
Chapter 12. Using XML to transport relational data
The principal subject of this chapter is the use of XML to transport data between locations. To make the demonstration more interesting, we’ll use XML to transport relational data.
Before we start developing the database solution, we have to analyze and understand our business case. Only after identifying every relevant fact about the business case should you attempt any development work.
In the course of this chapter, through planning and developing activities, we’ll learn the basics of how XML can be used in a Microsoft SQL Server 2005 (or later) database, but not before we touch on some basic truths about the XML standard itself.
Understanding before coding
To make the essence of this chapter as simple to understand as possible, our business case will cover a subject everyone should be fairly familiar with: discography.
What’s a discography? In plain English, a discography is a collection of data about recorded music. It contains data about the composers, performers, compositions themselves, and so on.
For the purposes of analyzing this chapter’s business case, we will interview a long-time employee of the music business—meet Joe “Mix-Remix” Quickfinger, our imaginary recording engineer/producer/former roadie, and a self-claimed recording industry expert. We should listen to Joe carefully, but at the same time not take everything for granted.
The concept
Before we unleash Joe, let’s think for a second about our objectives. We need to design a data-centric solution capable of maintaining a discography, which also supports the exchange of business data between similar solutions using XML.
You might ask, why XML? XML is a well-known standard supporting both data exchange and data storage, although we’ll focus on the former. XML is humanly readable. It can be read and written by people; its usability doesn’t require any specific tools; it comes with a standard way of enforcing the validity of individual XML entities (namely the XML Schema); and—last but not least—the querying language used in the automation of XML retrieval as well as modification operations is also a standard (the XML Querying Language or XQuery). As we’ll see later in this chapter, there’s another benefit in using XML, but let this be enough theory for now.
XML, XML Schema, XML Path Language, and XML Querying Language recommendations
All these standards have been developed by the World Wide Web Consortium (or W3C), an international consortium of individuals and organizations that focuses on the development of protocols and guidelines aimed at ensuring long-term growth for the web.
You can find more information on W3C at its web site: http://www.w3.org/.
You can learn more about XML, XML Schema, XPath, and XQuery online:
- XML (Extensible Markup Language): http://www.w3.org/XML/
- XML Schema: http://www.w3.org/XML/Schema/
- XML Path Language (XPath): http://www.w3.org/TR/xpath/
- XML Query (XQuery): http://www.w3.org/XML/Query/
Joe has just had his fifth coffee and he’s as ready to share his knowledge with us as he’ll ever be. Because this isn’t Joe Quickfinger’s autobiography, I’ve taken the liberty of reducing the monologue to the bare essentials. Joe begins:
The music industry isn’t a business as much as it’s a big mess, let me tell you. First of all, music is written by authors and performed by artists. Sometimes artists write their own music, and sometimes authors perform their own music themselves.
Generally, artists are sociable people, and in the course of socializing they tend to form bands. A band would then consist of several artists. Some artists, on the other hand, are less sociable—they prefer to ‘go solo,’ but sometimes they too have to hire someone to help them perform their music.
So far we can safely say that a Song can be authored by one or more Persons and that a Person can author one or more Songs. Also, we can safely say that a Band is a collection of one or more Persons, and that a Person can be a member of one or more Bands. Joe continues to explain:
In order to make a living and also be able to have some time off to socialize, the bands select one or more of their songs, record them, and publish them in the form of an album. People in the recording business for some reason think the word song is inappropriate and the word composition is too long; therefore they call songs tracks instead.
Sometimes bands will invite other bands to help them put together an album. More often than that, the producers do a bit of “composing” on their own and end up with albums containing tracks performed by several bands and authored by several authors. Despite all this confusion, these albums aren’t called complications.
We can safely say that a single Band can perform one or more Tracks and be present on one or more Albums, and that a single album may contain Tracks by one or more Bands.
When music was first created back in the Stone Age there weren’t very many musicians, let alone bands! Nowadays, regardless of the number of musicians in it, each band is given a name. Usually the names are unique, but don’t bet on it.
Each track is given a definite title, and as soon as it’s ready to be put on an album it’s also marked with a track number.
Albums also have titles. And we can tell when they were released, and—thanks to the devoted and sometimes psychotic fans—we can know this fact down to the very second the delivery truck reached the first store.
The information provided by Joe contains the essence of what you’d need to know about discographies in order to design a solution that could support Joe and his colleagues in their work.
We can identify individual business entities, the relationships that exist between them, and the attributes that describe them. And that’s exactly what we need for the next step.
The logical model
To get a clear picture of all the elements that constitute the discography business case, see table 1, which shows individual business entities and facts about them.
Table 1. Entities, the facts about them, and the roles those facts play in the business case
|
Entity |
Fact |
Type of fact |
|---|---|---|
|
Discography |
Contains Albums |
Relationship |
|
Album |
Consists of Tracks Has a Title |
Relationship Attribute |
|
Track |
Exists on Albums Is authored by Persons Is performed by Bands Has a Title Has a Track Number |
Relationship Relationship Relationship Attribute Attribute |
|
Person |
Authors Tracks Is in Bands Has a First Name Has a Middle Name Has a Last Name |
Relationship Relationship Attribute Attribute Attribute |
|
Band |
Performs Tracks Contains Persons Has a Name Has an Established date/time Has a Disbanded date/time |
Relationship Relationship Attribute Attribute Attribute |
A few words on logical modeling
Entities are intellectual concepts representing objects (things) and subjects (persons) present in a particular business; in fact, they exist at the center of the business. Everything in any business revolves around the entities. In our case, we’ve identified individual entities in Joe’s statements.
The position of the entities in regard to the business is reflected in our summary of Joe’s explanations through the relationships that exist between them and the attributes that describe them.
Put as simply as possible, a relationship can be represented by a verb designating an action or a state involving at least two entities. Verbs designating ownership, on the other hand, represent a different kind of relationship—a reference to an attribute. Relationships describe what happens and/or what is in regard to several entities, whereas attributes describe a single entity.
The entity-relationship schema is an essential part of the logical model, though not the only one, just like the data store in itself is not the only part of a data-centric solution. Business logic is the other essential part of the logical model. It defines all the data management operations needed for maintenance of the business entities. For the purposes of this chapter, we’ll focus on the basic operations presented in table 2.
Table 2. Data management operations supported by our solution
|
Operation |
Description |
|---|---|
|
Create |
Entity is created; the data is imported into the database. |
|
Update |
Entity is modified; the data in the database is changed. |
|
Read |
Entity is retrieved; the data is read from the database. |
One particular operation isn’t present in table 2: delete, the removal of entities from the database, won’t be supported by our solution.
Before continuing, please take another good look at the tables.
The physical model
There may be other facts about the discography business, but for the sake of keeping this example simple, let’s agree that they’re not important right now.
In order to implement the logical model in our solution, we need to transform it into a physical model. This transformation is a science of its own, and is as such outside the scope of this chapter. Therefore we’ll now move straight to the finished physical model, shown in figure 1.
Figure 1. The physical model
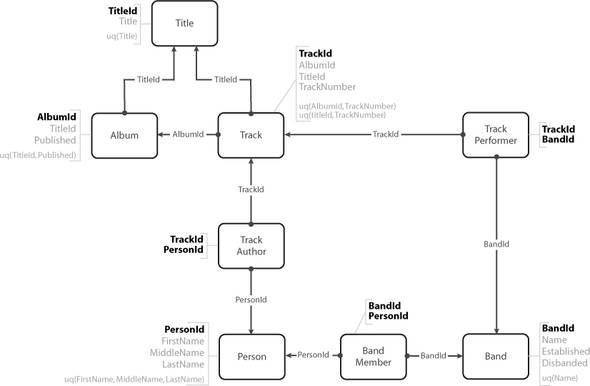
The bold outlined boxes represent our entities along with their attributes. The arrows and the light outlined boxes represent the relationships: the one-to-many (for example, several Albums can have the same Title) and the many-to-many relationships (for example, several Persons can be members of several Bands), respectively. The callouts connected to each box list the attributes of each individual entity, and also contain other information—specifically the constraints that need to be implemented.
We can see that one new entity has been added to the physical model, named Title, and that it’s referenced by both the Album as well as the Track entity. This new entity is the result of a process called normalization, an explanation of which is also beyond the scope of this chapter. In brief, one of the objectives of normalization is the removal (or at least the reduction) of data redundancy. In plain English, each individual unit of information (such as an attribute or relationship) that’s used in the business is only stored in a single place throughout the data model. To achieve this, we’ve also introduced surrogate keys representing each entity (the AlbumId, TrackId, PersonId, BandId, and TitleId columns or a combination thereof, shown in bold in figure 1) in addition to the natural keys present in the data itself—one or more columns containing values that uniquely identify each individual row in a table. (In our model, every Title is unique, and no more than one Album can be Published on the same day using the same Title.) The keys in our data model are enforced using primary key constraints, shown in bold, and unique constraints, shown in parentheses preceded by the abbreviation uq in figure 1. The question of surrogate keys versus natural keys is another issue that exceeds the scope of this chapter.
As you can observe from figure 1, one entity that we identified in the section “The logical model” seems to be missing from the physical model—the Discography. But is that really true? Based on the sole fact about this entity (that it “contains Albums”) and the rest of the facts about the Album entity, we could define the Discography entity as the container of all other entities.
The database
The principal purpose of the physical model is to serve as a set of well-defined guidelines used in the development of our data store. As we can see from figure 1, no specific data store is implied, which means that we’re free to decide on using any relational database management system (RDBMS). But because the RDBMS used throughout this book is Microsoft SQL Server, we’ll use our data model to create a SQL Server database. Put more accurately: we’ll implement the physical model of our business case in the form of a SQL Server database.
What shall we name this new database? First of all, it’ll contain all the entities. By naming it Discography we could also implement the Discography entity as the container of every other entity.
One down, five to go. The data model has eight entities: five primary entities defined in the logical model (shown in table 1), and three associative entities (TrackAuthor, TrackPerformer, and BandMember) representing the many-to-many relationships between the primary entities.
You’re welcome to design the database and the tables yourself, or use the scripts published at http://www.manning.com/SQLServerMVPDeepDives.
The XML Schema
At the beginning of this chapter, we decided on using XML as a means of transporting data to and from our database. We also mentioned the essential benefits of using XML, one of them being a standard method of enforcing the validity of our XML entities—the XML Schema. Again, the subject of XML and XML Schema exceeds the scope of this article; therefore let’s emphasize one principal benefit of using the XML Schema.
In SQL Server, the XML standard is implemented as a data type, and because all data types typically represent (implement) a specific (data) domain, the purpose of the XML Schema in regards to the XML data type is to enforce its domain.
The XML Schema will provide us with a guarantee that the discography data coming in or going out of our database is valid—that it complies with the business rules.
Data domain
A data domain defines which values are allowed in a specific data element (such as a variable, a column, and so on).
For instance, a data element of a numerical type can only contain numerical data (numbers)—it can’t, for instance, contain letters or punctuation marks (with the obvious exception of the decimal point). A data element of the integer numerical type can only contain numbers, and no other characters.
The XML data domain is similar to the two examples in the previous paragraph, but is governed by a much more complex set of rules defined by an XML Schema.
Entities of Principal Importance
Let’s take another look at the physical model. We can see two entities that stand out as being more significant to the business compared to the rest.
The first such entity is the Album—even from Joe’s narrative it should be quite clear that the Album represents a principal business entity. It contains all the information vital to the discography business: all the data about the Tracks and about the Album itself.
The other principal entity—also verifiable both in the logical and the physical models, as well as in Joe’s statements—is the Band. Bands represent (at least in our particular model) the groups of Persons collectively responsible for the existence of the discography business.
This means that we’ll require two XML Schemas: one to represent the Albums, and one to represent the Bands. By using two separate schemas, we’ll also be able to isolate the two principal business entities (allowing independent exchange of information regarding each of them), and we’ll be able to eliminate some redundancy. We’ll illustrate that last statement in a minute.
Let’s now implement our physical model in the form of XML Schemas. We’ll be implementing the same data model as before, but this time using a different technology. See listing 1.
Listing 1. The Album XML Schema
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:ma="http://schemas.milambda.net/Music-Album"
xmlns:m="http://schemas.milambda.net/Music"
elementFormDefault="qualified"
attributeFormDefault="qualified"
targetNamespace="http://schemas.milambda.net/Music-Album">
<xs:import namespace="http://schemas.milambda.net/Music" schemaLocation="common.xsd"/>
<xs:element name="discography">
<xs:complexType>
<xs:sequence>
<xs:element name="album" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="track" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="author" type="m:person" maxOccurs="unbounded"/>
<xs:element name="band" maxOccurs="unbounded">
<xs:complexType>
<xs:attribute name="bandName" type="m:bandName"/>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="title" type="m:entityTitle" use="required"/>
<xs:attribute name="trackNumber" type="xs:integer" use="required"/>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="title" type="m:entityTitle" use="required"/>
<xs:attribute name="published" type="xs:dateTime" use="required"/>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
In listing 1, we can observe how our data model can be implemented as an XML Schema from the perspective of the Album entity: a Discography contains one or more Albums, which contain one or more Tracks written by one or more Authors and performed by one or more Bands.
Because we’ll be using a separate XML Schema for the Band entity, we can leave out the Band Members from the Album definition, clearly eliminating unnecessary data redundancy, as shown in listing 2.
Listing 2. The Band XML Schema
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:mb="http://schemas.milambda.net/Music-Band"
xmlns:m="http://schemas.milambda.net/Music"
elementFormDefault="qualified"
attributeFormDefault="qualified"
targetNamespace="http://schemas.milambda.net/Music-Band">
<xs:import namespace="http://schemas.milambda.net/Music" schemaLocation="common.xsd"/>
<xs:element name="bands">
<xs:complexType>
<xs:sequence>
<xs:element name="band" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="member" type="m:person" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="bandName" type="m:bandName" use="required"/>
<xs:attribute name="established" type="xs:dateTime" use="required"/>
<xs:attribute name="disbanded" type="xs:dateTime" use="optional" default="9999-12-31T00:00:00.000"/>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
In listing 2 we can observe how the data model can be implemented from the perspective of the Band entity: a Discography is a collection of one or more Bands, containing one or more Members.
This way, each individual Band entity can exist independently of any Album entity, but the consistency of the Discography as a whole remains intact as long as each Album entity references the appropriate Band entity (or entities).
A few comments on the structure of the XML Schemas
The entities are implemented as XML elements. Their attributes are implemented as XML attributes of the XML element implementing the corresponding entity.
The relationships between the entities are implemented in the structuring of the XML, and the nesting of XML elements. For example, following the logical model rule, which states that the Discography entity contains Album entities, the Album element is placed inside the Discography element, and because an Album entity contains Track entities, the latter are represented by elements nested inside the Album element.
In listings 1 and 2 we can observe that both XML Schemas import a third one. This is due to yet another simplification, based on the fact that both the Album and the Band XML Schemas use a shared collection of types. These shared types are defined in the Common XML Schema, shown in listing 3.
For instance, the Person entity is present in the Album XML as well as the Band XML; therefore both can use the same type for the Person entity, rather than explicitly implementing two separate types with the same set of properties.
Listing 3. Common XML Schema
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:m="http://schemas.milambda.net/Music"
elementFormDefault="qualified"
attributeFormDefault="qualified"
targetNamespace="http://schemas.milambda.net/Music">
<xs:simpleType name="personName">
<xs:restriction base="xs:string">
<xs:maxLength value="150"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="bandName">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="450"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="entityTitle">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="450"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="person">
<xs:attribute name="firstName" use="required">
<xs:simpleType>
<xs:restriction base="m:personName">
<xs:minLength value="1"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
<xs:attribute name="middleName" type="m:personName" use="required"/>
<xs:attribute name="lastName" type="m:personName" use="required"/>
</xs:complexType>
</xs:schema>
Now, if you want to see an example of the amount of redundancy eliminated because we chose to separate the two principal entities and implemented two XML Schemas instead of one, look at the XML examples containing partial discography data of two well-known rock bands published at http://www.manning.com/SQLServerMVPDeep Dives (both XML Schemas are also located there).
Enabling and maintaining the data flow
After implementing the data store part of the data model, we can now focus on the operational part of the logical model. We mentioned three data management operations that will be supported by our solution: entity creation, entity modification, and entity retrieval.
Regarding their relationship to the data flow, we can divide the supported data management operations into two groups:
- Inbound operations— Govern the flow of data into the database. Create and Update are both inbound operations;
- Outbound operations— Govern the flow of data out of the database. Read is the outbound operation.
With inbound operations, our objective should be clear. We’ll have to
- Extract the data from the XML source.
- Insert the data into the data store that doesn’t yet exist there.
- Update data that already exists in the data store to reflect the data extracted from the source.
With outbound operations, the objective is to
- Read the data from the database and return it in XML format.
Preparing the inbound data flow
Before we begin coding, we must consider all the relevant facts about the XML sources used in our solution.
Both XML Schemas allow the XML to contain more than one entity. The related entities are nested in the source, which reflects the relationships between them. Not only must we extract the entities from the XML source, but we also have to do this in the correct order.
How do we determine the correct order? By reviewing the physical model, shown in figure 1, the dependency of individual sets of data can be observed (follow the arrows and identify where they all point to). When importing the data into the database, we should start with the independent entities and finish with dependent ones.
This is a valid order of inbound operations for the Album XML Schema:
- Title (doesn’t depend on any other entity)
- Album (depends on Title)
- Track (depends on Title and Album)
- Person (doesn’t depend on any other entity)
- Track Author (depends on Person and Track)
- Band (doesn’t depend on any other Entity)
- Track Performer (depends on Band and Track)
This is a valid order of inbound operations for the Band XML Schema:
- Band (doesn’t depend on any other entity)
- Person (doesn’t depend on any other entity)
- Band Member (depends on Person and Band)
Extracting Data from XML Using Transact-SQL
You can choose from three data retrieval methods implemented in SQL Server 2005 and SQL Server 2008, and all the details regarding them are available in Books Online. In this chapter, we only need to know the bare essentials about these methods:
- The purpose of the value() method is to extract the value from a single XML data element (a singleton) and return it in the designated data type. We’ll use this method to extract the values from the XML nodes.
- The purpose of the query() method is to read data from one or more XML nodes and return a sequence of XML data elements or a single XML data element. The query() method can also be used to create XML data, but in this chapter we’ll only use it to retrieve data. The return type of the query() method is XML. We’ll use this method to specify the target of the extraction operation and to transform the source data if needed.
- The purpose of the nodes() method is to read data from an XML entity and return a set of XML nodes. This method returns a row of XML data for each node in the XML entity that corresponds to the given criteria. We’ll use this method to retrieve the data from the XML source in the form of a dataset representing a single entity or a single relationship between our entities.
The execution of all three methods is governed through an XQuery statement or an XPath expression passed to each of the methods as an argument. A detailed explanation of XQuery and XPath expressions is once again outside the scope of this chapter, but a brief version of the explanation is presented in the sidebar, “A few words on XPath expressions and XQuery statements.”
A few words on XPath expressions and XQuery statements
The XPath expression is the principal expression used in retrieving data from XML entities. It guides the XML processor as it traverses the XML entity toward the targets containing the data that you want to extract.
For example, the /orders/order/orderDate XPath expression points to all elements named orderDate that exist inside elements named order, which in turn exist inside the element named orders, which exists at the root of the XML entity.
We could compare the XPath expression with the FROM clause of a Transact-SQL (T-SQL) query.
An XPath expression can be extended with an XPath predicate, the purpose of which is to restrict the traversal of the XML entity even further.
For example, the /orders/order/orderDate[. > 20080101] XPath expression contains an XPath predicate (enclosed in square brackets) restricting the XPath expression to point to only those elements named orderDate that contain values greater than 20080101.
We could compare the XPath predicate with the WHERE clause of a T-SQL query.
Compared to the XPath expression, the XQuery statement provides additional functionality needed in extracting the data from XML entities and transforming it. An XQuery statement can also be used to write XML data. One or more XPath expressions are used in every XQuery statement.
In this chapter, no data management operations against XML entities will require any knowledge of XQuery.
In table 3, we can see the XPath expressions pointing to individual entities of the Album XML Schema, and in table 4 we can see the XPath expressions pointing to individual entities of the Band XML Schema.
Table 3. XPath expressions used to extract the entities from the Album XML
|
Entity |
XPath expression |
|---|---|
|
Title |
/ma:discography/ma:album |
|
Album |
/ma:discography/ma:album |
|
Track |
/ma:discography/ma:album/ma:track |
|
Person |
/ma:discography/ma:album/ma:track/ma:author |
|
Band |
/ma:discography/ma:album/ma:track/ma:band |
Table 4. XPath expressions used to extract the entities from the Band XML
|
Entity |
XPath expression |
|---|---|
|
Band |
/mb:bands/mb:band |
|
Person |
/mb:bands/mb:band/mb:member |
Note that in tables 3 and 4, the names of the elements are prefixed with a reference to the respective XML namespace implemented by each XML Schema. You can observe all of the XML namespace declarations in listings 1 through 3. The namespaces are declared in the xmlns attributes of the root (schema) element of each XML Schema. Each XML Schema also targets a specific XML namespace, as declared in the targetNamespace attribute of the schema element. This specifies the namespace of the XML entity in which a particular XML Schema is used.
A few words about XML namespaces
First of all, the subject of XML namespaces exceeds the scope of this chapter. But what you should know about XML namespaces in order to understand their role in these examples is that they represent the business domain in which a particular XML entity exists.
In our examples, we’ve introduced three XML namespaces: one for Album data, another for Band data, and a third to represent a shared domain used both by the Album and the Band domains.
Think about it: does an Album represent the same business entity as a Band? No, absolutely not! Therefore, if we’ve decided on using XML to represent each of them, we need a way to distinguish between them, and this is where XML namespaces come in.
An XML entity that exists in the Album namespace can’t be mistaken for an XML entity that exists in the Band namespace, although they’re both represented as XML. In plain English: an Album can’t be a Band and a Band can’t be an Album.
Microsoft SQL Server 2005 and later versions support XML namespaces and introduces two methods used to declare them using T-SQL. Throughout this chapter we’ll be using the WITH XMLNAMESPACES clause to declare XML namespaces that will be used in XPath expressions. All the details regarding XML namespaces in SQL Server and the WITH XMLNAMESPACES clause can be found in Books Online.
General information regarding XML namespaces can also be found online: http://www.w3.org/TR/xml-names/.
Importing the data
Using the XPath expressions listed in tables 3 and 4, we can prepare individual T-SQL SELECT statements used to extract the data from the XML source. In these SELECT statements, we’ll use the XML retrieval methods mentioned earlier, and in the final definition of the query, we’ll include them in INSERT statements that will be used to import the data extracted from the XML source into the corresponding tables of our Discography database.
Note that in the INSERT statements, we’ll also have to prevent certain constraint violations—most of all, we’ll need to prevent the import of data that already exists in the database.
Extracting Album Data
The source of the Album data is an XML entity based on the Album XML Schema shown in listing 1 earlier in this chapter. This XML Schema provides the structure to hold the data for the Title, Album, and Person entities, including data for the Track Author and Track Performer associative entities.
All the details regarding XPath functions implemented in SQL Server are available in the Books Online article titled “XQuery Functions against the xml Data Type.”
In the following examples, @xml designates a variable of the XML type holding the XML data in question. First off, listing 4 shows the code to extract the titles.
Listing 4. Extracting the titles
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Album' as ma
)
select Discography.Album.query
('
data(@ma:title)
').value
(
'.'
,'nvarchar(450)'
) as Title
from @xml.nodes
('
/ma:discography/ma:album
') Discography (Album)
union
select Discography.Track.query
('
data(@ma:title)
').value
(
'.'
,'nvarchar(450)'
)
from @xml.nodes
('
/ma:discography/ma:album/ma:track
') Discography (Track)
The Title entity contains both the Album and the Track titles. Because in SQL Server 2005 it’s not possible to specify a union XPath expression, the two sets must be merged into one using the T-SQL UNION clause.
Using the union XPath expression, the query could be simplified as shown in listing 5.
Listing 5. Simplified query with union XPath expression
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Album' as ma
)
select Discography.Album.query
('
data(@ma:title)
').value
(
'.'
,'nvarchar(450)'
) as Title
from @xml.nodes
('
/ma:discography/ma:album
|
/ma:discography/ma:album/ma:track
') Discography (Album)
Next up, listing 6 shows the code to extract the albums.
Listing 6. Extracting the albums
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Album' as ma
)
select Discography.Album.query
('
data(@ma:title)
').value
(
'.'
,'nvarchar(450)'
) as Title
,Discography.Album.query
('
data(@ma:published)
').value
(
'.'
,'datetime'
) as Published
from @xml.nodes
('
/ma:discography/ma:album
') Discography (Album)
Listing 7 shows the code to extract the tracks.
Listing 7. Extracting the tracks
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Album' as ma
)
select Discography.Track.query
('
data(@ma:title)
').value
(
'.'
,'nvarchar(450)'
) as TrackTitle
,Discography.Track.query
('
data(@ma:trackNumber)
').value
(
'.'
,'int'
) as TrackNumber
,Discography.Track.query
('
data(parent::ma:album/@ma:title)
').value
(
'.'
,'nvarchar(450)'
) as AlbumTitle
,Discography.Track.query
('
data(parent::ma:album/@ma:published)
').value
(
'.'
,'datetime'
) as Published
from @xml.nodes
('
/ma:discography/ma:album/ma:track
') Discography (Track)
Listing 8 shows the code to extract the persons.
Listing 8. Extracting the persons
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Album' as ma
)
select distinct
Discography.Person.query
('
data(@m:firstName)
').value
(
'.'
,'nvarchar(150)'
) as FirstName
,Discography.Person.query
('
data(@m:middleName)
').value
(
'.'
,'nvarchar(150)'
) as MiddleName
,Discography.Person.query
('
data(@m:lastName)
').value
(
'.'
,'nvarchar(150)'
) as LastName
from @xml.nodes
('
/ma:discography/ma:album/ma:track/ma:author
') Discography (Person)
Listing 9 shows the code to extract the bands.
Listing 9. Extracting the bands
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Album' as ma
)
select distinct
Discography.Band.query
('
data(@ma:bandName)
').value
(
'.'
,'nvarchar(450)'
) as [Name]
from @xml.nodes
('
/ma:discography/ma:album/ma:track/ma:band
') Discography (Band)
Extracting Band Data
The source of the Band data is an XML entity based on the Band XML Schema shown in listing 2 earlier in this chapter. This XML Schema provides all the data for the Band and Person entities, including the data for the Band Member associative entity.
Compare the XML namespace declarations in listing 10 with the declaration in the code listings presented earlier. Is there something different? Why?
Listing 10. Extracting the bands
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Band' as mb
)
select distinct
Bands.Band.query
('
data(@mb:bandName)
').value
(
'.'
,'nvarchar(450)'
) as [Name]
,nullif(Bands.Band.query
('
data(@mb:established)
').value
(
'.'
,'datetime'
), N'') as Established
,nullif(Bands.Band.query
('
data(@mb:disbanded)
').value
(
'.'
,'datetime'
), cast(N'99991231' as datetime)) as Disbanded
from @xml.nodes
('
/mb:bands/mb:band
') Bands (Band)
Listing 11 shows the code to extract the persons.
Listing 11. Extracting the persons
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Band' as mb
)
select distinct
Bands.Band.query
('
data(@mb:bandName)
').value
(
'.'
,'nvarchar(450)'
) as [Name]
,nullif(Bands.Band.query
('
data(@mb:established)
').value
(
'.'
,'datetime'
), N'') as Established
,nullif(Bands.Band.query
('
data(@mb:disbanded)
').value
(
'.'
,'datetime'
), N'') as Disbanded
from @xml.nodes
('
/mb:bands/mb:band
') Bands (Band)
By combining the queries listed previously into a workflow of data management operations, we can design two SQL procedures, each with a specific purpose based on the two principal business entities mentioned in the section “The XML Schema”: one procedure to save the Album data and one procedure to save the Band data.
Tip
Here’s a beginner’s trick for memorizing XML retrieval methods: Nodes provide the set, query retrieves the data element, and value extracts the data.
We haven’t discussed one important issue yet—the question of associative entities. As you may have observed in our examples, only the primary entities are listed. Why is that? The answer is simple: associative entities, representing the many-to-many relationships between the primary entities, can be retrieved from the XML source by combining the queries used in retrieving the data of the individual primary entities of a particular relationship. The combinations are listed in table 5.
Table 5. Retrieving the associative entities
|
Associative entity |
Provided by combining these primary entities |
|---|---|
|
Track Author |
Track joined with Person—based on the nesting of the Author XML element inside the Track XML element of the Album XML |
|
Track Performer |
Track joined with Band—based on the nesting of the Band XML element inside the Track XML element of the Album XML |
|
Band Member |
Band joined with Person—based on the nesting of the Person XML element inside the Band XML element of the Band XML |
Similarly, the one-to-many relationships between primary entities can be retrieved:
- A Track is related to the corresponding Album based on the nesting of the Track XML element inside the Album XML element.
- A Track is related to a Title based on the value of the Title XML attribute of the Track XML element.
- An Album is related to a Title based on the value of the Title XML attribute of the Album XML element.
The scripts containing the definitions of the two procedures can be downloaded from http://www.manning.com/SQLServerMVPDeepDives.
You should study both definitions thoroughly before creating and/or attempting to use the procedures.
Note that in both procedures, table variables are used as temporary storage, which provides the primary keys (based on IDENTITY columns) needed for preserving referential integrity in the Discography database. The dependency of individual business entities was mentioned in the section “Preparing the inbound data flow.”
In both procedures, in the INSERT statements used to import the data into the tables of the Discography database, observe the methods used to prevent the unique and primary key constraint violations.
In brief, this is the operational flow used in both procedures:
- From the XML source, extract the data that represents each primary entity (in the order mentioned in the section “Preparing the inbound data flow”).
- Insert the data into the database table, but exclude rows that already exist at the destination (using the EXCEPT clause or the NOT EXISTS predicate).
- Save the data of each primary entity in a table variable, including the surrogate key values that the rows received when they were inserted into the database table.
- After both primary entities of a particular one-to-many relationship have been inserted and temporarily saved in the corresponding table variables, insert the data representing these relationships to the associative database tables.
- After all the data has been extracted and all primary and associative entities have been inserted, the process finishes.
After you’ve carefully studied both stored procedures and have identified all the concepts presented in this chapter, prepare a T-SQL script to import the XML samples. Execute the script in steps: one XML file at a time, observe the progress, and inspect the tables of the Discography database after each step of the script has finished.
A sample script can also be downloaded from http://www.manning.com/SQLServerMVPDeepDives.
Exporting the data
To provide the outbound data flow, we pretty much have to do the opposite of what we achieved in the previous section: extract the data from the database and return it as XML.
In the data export, we’ll also implement both XML Schemas designed earlier; therefore we’ll need two retrieval procedures—one for the Album data and another for the Band data.
You should study the following two queries carefully in order to understand how the FOR XML clauses using the PATH declaration instruct the database engine to construct the XML entity. You can find all the details regarding the FOR XML clause in Books Online.
Let’s start with the simpler of the two queries. As we defined earlier in this chapter, a Discography contains one or more Bands containing one or more Members. In the Band XML Schema, the relationship between the Band and the Person entities is implemented in form of XML elements representing the Band Members nested inside the XML element representing each individual Band.
In listing 12, you can observe how the FOR XML query used to retrieve the Person entity data is nested inside the FOR XML query used to retrieve the Band entity data. The result from the nested query is exposed as a column in the outer query, and the name of this column is specified in the PATH declaration of the inner query’s FOR XML clause (in our example, mb:member).
Listing 12. To export the Band data from the database
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Band' as mb
)
select Music.Band.Name as [@mb:bandName]
,Music.Band.Established as [@mb:established]
,Music.Band.Disbanded as [@mb:disbanded]
,(
select Music.Person.FirstName as [@m:firstName]
,Music.Person.MiddleName as [@m:middleName]
,Music.Person.LastName as [@m:lastName]
from Music.Person
inner join Music.BandMember
on Music.BandMember.PersonId = Music.Person.PersonId
where (Music.BandMember.BandId = Music.Band.BandId)
order by Music.Person.LastName
,Music.Person.FirstName
,Music.Person.MiddleName
for xml path('mb:member'), type
)
from Music.Band
order by Music.Band.Name
for xml path('mb:band'), root('mb:bands'), type
The proper nesting of the data (namely, that the Band contains the correct Members) is achieved by correctly referencing the Band Member associative entity, where the many-to-many relationships between the Bands and the Persons are stored.
The outer query also uses a PATH declaration specifying the XML node (mb:band) together with the ROOT declaration specifying the name of the XML root node.
The TYPE declaration is used to instruct the database engine to return the resultset as XML data rather than character data, which is the default (if the TYPE declaration is omitted).
Once again, we began the T-SQL query with the XML namespaces declaration, providing us with all the necessary namespaces implemented by the corresponding Band XML Schema.
The first thing that should be apparent from listing 13 is the added complexity resulting from the deeper nesting of the Album XML entity. Remember how we defined the Album XML Schema: a Discography contains one or more Albums containing one or more Tracks written by one or more Authors and performed by one or more Bands.
Listing 13. To export the Album data from the database
with xmlnamespaces
(
'http://www.w3.org/2001/XMLSchema-instance' as xsi
,'http://schemas.milambda.net/Music' as m
,'http://schemas.milambda.net/Music-Album' as ma
)
select Music.Title.Title as [@ma:title]
,Music.Album.Published as [@ma:published]
,(
select Music.Title.Title as [@ma:title]
,Music.Track.TrackNumber as [@ma:trackNumber]
,(
select Music.Person.FirstName as [@m:firstName]
,Music.Person.MiddleName as [@m:middleName]
,Music.Person.LastName as [@m:lastName]
from Music.Person
inner join Music.TrackAuthor
on Music.TrackAuthor.PersonId = Music.Person.PersonId
where (Music.TrackAuthor.TrackId = Music.Track.TrackId)
order by Music.Person.LastName
,Music.Person.FirstName
,Music.Person.MiddleName
for xml path('ma:author'), type
)
,(
select Music.Band.Name as [@ma:bandName]
from Music.Band
inner join Music.TrackPerformer
on Music.TrackPerformer.BandId = Music.Band.BandId
where (Music.TrackPerformer.TrackId = Music.Track.TrackId)
order by Music.Band.Name
for xml path('ma:band'), type
)
from Music.Title
inner join Music.Track
on Music.Track.TitleId = Music.Title.TitleId
where (Music.Track.AlbumId = Music.Album.AlbumId)
order by Music.Track.TrackNumber
for xml path('ma:track'), type
)
from Music.Title
inner join Music.Album
on Music.Album.TitleId = Music.Title.TitleId
order by Music.Album.Published
for xml path('ma:album'), root('ma:discography'), type
The queries to retrieve Person and Band data are nested inside the outer query used to retrieve Track data, which is nested inside the outermost query used to retrieve Album data. The result of each inner query is exposed to the outer query as a column of the outer query’s resultset, and its name is specified by the inner query’s PATH declaration of the FOR XML clause.
The outermost query also uses the PATH declaration specifying the destination XML node and the ROOT declaration specifying the root node of the destination XML entity.
The XML namespaces declaration at the beginning of the query provides all the necessary namespaces implemented by the corresponding Album XML Schema.
The queries presented in listings 11 and 12 are used in two SQL procedures, the definitions of which can be downloaded from http://www.manning.com/SQLServerMVPDeepDives.
Review both procedures carefully before creating them in the Discography database. Pay attention to the optional input parameters used by the procedures, and how they’re used in the queries to restrict the resultset.
Can you predict what would happen if the parameters weren’t specified when using the procedures to retrieve data?
Preparing the sample data
As the development of a client application to create and edit XML data is outside the scope of this chapter, you could resort to a generic solution such as Microsoft InfoPath, or design a custom application implementing the functionalities provided in this chapter, or even use a text editor to create XML data.
InfoPath, for instance, provides a fairly simple way of designing forms based on sample XML data or on an XML Schema, such as the two schemas used in this chapter.
In fact, the samples published to http://www.manning.com/SQLServerMVPDeep Dives have been created using two InfoPath forms based on the Album and the Band XML Schemas. These forms can also be downloaded from http://www.manning.com/SQLServerMVPDeepDives.
Homework
Even though this chapter spans several diverse subjects, it’s not as diverse as the reality it tries to imitate. We left a few gaps; for one, we haven’t considered all the facts about the discography business that can be observed in reality.
Here are some things you could do to improve this solution:
- Create additional sample data:
- Use the editor of your choice to add data to the sample XML entities.
- Design InfoPath forms based on the XML Schemas designed in this chapter.
- Design a custom client application implementing the XML Schemas and SQL procedures designed in this chapter.
- Extend the entities with additional attributes:
- Track Duration.
- Album Description.
- Lyrics.
- Think about other facts about discographies:
- Tracks aren’t performed by Bands; they’re performed by Musicians. Sometimes, Bands hire additional Musicians who aren’t Band Members to help them record.
- Musicians play (different) Instruments and perform in different Roles as Band Members.
- Persons join the Band at some time, and they can also leave the Band at some time. They can even join and leave a Band more than once.
- More people are involved in making an Album than Authors and Artists.
- Bands can share a Name, yet Bands with the same name rarely share their Origin.
- Think about data management as presented in this chapter and data management in general:
- Could the existing processes be optimized?
- Could the error handling in the procedures be improved in any way?
- What would be needed to support all data management operations (such as including Delete)?
- What other possibilities in terms of data analysis does the data model provide?
- Think about other possibilities of retrieving Album and/or Band data as XML corresponding to the appropriate XML Schema.
Summary
We took a real-life business and analyzed it, and interviewed an (imaginary) expert in the business and summarized his responses. We then collected all the facts and used them to design the logical model of the forthcoming software solution.
After applying a bit of good old normalization “magic,” we transformed the logical model into a physical model that we could then implement in the form of a SQL Server database, and also in the form of two XML Schemas.
The Discography database will serve as permanent storage for our discography data, and the schema-governed XML will serve as temporary storage and provide a way of transporting the data in and out of the permanent data store.
We’ve seen examples of the XML retrieval functionalities provided in Microsoft SQL Server’s T-SQL language. Essential information was provided regarding the XML standard, the XML Schema, the XML Query (or XQuery), the XPath expression and XPath predicates, and last but not least, the XML namespaces. This essential information provides a first step into the world of XML, and shows ways of bridging the gap between the world of XML and the world of SQL, using SQL Server 2005 or later.
About the author

Matija Lah graduated at the Faculty of Law at the University of Maribor, Slovenia, in 1999. As a lawyer with extensive experience in IT, in 2001 he joined IUS SOFTWARE d.o.o., the leading provider of legal information in Slovenia, where he first came into contact with Microsoft SQL Server. In 2005, he decided to pursue a career as a freelance consultant in the domain of general, business, and legal information. In 2006 this led him to join AI-in-Law Future Technologies, Inc., a company that applies artificial intelligence to the legal information domain. Based on his continuous contributions to the SQL community, Microsoft gave him the Most Valuable Professional award for SQL Server in 2007.