
Much of what is loosely considered to be a part of “HTML5” isn’t, strictly speaking, HTML at all—it’s a set of additional APIs that provide a wide variety of tools to make our websites even better. We introduced the concept of an API way back in Chapter 1, but here’s a quick refresher: an API is an interface for programs. So, rather than a visual interface where a user clicks on a button to make something happen, an API gives your code a virtual “button” to press, in the form of a method it calls that gives it access to a set of functionality. In this chapter, we’ll walk you through a few of the most useful of these APIs, as well as give you a brief overview of the others, and point you in the right direction should you want to learn more.
With these APIs, we can find a visitor’s current location, make our website available offline as well as perform faster online, and store information about the state of our web application so that when a user returns to our site, they can pick up where they left off.
Warning: Here There be Dragons
A word of warning: as you know, the P in API stands for Programming—so there’ll be some JavaScript code in the next two chapters. If you’re fairly new to JavaScript, don’t worry! We’ll do our best to walk you through how to use these new features using simple examples with thorough explanations. We’ll be assuming you have a sense of the basics, but JavaScript is an enormous topic. To learn more, SitePoint’s Simply JavaScript by Kevin Yank and Cameron Adams is an excellent resource for beginners.[15] You may also find the Mozilla Developer Network’s JavaScript Guide useful.
As with all the JavaScript examples in this book so far, we’ll be using the jQuery library in the interests of keeping the examples as short and readable as possible. We want to demonstrate the APIs themselves, not the intricacies of writing cross-browser JavaScript code. Again, any of this code can just as easily be written in plain JavaScript, if that’s your preference.
The first new API we’ll cover is geolocation. Geolocation allows your visitors to share their current location.
Depending on how they’re visiting your site, their location may be determined by any of the following:
-
IP address
-
wireless network connection
-
cell tower
-
GPS hardware on the device
Which of the above methods are used will depend on the browser, as well as the device’s capabilities. The browser then determines the location and passes it back to the Geolocation API. One point to note, as the W3C Geolocation spec states: “No guarantee is given that the API returns the device’s actual location.”
Not everyone will want to share their location with you, as there are privacy concerns inherent to this information. Thus, your visitors must opt in to share their location. Nothing will be passed along to your site or web application unless the user agrees.
The decision is made via a prompt at the top of the browser. Figure 10.1 shows what this prompt looks like in Chrome.
Warning: Blocking of the Geolocation Prompt in Chrome
Be aware that Chrome may block your site from showing this prompt entirely if you’re viewing your page locally, rather than from an internet server. If this happens, you’ll see an icon in the address bar alerting you to it.
There’s no way around this at present, but you can either test your functionality in other browsers, or deploy your code to a testing server (this can be a local server on your machine, a virtual machine, or an actual internet server).
With geolocation, you can determine the user’s current position. You can also be notified of changes to their position, which could be used, for example, in a web application that provided real-time driving directions.
These different tasks are controlled through the three methods currently available in the Geolocation API:
Before we attempt to use geolocation, we should ensure that our visitor’s browser supports it. We can do that with Modernizr.
We’ll start by creating a function called called
determineLocation. We’ve put it in its own
JavaScript file, geolocation.js, and included that
file in our page.
Inside the function, we’ll first use Modernizr to check if geolocation is supported:
Let’s examine this line by line:
|
We declare a function called
| |
|
We check the |
The getCurrentPosition method takes one,
two, or three arguments. Here is a summary of the method’s definition
from the W3C’s
Geolocation API specification:
void getCurrentPosition(successCallback, errorCallback, options);
Only the first argument, successCallback,
is required. successCallback is the name of the
function you want to call once the position is determined.
In our example, if the location is successfully found, the
displayOnMap function will be
called with a new Position object. This
Position object will contain the current location
of the device.
Note: Callbacks
A callback is a function that is passed as an argument to
another function. A callback is executed after the parent function is
finished. In the case of getCurrentPosition,
the successCallback will only run once
getCurrentPosition is completed, and the
location has been determined.
Let’s take a closer look at the Position
object, as defined in the Geolocation API. The
Position object has two attributes: one that
contains the coordinates of the position (coords),
and another that contains the timestamp of when the position was determined
(timestamp):
interface Position {
readonly attribute Coordinates coords;
readonly attribute DOMTimeStamp timestamp;
};
Note: Interfaces
The HTML5, CSS3, and related specifications contain plenty of “interfaces” like the above. These can seem scary at first, but don’t worry. They’re just summarized descriptions of everything that can go into a certain property, method, or object. Most of the time the meaning will be clear—and if not, they’re always accompanied by textual descriptions of the attributes.
But where are the latitude and longitude stored? They’re inside
the Coordinates object. The
Coordinates object is also defined in the W3C
Geolocation spec, and here are its attributes :
interface Coordinates {
readonly attribute double latitude;
readonly attribute double longitude;
readonly attribute double? altitude;
readonly attribute double accuracy;
readonly attribute double? altitudeAccuracy;
readonly attribute double? heading;
readonly attribute double? speed;
};
The question mark after double in some
of those attributes simply means that there’s no guarantee that the
attribute will be there. If the browser can’t obtain these attributes,
their value will be null. For example, very few
computers or smartphones contain an altimeter—so most of the time you
won’t receive an altitude value from a geolocation
call. The only three attributes that are guaranteed to be there are
latitude, longitude, and
accuracy.
latitude and longitude
are self-explanatory, and give you exactly what you would expect: the
user’s latitude and longitude. The accuracy
attribute tells you, in meters, how accurate is the latitude and
longitude information.
The altitude attribute is the altitude in
meters, and the altitudeAccuracy attribute is the
altitude’s accuracy, also in meters.
The heading and speed
attributes are only relevant if we’re tracking the user across multiple
positions. These attributes would be important if we were providing
real-time biking or driving directions, for example. If present,
heading tells us, in degrees, the direction the
user is moving in relation to true north. And speed,
if present, tells us how quickly the user is moving in meters per
second.
Our successCallback is set to the function
displayOnMap. Here’s what this
function looks like:
function displayOnMap(position) {
var latitude = position.coords.latitude;
var longitude = position.coords.longitude;
// Let’s use Google Maps to display the location
}
The first line of our function grabs the
Coordinates object from the
Position object that was passed to our callback
by the API. Inside the Coordinates object is the
property latitude, which we store inside a variable
called latitude. We do the same for
longitude, storing it in the variable
longitude.
In order to display the user’s location on a map, we’ll leverage the Google Maps JavaScript API. But before we can use this, we need to add a reference to it in our HTML page. Instead of downloading the Google Maps JavaScript library and storing it on our server, we can point to Google’s publicly available version of the API:
…
<!-- google maps API -->
<script type="text/javascript" src="http://maps.google.com/maps/
↵api/js?sensor=true">
</script>
</body>
</html>
Google Maps has a sensor parameter to
indicate whether this application uses a sensor (GPS device) to
determine the user’s location. That’s the sensor=true
you can see in the sample above. You must set this value explicitly to
either true or false. Because the
W3C Geolocation API provides no way of knowing if the information you’re
obtaining comes from a sensor, you can safely specify
false for most web applications (unless they’re
intended specifically for devices that you know have GPS capabilities,
like iPhones).
Now that we’ve included the Google Maps JavaScript, we need to,
first, add an element to the page to hold the map, and, second, provide
a way for the user to call our
determineLocation method by clicking a
button.
To take care of the first step, let’s create a fourth box in the
sidebar of The HTML5 Herald, below the three
advertisement boxes. We’ll wrap it inside an article element, as we did for all the other
ads. Inside it, we’ll create a div
called mapDiv to serve as a
placeholder for the map. Let’s also add a heading to tell the user what
we’re trying to find out:
<article id="ad4">
<div id="mapDiv">
<h1>Where in the world are you?</h1>
<form id="geoForm">
<input type="button" id="geobutton" value="Tell us!">
</form>
</div>
</article>
We’ll also add a bit of styling to this new HTML:
#ad4 h1 {
font-size: 30px;
font-family: AcknowledgementMedium;
text-align: center;
}
#ad4 {
height: 140px;
}
#mapDiv {
height: 140px;
width: 236px;
}
Figure 10.2 reveals what our new sidebar box looks like.

The second step is to call
determineLocation when we hit the button. Using
jQuery, it’s a cinch to attach our function to the button’s click
event:
$('document').ready(function(){
$('#geobutton').click(determineLocation);
});
Note: Document Ready
In the above code snippet, the second line is the one that’s
doing all the heavy lifting. The
$('document’).ready(function(){ … }); bit is just
telling jQuery not to run our code until the page has fully loaded.
It’s necessary because, otherwise, our code might go looking for the
#geobutton element before that element even exists,
resulting in an error.
This is a very common pattern in JavaScript and jQuery. If you’re just getting started with front-end programming, trust us, you’ll be seeing a lot of it.
With this code in place,
determineLocation will be called whenever the
button is clicked.
Now, let’s return to our
displayOnMap function and deal with the
nitty-gritty of actually displaying the map. First, we’ll create a
myOptions variable to store some of the options that
we’ll pass to the Google Map:
function displayOnMap(position) {
var latitude = position.coords.latitude;
var longitude = position.coords.longitude;
// Let’s use Google Maps to display the location
var myOptions = {
zoom: 14,
mapTypeId: google.maps.MapTypeId.ROADMAP
};
The first option we’ll set is the zoom level. For a complete map of the Earth, use zoom level 0. The higher the zoom level, the closer you’ll be to the location, and the smaller your frame (or viewport) will be. We’ll use zoom level 14 to zoom in to street level.
The second option we’ll set is the kind of map we want to display. We can choose from the following:
-
google.maps.MapTypeId.ROADMAP -
google.maps.MapTypeId.SATELLITE -
google.maps.MapTypeId.HYBRID -
google.maps.MapTypeId.TERRAIN
If you’ve used the Google Maps website before, you’ll be familiar
with these map types. ROADMAP is the default, while
SATELLITE shows you photographic tiles.
HYBRID is a combination of
ROADMAP and SATELLITE, and
TERRAIN will display elements like elevation and
water. We’ll use the default, ROADMAP.
Note: Options in Google Maps
To learn more about Google Maps’ options, see the Map Options section of the Google Maps tutorial.
Now that we’ve set our options, it’s time to create our map! We do
this by creating a new Google Maps object with new
google.maps.Map().
The first parameter we pass is the result of the DOM method
getElementById, which we use to grab the
placeholder div we put in our
index.html page. Passing the results of this method
into the new Google Map means that the map created will be placed inside
that element.
The second parameter we pass is the collection of options we just
set. We store the resulting Google Maps object in a variable called
map:
function displayOnMap(position) {
var latitude = position.coords.latitude;
var longitude = position.coords.longitude;
// Let’s use Google Maps to display the location
var myOptions = {
zoom: 16,
mapTypeId: google.maps.MapTypeId.ROADMAP
};
var map = new google.maps.Map(document.getElementById("mapDiv"),
↵myOptions);
Now that we have a map, let’s add a marker with the location we found for the user. A marker is the little red drop we see on Google Maps that marks our location.
In order to create a new Google Maps marker object, we need to
pass it another kind of object: a
google.maps.LatLng object—which is just a
container for a latitude and longitude. The first new line creates this
by calling new google.maps.LatLng and passing it the
latitude and longitude variables
as parameters.
Now that we have a google.maps.LatLng
object, we can create a marker. We call new
google.maps.Marker, and then between two curly braces
({}) we set position to the
LatLng object, map to the
map object, and title to "Hello
World!". The title is what will display when we hover our
mouse over the marker:
function displayOnMap(position) {
var latitude = position.coords.latitude;
var longitude = position.coords.longitude;
// Let’s use Google Maps to display the location
var myOptions = {
zoom: 16,
mapTypeId: google.maps.MapTypeId.ROADMAP
};
var map = new google.maps.Map(document.getElementById("mapDiv"),
↵myOptions);
var initialLocation = new google.maps.LatLng(latitude, longitude);
var marker = new google.maps.Marker({
position: initialLocation,
map: map,
title: "Hello World!"
});
}
The final step is to center our map at the initial point, and we
do this by calling map.setCenter with the
LatLng object:
map.setCenter(initialLocation);
You can find a plethora of documentation about Google Maps’ JavaScript API, version 3 in the online documentation.
While the W3C Geolocation API is well-supported in current mobile device browsers, you may need to account for older mobile devices, and support all the geolocation APIs available. If this is the case, you should take a look at the open source library geo-location-javascript.
The visitors to our websites are increasingly on the go. With many using mobile devices all the time, it’s unwise to assume that our visitors will always have a live internet connection. Wouldn’t it be nice for our visitors to browse our site or use our web application even if they’re offline? Thankfully, we can, with Offline Web Applications.
HTML5’s Offline Web Applications allows us to interact with websites offline. This initially might sound like a contradiction: a web application exists online by definition. But there are an increasing number of web-based applications that could benefit from being usable offline. You probably use a web-based email client, such as Gmail; wouldn’t it be useful to be able to compose drafts in the app while you were on the subway traveling to work? What about online to-do lists, contact managers, or office applications? These are all examples of applications that benefit from being online, but which we’d like to continue using if our internet connection cuts out in a tunnel.
The Offline Web Applications spec is supported in:
It is currently unsupported in all versions of IE.
Offline Web Applications work by leveraging what is known as the application cache. The application cache can store your entire website offline: all the JavaScript, HTML, and CSS, as well as all your images and resources.
This sounds great, but you may be wondering, what happens when there’s a change? That’s the beauty of the application cache: your application is automatically updated every time the user visits your page while online. If even one byte of data has changed in one of your files, the application cache will reload that file.
Note: Application Cache versus Browser Cache
Browsers maintain their own caches in order to speed up the loading of websites; however, these caches are only used to avoid having to reload a given file—and not in the absence of an internet connection. Even all the files for a page are cached by the browser. If you try to click on a link while your internet connection is down, you’ll receive an error message.
With Offline Web Applications, we have the power to tell the browser which files should be cached or fetched from the network, and what we should fall back to in the event that caching fails. It gives us far more control about how our websites are cached.
There are three steps to making an Offline Web Application:
-
Create a cache.manifest file.
-
Ensure that the manifest file is served with the correct content type.
-
Point all your HTML files to the cache manifest.
The HTML5 Herald isn’t really an application at all, so it’s not the sort of site for which you’d want to provide offline functionality. Yet it’s simple enough to do, and there’s no real downside, so we’ll go through the steps of making it available offline to illustrate how it’s done.
Despite its fancy name, the cache.manifest file is really nothing more than a text file that adheres to a certain format.
Here’s an example of a simple cache.manifest file:
CACHE MANIFEST CACHE: index.html photo.jpg main.js NETWORK: *
The first line of the cache.manifest file
must read CACHE MANIFEST. After this line, we enter
CACHE:, and then list all the files we’d like to
store on our visitor’s hard drive. This CACHE:
section is also known as the explicit section (since we’re explicitly telling the
browser to cache these files).
Upon first visiting a page with a cache.manifest file, the visitor’s browser makes a local copy of all files defined in the section. On subsequent visits, the browser will load the local copies of the files.
After listing all the files we’d like to be stored offline, we can specify an online whitelist. Here, we define any files that should never be stored offline—usually because they require internet access for their content to be meaningful. For example, you may have a PHP script, lastTenTweets.php, that grabs your last ten updates from Twitter and displays them on an HTML page. The script would only be able to pull your last ten tweets while online, so it makes no sense to store the page offline.
The first line of this section is the word
NETWORK. Any files specified in the
NETWORK section will always be reloaded when the
user is online, and will never be available offline.
Here’s what that example online whitelist section would look like:
NETWORK lastTenTweets.php
Unlike the explicit section, where we had to painstakingly list
every file we wanted to store offline, in the online whitelist section
we can use a shortcut: the wildcard *. This
asterisk tells the browser that any files or URLs not mentioned in the
explicit section (and therefore not stored in the application cache)
should be fetched from the server.
Here’s an example of an online whitelist section that uses the wildcard:
NETWORK *
Warning: All Accounted For
Every URL in your website must be accounted for in the
cache.manifest file, even URLs that you simply
link to. If it’s unaccounted for in the manifest file, that resource
or URL will fail to load, even if you’re online. To avoid this
problem, you should use the
* in the NETWORK
section.
You can also add comments to your
cache.manifest file by beginning a line with
#. Everything after the
# will be ignored. Be careful to avoid having a
comment as the first line of your cache.manifest
file—as we mentioned earlier, the first line must be CACHE
MANIFEST. You can, however, add comments to any other
line.
It’s good practice to have a comment with the version number of your cache.manifest file (we’ll see why a bit later on):
CACHE MANIFEST # version 0.1 CACHE: index.html photo.jpg main.js NETWORK: *
The next step in making your site available offline is to ensure that your server is configured to serve the manifest files correctly. This is done by setting the content type provided by your server along with the cache.manifest file—we discussed content type in the section called “ MIME Types” in Chapter 5, so you can skip back there now if you need a refresher.
Assuming you’re using the Apache web server, add the following to your .htaccess file:
AddType text/cache-manifest .manifest
The final step to making your website available offline is to
point your HTML pages to the manifest file. We do that by setting the
manifest attribute on the
html element in each of our
pages:
<!doctype html>
<html manifest="/cache.manifest">
Once we’ve done that, we’re finished! Our web page will now be available offline. Better still, since any content that hasn’t changed since the page has been viewed will be stored locally, our page will now load much faster—even when our visitors are online.
Warning: Do This for Every Page
Each HTML page on your website must set the manifest attribute on the html element. Ensure you do this, or your
application might not be stored in the application cache!
While it’s true that you should only have one
cache.manifest file for the entire application,
every HTML page of your web application needs <html
manifest="/cache.manifest">.
As with geolocation, browsers provide a permission prompt when a website is using a cache.manifest file. Unlike geolocation, however, not all browsers are required to do this. When present, the prompt asks the user to confirm that they’d like the website to be available offline. Figure 10.3 shows the prompt’s appearance in Firefox.
Once we have completed all three steps to make an offline website, we can test out our page by going offline. Firefox and Opera provide a menu option that lets you work offline, so there’s no need to cut your internet connection. To do that in Firefox, go to > , as shown in Figure 10.4.
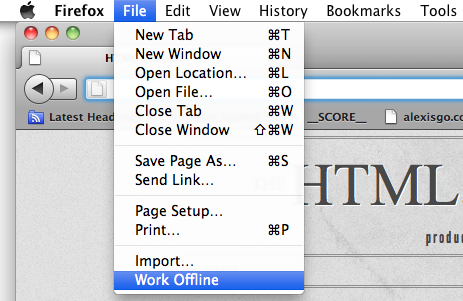
While it’s convenient to go offline from the browser menu, it’s most ideal to turn off your network connection altogether when testing Offline Web Applications.
Going offline is a good way to spot-check if our application cache is working, but for more in-depth debugging, we’ll need a finer instrument. Fortunately, Chrome’s Web Inspector tool has some great features for examining the application cache.
To check if our cache.manifest file has the correct content type, here are the steps to follow in Chrome (http://html5laboratory.com/s/offline-application-cache.html has a sample you can use to follow along):
-
Navigate to the URL of your home page in Chrome.
-
Open up the Web Inspector (click the wrench icon, then choose > ).
-
Click on the Console tab, and look for any errors that may be relevant to the cache.manifest file. If everything is working well, you should see a line that starts with “Document loaded from Application Cache with manifest” and ends with the path to your cache.manifest file. If you have any errors, they will show up in the Console, so be on the lookout for errors or warnings here.
-
Click on the Resources tab.
-
Expand the Application Cache section. Your domain (www.html5laboratory.com in our example) should be listed.
-
Click on your domain. Listed on the right should be all the resources stored in Chrome’s application cache, as shown in Figure 10.5.

Now that we understand the ingredients required to make a website
available offline, let’s practice what we’ve learned on The
HTML5 Herald. The first step is to create our
cache.manifest file. You can use a program like
TextEdit on the Mac or Notepad on Windows to create it, but you have to
make sure the file is formatted as plain text. If you’re using Windows,
you’re in luck! As long as you use Notepad to create this file, it will
already be formatted as plain text. To format a file as plain text in
TextEdit on the Mac, choose >
. Start off your file by
including the line CACHE MANIFEST at the top.
Next, we need to add all the resources we’d like to be available
offline in the explicit section, which starts with the word
CACHE:. We must list all our files in this section.
Since there’s nothing on the site that requires network access (well,
there’s one thing, but we’ll get to that in a bit),
we’ll just add an asterisk to the NETWORK section to
catch any files we may have missed in the explicit section.
Here’s an excerpt from our cache.manifest file:
CACHE MANIFEST #v1 index.html register.html js/hyphenator.js js/modernizr-1.7.min.js css/screen.css css/styles.css images/bg-bike.png images/bg-form.png … fonts/League_Gothic-webfont.eot fonts/League_Gothic-webfont.svg … NETWORK: *
Once you’ve added all your resources to the file, save it as cache.manifest. Be sure the extension is set to .manifest rather than .txt or something else.
Then, if you’re yet to do so already, configure your server to deliver your manifest file with the appropriate content type.
The final step is to add the manifest attribute to the html element in our two HTML pages.
We add the manifest attribute
to both index.html and
register.html, like this:
<!doctype html>
<html lang="en" manifest="cache.manifest">
And we’re set! We can now browse The HTML5 Herald at our leisure, whether we have an internet connection or not.
While the Offline Web Applications spec doesn’t define a specific storage limit for the application cache, it does state that browsers should create and enforce a storage limit. As a general rule, it’s a good idea to assume that you’ve no more than 5MB of space to work with.
Several of the files we specified to be stored offline are video files. Depending on how large your video files are, it mightn’t make any sense to have them available offline, as they could exceed the browser’s storage limit.
What can we do in that case? We could place large video files in
the NETWORK section, but then our users will simply
see an unpleasant error when the browser tries to pull the video while
offline.
A better alternative is to use an optional section of the cache.manifest file: the fallback section.
This section allows us to define what the user will see should a resource fail to load. In the case of The HTML5 Herald, rather than storing our video file offline and placing it in the explicit section, it makes more sense to leverage the fallback section.
Each line in the fallback section requires two entries. The first is the file for which you want to provide fallback content. You can specify either a specific file, or a partial path like media/, which would refer to any file located in the media folder. The second entry is what you would like to display in case the file specified fails to load.
If the files are unable to be loaded, we can load a still image of the film’s first frame instead. We’ll use the partial path media/ to define the fallback for both video files at once:
Of course, this is a bit redundant since, as you know from Chapter 5, the HTML5 video
element already includes a fallback image to be displayed in case the
video fails to load.
So, for some more practice with this concept, let’s add another fallback. In the event that any of our pages don’t load, it would be nice to define a fallback file that tells you the site is offline. We can create a simple offline.html file:
<!doctype html>
<html lang="en" manifest="/cache.manifest">
<head>
<meta charset="utf-8">
<title>We are offline!</title>
<link rel="stylesheet" href="css/styles.css?v=1.0"/>
</head>
<body>
<header>
<h1>Sorry, we are now offline!</h1>
</header>
</body>
</html>
Now, in the fallback section of our cache manifest, we can specify /, which will match any page on the site. If any page fails to load or is absent from the application cache, we’ll fall back to the offline.html page:
Important: Safari Offline Application Cache Fails to Load Media Files
There is currently a bug in Safari 5 where media files such as .mp3 and .mp4 won’t load from the offline application cache.
When using a cache manifest, the files you’ve specified in your explicit section will be cached until further notice. This can cause headaches while developing: you might change a file and be left scratching your head when you’re unable to see your changes reflected on the page.
Even more importantly, once your files are sitting on a live website, you’ll want a way to tell browsers that they need to update their application caches. This can be done by modifying the cache.manifest file. When a browser loads a site for which it already has a cache.manifest file, it will check to see if the manifest file has changed. If it hasn’t, it will assume that its existing application cache is all it needs to run the application, so it won’t download anything else. If the cache.manifest file has changed, the browser will rebuild the application cache by re-downloading all the specified files.
This is why we specified a version number in a comment in our cache.manifest. This way, even if the list of files remains exactly the same, we have a way of indicating to browsers that they should update their application cache; all we need to do is increment the version number.
This might sound absurd, but your cache.manifest file may itself be cached by the browser. Why, you may ask? Because of the way HTTP handles caching.
In order to speed up performance of web pages overall, caching
is done by browsers, according to rules set out via the HTTP
specification. What do you need to know about these rules?
That the browser receives certain HTTP headers, including
Expire headers. These Expire
headers tell the browser when a file should be expired from the cache,
and when it needs updating from the server.
If your server is providing the manifest file with instructions to cache it (as is often the default for static files), the browser will happily use its cached version of the file instead for fetching your updated version from the server. As a result, it won’t re-download any of your application files because it thinks the manifest has not changed!
If you’re finding that you’re unable to force the browser to refresh its application cache, try clearing the regular browser cache. You could also change your server settings to send explicit instructions not to cache the cache.manifest file.
If your site’s web server is running Apache, you can tell Apache not to cache the cache.manifest file by adding the following to your .htaccess file:
The <Files cache.manifest> tells Apache
to only apply the rules that follow to the
cache.manifest file. The combination of
ExpiresActive On and ExpiresDefault
"access" forces the web server to always expire the
cache.manifest file from the cache. The effect
is, the cache.manifest file will never be cached
by the browser.
Sometimes, you’ll need to know if your user is viewing the page offline or online. For example, in a web mail app, saving a draft while online involves sending it to the server to be saved in a database; but while offline, you would want to save that information locally instead, and wait until the user is back online to send it to your server.
The offline web apps API provides a few handy methods and events for managing this. For The HTML5 Herald, you may have noticed that the page works well enough while offline: you can navigate from the home page to the sign-up form, play the video, and generally mess around without any difficulty. However, when you try to use the geolocation widget we built earlier in this chapter, things don’t go so well. This makes sense: without an internet connection, there’s no way for our page to figure out your location (unless your device has a GPS), much less communicate with Google Maps to retrieve the map.
Let’s look at how we can fix this. We would like to simply provide
a message to users indicating that this functionality is unavailable
while offline. It’s actually very easy; browsers that support Offline
Web Applications give you access to the
navigator.onLine property, which will be
true if the browser is online, and
false if it’s not. Here’s how we’d use it in our
determineLocation method:
function determineLocation(){
if (navigator.onLine) {
// find location and call displayOnMap
} else {
alert("You must be online to use this feature.");
}
}
Give it a spin. Using Firefox or Opera, first navigate to the page and click the button to load the map. Once you’re satisfied that it works, choose Work Offline, reload the page, and try clicking the button again. This time you’ll receive a helpful message telling you that you’ll need to be online to access the map.
Some other features that might be of use to you include events
that fire when the browser goes online or offline. These events fire on
the window element, and are simply called
window.online and
window.offline.
These can, for example, allow your scripts to respond to a change in
state by either synchronizing information up to the server when you go
online, or saving data locally when you drop offline.
There are a few other events and methods available to you for dealing with the application cache, but the ones we’ve covered here are the most important. They’ll suffice to have most websites and applications working offline without a hitch.
If you would like to learn more about Offline Web Applications, here are a few good resources:
The Web Storage API defines a standard for how we can save simple data locally on a user’s computer or device. Before the emergence of the Web Storage standard, web developers often stored user information in cookies, or by using plugins. With Web Storage, we now have a standardized definition for how to store up to 5MB of simple data created by our websites or web applications. Better still, Web Storage already works in Internet Explorer 8.0!
Web Storage is a great complement to Offline Web Applications, because you need somewhere to store all that user data while you’re working offline, and Web Storage provides it.
Web Storage is supported in these browsers:
There are two kinds of HTML5 Web Storage: session storage and local storage.
Session storage lets us keep track of data specific to one window or tab. It allows us to isolate information in each window. Even if the user is visiting the same site in two windows, each window will have its own individual session storage object and thus have separate, distinct data.
Session storage is not persistent—it only lasts for the duration of a user’s session on a specific site (in other words, for the time that a browser window or tab is open and viewing that site).
Unlike session storage, local storage allows us to save persistent data to the user’s computer, via the browser. When a user revisits a site at a later date, any data saved to local storage can be retrieved.
Consider shopping online: it’s not unusual for users to have the same site open in multiple windows or tabs. For example, let’s say you’re shopping for shoes, and you want to compare the prices and reviews of two brands. You may have one window open for each brand, but regardless of what brand or style of shoe you’re looking for, you’re always going to be searching for the same shoe size. It’s cumbersome to have to repeat this part of your search in every new window.
Local storage can help. Rather than require the user to specify again the shoe size they’re browsing for every time they launch a new window, we could store the information in local storage. That way, when the user opens a new window to browse for another brand or style, the results would just present items available in their shoe size. Furthermore, because we’re storing the information to the user’s computer, we’ll be able to still access this information when they visit the site at a later date.
Warning: Web Storage is Browser-specific
One important point to remember when working with web storage is that if the user visits your site in Safari, any data will be stored to Safari’s Web Storage store. If the user then revisits your site in Chrome, the data that was saved via Safari will be unavailable. Where the Web Storage data is stored depends on the browser, and each browser’s storage is separate and independent.
Note: Local Storage versus Cookies
Local storage can at first glance seem to play a similar role to HTTP cookies, but there are a few key differences. First of all, cookies are intended to be read on the server side, whereas local storage is only available on the client side. If you need your server-side code to react differently based on some saved values, cookies are the way to go. Yet, cookies are sent along with each HTTP request to your server —and this can result in significant overhead in terms of bandwidth. Local storage, on the other hand, just sits on the user’s hard drive waiting to be read, so it costs nothing to use.
In addition, we have significantly more size to store things using local storage. With cookies, we could only store 4KB of information in total. With local storage, the maximum is 5MB.
Data saved in Web Storage is stored as key/value pairs.
A few examples of simple key/value pairs:
-
key: name, value: Alexis
-
key: painter, value: Picasso
-
key: email, value: [email protected]
The methods most relevant to Web Storage are defined in an object
called Storage. Here is the complete definition
of Storage:
interface Storage {
readonly attribute unsigned long length;
DOMString key(in unsigned long index);
getter any getItem(in DOMString key);
setter creator void setItem(in DOMString key, in any value);
deleter void removeItem(in DOMString key);
void clear();
};
The first methods we’ll discuss are
getItem and
setItem. We store a key/value pair in either
local or session storage by calling setItem,
and we retrieve the value from a key by calling
getItem.
If we want to store the data in or retrieve it from session
storage, we simply call setItem or
getItem on the
sessionStorage global object. If we want to use local
storage instead, we’d call setItem or
getItem on the localStorage
global object. In the examples to follow, we’ll be saving items to local
storage.
When we use the setItem method, we must
specify both the key we want to save the value under, and the value
itself. For example, if we’d like to save the value
"6" under the key "size", we’d
call setItem like this:
localStorage.setItem("size", "6");
To retrieve the value we stored to the "size"
key, we’d use the getItem method, specifying
only the key:
var size = localStorage.getItem("size");
Web Storage stores all values as strings, so if you need to use
them as anything else, such as a number or even an object, you’ll need
to convert them. To convert from a string to a numeric value, we can use
JavaScript’s parseInt method.
For our shoe size example, the value returned and stored in the
size variable will actually be the string
"6", rather than the number 6. To
convert it to a number, we’ll use
parseInt:
var size = parseInt(localStorage.getItem("size"));
We can quite happily continue to use
getItem(key) and setItem(key,
value); however, there’s a shortcut we can use to save and
retrieve data.
Instead of localStorage.getItem(key), we can
simply say localStorage[key]. For example, we could
rewrite our retrieval of the shoe size like this:
var size = localStorage["size"];
And instead of localStorage.setItem(key,
value), we can say localStorage[key] =
value:
localStorage["size"] = 6;
To remove a specific item from Web Storage, we can use the
removeItem method. We pass it the key we want
to remove, and it will remove both the key and its value.
To remove all data stored by our site on a
user’s computer, we can use the
clear method. This will delete
all keys and all values stored for our domain.
Internet Explorer “allows web applications to store nearly 10MB of user data.” Chrome, Safari, Firefox, and Opera all allow for up to 5MB of user data, which is the amount suggested in the W3C spec. This number may evolve over time, as the spec itself states: “A mostly arbitrary limit of five megabytes per origin is recommended. Implementation feedback is welcome and will be used to update this suggestion in the future.” In addition, Opera allows users to configure how much disk space is allocated to Web Storage.
Rather than worrying about how much storage each browser has, a
better approach is to test to see if the quota is exceeded before saving
important data. The way you test for this is by catching the
QUOTA_EXCEEDED_ERR
exception. Here’s one example of how we can do this:
try
{
sessionStorage["name"] = "Tabatha";
}
catch (exception)
{
if (exception == QUOTA_EXCEEDED_ERR)
{
// we should tell the user their quota has been exceeded.
}
}
Note: Try/Catch and Exceptions
Sometimes, problems happen in our code. Designers of APIs know this, and in order to mitigate the effects of these problems, they rely on exceptions. An exception occurs when something unexpected happens. The authors of APIs can define specific exceptions to be thrown when particular kinds of problems occur. Then, developers using those APIs can decide how they’d like to respond to a given type of exception.
In order to respond to exceptions, we can wrap any code we think
may throw an exception in a
try/catch block. This works the
way you might expect: first, you try to do
something. If it fails with an exception, you can
catch that exception and attempt to recover
gracefully.
To read more about
try/catch blocks, see the “try…catch”
article at the Mozilla Developer Networks’ JavaScript
Reference.
Web Storage has what’s known as origin-based security. What this means is that data stored via Web Storage from a given domain is only accessible to pages from that domain. It’s impossible to access any Web Storage data stored by a different domain. For example, assume we control the domain html5isgreat.com, and we store data created on that site using local storage. Another domain, say, google.com, does not have access to any of the data stored by html5isgreat.com. Likewise, html5isgreat.com has no access to any of the local storage data saved by google.com.
We can use Web Storage to add a “Remember me on this computer” checkbox to our registration page. This way, once the user has registered, any other forms they may need to fill out on the site in the future would already have this information.
Let’s define a function that grabs the value of the form’s
input elements for name and email
address, again using jQuery:
function saveData() {
var email = $("#email").val();
var name = $("#name").val();
}
Here we’re simply storing the value of the email and name form
fields, in variables called email and
name, respectively.
Once we have retrieved the values in the two input elements, our next step is to actually
save these values to localStorage:
function saveData() {
var email = $("#email").val();
var name = $("#name").val();
localStorage["name"] = name;
localStorage["email"] = email;
}
Let’s also store the fact that the “Remember me” checkbox was checked by saving this information to local storage as well:
function saveData() {
var email = $("#email").val();
var name = $("#name").val();
localStorage["name"] = name;
localStorage["email"] = email;
localStorage["remember"] = "true";
}
Now that we have a function to save the visitor’s name and email
address, let’s call it if they check the “Remember me on this computer”
checkbox. We’ll do this by watching for the
change event on the checkbox—this event will
fire whenever the checkbox’s state changes, whether due to a click on
it, a click on its label, or a keyboard press:
Next, let’s make sure the checkbox is actually checked, since the
change event will fire when the
checkbox is unchecked as well:
function saveData() {
if ($("#rememberme").attr("checked"))
{
var email = $("#address").val();
var name = $("#register-name").val();
localStorage["name"] = name;
localStorage["email"] = email;
localStorage["remember"] = “true”;
}
}
This new line of code calls the jQuery method
attr("checked"), which will return
true if the checkbox is checked, and
false if not.
Finally, let’s ensure that Web Storage is present in our visitor’s browser:
function saveData() {
if (Modernizr.localstorage) {
if ($("#rememberme").attr("checked"))
{
var email = $("#address").val();
var name = $("#register-name").val();
localStorage["name"] = name;
localStorage["email"] = email;
localStorage["remember"] = “true”;
}
}
else
{
// no support for Web Storage
}
}
Now we’re saving our visitor’s name and email whenever the checkbox is checked, so long as local storage is supported. The problem is, we have yet to actually do anything with that data!
Let’s add another function to check and see if the name and email
have been saved and, if so, fill in the appropriate input elements with that information. Let’s
also precheck the “Remember me” checkbox if we’ve set the key
"remember" to "true" in local
storage:
function loadStoredDetails() {
var name = localStorage["name"];
var email = localStorage["email"];
var remember = localStorage["remember"];
if (name) {
$("#name").val(name);
}
if (email) {
$("#email").val(name);
}
if (remember =="true") {
$("#rememberme").attr("checked", "checked");
}
}
Again, we want to check and make sure Web Storage is supported by the browser before taking these actions:
function loadStoredDetails() {
if (Modernizr.localstorage) {
var name = localStorage["name"];
var email = localStorage["email"];
var remember = localStorage["remember"];
if (name) {
$("#name").val(name);
}
if (email) {
$("#email").val(name);
}
if (remember =="true") s{
$("#rememberme").attr("checked", "checked");
}
} else {
// no support for Web Storage
}
}
As a final step, we call the
loadStoredDetails function as soon as the page
loads:
$('document').ready(function(){
loadStoredDetails();
$('#rememberme').change(saveData);
});
Now, if the user has previously visited the page and checked “Remember me on this computer,” their name and email will already be populated on subsequent visits to the page.
We can use the Safari or Chrome Web Inspector to look at, or even change, the values of our local storage. In Safari, we can view the stored data under the Storage tab, as shown in Figure 10.6.

In Chrome, the data can be viewed through the Resources tab.
Since the user owns any data saved to their hard drive, they can actually modify the data in Web Storage, should they choose to do so.
Let’s try this ourselves. If you double-click on the “email” value in Web Inspector’s Storage tab while viewing the register.html page, you can actually modify the value stored there, as Figure 10.7 shows.
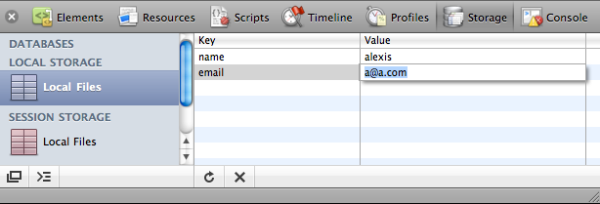
There’s nothing we as developers can do to prevent this, since our users own the data on their computers. We can and should, however, bear in mind that savvy users have the ability to change their local storage data. In addition, the Web Storage spec states that any dialogue in browsers asking users to clear their cookies should now also allow them to clear their local storage. The message to retain is that we can’t be 100% sure that the data we store is accurate, nor that it will always be there. Thus, sensitive data should never be kept in local storage.
If you’d like to learn more about Web Storage, here are a few resources you can consult:
There are a number of other APIs that are outside the scope of this book. However, we’d like to mention them briefly here, to give you an overview of what they are, as well as give you some resources should you want to learn more.
The new Web Workers API allows us to run large scripts in the background without interrupting our main page or web app. Prior to Web Workers, it was impossible to run multiple JavaScript scripts concurrently. Have you ever come across a dialogue like the one shown in Figure 10.8?
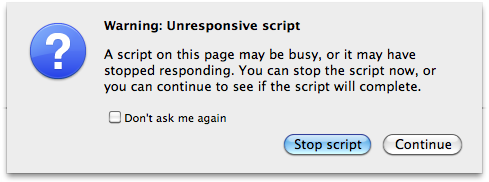
With Web Workers, we should see less of these types of warnings. The new API allows us to take scripts that take a long time to run, and require no user interaction, and run them behind the scenes concurrently with any other scripts that do handle user interaction. This concept is known as threading in programming, and Web Workers brings us thread-like features. Each “worker” handles its own chunk of script, without interfering with other workers or the rest of the page. To ensure the workers stay in sync with each other, the API defines ways to pass messages from one worker to another.
-
Safari 4+
-
Chrome 5+
-
Firefox 3.5+
-
Opera 10.6+
Web Workers are currently unsupported in all versions of IE, iOS, and Android.
To learn more about Web Workers, see:
Web Sockets defines a “protocol for two-way communication with a remote host.” We’ll skip covering this topic for a couple of reasons. First, this API is of great use to server-side developers, but is less relevant to front-end developers and designers. Second, Web Sockets are still in development and have actually run into some security issues. Firefox 4 and Opera 11 have disabled Web Sockets by default due to these issues.[16]
-
Safari 5+
-
Chrome 4+
-
Firefox 4+ (but disabled by default)
-
Opera 11+ (but disabled by default)
-
iOS (Mobile Safari) 4.2+
Web Sockets are currently unsupported in all versions of IE and on Android.
To learn more about Web Sockets, see the specification at the W3C: http://dev.w3.org/html5/websockets/.
There are times when the 5MB of storage and simplistic key/value pairs offered by the Web Storage API just aren’t enough. If you need to store substantial amounts of data, and more complex relationships between your data, you likely need a full-fledged database to take care of your storage requirements.
Usually databases have been unique to the server side, but there are currently two database solutions proposed to fill this need on the client side: Web SQL and the Indexed Database API (called IndexedDB for short). The Web SQL specification is no longer being updated, and though it currently looks like IndexedDB is gaining steam, it remains to be seen which of these will become the future standard for serious data storage in the browser.
-
Safari 3.2+
-
Chrome
-
Opera 10.5+
-
iOS (Mobile Safari) 3.2+
-
Android 2.1+
Web SQL is currently unsupported in all versions of IE and Firefox. IndexedDB, meanwhile, is currently only supported in Firefox 4.
If you would like to learn more, here are a few good resources:
In this chapter, we’ve had a glimpse into the new JavaScript APIs available in the latest generation of browsers. While these might for some time lack full browser support, tools like Modernizr can help us gradually incorporate them into our real-world projects, bringing an extra dimension to our sites and applications.
In the next—and final—chapter, we’ll look at one more API, as well as two techniques for creating complex graphics in the browser. These open up a lot of potential avenues for creating web apps that leap off the page.