
Chapter 14. Simil: an algorithm to look for similar strings
Are you a perfect speller? Is everyone in your company? How about your business partners? Misspellings are a fact of life. There are also legitimate differences in spelling: what Americans call rumors, the British call rumours. Steven A. Ballmer and Steve Ballmer are two different but accurate forms of that man’s name. Your database may contain a lot of legacy values from the days before better validation at the point of data entry.
Overall, chances are your database already contains imperfect textual data, which makes it hard to search. Additionally, the user may not know exactly what to look for. When looking for a number or a date, we could search for a range, but text is more unstructured, so database engines such as SQL Server include a range of tools to find text, including the following:
- EQUALS (=) and LIKE
- SOUNDEX and DIFFERENCE
- CONTAINS and FREETEXT
- Simil
Equals and LIKE search for equality with or without wildcards. SOUNDEX uses a phonetic algorithm based on the sound of the consonants in a string. CONTAINS is optimized for finding inflectional forms and synonyms of strings.
Simil is an algorithm that compares two strings, and based on the longest common substrings, computes a similarity between 0 (completely different) and 1 (identical). This is sometimes called fuzzy string matching. Simil isn’t available by default. Later in this chapter we’ll discuss how to install it.
In this chapter, we take a closer look at these various methods, beginning with the simplest one.
Equals (=) and LIKE
In this section we’ll discuss two simple options for looking up text.
Equals (=) is appropriate if you know exactly what you’re looking for, and you know you have perfect data. For example, this statement finds all contacts with a last name of Adams. If you have an index on the column(s) used in the WHERE clause, this lookup is very fast and can’t be beat by any of the other techniques discussed later in this chapter:
SELECT FirstName, LastName
FROM Person.Person
WHERE (LastName = 'Adams')
Note
Throughout this chapter, I’m using SQL Server 2008 and the sample database AdventureWorks2008, available at http://www.codeplex.com/SqlServerSamples.
LIKE allows wildcards and patterns. This allows you to find data even if there’s only a partial match. For example, this statement finds all contacts with a last name starting with A:
SELECT FirstName, LastName
FROM Person.Person
WHERE (LastName LIKE 'A%')
The wildcards % and _ are used as a placeholder for any text and any character. If you omit wildcards altogether, the statement returns the same records as if = were used. If, as in the preceding example, you use LIKE with a wildcard at the end, you have the benefit of a fast indexed lookup if there’s an index on the column you’re searching on. Wildcard searches such as WHERE (LastName LIKE '%A') can’t use an index and will as a result be slower.
LIKE also supports patterns indicating which range of characters are allowed. For example, this statement finds last names starting with Aa through Af:
SELECT FirstName, LastName
FROM Person.Person
WHERE (LastName LIKE 'A[a-f]%')
Whether the lookup is case sensitive depends on the collation selected when the server was installed. A more detailed discussion of case sensitivity isn’t in scope of this chapter.
But what if you don’t know the exact string you’re looking for? Perhaps you heard a company name on the radio and only know what it sounds like.
SOUNDEX and DIFFERENCE
If you’re looking for words that sound alike, SOUNDEX and DIFFERENCE are the built-in functions to use. They only work for English pronunciation.
To get the SOUNDEX value, call the function:
SELECT FirstName, LastName, SOUNDEX(LastName)
FROM Person.Person
WHERE (LastName LIKE 'A%')
SOUNDEX returns a four-character string representing the sound of a given string. The first character is the first letter of the string, and the remaining three are numbers representing the sound of the first consonants of the string. Similar-sounding consonants get the same value; for example the d in Adams gets a value of 3, just like a t would. After all substitutions, Adams and Atoms have the same SOUNDEX value of A352. One typical use for SOUNDEX is to store the values in a table, so that you can later run fast-indexed lookups using =.
The DIFFERENCE function is used to compare SOUNDEX values in expressions. It converts its two arguments to SOUNDEX equivalents and computes the difference, expressed in a value between 0 (weak or no similarity) and 4 (strong similarity or identical). For example, this statement finds contacts with last names somewhat similar to Adams:
SELECT FirstName, LastName
FROM Person.Person
WHERE (DIFFERENCE(LastName, 'Adams') = 3)
Resulting names from the sample database include Achong, Adina, Ajenstat, and Akers. As you can see, not all of them would we immediately associate with Adams. That’s one of the limitations of this simple algorithm. Keep reading for more sophisticated options.
CONTAINS and FREETEXT
So far we’ve covered a few fairly simple ways of finding text: by literal value, using literal values and wildcards, and by comparing the sounds of strings. Now we’re going to check out the most powerful text-matching features built into SQL Server.
The keywords CONTAINS and FREETEXT are used in the context of full-text indexes, which are special indexes (one per table) to quickly search words in text. They require the use of a special set of predicates. Let’s look at a few of these powerful statements.
The first one looks for all records with the word bike in them:
SELECT ProductDescriptionID, Description
FROM Production.ProductDescription
WHERE CONTAINS(Description, 'bike')
You might think that’s equivalent to the following:
SELECT ProductDescriptionID, Description
FROM Production.ProductDescription
WHERE (Description LIKE '%bike%')
But the two statements aren’t equivalent. The former statement finds records with the word bike, skipping those with bikes, biker, and other forms. Changing the latter statement to LIKE '% bike %' doesn’t work either, if the word is next to punctuation.
The CONTAINS and FREETEXT keywords can also handle certain forms of fuzzy matches, for example:
SELECT Description
FROM Production.ProductDescription
WHERE CONTAINS(Description, 'FORMSOF (INFLECTIONAL, ride) ')
This statement finds words that are inflectionally similar, such as verb conjugations and singular/plural forms of nouns. So words such as rode and riding-whip are found, but rodeo isn’t.
FREETEXT is similar to CONTAINS, but is much more liberal in finding variations. For example, a CONTAINS INFLECTIONAL search for two words would find that term and its inflections, whereas FREETEXT would find the inflections of two and words separately.
Another aspect of fuzzy matches is using the thesaurus to find similar words. Curiously, the SQL Server thesaurus is empty when first installed. I populated the tsglobal.xml file (there are similar files for specific languages) with the following:
<expansion>
<sub>bicycle</sub>
<sub>bike</sub>
</expansion>
Then I was able to query for any records containing bike or bicycle:
SELECT Description
FROM Production.ProductDescription
WHERE CONTAINS(Description, 'FORMSOF (THESAURUS, bike) ')
The thesaurus can also hold misspellings of words along with the proper spelling:
<replacement>
<pat>visualbasic</pat>
<pat>vb</pat>
<pat>visaul basic</pat>
<sub>visual basic</sub>
</replacement>
If I were writing a resume-searching application, this could come in handy.
The last option I want to cover here is the NEAR keyword, which looks for two words in close proximity to each other:
SELECT Description
FROM Production.ProductDescription
WHERE CONTAINS(Description, 'bike NEAR woman')
CONTAINS and FREETEXT have two cousins—CONTAINSTABLE and FREETEXTTABLE. They return KEY and RANK information, which can be used for ranking your results:
SELECT [key], [rank]
FROM CONTAINSTABLE(Production.ProductDescription, Description, 'bike')
ORDER BY [rank] DESC
So far we’ve covered the full range of text-searching features available in T-SQL, and we’ve been able to perform many text-oriented queries. If it’s impractical to build a thesaurus of misspellings and proper spellings, we have to use a more generic routine. Let’s get to the core of this chapter and take a closer look at one answer to this problem.
Simil
As shown earlier, T-SQL allows us to perform a wide range of text searches. Still, a lot remains to be desired, especially with regard to misspellings. If you want to find a set of records even if they have misspellings, or want to prevent misspellings, you need to perform fuzzy string comparisons, and Simil is one algorithm suited for that task.
One use for Simil is in data cleanup. In one example, a company had a table with organic chemistry compounds, and their names were sometimes spelled differently. The application presents the user with the current record and similar records. The user can decide which records are duplicates, and choose the best one. One button click later, all child records are pointed to the chosen record, and the bad records are deleted. Then the user moves to the next record.
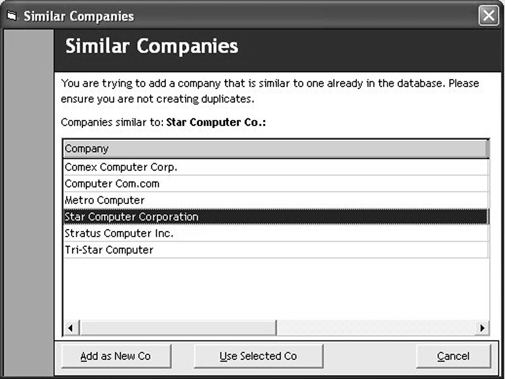
Another typical use for Simil is in preventing bad data from entering the database in the first place. Our company has a Sales application with a Companies table. When a salesperson is creating or importing a new company, the application uses Simil to scan for similar company names. If it finds any records, it’ll show a dialog box asking the user if the new company is one of those, or indeed a new company, as shown in figure 1.
Figure 1. A form showing similar database records
Other uses include educational software with open-ended questions. One tantalizing option the original authors mention is to combine Simil with a compiler, which could then auto-correct common mistakes.
Let’s look at Simil in more detail, and learn how we can take advantage of it.
In 1988, Dr. Dobb’s Journal published the Ratcliff/Obershelp algorithm for pattern recognition (Ratcliff and Metzener, “Pattern Matching: The Gestalt Approach,” http://www.ddj.com/184407970?pgno=5). This algorithm compares two strings and returns a similarity between 0 (completely different) and 1 (identical). Ratcliff and Obershelp wrote the original version in assembly language for the 8086 processor. In 1999, Steve Grubb published his interpretation in the C language (http://web.archive.org/web/20050213075957/www.gate.net/~ddata/utilities/simil.c). This is the version I used as a starting point for the .NET implementation I’m presenting here.
The purpose of Simil is to calculate a similarity between two strings.
Algorithm
The Simil algorithm looks for the longest common substring, and then looks at the right and left remainders for the longest common substrings, and so on recursively until no more are found. It then returns the similarity as a value between 0 and 1, by dividing the sum of the lengths of the substrings by the lengths of the strings themselves.
Table 1 shows an example for two spellings of the word Pennsylvania. The algorithm finds the largest common substrings lvan, and then repeats with the remaining strings until there are no further common substrings.
Table 1. Simil results for Pennsylvania
|
Word 1 |
Word 2 |
Common substring |
Length |
||||
|---|---|---|---|---|---|---|---|
|
Pennsylvania |
Pencilvaneya |
lvan |
8 |
||||
|
Pennsy |
ia |
Penci |
eya |
Pen |
6 |
||
|
nsy |
ia |
ci |
eya |
a |
2 |
||
|
nsy |
i |
ci |
ey |
(none) |
0 |
||
|
Subtotal |
16 |
||||||
|
Length of original strings |
24 |
||||||
|
Simil = 16/24 |
0.67 |
||||||
Simil is case sensitive. If you want to ignore case, convert both strings to uppercase or lowercase before calling Simil.
At its core, Simil is a longest common substring or LCS algorithm, and its performance can be expected to be on par with that class of algorithms. Anecdotally, we know that using Simil to test a candidate company name against 20,000 company names takes less than a second.
Simil has good performance and is easy to understand. It also has several weaknesses, including the following:
- The result value is abstract. Therefore it’ll take some trial and error to find a good threshold value above which you’d consider two strings similar enough to take action. For data such as company names, I recommend a starting Simil value of about 0.75. For the organic chemistry names, we found that 0.9 gave us better results.
- It’s insensitive for very small strings. For example, Adams and Ramos have three out of five characters in common, so the Simil value is 0.6. Most people wouldn’t call those names similar.
- It treats every letter the same, without regard for vowels or consonants, or for letters that often occur together, or for the location in the string, or any other criteria. Some other algorithms do; for example, in the English language the letters Q and U nearly always occur together and in that order, so much so that they could almost be considered a single letter. In a more comprehensive algorithm, such occurrences could be given special consideration. SOUNDEX is another algorithm that does take into account that some consonants are almost the same (for example, d and t).
- Simil can’t be precalculated, always requires a table scan, and can’t take advantage of indexes. This may be a problem for large datasets.
Implementation in .NET
Several years ago I used the C version from Steve Grubb to create a classic Windows DLL that was called from the business layer of an application, and it has served me well. This DLL is available in the download package.
In a search for higher levels of performance, I rewrote the code for .NET in two ways. The first is a straight port from C to VB.NET; the second is a pure .NET interpretation. Why two ways? When a new development platform comes out, some developers stay with what they know and mold the platform to their way of programming, while others go with the flow and change their way of programming to what the platform has to offer. I was curious to find out which approach would yield the best performance.
The straight port is available in the Simil method of the clsSimil class in SimilCLR.dll.
The pure .NET version is available in the Simil method of the RatcliffObershelp class in SimilCLR.dll. This version is the one we’re using in the next section.
To me, it was gratifying to find out that the pure .NET version performed 30 percent better than the straight port.
Installation
SimilCLR.dll is a .NET assembly. An assembly is a unit of execution of a .NET application. SQL Server 2005 introduced the ability to run .NET assemblies in the SQL Server process space. Running inside of the SQL Server process offers performance benefits over the previous method of calling an extended stored procedure. If you’re using an older version of SQL Server, I suggest using the classic DLL from your client or middle-tier code. All code modules discussed here can be downloaded from the book’s download site at http://www.manning.com/SQLServerMVPDeepDives.
Because they can pack tremendous power, by default SQL Server doesn’t allow .NET assemblies to run. To enable this capability, use the following:
EXEC sp_configure 'clr enabled', 1
GO
RECONFIGURE
GO
Please note that this is a server-wide setting.
Next copy SimilCLR.dll to a folder of your choice on the database server machine. To register an assembly with SQL Server, use the following:
CREATE ASSEMBLY asmSimil
AUTHORIZATION dbo
FROM N'C:WindowsSimilCLR.dll' --Enter your path.
WITH PERMISSION_SET = SAFE;
GO
Once the assembly is registered, we need to make its methods accessible to T-SQL. This code creates a scalar function that takes the two strings to be compared, calls the Simil method in the assembly, and returns the Simil value for them:
CREATE FUNCTION dbo.fnSimil(@s1 nvarchar(max), @s2 nvarchar(max))
RETURNS float WITH EXECUTE AS CALLER
AS
EXTERNAL NAME asmSimil.[SimilCLR.RatcliffObershelp].Simil
In the next section, we’ll use this function to run the Simil algorithm.
Usage
The simplest use of this function, as shown in listing 1, is a procedure that takes a pair of strings and returns the result through the output parameter.
Listing 1. Calling the fnSimil() function from a stored procedure
CREATE PROCEDURE dbo.spSimil
@str1 nvarchar(max),
@str2 nvarchar(max),
@dblSimil float output
AS
SET NOCOUNT ON
SELECT @dblSimil = dbo.fnSimil(@str1, @str2)
RETURN
You can call this procedure like this:
DECLARE @dblSimil float
EXEC dbo.spSimil 'some string', 'some other string', @dblSimil OUTPUT
SELECT @dblSimil --0.786
A more powerful use of the function, shown in listing 2, is where you search an entire table for similar strings, only returning those more similar than some threshold value. This procedure returns all Person records where the Person’s name is more similar to the given name than a certain threshold.
Listing 2. Using the fnSimil() function to search an entire table
CREATE PROCEDURE dbo.spSimil_FirstNameLastName
@str1 nvarchar(max),
@threshold float
AS
SET NOCOUNT ON
SELECT *
FROM (SELECT dbo.fnSimil(@str1, Person.Person.FirstName + N' ' + Person.Person.LastName) AS Simil, * FROM Person.Person) AS T
WHERE T.Simil >= @threshold
ORDER BY T.Simil DESC;
This procedure can be called like this:
EXEC dbo.spSimil_FirstNameLastName N'John Adams', 0.75
A query like this can be used to ensure that only genuinely new persons are added to the database, and not simple misspellings.
Testing
In order to test the new .NET code, I used NUnit (http://www.nunit.com) to write test scenarios and execute them. I highly recommend this tool, especially for code modules such as Simil that don’t have a user interface. The test scripts are available in the download package, and include tests for null strings, similar strings, case sensitive strings, and more. One test worth mentioning here is one where the new code is compared with the results from the previous classic DLL based on Steve Grubb’s work, for all CompanyNames in the Northwind database.
This test shown in listing 3 opens an ADO.NET data table and loops over each record. It compares the Simil value from our .NET assembly with the previous classic DLL version (the “expected” value). The two values are compared in the Expect method and, if not equal, an exception is thrown and the test fails.
Listing 3. Comparing Simil values between a .NET assembly and a classic DLL
<Test()> _
Public Sub TestCompanyNames()
Dim dt As dsNorthwind.dtCustomersDataTable = m_Customers.GetData()
For Each r1 As dsNorthwind.dtCustomersRow In dt.Rows
For Each r2 As dsNorthwind.dtCustomersRow In dt.Rows
Dim similNew As Double = SqlServerCLR.RatcliffObershelp.Simil(r1.CompanyName, r2.CompanyName)
Dim similClassic As Double = similClassic(r1.CompanyName, r2.CompanyName)
Dim strMsg As String = "s1=" & r1.CompanyName & ", s2=" & r2.CompanyName & ": simil new=" & similNew & ", expected=" & similClassic
Expect(similNew, EqualTo(similClassic), strMsg)
Next
Next
End Sub
NUnit allows the developer to run the tests repeatedly until all tests get a passing grade. This test even helped me find a bug. In the .NET version, I was using a Byte array to store the characters of the two strings to be compared, and for characters with accents such as in Antonio Moreno Taquería, the classic DLL and the .NET version aren’t the same. I quickly switched to using a Char array and the values agreed again. Without NUnit, this bug would likely have been found by one of you, the users, rather than by the developer/tester.
Summary
In this chapter, we presented several ways to look up text in a database table. We presented a modern implementation of Simil as a .NET assembly. With a free download and a few simple T-SQL scripts you can start using it today in your applications.
About the author

Tom van Stiphout is the software development manager of Kinetik I.T. (http://www.kinetik-it.com). Tom has a degree from Amsterdam University and came to the United States in 1991. After a few years with C++ and Windows SDK programming, he gradually focused more on database programming. He worked with Microsoft Access from version 1.0, and Microsoft SQL Server from version 4.5. During the last several years, Tom added .NET programming to his repertoire.
Tom has been a frequent contributor to the online newsgroups for many years. He’s a former Microsoft Regional Director and a current Microsoft Access MVP.