
Chapter 3. The information landscape
Now that you’ve gotten started with Tika, you probably feel ready to attack the information content that’s out there. The interfaces that you know so far will allow you to grab content from the command line, GUI, or from Java, and feed that content into Tika for further analysis. In upcoming chapters, you’ll learn advanced techniques for performing those analyses and extending the powerful Java API on which Tika is constructed to classify your content, parse it, and represent its metadata.
Before diving too deep into Tika’s guts, as we’ll do in the next few chapters, we’d like you to collectively take a step back and consider this: where does all of the information that you feed to your Babel Fish come from? How is it stored? What’s the information’s ultimate utility, and where can Tika help to deliver that utility in the way that you (or others) expect?
For example, take movies from a movie content provider, as shown in figure 3.1. You can probably think of a few existing ones that either ship movies to you on DVD or Blu-ray, or that stream movies over the internet to one of a number of powerful computing devices such as a computer, video game system, or specialized hardware unit. Though the ability to extract text such as speech from these movie files is more of a research task than a turnkey practice, the extraction of metadata isn’t. All sorts of metadata is useful in these situations! A movie title, its production company, a series of lead actors and actresses—these are just the set of metadata that you may search on. Beyond these attributes, you may be interested in textual summaries of the movie (which unlike speech are easily extractable), your ratings of the movies, your friends’ ratings, and so on.
Figure 3.1. A postulated movie distribution system. Movies are sent via the network (or hard media) to a consumer movie distribution company. The company stores the electronic media on their hard disk (the movie repository), and then metadata and information is extracted (using Tika) from the movie files and stored in a movie metadata catalog. The metadata and movie files are made available electronically to consumers from the company’s user interface. An average user, Joe User, accesses the movie files, and, potentially, to save bandwidth across the wire, Tika can be called on the server to extract summaries, provide ratings, and so on from the streamed movie to the end user’s console systems.

As we’ve learned by now, making this type of metadata and text available to Tika unlocks the ability to differentiate and categorize those movie files (based on their MIME type); to identify the relevant language of the movie, the representation of ratings, and other user-defined metadata; and much more. In reality, Tika is useful in a number of areas—the question is how the content is provided to Tika. Is Tika called on the client side of this application, living inside your computer, video game system, or custom hardware? Or is Tika present in some server-side functionality, leveraged to categorize and classify movie content which is then presented back to you as a user of the system?
The goal of this chapter is to paint a picture of where and how information is stored out there and what kind of information-processing mechanisms could benefit from using Tika. In doing so, we’ll characterize that landscape in terms of scale, growth, and heterogeneity, and suggest how and where Tika can be used to incrementally and efficiently navigate the space.
3.1. Measuring information overload
In this section, we’ll give you a feel for the scale and growth rate of the internet by exploring some real data. We’ll discuss why the internet is growing at the rate that it is, and explore its underlying architecture from first principles. What follows is a discussion of the growing complexity of the internet in terms of the types of information available (PDF files, Word documents, JPEG images, QuickTime files), and in terms of the number of languages and encoding schemes that this information is provided in. Aren’t you glad that frameworks such as Tika exist to help you weed through this electronic haystack?
3.1.1. Scale and growth
The internet has grown tremendously over the years—by some estimates nowadays (see figures 3.2 and 3.3) well into the hundreds of millions of websites, and into the tens of billions of web pages. According to one published report (http://mng.bz/qvry), as of 2007 the amount of digital information available had reached well into the 281 exabyte range, which is somewhere near 281 billion gigabytes.
Figure 3.2. An estimate of the size of the World Wide Web from http://www.worldwidewebsize.com/. The graph is estimated and generated dynamically by inspecting results from Google, Yahoo!, Bing, and Ask.com from 2008–2010. The size of the web has remained relatively constant, with a large gap between those results that are weighted using Google’s estimate (GYWA) and those weighted using Yahoo!’s estimate (YGWA) (a +20–30 billion page difference, with Google having the more conservative estimate). Still, the scale is representative of both the amount of information out there, as well as the difficulty in understanding it (your home library likely nowhere near approaches 10 billion pages in size!).
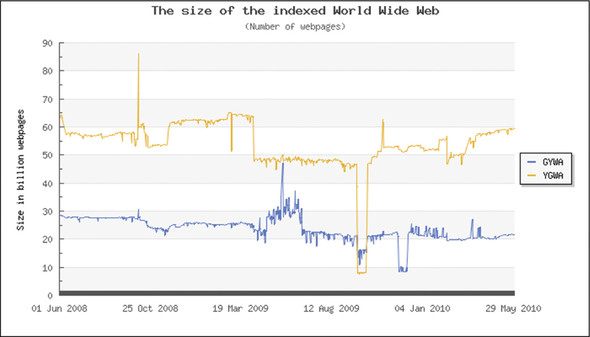
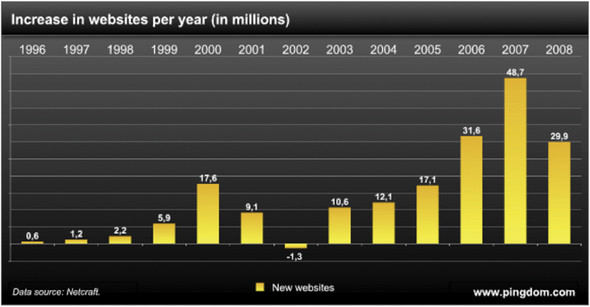
Figure 3.3. The amount of website growth per year (in millions of websites) over the last decade, estimated by http://pingdom.com with data provided by Netcraft. There was steady growth (tens of millions of sites per year) for the later part of the 1990s and into the early 2000s, but between 2005–2008 there has been three orders of magnitude growth (from 10 million to ~30 million) in new websites per year.
Much of this information is courtesy of the World Wide Web (WWW). The collective knowledge of the world is made available through technologies such as HTML (a language for authoring web documents), components called web servers that respond to user requests for HTML documents, and client browsers (Firefox, Safari, Internet Explorer, and so on) that request those HTML documents (and other forms of content) from those web servers. A wealth of content is also available from File Transfer Protocol (FTP) servers, especially science data sets.
Each element can be thought of as a component in the overall WWW’s architecture. In the traditional sense, architecture is the blueprint that guides how software systems are designed. It consists of the logical components of the architecture, their interactions, and the principles that enforce a particular methodology for arranging the components and guiding their interactions. The WWW’s architecture is called REST. The REST architecture and its foundational principles have a direct causal relationship on the WWW’s inherent scalability and growth properties.
The web’s architecture was first comprehensively documented in 2000 by Roy Fielding in his Ph.D. dissertation, Architectural Styles and the Design of Network-based Software Architectures, where he described the Representational State Transfer (REST) architecture. REST prescribes the methodology by which the internet has grown to its current scale, including promotion of intermediaries to reduce single points of failure and enhance scalability, enforcing that all interactions are context-free, and promoting the use of metadata in interactions, to name a few. These principles (and others) have helped to grow the web’s scale and ultimate availability of information, as shown in table 3.1.
Table 3.1. Some underlying principles of the REST architecture and their influence on the web’s scalability. These are only a cross-section of the full description of REST from Fielding’s dissertation.
|
REST principle |
Influence |
|---|---|
| Promotion of intermediaries | This principle promotes scalability and reliability by increasing the number of replicas of data, and replicas of software and components in the form of gateways, proxies, and other providers. |
| Context-free interaction | Not requiring state means that actions and histories of actions required to produce a result need not be maintained, which lessens memory requirements and increases scalability. |
| Use of metadata | Interaction and resources within the REST architecture are both described using rich metadata. The use of this metadata directly enables technologies that understand metadata, like Tika, to have a good shot at understanding not just the ultimate content (web pages, PDFs, and so on) out there, but also the interactions which obtain the content. |
3.1.2. Complexity
You might be wondering: why is scale important? or how does this relate to Tika? Scale influences the web’s overall complexity in that the more content that’s made available (which is growing at a tremendous rate), the greater the likelihood of the content’s non-uniformity. And, true to form, this is certainly the case. By some accounts (see http://filext.com), between 15,000 and 51,000 content types are available out there (a sampling of which is shown in figure 3.4), and despite efforts to classify those types, the number is growing at a rate faster than any standards body can keep up with.
Figure 3.4. A sampling of well-known content types of the up to 51,000 in existence. As a user of the modern internet, you’ll likely see some of these documents and files while navigating and searching for your topic of interest. What’s even more likely is that custom applications are required to view, modify, or leverage these documents and files in your particular task.

Content types typically vary along several dimensions such as size, scale, format, and encoding, all of which make it difficult to bring the data together and “mash it up” for the purposes of study and exploration. As a further illustration of this, consider some of the recent discussion within the Tika community regarding character sets (often abbreviated charsets), which are (sometimes numerical) encodings of characters from a particular alphabet, language, or dialect used to ensure interoperability and proper representation of heterogeneous electronic textual formats. Examples of charsets include the American Standard Code for Information Interchange (ASCII) and Unicode.
The charset discussion centered on results (shown in figure 3.5) from a topical test run wherein which a large public internet dataset called the Public Terabyte Dataset (PTD: see http://mng.bz/gYOt) was used along with Tika to determine what types of charsets were in use on the internet. PTD contains somewhere between 50–250 million pages from the top million US domains, and is a sufficiently rich, representative example of the internet.
Figure 3.5. Results from a test run by Bixolabs and its Public Terabyte Dataset (PTD) project. The dataset contains 50–250 million representative pages crawled from the top million US-traffic domains. The test involved running a large-scale crawl job programmed in Cascading (a concurrent workflow construct and API for running jobs on a Hadoop cluster) on Amazon EC2. One part of the crawl job used Tika to evaluate the charset of the document being crawled. The Y axis demonstrates accuracy in detection, and the points show the particular charset and its frequency within documents in the dataset. The results of the test demonstrate decent (60%) accuracy on charsets that were in the median frequency of the dataset, and mixed results (30%) on some common charsets such as UTF-8.
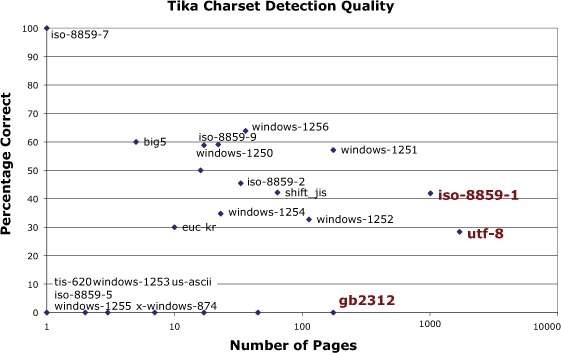
The results were informative. Besides demonstrating that character detection at internet scale is tricky (Tika ranged anywhere from 60% accuracy in terms of correctly identifying charsets from an average number of pages in the dataset to a low of 30% in accuracy on some of the more common charsets, such as UTF-8), the test highlighted the proliferation of charsets in use today, and the strong need to improve on software’s ability to interpret and understand these encodings (we’re working on it in Tika!). See chapter 15 for a more detailed case study of this PTD experiment.
By understanding the rationale behind the internet’s growth, we’re better equipped in Tika to exploit that information in developing novel solutions to navigating the internet’s vast information landscape. As an example, understanding the scale and growth of the internet helped inform the importance of having a sound MIME classification framework as part of Tika. Additionally, in understanding the principles of REST such as context-free interactions, we can leverage the existing metadata provided in each HTTP request to obtain more information (such as the provided content type, content length, and content encoding) about the files we feed into Tika to classify and analyze.
Luckily, as information and content has accumulated, so has our collective skill in searching through the information rapidly and accurately. Modern search engines can deal with the internet’s scale and still provide results in a few milliseconds. In the next section, we’ll examine how search engines have dealt with the information overload, and point to areas where Tika fits in and helps reduce the work that the search engine must perform to sift through the information.
3.2. I’m feeling lucky—searching the information landscape
The digital world is vast, but thankfully we’re not flying blind. More than 15 years ago, the first modern search engines arrived on the scene (anyone remember Hotbot?), spawned by the desire to enter a few keywords and quickly sift through the results. Though the first search engines weren’t as quick as we’d expect in modern days, they did inspire the development of improvements in speed, scalability, and quality of results that gave us the eventual search engine architecture, described by Sergey Brin and Lawrence Page in their seminal Ph.D. research project on Google (see http://ilpubs.stanford.edu:8090/361/). We’ll cover the search engine architecture in this section, providing information about its techniques for helping to accurately and rapidly allow users to sift through information. Then, we’ll tell you where Tika fits into that overall search engine architecture and how it enables many of its features.
3.2.1. Just click it: the modern search engine
Search engines are a big part of how we cope with the information overload nowadays. Though search has been in the mainstream for the past 15–20 years, only since the early ’90s and the advent of the G word (yes we’re talking about Google) has search solidified its place in the technology stack.
Modern search engines are complex, distributed software systems that must deal with all of the aforementioned heterogeneity of the internet. They must decide what content is the most appropriate to crawl and make available in the system, how to obtain that content, what to do with it (parse out the relevant text and metadata), and then how to index the content at scale so that it can be made available for search to the system’s end users. Even with all of those responsibilities, we’ve still significantly simplified what the search engine system is actually doing; for example, the problem of determining what content is worth crawling is extremely complex.
See the example search engine architecture shown in figure 3.6. The crawler (denoted by the bold label C) navigates different website nodes on the internet, guided by its internal architecture shown in the upper-right portion of the figure. Two core components of that architecture are URL filtering and deduplication. URL filtering is the process of selecting URLs from the internet to crawl based on some criteria, such as a set of accepted sites (white list), sets of unacceptable sites (black list), acceptable file types (PDF, Word, but not XLS, for example), domain-based URL filtering (all .edu domain pages, all .com pages), and so forth.
Figure 3.6. The architecture of a web search engine. The circular structures in the middle of the diagram are websites that the crawler (the eight-legged creature labeled with a bold C) visits during a full web crawl. The crawler is itself made up of several functional components, shown magnified in the upper-right corner of the figure. The components include URL filtering (for narrowing down lists of URLs to sites that the crawler must visit); deduplication (for detecting exact or near-exact copies of content, so the crawler doesn’t need to fetch the content); a protocol layer (for negotiating different URL protocols such as http://, ftp://, scp://); a set of parsers (to extract text and metadata from the fetched content); and finally an indexer component (for taking the parsed text and metadata, and ingesting them into the search index, making them available for end users). The crawler is driven by configurable policy containing rules and semantics for politeness, for identification of the crawler, and for controlling the behavior of the crawler’s underlying functional components. The stars labeled with T indicate areas where Tika is a critical aspect of the crawler’s functionality.

Deduplication is the process of determining similarity of fetched content to that of existing content in the index, or to-be-fetched URLs later on in the fetch list. This is performed to weed out the indexing and fetching of duplicate content, which saves resources such as disk space, and helps the overall politeness rating of the crawler by not wasting resources on web content providers and their already overloaded web servers. Deduplication can feed into URL filtering, and vice versa.
Deduplication can be classified into a few areas. The first area is concerned with URL detection and virtual hosting, such as noting that two different URLs point at the same content (such as http://www.espn.com and http://espn.go.com, which both point to ESPN’s main website). Beyond URL detection, deduplication can also involve content-matching techniques, which boil down to either exacting similarity (such as examining the bytes of two fetched URLs and hashing them using the MD5 or SHA1 hashing algorithms, and then comparing the resultant hash values) or near-similarity (two pages that have the same content, but that differ in ads present on the page, timestamps, counters, or some other form of dynamic content). Deduplication can also be concerned with the link structure of pages, looking and filtering out sets of pages that link to one another in similar ways, or the physical properties of the network such as node structures, ISPs, and content available only in certain countries or in certain languages.
3.2.2. Tika’s role in search
The preceding is a simple illustration that even a subset of the functional components in a search codify complex processes that make the end user experience more fulfilling and do much to alleviate the complexity of navigating the information landscape. What’s more, Tika provides many of the capabilities that directly enable both the simple and more complex capabilities required by the search engine. For example, many of the mechanisms for URL filtering discussed earlier can be provided through Tika’s MIME detector, which provides classification based on URL or file extension. The process of deduplication? In many cases, it’s a snap with Tika’s parsing framework, which extracts structured text that can be used for feature comparison and for hashing to determine exact and near-exact similarity matching, as well as page link structure. This pervasiveness is noted in figure 3.6 everywhere you see a star—these indicate places where Tika’s capabilities provide significant functionality leveraged by the search engine and the crawler. You’ll hear more about this when we cover Nutch and Tika in chapter 10.
Once the search engine and its crawler decide which URLs to visit and which URLs are duplicates of one another, the content must be obtained somehow. Crawlers typically have robust protocol handlers and a protocol layer that understands how to interpret a URL and map it to a mechanism to obtain the content (if it’s an HTTP URL, a HTTP request must be made, and so forth). The protocol layer obtains the bits of the remote files referenced by the URLs, and once those bits are obtained, they must be analyzed and summarized, two steps that are regularly handled by a set of parsers that are available to the crawler. As we’ve seen, Tika provides a fairly generalized and robust interface for normalizing the heterogeneity of parsing libraries. In addition, the process by which the crawler decides which parser (or set of parsers) to call for a particular fetched content item is another area where Tika shines—its MIME detection framework and its AutoDetectParser perform this mapping automatically. Once the content is parsed by the crawler, the extracted text and metadata are sent to a search index by the indexer component, which is interested in metadata to make available for search. This is another area where Tika shines: in reducing the overall complexity of the activity through its rich support for metadata, which we’ll learn more about in chapter 6.
If we’ve whetted your appetite for thinking about the overall search engine stack, its use in providing a roadmap for the information landscape, and Tika’s relationship to the search engine’s success, then we direct you to chapter 10 for a more detailed breakdown of Tika’s involvement in Apache Lucene. Lucene is a family of search-related projects at the Apache Software Foundation, including a RESTful search web service called Solr; Lucene-java, the core indexing and searching library; and formerly including Mahout, a classification, clustering, and analysis platform which we’ll briefly discuss in the next section.
We’ve focused at length on dealing with information discovery as a means of navigating information, but once you’ve found the information, you need to do something with it. Cluster it. Make a hypothesis. Leverage it to determine what types of books you may be interested in buying. You can do a lot with the data that you find and retrieve with a search engine. We’ll discuss some neat things you can do with your data in the next section, and pinpoint the utilities of Tika in these activities along the way.
3.3. Beyond lucky: machine learning
Cruising around the internet with a powerful search engine is great, but after awhile, you may develop a set of favorite websites that you regularly visit and no longer require a search engine to get you there. What’s more, as you frequent these sites, you begin to notice that they remember certain things about you: products that you like to purchase, other users of the sites with similar interests, and so forth. How do they do this? The sites exploit modern approaches to machine learning, which you’ll learn about in this section. Techniques for machine learning help reduce the complexity of the information landscape by using information that sites remember about you to make highly accurate recommendations for content you’ll be interested in, obviating the need to search any further for it. We’ll discuss some common uses of machine learning, and then discuss two real-world implementations of machine learning algorithms from the open source community at Apache—we’re pleased to say that Tika is a part of both of them! Read on to find out the how and the where.
3.3.1. Your likes and dislikes
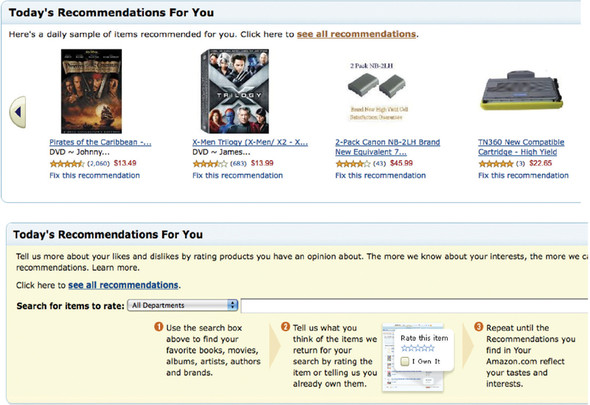
So far, we’ve discussed finding your way around the information landscape with a search engine, whose main goal is data reduction, and navigating the landscape via exploration. Another common approach is to have software suggest what information would be relevant to you, based on indicated preferences—movie genres you’ve declared that you like, your past purchase history, and so on. These are all types of machine learning, or ML. Some of the more popular ML techniques that are relevant to our discussion are collaborative filtering for providing item- and user-based recommendations, clustering (of seen content) based on similarities deduced, and categorization (of unseen content and users) for the purposes of shoe-horning that content and those users into existing clusters. These techniques are often combined to make recommendations to users about what items to buy, other users who are similar to them, and so on. A good example of collaborative filtering in action is the recommendations that you regularly get from e-commerce sites like Amazon.com when you log in, as shown in figure 3.7.
Figure 3.7. An example of collaborative filtering as provided by Amazon.com. Recommendations are automatically suggested on entering the site through collection and processing of past purchases and user preferences. In the bottom portion of the figure, Amazon explicitly solicits feedback and ratings for items in a category from the user to use in future recommendations.
E-commerce websites have recently taken up ML techniques so that they can take advantage of the data that they have been collecting for years. The collected information falls into a few basic categories, a representative cross-section of which is shown in table 3.2.
Table 3.2. Information representative of the type collected about users of e-commerce sites. This would then be fed into a collaborative filtering, clustering, or categorization technique to provide recommendations, find similarities between your purchasing history with that of other users, and so on.
|
Information category |
ML utility |
|---|---|
| Item rating | By explicitly requesting that a user rate an item (as shown in the bottom portion of figure 3.7) websites can obviate the need to sense your mental model of popularity. Ratings are typically on some numerical scale, such as 1–5, or 1–10, and visually depicted as “tagging” an item with gold stars. Ratings can be fed into algorithms such as Slope One, an approach for collaborative filtering which uses your ratings and those of other users to determine future recommendations tailored to your tastes. |
| User purchase history | Purchase history typically includes information such as item bought, category, number of times purchased, date purchased, cost, and other information that can be fed into clustering techniques to relate your purchase history to that of like users. If the websites can determine the appropriate cluster for you and your fellow users, and map that to the items you and others in that cluster have purchased, it has a good sense of what future items you and your cluster mates may be interested in purchasing. |
| User characteristics | Includes information such as location, gender, credit card type, and other demographics that can be used to relate you to users of similar characteristics. Tying this information with existing user-to-item mappings deduced from purchase history or ratings can allow websites to provide recommendations immediately to users as soon as they enter the site. |
As the internet has grown, and with the advent of social media such as Facebook and Twitter, more and more information is being gathered, even outside of the realm of the traditional e-commerce sites. Imagine all of the information that you as a user include in your Facebook profile that would be useful for Amazon.com to relate to the items that it would like to sell you. For example, Facebook user profiles have a Likes and Interests section, which users create by clicking the Like button on pages belonging to rock bands, political parties, types of food, all sorts of different things. Imagine that Amazon.com is promoting a new book on Southern-style cooking. Ideally, Amazon.com would only want to recommend this book to those interested in buying it, because recommending it to someone who isn’t interested weakens the belief of users that Amazon.com really understands their likes and dislikes. On the other hand, recommending the book to a user who enjoys Southern food is an instant recipe for increasing Amazon.com’s profits.
Amazon.com doesn’t collect information about your likes and dislikes. But Facebook and Twitter do, and provide open APIs for other companies to access your information based on your declared privacy ratings. So the clear goal of a company like Amazon.com would be to leverage the social media information about you to increase its chances of targeting the right users for sales. That said, accessing your social information is only one part of the battle, as we’ve seen by now! Once the information is acquired, it’s likely in a form that requires further processing, including text and metadata extraction, exactly like the processing provided by Tika! Likes and dislikes as provided by social media APIs might not be in the format that Amazon.com expects, and may be annotated with HTML tags (for emphasis and structure), as well as relevant metadata that could be useful as well.
3.3.2. Real-world machine learning
Three recent open source software projects that directly implement many of the ML techniques we’ve discussed are Apache Mahout (http://mahout.apache.org/), Apache UIMA (Unstructured Information Management Architecture: see http://uima.apache.org/), and the Behemoth project (https://github.com/jnioche/behemoth). All three have extensions built in that leverage Tika in a fashion similar to our Amazon.com example.
Apache Mahout is a framework for providing ML algorithms on top of a scalable cloud computing platform called Apache Hadoop. Mahout implements collaborative filtering, clustering, and categorization techniques, and provides an extension mechanism and architecture called Taste. With Taste, users can write their own ML algorithms, provide them vector data from a variety of different sources, and then produce user recommendations. Common mechanisms for providing data via Taste include CSV files, Java programs that extract and translate internet data sources, approaches involving databases, and so forth. A recent extension to Mahout involved integrating Tika to assist in taking arbitrary binary content, extracting its text and metadata, and then using the combination of text and metadata to form vector input to Mahout’s ML algorithms. This process is depicted in the upper portion of figure 3.8.[1]
1 For more detail, have a look at another recent Manning book, Mahout in Action (http://manning.com/owen/).
Figure 3.8. Tika’s utility in machine learning (ML) applications. The dashed line in the middle of the figure delineates two use cases. The first is within the Apache Mahout project, whose goal is to use ML to provide collaborative filtering, clustering, and categorization. Mahout algorithms usually take vectors as input—descriptions of the clustering, user or item preferences, or categorizations of incoming content, where content can be arbitrary electronic documents. An emerging use case is to take files and use Tika to extract their textual contents and metadata, which can be translated into Mahout vectors to feed into its ML algorithms. In the bottom of the figure is a use case for Apache UIMA, a reference implementation of the UIMA standard being developed by OASIS. In this use case, Tika is used to implement a UIMA annotator that extracts features from incoming content, and then classifies those features in a UIMA Common Analysis Structure (CAS) model.

Apache UIMA is an open source implementation of the UIMA standard actively being worked on by the OASIS standards organization. UIMA was originally donated to the Apache Software Foundation by IBM, and has since grown into an Apache Top Level Project (TLP), in a fashion similar to Mahout. UIMA’s goal is to make sense of unstructured information by providing explicit support for modeling, analyzing, and processing it in a number of programming languages, including Java and C++. One use case of UIMA is taking in content and running several analyzers on it to produce what UIMA calls annotations, which are content features extracted by the UIMA annotators. A recent contribution to UIMA is the Tika Annotator, which uses Tika to extract document text and metadata as a means of feature extraction. Features are grouped into a common analysis structure (CAS), which can then be fed into further information analysis and visualizations. This interaction is depicted in the bottom portion of figure 3.8.
Another example of open source machine learning and analysis is the Behemoth framework. Behemoth brings together UIMA and the General Architecture for Text Engineering (GATE: see http://gate.ac.uk/) software toolkits, as well as Tika for providing textual analysis software that runs on top of the Hadoop framework. Behemoth allows users to rapidly go between GATE annotations and heterogeneous document formats using Hadoop as the underlying substrate. In a nutshell, Behemoth focuses on linking together various information extraction components which operate on documents. Many folks use Behemoth as “glue” to ease large-scale processing of documents and to help combine various open source projects such as Nutch, Tika, UIMA, Mahout, and Solr. For instance, Behemoth can take the output of a Nutch crawl, process it with Tika, get extra information using UIMA, and then convert it all into vectors for Mahout or send the data to index in Solr.
Tika’s recent use with Mahout, UIMA, and Behemoth is likely only the tip of the iceberg as more ML technologies and techniques emerge and as more user information is made available on the internet with the advent of social media. E-commerce sites and other for-profit corporations are increasingly interested in collecting as much of the disparate information out there as possible and correlating it using machine learning techniques. Technologies such as Tika can insulate the ML techniques from having to deal with the heterogeneity of the information landscape, allowing them to focus on improving the way computers understand our documents, and ultimately increasing our collective ability to leverage the power of the information that’s out there.
3.4. Summary
The focus of this chapter was to navigate the information landscape and reflect on the breadth of information out there in the form of HTML pages, PDF files, Word documents, and other goodies that you’ll want Tika to automatically understand for you.
We started out examining the scale, growth, and complexity of the information that’s available via the internet. Its distributed nature, its resiliency to failures, and its ultimate scalability have engendered its role in modern society, and at the same time increased the available information by orders of magnitude, well into the tens of billions of web pages. That includes much more than just HTML pages, which is why technologies such as search engines and content management systems must easily extract information from numerous types of documents available out there.
Search engines came about to help tame the complexity of the web by allowing users to type keywords into a text box to rapidly and accurately find documents that matched their interest. Dealing with the scale, complexity, and growth of the internet (or even a corporate intranet) required search engines to have a fairly detailed modular architecture, involving determining what links on the WWW to crawl, fetching the content pointed to by the links, parsing the content, indexing its metadata and text, and ultimately making the information available for query. We saw where Tika came into play in the overall search engine architecture, as well as its utility in understanding content at scale.
Once content is identified and obtained via the search engine process, most often it needs to be analyzed or processed in some way. We saw how technologies such as UIMA and Mahout make it easier to cluster and analyze data, and what role Tika can play in assisting those technologies even beyond the point of identifying the content and files that feed into them.
We’re pretty far down the rabbit hole at this point in terms of looking at Tika, understanding its architecture, and integrating it into software. But we’ve only scratched the surface of what Tika can do. In the next few chapters, we’ll get up close and personal with Tika and its Java codebase, looking first at its typical initial utility in your application: MIME type identification!