


Core component architecture
IBM FileNet P8 Platform is the unified enterprise foundation for the integrated IBM FileNet P8 products. This chapter describes the core components of IBM FileNet P8 Platform, their architecture, data model, and associated security features.
This chapter covers the following topics:
2.1 Core components overview
IBM FileNet P8 Platform is a collection of tightly integrated components that are bundled together under a common platform. The broad functionality provided by these integrated components constitute an enterprise content and process management platform. Some of the key elements of this platform are a metadata repository, a process management repository, an out-of-the-box user interface for accessing content and process elements, and a storage framework that can support a wide range of storage devices and platforms.
To provide these services, the IBM FileNet P8 Platform relies on three core components:
•Content Engine (CE)
•Process Engine (PE)
•Workplace (WP) / Workplace XT (WP XT)
All other add-on products are built on the foundation that these three components provide.
Figure 2-1 provides a high-level architectural view of these key components and their relative interactions.

Figure 2-1 IBM FileNet P8 core components
|
Application Engine and Workplace naming convention: Application Engine is the official name for Workplace. Application Engine does not equate to Workplace XT. Both Workplace and Workplace XT support a common set of functions but differ in other areas. For consistency of the terminology used in the book, we use Workplace instead of Application Engine throughout the book.
|
The primary components are delivered as stateless components with farmable architectures that can support both vertical and horizontal scaling. Technology variations in the servers affect the way in which each is load-balanced and provisioned. Regardless, each server provides highly performing and highly scalable services in support of handling even the largest enterprise's mission-critical loads.
The remaining sections of this chapter provide details about each of the main components: Content Engine (including the storage tier), Process Engine, and Workplace/Workplace XT. In addition, there is a section that reviews the new Case Manager. For a review of additional included user interfaces, including Workplace XT, see Chapter 3, “Application interfaces” on page 63.
2.2 Content Engine
The Content Engine stores and retrieves all content within an IBM FileNet P8 system. It provides a series of services for creating, retrieving, updating, deleting, and securing content. In addition, it provides interfaces for handling event-based actions, document life cycle, and integration with various storage mediums.
The Content Engine is a J2EE Enterprise Java Bean (EJB) application and is deployed to a supported J2EE application server. The IBM FileNet P8 Platform currently supports a variety of Java application servers, such as IBM WebSphere®. For the complete list of supported application servers, see the Hardware and Software requirements guide.
The Content Engine application is written based on a generic set of J2EE services and is implemented primarily as a set of stateless session beans that take advantage of JDBC to store the metadata in the underlying database. The Content Engine also leverages both native and API-based interfaces to store content in a variety of storage medium. These J2EE services are fronted by two stateless EJBs that make up the EJB Listener, which demarcates the transaction and authentication boundaries into the server. Various asynchronous activities within the server are managed by a series of background threads.
Figure 2-2 shows the internal system architecture of a Content Engine.

Figure 2-2 Content Engine internal system architecture
Organization
Each Content Engine server instance is configured as a member of a given IBM FileNet P8 domain. A Content Engine server instance can support one or more object stores where content is stored. Each object store can be scaled to store hundreds of millions of objects and to service requests from thousands of concurrent users.
There is a single global configuration database (GCD) per IBM FileNet P8 domain. The GCD contains the system configuration, marking sets, and registration for all object stores that are defined in the system. Object Stores define a set of content, properties, and storage areas that represents a data set.
Figure 2-3 on page 23 illustrates the Content Engine’s internal data structure.

Figure 2-3 Content Engine internal data structure
2.2.1 Data model
The Content Engine stores documents and metadata in a combination of a database and target storage. The Content Engine uses an object-oriented data model defined by properties, classes, custom objects, and folders.
Central to the Content Engine is a strongly typed, hierarchical, and extensible object model. The Content Engine comes with a set of defined system classes that you can extend to create custom classes for use within an application. Some examples of the predefined classes are Document, Folder, Custom Object (special object that is content-free with metadata information only), Annotation, and Referential Containment Relationship.
Metadata and properties
Object information and metadata are defined and stored as properties for a given Content Engine object. These properties can be defined as one of the following property types: string, 32-bit integer, 64-bit floating point, binary data, ID (a GUID), date and time, boolean, and another object (object-valued property). The property can be defined as either containing a single value or multiple values (single- or multi-valued). In addition, it is also possible to configure a property’s default value(s) and to define whether a property value is required, how the values persists across versions, and when the value can be set (on creation only or at will).
Object-valued properties operate differently than the other data types. Single valued properties do not contain a simple value (for example a single string or a number), but instead contain a pointer to another object in the system, for example, a Folder object has an object-valued property named Parent referencing the Folder that it is contained in. Unlike other data types, a multi-valued object property does not contain an actual list of other objects, but instead it works as a reflective object property, meaning the values of that property are other objects that are pointing back to the object. Figure 2-4 illustrates the difference between single-value and reflective object property.
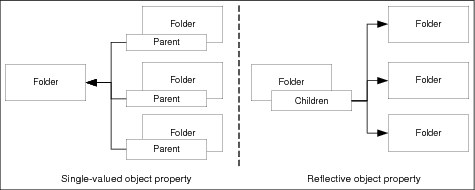
Figure 2-4 Single and reflective object properties
The cardinality of the property (single or multi-valued) defines whether the values are stored with the object record or in a series of multi-value tables (ListOfString, for example).
Classes
Within the Content Engine, each object is defined as an instance of a class. The class defines what type of object is being created, what metadata is to be collected about that object, and how that object is to be stored in the system. In keeping with the object-oriented nature of the Content Engine, classes can be subclassed. This orientation allows for a parent class to define a set of shared properties and behaviors; therefore, the subclass can define additional properties and possibly override the parent’s behavior as necessary.
Documents
The Content Engine allows for storing content as document objects. Document objects have metadata (properties) and one or more content elements. In addition, documents can optionally have life cycle and versions. For versioning, a document can be versioned at both a major and a minor level. Check-out and check-in operators provide facilities for locking a given revision for a given user.
Each independent document object results in a single row in the DocVersion table and are linked together by a VersionSeries object.
Custom objects
Custom objects are metadata-only objects with no associated content elements and are not versionable. Custom objects are typically thought of as a collection of metadata and possibly links to other objects within the IBM FileNet P8 repository.
Each object creates a new record in the Generic table.
Foldering
Content Engine offers a folder and foldering mechanism for organizing content by related items into a file system-like structure. Every folder in the system exists in the folder tree that derives from the root folder. Any document or custom object can be filed into one or more folders using a referential containment relationship object.
Because a folder is an object, it too can have metadata properties assigned to it. Each folder has a set of default metadata that is assigned (date created, creator, parent folder, and name). The folder class can also be subclassed to allow for additional metadata to be collected and stored.
Each folder results in a single row in the Container table.
2.2.2 Security
In addition to storing the content and metadata in the repository, the Content Engine offers a robust security model to allow for authenticating users and then controlling whether a user has rights (or is authorized) to use, view, update, and delete any given object or resource in the repository.
Authentication
Authentication is the process of determining who users are and whether users are who they say that they are. For authentication, Content Engine relies on the J2EE authentication model, which is based on the Java Authentication and Authorization Service (JAAS). Content Engine relies on the application server to perform this JAAS authentication. This leverages the security of the application server itself, which might do the authentication itself or might use perimeter authentication, if the authentication was already performed by another front-end system.
Content Engine (and IBM FileNet P8 in general) does not contain its own user database. Instead it leverages the existing user repository within an organization. This repository is accessed using LDAP and eliminates the need to maintain a user sync between the corporate user repository and the IBM FileNet P8 system.
Authorization
Authorization is the process of determining whether a user is allowed or disallowed permission to perform an action on an object, such as view or update. Content Engine manages these permissions right through an access control-based authorization model. Individual access rights control which actions can be performed on a given object by a given user or group (known as principals). These individual access rights, called Access Control Entries or ACEs, can be grouped together to form an access control list, or ACL. Applying one or more ACLs to an object individualizes the level of security that is enforced on an object. ACLs can apply directly to the object, or the object can be secured by ACLs derived from other sources:
•Default: Each class is created with a Default Instance Permissions ACL. By default, the Default Instance Permissions ACL is applied to instances of the class.
•Templates: Security templates, which contain a predefined list of access rights, can be applied to an object.
•Inherited: Permissions applied to some objects (folders, documents, or custom objects) can be inherited by other objects so that these “inherited” permissions supplement other permissions on the receiving objects. See “Security Inheritance” on page 27 for more information.
Principals that are defined within an ACE for a given ACL represent users or groups that are defined within an underlying LDAP repository. The task of mapping an access right to a user or group is supported by the authorization framework, which manages the user and group look-up in the configured LDAP repository or repositories. Content Engine supports most of the widely used LDAP stores (including Tivoli® Directory Server, Active Directory, and SunOne Directory Server). For more information, refer to IBM FileNet P8 Hardware and Software Requirements.
When generating an ACL, the Content Engine stores in the ACE a unique identifier for the user or group. In previous versions, which unique ID to store was not configurable, but in 5.0, the desired LDAP attribute to use as the unique ID can be specified during initial configuration, which allows more flexibility when moving systems between providers or within an organization.
For more information about security, see section 8.3.1, “Security of Content Engine objects” on page 215.
Security templates
Security templates are used to apply a specific set of rights to a document based on the values of the template. Templates can be combined with a document life cycle to easily change the security of the document based on where it is in its life cycle, for example, a document that is in process will likely be restricted to a small number of authors and perhaps reviewers, while a released document will have a much wider audience. See 2.2.4, “Life-cycles” on page 31 for additional information about life cycles and section 8.4.2, “Security policies” on page 234.
Marking sets
For some data it is desirable to allow the users to modify the security of an object based on its metadata rather than by updating the ACL, for example a document might have a classification level, such as public, secret, or top secret. Each classification conveys a specific set of user access rights. Rather than having to write custom code to update the ACL based on the given property value, the Content Engine offers a marking set. Marking Sets can modify the actual rights on the document by removing rights based on the value of a string property.
For more information, see section 8.4.1, “Marking sets” on page 229.
Security Inheritance
Using the IBM FileNet P8 Content Engine's Security Inheritance feature one object, a security parent, can pass its permissions to some other object, its security child. When permissions on the security parent change, the permissions on all its children also dynamically change. This feature gives much easier security management as, for example, you can set up your security so that changing the permissions on a single custom object can affect the security of all documents on your system.
One place where this is used is in folder-inherited security. It works by creating an object-valued property and using this property to propagate security from the target object.
For more information, see section 8.4.4, “Dynamic security inheritance” on page 239.
2.2.3 Event framework
Content Engine provides an extensible framework by which custom code is executed in response to various system- or user-defined events, such as adding a document to an object store.
The primary elements of the Content Engine event framework are:
•Event: A predefined action, such as the creation or deletion of a document.
•Event action: An object associated with the event, which specifies, through its property settings, which custom code to execute in response to the event.
•Event action handler: The code, written as custom Java classes that implement the EventActionHandler interface.
•Subscription: Links one or more events, a target Content Engine object, and an event action object.
Events within the Content Engine can be executed either synchronously or asynchronously to the initiating Content Engine transaction. Synchronous events execute within the transaction context of the executing request, so a failure of the action forces the overall transaction to fail. Asynchronous events are queued for later processing by the Content Engine server in the background, asynchronous-event thread.
System events
The Content Engine allows the firing off of events for certain incidents, which can be subscribed to and handled by a configurable event handler. This ability highlights the event-driven architecture of the IBM FileNet P8 Platform. The Content Engine allows the creation of an event when an important state is changed for a managed object. Table 2-1 lists the system events that can be subscribed to.
Table 2-1 List of system events for the Content Engine
|
Event
|
Description
|
Subscribable class or object
|
|
Creation
|
Triggers when an instance of a class is created or saved or a reservation object is created (CheckOut).
|
Document, Folder, Custom Object
|
|
Deletion
|
Triggers when an object is deleted from an Object Store.
|
Document, Folder, Custom Object
|
|
Update
|
Triggers when the properties of an object are changed.
|
Document, Folder, Custom Object
|
|
Update Security
|
Triggers when the access control information for an object is changed.
|
Document, Folder, Custom Object
|
|
Change State
|
Triggers when the document life cycle state for a document is changed
|
Document
|
|
Change Class
|
Triggers when the class of an object is changed
|
Document, Folder, Custom Object
|
|
CheckIn
|
Triggers when a document is checked in. Only available for Document classes that have versioning enabled
|
Document
|
|
CheckOut
|
Triggers when a document is checked out. Only available for Document classes that have versioning enabled
|
Document
|
|
Cancel Checkout
|
Triggers when a checkout is cancelled for a document. Only available for Document classes that have versioning enabled
|
Document
|
|
Classify Complete
|
Triggers when the classification for a document completes
|
Document
|
|
Promote Version
|
Triggers when a document is promoted to a new major version. Only available for Document classes that have versioning enabled
|
Document
|
|
Demote Version
|
Triggers when a document is demoted to a minor version. Only available for Document classes that have versioning enabled
|
Document
|
|
File
|
Triggers when an object is filed to a folder (including the creation of a subfolder)
|
Folder
|
|
Unfile
|
Triggers when an object is unfiled to a folder (including the deletion of a subfolder)
|
Folder
|
|
Freeze
|
Triggers when the Freeze method is called for a document
|
Document
|
|
Lock
|
Triggers when an object is locked
|
Document, Folder, Custom Object
|
|
Unlock
|
Triggers when an object is unlocked
|
Document, Folder, Custom Object
|
The system events cover a large variety of object-related state changes. Additional custom events can be defined, and the subscription to these events and the configuration of the corresponding actions occur in exactly the same way as it occurs for system events.
Custom events
The Content Engine provides various system events that can be used to activate managed content and for auditing purposes. However, in complex situations, the system events that are provided (ready to use immediately) might not provide all of the required functionality. Using the flexible IBM FileNet P8 architecture you can extend the event model by adding custom events.
The Content Engine itself does not generate custom events; instead, custom events occur by a custom application through calling a RaiseEvent method for the corresponding object. This approach is beneficial because after the event is raised it is treated like a system event, which means that the corresponding event action (and filter conditions) can be configured using the Enterprise Manager.
Custom event actions
The Content Engine’s event-driven architecture can raise system events and custom events. The administrator can configure components that subscribe to these events to take the appropriate action: launching a workflow or by implementing a custom event action.
The event action handler code is written as Java classes that implement the EventActionHandler interface. These custom Java classes are delivered as jar files located through the global class path or stored as content objects called Code Modules (the jar files or compiled classes are stored as content elements). When a given action occurs on a particular object, a query is executed to find the set of associated subscriptions and their corresponding event action handlers. For each subscription, the event action handler is loaded through a custom class loader and executed through the EventActionHandler.onEvent() method.
For additional information about creating event actions and developing event handlers, refer to Developing Applications with the IBM FileNet P8 APIs, SG24-7743.
Interacting with business processes
Launching a process on the Process Engine is another option for handing an event within the Content Engine. This happens thorough a workflow subscription. Workflow subscriptions can be defined and configured using either Workplace XT or the FileNet Enterprise Manager. A workflow subscription calls a defined version of a workflow. It does not automatically launch the latest version for this workflow, which allows transferring and pre-testing a new version of a workflow definition but still maintaining the production workflow subscription using the old workflow definition. If it is required to always launch the latest version of a workflow by a subscription, use a launcher workflow that starts the most current release of the business workflow.
On the level of the workflow subscription, mapping properties for the object that launched the workflow to workflow fields can be configured and additional filter conditions that determine if the workflow will really be launched (for example launch a workflow only if a major version of a document is added).
2.2.4 Life-cycles
Throughout a document’s life it moves from one state to another, such as from Application to Approval in the case of a loan application document. The Content Engine provides document life cycle management through life cycle policies and life cycle actions:
•Life cycle polices define the states that a document can transition through. The life cycle policy can define a security template to be applied to the document when it enters a new state. Lifecycle policies can be associated with a document class and applied to subsequent instances of that class or they can be associated with an individual document instance.
•Life cycle actions define the action that occurs when a document moves from one state to another. Life cycle actions are associated with state changes in the life cycle policy object.
In addition to events, a life cycle policy can apply a security policy based on the life cycle stage of a document. For additional information about Security Policies, “Security templates” on page 27.
For additional information about life-cycles, see section 8.4.3, “Document lifecycle policies” on page 237.
2.2.5 Content storage
The primary categories of content storage that are associated with the Content Engine are database storage, file storage, fixed content device storage, and content federation. These storage options can be used individually or in conjunction with one another. A specific storage device is created in the object store as a storage area. Individual classes can be configured to use a specific storage area or can be instructed to use a storage policy. A storage policy defines the storage area to use based on rules configured for the policy by the administrator.
Content is always streamed from the client to the server and stored in a temporary staging area prior to being committed to the final destination. The final committal step is different depending on the chosen storage option. Figure 2-5 on page 32 illustrates the various Content Engine storage services.
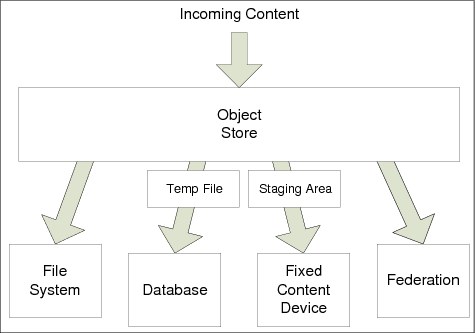
Figure 2-5 Content Engine storage options
Database storage
Database storage is the mechanism for storing content within the configured relational database management system. Each piece of content is stored as a BLOB within the Content table of the database. Database storage is typically configured for content that does not need retention and that tends to be smaller. Every object store has a single database store configured, although it might not be assigned to a class or storage policy.
File storage
File storage represents any device that can be mounted through the Common Internet File System (CIFS) or Network File System (NFS) protocols. The storage device can be direct-attached (either local disk or SAN) or network-attached storage (NAS). All servers in a farmed deployment must have access to all storage areas, which requires that the storage must be shared in some fashion, for example, NAS. Content files are initially written to a temporary file name on the storage device, then the process is completed in the following order:
1. The metadata updates are committed along with an entry in the ContentQueue table.
2. The entry in the content queue table is processed by an asynchronous background thread in which the content file is renamed to its final name.
3. The entry is removed from the ContentQueue table.
Fixed Content Device (FCD) storage
Fixed content devices represent a variety of IBM and third-party products that deliver additional functionality over standard file systems. This functionality can include Write Once Read Many (WORM), hardware-based object retention, multi-tiered storage, and others. An example of fixed content devices supported include the IBM Information Archive, IBM Tivoli Storage Manager, and some third-party storage systems.
Typically, third-party product integrations rely in some part on device APIs to manage the interactions that are necessary for committing or finalizing the content operations. Much like other storage types, the content is streamed from the client and stored in a temporary staging area on the server. The content is then written to a file storage area and a subsequent request to migrate the content out of the queue is processed. This migration request triggers the update to the fixed content device (generally through APIs), after which the system updates the document entry in the DocVersion table with a referral record to the entry in the FCD, and deletes the file in the staging area.
Content Federation
The final storage medium for a Content Engine system is federated document storage. Federation allows for the Content Engine to access data stored in a third party or mature system, such as IBM FileNet Image Services or third-party systems through IBM Content Integrator. For more information about federation, see Chapter 5, “Expansion products for connection and federation” on page 117.
Storage policies
In addition to defining where content can be stored in a repository, the Content Engine also offers an additional level of abstraction and definition to content storage through storage policies. A storage policy defines target storage using rules and can be used to farm content out to a number of storage areas for load balancing.
Using a storage policy allows for additional storage areas to be added to a system at a later date and ensures that all new content (new document and new versions of existing documents) uses that storage. Each class that accepts content can be defined with either a default storage area or a storage policy. If a storage policy is defined, at object creation time the system determines the final storage area based on the rules of the storage policy.
2.2.6 Full-text indexing
Content Engine provides search services based on the metadata of an object. Textual data and property values pertaining to documents are searchable using Content Search Services or the Legacy Content Search Engine.
Content Search Services
With the P8 5.0 release, Content Search Services (CSS) is introduced as an alternative to the IBM Legacy Content Search Engine (CSE). CSS uses Apache Lucene for indexing and search, UIMA (Unstructured Information Management Architecture) for tokenization and, LanguageWare® for dictionary processing. Full-text indexing and indexing of specific metadata attributes can be configured on a per class basis, for instance, any create or update operation on a given document instance triggers the server to evaluate the object’s full-text attribute to determine whether to queue the document for indexing.
Each CSS instance can be used for both indexing and searching tasks. You can deploy a single CSS server in your environment to be used for both indexing and search. However, the recommended approach is to deploy multiple CSS server instances and assign each one to do only indexing or only searching tasks. See Figure 2-6 on page 35 for these deployment options.

Figure 2-6 Content Search Services server configurations
The indexing process begins at the Content Engine when CBR-enabled objects, such as documents whose class is CBR enabled, are created or updated. The Content Engine stores indexing data for the object in indexes managed by the CSS servers. Each index is associated to a distinct index area in an object store. During the indexing process, the system can write to multiple indexes across these different index areas. When an index's capacity is reached, the index is automatically closed and a new index is opened. The Content Engine runs a background service on an indexing table to identify documents that are queued for indexing. The system queries items from the indexing table and then groups index requests pertaining to the same target index into an index batch. The binary documents in this batch are converted to text, and the entire batch is then submitted to a CSS indexing server.
After the index server receives the index batch, the preprocessing functions begin. Preprocessing functions consist of document construction, language identification, and tokenization of the document’s content and properties:
1. The XML filtering utility removes any superfluous XML elements from the extracted text containing XML elements. Non-searchable XML elements must be defined as a surplus element in the CSS configuration. This feature assists with minimizing index files by not indexing XML elements that will not be relevant for full text searches.
2. The language of the text is identified. To ensure accurate processing and optimal performance, a default language can be specified for an object store. If one language cannot be definitively identified for the content of an object store, the identification of the language can be set to automatic and triggers language identification on an object-by-object basis.
3. In the final step of preprocessing, tokens are created from the extracted text and index for the document is updated or created in its respective index area.
Users can submit Content-based retrieval (CBR) queries against the metadata, the full-text index data, or both. Search requests are initiated through FileNet Enterprise Manager or other client applications using the Content Engine API and includes a full-text expression that is submitted to the search server by the subsystem dispatcher. The search server can use word stems, synonyms, and stop words to improve search efficiency. The search server searches for and identifies the stem for all word terms included in a full-text search expression, for example, if you search for the word “running”, the search server automatically searches for the word “run” too. The search server also searches for all defined synonyms in the search expression, for example, if “International Business Machines” and “ibm” are defined as synonyms, searching for “ibm” is equivalent to searching for “ibm” or “International Business Machines”. A stop word is a word or phrase that is ignored by the search server to avoid irrelevant search results caused by common expressions, for example, if the word “the” is defined as a stop word, the phrase “The cat and the dog” and “cat and dog” are equivalent. The search server uses these definitions to evaluate the appropriate index and runs the full-text search. The results are returned to the subsystem dispatcher which then joins the results with other tables in the query and runs the query.
Legacy Content Search Engine
The Legacy Content Search Engine uses the Verity K2 server, a search engine from Autonomy, to provide full-text indexing. The Content Engine stores indexes into collections, where each collections is managed by a Verity server instance. During the indexing process, the system can write to multiple collections depending on the indexes being create or updated. Each index area has its own distinct set of collections. When the collection’s capacity is reached, the collection is automatically closed and a new collection is opened. The Content Engine runs a background service on an indexing table to identify documents that are queued for indexing. The system queries items from the indexing table and submits them in a batch to the Verity server. The Verity server uses a location on the file system to temporarily store documents before they are indexed. If a given document has any metadata attributes tagged for indexing, those attributes are written to a separate text file that is passed to the Verity server along with the content files to be indexed. Metadata and content files are passed to the Verity server as URIs, which the search engine uses to directly access and read those files for indexing.
Users submit CBR queries to CSE from the FileNet Enterprise Manager or custom application using the Content Engine API. Results from queries against the metadata and full-text index data are dumped into a temporary table and a join is executed across the associated metadata table to handle any metadata-related portions of the query. Where multiple, active, index areas are configured for a given class of objects, queries are executed against each index area, and the final result-set is aggregated from the individual query and returned to the Content Engine. CSE also uses the concepts of word stems, synonyms, and stop words, as described in the Content Search Services section, to improve search efficiency.
Migration
The Content Engine allows for the migration of Legacy Content Search Engine (CSE) indexes to a Content Search Services object store. Migration is initiated by enabling CSS in an object store that is already enabled for CSE. A background migration index job is launched and processes all objects indexed in Verity collections and indexes them into CSS indexes. The Content Engine runs in dual-index mode, where objects are indexed, updated, and deleted in both Verity collections and CSS indexes. Dual-indexing is required until all CSE objects for the respective object store are migrated to CSS, but the Content Engine can run in this mode for as long as the administrator deems necessary. Searches are routed to CSE, but there is an option to route searches to CSS on a per-search basis to allow for testing of the CSS indexes (CSS indexes are incomplete until the migration process is complete). After completion of the migration index job, the default search engine can be switched to CSS. Switching to CSS affects all client application searches and can be reversed prior to disabling CSE from the respective object store. After the switch to CSS is successfully validated, CSE can be disabled, which ends dual-indexing mode. Disabling CSE is a non-reversible action.
2.2.7 Publishing
Content Engine provides publishing services using integration with a third-party rendition engine from Liquent. The rendition engine provides the ability to render various documents’ formats into either PDF or HTML. The publishing framework can be leveraged to generate a new publication document or to generate a new version of an existing publication document.
The publishing framework consists of two primary components, a publish template and a publish style template. Along with the IBM FileNet Enterprise Manager, the Publishing Style Template Manager is installed. This tool can be used to create and edit publish style templates. The Workplace-supplied Publishing Designer is used to create and edit publish templates, which optionally can specify a publish template. The publish template is used during the publishing operation and defines the properties and security attributes for the published document. The publish style template defines the output format and various other rendering options, such PDF security and PDF watermarks.
2.2.8 Classification
The Content Engine provides an extensible framework that enables incoming documents of specified content types to be automatically assigned to a target document class and setting selected properties of that target class based on values that are found in the incoming document.
When a new document is created, a flag determines whether automatic classification is executed or not. If classification is enabled for the document, the Content Engine executes the following steps:
1. The classification is performed asynchronously by queuing a classification request (with the reference to the document). The Content Engine ensures that the classification requests are properly queued and that the status for the classification is set to “pending” for the document.
2. Within a transaction:
– The Document is handed to the Classification Manager, which determines the MimeType from the source document.
– The Classification Manager determines which Classifier must be invoked for the MimeType and passes control to the Classifier.
– The Classifier extracts the information from the document, performs a Change Class operation based on extracted information, updates the metadata accordingly, and passes back a status.
– The Classification Manager evaluates the status, sets the document’s classification status accordingly, and deletes the request from the queue. The Content Engine ships with one default auto classification module for XML documents.
In addition to the internal classification system, there are a number of add-on products that can assist in performing content classification. For more information, see Chapter 6, “Expansion products for Information Lifecycle Governance” on page 135.
2.2.9 Protocols
A Content Engine deployment might take advantage of several protocols. On the client-side, requests come into the client tier through the web service listener or the EJB listener. Although the web services listener communicates through HTTP only, the EJB listener communicates using the same protocol that the application server leverages for its EJB interactions (IIOP, for example). Workplace XT communicates to back-end Content Engine servers through the EJB protocol only. Custom clients can use either the EJB or WSI interfaces. IBM FileNet Enterprise Manager (the Content Engine administration client) uses the .NET API over the web services (HTTP) interface.
On the server-side, the Content Engine uses:
•JDBC to communicate with the relational database management system, including the database storage areas.
•NFS or CIFS to communicate with the file storage areas.
•Various protocols for the fixed content devices. For more information, see the third-party vendor-specific documentation.
•LDAP to communicate with the underlying directory service provider(s).
•Liquent rendition engine's proprietary protocol.
•Content Search protocol
2.2.10 APIs
The Content Engine offers two primary APIs: Java and .NET. The two APIs are almost identical and offer objects and methods to handle creating, retrieving, updating, and deleting objects, folders, and documents. In addition, the API offers methods for handling additional administrative tasks, such as updating security.
While the two APIs are almost identical, the Java API does offer the additional ability of being enlisted in a J2EE transaction and the ability to communicate over the native application server protocol, such as IIOP. However, the Java API can communicate over the web services transport just like the .NET API.
For additional information about developing with the Content Engine API, refer to Developing Applications with the IBM FileNet P8 APIs, SG24-7743.
2.2.11 CMIS
IBM FileNet P8 5.0 now offers support for the Content Management Interoperability Services (CMIS) standard. This standard includes both an object model and two bindings (a RESTful and a web service based binding). While the CMIS standard does not expose the complete capabilities of the Content Engine, it does provide a standard set of functionality across all compliant repositories. The IBM CMIS server's available functionality from the specification includes:
•Support for all CRUD (Create, Read, Update, Delete) operations on documents and folders
•Versioning (checkin, checkout)
•Filing operations for documents in folders
•Type (metadata discovery)
•A powerful SQL-92 based query language
2.3 Process Engine
The Process Engine provides the IBM FileNet P8 Platform with workflow management capabilities. These capabilities include personal inboxes, work object routing, group queues, process tracking, and process orchestration capabilities.
As of version 5.0, Process Engine is now a pure Java-based application that stores all workflow information (except the raw process maps that are stored in the Content Engine) in a database. To help facilitate logical separation between lines of business and applications, the Process Engine offers the ability to segregate workflow data into subdivisions of the repository called isolated regions.
2.3.1 Architecture
With the move to a Java-based implementation, the Process Engine was migrated to a single process, multi-threaded architecture. This move allows for better use of the operating system, its resources, and simplifying start up and shutdown routines.
Another benefit of the move to a single process and away from the shared memory model of the old implementation is the possibility of multi-tenancy within a Process Engine server. Now it is possible to have multiple instances of Process Engine fronting different process stores and running on the same system. There is no support for multiple server instances on the same system fronting the same Process Store. Also there is no support for a single Process Engine server instance that fronts multiple Process Stores.
The Process Engine has two kinds of processes: PEServer and PEManager. A running Process Engine Server instance is an instance of the PEServer process. It handles all database persistence, background tasks, daemon threads, and fields any RPC calls. The PEManager process runs as a single instance in a system. It is responsible for managing the Process Engine server instances including starting and stopping them.
A particular Process Engine is configured as a member of a given Content Engine domain and provides workflow management for any applications and users that need access to the data in that domain. A given Process Engine service can be leveraged by one or more Content Engine object stores for managing business processes that are associated with content in those repositories.
Figure 2-7 shows the Process Engine system architecture.
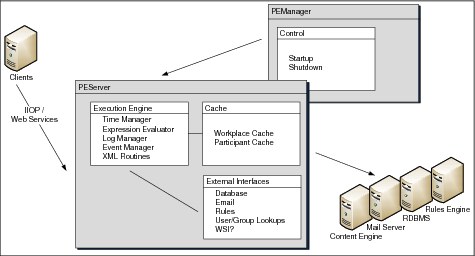
Figure 2-7 The Process Engine system architecture
2.3.2 Data model
Process Engine divides workflow data into work items in rosters and queues. Workflow data and transferred workflows are stored in a RDBMS. This database is either stand-alone or co-located with the Content Engine database. For Case Manager, the database must be co-located with the Content Engine database; otherwise, the database can be separate.
Isolated regions
The Process Engine allows process data to be segregated into smaller units within a single process store. This division is called an isolated region. An isolated region contains all of the related process definitions and metadata in separate tables within the Process Engine database. It also contains a unique set of rosters, queues, and work items.
Workflow definitions
Workflow definitions are made up of maps. Each map contains steps and routing logic. They are stored in the Content Engine, and are then transferred and compiled in the Process Engine. Built using Process Designer, described in section 2.5.2, “Process Engine” on page 54, the workflow map defines the steps, routing, and participants in a workflow.
Work items
When a workflow is launched, a new work item is created. A workflow instance can contain one or more work items. The work item does not contain any map or definition information. It has information, such as the current map and step ID. The work item contains the properties for the work item. These properties can be of the following types: Integer, String, Boolean, Float, Time, Attachment, and Participant.
An integral part of the handling process is often a piece or pieces of content. This content must be carried with the workflow so that the user or system acting on that step can view or retrieve the content in question. The work item contains a reference to one or more content objects through the use of attachments. In the context of a IBM FileNet P8 deployment, these attachments are references to objects within the Content Engine.
The metadata and attachment data is serialized and stored as a BLOB within the database. While all data is stored in the BLOB, Process Engine does offer a way to expose some of the data in a searchable format. See “Rosters” and “Queues” on page 43 for more information.
Rosters
After a workflow is instantiated, the data is available in a roster. The process map defines which roster a given process definition is associated with at design time.
The roster exposes a number of system-level fields, such as date created, and can expose selected properties from the work item to help speed finding work items. At runtime, when a work item is created or updated, the values in the exposed properties are copied into the database table.
A given Process Engine isolated region has at least one roster, the default roster. In addition, more rosters can be created to help segregate data and to improve performance. Each roster that is created results in a new table being created in the database and all work items assigned to that roster referenced in that table.
Rosters are used to query for objects regardless of where they are in their process flow, typically for administrative purposes.
Queues
While work items can be retrieved from the roster, it is important to offer a way for users or applications to find work items that are relevant to them. Process Engine offers an additional level of organization in the form of a process queue. A queue represents all of the running instances that are on a particular step (or related steps) within the work item. Where the roster represents objects that are based on their type of process, a queue represents objects that are based on the type of step they are on, at a particular point in time.
There are different types of queues:
•Process queues can be thought of as public queues where numerous users might have access and any of those users are allowed to browse and process work items from those queues on a first-come-first-served basis.
•User queues, in contrast, are associated with a particular user and only have work items that are specifically designated for that user to work.
•Component queues are a special kind of process queue that the Component Manager application uses for background processing of custom actions.
•System queues manage various system activities on work items.
In-baskets
In-baskets provide an additional way to display items from a queue, basically a view to a queue. This view can have one or more filters to apply business rule-based criteria to the items in the queue. These filters cannot be modified by the user, only by the process administrators. In addition to filters, in-baskets allow for the definition of columns or sets of attributes from the underlying queue. These columns are also made available to the user or application.
Roles
A role is used within Process Engine to tie a set of users and groups to one or more in-baskets. This provides an application developer or an application, such as widgets, a simple way to present users the in-baskets that are appropriate to their position with an organization.
Application spaces
Application spaces within the Process Engine provide a solution with a way to group together a number of roles that apply to that application or line of business.
Event Logs
Event logs are used to log event data for various activities that occur on work items within the Process Engine. Like rosters, there is a default event log and additional event logs can be configured. Process definitions can be associated with a given event log so that subsequent actions that occur on instances of those process definitions can be recorded. Event logs, like rosters, are separate tables within the Process Engine database. Each row represents an event action for a specific work item. Also like rosters (and queues), the metadata that is collected in these tables is defined by the columns that are configured for a given event log. The column name and type are matched with corresponding properties of a work item. For those that match, the data is copied from the work item.
The types of events that get logged are configurable and provide a fair degree of control over how much data is collected and what it represents. The event log table can be queried to retrieve data on historical events that occurred within the system. The Process Tracker application uses this data to show the history for a given work item. The event log tables are also the primary source of data for the analytics engine.
Figure 2-8 on page 45 shows some of the tables in the Process Engine database.

Figure 2-8 Process Engine database
Accessing work
Any given work item can be retrieved and examined through a variety of views. These views are roster element, queue element, step element, and work object:
•A roster element represents each of the data elements (columns) exposed for a given roster.
•A queue element represents each of the data elements (columns) that are exposed for a given queue.
•A step element represents each of the data elements defined for a given step in the process flow, which are defined at design time by specifying for any given step what fields are used. Step element data fields might be dynamic in the sense that the definition for a step might include an expression for the data element that is evaluated at runtime when generating the step element.
•A work object represents the data defined in the workflow definition. Each work object is a copy of the data. If a workflow instance contains multiple active work objects, each work object might contain different data.
Understanding this model is important for performance and scalability reasons. Roster and queue elements are generally the fastest and lightest-weight elements because they represent a subset of the overall metadata, and neither requires deserialization of the binary data to generate. Step elements usually offer the next best performance. They do require deserialization of the binary data but also often represent a small subset of the overall metadata. Work objects are the most expensive because they require deserialization of the binary data, and return all metadata associated with a given work item.
2.3.3 Access control
Security within the process system is not managed on individual work items but rather on the queues and rosters in which these items reside. User access to work items or portions of work items is controlled by the security rights that they have on the associated rosters and queues that those work items exist in. User queues are additionally enforced by giving access only to the user for which those work items were specifically assigned (based on the current step in the process flow). For more information about Process Engine security, see 8.2.2, “Process Engine” on page 210.
2.3.4 Process orchestration
The Process Engine can be either a provider or a consumer of web services. One mechanism for accomplishing this is through the process orchestration framework. Based on the orchestration portion of the BPEL specification, this framework, shown in Figure 2-9, provides a mechanism by which individual process steps can call out to an external web service or, conversely, be exposed as a web service for external consumption.

Figure 2-9 Process orchestration
There are three main actions involved: receive, reply, and invoke. The receive and reply steps define a point in the process to expose externally as a web services entry point and if necessary return a response. The invoke and receive steps call out to an external web service and if necessary receive a subsequent response. Figure 2-10 depicts the various interactions that are enabled through the process orchestration framework.

Figure 2-10 Process orchestration interaction
2.3.5 Component Integrator
The Process Engine also offers a service for integrating with external systems. The Component Integrator makes it possible to import custom Java components and make them available in a workflow. In the workflow definition, a component step connects to a component queue configured for one or more operations in the external component.
There are two parts to the Component Integrator:
•Component Manager: This service runs on the Workplace/Workplace XT and connects a work item with its appropriate Java or JMS Service Adaptor.
•Configuration: Configure the component queues using Process Configuration Console.
2.3.6 Analysis and optimization
As opposed to business activity monitoring, business analysis and optimization focuses on data that is gathered over a time in the past. The time span being analyzed might be days, weeks, or even years to analyze trends and draw conclusions.
IBM FileNet P8 Platform supplies the Case Analyzer tool to analyze business processes. Case Analyzer leverages Microsoft MS SQL Analysis Services to supply the data in a format that can be quickly explored and drilled down by users. The Process Simulator tool is also available to perform what-if simulations of the process model to discover bottlenecks in the process execution. Analysis and simulation aim for continuous improvement in the quality of the business processes. For this optimization, it is necessary that the process is executed on a BPM system to efficiently collect the matrix.
Data from the Process Engine event logs is fed on a schedule into a datamart database. This datamart stores the data in a special representation (snowflake/star schema) as opposed to the flat schema that is used by the event logs’ tables, for example. In a second step, the OLAP cubes are calculated from the current datamart information. There are basic OLAP cubes, which are provided during the installation of the Process Engine, and customers can define new cubes, if required. The configuration of the cubes is stored in the Microsoft SQL Analysis server. Figure 2-11 on page 49 outlines how data from the Process Engine event logs becomes available in the OLAP data cubes for further investigation.
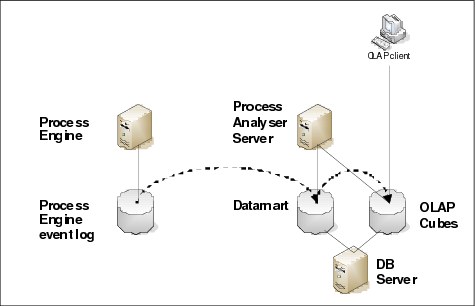
Figure 2-11 FileNet Process Analyzer data flow
The OLAP cubes can be inspected using an OLAP client, for example, IBM Cognos Business Intelligence or Microsoft Excel. Case Analyzer installs a number of predefined Microsoft Excel spreadsheets that use the base OLAP cubes to generate reports for information, such as process execution time, step completion time, queue load, and much more. Use the reports to perform a slice and dice analysis, which means that the data viewed is narrowed down further to see details, for example, a report might show the number of completed transactions over a time period, and then how the transaction value affected the processing time or how the transactions are distributed over different regions and if there are differences in the average transaction value for the regions. Assuming that these details are gathered from the event logs and are stored in the datamart, these analysis scenarios can be performed by just a few clicks.
Based on the results of the analysis, the Process Simulator (PS) can be used to determine which changes to the process definition must be applied to eliminate given inefficiencies or bottlenecks. To do so, the process definitions are reused, altered, and loaded it into the PS. For each simulation, a scenario is defined that consists of the process model, arrival times, work shifts for manual processing steps, and (optionally) costs. Arrival times can be defined manually or derived from the production Process Engine. The scenario is versioned in the Content Engine and handed over to the PS. The PS uses statistical methods for the arrival times and simulates the flow of the process instances on the workflow map. The PS provides basic measures for the simulated process, such as process execution times and costs. In case a deeper analysis of the simulation is desired, a Case Analyzer instance can be attached to the PS. In this configuration, it is possible to further analyze the simulation results with the Case Analyzer, as previously described.
The optimization of Content-centric processes is an important building block in the architecture of an ECM platform. Continuous optimization of the business processes is a critical asset for organizations to keep their competitive advantage even in changing business conditions. Leveraging the flexibility and the support of a wide range of standards of IBM FileNet P8 Platform allows enterprises to roll out solutions for their Content-centric processes that can easily be adjusted to changes in the way they perform their business, thus ensuring a low TCO compared to applications that are individually developed.
2.3.7 Rules framework
Rules Engine leverages industry standard web service as the communication mechanism for external application to invoke their business rules. With the Process Designer, the customer can author web service calls to the Rules Engine from the workflow. At run-time the workflow invokes the business rules as part of the process.
2.3.8 Protocols
There are a variety of protocols leveraged within a Process Engine deployment. Starting at the client tier, requests might come in through various out-of-the-box applications that make SOAP requests over HTTP to the Workplace or Workplace XT server. Custom applications that take advantage of the Java API communicate over IIOP to the Process Engine server. Lastly, there are a set of exposed web services that can be accessed through HTTP.
After it is in the server, the Process Engine uses the protocols:
•JDBC connectivity to the database
•Web services calls over HTTP to Content Engine to resolve users and groups
2.3.9 APIs
There are three primary APIs for the Process Engine, the Java API, the REST API, and the web services API. The Java API communicates with the Process Engine over IIOP.
The APIs provide classes and methods for the following functions:
•Creating, working, and completing workflow items
•Searching for work items in queues and rosters
•Viewing the event logs
The REST and web services API uses the Java API to communicate with the Process Engine.
For more information about the API, refer to Developing Applications with the IBM FileNet P8 APIs, SG24-7743.
2.4 Workplace and Workplace XT
Workplace and Workplace XT provide user interfaces that can immediately access Content Engine and Process Engine. These web applications are also a container for a number of additional add-on elements necessary for operation of an IBM FileNet P8 system.
Workplace is the official name for the Workplace web application, which is different than the Workplace XT web application. They both offer similar functionalities but have their differences. The preferred user interface is Workplace XT.
Workplace XT is a JSF-based application that provides a general folder-based view of an IBM FileNet P8 content repository. In addition to the content management functions, Workplace XT provides user interface for process management items, such as inboxes, public queues, and step processors. Finally, Workplace XT hosts a series of Java applets and wizards for basic application deployment, search definition, and UI component definition. For more information about Workplace and Workplace XT, see 3.1, “Workplace XT” on page 64 and 3.2, “Workplace” on page 67.
|
Note: Workplace can also host custom applications that use the Web Application Toolkit provided by Workplace only or the Content and Process APIs that are readily available.
|
|
Application Engine and Workplace naming convention: Application Engine is the official name for Workplace. Application Engine does not equate to Workplace XT. Both Workplace and Workplace XT support a common set of functions but differ in other areas. For consistency of the terminology used in the book, we use Workplace instead of Application Engine throughout the book.
|

Figure 2-12 Workplace/Workplace XT system architecture
2.4.1 Component Manager
The Component Manager is a Process Engine component that is hosted and managed within the Workplace/Workplace XT. The Component Manager provides an integration framework that enables the Process Engine to make calls on external components. These might be Java components, web services, or JMS queues, for example, the Component Manager includes a web services adaptor that handles outbound web services calls for the process orchestration framework. It also handles calls on custom Java components that can be registered within the system and called at explicit points in a process. The Component Manager also hosts the CEOperations component, which can be used for executing certain content-related operations against the Content Engine.
2.4.2 User preferences
User preferences are a collection of configuration settings that allow a user to modify various display and functional characteristics of Workplace or Workplace XT. Those preferences are stored within a user preference object in the Content Engine repository and retrieved at logon to customize the user experience.
2.5 Configuration tools
For each of the primary engines within an IBM FileNet P8 deployment, there are a number of configuration and management applications.
2.5.1 Content Engine
The Content Engine offers three primary configuration and management interfaces: Enterprise Manager, Administrative Console for Content Engine, and Configuration Manager.
IBM FileNet Enterprise Manager
IBM FileNet Enterprise Manager is the configuration and administration tool for Content Engine. IBM FileNet Enterprise Manager is a Microsoft Windows® application built using the .NET API and communicates with the Content Engine using the web services interface. IBM FileNet Enterprise Manager supports the following actions:
•Configuring all aspects of the domain and underlying object stores.
•Defining custom metadata, such as classes, properties, templates, subscriptions, and event actions.
•Assigning many aspects of security access rights.
•Searching for and administering instances of documents, folders, and custom objects.
IBM Administrative Console for Content Engine
Finally, in IBM FileNet P8 5.0 there is a new web-based domain administration system, the IBM Administrative Console for Content Engine (ACCE). The ACCE offers a subset of the domain administrative tools, including:
•Initial domain configuration
•Object store creation and security management
•Work with PE connection points
•Trace control and logging management
•Review of Content Engine system health metrics
IBM Configuration Manager
The IBM Configuration Manager is designed to help with common setup and configuration tasks. These tasks include configuring the underlying application server JDBC data sources and providers, creating a new Content Engine domain, and creating of new object stores.
2.5.2 Process Engine
There are many tools that the Process Engine provides for designing processes, administering process instances, configuring the data model, administering the server functions, and doing low level analysis of various server activities.
•Process Designer provides the general process design capabilities where users (typical business and IT analysts) define their process flows. The Process Designer can read and write proprietary format (PEP) and XPDL 2.x workflow maps. In addition, Process Designer can import Visio documents, mapping shapes to native objects. A provided Visio template provides BPMN shapes.
•Process Administrator lets an administrative user query the system for process instances and view the current state of those instances.
•Process Tracker can be launched to view the current and historical state of an individual process instance.
•Process Configuration Console defines the rosters, queues, event logs, and various other system-related components.
•Process Task Manager can be used to start and stop the various server components, including the server itself.
•There are a series of lower-level tools on the server, such as vwtool and vwlog, that can be used for viewing detailed information about server state and activities that occur there.
2.5.3 P8 Platform tools
The IBM FileNet P8 Platform also includes a couple of cross-engine tools for configuration and deployment. These tools include the IBM FileNet Deployment Manager and IBM FileNet System Dashboard.
IBM FileNet Deployment Manager
The IBM FileNet Deployment Manager is a tool that moves content and processes solutions from one environment to another. In a typical environment, all development and testing occur on different environments than the production. This setup allows for sandboxing development and ensuring changes are properly tested before bringing them live in production.
To help simplify the movement of classes, properties, and workflows between, the Deployment Manager takes a set of objects from the source system, compares them to the target system, and either creates or updates the target system with the changes.
IBM System Dashboard for Enterprise Content Management
The IBM System Dashboard for Enterprise Content Management provides a number of system management and performance reporting tools for the various engines in the IBM FileNet P8 Platform. The System Dashboard can gather and display information, such as:
•Operating system information and performance data
•IBM FileNet-specific data, such as RPC counts, Content Engine operations, and other engine specific counters
•Environmental data including Java runtime versions and memory settings
In addition to gathering the counter and system information, the System Dashboard provides the ability to create user-defined charts, export data for historical analysis, display alerts and urgent messages from applications, and provides listener agents for gathering data from other applications.
2.6 Case Manager
IBM Case Manager, new for IBM FileNet P8 5.0, is a platform for case management that is built into the IBM FileNet P8 Platform. Case Manager is a more flexible solution for solving business problems. Through a combination of a widget- and Web-based UI, a flexible task-based environment, and comprehensive case-based data model, Case Manager enables users to more flexibly complete their business goals.
Case Manager offers a different approach to solving problems by enabling a wider range of groups within an organization to assist in creating the solution. Instead of just relying on developers to build the solution, Case Manager functionality and user interfaces allow business analysts a greater role in helping define the types of problems being solved and how they are solved within an IBM FileNet P8 solution. With that in mind, Case Manager and is designed to be:
•A platform for designing and building case solutions
•A run time environment for launching, processing, and interacting with cases
•A set of tools for configuring and moving solutions into production environments
•A set of APIs and templates for customizing case solutions
In addition to being built on the core platform, Case Manager also offers a native case object model built into P8 Platform. This object model is extensible and allows for defining the various elements of a case and how they are to be handled. See 2.6.1, “Data model” on page 57 for more details about the Case Manager data model.
To help facilitate rapid deployment of solutions, Case Manager comes with a widget and web-based user interface for both design and runtime use. Case Manager also offers a REST-based API for building custom solutions that go beyond the functionality offered by the user interfaces that are readily available.
Case Manager also offers deep integration with the following components:
•WebSphere Integration Developer 7 Feature Pack 2 which enables integrating WebSphere Process Server components and processes with case management tasks.
•Content Analytics 2.2 (Full Text Unstructured Analytics)
•Cognos Real Time Monitoring 10.1 (Active Analytics)
•Cognos BI 10.1 (Historical Analytics)
•Lotus Sametime® 8.5.1 (embedded awareness in case runtime and web chat)
Figure 2-13 on page 57 shows the architecture of Case Manager.
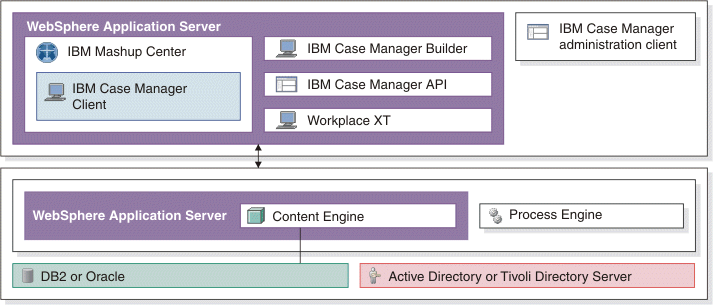
Figure 2-13 Case Manager architecture
2.6.1 Data model
From a high-level standpoint, Case Manager uses a solution-based data model. The solution defines the task to be completed using the following items: case types, roles, pages, in-baskets, and document types. These items are implemented as a single Process Engine isolated region and application space and one or more Content Engine object stores.
Roles/In-baskets
A role represents a specific business function, for example, a role might be an Applicant or a Supervisor. Users are assigned to roles, and roles allow users to access a particular task.
Roles are defined within a solution and are associate roles with tasks. The Case Manager Client assigns users and groups to roles which specifies which users can access a particular task or step. Roles can be reused across all case types within the solution.
Case types
Case types define the tasks, the necessary document types to support the task, the task steps, and the roles that must complete those steps to solve a business problem. The case type also includes properties that are displayed to case workers in views in the Case Manager Client. Related case types make up a solution. A case is an instance of a case type.
Tasks
A case contains tasks. A task has one or more steps that must be completed to complete the task, for example, a task might be to review new hire applications. A case is not complete until all required tasks are completed or manually disabled. Each task has roles that are associated with it.
A task can be implemented either as a Case Builder workflow or a WebSphere component or process. Case builder tasks are implemented as a Process Engine workflow and can be round-tripped between the Case Builder and the Process Designer. For WebSphere components, it must be an empty task in Case Builder, and must be implemented using the WebSphere Integration Developer (WID).
Tasks have states to indicate where the task is in the process of completion. These states are defined as waiting, ready, working, complete, and failed, as shown in Figure 2-14.

Figure 2-14 Task state transition and flow
Cases
Within Case Manager, a case is defined as a collection of tasks and supporting material. A case is complete when all required tasks are completed. Within the Content Engine, a case is represented as a folder. This folder contains the supporting material and objects.
Content Engine elements
A Case Manager implementation is defined by two object stores within the Content Engine: a design object store and a target object store.
Design object store
The design object store is where Case Manager stores configuration data, such as mashup layouts, pages, and solution templates. Within the design object store, each case solution is represented by a set of files, the “solution package” including the solution definition file (SDF), configuration XML files, and workflow definitions.
Finally, within Case Manager and IBM FileNet P8 domain, there is only one design object store. The Case Builder UI only reads and writes from the design object store, and the object store is configured using the Case Manager Administration Client.
Target object store
While the design object store holds the configuration, it is the target object store that actually holds the deployed solution. It is also the target object store that the case workers interact with and where case instances are stored.
The target object store can be a new or existing object store and can have one or more solutions deployed to it. A Case Manager deployment in an IBM FileNet P8 domain can support multiple target object stores. At deployment time, the CMAC uses the solution configuration to generate all required artifacts in the underlying object stores and isolated regions, including classes, folders, and workflow instances.
2.6.2 User interface
Case Manager ships with three primary user interfaces: Case Builder, Case Manager Client, and Case Manager Administration Client.
Case Builder
The case builder is the primary tool for building a case-based solution, which it does by providing tools for creating case types, defining tasks, and building pages. The Case Builder is designed so that a business analyst can build the solution using the web-based application. The Case Builder also allows the analyst to deploy the solution to a development or test environment for rapid prototyping and testing.
After a solution is deployed to the test environment, the analyst can then work sample cases and tests in a sandboxed testing area using the Case Manager Client. The solution can be returned to the Case Builder for additional refinement as necessary.
After a solution is refined and is ready to be deployed, the analyst then works with the administrators to deploy the complete solution to the production environment. This deployment occurs using the Case Manager Administration Client.
Case Manager Client
While the Case Builder is used by business analysts to define case types, the Case Manager Client is the primary user interface for case workers to process case assignments. The Case Manager Client is a widget and web-based application. Because it is widget based, it is possible to include additional functionality as part of the solution without necessarily needing to develop a custom application or user interface.
The Case Manager Client is divided into three default spaces: the solution space, step pages space, and the case pages space. These spaces all include a set of widgets that can be used directly. The spaces can also be rearranged to use custom built and other vendor’s widgets.
Solution space
The Solution space is a mashup space that case workers use for interacting with a solution. It is the main IBM Case Manager space and contains two pages:
•Work page, with the In-baskets and Toolbar widgets
•Cases page, with the Case Search-related widgets
Step pages space
The step pages space is a mashup space that includes step pages that display when a case worker opens a work item. The step pages space contains three pages:
•Add task page for adding a new task for the case.
•Work details page for working on a work item.
•Work details eForm page for working on a form-based work item.
Case pages space
The case pages space is a mashup space that includes pages that display when a case worker opens a case to view its details or add a case. There are two types of case pages: those used to create a case, and those used to open and view the details of an existing case. The case pages space is divided into two sections, the case toolbar widget and the case information widget.
Case Manager Administration Client
The Case Manager Administration Client is similar to the P8 Configuration Client in that it bootstraps the various components (Case Builder, Integration Tier, and Widgets) and helps deploy them to WebSphere Application Server. The Case Manager Administration Client:
•Builds Case Builder, widgets, and P8 WebSphere Application Server “trust” (LTPA Key)
•Creates connection profiles
•Used to deploy a solution to production
•Configures Lotus Mashup spaces and pages
•Registers default solution space and case detail and work item pages in the design object store
•Used to test or “visualize” a solution without requiring the Business Analyst to create spaces or pages
Pages are discoverable from Case Builder and can be associated with a solution at design time.
2.6.3 API
Combined with the existing IBM FileNet P8 APIs, Case Manager offers an API that provides full access to case content and process. The APIs are REST-based and allow for dynamic case manipulation and creation. The API can be used to create and assign new case activities on the fly and manipulate the native case object model.
2.6.4 Case templating
The Case Manager solution also offers the ability to package a solution into a template. This allows customers and third parties to solve a specific case management problem and then package the solution into a reusable template. These templates can include:
•Industry vertical sample templates
•Pre-defined process as well as dynamic activity creation and assignment
•Run-time collaboration
•Cross-case analysis and reporting
2.6.5 WebSphere Process Server integration
Case Manager also offers strong links into the WebSphere Process Server. These links allow a Case Manager workflow to initiate or be part of a WebSphere Process Server workflow. This integration allows for leveraging existing WebSphere Process Server workflows and connections with other systems. It also allows for the addition of case management functionality to WebSphere Process Server workflows.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.