
 CHAPTER 4
CHAPTER 4
Analyzing Parallel Cellular Genetic Algorithms
Universidad de Málaga, Spain
B. DORRONSORO
Université du Luxembourg, Luxembourg
4.1 INTRODUCTION
Genetic algorithms are population-based metaheuristics that are very suitable for parallelization because their main operations (i.e., crossover, mutation, local search, and function evaluation) can be performed independently on different individuals. As a consequence, the performance of these population-based algorithms is improved especially when run in parallel.
Two parallelizing strategies are especially relevant for population-based algorithms: (1) parallelization of computation, in which the operations commonly applied to each individual are performed in parallel, and (2) parallelization of population, in which the population is split into different parts, each evolving in semi-isolation (individuals can be exchanged between subpopulations). Among the most widely known types of structured GAs, the distributed (dGA) (or coarse-grained) and cellular (cGA) (or fine-grained) algorithms are very popular optimization procedures (see Figure 4.1). The parallelization of the population strategy is especially interesting, since it not only allows speeding up the computation, but also improving the search capabilities of GAs [1,2].
In this chapter we focus on cGAs, which have been demonstrated to be more accurate and efficient than dGAs for a large set of problems [3]. Our main contribution in this chapter is the implementation and comparison of several parallel models for cGAs. This model has typically been parallelized in massively parallel machines, but few studies propose parallel models for clusters of computers with distributed memory. We implement the main models of parallel cGAs that appear in the literature for clusters of computers, and compare their performance.

Figure 4.1 (a) Panmictic, (b) distributed, and (c) cellular GAs.
The chapter is organized as follows. In Section 4.2 we describe the standard model of a cGA, in which the individuals in the population are structured in a grid. Next, different implementations of parallel cGAs are presented, followed by parallel models for the cGAs used in the literature. In Section 4.5 we test and compare the behavior of several parallel models when solving instances of the well-known p-median problem. Finally, we summarize our most important conclusions.
4.2 CELLULAR GENETIC ALGORITHMS
A canonical cGA follows the pseudocode in Algorithm 4.1. In this basic cGA, the population is usually structured in a regular grid of d dimensions (d = 1, 2, 3), and a neighborhood is defined on it. The algorithm iteratively applies the variation operators to each individual in the grid (line 3). An individual may only interact with individuals belonging to its neighborhood (line 4), so its parents are chosen among its neighbors (line 5) with a given criterion. Crossover and mutation operators are applied to the individuals in lines 6 and 7 with probabilities Pc and Pm, respectively. Afterward, the algorithm computes the fitness value of the new offspring individual (or individuals) (line 8), and inserts it (or one of them) into the place of the current individual in the population (line 9) following a given replacement policy. This loop is repeated until a termination condition is met (line 2). The most usual termination conditions are to reach the optimal value (if known), to perform a maximum number of fitness function evaluations, or a combination.
Algorithm 4.1 Pseudocode for a Canonical cGA


Figure 4.2 In cellular GAs, individuals are allowed to interact with their neighbors only during the breeding loop.
In Figure 4.2 we show the steps performed during the breeding loop in cGAs for every individual, as explained above. There are two possible ways to update the individuals in the population [4]. The one shown in Figure 4.2 is called asynchronous, since the newly generated individuals are inserted into the population (following a given replacement policy) and can interact in the breeding loops of its neighbors. However, there is also the possibility of updating the population in a synchronous way, meaning that all the individuals in the population are updated at the same time. For that, an auxiliary population with the newly generated individuals is kept, and after applying the breeding loop to all the individuals, the current population is replaced by the auxiliary population.
4.3 PARALLEL MODELS FOR cGAs
As noted earlier, cGAs were developed initially in massively parallel machines, although other models more appropriate for the currently existing distributed architectures have emerged. In this section we describe briefly the primary conceptual models of the major parallel cGA paradigms that can be used.
Independent Runs Model This extremely simple method of doing simultaneous work can be very useful. In this case, no interaction exists among the independent runs. For example, it can be used to execute several times the same problem with different initial conditions, thus allowing gathering statistics on the problem. Since cGAs are stochastic in nature, the availability of this type of statistics is very important.
Master–Slave Model This method consists of distributing the objective function evaluations among several slave processors, while the main loop of the cGA is executed in a master processor. This parallel paradigm is quite simple to implement and its search space exploration is conceptually identical to that of a cGA executing on a serial processor. The master processor controls the parallelization of the objective function evaluation tasks (and possibly the fitness assignment and/or transformation) performed by the slaves. This model is generally more efficient as the objective evaluation becomes more expensive to compute, since the communication overhead is insignificant with respect to the fitness evaluation time.
Distributed Model In these models the overall cGA population is partitioned into a small number of subpopulations, and each subpopulation is assigned to a processor (island). In this scheme, the designer has two alternatives:
1. Each island executes a complete cGA using only its subpopulations, and individuals occasionally migrate between one particular island and its neighbors, although these islands usually evolve in isolation for the majority of the cGA run. The main idea is that each island can search in very different regions of the entire search space, and the migration helps to avoid the premature convergence of each island. This model is not considered in this chapter since it does not fit the canonical cGA model.
2. The global behavior of the parallel cGA is the same as that of a sequential (cellular) cGA, although the population is divided in separated processors. For that, at the beginning of each iteration, all the processors send the individuals of their first/last column/row to their neighboring islands. After receiving the individuals from the neighbors, a sequential cGA is executed in each subpopulation. The partition of the population can be made using different schemas. The two principal existing schemes are shown in Figure 4.3.
4.4 BRIEF SURVEY OF PARALLEL cGAs
In Table 4.1 the main existing parallel cEAs in the literature are summarized. Some examples of cGAs developed on SIMD machines are those studied by Manderick and Spiessens [5] (improved later in ref. 24), Mühlenbein [25,26], Gorges-Schleuter [27], Collins [28], and Davidor [6], where some individuals are located on a grid, restricting the selection and recombination to small neighborhoods in the grid. ASPARAGOS, the model of Mühlenbein and Gorges-Schleuter, was implemented on a transputers network, with the population structured in a cyclic stair. Later it evolved, including new structures and matching mechanisms [14], until it was constituted as an effective optimization tool [29].

Figure 4.3 (a) CAGE and (b) combined parallel model of a cGA.
We also note the work of Talbi and Bessière [30], who studied the use of small neighborhoods, and that of Baluja [8], where three models of cGAs and a GA distributed in islands are analyzed on a MasPar MP-1, obtaining the best behavior of the cellular models, although Gordon and Whitley [31] compared a cGA to a coarse-grained GA, with the latter being slightly better. Kohlmorgen et al. [32] compared some cGAs and presented the equivalent sequential GA, showing clearly the advantages of using the cellular model. Alba and Troya [33] published a more exhaustive comparison than previous ones between a cGA, two panmictic GAs (steady-state and generational GAs), and a GA distributed in an island model in terms of the temporal complexity, the selection pressure, the efficacy, and the efficiency, among others issues. The authors conclude the existence of an important superiority of structured algorithms (cellular and island models) over nonstructured algorithms (the two panmictic GAs).
In 1993, Maruyama et al. [34] proposed a version of a cGA on a system of machines in a local area network. In this algorithm, called DPGA, an individual is located in each processor, and in order to reduce the communication to a minimum, in each generation each processor sends a copy of its individual to another randomly chosen processor. Each processor keeps a list of suspended individuals in which the individuals are located when they arrive from other processors. When applying the genetic operators in each processor, this list of suspended individuals behaves as the neighborhood. This model is compared to APGA, an asynchronous cGA proposed by Maruyama et al. [35], a sequential GA, and a specialized heuristic for the problem being studied. As a conclusion, the authors remark that DPGA shows an efficiency similar to that of the equivalent sequential algorithm.
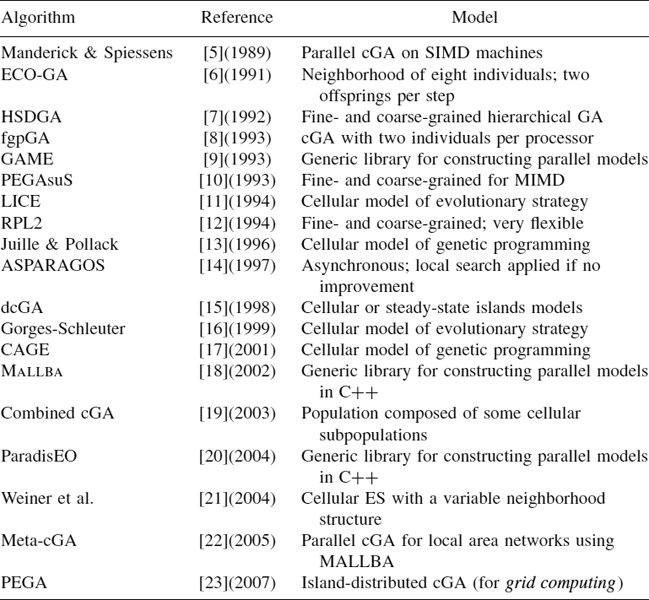
TABLE 4.1 Brief Summary of the Main Existing Parallel cEAs
There also exist more modern parallel cGA models, which work on connected computers in local area networks. These models should be designed to reduce communications to a minimum, as, due to their own characteristics, the cellular models need a high number of communications. In this frame, Nakashima et al. [36] propose a combined cGA in which there exist subpopulations with evolving cellular structure, interacting through their borders. A graph of this model can be seen on the right in Figure 4.3. In a later work [19], the authors proposed some parameterizations with different numbers of subpopulations, methods of replacement, and the topology of the subpopulation, and they analyze the results. The authors used this model in a sequential machine, but it is extrapolated directly to a parallel model, where each processor contains one of the subpopulations. This idea of splitting the population into smaller cellular subpopulations running in parallel was also studied by Luque et al. [22], who present the meta-cGA, which was developed using the MALLBA framework, and compared versus other sequential and parallel models in clusters of 2, 4, 8, and 16 computers.
Folino et al. [37] proposed CAGE, a parallel GP. In CAGE the population is structured in a bidimensional toroidal grid, and it is divided into groups of columns that constitute subpopulations (see the graph on the left in Figure 4.3). In this way, the number of messages to send is reduced according to other models, which divide the population in two dimensions (x and y axes). In CAGE, each processor contains a determined number of columns that evolve, and at the end of the generation the two columns at the borders are sent to neighboring processors so that they can use these individuals as neighbors of the individuals located in the limits of its subpopulation.
Dorronsoro et al. [23] proposed a new parallel cGA called PEGA (parallel cellular genetic algorithm), which adopts the two principal parallelization strategies commonly used for GAs: fine- and coarse-grained. The population is divided into several islands (dGA), the population of each island being structured by following the cellular model (cGA). Furthermore, each cGA implements a master–slave approach (parallelization of the computation) to compute the most costly operations applied to their individuals. Periodically, cGAs exchange information (migration) with the goal of inserting some diversity into their populations, thus avoiding their falling into local optima. By using such a structure in the population, the authors keep a good balance between exploration and exploitation, thus improving the capability of the algorithm to solve complex problems [1,38]. PEGA was applied successfully to the largest existing instances of the vehicle routing problem in a grid of about 150 computers.
Finally, there exist some generic programming frameworks of parallel algorithms that make it easy to implement any type of parallel algorithm, including the cellular models considered. These include GAME [9], ParadisEO [20], and MALLBA [18].
4.5 EXPERIMENTAL ANALYSIS
In this section we perform several experimental tests to study the behavior of the various parallel models described in previous sections. To test parallel algorithms we have used the well-known p-median problem [39]. We describe the p-median problem briefly in the next subsection and then discuss the results. First, we compare several well-known parallel models: a parallel cGA using independent runs (ircGA), a master–slave cGA (mscGA), and two different distributed cGAs, one that divides the populations into groups of columns [c-dcGA; see in Figure 4.3(a)], and another that partitions the population in squares [s-dcGA; see Figure 4.3(b)]. Later, we study some modifications of distributed versions. Specifically, we test an asynchronous distributed variant and change the migration gap. This causes the behavior of the algorithm to change with respect to the canonical serial model.
4.5.1 p-Median Problem
The p-median problem (PMP) is a basic model from location theory [39]. Let us consider a set I = {1, …, n} of potential locations for p facilities and an n × n matrix (gi, j) of transportation costs for satisfying the demands of customers. The p-median problem is to locate the p facilities at locations I to minimize the total transportation cost for satisfying customer demands. Each customer is supplied from the closest open facility.
This problem was shown to be NP-hard. The PMP has numerous applications in operations research, telecommunications, medicine, pattern recognition, and other fields. For the experiments we have used five instances (pmed16–21) provided by Beasley [40]. There are 400 customers and 5, 10, 40, 80, and 133 positions to be chosen, depending on the circumstance.
4.5.2 Analysis of Results
In this section we study the behavior of different parallel implementations of a cGA when solving the p-median problem. We begin with a description of the parameters of each algorithm. No special configuration analysis has been made for determining the optimum parameter values for each algorithm. The entire population comprises 400 individuals. In parallel implementations, each processor has a population of 400/n, where n is the number of processors (in these experiments, n = 8). All the algorithms use the uniform crossover operator (with probability 0.7) and bit-flip mutation operator (with probability 0.2). All the experiments are performed on eight Pentium 4 processors using 2.4-GHz PCs linked by a fast Ethernet communication network. Because of the stochastic nature of genetic algorithms, we perform 30 independent runs of each test to gain sufficient experimental data.
Performance of Parallel cGA Models Next we analyze and compare the behavior of four parallel variants, which are also compared against the canonical sequential cGA model. Table 4.2 summarizes the results of applying various parallel schemas to solve the five PMP instances. In this table we show the mean error with respect to the optimal solution (% error columns) and the mean execution time to find the best solution in seconds (time columns). We do not show the standard deviation because the fluctuations in the accuracy of different runs are rather small, showing that the algorithms are very robust. For the mean speedup time of these algorithms, shown in Figure 4.4, we use the weak definition of speedup [1]; that is, we compare the parallel implementation runtime with respect to the serial implementation runtime.
When we interpret the results in Table 4.2, we notice several facts. On the one hand, the ircGA model allows us to reduce the search time and obtain very good speedup (see Figure 4.4), nearly linear, but the results are worse than those of serial algorithms. This is not surprising, since when we use several islands, the population size of each is smaller than when using a single island, and the algorithm is not able to maintain enough diversity to provide a global solution. On the other hand, the behavior of the remainder of the variants is similar to that of the sequential version since they obtain the same numerical results (with statistical significance, p-value > 0.05). This is expected because these parallel models do not change the dynamics of the method with respect to the canonical version. Then we must analyze the execution time. The profit using the master–slave method is very low (see Figure 4.4) because the execution time of the fitness function does not compensate for the overhead cost of the communications.
TABLE 4.2 Overall Results of Parallel cGA Models


Figure 4.4 Mean weak speedup.
The distributed versions of the cGA are better than the sequential algorithm in terms of search time. The execution time is quite similar for both versions, and in fact, there is no statistical difference between them. The speedup is quite good, although it is sublinear. These results are quite surprisingly since these algorithms perform a large number of exchanges. This is due to the fact that the communication time is quite insignificant with respect to the computation time.
Performance of Asynchronous Distributed cGA Since the results of the distributed versions of cGA are very promising, we have extended this model using asynchronous communication. In the previous (synchronous) experiments, each island computes the new population, sends the first/last columns/rows to its neighbors, and waits to receive the data from the other islands. In the asynchronous case, the last step is different; the island does not wait, and if pending data exist, they are incorporated into its subpopulation, but otherwise, it computes the next iteration using the latest data received from its neighborhood. This asynchronous model demonstrates behavior that differs from that of the canonical model, since the islands are not working with the latest version of the solutions. In this scheme we must define the migration gap, the number of steps in every subpopulation between two successive exchanges (steps of isolated evolution).
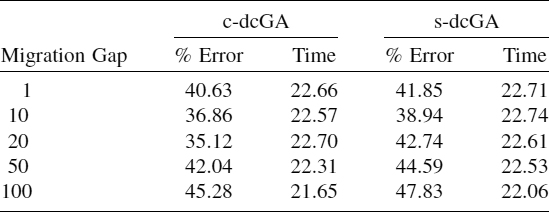
We have tested several values of this parameter: 1, 10, 20, 50, and 100, the results of this experiment being summarized in Table 4.3. In this case we used the pmed20 instance, the most complex. Several conclusions can be extracted from Table 4.3. First, we can observe that the asynchronous versions of the dcGA allows us to reduce the error when we use a small–medium-sized migration gap. However, for large values of the migration gap this model becomes less suitable and obtains poorer solutions. This is due to low–medium values of the migration gap that allow each island to search in a different space region, and is beneficial. However, if this parametric value is too large, subpopulations converge quickly to suboptimal solutions such as that which occurs in the ircGA variant. Second, we can notice that the c-dcGA version obtains a better numerical performance than the s-dcGA version, since the rectangular shape of each subpopulation makes it possible to maintain population diversity longer and is a key factor when dealing with small populations. With respect to the execution time, it is slightly reduced when the migration gap increases, but the difference is quite small, because as we said before, the computational cost is significant higher than the communication time.
TABLE 4.3 Overall Results of Asynchronous Distributed cGA Models
4.6 CONCLUSIONS
In this chapter we have discussed several parallel models and implementations of cGAs. This method appeared as a new algorithmic model intended to profit from the hardware features of massively parallel computers, but this type of parallel computer has become less and less popular. We then extended the basic concepts of canonical cGAs with the aim of offering the reader parallel models that can be used in modern parallel platforms. An overview of the most important up-to-date cEA systems was provided. The reference list can serve as a directory to provide the reader access to the valuable results that parallel cEAs offer the research community.
Finally, we performed an experimental test with the most common parallel models used in the literature. We use two distributed cellular, master–slave, and independent runs models to solve the well-known p-median problem. We note that the master–slave model is not suitable for this problem since the overhead provoked by the communications is not compensated by the execution time of the objective function. The independent runs model obtains very low execution times, but the solution quality gets worse. Use of distributed models improves the search time. Later, we tested an asynchronous version of distributed models, observing that the isolation computation of each island imposed for this scheme is beneficial for the algorithm when a low or medium-sized value of the migration gap is used, allowing us to reduce the error and the execution time.
Acknowledgments
The authors are partially supported by the Ministry of Science and Technology and FEDER under contract TIN2005-08818-C04-01 (the OPLINK project).
REFERENCES
1. E. Alba and M. Tomassini. Parallelism and evolutionary algorithms. IEEE Transactions on Evolutionary Computation, 6(5):443–462, 2002.
2. E. Cantú-Paz. Efficient and Accurate Parallel Genetic Algorithms, 2nd ed., vol. 1 of Series on Genetic Algorithms and Evolutionary Computation. Kluwer Academic, Norwell, MA, 2000.
3. E. Alba and B. Dorronsoro. Cellular Genetic Algorithsm, vol. 42 of Operations Research/Computer Science Interfaces. Springer-Verlag, Heidelberg, Germany 2008.
4. E. Alba, B. Dorronsoro, M. Giacobini, and M. Tomassini. Decentralized cellular evolutionary algorithms. In Handbook of Bioinspired Algorithms and Applications. CRC Press, Boca Raton, FL, 2006, pp. 103–120.
5. B. Manderick and P. Spiessens. Fine-grained parallel genetic algorithm. In J. D. Schaffer, ed., Proceedings of the 3rd International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1989, pp. 428–433.
6. Y. Davidor. A naturally occurring niche and species phenomenon: the model and first results. In R. K. Belew and L. B. Booker, eds., Proceedings of the 4th International Conference on Genetic Algorithms (ICGA), San Diego, CA. Morgan Kaufmann, San Francisco, CA, 1991, pp. 257–263.
7. H. M. Voigt, I. Santibáñez-Koref, and J. Born. Hierarchically structured distributed genetic algorithms. In R. Männer and B. Manderick, eds., Proceedings of the International Conference on Parallel Problem Solving from Nature II (PPSN-II). North-Holland, Amsterdam, 1992, pp. 155–164.
8. S. Baluja. Structure and performance of fine-grain parallelism in genetic search. In S. Forrest, ed., Proceedings of the 5th International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1993, pp. 155–162.
9. J. Stender, ed. Parallel Genetic Algorithms: Theory and Applications. IOS Press, Amsterdam, 1993.
10. J. L. Ribeiro-Filho, C. Alippi, and P. Treleaven. Genetic algorithm programming environments. In J. Stender, ed., Parallel Genetic Algorithms: Theory and Applications. IOS Press, Amsterdam, 1993, pp. 65–83.
11. J. Sprave. Linear neighborhood evolution strategies. In A. V. Sebald and L. J. Fogel, eds., Proceedings of the Annual Conference on Evolutionary Programming. World Scientific, Hackensack, NJ, 1994, pp. 42–51.
12. P. D. Surry and N. J. Radcliffe. RPL2: a language and parallel framework for evolutionary computing. In Y. Davidor, H.-P. Schwefel, and R. Männer, eds., Proceedings of the International Conference on Parallel Problem Solving from Nature III (PPSN-III). Springer-Verlag, Heidelberg, Germany, 1994, pp. 628–637.
13. H. Juille and J. B. Pollack. Massively parallel genetic programming. In Advances in Genetic Programming, vol. 2. MIT Press, Cambridge, MA, 1996, pp. 339–358.
14. M. Gorges-Schleuter. Asparagos96 and the traveling salesman problem. In Proceedings of the IEEE International Conference on Evolutionary Computation (CEC). IEEE Press, New York, 1997, pp. 171–174.
15. C. Cotta, E. Alba, and J. M. Troya. Un estudio de la robustez de los algoritmos genéticos paralelos. Revista Iberoamericana de Inteligencia Artificial, 98(5):6–13, 1998.
16. M. Gorges-Schleuter. An analysis of local selection in evolution strategies. In W. Banzhaf et al., eds., Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), vol. 1. Morgan Kaufmann, San Francisco, CA, 1999, pp. 847–854.
17. G. Folino, C. Pizzuti, and G. Spezzano. Parallel hybrid method for SAT that couples genetic algorithms and local search. IEEE Transactions on Evolutionary Computation, 5(4):323–334, 2001.
18. E. Alba and the MALLBA Group. MALLBA: A library of skeletons for combinatorial optimization. In R. F. B. Monien, ed., Proceedings of the Euro-Par, Paderborn, Germany, vol. 2400 of Lecture Notes in Computer Science. Springer-Verlag, Heidelberg, Germany, 2002, pp. 927–932.
19. T. Nakashima, T. Ariyama, T. Yoshida, and H. Ishibuchi. Performance evaluation of combined cellular genetic algorithms for function optimization problems. In Proceedings of the IEEE International Symposium on Computational Intelligence in Robotics and Automation, Kobe, Japan. IEEE Press, Piscataway, NJ, 2003, pp. 295–299.
20. S. Cahon, N. Melab, and E.-G. Talbi. ParadisEO: a framework for the reusable design of parallel and distributed metaheuristics. Journal of Heuristics, 10(3):357–380, 2004.
21. K. Weinert, J. Mehnen, and G. Rudolph. Dynamic neighborhood structures in parallel evolution strategies. Complex Systems, 13(3):227–243, 2001.
22. G. Luque, E. Alba, and B. Dorronsoro. Parallel metaheuristics: a new class of algorithms. In Parallel Genetic Algorithms. Wiley, Hoboken, NJ, 2005, pp. 107–125.
23. B. Dorronsoro, D. Arias, F. Luna, A. J. Nebro, and E. Alba. A grid-based hybrid cellular genetic algorithm for very large scale instances of the CVRP. In W. W. Smari, ed., 2007 High Performance Computing and Simulation Conference (HPCS'07). IEEE Press, Piscataway, NJ, 2007, pp. 759–765.
24. P. Spiessens and B. Manderick. A massively parallel genetic algorithm: implementation and first analysis. In R. K. Belew and L. B. Booker, eds., Proceedings of the 4th International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1991, pp. 279–286.
25. H. Mühlenbein. Parallel genetic algorithms, population genetic and combinatorial optimization. In J. D. Schaffer, ed., Proceedings of the 3rd International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1989, pp. 416–421.
26. H. Mühlenbein, M. Gorges-Schleuter, and O. Krämer. Evolution algorithms in combinatorial optimization. Parallel Computing, 7:65–88, 1988.
27. M. Gorges-Schleuter. ASPARAGOS: an asynchronous parallel genetic optimization strategy. In J. D. Schaffer, ed., Proceedings of the 3rd International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1989, pp. 422–428.
28. R. J. Collins and D. R. Jefferson. Selection in massively parallel genetic algorithms. In R. K. Belew and L. B. Booker, eds., Proceedings of the 4th International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1991, pp. 249–256.
29. M. Gorges-Schleuter. A comparative study of global and local selection in evolution strategies. In A. E. Eiben et al., eds., Proceedings of the International Conference on Parallel Problem Solving from Nature V (PPSN-V), vol. 1498 of Lecture Notes in Computer Science. Springer-Verlag, Heidelberg, Germany, 1998, pp. 367–377.
30. E.-G. Talbi and P. Bessière. A parallel genetic algorithm for the graph partitioning problem. In E. S. Davidson and F. Hossfield, eds., Proceedings of the International Conference on Supercomputing. ACM Press, New York, 1991, pp. 312–320.
31. V. S. Gordon and D. Whitley. Serial and parallel genetic algorithms as function optimizers. In S. Forrest, ed., Proceedings of the 5th International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1993, pp. 177–183.
32. U. Kohlmorgen, H. Schmeck, and K. Haase. Experiences with fine-grained parallel genetic algorithms. Annals of Operations Research, 90:203–219, 1999.
33. E. Alba and J. M. Troya. Improving flexibility and efficiency by adding parallelism to genetic algorithms. Statistics and Computing, 12(2):91–114, 2002.
34. T. Maruyama, T. Hirose, and A. Konagaya. A fine-grained parallel genetic algorithm for distributed parallel systems. In S. Forrest, ed., Proceedings of the 5th International Conference on Genetic Algorithms (ICGA). Morgan Kaufmann, San Francisco, CA, 1993, pp. 184–190.
35. T. Maruyama, A. Konagaya, and K. Konishi. An asynchronous fine-grained parallel genetic algorithm. In R. Männer and B. Manderick, eds., Proceedings of the International Conference on Parallel Problem Solving from Nature II (PPSN-II). North-Holland, Amsterdam, 1992, pp. 563–572.
36. T. Nakashima, T. Ariyama, and H. Ishibuchi. Combining multiple cellular genetic algorithms for efficient search. In L. Wang et al., eds., Proceedings of the Asia-Pacific Conference on Simulated Evolution and Learning (SEAL). IEEE Press, Piscataway, NJ, 2002, pp. 712–716.
37. G. Folino, C. Pizzuti, and G. Spezzano. A scalable cellular implementation of parallel genetic programming. IEEE Transactions on Evolutionary Computation, 7(1):37–53, 2003.
38. E. Alba and B. Dorronsoro. A hybrid cellular genetic algorithm for the capacitated vehicle routing problem. In Engineering Evolutionary Intelligent Systems, vol. 82 of Studies in Computational Intelligence. Springer-Verlag, Heidelberg, Germany, 2007, pp. 379–422.
39. C. ReVelle and R. Swain Central facilities location. Geographical Analysis, 2:30–42, 1970.
40. J. E. Beasley. A note on solving large-median problems. European Journal on Operations Reserach, 21:270–273, 1985.
Optimization Techniques for Solving Complex Problems, Edited by Enrique Alba, Christian Blum, Pedro Isasi, Coromoto León, and Juan Antonio Gómez
Copyright © 2009 John Wiley & Sons, Inc.