
Chapter 40. When is an unused index not an unused index?
Rob Farley
Indexes can help you access your data quickly and effectively, but index overhead can sometimes be costly. Keeping an index updated when data is changing is one cost, but there is also the cost of extra storage space and the increased size of backups. So if an index isn’t being used, you should remove it, right?
In this chapter, I’ll show you ways to find out if an index is used. Then I’ll show you a type of index that may appear to be unused even although it really is used. Hopefully this won’t leave you too disheartened about the idea of researching your indexes but instead convince you of the power of SQL Server.
Overview of indexing
My favorite analogy for indexes is telephone directories. I’m not sure whether I heard this analogy or came up with it—I just know that it’s a way of describing indexes that everyone grasps easily. Like most analogies, it doesn’t fit completely, but on the whole it’s fairly good.
In Australia, the company Sensis publishes two phone books: the Yellow Pages (which lists entries according to business type) and the White Pages (which lists telephone entries by surname or business name). I assume that somewhere there is a list of all the information about the telephone numbers in Australia. Nowadays it would be electronic, but for the purpose of the analogy, we’re going to consider a paper-based system. Suppose that the master list of the telephone number information is a massive folder stored at the telecommunication provider’s head office. Suppose also that it’s sorted by telephone number.
This folder would not be useful if I wanted to look up the phone number of my friend Andrew. His number could be on any page of the folder, so I’d have to hunt through the lot—starting on page one and continuing until I found him. If he had two numbers, I would have to keep looking to the end, even if it turned out he was on page one. If the folder contains millions of phone numbers, this would not be feasible. The folder is analogous to a clustered index in SQL Server. The folder contains all the information that is available, and the phone number acts as the key to unlock it—providing order to the information and a way of identifying each individual record.
The White Pages is useful for finding Andrew’s phone number, though. I know Andrew’s surname, so I can find him very quickly. As it’s sorted by surname, I can turn straight to his record (almost—I might have to jump around a little) and see his phone number there.
As I only need his phone number, the White Pages (but I’d rather call it a nonclustered index) is the only resource I need. I can say that it covers my query. But if I wanted to get another piece of information, such as his billing number, I’d have to use his phone number to look him up in the master folder. In SQL Server land, this is known as a key lookup.
I won’t go further into indexes now. Entire chapters could be written about best practices for indexes, and I want to make a point about unused indexes.
Unused indexes
If I never used the White Pages, there would be no point in having it in that small cupboard on which the phone sits. I could put other, more useful stuff there. What’s more, whenever someone moves or changes his name or phone number, the White Pages must be updated. Although I get a new physical copy only once a year, the online version is updated much more often. Perhaps if I were eager, I could keep my eye out for changes to the underlying data and keep my copy of the White Pages up to date. But that would be arduous.
The same principle applies to indexes in databases. If we don’t use an index, there’s little point in having it around. Learning how to find the indexes that aren’t used is a fairly useful skill for a database administrator to pick up, and SQL Server 2005 makes this easier.
SQL Server 2005 introduced Dynamic Management Views (DMVs) that are useful for providing dynamic metadata in the form of queryable views. There are other types of system views, such as catalog views like the useful sys.indexes, but for finding out which indexes are used, the most useful view is the DMV sys.dm_db_index_usage_stats. Let’s look at the structure of this view, by expanding the relevant part of the Object Explorer in SQL Server Management Studio (SSMS), which is in the System Views section under the database of interest. Figure 1 comes from SQL Server 2008 Management Studio, even though my queries are running against SQL Server 2005. I’m also using administrator access, although you only need VIEW DATABASE STATE permission to read from the DMV.
Figure 1. The structure of sys.dm_db_index_usage_stats

You’ll notice that the DMV lists the number of seeks, scans, lookups, and updates that users and the system perform, including when the latest of each type was done. The DMV is reset when the SQL Server service starts, but that’s just a warning to people who might have thought that data remained there from long ago. An index that isn’t used won’t have an entry in this view. If no seeks, scans, lookups, or updates have been performed on an index, this view simply won’t list the index. Incidentally, bear in mind that to get the name of the index, you may want to join this view to sys.indexes.
You can also find out which indexes are used by looking at the execution plans that are being used by the queries issued against the database. This is even more useful, as the impact of an index can be easily evaluated by its impact on individual queries. If you consider the performance gain on an individual query, and examine how often this query is executed, you have a fantastic metric for the impact of an index. Query plans make it clear which indexes are being used, as an icon is shown for each index scan or seek. SQL Server 2008 Management Studio has significantly improved the readability of execution plans by displaying only the table name and index name, rather than using the three-part naming convention for the table and the index name. Figure 2 is a screen shot of an execution plan from SSMS 2005. Compare it with figure 3, which is a screen shot of an execution plan from SSMS 2008.
Figure 2. Execution plan in SSMS 2005
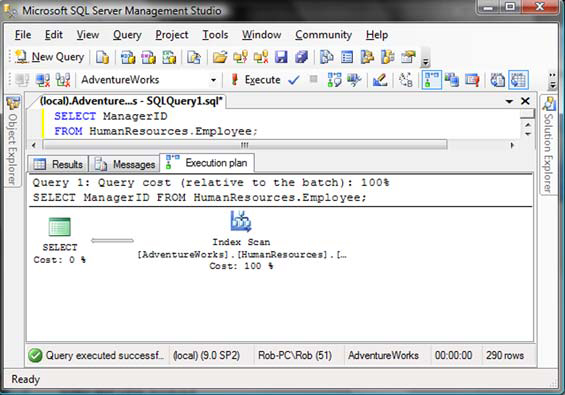
Figure 3. Execution plan in SSMS 2008
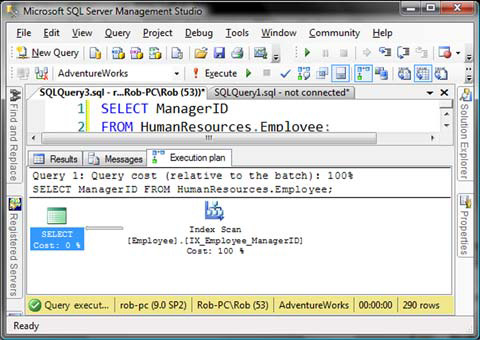
As you can see in figure 3, the query plan is not different; it’s just displayed in a more readable way. This is the main reason I opted to use SQL Server 2008 Management Studio throughout this chapter.
Although you could use a SQL trace to collect the query plan for every query that runs, this is not practical. The impact on performance of this type of trace can be significant, and processing the plans can also be painful. Using the sys.dm_db_index_usage_stats DMV to evaluate index usage is far easier. Querying the DMV every so often (particularly prior to any maintenance windows that might involve a service restart) can allow the information to be collected and analyzed, giving a strong indication of which indexes are used, and which are needlessly clogging up the system.
After the unused indexes have been identified, it is simple to drop them and free up the space in the data files.
Unused indexes that are actually used
Let’s consider a couple of different queries, looking at which indexes are being used and which aren’t. We’ll look at the queries themselves, and also look at the execution plans and the metadata stored within sys.indexes and sys.dm_db_index_usage_stats. To avoid distractions I’ll use my local server, which has just had its service restarted, thereby resetting sys.dm_db_index_usage_stats. I will also use a fresh copy of the AdventureWorks sample database on SQL Server 2005. You can find AdventureWorks on the CodePlex website, with all the other samples that Microsoft makes available. It’s also found on the installation DVD for SQL Server 2005 Developer Edition.
I’ll use the Production.Product and Production.ProductSubcategory tables. The Production.Product table has a field called ProductSubcategoryID, which acts as a foreign key to the Production.ProductSubcategory table. The ProductSubcategoryID field in Production.Product allows NULLs, to cater for those products which are not allocated to a SubCategory.
Let’s consider the following query:
SELECT DISTINCT color FROM Production.Product;
This gives us ten rows, each containing a different color that is used in the Product table. The word DISTINCT ensures that no two rows are identical. If we consider its execution plan, shown in figure 4, we can clearly see how the DISTINCT operator is applied—through the use of a distinct sort.
Figure 4. Execution plan for simple DISTINCT query

We don’t have an index that starts with the Color field, so the system has no better way of finding different colors than to scan through the whole table (on the Clustered Index) and then perform a distinct sort.
But what if we also needed the ProductNumber of each one? Let’s run the query, and look at the execution plan, shown in figure 5.
Figure 5. Execution plan for second simple DISTINCT query

We see that the Distinct Sort operator is no longer visible. We see from the execution plan (or by querying sys.dm_db_index_usage_stats) that the only index being used is the Clustered Index, and yet another index is playing an important role. We’ll examine this in the next section.
For now, let’s consider the query in listing 1.
Listing 1. Querying the DMV to review the indexes and the execution plan
SELECT s.Name, COUNT(*)
FROM Production.ProductSubcategory s
JOIN
Production.Product p
ON p.ProductSubCategoryID = s.ProductSubCategoryID
GROUP BY s.Name;
If the server instance is restarted, the DMV is reset. Now we can run this query knowing that it’s not being tainted by earlier queries and can see which indexes are being used by the query, as shown in figure 6. We can also look in the execution plan to see what’s being used, as shown in figure 7. Both of these methods of reviewing indexes show us that the only indexes being used are the clustered indexes (all clustered indexes have an index_id of 1). In particular, we’re not using a nonclustered index which exists on the table, called AK_ProductSubcategory_Name.
Figure 6. Querying the DMV
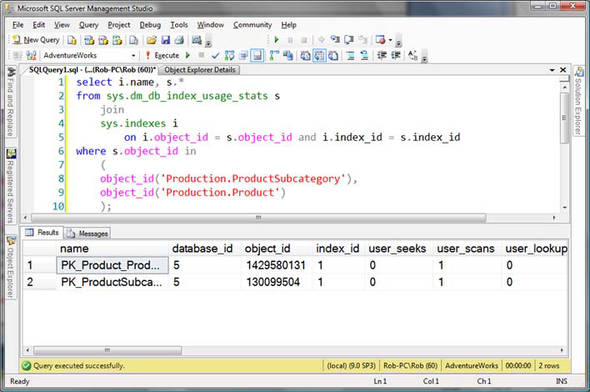
Figure 7. Execution plan with index

So, clearly, we should be able to drop the index AK_ProductSubcategory_Name, as it’s not being used. We can use the following statement to drop it:
DROP INDEX AK_ProductSubcategory_Name
ON Production.ProductSubcategory;
And if we want to re-create it later, we do this:
CREATE UNIQUE NONCLUSTERED INDEX AK_ProductSubcategory_Name
ON Production.ProductSubcategory (Name);
But when we drop the index, the execution plan of this query changes. It now appears as in figure 8. In fact, looking at the estimated cost of the query as reported in the plan, we see that it’s approximately 30 percent higher (estimated cost of 0.05325 on my machine, compared to 0.04055 earlier). It seems our index is being used after all. Compare the execution plan in figure 8 with the one in figure 7; you can clearly see differences in the ways they are being used.
Figure 8. Execution plan without index

Note in particular the fact that the query is the same in both cases. Assuming the data has not changed, the results will be identical. Adding or removing indexes will not affect the rows that are returned by a query.
I’m not suggesting that our indexing strategy for this index is perfect. There are indexes that could make the query run better. The point is simply that the index called AK_ProductSubcategory_Name is actually being used, despite the fact that neither of the traditional methods (examining the execution plan or examining the DMV) is showing its use. Let’s look at what’s going on in more detail.
How is the unused index being used?
The DMV tells us that the index isn’t being used, and this is wrong. But actually, it’s my statement the DMV tells us that the index isn’t being used that’s wrong. The DMV is saying nothing of the sort. It correctly tells us that the index isn’t being used for scans, seeks, lookups, and updates. The execution plan is also correct, because it indicates the indexes (or heaps) from which the data is being fetched.
What neither of these tells us is that the existence of the index is being used by the optimizer. The optimizer sees that we’re grouping by a field which has a unique index on it, and realizes that this is somewhat redundant. That’s right—AK_ProductSubcategory_Name is a UNIQUE index, ensuring that every entry in the Name column is different from all the rest. Therefore, the optimizer can treat the query as if it’s grouping by the field from the other table (the field that we’re joining to) without changing the logic of the query at all. Without the unique index, the optimizer considers that there may be nondistinct values in the field, so it must perform the grouping on that field explicitly. We see this in our first, simpler queries as well. When the unique field ProductNumber was introduced to the mix, the optimizer realized that no Distinct Sort was required, and treated the query as a simple index scan.
In figure 7, we see that the Production.ProductSubcategory table is accessed only after the grouping has been completed. The Sort operator is sorting the Production. Product table by the ProductSubcategoryID field and aggregating its data on that field. Even though we request the grouping to be done on s.Name, the system has completed the grouping before s.Name becomes available. The optimizer is clearly using the existence of the unique index when deciding how to execute the query, even though the index isn’t being used in other ways.
How does this affect me?
If you are tempted to investigate the index usage in your system, please bear in mind that unique indexes may be in use even if they are not being used in a way that is reflected in sys.dm_db_index_usage_stats or in the execution plan. If you remove one of these indexes, you may have queries which perform worse than before.
You may also want to consider introducing unique indexes. Even if you have logic in your application’s business layer that ensures the uniqueness of a particular field, you could improve the performance of some queries by creating a unique index on them. Don’t create additional indexes without giving appropriate thought to the matter, but don’t disregard indexes simply because they’re not being used. The optimizer is powerful and can take advantage of these indexes in ways you might not have considered.
Summary
Indexes are incredibly useful in databases. They not only help you get to your data quickly and effectively, but they let the optimizer make good decisions so that your queries can run faster. By all means, take advantage of methods to evaluate whether or not indexes are being used, but also try to consider if the optimizer might be using some indexes behind the scenes.
About the author

Rob Farley is a Microsoft MVP (SQL) based in Adelaide, Australia, where he runs a SQL and BI consultancy called LobsterPot Solutions. He also runs the Adelaide SQL Server User Group, and regularly trains and presents at user groups around Australia. He holds many certifications and has made several trips to Microsoft in Redmond to help create exams for Microsoft Learning in SQL and .NET. His passions include the Arsenal Football Club, his church, his wife, and three amazing children. The address of his blog is http://msmvps.com/blogs/robfarley and his company website is at http://www.lobsterpot.com.au.