in experimental evaluation of parameters for metaheuristics approaches in a dynamic setting is somewhat limited compared to studies carried out in the static setting. Dynamic optimization problems are becoming increasingly important, especially those arising from computational systems such as the problem of job scheduling. Such problems require the development of effective systems to experimentally study, evaluate, and compare various metaheuristics resolution techniques.
In this chapter we present the use of a grid simulator [31] to study genetic algorithms (GAs)– based schedulers. The main contribution of this work is an approach to plug in GA-based implementations for independent job scheduling in grid systems with the grid simulator. Unlike other approaches in the literature, in which the scheduling algorithms are part of the simulation tool, in our approach the simulator and the scheduler are decoupled. Therefore, although we use a GA-based scheduler, in fact, any other heuristics scheduler can be plugged into the simulator. Moreover, in this approach we are able to observe the performance of GA-based schedulers in a dynamic setting where resources and jobs vary over time. Also, using this approach we could tune the simulator to capture different real grid systems with the aim of evaluating performance behavior, in terms of both optimization criteria and the robustness of the GA-based scheduler.
The remainder of the chapter is organized as follows. In Section 24.2 we give a short overview of some related work on experimenting and on fine tuning of metaheuristics in static and dynamic setting. Independent job scheduling is defined in Section 24.3, and the GA-based scheduler for the problem is presented in Section 24.4. In Sections 24.5 and 24.6 we present the grid simulator and the interface for using the GA-based scheduler with the grid simulator, respectively. Some computational results are given in Section 24.7. We end the chapter with some conclusions and indications for future work.
24.2 RELATED WORK
Experimental analysis and fine tuning of metaheuristics have attracted the attention of many researchers, and a large body of literature exists for the static setting. In the general context of the experimental analysis of algorithms, Johnson [14] presented several fundamental issues. Although the approach is applicable to metaheuristics, due to its particularities, such as the resolution of large-scale problems, hybridization, convergence, use of adaptive techniques, and so on, the metaheuristics community has undertaken research for the experimental analysis and fine tuning of metaheuristics on its own. It should be noted, however, that most of the research work in the literature is concerned with experimenting on and fine tuning of metaheuristics in a static setting.
On the one hand, research efforts have been oriented toward the development of a methodology and rigorous basis for experimental evaluation of heuristics (e.g., Rardin and Uzsoy [22], Barr et al. [4]). On the other hand, concrete approaches to dealing in practice with the fine tuning of parameters such as the development of specific software (e.g., the CALIBRA [2]) or the use of statistics and gradient descent methods [9] and the use of self-adaptive procedures [17] have been proposed. These approaches are generic in purpose and could also be used in experimenting on and fine tuning of metaheuristics for scheduling in a static setting.
Due to increasing interest in dynamic optimization problems, recently many researchers have focused on experimental analysis in dynamic setting [15]. There is little research work on studying schedulers experimentally in dynamic environments. YarKhan and Dongarra [32] presented an experimental study of scheduling using simulated annealing in a grid environment. Based on experimental analysis, the authors report that a simulated annealing scheduler performs better, in terms of estimated execution time, than an ad hoc greedy scheduler. Zomaya and Teh [33] analyzed genetic algorithms for dynamic load balancing. The authors use a “window-sized” mechanism for varying the number of processors and jobs in a system. Madureira et al. [19] presented a GA approach for dynamic job shop scheduling problems that arise in manufacturing applications. In their approach, the objective was to adapt the planning of jobs due to random events occurring in the system rather than computing an optimum solution, and thus the approach deals with the design of a GA scheduler to react to random events occurring in the system. Klusácek et al. [16] presented an evaluation of local search heuristics for scheduling using a simulation environment.
Other approaches in the literature (Bricks [27], MicroGrid [26], ChicSim [21], SimGrid [8], GridSim [7], and GangSim [11]) use simulation as a primary objective and embed concrete scheduling policies rather than optimization approaches for scheduling in the simulator.
24.3 INDEPENDENT JOB SCHEDULING PROBLEM
Computational grids (CGs) are very suitable for solving large-scale optimization problems. Indeed, CGs join together a large computing capacity distributed in the nodes of the grid, and CGs are parallel in nature. Yet to benefit from these characteristics, efficient planning of jobs (hereafter, job and task are used indistinctly) in relation to resources is necessary. The scheduling process is carried out in a dynamic form; that is, it is carried out while jobs enter the system, and the resources may vary their availability. Similarly, it is carried out in running time to take advantage of the properties and dynamics of the system that are not known beforehand. The dynamic schedulers are therefore more useful than static schedulers for real distributed systems. This type of scheduling, however, imposes critical restrictions on temporary efficiency and therefore on its performance.
The simplest version of job scheduling in CGs is that of independent jobs, in which jobs submitted to the grid are independent and are not preemptive. This type of scheduling is quite common in real-life grid applications where independent users submit their jobs, in complete applications to the grid system, or in applications that can be split into independent jobs, such as in parameter sweep applications, software and/or data-intensive computing applications and data-intensive computing, and data mining and massive processing of data.
Problem Description Under the ETC Model Several approaches exist in the literature to model the job scheduling problem. Among them is the proposed expected time to compute (ETC) model, which is based on estimations or predictions of the computational load of each job, the computing capacity of each resource, and an estimation of the prior load of the resources.
This approach is common in grid simulation, where jobs and their workload, resources, and computing capacities are generating through probability distributions. Assuming that we dispose of the computing capacity of resources, the prediction of the computational needs (workload) of each job, and the prior load of each resource, we can then calculate the ETC matrix where each position ETC[t][m] indicates the expected time to compute job t in resource m. The entries ETC[t][m] could be computed by dividing the workload of job t by the computing capacity of resource m, or in more complex ways by including the associated migration cost of job t to resource (hereafter, resource and machine are used indistinctly) m, and so on.
The problem is thus defined formally as (a) a set of independent jobs that must be scheduled (any job has to be processed entirely in a unique resource); (b) a set of heterogeneous machine candidates to participate in the planning; (c) the workload (in millions of instructions) of each job; and (d) the computing capacity of each machine (in MIPS).
The number of jobs and resources may vary over time. Notice that in the ETC matrix model, information on MIPS and workload of jobs is not included. As stated above, this matrix can be computed from the information on machines and jobs. Actually, ETC values are useful to formulate the optimization criteria, or fitness of a schedule. Also, based on expected time to compute values, the ready times of machines (i.e., times when machines will have finished previously assigned jobs) can be defined and computed. Ready times of machines measure the previous workload of machines in the grid system.
Optimization Criteria Among the possible optimization criteria for the problem, the minimization of makespan (the time when the latest job finishes) and flowtime (the sum of finalization times of all the jobs) and the maximization of (average) utilization of grid resources can be defined. Next, we give their formal definition (see Equations 24.2 to 24.5); to this end we define first the completion time of machines, completion[m], which indicates the time in which machine m will finalize the processing of the jobs assigned previously, as well as of those already planned for the machine; Fj denotes the finishing time of job j, ready[m] is the ready time of machine m, Jobs is the set of jobs, Machines is the set of machines, and schedule is a schedule from the set S of all possible schedules:


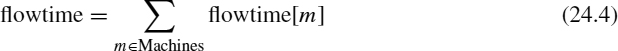

In the equations above, Machines indicate the set of machines available. These optimization criteria can be combined in either a simultaneous or hierarchic mode. In the former, we try to optimize the criteria simultaneously, while in the later, the optimization is done according to a previously fixed hierarchy of the criteria according to the desired priority (see Section 24.7).
24.4 GENETIC ALGORITHMS FOR SCHEDULING IN GRID SYSTEMS
Genetic algorithms (GAs) [5] have proved to be a good alternative for solving a wide variety of hard combinatorial optimization problems. GAs are a population-based approach where individuals (chromosomes) represent possible solutions, which are successively evaluated, selected, crossed, mutated, and replaced by simulating the Darwinian evolution found in nature.
One important characteristic of GAs is the tendency of the population to converge to a fixed point where all individuals share almost the same genetic characteristics. If this convergence is accelerated by means of the selection and replacement strategy, good solutions will be obtained faster. This characteristic is interesting for the job scheduling problem in grid systems given that we might be interested to obtain a fast reduction in the makespan value of schedule.
GAs are high-level algorithms that integrate other methods and genetic operators. Therefore, to implement it for the scheduling problem, we used a standard template and designed the encodings, inner methods, operators, and appropriate data structures.
In this section we present briefly the GA-based scheduler [10,30], which has been extended with new versions for the purposes of this work. Two encodings and several genetic operators are presented; in the experimental study (see Section 24.7), those that showed the best performance are identified.
Schedule Encodings Two types of encoding of individuals, the direct representation and the permutation-based representation, were implemented. In the former, a schedule is encoded in a vector of size nb_jobs, where schedule[i] indicates the machine where job i is assigned by the schedule. In the latter, each element in the encoding must be present only once, and it is a sequence < S1, S2, …, Sm >, where Si is the sequence of jobs assigned to machine mi.
GA's Methods and Operators Next we describe briefly the methods and operators of the GA algorithm for the scheduling problem based on the encodings above.
1. Generating the initial population. In GAs, the initial population is usually generated randomly. Besides the random method, we have used two ad hoc heuristics: the longest job to fastest resource–shortest job to fastest resource (LJFR-SJFR) heuristic [1] and minimum completion time (MCT) heuristics [20]. These two methods are aimed at introducing more diversity to the initial population.
2. Crossover operators. We considered several crossover operators for the direct representation and other crossover operators for the permutation-based representation. In the first group, one-point crossover, two-point crossover, uniform crossover, and fitness-based crossover were implemented; in the second group we considered the partially matched crossover (PMX), cycle crossover (CX), and order crossover (OX).
3. Mutation operators. The mutation operators are oriented toward achieving load balancing of resources through movements and swaps of jobs in different resources. Thus, four mutation operators were defined: Move, Swap, Move&Swap, and Rebalancing mutation.
4. Selection operators. The selection of individuals to which the crossover operators will be applied is done using the following selection operators: select random, select best, linear ranking selection, binary tournament selection, and N-tournament selection.
5. Replacement operators. Several replacement strategies known in the literature were implemented: generational replacement, elitist generational replacement, replace only if better, and steady-state strategy.
The final setting of GA operators and parameters is done after a tuning process (see Section 24.7).
24.5 GRID SIMULATOR
In this section we describe the main aspects of HyperSim-G, a discrete event-based simulator for grid systems (the reader is referred to Xhafa et al. [31] for details). The simulator has been conceived, designed, and implemented as a tool for experimentally studying algorithms and applications in grid systems. There are many conditions that make simulation an indispensable means for experimental evaluation. Among them we could distinguish the complexity of the experimentation and the need to repeat and control it. Also, resources of the grid systems could have different owners who establish their local policies on use of resources, which could prevent free configuration of grid nodes.
24.5.1 Main Characteristics of the Grid Simulator
HyperSim-G simulator is based on a discrete event model; the behavior of the grid is simulated by discrete events occurring in the system. The sequence of events and the changes in the state of the system capture the dynamic behavior of the system.
The simulator offers many functionalities that allow us to simulate resources, jobs, communication with schedulers, recording data traces, and the definition of grid scenarios, among others. Thus, a complete specification of resource characteristics (computing capacity, consistency of computing, hardware/software specifics, and other parameters) can be done in the simulator. Regarding jobs submitted to the grid, a complete specification of job characteristics is possible. In addition to standard characteristics such as release time, jobs can also have their own requirements on resources that can solve them.
Parameters of the Simulator The simulator is highly parameterized, making it possible to simulate realistically grid systems. The parameters used in the simulator follow.
Usage: sim [options] Options: -n, --ttasks <integer> Total number of tasks (jobs) -b, --itasks <integer> Initial number of tasks -i, --iatime <distrib> Task mean interarrival time -w, --workload <distrib> Task mean workload (MI) -o, --ihosts <integer> Initial number of hosts -m, --mips <distrib> Host mean (MIPS) -a, --addhost <distrib> Add-host event distribution -d, --delhost <distrib> Del-host event distribution -f, --minhosts <integer> Minimum number of hosts -g, --maxhosts <integer> Maximum number of hosts -r, --reschedule Reschedule uncompleted tasks -s, --strategy <meta_p> Scheduler meta policy -x, --hostselect <host_p> Host selection policy -y, --taskselect <task_p> Task selection policy -z, --activate <wake_p> Scheduler activation policy -l, --allocpolicy <local_p> Host local scheduling policy -1, --nruns <integer> Number of runs -2, --seed <integer> Random seed -3, --thrmach <double> Threshold of machine type -4, --thrtask <double> Threshold of task type -5, --inmbatch <double> Threshold for immediate and batch -t, --trace <filename> Enable trace on output file -h, --help Shows this help
Output of the Simulator For a setting of input parameters, the simulator outputs the following (statistical) values:
- Makespan: the finishing time of the latest job
- Flowtime: sum of finishing times of jobs
- Total Potential Time: sum of available times of machines
- Total Idle Time: sum of idle times of machines
- Total Busy Time: sum of busy time of machines
- Total Lost Time: sum of execution times lost due to resource dropping from the system
- Host Utilization: the quotient of host utilization
- Number Hosts: number of hosts (idle or not) available in the system
- Number Free Hosts: number of idle hosts available in the system
- Global Queue Length: number of jobs pending to schedule
- Waiting Time: time period between the time when a job enters the system and starts execution in a grid resource
- Schedules Per Task: number of times a job has been scheduled
- Number Scheduler Calls: number of times the scheduler has been invoked
- Number Activations: number of times scheduling took place (the scheduler is activated and job planning took place)
- Scheduler Activation Interval: time interval between two successive activations of the scheduler
24.5.2 Coupling of Schedulers with the Simulator
Unlike other simulation packages in which the scheduling policies are embedded in the simulator, in HyperSim-G the scheduling algorithms are completely separated from the simulator, which need not to know the implementation of the specific scheduling methods. This requirement regarding scheduling is achieved through a “refactoring” design and using new classes and methods, as shown in Figure 24.1.
HyperSim-G includes several classes for scheduling. We distinguish here the Scheduler class, which, in turn, uses four other classes: (a) TaskSelectionPolicy: this class implements job selection policies; for instance, SelectAllTasks; (b) HostSelectionPolicy: this class implements resource selection policies; for instance, SelectAllHosts, SelectIdleHosts; (c) SchedulerActivacion: this class implements different policies for launching the scheduler (e.g., TimeIntervalActivacion); and (d) the class SchedulingPolicy, which serves as a basis for implementing different scheduling methods. It is through this class that any scheduling method could be plugged in the scheduler; the simulator need not know about the implementation of specific scheduling methods, such as GA-based schedulers.

Figure 24.1 Scheduling entities in HyperSim-G.
24.6 INTERFACE FOR USING A GA-BASED SCHEDULER WITH THE GRID SIMULATOR
The GA-based scheduler is implemented using the skeleton design of Alba et al. [3]. However, it is not possible to plug in the scheduler to the simulator in a straightforward way since the skeleton interface and the SchedulingPolicy interface in the simulator cannot “recognize” each other. This is, in fact, the most common situation since the scheduler needs not to know about the simulator, and vice versa, the simulator needs not to know the implementation of the scheduler. Therefore, the simulator, as a stand-alone application, has been extended using the the adapter design pattern to support the use of external schedulers without changing the original definition of the simulator class.
GAScheduler Class This class inherits and implements the SchedulingPolicy interface. This class is able to “connect” the behavior of the GA-based scheduler with the simulator. In Figure 24.2 we show the class diagram using the adapter pattern.
Essentially, it is through the constructor of the GAScheduler and the virtual method schedule that the parameters and the problem instance are passed to any of the subclasses implementing the SchedulingPolicy interface. It should be noticed that the simulator will now act as a grid resource broker, keeps information on the system's evolution, and is in charge of planning the jobs dynamically as they arrive at the system.
Taking into account the dynamic nature of the grid is very important here. A new activation policy of the scheduler (ResourceAndTimeActivation) has been defined, which generates an event schedule: (a) each time a resource joins the grid or a resource is dropped from the grid; or (b) activate the schedule at each time interval to plan the jobs entered in the system during that time interval. Moreover, since we also aim to optimize the flowtime, a new local scheduling policy, called SPTFPolicy (shortest-processing-time-first policy), has been defined.
Use of the Simulator with the GA-Based Scheduler Currently, the simulator with the GA-based scheduler can be used from a command line by using the option -s (scheduling strategy) as follows:
-s GA_scheduler(t,s)
which instructs to the simulator to run the GA-based scheduler for t seconds in simultaneous optimization mode.

Figure 24.2 Adapter GAScheduler class.
24.7 EXPERIMENTAL ANALYSIS
In this section we present some computational results for evaluation of the performance of the GA-based schedulers used in conjunction with the grid simulator. Notice that the experimental study is conducted separately for each of the four GA-based schedulers: elitist generational GA with hierarchic optimization, elitist generational GA with simultaneous optimization, steady-state GA with hierarchic optimization, and steady-state GA with simultaneous optimization. The basic GA configuration shown in Table 24.1 is used for all of them.
24.7.1 Parameter Setting
Two cases have been considered for measuring the performance of the GA-based scheduler: the static and dynamic. In the first one, the planning of jobs is done statically; that is, no new jobs are generated, and the available resources are known beforehand. Essentially, this is using the simulator as a static benchmark of instances. The static case was helpful to fine-tune the parameters. In the dynamic case, which is the most relevant, both jobs and resources may vary over time.
For both static and dynamic cases, the performance of the GA-based scheduler is studied for four grid sizes: small, medium, large, and very large. The number of initial number of hosts and jobs in the system for each case is specified below for the static and dynamic cases, respectively.
GA Configuration We report here computational results for makespan and flowtime values obtained with two versions of GAs—the elitist generational GA and steady-state GA—and for each of them, both simultaneous and hierarchic optimization modes were considered.
The GA configuration used is shown in Table 24.1.
Notice that both GA-based schedulers are run for the same time, which in the static case is about 40 seconds and in the dynamic case is about 25 seconds. A total of 30 independent runs were performed; the results reported are averaged and the standard deviation is shown. The simulations were done in the same machine (Pentium-4 HT, 3.5 GHz, 1-Gbyte RAM, Windows XP) without other programs running in the background.
24.7.2 Parameters Used in a Static Setting
In the static setting the simulator is set using the parameter values [sptf stands for shortest-processing-time-first policy and n(.,.) denotes the normal distribution] in Table 24.2. Observe that in this case, the number of hosts and jobs is as follows: small (32 hosts, 512 jobs), medium (64 hosts, 1024 jobs), large (128 hosts, 2048 jobs), and very large (256 hosts, 4096 jobs).
In Tables 24.3, 24.4, and 24.5 we show the results for makespan, flowtime, and resource utilization for both versions of GA-based scheduler, and for each of them for both optimization modes. The confidence interval is also shown. A 95% CI means that we can be 95% sure that the range of makespan (flowtime, resource utilization) values would be within the interval shown if the experiment were to run again.
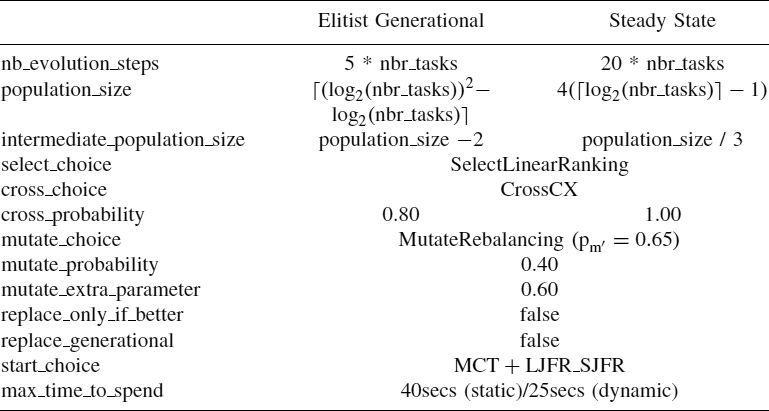
TABLE 24.2 Setup of the Simulator in the Static Case

TABLE 24.3 Makespan Values (Arbitrary Time Units) for Two GA-Based Schedulers in a Static Setting

TABLE 24.4 Flowtime Values for Two GA-Based Schedulers in a Static Setting

24.7.3 Evaluation of the Results
As can be seen from Tables 24.3, 24.4, and 24.5, the steady-state GA in its hierarchic version shows the best performance for makespan values, and the confidence interval (CI) increases slowly with increase in the grid size. It can also be observed that the CI is larger for simultaneous optimization than for hierarchic optimization.
TABLE 24.5 Resource Utilization Values for Two GA-Based Schedulers in a Static Setting

Regarding the flowtime, the steady-state GA in its simultaneous version shows the best performance. It should be noted that the value of flowtime is not affected by the average number of jobs assigned to a resource since it depends on the total number of jobs to be assigned. We also observed that for small grid size, the elitist generational GA in its simultaneous version obtained the best flowtime reductions.
Finally, regarding the resource utilization, we observed that the resource utilization is very good in general. The best values are obtained by the steady-state GA in its hierarchic version.
24.7.4 Parameters Used in a Dynamic Setting
In the dynamic setting the simulator is set using the parameter values in Table 24.6. Observe that in this case, the initial number of hosts and jobs is as follows: small (32 hosts, 384 jobs), medium (64 hosts, 768 jobs), large (128 hosts, 1536 jobs), and very large (256 hosts, 3072 jobs).
In Tables 24.7, 24.8, and 24.9 we show the results for makespan, flowtime, and resource utilization for both versions of GA-based scheduler and for each of them for both optimization modes.
Evaluation of the Results As can be seen from Tables 24.7, 24.8, and 24.9, for makespan values, steady-state GA again showed the best performance. However, for small and medium-sized grids, the makespan reductions are worse than in the static case. This could be explained by the fact that in the dynamic case changes in the available resources cause changes in the computational capacity, which in turn implies losts of execution time (due to the fluctuations). On the other hand, elitist generational GA showed to be more sensible to the grid size increment and does not make good use of the increment of the computing capacity of the grid. The simultaneous versions again showed worse performance; nonetheless, they performed better than in the static case. Similar observations as in the makespan case hold for the flowtime. Finally, regarding resource utilization, it seems that GA-based schedulers for high dynamic environments are not able to obtain high resource utilization, which is due to not-so-good load balancing achieved by GAs in the dynamic setting. Again steady-state GA showed the best performance.
TABLE 24.6 Setup of the Simulator in the Dynamic Case

TABLE 24.7 Makespan Values (Arbitrary Time Units) for Two GA-Based Schedulers in a Dynamic Setting

TABLE 24.8 Flowtime Values for Two GA-Based Schedulers in a Dynamic Setting

TABLE 24.9 Resource Utilization Values for Two GA-Based Schedulers in a Dynamic Setting

24.8 CONCLUSIONS
In this work we have presented an approach for experimental evaluation of metaheuristics-based schedulers for independent job scheduling using a grid simulator. In our approach, the metaheuristic schedulers can be developed independently from the grid simulator and can be coupled with the grid simulator using an interface, which allow communication between the scheduler and the simulator.
We have exemplified the approach for the experimental evaluation of four GA-based schedulers in a dynamic environment: elitist generational GA (in both hierarchic and simultaneous optimization mode) and steady-state GA (in both hierarchic and simultaneous optimization mode). The results of the study showed, on the one hand, the usefulness and feasibility of using the grid simulator for experimental evaluation of GA-based schedulers in a dynamic setting and, on the other hand, that steady-state GA performed best for both makespan and flowtime objectives in its hierarchic and simultaneous versions, respectively.
Acknowledgments
This research is partially supported by projects ASCE TIN2005-09198-C02-02, FP6-2004-ISO-FETPI (AEOLUS), MEC TIN2005-25859-E, and MEFOALDISI (Métodos formales y algoritmos para el diseño de sistemas) TIN2007-66523.
REFERENCES
1. A. Abraham, R. Buyya, and B. Nath. Nature's heuristics for scheduling jobs on computational grids. In Proceedings of the 8th IEEE International Conference on Advanced Computing and Communications, Cochin, India, 2000, pp. 45–52.
2. B. Adenso-Díaz and M. Laguna. Fine tuning of algorithms using fractional experimental designs and local search. Operations Research, 54(1):99–114, 2006.
3. E. Alba, F. Almeida, M. Blesa, C. Cotta, M. Díaz, I. Dorta, J. Gabarró, C. León, G. Luque, J. Petit, C. Rodríguez, A. Rojas, and F. Xhafa. Efficient parallel LAN/WAN algorithms for optimization: the MALLBA project. Parallel Computing, 32(5–6):415–440, 2006.
4. R. S. Barr, B. L. Golden, J. Kelly, W. R. Stewart, and M. G. C. Resende. Designing and reporting computational experiments with heuristic methods. Journal of Heuristics, 1(1):9–32, 2001.
5. T. Braun, H. Siegel, N. Beck, L. Boloni, M. Maheswaran, A. Reuther, J. Robertson, M. Theys, and B. Yao. A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems. Journal of Parallel and Distributed Computing, 61(6):810–837, 2001.
6. R. E. Burkard, S. E. Karisch, and F. Rendl. QAPLIB: a quadratic assignment problem library. Journal of Global Optimization, 10(4):391–403 1997. http://www.opt.math.tu-graz.ac.at/qaplib/.
7. R. Buyya and M. M. Murshed. GridSim: a toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing. Concurrency and Computation: Practice and Experience, 14(13-15):1175–1220, 2002.
8. H. Casanova. SimGrid: A toolkit for the simulation of application scheduling, In Proceedings of the First IEEE/ACM International Symposium on Cluster Computing and the Grid (CCGrid'01), Brisbane, Australia, May 15–18, 2001, pp. 430–437.
9. S. P. Coy, B. L. Golden, G. C. Runer, and E. A. Wasil. Using experimental design to find effective parameter settings for heuristics. Journal of Heuristics, 7:77–97, 2000.
10. J. Carretero and F. Xhafa. Using genetic algorithms for scheduling jobs in large scale grid applications. Journal of Technological and Economic Development: A Research Journal of Vilnius Gediminas Technical University, 12(1):11–17, 2006.
11. C. Dumitrescu and I. Foster. GangSim: a simulator for grid scheduling studies. In Proceedings of the 5th International Symposium on Cluster Computing and the Grid (CCGrid'05), Cardiff, UK. IEEE Computer Society Press, Los Alamitos, CA, 2005, pp. 1151–1158.
12. A. Freville and G. Plateau. Hard 0–1 multiknapsack test problems for size reduction methods. Investigation Operativa, 1:251–270, 1990.
13. J. H. Holland. Adaptation in Natural and Artificial Systems. University of Michigan Press, Ann Arbor, MI, 1975.
14. D. S. Johnson. A theoretician's guide to the experimental analysis of algorithms. In M. Goldwasser, D. S. Johnson, and C. C. McGeoch, eds., Proceedings of the 5th and 6th DIMACS Implementation Challenges. American Mathematical Society, Providence, RI, 2002, pp. 215–250.
15. L. Kang, A. Zhou, B. MacKay, Y. Li, and Zh. Kang. Benchmarking algorithms for dynamic travelling salesman problems. In Proceedings of Evolutionary Computation (CEC'04), vol. 2, 2004, pp. 1286–1292.
16. D. Klusácek, L. Matyska, H. Rudová, R. Baraglia, and G. Capannini. Local search for grid scheduling. Presented at the Doctoral Consortium at the International Conference on Automated Planning and Scheduling (ICAPS'07), Providence, RI, 2007.
17. J. Kivijärvi, P. Fränti, and O. Nevalainen. Self-adaptive genetic algorithm for clustering. Journal of Heuristics, 9:113–129, 2003.
18. k-Tree benchmark. http://iridia.ulb.ac.be/~cblum/kctlib/.
19. A. Madureira, C. Ramos, and S. Silva. A genetic approach for dynamic job-shop scheduling problems. In Proceedings of the 4th Metaheuristics International Conference (MIC'01), 2001, pp. 41–46.
20. M. Maheswaran, S. Ali, H. Siegel, D. Hensgen, and R. Freund, Dynamic mapping of a class of independent tasks onto heterogeneous computing systems. Journal of Parallel and Distributed Computing, 59(2):107–131, 1999.
21. K. Ranganathan and I. Foster. Simulation studies of computation and data scheduling algorithms for data grids. Journal of Grid Computing, 1(1):53–62, 2003.
22. R. L. Rardin and R. Uzsoy. Experimental evaluation of heuristic optimization algorithms: a tutorial. Journal of Heuristics, 7:261–304, 2001.
23. G. Ritchie. Static multi-processor scheduling with ant colony optimisation and local search. Master's thesis, School of Informatics, University of Edinburgh, UK, 2003.
24. G. Ritchie and J. Levine. A fast, effective local search for scheduling independent jobs in heterogeneous computing environments. TechRep. Centre for Intelligent Systems and Their Applications, University of Edinburgh, UK, 2003.
25. G. Ritchie and J. Levine. A hybrid ant algorithm for scheduling independent jobs in heterogeneous computing environments. Presented at the 23rd Workshop of the UK Planning and Scheduling Special Interest Group (PLANSIG'04), 2004.
26. H. J. Song, X. Liu, D. Jakobsen, R. Bhagwan, X. Zhang, K. Taura, and A. Chien. The microgrid: a scientific tool for modeling computational grids. Journal of Science Programming, 8(3):127–141, 2000.
27. A. Takefusa, S. Matsuoka, H. Nakada, K. Aida, and U. Nagashima. Overview of a performance evaluation system for global computing scheduling algorithms. In Proceedings of the High Performance Distributed Conference, IEEE Computer Society, Washington, DC, 1999, pp. 11–17.
28. Travelling salesman problem benchmark. http://elib.zib.de/pub/mp-testdata/tsp/tsplib/tsplib.html.
29. F. Xhafa, E. Alba, B. Dorronsoro, and B. Duran. Efficient batch job scheduling in grids using cellular memetic algorithms. Journal of Mathematical Modelling and Algorithms (online), Feb. 2008.
30. F. Xhafa, J. Carretero, and A. Abraham. Genetic algorithm based schedulers for grid computing systems. International Journal of Innovative Computing, Information and Control, 3(5):1–19, 2007.
31. F. Xhafa, J. Carretero, L. Barolli, and A. Durresi, A. Requirements for an event-based simulation package for grid systems. Journal of Interconnection Networks, 8(2):163-178, 2007.
32. A. YarKhan and J. Dongarra. Experiments with scheduling using simulated annealing in a grid environment. In Proceedings of GRID'02, 2002, pp. 232–242.
33. A. Y. Zomaya and Y. H. Teh. Observations on using genetic algorithms for dynamic load-balancing. IEEE Transactions on Parallel and Distributed Systems, 12(9):899–911, 2001.
Optimization Techniques for Solving Complex Problems, Edited by Enrique Alba, Christian Blum, Pedro Isasi, Coromoto León, and Juan Antonio Gómez
Copyright © 2009 John Wiley & Sons, Inc.