
The .loc operator supports pure label-based indexing. It accepts the following as valid inputs:
- A single label such as ["colC"], [2], or ["R1"]—note that in cases where the label is an integer, it doesn't refer to the integer position of the index, but the integer is itself a label.
- A list or array of labels, for example, ["colA", "colB" ].
- A slice object with labels, for example, "colB":"colD".
- A Boolean array.
Let's examine each of these four cases with respect to the following two Series—one with an integer-based label and another with a string-based label:
ser_loc1 = pd.Series(np.linspace(11, 15, 5))
ser_loc2 = pd.Series(np.linspace(11, 15, 5), index = list("abcde"))
# Indexing with single label
In: ser_loc1.loc[2]
Out: 13.0
In: ser_loc2.loc["b"]
Out: 12.0
# Indexing with a list of labels
ser_loc1.loc[[1, 3, 4]]
This results in the following output:

ser_loc2.loc[["b", "c", "d"]]

# Indexing with range slicing
ser_loc1.loc[1:4]

ser_loc2.loc["b":"d"]

Notice that, unlike the ranges in Python where the posterior end is excluded, here, both the exteriors are included in the selected data. pandas objects can also be filtered based on logical conditions applied to values within the objects:
# Indexing with Boolean arrays
ser_loc1.loc[ser_loc1 > 13]

Now, these techniques for slicing can be applied to a DataFrame. It works the same, except for the fact that there is a provision to supply two sets of labels—one for each axis:
# Create a dataframe with default row-labels
df_loc1 = pd.DataFrame(np.linspace(1, 25, 25).reshape(5, 5), columns = ["Asia", "Europe", "Africa", "Americas", "Australia"])
# Create a dataframe with custom row labels
df_loc2 = pd.DataFrame(np.linspace(1, 25, 25).reshape(5, 5), columns = ["Asia", "Europe", "Africa", "Americas", "Australia"], index = ["2011", "2012", "2013", "2014", "2015"])
# Indexing with single label
df_loc1.loc[:,"Asia"]

df_loc1.loc[2, :]

In the preceding case, "2" did not represent the position, but the index label:
df_loc2.loc["2012", :]

# Indexing with a list of labels
df_loc1.loc[:,["Africa", "Asia"]]

# Indexing with range slicing
df_loc1.loc[:,"Europe":"Americas"]
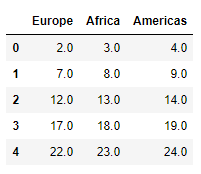
# Indexing with Boolean array
df_loc2.loc[df_loc2["Asia"] > 11, :]
