


Expansion products for content ingestion
IBM FileNet P8 provides a number of major expansion products that extend enterprise content management functionality beyond the core platform. Expansion products implement critical features to ingest, organize, and access content, connect information, and users expediently and support discovery and compliance while giving greater insight into critical business trends. This chapter provides an overview of the major expansion products for the P8 Platform and then focus specifically on the content-ingestion related expansion products. Other key expansion products are discussed in other chapters.
This chapter covers the following topics:
4.1 Expansion product overview
IBM FileNet P8 expansion products facilitate getting content into IBM FileNet P8, accessing content outside of IBM FileNet P8, and organizing and controlling that information. They complete the full life cycle of content from creation to storage, through usage, and finally to decommissioning. This ability to utilize existing assets in new and insightful solutions is critical for enterprise-level content management.
Expansion products covered in this book are categorized as:
•Content ingestion products:
•Connection and federation products:
•Information Lifecycle Governance products:
In Chapter 4, “Expansion products for content ingestion” on page 91, content ingestion products are covered. Content ingestion solutions take paper, faxes, e-mails, and other forms of information, organize it, and insert it into IBM FileNet P8.
In Chapter 5, “Expansion products for connection and federation” on page 117, connectors and federation products are covered. Federation products use content that is already available in other repositories and locations and make it accessible and relevant. Connectors expose this information into a variety of user interfaces. Together, they increase the value of corporate assets and activate the information to participate in business processes.
In Chapter 6, “Expansion products for Information Lifecycle Governance” on page 135, Information Life Governance products are covered. It is necessary to secure, maintain, preserve, and retain the content in a useful and controlled manner. Legal requirements for document life cycles and discovery drive IBM FileNet P8 expansion products in records management and search and discovery. They expand document usefulness by annotating and classifying them for reuse. Search, classification, and discovery products organize and harvest this information.
The remaining portion of this chapter focuses on content ingestion products.
|
Note: Cognos Realtime Monitoring (formerly known as Cognos Now! and IBM FileNet Business Activity Monitor) is not covered in this book. See the www.ibm.com web site for support and architectural information.
|
4.2 Content ingestion products overview
Content ingestion products provide a solution to pull in documents from file systems, email servers, incoming faxes and images, and paper sources into IBM FileNet P8 systems. In addition to bringing existing content under control, they continue to get unexpected content under control through ongoing policy-based capture. These products not only collect this information and centralize them in the IBM FileNet P8 Platform, they also provide an abundance of other functionality.
Three key expansion products that focus on content ingestion are:
•IBM Content Collector: Expands and consolidates the previous functionality of IBM CommonStore, IBM FileNet Email Manager, IBM FileNet Records Crawler, IBM FileNet connectors for SharePoint Libraries, and IBM FileNet Application Connector for SAP R/3 (ACSAP) into a flexible software solution that collects, enhances, and manages content from Microsoft SharePoint, SAP, file shares, and email servers.
•IBM Datacap products: New to the IBM portfolio, Datacap quickly and easily captures, manages, and integrates enterprise content while extracting critical content. Datacap's offerings include easy to use customization with high-volume document capture.
•IBM FileNet Capture Professional and Advanced Document Recognition (ADR): Capture and Capture ADR are veteran products in the IBM FileNet portfolio for document capture functionality that fulfills enterprise requirements.
With these products, organizations can quickly and automatically gain control over their content. Businesses can get the right information to the right people faster with content ingestion expansion products.
4.3 IBM Content Collector
IBM Content Collector enables organizations to unlock the business value of content. Instead of merely archiving content, Content Collector breaks down silos of information by gathering and controlling it automatically. Corporations can transparently enforce compliance and operational policies while lowering the total cost of ownership. Business requirements are easily addressed with central administration, while classification and metadata makes the information more useful and reusable. Content Collector can start processes and workflows as documents are incorporated into the system. Content Collector collects, enhances, and manages content, making assets an active part in business processes.
Content Collector consists of four offerings:
•Content Collector for Email
•Content Collector for File Systems
•Content Collector for Microsoft SharePoint
•Content Collector for SAP Applications
These offerings are in the IBM ECM Content Collection and Archiving strategy line of products. Content Collector addresses four main use cases: management for compliance purposes, management for storage purposes, integration with business processes, or simply collection for eDiscovery. It is tightly integrated into the IBM FileNet P8 Platform, which simplifies and automates the process of collecting, enhancing, and managing content.
Content Collector retrieves content from these sources and applies rules to decide if and how it is processed and where they are stored. In the process, they can be classified and indexed, mined for information, removed or replaced with links to the object store, de-duplicated, and declared as records.
Although a fully detailed description of Content Collector cannot be included in this book, this section highlights those features and information related to FileNet P8 integration. Three of the offerings (Email, File Systems, and SharePoint) are almost identical in their behavior except for the source of the content and are discussed together in 4.3.1, “Overview: Email, File Systems, and SharePoint” on page 94. Differences between them are highlighted when appropriate. Content Collector for SAP Applications is covered in 4.3.2, “Content Collector for SAP applications” on page 99.
4.3.1 Overview: Email, File Systems, and SharePoint
Content Collector for Email, File Systems, and SharePoint is configured through its main application, the Content Collector Configuration Manager. This single administrative interface is used to develop and implement content collection plans and specifications. In this application, sources and destinations are identified, collections scheduled, and management and enhancement functionality specified. The following sections contain some of the terms common to this application.
Connectors
Connectors specify the source of the information to be collected and are available based on the offering installed and can include email, files, and SharePoint content. Some connectors are used for configuration for location, connection, and logging configuration for Email, File Systems, and SharePoint. There are utility connectors for functionality, such as metadata and text extraction too. A connector can specify a source, a target, or a utility.
Source connectors retrieve content and metadata but can also set metadata on source content, enabling it to stub email, for instance, or mark content as collected.
Source connectors include services for:
•Lotus Domino®
•Microsoft Exchange
•File Systems
•SharePoint
•and other connectors
Targets might have various search and metadata capabilities, and Content Collector exposes these features where possible in the Configuration Manager.
Target connectors include support for:
•Image Services
•FileNet P8
•IBM Content Manager
•File Systems
A single Content Collector server can connect to multiple types of sources. All of these services use the same APIs as part of the modular architecture.
Task connectors include:
•Classification
•Text Extraction
•Records Declaration
File Systems
Content Collector for File Systems collects files from any file system that can be mapped to a Microsoft Windows file system. In the newest version, users are no longer required to logon to ECM client applications to view stubbed documents
Email
Email is archived in a format that supports legal discovery, storage management, and duplication management. The email connector supports such features as connecting to the source system, collecting the email documents, and even a life cycle for managing the document stubbing policies. The connector also supports a flexible set of collection targets including individual mailboxes or users, all mailboxes in a group, PST files, and even local Lotus Notes® NSF archive databases.
SharePoint
The Microsoft SharePoint connector allows organizations to collect and manage content from SharePoint document libraries, picture libraries, blog libraries, and wiki libraries. As the content is collected it can be classified, organized, and even managed as important business records. The SharePoint connector can be configured to collect content from individual sites or all content from all sites in a site collection. The connector can also further filter content out by specific folder paths or by content type.
Content classification
IBM Content Collector also supports an integration with IBM Classification Module. This integration allows organizations to analyze the full textual content of a document to make more intelligent collection decisions. This integration can be used to determine how to classify the data, what type of record to declare, and can even extract additional metadata from the full text of the document.
Records declaration
In addition to utilizing Classification Module to classify the collected content, Content Collector integrates with IBM Enterprise Records to support automatic declaration of email and files as records during the content capture process, which protects assets automatically and preserves them for future use.
Content Collector Configuration Manager
Content Collector provides a Configuration Manager for all Content Collector administration, including designing task routes. The Content Collector Configuration Manager is also the administration interface for all configuration that is required for the Content Collector Task Routing Engine. Other administrative tasks for repositories are managed using their respective administration tools.
Task routes
A task route is like a workflow, a visual representation of the process for content (such as emails, attachments, or files) in the system. Task routes specify how and where the content is collected and processed within the system. It begins with collection and ends with storage in the repository. Task routes apply rules at multiple points in the capture process. Decision points allow conditional processing of content using rules with potentially different outcomes for each decision. Processing assets can include extracting metadata, classification, extracting content, de-duplication, and records declaration. Figure 4-1 shows a sample task route.
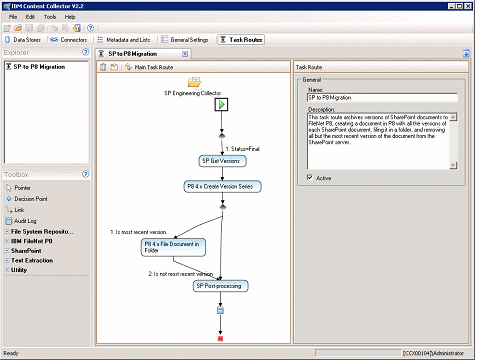
Figure 4-1 Content Collector Configuration Manager with a sample task route
Connectors and task routes are the building blocks for consolidating content and breaking down information silos.
System health statistics
Key operations statistics are available for task, target, and source connectors and include documents processed, archived, and errors. This data can be viewed in Windows Performance Monitor, IBM System Director, and other tools.
Retention Manager and Set Expiration task
The Retention Manager sweeps expired documents out of the repository, if they have no other holds placed on them. The Set Expiration task is used in task routes to set this field.
Content Collector Web application
The Content Collector Web application is used for viewing emails and searching emails in a web browser. The actions can be triggered directly from the users' email clients and the email authentication controls security. Workplace XT can use the email viewer application too.
In this web application, the user searches against their collection and can preview the results. Search texts are highlighted in the results window. Figure 4-2 shows the user interface for the email search Web application.

Figure 4-2 Content Collector email search Web application
Application integration
Content Collector can be integrated into Lotus Notes, Lotus iNotes®, Microsoft Outlook, and Microsoft Outlook web clients. The optional outlook extension for Microsoft Outlook and Lotus Notes template modifications are available and can be installed on users' desktop computers.
4.3.2 Content Collector for SAP applications
Content Collector for SAP has a specific architecture that enhances the SAP business infrastructure with archival and portability support. SAP systems tend to produce significant volumes of data, and Content Collector for SAP archives these assets efficiently. Documents are still accessible by SAP while reducing storage costs, increasing productivity, and improving system performance.
Content Collector for SAP enables retention periods and holds on archived SAP transactions, automating compliance with regulatory and legal requirements. It includes components to archive and view data, documents, and print lists, and to link to archived documents. Multiple SAP servers can be accessed, and Image Services documents can also be utilized through FileNet P8 when CFS is installed.
Architecture
Figure 4-3 shows the Collector Server interfacing between SAP and the repositories. Three clients—the Viewing, Archiving, and Utility Clients—provide the ability to see, share, link, archive, and preserve indexing of content.
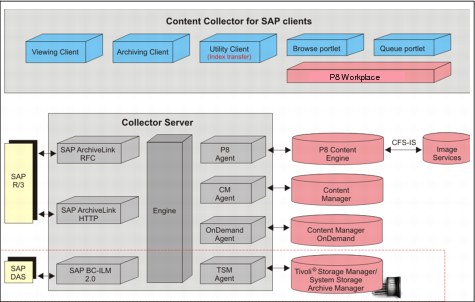
Figure 4-3 Content Collector for SAP architecture
Archiving Client
The Archiving Client is Windows based and is used to archive scanned documents. It can take documents from file systems, scanning application description files, and IBM Content Management work lists.
It supports early, simultaneous, and late (with barcode) archiving scenarios into FileNet repositories. In Early Archiving, a document is captured into a FileNet repository and made available for linking before the associated SAP business object is created. It is also the first stage of any incoming document scenario where the document is processed using SAP Business Workflow.
In Simultaneous Archiving, all document entry and SAP object processing steps are carried out by the same SAP user. Overall the process is the same as in Early Archiving except that the SAP work object, which is created at link time, is assigned to the current user.
In Late Archiving, the creation and processing of the SAP business object comes first and linking to the corresponding supporting document happens later in the process. In practical terms, this process is like a traditional paper-based process. This process can include bar code linking.
Viewing Client
The Viewing Client, also a Windows-based application, opens an external viewer for the SAP request. Users can add notes and save and share them with the document. Documents can also be emailed along with any attached notes.
Utility Client
The Utility Client can also link documents by creating a work item in an SAP workflow or by sending barcodes. It provides index transfers, which becomes metadata on the document in FileNet and searchable. FileNet documents, folders, search templates, and searches can all be linked to SAP. The Utility Client links all documents in a P8 queue. The P8 Client portlet allows selection of specific documents and versions.
P8 Client: Browse and queue portlets
The Browse portlet in P8 Workplace and Workplace XT enables linking to specific documents, stored searches templates, and entire folders. It also specifies the desired version, which creates a work item in the SAP Inbox.
The Queue portlet links documents available in a P8 queue like the Utility Client does. The work item is moved from the P8 to the SAP Inbox. For both, the user can specify which inbound linking process to use. The P8 client also supports mass archiving.
4.3.3 Content Collector summary
Content Collector products enable organizations to take back control and unlock business value of content while enforcing compliance and operational policies and lowering the total cost of ownership. With automation and centralized administration, compliance requirements become easy to address. Using classification and metadata makes the information more useful, and reusable, which enables businesses to extract more information out of their content. Content Collector can start processes and workflows as email, and files are incorporated into the system.
Content Collector provides a modular, extensible architecture for collecting content from multiple sources and applying flexible rules to the disposition of the content. The assets become organized, useful, enhanced, and managed. Businesses reap the benefits of IBM FileNet P8 rapidly, providing increased organizational agility, lowered costs, and better compliance.
4.4 IBM Datacap
Datacap is one of the IBM new acquisitions, and completes the end-to-end document management solution. Datacap's document capture and integration products help green initiatives by reducing paper requirements. Datacap captures, manages, and automates business information, and then integrates it tightly with the p8 platform, creating streamlined enterprise solutions.
4.4.1 Introduction to Datacap
The Datacap product line consists of three main products:
•Taskmaster
Taskmaster is an SOA capture and automation solution with both web and thick clients. It is a document ingestion product.
•Rulerunner
The Rulerunner service is a core differentiator for Datacap products and is embedded in Taskmaster and FastDoc. It can also run decoupled and can run as a web service. Easily extensible, it drives business rules and actions which make Datacap solutions so flexible and powerful.
•FastDoc Capture
FastDoc Capture is a stand-alone product that integrates out of the box with file systems and SharePoint. It can also be operated offline. It is a document ingestion product.
Building on these core products, Datacap also offers a number of industry specific and technology specific solutions. These are discussed briefly in the products section in this chapter.
4.4.2 IBM Datacap Capture process overview
The Datacap capture process, shown in Figure 4-4, follows four main stages, although it is easily customized to follow any flow required for business solutions. These stages: scan, recognize, verify, and export cover the process of getting images, cleaning them up, mining them for information and data correction, and placing them in appropriate repositories for further use. The Rulerunner Service passes batches of images from state to state according to the business rules configured.
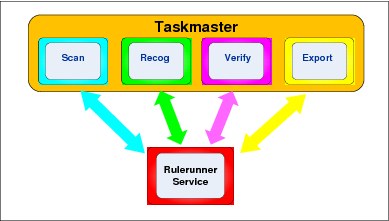
Figure 4-4 Datacap Capture process
Scan stage
The scan stage creates batch images to be processed. These images can be from a scanner, file folder, or other location. This might also include identifying the beginning and end of documents and adjusting orientation, but these might also occur in Validation.
Recognize stage
In validation, documents are processed as much as it is possible to do so automatically. Batches are separated into documents, if necessary and the batch, document, and page information are saved. Documents are scanned for all information, which is stored in a related file. This unique process means that all of the recognized text is available to users and processes in later stages, even if they were not initially identified as important. Documents are also identified according to type using fingerprints, which is an image file with associated data used to identify documents. Think of it like a fuzzy outline of a document's shape.
Within the document, fields for that document type are located by zone or by keyword. Barcodes, check marks, handwriting, and voting type information is also located. This information is also saved. Additional processing, such as data lookups, formatting and range validation, and other logic, can occur during this step.
There are two ways to define the location of index fields: with keywords or by Zone:
•Zone: Indicates where FastDoc Capture must look for the index value on the page. After that particular image is exported successfully, FastDoc Capture saves a fingerprint and automatically recognizes the image and the fields the next time.
•Keywords: Defines labels (sets of recognized characters or barcodes) FastDoc Capture will search for on the image, and define the position of the index value relative to that label.
Verify stage
If documents in a batch require a user's assessment and correction, those documents proceed to the Verify stage. In this stage, the user is presented with the image along with the fields and with snippets of the image as recognized in the previous stage. Users can update data and re-run validation and business logic, run other business rules, and do any final processing required.
Ideally, the Verify step leaves few, or no, images left and only uses human intervention when necessary.
Export stage
In the final stage, export tasks are performed. This stage formats and exports images and related data to p8 or other repositories.
4.4.3 Architecture
Figure 4-5 on page 104 shows a variety of ways that Datacap can support data capture and processing. Images can come in through email, fax, traditional scanners, and multi function devices (MFD). These images can enter the system through the Taskmaster web client, the thick client, directly using email and fax servers, and through network folders.
The Taskmaster server is the core server, handing out tasks with batches of images to Rulerunner stations to process. The Taskmaster Web Server hosts the web site and manages information from Taskmaster.The IBM Datacap Taskmaster Capture RV2 web application displays information about the current status of batches and other relevant activities.
After processing is complete, the images are stored along with the information gathered and generated in line of business systems, databases, and repositories such as FileNet P8.
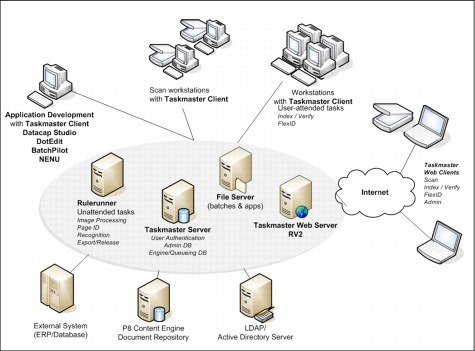
Figure 4-5 Datacap solution architecture
4.4.4 Components of the Datacap Taskmaster Capture solution
Figure 4-5 shows several key components that form the core Datacap Taskmaster Capture solution:
•Taskmaster Clients: Both thick and web clients provide the user interface. Typically this is used for validation and scanning interaction.
•Taskmaster Server: Includes authentication and permissions functionality and manages the queue of batches and jobs.
•Taskmaster Web Server: Serves pages and handles requests for web clients. The Taskmaster Web Server is only needed if the web clients are in use or if the RV2 report generator is being used.
•Rulerunner Service: Performs the actions specified on the objects provided. Its service-oriented architecture (SOA) enables it to be used by other applications. For instance, FileNet's workflows can call into the Rulerunner service to perform various recognition actions on documents already in the repository.
•Datacap Studio: Thick client tool that is used to configure objects, variables, the recognition to be used for documents and fields, and to define and configure actions to perform during processing.
Other components include tools to configure display screens and forms, manage fingerprints, and other useful functionality. The FastDoc Capture solution encapsulates the functionality of the clients, server, web server, and Rulerunner in one client.
Rules
Rules make Datacap’s data processing superior because of their flexibility and reusability. Rules are code snippets that can be combined and extended easily. Users can quickly make changes and improvements because the rules are configured, rather than coded. These rules contain decades of user experience and cover a wide range of requirements and scenarios, making application creation easy. Rulesets can easily be extended in VBScript, .Net, and other languages and scripts.
A rule is typically several rulesets of several fairly simple actions, such as opening a connection to a database, performing a lookup, and then setting a field to that value. Rules perform recognition, image processing, verification, export and most other operations required by the application.
Task Profiles and jobs
Jobs are like steps in a workflow, and Task Profiles are which rules are performed during that job and in what order. An example job might be Validate, and one of the tasks Validate performs is Recognition, which applies a series of rules for cleaning up images and then running OCR on them.
Rulerunner takes a batch and applies the task profile requested on that batch. Each Rulerunner server runs a copy of the SOA rules engine, is configured for that tasks it will process, such as export or verification, and executes the set of business rules given to it according to its profile. Typically Rulerunner servers are allocated separate tasks to address load balancing. The tasks are typically split when machine types that work on that task are different, for instance, scanning is separate from profiling because profiling can run in the background.
Datacap objects
Datacap object information is stored in a batch Datacap document hierarchy (DCO), which is the document hierarchy. This is a key differentiator for the IT staff that is in charge of configuration because this information is clear, easy to understand, and manageable in several consistent places in the user interface (UI). The DCO contains information about batches, documents, pages, and fields. Figure 4-6 shows how the hierarchy fits together.

Figure 4-6 Datacap document hierarchy
Rulerunner services process rules based on the information about batches and rules. The rules are processed as defined by customized workflows in order from the batch all the way down to the fields.
4.4.5 Products and applications
Rulerunner is available as a separate product. Both Taskmaster and FastDoc Capture contain Rulerunner. FastDoc offers a rapid on-ramp for smaller or stand-alone installations, and Taskmaster offers larger enterprise-scale capabilities.
IBM Datacap FastDoc Capture
FastDoc Capture is a stand-alone thick client user interface to a Datacap Capture solution. It is used to scan, recognize, validate, verify, and export batches of images and documents offline or online and can export to files or to SharePoint natively.
FastDoc Capture has a single, intuitive interface for all activities. Administration and operation all occur within this one application. Its streamlined configuration accelerates time to production without complicated templates or programming. Automatic data recognition frees operators to focus on key issues rather than constant keying of data.
FastDoc Capture includes both user and administrative capabilities. An administrative login uses it to configure document recognition.
Administrator mode is used to:
•Set up Document Types and fields.
•Zone specific fields on the Document Type. These zones provide the Recognition file with information about the location of the zoned fields.
•Assign Keyword located fields.
•Create field validation rules.
•Set field export configuration.
•Set document export configuration.
•Perform all user capabilities.
Operator (user) mode is used to:
•Select batch sources (printers, file shares, and so on)
•Set up batches of images
•Define, order, and separate images in a batch
•Validate or correct document type classification
•Validate or correct recognized field data
4.4.6 IBM Datacap Taskmaster Capture
Datacap Taskmaster Capture uses thick and web clients to communicate with the Taskmaster Server or the Taskmaster Web server respectively. This offering has much richer functionality and comes with a variety of tools that are used to configure user interfaces, objects, and rules. There are two foundation applications built on Taskmaster Capture that are often used as base applications for creating customized solutions, saving organizations development time and harnessing Datacap's extensive experience.
Taskmaster Accounts Payable Technology
The Accounts Payable Technology (APT) application was developed for invoice processing, but its key strength is in finding data on highly variable forms. It excels at finding data that is similar from form-to-form, such as addresses or totals, whose locations move from form-to-form. Basic and advanced invoice form processing is included in this application to remove manual entry. Invoice information can also be captured using Click and Key, where information recognized on the form can be selected by a click to speed processing. Line items are recognized and processed regardless of the shape of the form.
Taskmaster for medical claims
This application handles United States (US) medical forms and exports it in a HIPAA-Compliant EDI stream. Professional claim forms (CMS 1500) and institutional claim forms (UB04) which are used extensively by doctors, hospitals, and insurance agencies, are pre-configured.
Sample applications
Datacap also provides sample applications that are useful as a base for creating custom solutions. This feature includes tax forms, handwriting recognition, surveys, and database-driven indexing.
4.4.7 Dependencies
Datacap solutions operate on Windows operating systems and can use Microsoft SQL server or Oracle databases for a back end. Although Datacap has a built in authentication, it can also integrate with Windows Active Directory. It supports both ISIS and TWAIN drivers; however, the scanner interfaces are not included. At the time of writing this book, English is the only supported user interface language.
4.4.8 Connection and integration points
Datacap can obtain images directly through scanners, from monitoring network drives and through controlling scanners using user interfaces. Although a full discussion of input and output image formats is contained in the product documentation, it is useful to note that it supports natively or with conversion TIFF, JPG, PDF, and some PNG formats. It exports to TIFF, JPG, PDF, PDF/A, and PNG formats.
Additionally, Datacap can interface with virtually any business application or data store through the included or customized rules and actions. Database and web services actions are often provided by Datacap. The integration with FileNet is through actions that the user needs merely to customize with specific logon information for their data store. The FileNet actions include the ability to set document type, location, and metadata.
In turn, FileNet can invoke Rulerunner as an SOA service. In this manner, document processing and other business rules can be embedded in a business process, for instance, images added to an ad hoc process can have OCR applied, barcodes scanned, and that information used to link or drive other documents and processes.
4.4.9 Datacap summary
Datacap Capture products integrate seamlessly with FileNet processes and content management. Using Datacap to ingest products helps organizations to organize content, harvest data, and control documents. Businesses streamline and accelerate the flow of information by obtaining it from the point of origin.
4.5 IBM FileNet Capture
IBM FileNet enables ingesting paper and image-based content with another set of products: IBM FileNet Capture Desktop and IBM FileNet Capture Professional. Like Datacap solutions, IBM FileNet Capture products automate control and classification during the capture process, which enhances IBM FileNet P8 compliance by increasing accuracy and lowering the risk of lost or inaccessible information. IBM FileNet Capture functionality is mostly a subset of Datacap's offerings, with three key differences:
•IBM FileNet Capture has internationalization and localization supported, particularly Asian language support for OCR in version 5.2.1.
•IBM FileNet Capture does not include advanced data extraction capabilities. The OCR in FileNet Capture is limited to simple document properties or full text.
•IBM FileNet Capture does not include many advanced features contained in Datacap capture products including web-based scanning and indexing, handwriting recognition, complex data validation, and data export.
IBM FileNet Capture Desktop and Professional can be used to scan, index, and convert content and store it in IBM FileNet P8.
4.5.1 FileNet Capture process overview
FileNet Capture processes convert paper documents into digital documents that are a representation of the original paper. There are six steps in the typical capture process:
1. Create images using scan or file import.
2. Process document, which involves image clean up and bar code/patch code recognition (Optional).
3. Acquire metadata, either through barcode recognition, zonal OCR, or manual data entry.
4. Convert to PDF (Optional).
5. Control document with Record activator (Optional).
6. Commit to IBM FileNet P8 Content Engine.
Figure 4-7 shows the basic capture functionality provided by IBM FileNet Capture. The Scan module has document processing and image cleanup already incorporated, thus scanned documents go directly to indexing. The indexing function acquires metadata from the documents. OCR2PDF is PDF conversion, which is an optional feature. Additionally, documents can be declared as records before the images are committed to the IBM FileNet P8 repository.

Figure 4-7 Basic FileNet Capture functionality
Typically, paper-based content that requires capture is external to an organization, such as mailed correspondence, invoices, or technical information. This information serves to initiate, support, and further a business process. Much of the capture for paper-based documentation is centralized as an adjunct or extension to a mail room operation. Centralized capture or scan operations typically run in a specialized production environment. The need to quickly move information through such an operation requires multiple levels of expertise. There is also a high degree of validation and control to ensure that the paper-based information is moved correctly to a digital form.
Because of the steps needed to move information from paper to digital, capture supports a simplified queue system that allows batches of images to be automatically routed through the capture process. This simplified queue system is called a Capture Path, which is covered in “Capture Path” on page 112.
These capabilities constitute the essence of capture supported by IBM FileNet Capture technology and provide the ability to tailor a capture solution to meet the changing needs and specific requirements of an enterprise. All document capture components, which includes assembly, document entry, document processing, file import, and Optical Character Recognition (OCR) can be easily included or removed from the application.
4.5.2 Capture systems architecture
Figure 4-8 shows the FileNet Capture in a distributed architecture and the capture system elements. Distributed architecture is preferred for high-volume applications. Each of the steps in the capture process can be performed on separate systems.

Figure 4-8 IBM FileNet Capture in a distributed architecture
Separate individual systems perform file import and optionally document processing before the capture process goes through document review. The images can also be converted to PDF and records controlled before committing to the FileNet repository.
4.5.3 IBM FileNet Capture products overview
Capture technology is an extremely critical part of any successful ECM project. Basic capture functionality is supported by IBM FileNet Capture Professional and Capture Desktop. IBM FileNet Capture Professional also includes capture paths for automation, OCR and Patch/Bar code recognition, and manual indexing.
Capture Professional includes:
•Basic capture, scan, and import
•Capture path automation
•Zonal OCR
•Patch/Bar code recognition
•Manual indexing
•Conversion to PDF
•Record declaration
•Committal to FileNet Content Engine
FileNet Capture Desktop performs scanning, indexing, and PDF conversion only and is a simplified capture solution. This subset of Capture Professional is non-distributed and contains no fax or OCR support.
The FileNet capture modules for desktop and professional support the entire range of batch capture functions and a collection of drivers for production-level scanners and the major driver standards, including:
•ISIS
•Twain
•Kofax
The next sections detail how these products expand IBM FileNet functionality, focusing on Capture Professional.
4.5.4 IBM FileNet Capture Professional functions
IBM FileNet Capture Professional provides enterprise-level production. Capture can be automated and scripted through the Capture Path, Batch Template, Settings Collection, and Capture Toolkit.
Capture Path
The Capture Path is a key concept in IBM FileNet Capture Professional. It defines an automated sequence of document ingestion operations to process the batch. The ability to configure and manage capture paths supports flexibility and efficiency.
Batch Template
A Batch Template determines what is done to a set of documents, and where they go. It is created by selecting a Settings Collection and a Capture Path.
Settings collection
A Settings Collection holds configuration information that defines how Capture components behave when they process a batch. In addition, the Settings Collection specifies the FileNet Repository Document Class.
Capture Toolkit
The Capture Toolkit is a part of Capture Professional and Capture Desktop that provides a rich set of sample applications, documentation, and other files that are used to develop custom Capture applications using the Capture components. Sample applications are provided with separate user interfaces for scanning or indexing, which includes document assembly, repository administration, local and multi-station automation, conversion from other systems, continuous scanning, error management, and custom components.
The toolkit takes advantage of the Capture architecture to automate document entry through built-in tools, such as Capture Paths and through custom implementations. The underlying COM objects give complete control over the user interface and Capture operations to manipulate repository servers and repository objects.
4.5.5 IBM FileNet Capture Professional components
IBM FileNet Capture Professional components support document ingestion operations that can be invoked while capturing documents. These components include Image Verify, Document Processing, Blank Page Detection, Patch/Bar code recognition, Event Activator, Assembly, OCR, Index, Index Verify, Merge, OCR2PDF, and Records Activator.
Image Verify
Image verification is used to display captured images to fix image quality and page organization. Image verification normally occurs before assembly but can also occur before assembled documents are committed. Pages can be reviewed, rejected, or marked for rescanning.
Document Processing
Document Processing (DocProcessing) provides a set of components to automate indexing and to improve image quality after scanning, faxing, or importing. This functionality also includes image clean up and Bar code/Patch Code recognition. It is optional.
Patch/Bar code recognition
Patch codes are commonly used to separate batches, and bar codes separate documents. The bar code value can exist on a separator page. Capture can interface with scanners and scanner drivers that can perform patch code recognition.
Blank Page Detection
This component detects and removes blank pages in batches.
Event Activator
The Event Activator component performs three types of actions based on rules:
•Separating objects into folders, batches, and documents.
•Changing the name that is assigned to a folder, batch, and document.
•Switching to another settings collection: supported when Event Activator is used with a batch separator rule.
Assembly
Document assembly is the process of sorting, organizing, and grouping individual pages into documents for subsequent indexing and committal. A batch is usually assembled only one time and in one of three ways: manually, ad hoc, or using a capture path.
Optical Character Recognition
Optical Character Recognition (OCR), converts parts of or all of scanned pages of machine print into editable text. Converting locations in scanned pages is known as Zonal OCR. The values that are found can become metadata or attributes of the document. The metadata can be used to route or index automatically.
Index
Indexing with IBM FileNet Capture is a coordinated process that uses index fields from the IBM FileNet server and settings, metadata, and index fields from Capture. Indexing is typically done late in the process to ensure the maximum attributes are available for indexing.
Index Verify
Index Verify is a way to double-check selected index entries before a document is committed for Image Services only. The fields that are used for Index Verify are set up on the Image Services server at the same time that indexing for the document class is set up. Normally, Index Verify is used any time after a document is indexed or auto-indexed, but before it is committed.
Merge
The Merge component combines multiple individual image files of the same or compatible type into a single multi-page file.
OCR2PDF
The OCR2PDF module performs OCR on images and generates a PDF file with embedded text that allows full text search to be performed through IBM FileNet Content Manager's search engine.
Records Activator
Records Activator provides the capability to automatically assign records management-related information of a document based on a default value for the document class, batch, or document. Documents can be associated with a specific file plan based on their attributes, such as barcode value or state.
4.5.6 Integration points
IBM FileNet Capture Professional is built using the Microsoft OLE Automation technology, which provides an object-oriented component-based architecture. This architecture allows third-party components to interact seamlessly with Capture. The Capture modular architecture allows capture solution to be tailored to meet specific enterprise needs. IBM FileNet Capture is integrated with all FileNet Repositories all through the capture process, including:
•IBM FileNet P8
•IBM FileNet Image Services
•IBM FileNet Content Services
•IBM Enterprise Records
IBM FileNet Capture uses the authentication method for the FileNet repository to which it is connecting. FileNet Capture performs real time lookup of document class and field definitions that are configured in the FileNet repository. FileNet Capture uses the FileNet repository's APIs to store documents and metadata. VBScript functions can be used to manipulate the data that FileNet Capture recognizes. These functions are also integrated with all FileNet Repositories throughout the Capture process.
Components expose Enterprise Records File Plans for record declaration and retention, which allows documents to be declared as records in the capture path, so capture works directly with Enterprise Records. Organizations can bring scanned images under records control immediately.
4.5.7 IBM FileNet Capture summary
The IBM FileNet Capture expansion product set focuses on providing a management framework that allows customers to exploit capture technologies to improve business operations. In particular, these products allow for efficient implementation of a production capture environment to quickly capture, organize, control, and utilize their documents.
4.6 Summary
Content ingestion expansion products provide core applications to quickly, efficiently, and intelligently ingest documents into IBM FileNet P8. These products not only add content but also annotate and organize the information to make it more useful. Content Collector, IBM Datacap, and IBM FileNet Capture products and expand the IBM FileNet P8 Platform add key metadata, index, and declare records while faxing, scanning, and importing files from critical business applications. These products make automation and integration simple and powerful simultaneously. Businesses gain greater knowledge and control over their mission critical information while increasing their agility in responding to market changes.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.