
3 Essentials of OpenMP
Abstract: OpenMP is a shared-memory Application Programming Interface (API). It represents a collection of compiler directives, library routines, and environment variables for shared-memory parallelism in C, C++, and Fortran programs. OpenMP is managed by the non-profit technology consortium OpenMP Architecture Review Board (OpenMP ARB), which consists of major computer hardware and software vendors.The first OpenMP API specification was published in October 1997. The latest version (4.0) was released in July 2013.
3.1 OpenMP parallel programming model
OpenMP employs a portable, easy-to-use, and scalable programming model which gives programmers a simple and very flexible interface for the development of parallel applications on various platforms ranging from standard personal computers to the most powerful supercomputer systems.
OpenMP provides #pragma compiler directives, library routines, and environment variables to create and control the execution of parallel programs. OpenMP prag-mas begin with #pragma omp. They typically direct the compiler to parallelize sections of a code.
The syntax of #pragma omp directives is as follows:
OpenMP directives are ignored by compilers which do not support OpenMP. If so, the program will still behave correctly but without parallelism. The main directives are: parallel, for, parallel for, section, sections, single, master, critical, flush, ordered, and atomic. These directives specify either work-sharing or synchronization constructs. Each OpenMP directive may have a few extra optional modifiers, i.e. clauses, which affect the behavior of directives. Also, there are five directives (master, critical, flush, ordered, and atomic), which do not accept clauses at all.
OpenMP runtime routines mainly serve to modify and retrieve information about the environment. There are also API functions for certain kinds of synchronization. In order to use these functions a program must include the OpenMP header file omp . h.
3.2 The parallel construct
The parallel construct is the most important construct of OpenMP. A program without parallel constructs is executed sequentially.
The syntax of the parallel construct has the following form:

The parallel construct is used to specify the code parts which should be executed in parallel. Code parts not wrapped by the parallel construct are executed serially.
OpenMP follows the fork-join programming model of parallel execution. An OpenMP program starts with a single thread of execution (called the initial thread). When certain conditions are met, e.g. a parallel construct, it becomes the master thread of the new team of threads created to execute a parallel region. The number of threads in the team remains constant. Each thread in the team is assigned a unique thread number for identification; the number can be obtained using the omp_get_thread_num ( ) function. The master thread is assigned the thread number of zero. All threads in the team execute the parallel region, but only the parallel 1 construct ensures that work is performed in parallel. However, it does not distribute the work among threads, so if no action is specified, the work will simply be replicated.
The parallel region ends implicitly at the end of the structured block, and there is an implied barrier which forces all threads to wait until each thread in the team finishes its work within the parallel region. When the team threads complete statements in the parallel region, they synchronize and terminate, leaving only the master thread to resume execution.
A simple example is presented in Listing 3.1.
Listing 3.1.

The output for four threads is as follows:

The parallel construct has the following optional clauses:
- – if (<expression>) indicates that the parallel region is executed only if a certain condition is met; if the condition is not satisfied the directive fails and execution continues in the sequential mode.
- – num_threads (<integer-expression>) explicitly sets the number of threads which will execute a parallel region. The default value is the last value set by the omp_set_num_threads ( ) function, or the environment variable OMP_NUM_ THREADS.
- – de fault (shared | none) The shared value means that all variables without the directly assigned data-sharing attribute are shared by all threads. The none value means that data-sharing attributes of variables must be directly specified.
- – private (<list>) specifies a list of private variables which have local copies made for each thread, so that changes made in one thread are not visible in other threads.
- – firstprivate (<list>) prescribes a list of private variables which have local copies made for each thread. This makes copies of values of private variables into each thread before the parallel region.
- – shared (<list>) specifies a list of variables to be shared to all threads.
- – copyin (<list>) determines a list of threadprivate variables which have access to the the master thread’s value from all threads.
- – reduction (<operator:list>) specifies an operator and a list of variables which have local copies in each thread. The specified reduction operation is applied to each variable at the end of the parallel region.
3.3 Work-sharing constructs
Work-sharing constructs are responsible for distributing the work between threads which encounter this directive. These constructs do not launch new threads, and there is no implied barrier upon entry to a work-sharing construct. However, there is an implied barrier at the end of a work-sharing construct, unless the nowait clause is specified.
OpenMP defines the following work-sharing constructs:
- – for directive;
- – sections directive;
- – single directive.
These constructs must be connected with an active parallel region in order to have an effect or they are simply ignored. This is due to the fact that work-sharing directives can be in procedures used both inside and outside parallel regions, and can therefore be executed during certain calls and ignored in others.
The work-sharing constructs have the following restrictions:
- – they must be encountered by all threads in a team or none at all;
- – consecutive work-sharing constructs and barriers must be encountered in the same order by each thread in a team.
3.3.1 The for directive
If there is a loop operator in a parallel region, then it is executed by all threads, i.e. each thread executes all iterations of this loop. It is necessary to apply the for directive to distribute loop iterations between different threads.
The for directive gives instructions to a f or loop operator it is associated with to iterate the loop in the parallel mode. During execution, loop iterations are distributed between threads.
The syntax of the for directive is as follows:

The use of the for construct is limited to those types of loop operators where the number of iterations is an integer value. The iteration counter must also increase (decrease) by a fixed integer value on each iteration.
In the following example (Listing 3.2), the parallel directive is used to define a parallel region. Next, we distribute the work inside the parallel region among the threads with the help of #pragma omp for directive, which indicates that the iterations of the associated loop operator will be distributed among the threads.
Listing 3.2.

The output of the program for n = 8 is


It is easy to see that the program has been executed by five threads. Considering that this is a parallel program, we should not expect the results to be printed in the deterministic order known a priori.
3.3.2 The sections directive
The sections directive is employed to define a finite (iteration-free) parallelism mode. It contains a set of structured blocks which are distributed between threads. Each structured block is executed once by one of the threads.
The sections directive has the following syntax:

The sections directive is the easiest way to order different threads to perform different types of work, since it allows specification of different code segments, each of which will be executed by one of the threads. The directive consists of two parts: the first part is #pragma omp sections and indicates the start of the construct, and the second is #pragma omp section, which marks each separate section.
Each section must be a structured block of code independent from other blocks. Each thread executes only one block of code at a time, and each block of code is executed only once. If the number of threads is less than the number of blocks, some threads have to perform multiple blocks, otherwise the remaining threads will be idle.
The sections directive can be used to perform various independent tasks by threads. The most frequently used application is to carry out functions or subroutines in parallel mode. The following example (Listing 3.3), contains the sections directive consisting of two section constructs, which means that only two threads can execute it at the same time while other threads remain idle.

The sections directive may cause a load balancing problem; this occurs when threads have different amounts of work in different section constructs.
3.3.3 The single directive
If any portion of a code in a parallel region is to be executed only once, then this part should be allocated inside a single construct, which has the following syntax:

The single directive indicates to its structured block of code that this code must be executed only by a single thread. Which thread will execute the code block is not specified. Typically, the choice of thread can vary from one run to another. It can also be different for various single constructs within a single program. This is not a limitation; the directive single should only be used when it is not important which kind of thread executes the part of the program. Other threads remain idle until the execution of the single construct is completed.
The following example demonstrates the use of the single directive:
Listing 3.4.

The output of the program is
3.3.4 Combined work-sharing constructs
Combined constructs are shortcuts which can be applied when a parallel region includes exactly one work-sharing directive and this directive includes all code in the parallel region.
For example, we consider the following programs:


These programs are equivalent to the following codes:


Combined constructs allow us to specify options supported by both directives.
The main advantage of combined constructs is their readability, and also the performance growth which may occur in this case. When using combined constructs, a compiler knows what to expect and is able to generate a slightly more efficient code. For instance, the compiler does not insert more than one synchronization barrier at the end of a parallel region.
3.4 Work-sharing clauses
The OpenMP directives discussed above support a series of clauses which provide a simple and effective way to control the behavior of the directives to which they are applied. They include a syntax necessary to specify which variables are shared and which remain private in a code associated with a construct.
3.4.1 The shared clause
The shared clause is employed to identify data that will be shared between threads in a parallel region associated with the clause. Namely, we have one unique instance of a variable, and each thread in the parallel region can freely read and modify its value.
The syntax of the shared clause seems to be as follows:
A simple example using the shared clause is shown in Listing 3.5 below:
Listing 3.5.

In the above example, the a array is declared shared, which means that all threads can read and write the elements without interference.
When we employ the shared clause, multiple threads may simultaneously try to update the same memory location or, for example, one thread may try to read data from the memory location where another thread is writing. Special attention should be paid to ensure none of these situations occur and that the access to shared data is ordered in accordance with the requirements of an algorithm. OpenMP places the responsibility on users and contains several structures which can help to overcome such situations.
3.4.2 The private clause
The private clause specifies a list of variables which are private to each thread. Each variable in the list is replicated so that each thread has exclusive access to a local copy of this variable. Changes made to the data of one thread are not visible to other threads.
The syntax of the private clause is as follows:
Private variables replace all references to original objects with references to new declared objects with the same type as the original one. The new object is declared once for each thread. It is assumed that the private variables are uninitialized for each thread.
In Listing 3.6 we explain how to use the private clause.
Listing 3.6.

The variable i is a parallel loop iterations counter. It cannot be a shared variable because the loop iteration is divided between threads, and each thread must have its own unique local copy of i so that it can safely change its value. Otherwise, changes made by one thread can affect the value of i in the memory of another thread, thus making it impossible to track iterations. Even if i is explicitly declared as shared, it will be converted into a private variable.
Here both variables are declared as private. If variable a were to be listed as shared, several threads would simultaneously try to update it in an uncontrolled fashion. The final value of the variable would depend on which thread updated it last. This error is called a data race. Thus, the a variable must also be declared a private variable.
Because each thread has its own local copy of the variable there is no interference between them and the result will be correct.
Note that the values of variables from the list specified in the private clause are uninitialized. The value of any variable with the same name as a private variable will also be uncertain after the end of the associated construct, even if the corresponding variable was defined before entering the construct.
3.4.3 The schedule clause
The schedule clause is supported only by the for directive. It is used to control how loop iterations are divided among threads. This can have a major impact on the performance of a program. The default schedule depends on the implementation.
This clause has the following syntax:
chunk_size is a variable which determines the number of iterations allocated to threads. If it is specified, the value of chunk_size must be integer and positive.
There are four schedule types:
- – static. Iterations are divided into equal chunks with the size chunk_size. The chunks are statically assigned to threads. If chunk_size is not specified then the iterations are divided as uniformly as possible among threads.
- – dynamic. Iterations are allocated to threads by their request. After a thread finishes its assigned iteration, it gets another iteration. If chunk_size is not specified, it is equal to 1.
- – guided. Iterations are dynamically assigned to threads in chunks of decreasing size. It is similar to the dynamic type, but in this case chunk size decreases each time. The size of the initial chunk is proportional to the number of unassigned iterations divided by the number of threads. If chunk_size is not specified it is equal to 1.
- – runtime. The type of scheduling is determined at runtime using the environment variable OMP_SCHEDULE. It is illegal to specify chunk_size for this clause.
The static scheduling of iterations is used by default in most compilers supporting OpenMP unless explicitly specified. It also has the lowest overheads from the scheduling types listed above.
The dynami and guided scheduling types are useful for work with ill-balanced and unpredictable workloads. The difference between them is that with the guided scheduling type the chunk size decreases with time. This means that initially large pieces are more desirable because they reduce overheads. Load balancing becomes the essential problem by the end of calculations. The system then uses relatively small pieces to fill gaps in distribution.
3.4.4 The reduction clause
The reduction clause specifies some forms of recurrence calculation (involving associative and commutative operators), so that they can be performed in parallel mode without code modifications. It is only necessary to define an operation and variables that contain results. The results will be shared, therefore there is no need to explicitly specify the appropriate variables as shared.
The syntax of the clause has the following form:
operator is not an overloaded operator, but one of +, *, -, &, ^, |, &&, ||. It is applied to the specified 1 i s t of scalar reduction variables.
The reduction clause allows the accumulation of a shared variable without the use of special OpenMP synchronization directives, meaning that performance will be faster.
At the beginning of a parallel block a private copy of each variable is created for each thread and pre-initialized to a certain value. At the end of the reduction clause, the private copy is atomically merged into the shared variable using the defined operator.
Listing 3.7 demonstrates the use of the reduction clause.
Listing 3.7.

If the nowait clause is employed in the same construct as reduction, the value of the original list item is indeterminate because of the race condition until a barrier synchronization has been performed to ensure that all threads have completed the reduction clause; otherwise, the reduction computation will be complete at the end of the construct.
Some restrictions of the reduction clause are
- – the types of variables in the clause must be valid for the reduction operator, apart from pointer and reference types;
- – a variable specified in the clause cannot be constant;
- – an operator specified in the clause cannot be overloaded.
3.5 Synchronization
In this Section we consider the OpenMP directives which help to provide faultless access to shared data for multiple threads. For example, some problems arise when we need to organize actions of multiple threads that need to update a shared variable in a specific order, or when we need to make sure that two threads are not trying to write to a shared variable simultaneously. The directives described below can be employed when the use of only one implicit barrier synchronization is insufficient. Combined with work-sharing directives they represent a powerful set of features for parallelization of a large number of applications.
3.5.1 The barrier directive
The barrier directive synchronizes all threads. No thread can continue executing a code until all threads reach the barrier directive.
The syntax of the barrier directive is as follows:
Many OpenMP constructs implicitly add barrier synchronization, therefore including an explicit barrier synchronization in a program is often unnecessary. However, OpenMP provides such an opportunity.
Two important limitations of using the barrier directive are:
- – all threads must execute the barrier directive;
- – the sequence of work-sharing regions and barrier directives encountered must be the same for each thread.
Without these restrictions, the situation may arise that some threads wait for the moment when other threads reach the barrier.
C/C++ impose additional constraints regarding the placement of barriers. Barrier structures can only be placed in a program if they can be ignored or will not lead to syntactically incorrect programs.
Once all threads have encountered the barrier, each thread begins executing a statement after the barrier directive in parallel mode.
Listing 3.8 illustrates the behavior of the barrier directive.

In this example, all threads wait until the master thread finishes printing. The output of the program is as follows:

The barrier directive is often applied in order to avoid race condition errors. The use of barrier synchronization between writing and reading shared variables ensures that access is properly ordered. For example, writing into a shared variable will be completed before the other thread wants to read it.
3.5.2 The critical directive
The critical directive specifies a region of code which restricts the execution of an associated statement or structured block to a single thread at a time. This ensures that multiple threads do not try to update shared data simultaneously.
The syntax of the critical directive has the following form:

Here name is an optional label to identify a critical code. The name enables the existence of multiple different critical regions. It acts as a global identifier. If there are multiple critical regions with the same name they will be treated as the same region (e.g., unnamed critical sections). No two threads can execute a critical directive with the same name at the same time.
If we have a thread which makes executions inside a critical region, all other threads with the same name that have reached the critical region will be blocked until the first thread exits the critical region.
To illustrate the work of the critical construct, consider the example presented in Listing 3.9.

The extra comparison of the a [i] and max variables is due to the fact that the max variable could have been changed by another thread after comparison outside the critical section.
The output of the program is as follows:

3.5.3 The atomic directive
The atomic construct allows multiple threads to safely update a shared variable. It specifies that a specific memory location is updated atomically. The atomic directive is commonly used to update counters and other simple variables which are accessed by multiple threads simultaneously. In some cases it can be employed as an alternative to the critical construct.
Unlike other OpenMP constructs, the atomic construct can only be applied to a single assignment statement which immediately follows it. The affected expression must conform to certain rules to have an effect, which severely limits its area of applicability.
The syntax of the atomic directive is shown below.

The way the atomic construct is used is highly dependent on the implementation of OpenMP. For example, some implementations can replace all atomic directives with critical directives with the same unique name. On the other hand, there are hardware instructions which can perform atomic updates with lower overheads and are optimized better than the critical constructs.
The atomic directive is applied only to a single operator assignment. The atomic setting can only be specified to simple expressions such as increments and decrements. It cannot include function calls, array indexing or multiple statements. The supported operators are: +, *, -, /, &, ^, |, «, ».
The atomic directive only specifies atomically the update of the memory cell located to the left of the operator. It does not guarantee that an expression to the right of the operator is evaluated atomically. If the hardware platform is able to perform atomic read-modify-write instructions, then the atomic directive tells the compiler to use this operation.
Listing 3.10 demonstrates the application of the atomic directive.
Listing 3.10.

In the next example (Listing 3.11), the atomic directive does not prevent multiple threads from executing the func function at the same time. It only atomically updates the variable j . If we do not intend to allow threads to simultaneously execute the func function, the critical construct should be used instead of the atomic directive.
Listing 3.11.

To avoid race conditions, all updates in parallel computations should be protected with the atomic directive, except for those that are known to be free of race conditions.
3.6 Dirichlet problem for the Poisson equation
Partial differential equations provide the basis for developing mathematical models in various fields of science and technology. Usually, the analytic solution of these equations is possible only in particular simple cases. Therefore, an analysis of mathematical models based on differential equations requires the application of numerical methods.
In this Section, we employ OpenMP technology to develop a parallel program which solves the Dirichlet problem for the Poisson equation.
3.6.1 Problem formulation
Let us consider in the unit square domain
the Poisson equation
(3.1)
with Dirichlet boundary conditions
(3.2)
For simplicity, we define the function ƒ(x) and the boundary condition g(x) as follows:
(3.3)
We need to find an approximate solution of (3.1)-(3.3).
We introduce a uniform grid ![]() with steps h1 and h2 in the corresponding directions. Here ω is the set of interior nodes
with steps h1 and h2 in the corresponding directions. Here ω is the set of interior nodes
and ∂ω is the set of boundary nodes. We apply the finite difference approximation in space for the problem (3.1)-(3.3) and obtain the following grid problem with the solution denoted by y(x), ![]() :
:
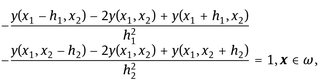
(3.4)
(3.5)
The system can be written in the form of a matrix problem:
where A is the coefficient matrix, and b is the vector on the right. The matrix is sparse (only five diagonals contain nonzero values). We solve the system using one of the best known iterative techniques: the conjugate gradient method. The numerical algorithm is as follows:
- – preset the initial value y0,
- – calculate s0 = r0 = b – Ay0,
- – arrange the loop with k = 0,1, ..., where:
- – calculate pk = Ask,
- – calculate the iteration parameter τ = (rk, rk)/(sk, pk),
- – find the new iteration value yk+1 = yk + τsk,
- – calculate the residual rk+1 = rk - τpk,
- – evaluate sk+1 = rk+1 + sk(rk+1, rk+1)/(rk, rk).
The iterative process terminates if
where is the required tolerance.
3.6.2 Parallel implementation
First, we include standard libraries and define the size of domain as demonstrated in Listing 3.12.
Listing 3.12.

Listing 3.13.

Here, we define the size of the matrix variable A employing macros N1 and N2, and specify the steps of the grid by means of the variables h1 and h2. We also allocate memory for the pointers A, y, and b.
Next we initialize the matrix data as illustrated in the following Listing 3.14.
Listing 3.14.

Obviously, it is a five-diagonal matrix.
The implementation of the conjugate gradients method is shown in Listing 3.15.
Listing 3.15.


In the function for matrix-vector multiplication, we use the #pragma omp parallel for construct, which allows us to distribute iterations among threads.
Listing 3.16.

The function for the scalar product includes the #pragma omp parallel for construct with the reduction (+: a) clause. This means that each variable a will be added at the end of the parallel region as shown in Listing 3.17.
Listing 3.17.

The complete text of the program is presented in Listing 3.18.
Listing 3.18.



We set the required tolerance as ε = 10-3 , and the grid sizes N1 = 100, N2 = 100. After the compilation program we run it with a different number of threads. The solution is found in 75 iterations (Figure 3.1).
In the output we see that the program execution time decreases when the number of threads increases:

Fig. 3.1. Solution of the Dirichlet problem (using gnuplot).
