
As we can see, one simple example, in which the patterns are not linearly separable, has led us to more and more issues related to the use of the perceptron architecture. This need has led to the application of multilayer perceptrons. In Chapter 1, Getting Started with Neural Networks, we dealt with the fact that the natural neural network is structured in layers as well, and each layer captures pieces of information from a specific environment. In artificial neural networks, layers of neurons act in this way, by extracting and abstracting information from the data, transforming it into another dimension or shape.
In the XOR example, we found the solution to be the addition of the third component that would make a linear separation possible. However, there remained a few questions regarding how that third component would be computed. Now, let's consider the same solution as a two-layer perceptron, shown as follows:

Now, we have three neurons instead of just one, but in the output, the information transferred by the previous layer is transformed into another dimension or shape, whereby it would be theoretically possible to establish a linear boundary on the data points. However, the question of finding the weights for the first layer remains unanswered, or can we apply the same training rule to neurons other than the output? We are going to deal with this issue in the generalized delta rule section.
Multilayer perceptrons can have any number of layers and any number of neurons in each layer. The activation functions may be different on any layer. An MLP network is usually composed of at least two layers, one for the output and the other for the "hidden" layer.
Tip
There are also some references that consider the input layer as the nodes that collect input data. Therefore, for these cases, the MLP is considered to have at least three layers. For the purposes of this book, let's consider the input layer as a special type of layer that has no weights, and as the effective layers, that is, those enabled to be trained, we'll consider the hidden and output layers.
A hidden layer is so-called because it actually "hides" its outputs from the external world. Hidden layers can be connected in series in any number, thus forming a deep neural network. However, the more layers a neural network has, the slower both the training and running would be, and according to mathematical foundations, a neural network with one or two hidden layers at most can learn as well as deep neural networks with dozens of hidden layers.
Tip
It is recommended that the activation functions be nonlinear in the hidden layers, particularly if in the output layer the activation function is linear. According to linear algebra, having a linear activation function in all layers is equivalent to having only one output layer, provided that the additional variables introduced by the layers would be mere linear combinations of the previous ones or the inputs. Usually, activation functions such as hyperbolic tangent or sigmoid are used because they are derivable.
In an MLP feedforward network, a certain neuron i receives data from a neuron j of the previous layer and forwards its output to a neuron k of the next layer , as can be seen in the following schema:

MLPs in theory may be partially or fully connected. Partially means that not all neurons from one layer are connected to each neuron of the next layer, and fully connected means that all neurons from one layer are connected to all neurons of the next layer. The following figure shows both the partially and fully connected layers:

For mathematical simplicity, let's work only on fully connected MLPs, which can be described mathematically by the equation:

Where yo is the network output (if we have multiple outputs, we can replace y0 by Y, representing a vector), fo is the activation function of the output, l is the number of hidden layers, nhi is the number of neurons in the hidden layer i, wi is the weight connecting the ith neuron of the last hidden layer to the output, fi is the activation function of the neuron i, and bi is the bias of the neuron i. It can be seen that this equation gets larger, as the number of layers increase. In the last summing operation, there will be the inputs xi.
Neural networks can be both feedforward and feedback (recurrent). So, it is possible that some neurons or layers forward signals to a previous layer. This behavior allows the neural network to maintain state on some data sequence, and this feature is particularly exploited when dealing with time series or handwriting recognition. For training purposes, a recurrent MLP network can have feedback connections only in the output layer. In order to give it a more fully recurrent nature, one can connect multiple recurrent MLPs in cascade.
Although recurrent networks are very suitable for some problems, they are usually harder to train, and eventually, the computer may run out of memory while executing them. In addition, there are recurrent network architectures better than MLPs such as the Elman, Hopfield, echo state, and bi-directional RNN. However, we are not going to dive deep into these architectures, because this book focuses on the simplest applications for those who have minimal experience in programming. However, a good reference is the book of Haykin [2008], whose specifications can be found at the end of this book on recurrent networks for those who are interested in it.
Bringing these concepts into the OOP point of view, we can review the classes already designed so far already designed, resulting in the following diagram:
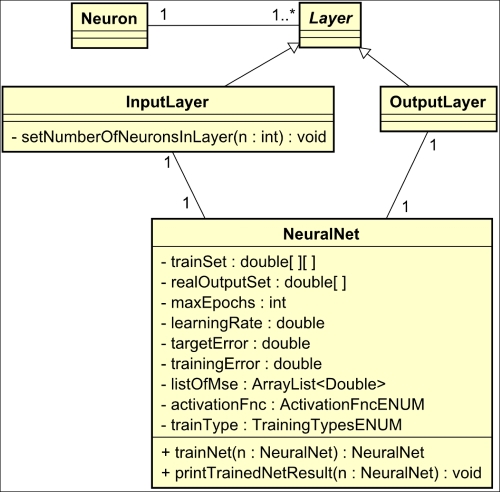
One can see that the neural network structure is hierarchical. A neural network is composed of layers that are composed of neurons. In the MLP architecture, there are three types of layers: input, hidden, and output. So, suppose that in Java, we would like to define a neural network consisting of three inputs, one output, and one hidden layer containing five neurons. The resulting code would be as follows:
NeuralNet n = NeuralNet(); InputLayer input = new InputLayer(); input.setNumberOfNeuronsInLayer(3); HiddenLayer hidden = new HiddenLayer(); hidden.setNumberOfNeuronsInLayer(5); OutputLayer output = new OutputLayer(); output.setNumberOfNeuronsInLayer(1); ////… n.setInputLayer(input); n.setHiddenLayer(hidden); n.setOutputLayer(output);