
1
Introducing Model Serving
While machine learning (ML) surprises us every day with new, stunning ideas and demos, a burning question remains: how can we make the model available to our users? Often, we see demos of models on different blogs, books, YouTube videos, and so on, and we remain hungry to use the models ourselves. This is where model serving comes into the picture. Model serving is how we make our models available for use.
In this chapter, we will learn the definition of model serving, the importance of model serving, the challenges that make model serving difficult, and how people currently serve models, and see some of the available tools used for model serving.
By the end of this chapter, we will understand what model serving is, why model serving is needed, what makes it different from traditional web serving, and how people currently deploy/serve models.
In this chapter, we are going to cover the following main topics:
- What is serving?
- What are models?
- What is model serving?
- Understanding the importance of model serving
- Challenges of serving models
- Using existing tools to serve models
Technical requirements
This chapter does not require you to follow along with any hands-on exercises. However, there are some examples used from the BentoML official site: https://docs.bentoml.org/en/latest/tutorial.html.
If you want to try those examples on your local machine, please feel free to install a local version of BentoML following the simple installation instructions here: https://docs.bentoml.org/en/latest/installation.html.
Basically, you need to install BentoML like other Python packages using the following command:
pip install bentoml
Feel free to follow the quick get-started link to understand the steps involved in model serving, which are highlighted in a later section in this chapter.
What is serving?
Serving is an important step for ensuring the business impact of the applications when we develop the life cycle of application development. The application we have developed needs to be available to the user so that they can use it. For example, let’s say we have developed a game. After the development, if the game just stays on the developer’s machine, then it is not going to be of any use to the users. So, the developer needs to bring the game to the users by serving it through a serving platform such as Apple Store, Google Play Store, and web servers.
So, serving can be seen as a mechanism to distribute our applications/services to end users. The end users can be different based on the applications/services we develop. Serving creates a bridge of communication between the two parties: the developer and the users. This bridge is vital for the business success of our application. If we don’t have people using our service, then we are not gaining any business value or impact from the applications we’ve developed. That’s what we have seen in the past when big corporate companies’ servers go down for some time: they incur a huge amount of loss. Facebook (Meta) lost ~65 million US dollars due to its outage for some hours in October 2021, as per Forbes: https://www.forbes.com/sites/abrambrown/2021/10/05/facebook-outage-lost-revenue/?sh=c1d7d03231ad.
The development-to-serving process usually forms the life cycle of the service or application.
For example, let’s consider the life cycle of web application development in Figure 1.1.

Figure 1.1 – Web development life cycle
The developer develops the website. Then, the website is served using a web server. Only after that are the users able to use the website. The cycle can continue through collecting feedback from users, improving the website, and serving again on the web server.
Now we know what serving is, let’s look at what we are actually serving.
What are models?
There are a lot of definitions of models from the perspective of various domains. When we define a model or use the term model in this book, we will consider it in the context of ML. A model in ML can be seen as a function that has been fine-tuned through training, using some well-engineered data so that the function can recognize and distinguish patterns in unseen data.
Depending on the problem and business goal, a different model can be used, for example, a linear regression model, a logistic regression model, a naive Bayes model, or a decision tree model. These models’ underlying logical representations are different from each other. However, we use the generic term model and the problem domain and name of the ML algorithm to give us a clear picture of what the model is, how it was trained, and how the model is represented. For example, if we are told that the model is for linear regression, then we know that it was trained by minimizing a cost function iteratively using the training data, and it can be saved by storing the regression parameters’ coefficients and intercepts. Similarly, other models will have different algorithms for training and storing. For a deep learning model, we might have to use forward propagation and backward propagation for training, and for storing we might have to store the weights and biases of all the layers.
The trained model can be stored in different formats to load later for serving and inference. Some popular formats in which to save a model are as follows:
- ONNX
- YAML
- Protobuf
- Pickle
- JSON
- H5
- TFJS
- Joblib
However, model-serving tools usually require the models to be saved in a particular format. So, they provide a function to save the model in its desired format. There are also tools and libraries to convert models from one format to another. For example, in Figure 1.2, we see that an AlexNet model that is pre-trained in PyTorch is loaded and exported to ONNX format in a file named alexnet.onnx.
PyTorch files
It’s worth knowing that PyTorch saves the model using the Python pickle (https://docs.python.org/3/library/pickle.html) library. For further reading on PyTorch strategies for saving and loading models, please check out their official documentation: https://pytorch.org/tutorials/beginner/saving_loading_models.html.

Figure 1.2 – Example code converting a PyTorch pre-trained AlexNet model to ONNX format
Note
Figure 1.2 is an example from the PyTorch official website: https://pytorch.org/docs/stable/onnx.html#example-alexnet-from-pytorch-to-onnx.
Now we should have a good idea about models and how each model is represented and stored. The following section will introduce us to model serving.
What is model serving?
Like serving a website, we need to serve the trained model so that the model can be used for making predictions to perform business goals. Web/software serving is already at a mature stage. So, we have sophisticated, agreed-upon tools and strategies to serve software. However, ML model serving is still in the phase of growth, and new ideas and tools are coming almost every day.
Model serving can be defined as bringing a model to production by deploying it to a location and providing some access points for users to pass data for prediction and get prediction results.
Model serving usually involves the following steps:
- Saving the trained model: The format in which the model needs to be saved can be different based on the serving tool. So, usually, the serving tools provide a function for saving the model to ensure the model is saved in a format needed by the library.
Let’s use BentoML as an example. We’ll cover BentoML in more detail in Chapter 14, but in the following code snippet taken from the BentoML official site, https://docs.bentoml.org/en/latest/tutorial.html, we see that the popular model-serving library BentoML provides a save function for each of the ML frameworks. During serving using BentoML, we have to call the save method on the appropriate framework. For example, if we have developed a model using sklearn, we need to call the bentoml.sklearn.save_model(<MODEL_NAME>, model) method to save the model in BentoML format from sklearn format:
import bentoml
from sklearn import svm
from sklearn import datasets
# Load training data set
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Train the model
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
# Save model to the BentoML local model store
saved_model = bentoml.sklearn.save_model("iris_clf", clf)
print(f"Model saved: {saved_model}")
# Model saved: Model(tag="iris_clf:zy3dfgxzqkjrlgxi")We can see the list of ML frameworks BentoML currently supports in its GitHub code repository: https://github.com/bentoml/BentoML. At the time of writing, they support the following frameworks shown in Figure 1.3. We will discuss BentoML in detail in Chapter 14.
Figure 1.3 – BentoML-supported frameworks. Some of these are still in the experimental phase
- Annotate the access points: In this stage, we usually create a service module where we create a function that will be executed when a user makes a request for a prediction. This method is annotated so that after deployment to the model-serving tool, it is exposed via a REST API. BentoML uses a special file, called a service.py file, to do this annotation and defining the method that will be annotated. For example, let’s look at the classify(..) method in the service.py file. It has been annotated with svc.api() and the input/output formats are also specified. The service.py code is annotated with the service access point:
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get( "iris_clf:latest").to_runner()
svc = bentoml.Service("iris_classifier", runners=[ iris_clf_runner])@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
result = iris_clf_runner.predict.run( input_series)
return result
- Deploy the saved model to a model-serving tool: In this stage, the model is stored or uploaded to a location needed by the library. Usually, the library takes care of the process behind the scenes and you just need to start the deployment by triggering a command. Sometimes, before deploying a special library, specific packaging might be needed. For example, BentoML creates a special deployable package called a Bento. To build a Bento, you need to first create a bentofile.yaml file in the project directory with which to provide the different parameters of the Bento. A sample bentofile.yaml file is shown in Figure 1.4.
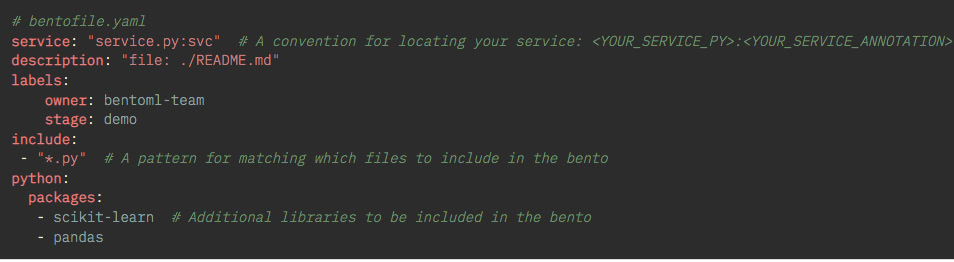
Figure 1.4 – A sample bentofile.yaml file that needs to be created before building a Bento
After that, we can create a Bento using the bentoml build command from the command line. The command will build the Bento and you will see some messages in the console, as in Figure 1.5.
Figure 1.5 – Sample bentoml build output
Please keep in mind that running the bentoml build command in a directory with venv can take a long time because it scans the whole directory before running the command. This example was run without creating a virtual environment.
Bentos will be saved in a local directory. We can see the Bentos using the bentoml list command, as in Figure 1.6.

Figure 1.6 – All the Bentos can be seen using the bentoml list command
Then, from the console, we can run the bentoml serve <MODEL_NAME:TAG> --production command to serve the model. <TAG> can be replaced by the appropriate tag, shown in Figure 1.6.
- Version controlling of the model: The model-serving tool also takes care of the version controlling behind the scenes for you. When a new version is uploaded, the APIs exposed from the model-serving tool use the latest model. For example, BentoML uses Tag to refer to different versions. To serve the latest version, you can use <MODEL_NAME:latest>. This will pick up the latest-<MODEL_NAME>.
In this section, we got a high-level understanding of model serving. In the next section, we will discuss the importance of model serving.
Understanding the importance of model serving
Model serving is one of the critical steps in the ML life cycle but is often neglected. As shown in Figure 1.7, users can only start using the model after serving is done. So, model serving is the key step to the business success of a data science or ML team.
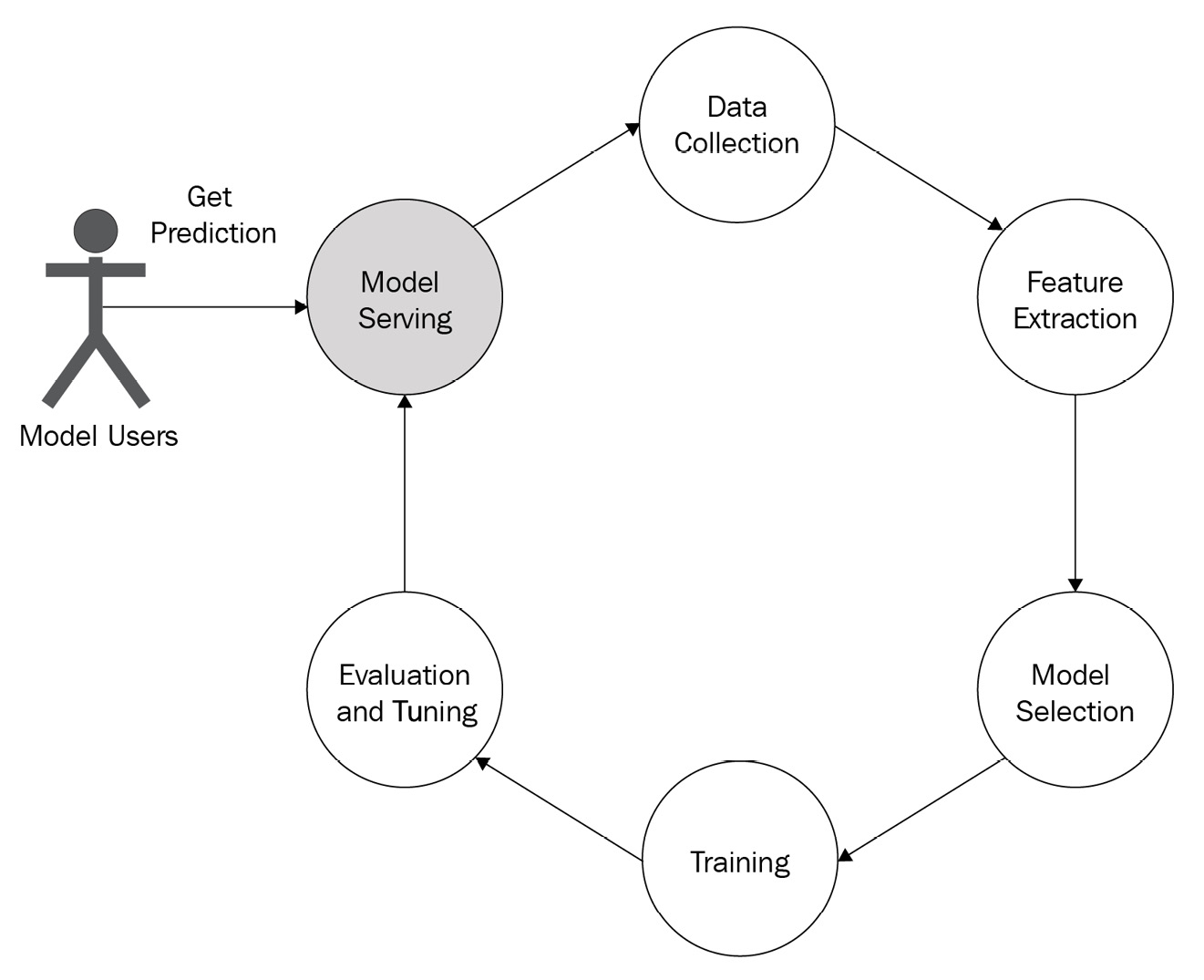
Figure 1.7 – ML life cycle
A lot of models remain unserved simply because model serving is hard. This happens mainly due to the following reasons:
- Separation of responsibilities: Often, model development is assigned to data scientists and serving is assigned to engineers, and there may be a gap between the domain knowledge of the two groups. For example, consider a data scientist who has developed a model using a notebook and is getting some predictions and a software engineer who will be serving the model. The product manager is asking for the model to be provided on a server in a production-ready state but some challenges come up:
- How should they save the model?
- Are the tools the software engineer is using compatible with the model the data scientist has developed?
- Data scientists tend to use a lot of fancy libraries to make models; are all those libraries supported in the platform the software engineering team is using?
- How will they maintain the version of the model? Is the model developed by data scientists easily maintainable?
- What kind of serving mechanism is needed?
- Which endpoint needs to be published for prediction?
- How does the data from users need to be processed on the server?
Challenges like this create barriers to serving a model after development.
- Choice of tool: Tool after tool is appearing for serving models. It makes serving more challenging, as a particular tool may be the perfect choice for a particular type of model, and you need to know which tool is best for which model type. For example, for a simple model, simple REST APIs developed using Flask may be sufficient. However, for complex models, developing a Flask API can be less effective as it was not developed to serve the purpose of stateful client-server communication. Switching from one tool to another can be a problem, and identifying which tool is better for which problem might be challenging. Therefore, as the volume of tools increases, the volume of confusion and challenges in model serving keep increasing.
- Versioning: In software engineering, the versioning of software is very easy. We need to redeploy the new updates through a continuous integration/continuous deployment (CI/CD) pipeline for a software application. However, in model serving, versioning is challenging because it involves new feature engineering, retraining with new data, and evaluation. Ensuring backward compatibility is not an easy task as it can lead to an error state in ML. Versioning models can be frustrating.
- Rollback: In software engineering, let’s say deployment to production is behaving incorrectly after the last change; we can then easily roll back the last change and go back to the previous state very quickly. However, in model serving, we cannot take advantage of this shortcut to roll back to the last model.
The preceding points gave us an idea about the challenges involved in model serving. In the following section, we will introduce you to some existing tools for model serving.
Using existing tools to serve models
There are a lot of tools to serve models available now. Some popular tools include the following:
- BentoML (https://www.bentoml.com/)
- MLflow (https://mlflow.org/)
- KServe (https://kserve.github.io/website/0.8/)
- Seldon core (https://www.seldon.io/solutions/open-source-projects/core)
- Cortex (https://www.cortex.dev/)
- TensorFlow Serving (https://www.tensorflow.org/tfx/guide/serving)
- TorchServe (https://pytorch.org/serve/index.html)
- Ray Serve (https://www.ray.io/ray-serve)
- Multi Model Server (MMS) (https://github.com/awslabs/multi-model-server)
- ForestFlow (https://github.com/ForestFlow/ForestFlow)
- DeepDetect (https://www.deepdetect.com/overview/introduction)
- Some examples of app-serving tools are CoreML and TensorFlow.js
There are many other tools being developed and made available to users. We will discuss a few of these tools in detail along with examples in the last part of this book.
Sometimes, developers also use very basic REST APIs developed using Flask or FastAPI if the model is simple and does not need frequent updates. This helps software engineers just follow the web development serving life cycle instead of the complex ML model serving life cycle.
These tools aim to reduce the challenges involved in model serving and make resilient model serving easier. However, the availability of a large number of tools also gives rise to confusion in choosing the best tool.
We have now discussed the advantages and challenges of model serving and also introduced some currently available tools for model serving.
Summary
In this chapter, we learned about serving, model serving, and the challenges involved. We learned that model serving is one of the hardest steps in the ML life cycle and, for that reason, is often neglected.
We started our discussion by giving a definition of models and discussing how models are stored. We have seen how models can be stored in a number of formats for serving. However, when using a particular tool for serving, we need to take care to use the format required by that tool.
Then, we discussed model serving. We saw some examples from BentoML, showing the different steps involved. We got an idea of how serving tools can aid you in removing the challenges of model serving.
Then, we discussed the challenges in model serving along with the importance of model serving.
We concluded by introducing you to some existing tools.
In the next chapter, we will introduce you to different model-serving patterns and give a high-level overview of different kinds of patterns we can follow during model serving to make serving resilient and scalable and create a better user experience.