
Chapter 3. Finding functional dependencies
Some people will tell you that properly normalizing your tables is hard. It’s not. The normalization rules are clear, and once you know all the functional dependencies in your data, you merely have to follow the rules carefully, taking care not to forget anything, and you’ll always end up with a properly normalized design.
The hard part comes before you can start normalizing—when you try to find all the functional dependencies. Considering how exact and well laid down the rules of normalization are, it’s surprising to find that there are no similar rules for finding the functional dependencies. For what use is a set of rules that guarantees a correct model from a correct set of functional dependencies if there’s no way to find that correct set of functional dependencies?
In this chapter, I’ll present a method to find all the functional dependencies. The only thing left for you to do is to find a domain expert who’s willing to answer your questions.
Interview method
Communication between domain experts and data modelers can be prone to misunderstandings. Once the interview gets beyond the basics, the domain expert can go into details that are far too advanced and complicated for the data modeler to understand, unless he’s a domain expert himself. And questions asked by the data modeler are often so abstract that the domain expert might misunderstand them, unless she has lots of experience with data modeling herself. To minimize the chance of misunderstandings, I use a technique that’s not used often in interviews, but has proven its worth many times: I use concrete examples (preferably in a notation familiar to the domain expert) instead of asking abstract questions.
To illustrate the benefits of this interview technique, let’s briefly assume that you, as a domain expert in the field of relational databases, are being interviewed by someone who has to make a data model for relational databases. At one point, this data modeler might ask you, “Can a table with a composite primary key be referenced by a foreign key constraint from more than a single table?” Before reading on, think about this question. Try to interpret what the data modeler wants, then answer the question.
Now what if the data modeler had instead asked you this: “Suppose I have TableA with a composite primary key made up of the columns Foo and Bar, TableB with a column Foo among others, and TableC with a column Bar among others. Is it allowed to define a foreign key constraint from the columns Foo and Bar in TableB and TableC, referencing Foo and Bar in TableA?” Would your answer still be the same? Or did you interpret the original question as being about two separate foreign key relationships, one from each of the referencing tables? I expect the latter, for after having worked with databases for some time, you’ve grown so accustomed to thinking in the patterns that make sense in the context of a database that you’re bound to interpret an ambiguous question in those patterns.
Although this illustrates the difference between an abstract question and a question asked by using a concrete example, it doesn’t show you the benefit of using a notation that’s familiar to the subject matter. But if you compare the data modeler’s second question to the exact same scenario depicted as a database diagram, as shown in figure 1, you’ll probably agree that this example makes the intention of the data modeler even easier to understand than either of the questions using words only.
Figure 1. A mocked-up database diagram makes it immediately obvious that this foreign key isn’t allowed.
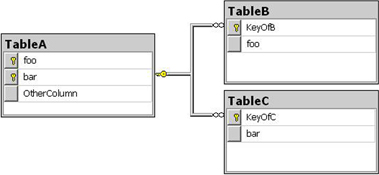
Figure 1 demonstrates that you can reduce the chance of misunderstandings by using concrete examples, preferably in a notation that the domain expert is familiar with. But it doesn’t help you to find functional dependencies. For that, you also need to know which questions to ask, and what conclusions to draw from the possible answers. I’ll cover that in the rest of the chapter, where I take on the role of the data modeler, trying to find the correct model for a sales order database.
Modeling the sales order
The sales order has to be one of the most standard and most downtrodden examples in the history of data modeling textbooks. Surely you don’t need any advanced techniques to find the functional dependencies for this example; you’ve seen it so often that you could build the relevant tables in your sleep. And that makes this an ideal example scenario for this chapter. Using a simple and recognizable example enables you to check my questions and the answers provided by the fictitious domain expert, and to see for yourself that the procedure of asking questions and drawing conclusions outlined in this chapter will indeed result in the correct data model—a statement you’d have to take for granted if I’d chosen to use a more complex example.
In real life, you won’t follow all steps exactly as I outline them here, but instead immediately conclude functional dependencies in case you feel confident that you’re sufficiently familiar with the domain, and use the detailed procedure in situations where you’re in doubt or have no idea at all. But for illustration purposes, I’ll presume that I (as the data modeler) am completely unfamiliar with the domain of sales orders, so I can’t assume anything, but have to ask the domain expert everything I need to know.
So let’s focus on WeTrade, Inc., a fictitious trading company, where I’m supposed to model the database for their sales orders. I’ve already acquired a sample order confirmation form (figure 2), which I used to determine that the data model would include the attributes OrderNo, CustomerName, CustomerID, Product, Qty, Price, TotalPrice, and OrderTotal.
Figure 2. A sample order confirmation form

The procedure for finding all functional dependencies is easier to perform if you first lay out all attributes in a simple tabular format, with the attribute names as column headers and some sample data below them. You need to start with at least one row of data, and you’re well advised to keep the number of rows low. I chose to use the contents of figure 2 as my starting data, so this table will look like table 1.
Table 1. Sample data in tabular format
|
OrderNo |
CustomerName |
CustomerID |
Product |
Qty |
Price |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|---|---|
|
7001 |
Northwind |
12 |
Gizmo |
10 |
12.50 |
125.00 |
225.00 |
|
7001 |
Northwind |
12 |
Dooble |
10 |
10.00 |
100.00 |
225.00 |
You’ll probably have noted that this table is already in first normal form. That should be the starting point. If at this stage there are multivalued attributes (for instance, an attribute Customer with contents of Northwind/12 and AdventureWorks/15) or repeating groups (for instance, attributes Product1, Product2, Product3, Qty1, Qty2, Qty3, TotalPrice1, TotalPrice2, and TotalPrice3), get rid of those first before you start the procedure to find functional dependencies.
First step: finding single-attribute dependencies
A functional dependency can be single-attribute (when a single attribute determines the dependent attribute) or multiattribute (when two or more attributes have to be combined to determine the dependent attribute). In the first step of the procedure, you’ll only search for single-attribute dependencies.
The definition of functional dependency implies that it’s never allowed to have two rows of data with the same value for the determining attribute but different values for the dependent attribute. I’ll leverage that knowledge by changing the sample data to include exactly those patterns and then asking the domain expert if the changed data would still be allowed.
First Attribute: OrderNo
Finding single-attribute functional dependencies is done on an attribute-by-attribute basis. I’ll start with OrderNo. I now have to either add a row or modify some existing data in my table so that I get a combination of two rows with the same value in the OrderNo column and different values in all other columns. I’ll modify some data, resulting in the data in table 2.
Table 2. Changing the data in the second row to find what attributes depend on OrderNo
|
OrderNo |
CustomerName |
CustomerID |
Product |
Qty |
Price |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|---|---|
|
7001 |
Northwind |
12 |
Gizmo |
10 |
12.50 |
125.00 |
250.00 |
|
7001 |
AdventureWorks |
15 |
Dooble |
12 |
10.00 |
100.00 |
200.00 |
We’ve already established that the best way to ask questions of the domain expert is to use concrete examples in a notation she’s familiar with. I have the concrete example, so all I need to do now is to transform it back into the familiar notation—that of an order confirmation form. The result is shown in figure 3.
Figure 3. Sample order confirmation modified to find which attributes depend on OrderNo

Note that there are sometimes different ways to represent the information from your table in a familiar format. For instance, in this case I used a single form with two customer names, two customer IDs, and two order totals. I could also have chosen to use two separate forms, one for each row in table 2. In fact, because I’m completely unfamiliar with the domain of sales orders, I should try both versions to make sure that I won’t conclude that the data isn’t allowed if the domain expert rejects an example that’s correct but incorrectly represented. To save space, I won’t include the two extra order confirmation forms I have to make to test the alternative representation.
When I showed my altered examples to the domain expert and asked her if these could be valid order confirmations, she told me that there were many problems. It’s not allowed to have two separate orders with the same order number, so this rules out the alternate representation I just described. But it’s also not allowed to have more than a single customer name or more than a single customer number on an order confirmation form. And finally, the total price of the order for 12 doobles doesn’t match the quantity and price, and neither of the order totals matches the sum of the individual total price values; all these numbers should match.
The last statement illustrates an important pitfall when using examples to find functional dependencies (or other constraints). A domain expert could reject an example for reasons other than what you’re trying to test. In this case, I wanted to know if more than one total price is allowed for a single order, but the domain expert rejects the example because a different business rule (total price = price * quantity) was violated. It’s important that you always verify why the domain expert rejects your example before jumping to conclusions.
Normally, the next step would be to correct the errors in the calculation of total price and order total and then consult the domain expert again. After all, the fact that she rejected the total price of the doobles because of a calculation error doesn’t imply that she’d also reject it if the calculation were correct—so far I’ve failed to create a proper test to check whether a single order can encompass more than a single total price. But in this case I can already see from the original example (figure 2), which is a correct example, that there can be multiple total prices for a single order, so there’s no need to test this column. This doesn’t fly for the order total, though. And no matter how hard I try, I quickly find that there’s no way to create an example with two order totals on a single order confirmation form that both match the sum of the individual total prices and yet are different. This shows that it’s impossible to have more than a single order total on a single order confirmation form, which is what I needed to know. I can already deduct this myself, so there’s no need to bother the domain expert with this.
Because the domain expert objected to associating multiple customer names or multiple customer IDs to a single order number and I could deduct that it’s impossible to associate multiple order totals with a single order number, I can now conclude that I’ve found three functional dependencies: CustomerName, CustomerID, and OrderTotal all are dependent on OrderNo.
Second Attribute: CustomerName
I obviously have to repeat the previous step for all attributes in the table. But I can save myself (and the domain expert) a lot of work if I take already-discovered functional dependencies into account.
In this case, because I already know that CustomerName is dependent on OrderNo, I also know that it’s impossible for attributes that don’t depend on OrderNo to depend on CustomerName. After all, if for instance Product depended on CustomerName, then it would as a result of the OrderNo → CustomerName dependency also transitively depend on OrderNo. And because I already established that Product doesn’t depend on OrderNo, there’s no way that it can depend on OrderNo. For this reason, I can exclude product, quantity, price, and total price from this round of testing.
I do still need to test the other columns, though. So I once more change the data from the original example to make sure that I get two rows with the same customer name, but different order number, customer ID, and order total. The result is shown in table 3.
Table 3. Another set of changed data, this time to test dependencies for CustomerName
|
OrderNo |
CustomerName |
CustomerID |
Product |
Qty |
Price |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|---|---|
|
7001 |
Northwind |
12 |
Gizmo |
10 |
12.50 |
125.00 |
125.00 |
|
7002 |
Northwind |
15 |
200.00 |
You’ll have noted that I left some cells empty. This is done deliberately, to draw your focus to the value combinations that I need to test for. I’ll next add in some values for the missing cells, taking particular care not to violate any of the already-identified functional dependencies or other business rules, and then I’ll once more transform this to the familiar notation of an order confirmation form before consulting the domain expert. I won’t include these steps here (nor for any of the following examples), to save space.
The domain expert informed me that there was nothing wrong with this new example. This shows that it’s great that I don’t have any knowledge about this domain, for I might otherwise have assumed that the combination of two customer IDs with the same customer name wouldn’t be allowed. Obviously, WeTrade, Inc., does business with different customers that share the same name.
Because the modified example wasn’t rejected, I can conclude that none of the attributes are functionally dependent on CustomerName.
Third Attribute: CustomerID
CustomerID is also functionally dependent on OrderNo, so I can again omit testing if any of the attributes Product, Qty, Price, or TotalPrice depend on CustomerID. This leaves the attributes OrderNo, CustomerName, and OrderTotal to be tested. For this, I create a new example order form based on the population in table 4.
Table 4. Testing functional dependencies for CustomerID
|
OrderNo |
CustomerName |
CustomerID |
Product |
Qty |
Price |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|---|---|
|
7001 |
Northwind |
12 |
Gizmo |
10 |
12.50 |
125.00 |
125.00 |
|
7002 |
AdventureWorks |
12 |
200.00 |
This time, the domain expert rejects the example. She tells me that it’s incorrect to have orders for the same customer ID but with different names—same customer ID should always imply same customer name. This leads me to the conclusion that CustomerName is functionally dependent on CustomerID. I already know that both CustomerName and CustomerID depend on OrderNo, which means I can deduct that OrderNo → CustomerName is a transitive dependency. Because third normal form disallows transitive dependencies in a table, I now know that I’ll end up with a separate table for CustomerID and CustomerName, and the latter removed from this table. I can choose to remove the column later and continue testing first (in which case I’ll have a complete set of dependencies when I’m done testing), or I can choose to remove this column now and continue my tests with the remaining attributes only (in which case I must take care not to forget testing the extra table just created, unless all possible dependencies have already been examined). I choose the latter—because the number of tests to perform increases more than linearly with the number of attributes in each table, I prefer to do the tests on several narrow tables rather than on one single wide table.
Next Attribute: Product
I haven’t yet found any attribute that Product depends on, so I can’t use the same argument used previously to exclude attributes without unknown dependency from the test. In this case, though, I can exclude the attributes that are already known to depend on some attribute. The reason for this is explained in the sidebar “Why can’t an attribute depend on two independent attributes?”
After having removed the transitively dependent attribute CustomerName and after modifying the remainder of the second row to test OrderNo, Qty, Price, and TotalPrice for dependency on Product, I got the data as shown in table 5.
Table 5. Testing functional dependencies for Product
|
OrderNo |
CustomerID |
Product |
Qty |
Price |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|---|
|
7001 |
12 |
Gizmo |
10 |
12.50 |
125.00 |
125.00 |
|
7002 |
Gizmo |
20 |
15 |
300.00 |
The domain expert rejected this modified example; she claimed that the same product would always have the same price. Obviously, price is functionally dependent on product, and this means that according to third normal form, we have to create a new table, with the product as the candidate key and including all attributes that depend on product (in this case, only price), which are then removed from the orders table. Once more, I choose to do this immediately. In this case, I need to make sure that I also create a test case to check whether there’s a functional dependency from Price to Product as well, but I won’t cover that in this chapter.
Why can’t an attribute depend on two independent attributes?
In the main text, I claim that it’s not required to test whether an attribute that depends on OrderNo (such as OrderTotal) also depends on an attribute that doesn’t depend on OrderNo (such as Product). The reason for this is because it’s impossible for an attribute to depend on two other attributes unless there’s at least one dependency between those two attributes. I already know that Product doesn’t depend on OrderNo, and I test for the reverse dependency in this step. If OrderNo depends on Product, then the transitive dependency from Product to OrderTotal is automatically implied and there’s no need to test for it. And if OrderNo doesn’t depend on Product, then there’s no way that OrderTotal could depend on it.
The reason for this impossibility is hard to explain in abstract terms, but obvious to explain by using a concrete example. Suppose we have two orders, one with order ID 1, product Gizmo, and an order total of $100.00, and the other with order ID 2, product Dooble, and an order total of $200.00. Because order total depends on order ID, order ID 1 can only be associated with an order total of $100.00. And if order total also depended on product, than the product Dooble should always be associated with an order total of $200.00. The absence of any functional dependency between order ID and product implies that it’s allowed to add a row with order ID 1 and product Dooble. But what should the order total of that row be? Product ID 1 implies it should be $100.00, but product Dooble implies it has to $ 200.00. The only possible conclusion is that this particular set of functional dependencies can’t exist.
The Remaining Attributes
After removing Price from the table, I still have three attributes left to test for single-attribute dependencies: Qty, TotalPrice, and OrderTotal. The first two are exactly like Product: I haven’t yet found any dependency for them. And OrderTotal is exactly like CustomerName and CustomerID, because it also depends on OrderNo. So the same rules apply when testing the functional dependencies for these three attributes. The modified data I used to test these attributes is represented in tables 6, 7, and 8.
Table 6. Testing functional dependencies for Qty
|
CustomerID |
Product |
Qty |
TotalPrice |
OrderTotal |
|
|---|---|---|---|---|---|
|
7001 |
12 |
Gizmo |
10 |
125.00 |
125.00 |
|
7002 |
Dooble |
10 |
170.00 |
Table 7. Testing functional dependencies for TotalPrice
|
OrderNo |
CustomerID |
Product |
Qty |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|
|
7001 |
12 |
Gizmo |
10 |
125.00 |
125.00 |
|
7002 |
Dooble |
20 |
125.00 |
Table 8. Testing functional dependencies for OrderTotal
|
OrderNo |
CustomerID |
Product |
Qty |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|
|
7001 |
12 |
Gizmo |
10 |
125.00 |
125.00 |
|
7002 |
15 |
125.00 |
None of these examples were rejected by the domain expert, so I was able to conclude that there are no more single-column dependencies in this table.
Note that I didn’t produce these three examples at the same time. I created them one by one, for if there had been more functional dependencies I could’ve further reduced the number of tests still needed. But because there turned out to be no more dependencies, I decided to combine them in this description, to save space and reduce the repetitiveness.
Second step: finding two-attribute dependencies
After following the preceding steps, I can now be sure that I’ve found all the cases where an attribute depends on one of the other attributes. But there can also be attributes that depend on two, or even more, attributes. In fact, I hope there are, because I’m still left with a few attributes that don’t depend on any other attribute. If you ever run into this, it’s a sure sign of one or more missing attributes on your shortlist—one of the hardest problems to overcome in data modeling.
The method for finding multiattribute dependencies is the same as that for single-attribute dependencies—for every possible combination, create a sample with two rows that duplicate the columns to test and don’t duplicate any other column. If at this point I hadn’t found any dependency yet, I’d be facing an awful lot of combinations to test. Fortunately, I’ve already found some dependencies (which you’ll find is almost always the case if you start using this method for your modeling), so I can rule out most of these combinations.
At this point, if you haven’t already done so, you should remove attributes that don’t depend on the candidate key or that transitively depend on the primary key. You’ll have noticed that I already did so. Not moving these attributes to their own tables now will make this step unnecessarily complex.
The key to reducing the number of possible combinations is to observe that at this point, you can only have three kinds of attributes in the table: a single-attribute candidate key (or more in the case of a mutual dependency), one or more attributes that depend on the candidate key, and one or more attributes that don’t depend on the candidate key, or on any other attribute (as we tested all single-attribute dependencies). Because we already moved attributes that depend on an attribute other than the candidate key, these are the only three kinds of attributes we have to deal with. And that means that there are six possible kinds of combinations to consider: a candidate key and a dependent attribute; a candidate key and an independent attribute; a dependent attribute and an independent attribute; two independent attributes; two dependent attributes; or two candidate keys. Because alternate keys always have a mutual dependency, the last category is a special case of the one before it, so I won’t cover it explicitly. Each of the remaining five possibilities will be covered below.
Candidate Key and Dependent Attribute
This combination (as well as the combination of two candidate keys, as I already mentioned) can be omitted completely. I won’t bother you with the mathematical proof, but instead will try to explain in language intended for mere mortals.
Given three attributes (A, B, and C), if there’s a dependency from the combination of A and B to C, that would imply that for each possible combination of values for A and B, there can be at most one value of C. But if there’s also a dependency of A to B, this means that for every value of A, there can be at most one value of B—in other words, there can be only one combination of A and B for every value of A; hence there can be only one value of C for every value of A. So it naturally follows that if B depends on A, then every attribute that depends on A will also depend on the combination of A and B, and every attribute that doesn’t depend on A can’t depend on the combination of A and B.
Candidate Key and Independent Attribute
For this combination, some testing is required. In fact, I’ll test combination first, because it’s the most common—and the sooner I find extra dependencies, the sooner I can start removing attributes from the table, cutting down on the number of other combinations to test.
But, as before, it’s not required to test all other attributes for dependency on a given combination of a candidate key and an independent attribute. Every attribute that depends on the candidate key will also appear to depend on any combination of the candidate key with any other attribute. This isn’t a real dependency, so there’s no need to test for it, or to conclude the existence of such a dependency.
This means that in my example, I need to test the combinations of OrderNo and Product, OrderNo and Qty, and OrderNo and TotalPrice. And when testing the first combination (OrderNo and Product), I can omit the attributes CustomerID and OrderTotal, but I do need to test whether Qty or TotalPrice depend on the combination of OrderNo and Price, as shown in table 9. (Also note how in this case I was able to observe the previously-discovered business rule that TotalPrice = Qty x Price—even though Price is no longer included in the table, it is still part of the total collection of data, and still included in the domain expert’s familiar notation.)
Table 9. Testing functional dependencies for the combination of OrderNo and Product
|
OrderNo |
CustomerID |
Product |
Qty |
TotalPrice |
OrderTotal |
|---|---|---|---|---|---|
|
7001 |
12 |
Gizmo |
10 |
125.00 |
225.00 |
|
7001 |
Gizmo |
12 |
150.00 |
The domain expert rejected the sample order confirmation I based on this data. As reason for this rejection, she told me that obviously, the orders for 10 and 12 units of Gizmo should’ve been combined on a single line, as an order for 22 units of Gizmo, at a total price of $375.00. This proves that Qty and TotalPrice both depend on the combination of OrderNo and Product. Second normal form requires me to create a new table with the attributes OrderNo and Product as key attributes, and Qty and TotalPrice as dependent attributes. I’ll have to continue testing in this new table for two-attribute dependencies for all remaining combinations of two attributes, but I don’t have to repeat the single-attribute dependencies, because they’ve already been tested before the attributes were moved to their own table. For the orders table, I now have only the OrderNo, CustomerID, and OrderTotal as remaining attributes.
Two Dependent Attributes
This is another combination that should be included in the tests. Just as with a single dependent attribute, you’ll have to test the key attribute (which will be dependent on the combination in case of a mutual dependency, in which case the combination is an alternate key) and the other dependent attributes (which will be dependent on the combination in case of a transitive dependency).
In the case of my sample Orders table, I only have two dependent attributes left (CustomerID and OrderTotal), so there’s only one combination to test. And the only other attribute is OrderID, the key. So I create the test population of table 10 to check for a possible alternate key.
Table 10. Testing functional dependencies for the combination of CustomerID and OrderTotal
|
OrderNo |
CustomerID |
OrderTotal |
|---|---|---|
|
7001 |
12 |
125.00 |
|
7002 |
12 |
125.00 |
The domain expert saw no reason to reject this example (after I populated the related tables with data that observes all rules discovered so far), so there’s obviously no dependency from CustomerID and OrderTotal to OrderNo.
Two Independent Attributes
Because the Orders table used in my example has no independent columns anymore, I can obviously skip this combination. But if there still were two or more independent columns left, then I’d have to test each combination for a possible dependency of a candidate key or any other independent attribute upon this combination.
Dependent and Independent Attributes
This last possible combination is probably the least common—but there are cases where an attribute turns out to depend on a combination of a dependent and an independent attribute. Attributes that depend on the key attribute can’t also depend on a combination of a dependent and an independent column (see the sidebar a few pages back for an explanation), so only candidate keys and other independent attributes need to be tested.
Further steps: three-and-more-attribute dependencies
It won’t come as a surprise that you’ll also have to test for dependencies on three or more attributes. But these are increasingly rare as the number of attributes increases, so you should make a trade-off between the amount of work involved in testing all possible combinations on one hand, and the risk of missing a dependency on the other. The amount of work involved is often fairly limited, because in the previous steps you’ll often already have changed the model from a single many-attribute relation to a collection of relations with only a limited number of attributes each, and hence with a limited number of possible three-or-more-attribute combinations.
For space reasons, I can’t cover all possible combinations of three or more attributes here. But the same logic applies as for the two-attribute dependencies, so if you decide to go ahead and test all combinations you should be able to figure out for yourself which combinations to test and which to skip.
What if I have some independent attributes left?
At the end of the procedure, you shouldn’t have any independent attributes left—except when the original collection of attributes was incomplete. Let’s for instance consider the order confirmation form used earlier—but this time, there may be multiple products with the same product name but a different product ID. In this case, unless we add the product ID to the table before starting the procedure, we’ll end up with the attributes Product, Qty, and Price as completely independent columns in the final result (go ahead, try it for yourself—it’s a great exercise!).
So if you ever happen to finish the procedure with one or more independent columns left, you’ll know that either you or the domain expert made a mistake when producing and assessing the collections of test sample data, or you’ve failed to identify at least one of the candidate key attributes.
Summary
I’ve shown you a method to find all functional dependencies between attributes. If you’ve just read this chapter, or if you’ve already tried the method once or twice, it may seem like a lot of work for little gain. But once you get used to it, you’ll find that this is very useful, and that the amount of work is less than it appears at first sight.
For starters, in a real situation, many dependencies will be immediately obvious if you know a bit about the subject matter, and it’ll be equally obvious that there are no dependencies between many attributes. There’s no need to verify those with the domain expert. (Though you should keep in mind that some companies may have a specific situation that deviates from the ordinary.)
Second, you’ll find that if you start by testing the dependencies you suspect to be there, you’ll quickly be able to divide the data over multiple relations with relatively few attributes each, thereby limiting the number of combinations to be tested.
And finally, by cleverly combining multiple tests into a single example, you can limit the number of examples you have to run by the domain expert. This may not reduce the amount of work you have to do, but it does reduce the number of examples your domain expert has to assess—and she’ll love you for it!
As a bonus, this method can be used to develop sample data for unit testing, which can improve the quality of the database schema and stored procedures.
A final note of warning—there are some situations where, depending on the order you choose to do your tests, you might miss a dependency. You can find them too, but they’re beyond the scope of this chapter. Fortunately this will only happen in cases where rare combinations of dependencies between attributes exist, so it’s probably best not to worry too much about it.
About the author

Hugo is cofounder and R&D lead of perFact BV, a Dutch company that strives to improve analysis methods and to develop computer-aided tools that will generate completely functional applications from the analysis deliverable. The chosen platform for this development is SQL Server.
In his spare time, Hugo likes to share and enhance his knowledge of SQL Server by frequenting newsgroups and forums, reading and writing books and blogs, and attending and speaking at conferences.