
Chapter 10. Introduction to XQuery on SQL Server
Starting with SQL Server 2005, Microsoft added built-in support for XML Query Language (XQuery). XQuery allows you to query your XML (Extensible Markup Language) data using a simple, yet powerful, path-style syntax. XQuery support makes it easy to
- Retrieve XML elements from XML content
- Extract scalar values from XML data
- Check for the existence of elements or values in XML data
- Modify your XML data via XML Data Manipulation Language (XML DML) extensions
SQL Server 2008 includes XQuery support with some slight improvements over the SQL Server 2005 release. This chapter is designed as an introduction to the XQuery functionality available in SQL Server. In this chapter we will assume little or no knowledge of XQuery in general.
What is XQuery?
XQuery is the XML Query Language, as defined by the World Wide Web Consortium (W3C) Recommendation at http://www.w3.org/TR/xquery/. The XQuery recommendation provides the syntax and semantics for a language for querying XML data. XML is a markup language that allows the creation of custom markup languages. SQL Server provides support for XQuery via the xml data type methods, listed in table 1.
Table 1. XML data type methods summary
|
xml data type method |
Description |
|---|---|
|
.exist() |
Checks for the existence of a node in your XML data |
|
.modify() |
Modifies the content of an XML document |
|
.nodes() |
Shreds XML content into relational data |
|
.query() |
Queries XML content using XQuery syntax |
|
.value() |
Extracts scalar values from XML content |
The primary means of querying XML data using XQuery is with a path-style syntax inherited directly from another W3C recommendation, the XML Path Language (XPath). XQuery and XPath path expressions look similar to an operating system file path you might enter at a command-line prompt. In fact, if you look at your XML data as similar to an operating system directory structure, you can immediately see the similarities. Consider the simple XML document in listing 1.
Listing 1. Simple XML document
<Math>
<Constants>
<e>2.71828183</e>
<pi>3.14159265</pi>
<square-root-2>1.41421356</square-root-2>
</Constants>
</Math>
If you were to view this XML document as a filesystem, it might look something like figure 1.
Figure 1. XML document viewed as a filesystem hierarchy

Like your filesystem, XML is structured hierarchically. If you wanted to access the contents of the pi file in your filesystem, you could use a file path like this:
MathConstantspi
Similarly, to access the contents of the <pi> element in the previous XML document, you’d use an XQuery path expression like this:
/Math/Constants/pi
XQuery paths come with several options that allow you to create more complex path expressions to query your XML. For instance, you can use the // axis step to locate any matching elements below the current element. Using // at the front of your path expression locates matching elements anywhere they occur in your XML document. For instance, the following path expression returns <Constants> elements anywhere they occur in your XML content:
//Constants
You can also use the wildcard character (*) in your path expression to match any node. The following path expression matches all elements under every <Constants> element wherever they occur in your XML content:
//Constants/*
The comparison of XML data to a hierarchical filesystem only goes so far. XML data can be much more complex in structure than a standard hierarchical filesystem. For example, you can have multiple elements with the same name in an XML document at the same level. Consider the XML data in listing 2, which has multiple <Colonel> elements at the same level.
Listing 2. XML with multiple instances of the same element at the same level
<Officers>
<Colonel id = "1">Harland Sanders</Colonel>
<Colonel id = "2">Tom Parker</Colonel>
<Colonel id = "3">Henry Knox</Colonel>
</Officers>
In order to query a specific <Colonel> element from the XML document, you need a method of differentiating them. XQuery provides predicates to fulfill this need. A predicate follows a path expression step and is enclosed in square brackets ([]). The predicate determines which element you want to retrieve. Only elements where the predicate evaluates to true are returned. As an example, consider a situation in which you want to return Colonel Tom Parker. Using the XML in listing 2, you could apply a path expression like the following:
/Officers/Colonel[. = "Tom Parker"]
In this case, the predicate compares the content of the <Colonel> elements to the string literal "Tom Parker". When it finds one that matches, the matching element is returned. In this example, it doesn’t make much sense to search for the string literal "Tom Parker", unless you are just checking to see if the name exists in your <Colonel> elements.
Using a different predicate, you can retrieve elements by their attributes. Note that each of the <Colonel> elements in the example has a related id attribute. You can retrieve Colonel Tom Parker from your XML data by using the id in the attribute, as shown in the following path expression:
/Officers/Colonel[@id = "2"]
This path expression returns Colonel Tom Parker because his <Colonel> element’s id attribute is set to 2.
Note
In XQuery, you differentiate attribute names from element names by prefixing attribute names with an at sign (@). In the previous example, the attribute id is specified as @id in the path expression.
XQuery predicates also provide access to a special function known as position(). You can use the position() function to return an element at a specific position in your XML data. You can also retrieve Colonel Tom Parker from the sample XML data using the position() function, as shown in the following path expression:
/Officers/Colonel[position() = 2]
You can also use a special type of predicate, known as a numeric predicate, which consists of a single integer number, as shown in the following path expression:
/Officers/Colonel[2]
The numeric predicate is functionally equivalent to using the position() function. It acts similarly to a 1-based array index. The numeric predicate in the example returns the second instance of a <Colonel> element that it encounters in the path expression—in this case the path expression retrieves the Colonel Tom Parker element.
How XQuery sees your XML
XQuery doesn’t process your XML in its textual form. Querying the text of your XML documents would have negative results, including the following:
- Storing the plain text of your XML documents would be inefficient.
- Querying the textual content of your XML documents would degrade performance, in many cases severely.
- Querying that relies on the raw textual representation of your XML documents would be inflexible, because you couldn’t assign data types to your XML document content.
In order to accommodate more efficient storage and querying, and to increase flexibility, XQuery converts your raw textual XML data to a format known as the XQuery/XPath Data Model (XDM). XDM relies on a tree-like representation of your textual XML document. Consider the XML content in listing 3.
Listing 3. Sample employee XML content
<employee id = "109">
<name>Ken J. Sánchez</name>
<title>CEO</title>
<date-of-hire>2002-10-12</date-of-hire>
</employee>
<employee id = "6">
<name>David Bradley</name>
<title>Marketing Mgr</title>
<date-of-hire>2003-01-04</date-of-hire>
</employee>
Note
The full W3C XDM recommendation is available at http://www.w3.org/TR/xpath-datamodel/.
This XML content is logically represented in XDM in a hierarchical form similar to that shown in figure 2.
Figure 2. XDM representation of an XML document

XDM provides an efficient hierarchical representation of raw XML textual data. XDM also allows you to type your XML data, so that you can manipulate XML content using numeric, date, or other type-specific operations.
Note
Creating typed XML instances in SQL Server requires the use of XML schemas, which are beyond the scope of this chapter.
Also keep in mind that when you store XML data in a SQL Server xml data type instance, it is automatically converted to XDM form internally. During the conversion process, SQL Server strips document type definitions (DTDs) and insignificant whitespace from your XML data. It also converts your XML character data content to typed binary representations.
The first thing to notice about the sample XDM representation is that, like your XML data, it’s hierarchical in structure. XDM converts XML elements and other markup structures (such as attributes and processing instructions) into logical nodes within the hierarchical tree structure.
Another interesting feature of XDM is that it can handle both well-formed XML (having a single root node) and XML content with multiple root nodes. The XML content in listing 3 has two <employee> root elements, meaning the content isn’t well-formed. XDM creates a single conceptual root node at the top of every XDM node hierarchy. This conceptual root node is indicated by the leading forward slash (/) in a path expression. The conceptual root node allows XQuery to easily query both non–well-formed XML fragments and well-formed XML documents.
Note
You can use the keyword DOCUMENT when declaring SQL Server xml data type columns or variables to restrict their contents to well-formed XML documents. Alternatively you can use the keyword CONTENT when your column or variable will contain XML data that has more than one root node, but is otherwise well-formed. I want to stress that although XML content can have more than one root node, it must follow all other rules for well-formed XML. In SQL Server terminology, the DOCUMENT and CONTENT keywords indicate facets that constrain your xml data. The default facet is CONTENT. More information is available in Books Online at http://msdn.microsoft.com/en-us/library/ms187339.aspx.
Querying XML
As we discussed in the section “What is XQuery?” SQL Server’s xml data type exposes several methods that allow you to query and manipulate XML data using XQuery. The .query() method is the most basic xml data type method. It accepts an XQuery expression and returns an XML result. Consider listing 4, which creates an xml data type variable, assigns an XML document to it, and then queries the document using the xml data type .query() method. The result is shown in figure 3.
Figure 3. Retrieving XML via the .query() method

Listing 4. Querying XML data
DECLARE @x xml;
SET @x = N'<?xml version = "1.0"?>
<definitions category = "Business Intelligence">
<concept>
<name>star schema</name>
<definition>
The star schema (sometimes referenced as star join schema) is the
simplest style of data warehouse schema. The star schema consists of
a few "fact tables" (possibly only one, justifying the
name) referencing any number of "dimension tables". The
star schema is considered an important special case of the snowflake
schema.
</definition>
<source>Wikipedia</source>
</concept>
<concept>
<name>snowflake schema</name>
<definition>
A snowflake schema is a logical arrangement of tables in a relational
database such that the entity relationship diagram resembles a
snowflake in shape. Closely related to the star schema, the snowflake
schema is represented by centralized fact tables which are connected
to multiple dimensions. In the snowflake schema, however, dimensions
are normalized into multiple related tables whereas the star
schema's dimensions are denormalized with each dimension being
represented by a single table.
</definition>
<source>Wikipedia</source>
</concept>
</definitions>';
SELECT @x.query(N'/definitions/concept[2]/name'),
As you can see, the XQuery path expression follows the hierarchical structure of the XML document. The first step of the path expression starts at the root of the XML document and then looks below to the <definitions> element. The second step uses a numeric predicate [2], indicating that the second occurrence of the <concept> element should be selected. Finally, the last step of the path expression indicates that the <name> element under the <concept> element should be retrieved.
The .value() method accepts both a path expression and a SQL Server data type. It returns a single scalar value from the XML data, cast to the appropriate data type. The SELECT query in listing 5 uses the .value() method on the xml data type variable defined in listing 4. The result is shown in figure 4.
Figure 4. Single scalar value returned by the .value() method

Listing 5. Retrieving a single scalar value
SELECT @x.value(N'(/definitions/concept[2]/name)[1]', N'nvarchar(100)'),
The entire path expression is wrapped in parentheses in this example, and a numeric predicate of [1] is used on the entire path expression. This ensures that only a single scalar value is returned. The .value() method will not accept any path expression that isn’t guaranteed, during the pre-execution static analysis phase of processing, to return a single scalar value.
Note
XQuery uses two-phase processing. Initially there’s a static analysis phase, during which XQuery checks syntax, data typing, and conformance to any special requirements (such as returning only a single node or single scalar value when necessary). XQuery performs pessimistic static type checking, meaning that it’ll throw errors during the static analysis phase whenever the path expression could potentially generate a static type error. After the static analysis phase, XQuery goes into the execution phase, where your path expression is evaluated against your data.
The xml data type also provides the .exist() method, which accepts a path expression and returns 1 if the query returns any nodes, and alternatively returns 0 if the query doesn’t return any nodes. Consider listing 6, which tells you whether the word dimensions appears in the character data of any of the <definition> elements in the XML data. This sample relies on the sample data used in listing 4. Results are shown in figure 5.
Figure 5. Results of using the .exist() method to check for node existence
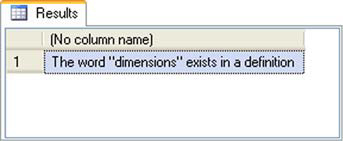
Listing 6. Confirming existence of a node
SELECT CASE @x.exist
(
N'/definitions/concept/definition[contains(., "dimensions")]'
)
WHEN 1 THEN N'The word "dimensions" exists in a definition'
WHEN 0 THEN N'The word "dimensions" doesn''t exist in a definition'
END;
Tip
Listing 6 introduces a new XQuery function, contains(), which works similarly to (but not exactly like) the SQL Server CHARINDEX() function to determine whether a given string is contained within your data. The full list of XQuery functions and operators (often referred to with the abbreviation F&O) available to SQL Server XQuery is available in Books Online at http://msdn.microsoft.com/en-us/library/ms189254.aspx.
In this example, we used a different predicate that uses the XQuery contains function. This function accepts a node and a string value. In this example, we used the period character (.), which indicates the current context node. The predicate returns true for every node that matches the predicate criteria. In this case, every node that contains the word dimensions returns true. The contains function (like XML in general, and by extension XQuery) is case sensitive. The .exist() method is most commonly used in the WHERE clause of SQL statements.
The .nodes() method allows you to shred your XML data or convert it into relational form. This method accepts a path expression and returns a relational result set of matching nodes as an xml data type column. The .nodes() method requires you to alias the result set and column name that will be returned. In listing 7, we used the alias Result for the returned result set and Col for the single xml data type column in that set. Again, this sample relies on the XML data introduced in listing 4. Partial results are shown in figure 6.
Figure 6. Shredding XML data with the .nodes() method

Listing 7. Shredding XML with the .nodes() method
SELECT Col.value(N'(./name)[1]', N'nvarchar(100)') AS [Name],
Col.value(N'(./definition)[1]', N'nvarchar(1000)') AS [Definition]
FROM @x.nodes(N'//concept') Result(Col);
Querying .nodes() results
Although the .nodes() method returns a result set of xml data type, it is a functionally limited version of the xml data type. You can’t query the result set instances directly. The only way to access the contents of the result set are through the use of the other xml data type methods, such as .value() or .query(). If you do try to query the contents directly, you’ll get an extremely verbose error message similar to the following:
Msg 493, Level 16, State 1, Line 35
The column 'Col' that was returned from the nodes() method cannot be
used directly. It can only be used with one of the four XML data type
methods, exist(), nodes(), query(), and value(), or in IS NULL and IS
NOT NULL checks.
FLWOR expressions
You can take advantage of powerful XQuery FLWOR expressions (an acronym for the XQuery keywords for-let-where-order by-return) in SQL Server. FLWOR expressions let you act on tuple streams as they’re generated by your path expression.
Note
In terms of XQuery, a tuple stream is a stream of nodes returned by a path expression. FLWOR expressions act on a tuple stream that’s generated by the for clause. The return clause returns the result of the tuple stream.
The FLWOR expression, at a minimum, requires a for clause and a return clause, as shown in listing 8. As in previous examples, listing 8 relies on the XML data introduced in listing 4. Results are shown in figure 7.
Figure 7. Result of a simple FLWOR expression

Listing 8. Querying XML with a FLWOR expression
SELECT @x.query
(
N'for $i in //name
return <topic>{$i/text()[1]}</topic>'
);
In this example, the for clause generates a tuple stream from the //name path expression and binds each tuple to the $i variable in turn. The tuple stream consists of the stream of tuples returned by each iteration of the for clause. The return clause returns the concatenated results generated by the tuple stream.
This simple FLWOR expression demonstrates an interesting feature of XQuery: XML construction. XML construction allows you to generate new XML content from source XML content. In this case, we’ve taken the content of every <name> element in the source XML document and reformatted that content as <topic> elements.
The let keyword allows you to bind tuples generated by the for clause tuple stream to variables. Consider listing 9, where we use the let clause to assign the character content of each <name> element to a variable named $j. The results are the same as those generated by listing 8.
Listing 9. Binding tuples to variables with the let clause
SELECT @x.query
(
N'for $i in //name
let $j := $i/text()[1]
return <topic>{$j}</topic>'
);
Note
The let clause wasn’t implemented in SQL Server 2005 XQuery, but is available in SQL Server 2008.
The order by clause allows you to sort your results. The FLWOR expression in listing 10 sorts the results in ascending order by the character content of the <name> elements. The results, shown in figure 8, are the reverse of those shown in figure 7.
Figure 8. Results of a FLWOR expression with the order by clause

Listing 10. Sorting tuples with the order by clause
SELECT @x.query
(
N'for $i in //name
let $j := $i/text()[1]
order by $j ascending
return <topic>{$j}</topic>'
);
The order by clause can accept the ascending or descending keywords to indicate sort direction. Ascending is the default if you don’t explicitly specify a sort order. If you don’t use an order by clause in your FLWOR expressions, results are always returned in document order. Document order is the default order in which elements occur in your XML document or data. The FLWOR expression order by clause is functionally similar to the T-SQL ORDER BY clause.
Finally, the FLWOR expression where clause allows you to limit the results returned with a predicate. The FLWOR expression’s where clause is analogous to the T-SQL WHERE clause. Listing 11 modifies the previous example slightly. This version adds a where clause that limits the results to only those where the content of the <source> element is equal to the string "Wikipedia".
Listing 11. Restricting results with the where clause
SELECT @x.query
(
N'for $i in //concept
let $j := ($i/name/text())[1], $k := ($i/source/text())[1]
where $k eq "Wikipedia"
order by $j ascending
return <topic>{$j}</topic>'
);
The predicate in the where clause uses the same operators as predicates in path expressions. These operators are described in the next section.
XQuery comparison operators
XQuery supports several operators for comparing values, nodes, and sequences. A sequence is an ordered collection of zero or more items. The items can be nodes or atomic values, although SQL Server supports only homogenous sequences, or those that don’t mix nodes and atomic values in a single XQuery sequence.
Note
The term ordered, as it applies to XQuery sequences, generally means document order as opposed to alphabetic or numeric order. In the XPath 1.0 recommendation, the concept of node sets is used instead of sequences. In node sets, the order is unimportant and duplicate nodes are disallowed. XQuery sequences stress the importance of order (as order is important in XML documents), and allow duplicate nodes.
Sequences are represented as follows in XQuery:
(10, 1, (2, 3), 5, 4, 6, 7, 8, 8, (), 9)
Sequences are a core concept within XQuery, and worth discussing further. Some of the important things to notice about the preceding sequence:
- Sequences in XQuery can be represented as comma-separated lists of values wrapped in parentheses.
- XQuery understands the concept of the empty sequence, represented by empty parentheses: ().
- XQuery sequences can contain subsequences, such as the (2, 3) sequence, which is a component of the larger sequence in the example.
- Sequences can contain numeric values, character strings, and values of other data types.
A sequence like the one shown is “flattened out” so that subsequences become part of the larger sequence, and empty sequences are removed. After this initial processing, the preceding sequence looks like the following to the XQuery processor:
(10, 1, 2, 3, 5, 4, 6, 7, 8, 8, 9)
An interesting and useful property of sequences is that any sequence containing only a single atomic scalar value is equivalent to that atomic scalar value. Because of this property, the sequence (3.141592) is equal to the atomic scalar value 3.141592, and the code sample in listing 12 returns a result of true.
Listing 12. Comparing a sequence with a single value to a scalar value
DECLARE @x xml;
SET @x = N'';
SELECT @x.query('(3.141592) eq 3.141592'),
XQuery supports several operators that can be used in expressions and predicates. These operators are listed in table 2.
Table 2. XQuery comparison operators
|
Value comparison operators |
General comparison operators |
||
|
eq |
Equal to |
= |
Equal to |
|
ne |
Not equal to |
!= |
Not equal to |
|
gt |
Greater than |
> |
Greater than |
|
ge |
Greater than or equal to |
>= |
Greater than or equal to |
|
lt |
Less than |
< |
Less than |
|
le |
Less than or equal to |
<= |
Less than or equal to |
|
Node comparison operators |
|||
|
is |
Node identity equality |
||
|
>> |
Left node follows right node |
||
|
<< |
Left node precedes right node |
||
XQuery comparison operators are classified in three groups, as shown in table 2. Value comparison operators are those operators that allow you to compare scalar atomic values to one another. Listing 13 demonstrates the lt value comparison operator. The result returned is true.
Listing 13. Comparing with the value comparison operators
DECLARE @x xml;
SET @x = N'';
SELECT @x.query('"ABC" lt "XYZ"'),
The second group of operators, general comparison operators, contains those operators classified as existential operators. Existential operators compare all atomic values contained in sequences on both sides of the operator, and if any of the comparisons return true, the result of the entire comparison is true. Consider the two general comparisons in listing 14.
Listing 14. Comparing sequences with general comparison operators
DECLARE @x xml;
SET @x = N'';
SELECT @x.query('(1, 2, 3) > (3, 4, 5)'),
SELECT @x.query('(1, 2, 3) = (3, 4, 5)'),
The first comparison uses the general comparison > (greater-than) operator. Because none of the scalar atomic values in the sequence on the left are greater than any of the scalar atomic values in the sequence on the right, the result of the entire comparison is false. The second comparison uses the = general comparison operator. Because the “3” in the sequence on the left is equal to the “3” in the sequence on the right, the result of the comparison is true.
The final group of operators consists of the node comparison operators. These operators allow you to compare nodes. In listing 15, the first expression uses the node comparison << operator to determine whether the /family/mother node appears before the /family/father node, in document order. The second expression uses the is operator to determine whether the first node returned by the //child path is the same as the first node returned by the /family/child path expression. The result of both expressions in the example is true.
Listing 15. Comparing nodes with the node comparison operators
DECLARE @x xml;
SET @x = N'<?xml version = "1.0"?>
<family surname = "Adams">
<mother>Morticia</mother>
<father>Gomez</father>
<child>Pugsley</child>
<child>Wednesday</child>
<uncle>Fester</uncle>
</family>';
SELECT @x.query('(/family/mother)[1] << (/family/father)[1]'),
SELECT @x.query('(//child)[1] is (/family/child)[1]'),
The is operator checks whether two nodes are actually the same node. Two nodes that might otherwise be considered equivalent (same node name, same character data content, and so on), but aren’t the exact same node, aren’t considered the same by the is operator.
XML indexes and XQuery performance
Whenever you query XML data on SQL Server, it is automatically converted to relational format behind the scenes. In this way, SQL Server can leverage the power of the relational query engine to fulfill XQuery queries. But on-the-fly shredding is an expensive process that can slow down overall processing. One answer to this problem is to use XML indexes. You can create a primary XML index on an xml data type column on a table to “pre-shred” your XML data. By pre-shredding the XML data, you avoid the overhead involved with on-the-fly shredding.
You can also create secondary XML indexes on your xml data type columns. These secondary XML indexes are relational indexes created on top of the primary XML index. You can choose from three types of secondary XML indexes, each designed to optimize access for different types of XQuery expressions. The creation and administration of XML indexes is beyond the scope of this chapter, but bear in mind that they’re available to help increase XQuery performance efficiency. The downside to XML indexes is that they can substantially increase the storage requirements for xml data type columns.
Note
More information on XML indexes is available at http://msdn.microsoft.com/en-us/library/ms191497.aspx.
Summary
This concludes our introduction to the basics of XQuery. XQuery is a powerful XML querying language, with far more features than we can cover in this introductory chapter. With built-in support for XQuery path expressions, standard XQuery comparison operators, FLWOR expressions, XML DML, and a wide variety of additional functions and operators, SQL Server provides a powerful XQuery implementation that can be used to query and manipulate XML on SQL Server.
About the author

Michael Coles is a SQL Server MVP and consultant based in New York City. Michael has written several articles and books on a wide variety of SQL Server topics, including Pro SQL Server 2008 XML and the Pro T-SQL 2008 Programmer’s Guide. He can be reached at http://www.sergeantsql.com.