
Chapter 9. Avoiding three common query mistakes
Writing correct and well-performing queries is both an art and a science. The query must return the expected results and execute in a reasonable time. Many blogs and articles have been written about improving query performance, but this chapter will focus on common mistakes that ultimately cause incorrect or incomplete data to be returned. These are problems I have frequently been asked to help solve or have encountered myself.
The examples in this chapter use SQL Server 2008 and the AdventureWorks2008 database that is available for download at http://www.codeplex.com. Search for “SQL Server 2008 code samples” on the site to find the latest release of the database. The queries will also work with the SQL Server 2005 version of the AdventureWorks database.
NULL comparisons
The NULL value means unknown; no value has been assigned. This is not the same as an empty string or zero. As long as the ANSI_NULLS setting is turned on, which is the default, comparing a value to NULL returns unknown. One usually expects a value of TRUE or FALSE when making comparisons, but unknown complicates matters under certain conditions.
When comparing a known value to NULL and unknown is returned, it effectively works the same as FALSE, and no results are returned. The AdventureWorks2008 database has a Production.Product table with a Color column that can contain NULLs. If you are trying to find all the products with the color red, you most likely do not want to see the products with no color assigned; therefore, this is not a problem. But if you would like a list of the products where the color does not equal red, you must decide whether or not the values with no assigned color belong in the results. If you intend for the NULL rows to be included, the criteria WHERE color <> 'red' will be incorrect.
Why is this the case? The expression value <> 'red' is the same as NOT(value = 'red'). If the value happens to be NULL, then unknown is the result of comparing the value to red within the parentheses. When applying NOT to unknown, the expression still returns unknown. Not FALSE is equal to TRUE, but not unknown is still unknown.
Listing 1 shows three ways to write a query to produce the partial results shown in figure 1. The second and third queries each use a function, ISNULL or COALESCE, to replace NULL with an empty string. This allows the color to be compared to the empty string instead of NULL.
Figure 1. NULL values are included along with the colors that have data.

Listing 1. Three queries to include NULL
SELECT ProductID, Color
FROM Production.Product
WHERE Color <> 'red' OR Color IS NULL
SELECT ProductID, Color
FROM Production.Product
WHERE ISNULL(Color,'') <> 'red'
SELECT ProductID, Color
FROM Production.Product
WHERE COALESCE(Color,'') <> 'red'
You also need to be careful when your expression contains the less-than operator (<). Again, the expression will return unknown when comparing a value to NULL.
Another query type that will leave T-SQL developers scratching their heads when NULLs are involved is using a subquery in the WHERE clause with NOT IN. If there is a NULL value returned in the subquery results, no rows will be returned from the outer query.
Suppose you have a table listing possible colors that could be used to populate the Color column in the Production.Product table, and you need to find out if any of the colors from the list are not used. A table of colors doesn’t exist in the AdventureWorks2008 database; therefore, let’s create our own. Run the code in listing 2 to create and populate the ColorList table.
Listing 2. The code to create the Production.ColorList table
CREATE TABLE Production.ColorList(
Color nvarchar(15) NOT NULL PRIMARY KEY)
GO
INSERT INTO Production.ColorList(Color)
SELECT Color FROM Production.Product
WHERE Color IS NOT NULL
GROUP BY Color
INSERT INTO Production.ColorList(Color)
VALUES('Purple'),('Orange'),('Lemon'),('Gold')
The Production.ColorList table contains all of the colors used in the Production.Product table and a few additional colors. To find the colors that haven’t been used in Production.Product, you might write the query in listing 3, but it will not return any results (see figure 2).
Figure 2. No results returned

Listing 3. Query returns no rows because of NULL values in the subquery
SELECT Color
FROM Production.ColorList
WHERE Color NOT IN (SELECT Color FROM Production.Product)
When the database engine processes the WHERE clause, each color in the Production.ColorList table is compared to the color values in the Production.Product table. Think of the subquery as a list of values that the Color column in the outer query will be compared to; for example, 'red','blue','green',NULL. When a color value from the Production.Product table is compared to the NULL value in the list, unknown is returned. Recall that unknown is not the same as False. When the NOT operator is applied, the answer is still unknown, and nothing shows up in the results.
Here is an example that illustrates this concept a bit more. Suppose you tried to compare the value “orange” to the list. This is equivalent to the following:
- 'orange' <> 'red'—True
- 'orange' <> 'blue'—True
- 'orange' <> 'green'—True
- 'orange' <> NULL—Unknown
Because unknown is returned, we don’t know if orange is in the list or not; therefore, orange does not show up in the results.
Listing 4 demonstrates how to write the query so that you get the correct results by filtering out the NULL values from the subquery. You can see the results in figure 3.
Figure 3. The list of colors not used in the Production.Product table
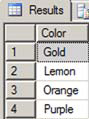
Listing 4. The correct code to find the list of unused colors
SELECT Color
FROM Production.ColorList
WHERE Color NOT IN (SELECT Color FROM Production.Product
WHERE Color IS NOT NULL)
Multiple OUTER JOINS
When you need to retrieve all the rows from one table in a join, even when there is not a matching row in the second table for every row in the first table, you must use an OUTER JOIN instead of an INNER JOIN. The query will return NULL values in the columns from non-matching rows in the second table.
Listing 5 is an example that shows the rows from Production.ColorList along with Production.Product data even when there are no rows in Production.Product that match. The results will contain NULL in the ProductID column when there isn’t a match. Figure 4 shows the results.
Figure 4. All rows from the Production.ColorList and the Production.Product rows that match. Non-matching rows return NULL in the ProductID column.
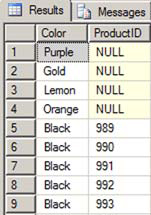
Listing 5. How to return all rows even if there isn’t a match
SELECT c.Color, p.ProductID
FROM Production.ColorList AS c
LEFT OUTER JOIN Production.Product AS p ON c.Color = p.Color
ORDER BY p.Color
Notice that the keyword LEFT is used in listing 5. That designates the position of the table that will return all rows. I prefer to use LEFT OUTER JOIN so that the main table is listed first. The query in listing 6 will produce the same results using a RIGHT OUTER JOIN.
Listing 6. The same results are returned when using a RIGHT OUTER JOIN.
SELECT c.Color, p.ProductID
FROM Production.Product AS p
RIGHT OUTER JOIN Production.ColorList AS c ON c.Color = p.Color
ORDER BY p.Color
If another table must be added to the query in listing 5, should you add it with an INNER JOIN, a RIGHT OUTER JOIN, or a LEFT OUTER JOIN? Well, that depends. If the new table joins the Production.Product table, it must be a LEFT OUTER JOIN because the columns of any of the non-matched rows from Production.Product will contain NULL values. The NULL values will be unable to join to the third table. In addition, any rows from Production.Product that do not appear in the Sales.OrderDetail table will drop out. When you use an INNER JOIN to join the third table, the non-matching rows from the main table will be eliminated.
The query in listing 7, joining the Sales.SalesOrderDetail table to the query from listing 5, is written incorrectly. The query eliminates the non-matching rows because rows with a NULL ProductID cannot match the Sales.SalesOrderDetail table (see figure 5).
Figure 5. The non-matching rows are lost.
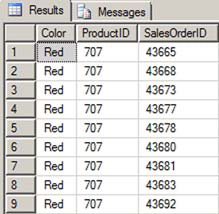
Listing 7. Non-matching rows lost when INNER JOIN follows LEFT OUTER JOIN.
SELECT c.Color, p.ProductID, d.SalesOrderID
FROM Production.ColorList AS c
LEFT OUTER JOIN Production.Product AS p ON c.Color = p.Color
INNER JOIN Sales.SalesOrderDetail AS d
ON p.ProductID = d.ProductID
ORDER BY p.ProductID
The correct way to write the query continues using LEFT OUTER JOIN down the LEFT OUTER JOIN path. The query in listing 8 does not eliminate the non-matching rows. Figure 6 shows that the rows with NULL ProductID values continue to show up in the results.
Figure 6. The correct results when the LEFT OUTER JOIN is continued

Listing 8. Using LEFT OUTER JOIN down the OUTER JOIN path
SELECT c.Color, p.ProductID, d.SalesOrderID
FROM Production.ColorList AS c
LEFT OUTER JOIN Production.Product AS p ON c.Color = p.Color
LEFT OUTER JOIN Sales.SalesOrderDetail AS d
ON p.ProductID = d.ProductID
ORDER BY p.ProductID
Another reason, besides listing the main table first, that I prefer to use LEFT instead of RIGHT, is that starting out with LEFT allows you to continue to use LEFT. When you start out with a RIGHT OUTER JOIN, you must switch to LEFT when adding the third table, which is confusing in my opinion. Listing 9 returns the same results and demonstrates how you must switch to LEFT when starting out with RIGHT.
Listing 9. Using a RIGHT OUTER JOIN followed by a LEFT OUTER JOIN
SELECT c.Color, p.ProductID, d.SalesOrderID
FROM Production.Product AS p
RIGHT OUTER JOIN Production.ColorList AS c ON c.Color = p.Color
LEFT OUTER JOIN Sales.SalesOrderDetail AS d ON p.ProductID = d.ProductID
ORDER BY p.ProductID
If you start out with LEFT, you can continue to use LEFT along that path as more tables are added.
If another table must be joined to the Production.ColorList table, the type of join to use depends on whether there will be any rows that don’t match. Whether to use an OUTER or INNER JOIN down a new path is not dependent on the previous join.
Incorrect GROUP BY clauses
Figuring out which columns belong in the GROUP BY clause in an aggregate query often aggravates T-SQL developers. The rule is that any column that is not part of an aggregate expression in the SELECT or ORDER BY clauses must be listed in the GROUP BY clause. That rule seems pretty simple, but I have seen many questions on forums about this very point.
If a required column is missing from the GROUP BY clause, you will not get incorrect results—you will get no results at all except for an error message. If extra columns are listed in the GROUP BY clause, no warning message will appear, but the results will probably not be what you intended. The results will be grouped at a more granular level than expected. I have even seen code that incorrectly included the aggregated column in the GROUP BY clause.
The query in listing 10 is missing the GROUP BY clause.
Listing 10. Missing the GROUP BY clause
SELECT COUNT(*), CustomerID
FROM Sales.SalesOrderHeader
Msg 8120, Level 16, State 1, Line 1
Column 'Sales.SalesOrderHeader.CustomerID' is invalid in the select list
because it is not contained in either an aggregate function or the GROUP
BY clause.
Listing 11 contains a query that lists the count of orders by CustomerID. The query includes the order date in the GROUP BY clause so that the results do not make sense. Figure 7 shows that there are multiple rows for each CustomerID value.
Figure 7. An extra column in the GROUP BY clause causes unexpected results.
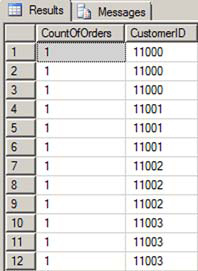
Listing 11. An extra column in the GROUP BY clause
SELECT COUNT(*) AS CountOfOrders, CustomerID
FROM Sales.SalesOrderHeader
GROUP BY CustomerID, OrderDate
ORDER BY CustomerID
Another issue to watch out for is including only the column in the GROUP BY clause when the column is used in an expression in the SELECT list. Say you want the results grouped by the year in which the orders were placed. If you leave the order date out of the GROUP BY clause, an error will result. If you add the column, the error goes away, but the results are not grouped as expected.
The query in listing 12 will not produce an error, but the results will not be as intended. We want a total for each year; therefore, there should only be one row per year. Figure 8 shows multiple rows for 2001 because the results are grouped by the order date.
Figure 8. Invalid results because OrderDate was included instead of the expression

Listing 12. This query runs, but the results are invalid.
SELECT COUNT(*) AS CountOfOrders,
YEAR(OrderDate) AS OrderYear
FROM Sales.SalesOrderHeader
GROUP BY OrderDate
ORDER BY YEAR(OrderDate)
The way to correct the query is to include the exact expression in the GROUP BY clause, not only the column. Listing 13 shows the corrected query with only four rows returned this time, one for each year (see figure 9).
Figure 9. The results when the expression is included in the GROUP BY clause
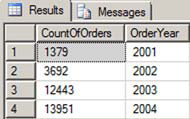
Listing 13. Writing the query so that the expression is used in the GROUP BY clause
SELECT COUNT(*) AS CountOfOrders,
YEAR(OrderDate) AS OrderYear
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate)
ORDER BY YEAR(OrderDate)
Summary
Learning to write T-SQL queries is not a skill you gain overnight. You must overcome many challenges along the way in order to write queries that return the expected results. Hopefully, this chapter will help you avoid three common mistakes.
Make sure you always think about NULL, especially when NOT, not equal to, or less than (<>, !=, or <) is part of the WHERE clause. Remember to continue LEFT OUTER JOIN down the OUTER JOIN path. And always check your GROUP BY clause to make sure that it contains the exact non-aggregate expressions and columns from the SELECT list and ORDER BY clause.
About the author

Kathi Kellenberger is a database administrator for Bryan Cave LLP, an international law firm headquartered in St. Louis, Missouri. She is coauthor of Professional SQL Server 2005 Integration Services (Wrox, 2006) and author of Beginning T-SQL 2008 (Apress, 2009). Kathi speaks about SQL Server for user groups and local events and has presented at PASS, DevTeach/SQLTeach, and SSWUG Virtual Conference. She has written over 25 articles, including her first one for SQL Server Magazine in July 2009. Kathi has been a volunteer for PASS since 2005, winning the PASSion award for her contributions to the organization in 2008.