
16. Collections
Objectives
In this chapter you’ll learn:
• What collections are.
• To use class Arrays for array manipulations.
• To use the collections framework (prepackaged data structure) implementations.
• To use collections framework algorithms to manipulate (such as search, sort and fill) collections.
• To use the collections framework interfaces to program with collections polymorphically.
• To use iterators to “walk through” a collection.
• To use persistent hash tables manipulated with objects of class Properties.
• To use synchronization and modifiability wrappers.
I think this is the most extraordinary collection of talent, of human knowledge, that has ever been gathered together at the White House—with the possible exception of when Thomas Jefferson dined alone.
—John F. Kennedy
The shapes a bright container can contain!
—Theodore Roethke
Journey over all the universe in a map.
—Miguel de Cervantes
Not by age but by capacity is wisdom acquired.
—Titus Maccius Plautus
It is a riddle wrapped in a mystery inside an enigma.
—Winston Churchill
Outline
16.1 Introduction
16.2 Collections Overview
16.3 Class Arrays
16.4 Interface Collection and Class Collections
16.5 Lists
16.5.1 ArrayList and Iterator
16.5.2 LinkedList
16.5.3 Vector
16.6 Collections Algorithms
16.6.1 Algorithm sort
16.6.2 Algorithm shuffle
16.6.3 Algorithms reverse, fill, copy, max and min
16.6.4 Algorithm binarySearch
16.6.5 Algorithms addAll, frequency and disjoint
16.7 Stack Class of Package java.util
16.8 Class PriorityQueue and Interface Queue
16.9 Sets
16.10 Maps
16.11 Properties Class
16.12 Synchronized Collections
16.13 Unmodifiable Collections
16.14 Abstract Implementations
16.15 Wrap-Up
16.1 Introduction
We now consider the Java collections framework, which contains prepackaged data structures, interfaces and algorithms for manipulating those data structures. Some examples of collections are the cards you hold in a card game, your favorite songs stored in your computer, the members of a sports team and the real-estate records in your local registry of deeds (which map book numbers and page numbers to property owners). In this chapter, we also discuss how generics (see Chapter 15) are used in the Java collections framework.
With collections, programmers use existing data structures, without concern for how they’re implemented. This is a marvelous example of code reuse. You can code faster and expect excellent performance, maximizing execution speed and minimizing memory consumption. In this chapter, we discuss the collections framework interfaces that list the capabilities of each collection type, the implementation classes, the algorithms that process the collections, and the so-called iterators and enhanced for statement syntax that “walk through” collections. This chapter provides an introduction to the collections framework. For complete details, visit java.sun.com/javase/6/docs/guide/collections.
The Java collections framework provides ready-to-go, reusable componentry—you do not need to write your own collection classes, but you can if you wish to. The collections are standardized so that applications can share them easily without concern for the details of their implementation. The collections framework encourages further reusability. As new data structures and algorithms are developed that fit this framework, a large base of programmers will already be familiar with the interfaces and algorithms implemented by those data structures.
16.2 Collections Overview
A collection is a data structure—actually, an object—that can hold references to other objects. Usually, collections contain references to objects that are all of the same type. The collections framework interfaces declare the operations to be performed generically on various types of collections. Figure 16.1 lists some of the interfaces of the collections framework. Several implementations of these interfaces are provided within the framework. Programmers may also provide implementations specific to their own requirements.
Fig. 16.1. Some collection framework interfaces.

The collections framework provides high-performance, high-quality implementations of common data structures and enables software reuse. These features minimize the amount of coding programmers need to do to create and manipulate collections. The classes and interfaces of the collections framework are members of package java.util. In the next section, we begin our discussion by examining the collections framework capabilities for array manipulation.
In earlier versions of Java, the classes in the collections framework stored and manipulated Object references. Thus, you could store any object in a collection. One inconvenient aspect of storing Object references occurs when retrieving them from a collection. A program normally has the need to process specific types of objects. As a result, the Object references obtained from a collection typically need to be cast to an appropriate type to allow the program to process the objects correctly.
In Java SE 5, the collections framework was enhanced with the generics capabilities we introduced in Chapter 15. This means that you can specify the exact type that will be stored in a collection rather than type Object. You also receive the benefits of compile-time type checking—the compiler ensures that you are using appropriate types with your collection and, if not, issues compile-time error messages. Also, once you specify the type stored in a collection, any reference you retrieve from the collection will have the specified type. This eliminates the need for explicit type casts that can throw ClassCastExceptions if the referenced object is not of the appropriate type. Programs that were implemented with prior Java versions and that use collections can compile properly because the compiler automatically uses raw types when it encounters collections for which type arguments were not specified.
16.3 Class Arrays
Class Arrays provides static methods for manipulating arrays. In Chapter 7, our discussion of array manipulation was low level in the sense that we wrote the actual code to sort and search arrays. Class Arrays provides high-level methods, such as sort for sorting an array, binarySearch for searching a sorted array, equals for comparing arrays and fill for placing values into an array. These methods are overloaded for primitive-type arrays and Object arrays. In addition, methods sort and binarySearch are overloaded with generic versions that allow programmers to sort and search arrays containing objects of any type. Figure 16.2 demonstrates methods fill, sort, binarySearch and equals. Method main (lines 65–85) creates a UsingArrays object and invokes its methods.
Fig. 16.2. Arrays class methods.



Line 17 calls static method fill of class Arrays to populate all 10 elements of filledIntArray with 7s. Overloaded versions of fill allow the programmer to populate a specific range of elements with the same value.
Line 18 sorts the elements of array doubleArray. The static method sort of class Arrays orders the array’s elements in ascending order by default. We discuss how to sort in descending order later in the chapter. Overloaded versions of sort allow the programmer to sort a specific range of elements.
Lines 21–22 copy array intArray into array intArrayCopy. The first argument (intArray) passed to System method arraycopy is the array from which elements are to be copied. The second argument (0) is the index that specifies the starting point in the range of elements to copy from the array. This value can be any valid array index. The third argument (intArrayCopy) specifies the destination array that will store the copy. The fourth argument (0) specifies the index in the destination array where the first copied element should be stored. The last argument specifies the number of elements to copy from the array in the first argument. In this case, we copy all the elements in the array.
Line 50 calls static method binarySearch of class Arrays to perform a binary search on intArray, using value as the key. If value is found, binarySearch returns the index of the element; otherwise, binarySearch returns a negative value. The negative value returned is based on the search key’s insertion point—the index where the key would be inserted in the array if we were performing an insert operation. After binarySearch determines the insertion point, it changes its sign to negative and subtracts 1 to obtain the return value. For example, in Fig. 16.2, the insertion point for the value 8763 is the element with index 6 in the array. Method binarySearch changes the insertion point to –6, subtracts 1 from it and returns the value –7. Subtracting 1 from the insertion point guarantees that method binarySearch returns positive values (>= 0) if and only if the key is found. This return value is useful for inserting elements in a sorted array.
Common Programming Error 16.1
![]()
Passing an unsorted array to binarySearch is a logic error—the value returned is undefined.
Lines 56 and 60 call static method equals of class Arrays to determine whether the elements of two arrays are equivalent. If the arrays contain the same elements in the same order, the method returns true; otherwise, it returns false. The equality of each element is compared using Object method equals. Many classes override method equals to perform the comparisons in a manner specific to those classes. For example, class String declares equals to compare the individual characters in the two Strings being compared. If method equals is not overridden, the original version of method equals inherited from class Object is used.
16.4 Interface Collection and Class Collections
The Collection interface is the root interface in the collection hierarchy from which interfaces Set, Queue and List are derived. Interface Set defines a collection that does not contain duplicates. Interface Queue defines a collection that represents a waiting line—typically, insertions are made at the back of a queue and deletions are made from the front, though other orders can be specified. We discuss Queue and Set in Section 16.8 and Section 16.9, respectively. Interface Collection contains bulk operations (i.e., operations performed on an entire collection) for adding, clearing, comparing and retaining objects (or elements) in a collection. A Collection can also be converted to an array. In addition, interface Collection provides a method that returns an Iterator object, which allows a program to walk through the collection and remove elements from the collection during the iteration. We discuss class Iterator in Section 16.5.1. Other methods of interface Collection enable a program to determine a collection’s size and whether a collection is empty.
Software Engineering Observation 16.1
![]()
Collection is used commonly as a method parameter type to allow polymorphic processing of all objects that implement interface Collection.
Software Engineering Observation 16.2
![]()
Most collection implementations provide a constructor that takes a Collection argument, thereby allowing a new collection to be constructed containing the elements of the specified collection.
Class Collections provides static methods that manipulate collections polymorphically. These methods implement algorithms for searching, sorting and so on. Section 16.6 discusses more about the algorithms that are available in class Collections. We also cover the wrapper methods of class Collections that enable you to treat a collection as a synchronized collection (Section 16.12) or an unmodifiable collection (Section 16.13). Unmodifiable collections are useful when a client of a class needs to view the elements of a collection, but should not be allowed to modify the collection by adding and removing elements. Synchronized collections are for use with a powerful capability called multithreading (discussed in Chapter 18). Multithreading enables programs to perform operations in parallel. When two or more threads of a program share a collection, there is the potential for problems to occur. As a brief analogy, consider a traffic intersection. We cannot allow all cars access to one intersection at the same time—if we did, accidents would occur. For this reason, traffic lights are provided at intersections to control access to the intersection. Similarly, we can synchronize access to a collection to ensure that only one thread manipulates the collection at a time. The synchronization wrapper methods of class Collections return synchronized versions of collections that can be shared among threads in a program.
16.5 Lists
A List (sometimes called a sequence) is an ordered Collection that can contain duplicate elements. Like array indices, List indices are zero based (i.e., the first element’s index is zero). In addition to the methods inherited from Collection, List provides methods for manipulating elements via their indices, manipulating a specified range of elements, searching for elements and getting a ListIterator to access the elements.
Interface List is implemented by several classes, including classes ArrayList, LinkedList and Vector. Autoboxing occurs when you add primitive-type values to objects of these classes, because they store only references to objects. Class ArrayList and Vector are resizable-array implementations of List. Class LinkedList is a linked list implementation of interface List.
Class ArrayList’s behavior and capabilities are similar to those of class Vector. The primary difference between Vector and ArrayList is that objects of class Vector are synchronized by default, whereas objects of class ArrayList are not. Also, class Vector is from Java 1.0, before the collections framework was added to Java. As such, Vector has several methods that are not part of interface List and are not implemented in class ArrayList, but perform identical tasks. For example, Vector methods addElement and add both append an element to a Vector, but only method add is specified in interface List and implemented by ArrayList. Unsynchronized collections provide better performance than synchronized ones. For this reason, ArrayList is typically preferred over Vector in programs that do not share a collection among threads.
Performance Tip 16.1
![]()
ArrayLists behave like Vectors without synchronization and therefore execute faster than Vectors because ArrayLists do not have the overhead of thread synchronization.
Software Engineering Observation 16.3
![]()
LinkedLists can be used to create stacks, queues, trees and deques (double-ended queues, pronounced “decks”). The collections framework provides implementations of some of these data structures.
The following three subsections demonstrate the List and Collection capabilities with several examples. Section 16.5.1 focuses on removing elements from an ArrayList with an Iterator. Section 16.5.2 focuses on ListIterator and several List- and LinkedList-specific methods. Section 16.5.3 introduces more List methods and several Vector-specific methods.
16.5.1 ArrayList and Iterator
Figure 16.3 uses an ArrayList to demonstrate several Collection interface capabilities. The program places two Color arrays in ArrayLists and uses an Iterator to remove elements in the second ArrayList collection from the first ArrayList collection.
Fig. 16.3. Collection interface demonstrated via an ArrayList object.


Lines 10–13 declare and initialize two String array variables, which are declared final, so they always refer to these arrays. Recall that it is good programing practice to declare constants with keywords static and final. Lines 18–19 create ArrayList objects and assign their references to variables list and removeList, respectively. These two lists store String objects. Note that ArrayList is a generic class as of Java SE 5, so we are able to specify a type argument (String in this case) to indicate the type of the elements in each list. Both list and removeList are collections of Strings. Lines 22–23 populate list with Strings stored in array colors, and lines 26–27 populate removeList with Strings stored in array removeColors using List method add. Lines 32–33 output each element of list. Line 32 calls List method size to get the number of ArrayList elements. Line 33 uses List method get to retrieve individual element values. Lines 32–33 could have used the enhanced for statement. Line 36 calls method removeColors (lines 46–57), passing list and removeList as arguments. Method removeColors deletes Strings specified in removeList from the list collection. Lines 41–42 print list’s elements after removeColors removes the String objects specified in removeList from the list.
Method removeColors declares two Collection parameters (line 47) that allow any Collections containing strings to be passed as arguments to this method. The method accesses the elements of the first Collection (collection1) via an Iterator. Line 50 calls Collection method iterator to get an Iterator for the Collection. Note that interfaces Collection and Iterator are generic types. The loop-continuation condition (line 53) calls Iterator method hasNext to determine whether the Collection contains more elements. Method hasNext returns true if another element exists and false otherwise.
The if condition in line 55 calls Iterator method next to obtain a reference to the next element, then uses method contains of the second Collection (collection2) to determine whether collection2 contains the element returned by next. If so, line 56 calls Iterator method remove to remove the element from the Collection collection1.
Common Programming Error 16.2
![]()
If a collection is modified by one of its methods after an iterator is created for that collection, the iterator immediately becomes invalid—any operations performed with the iterator after this point throw ConcurrentModificationExceptions. For this reason, iterators are said to be “fail fast.”
16.5.2 LinkedList
Figure 16.4 demonstrates operations on LinkedLists. The program creates two LinkedLists that contain Strings. The elements of one List are added to the other. Then all the Strings are converted to uppercase, and a range of elements is deleted.
Fig. 16.4. Lists and ListIterators.
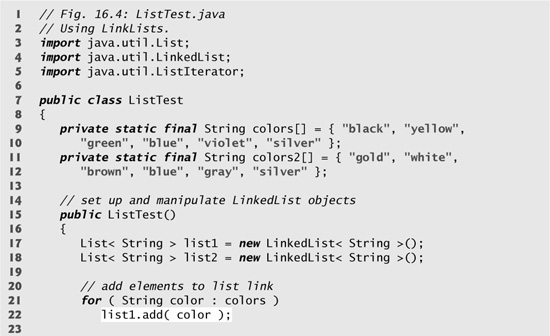


Lines 17–18 create LinkedLists list1 and list2 of type String. Note that LinkedList is a generic class that has one type parameter for which we specify the type argument String in this example. Lines 21–26 call List method add to append elements from arrays colors and colors2 to the end of list1 and list2, respectively.
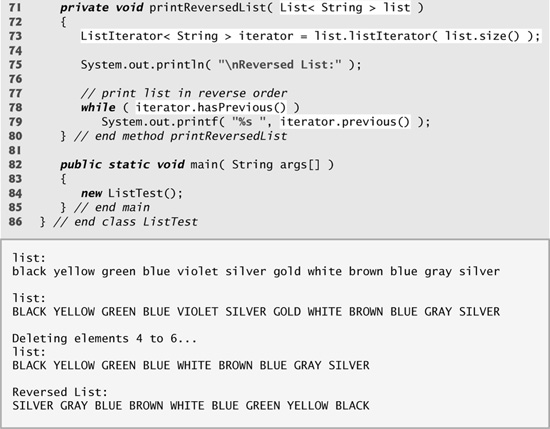
Line 28 calls List method addAll to append all elements of list2 to the end of list1. Line 29 sets list2 to null, so the LinkedList to which list2 referred can be garbage collected. Line 30 calls method printList (lines 42–50) to output list list1’s contents. Line 32 calls method convertToUppercaseStrings (lines 53–62) to convert each String element to uppercase, then line 33 calls printList again to display the modified Strings. Line 36 calls method removeItems (lines 65–68) to remove the elements starting at index 4 up to, but not including, index 7 of the list. Line 38 calls method printReversedList (lines 71–80) to print the list in reverse order.
Method convertToUppercaseStrings (lines 53–62) changes lowercase String elements in its List argument to uppercase Strings. Line 55 calls List method listIterator to get a bidirectional iterator (i.e., an iterator that can traverse a List backward or forward) for the List. Note that ListIterator is a generic class. In this example, the ListIterator contains String objects, because method listIterator is called on a List of Strings. The while condition (line 57) calls method hasNext to determine whether the List contains another element. Line 59 gets the next String in the List. Line 60 calls String method toUpperCase to get an uppercase version of the String and calls ListIterator method set to replace the current String to which iterator refers with the String returned by method toUpperCase. Like method toUpperCase, String method toLowerCase returns a lowercase version of the String.
Method removeItems (lines 65–68) removes a range of items from the list. Line 67 calls List method subList to obtain a portion of the List (called a sublist). The sublist is simply another view into the List on which subList is called. Method subList takes two arguments—the beginning and the ending index for the sublist. The ending index is not part of the range of the sublist. In this example, we pass (in line 36) 4 for the beginning index and 7 for the ending index to subList. The sublist returned is the set of elements with indices 4 through 6. Next, the program calls List method clear on the sublist to remove the elements of the sublist from the List. Any changes made to a sublist are also made to the original List.
Method printReversedList (lines 71–80) prints the list backward. Line 73 calls List method listIterator with the starting position as an argument (in our case, the last element in the list) to get a bidirectional iterator for the list. List method size returns the number of items in the List. The while condition (line 78) calls method hasPrevious to determine whether there are more elements while traversing the list backward. Line 79 gets the previous element from the list and outputs it to the standard output stream.
An important feature of the collections framework is the ability to manipulate the elements of one collection type (such as a set) through a different collection type (such as a list), regardless of the collection’s internal implementation. The set of public methods through which collections are manipulated is called a view.
Class Arrays provides static method asList to view an array as a List collection (which encapsulates behavior similar to that of linked lists). A List view allows the programmer to manipulate the array as if it were a list. This is useful for adding the elements in an array to a collection (e.g., a LinkedList) and for sorting array elements. The next example demonstrates how to create a LinkedList with a List view of an array, because we cannot pass the array to a LinkedList constructor. Sorting array elements with a List view is demonstrated in Fig. 16.9. Any modifications made through the List view change the array, and any modifications made to the array change the List view. The only operation permitted on the view returned by asList is set, which changes the value of the view and the backing array. Any other attempts to change the view (such as adding or removing elements) result in an UnsupportedOperationException.
Figure 16.5 uses method asList to view an array as a List collection and uses method toArray of a List to get an array from a LinkedList collection. The program calls method asList to create a List view of an array, which is then used for creating a LinkedList object, adds a series of strings to a LinkedList and calls method toArray to obtain an array containing references to the strings. Notice that the instantiation of LinkedList (line 13) indicates that LinkedList is a generic class that accepts one type argument—String, in this example.
Fig. 16.5. List method toArray.


Lines 13–14 construct a LinkedList of Strings containing the elements of array colors and assigns the LinkedList reference to links. Note the use of Arrays method asList to return a view of the array as a List, then initialize the LinkedList with the List. Line 16 calls LinkedList method addLast to add "red" to the end of links. Lines 17–18 call LinkedList method add to add "pink" as the last element and "green" as the element at index 3 (i.e., the fourth element). Note that method addLast (line 16) is identical in function to method add (line 17). Line 19 calls LinkedList method addFirst to add "cyan" as the new first item in the LinkedList. The add operations are permitted because they operate on the LinkedList object, not the view returned by asList. [Note: When "cyan" is added as the first element, "green" becomes the fifth element in the LinkedList.]
Line 22 calls List method toArray to get a String array from links. The array is a copy of the list’s elements—modifying the array’s contents does not modify the list. The array passed to method toArray is of the same type that you would like method toArray to return. If the number of elements in the array is greater than or equal to the number of elements in the LinkedList, toArray copies the list’s elements into its array argument and returns that array. If the LinkedList has more elements than the number of elements in the array passed to toArray, toArray allocates a new array of the same type it receives as an argument, copies the list’s elements into the new array and returns the new array.
Common Programming Error 16.3
![]()
Passing an array that contains data to toArray can cause logic errors. If the number of elements in the array is smaller than the number of elements in the list on which toArray is called, a new array is allocated to store the list’s elements—without preserving the array argument’s elements. If the number of elements in the array is greater than the number of elements in the list, the elements of the array (starting at index zero) are overwritten with the list’s elements. Array elements that are not overwritten retain their values.
16.5.3 Vector
Like ArrayList, class Vector provides the capabilities of array-like data structures that can resize themselves dynamically. Recall that class ArrayList’s behavior and capabilities are similar to those of class Vector, except that ArrayLists do not provide synchronization by default. We cover class Vector here primarily because it is the superclass of class Stack, which is presented in Section 16.7.
At any time, a Vector contains a number of elements that is less than or equal to its capacity. The capacity is the space that has been reserved for the Vector’s elements. If a Vector requires additional capacity, it grows by a capacity increment that you specify or by a default capacity increment. If you do not specify a capacity increment or specify one that is less than or equal to zero, the system will double the size of a Vector each time additional capacity is needed.
Performance Tip 16.2
![]()
Inserting an element into a Vector whose current size is less than its capacity is a relatively fast operation.
Performance Tip 16.3
![]()
Inserting an element into a Vector that needs to grow larger to accommodate the new element is a relatively slow operation.
Performance Tip 16.4
![]()
The default capacity increment doubles the size of the Vector. This may seem a waste of storage, but it is actually an efficient way for many Vectors to grow quickly to be “about the right size.” This operation is much more efficient than growing the Vector each time by only as much space as it takes to hold a single element. The disadvantage is that the Vector might occupy more space than it requires. This is a classic example of the space–time trade-off.
Performance Tip 16.5
![]()
If storage is at a premium, use Vector method trimToSize to trim a Vector’s capacity to the Vector’s exact size. This operation optimizes a Vector’s use of storage. However, adding another element to the Vector will force the Vector to grow dynamically (again, a relatively slow operation)—trimming leaves no room for growth.
Figure 16.6 demonstrates class Vector and several of its methods. For complete information on class Vector, visit java.sun.com/javase/6/docs/api/java/util/Vector.html.
Fig. 16.6. Vector class of package java.util.



The application’s constructor creates a Vector (line 13) of type String with an initial capacity of 10 elements and capacity increment of zero (the defaults for a Vector). Note that Vector is a generic class, which takes one argument that specifies the type of the elements stored in the Vector. A capacity increment of zero indicates that this Vector will double in size each time it needs to grow to accommodate more elements. Class Vector provides three other constructors. The constructor that takes one integer argument creates an empty Vector with the initial capacity specified by that argument. The constructor that takes two arguments creates a Vector with the initial capacity specified by the first argument and the capacity increment specified by the second argument. Each time the Vector needs to grow, it will add space for the specified number of elements in the capacity increment. The constructor that takes a Collection creates a copy of a collection’s elements and stores them in the Vector.
Line 18 calls Vector method add to add objects (Strings in this program) to the end of the Vector. If necessary, the Vector increases its capacity to accommodate the new element. Class Vector also provides a method add that takes two arguments. This method takes an object and an integer and inserts the object at the specified index in the Vector. Method set will replace the element at a specified position in the Vector with a specified element. Method insertElementAt provides the same functionality as the method add that takes two arguments, except that the order of the parameters is reversed.
Line 25 calls Vector method firstElement to return a reference to the first element in the Vector. Line 26 calls Vector method lastElement to return a reference to the last element in the Vector. Each of these methods throws a NoSuchElementException if there are no elements in the Vector when the method is called.
Line 35 calls Vector method contains to determine whether the Vector contains "red". The method returns true if its argument is in the Vector—otherwise, the method returns false. Method contains uses Object method equals to determine whether the search key is equal to one of the Vector’s elements. Many classes override method equals to perform the comparisons in a manner specific to those classes. For example, class String declares equals to compare the individual characters in the two Strings being compared. If method equals is not overridden, the original version of method equals inherited from class Object is used.
Common Programming Error 16.4
![]()
Without overriding method equals, the program performs comparisons using operator == to determine whether two references refer to the same object in memory.
Line 37 calls Vector method indexOf to determine the index of the first location in the Vector that contains the argument. The method returns –1 if the argument is not found in the Vector. An overloaded version of this method takes a second argument specifying the index in the Vector at which the search should begin.
Performance Tip 16.6
![]()
Vector methods contains and indexOf perform linear searches of a Vector’s contents. These searches are inefficient for large Vectors. If a program frequently searches for elements in a collection, consider using one of the Java Collection API’s Map implementations (Section 16.10), which provide high-speed searching capabilities.
Line 41 calls Vector method remove to remove the first occurrence of its argument from the Vector. The method returns true if it finds the element in the Vector; otherwise, the method returns false. If the element is removed, all elements after that element in the Vector shift one position toward the beginning of the Vector to fill in the position of the removed element. Class Vector also provides method removeAllElements to remove every element from a Vector and method removeElementAt to remove the element at a specified index.
Lines 53–54 use Vector methods size and capacity to determine the number of elements currently in the Vector and the number of elements that can be stored in the Vector without allocating more memory, respectively.
Line 59 calls Vector method isEmpty to determine whether the Vector is empty. The method returns true if there are no elements in the Vector; otherwise, the method returns false. Lines 66–67 use the enhanced for statement to print out all elements in the vector.
Among the methods introduced in Fig. 16.6, firstElement, lastElement and capacity can be used only with Vector. Other methods (e.g., add, contains, indexOf, remove, size and isEmpty) are declared by List, which means that they can be used by any class that implements List, such as Vector.
16.6 Collections Algorithms
The collections framework provides several high-performance algorithms for manipulating collection elements that are implemented as static methods of class Collections (Fig. 16.7). Algorithms sort, binarySearch, reverse, shuffle, fill and copy operate on Lists. Algorithms min, max, addAll, frequency and disjoint operate on Collections.
Fig. 16.7. Collections algorithms.

Software Engineering Observation 16.4
![]()
The collections framework algorithms are polymorphic. That is, each algorithm can operate on objects that implement specific interfaces, regardless of the underlying implementations.
16.6.1 Algorithm sort
Algorithm sort sorts the elements of a List, which must implement the Comparable interface. The order is determined by the natural order of the elements’ type as implemented by a compareTo method. Method compareTo is declared in interface Comparable and is sometimes called the natural comparison method. The sort call may specify as a second argument a Comparator object that determines an alternative ordering of the elements.
Sorting in Ascending Order
Figure 16.8 uses algorithm sort to order the elements of a List in ascending order (line 20). Recall that List is a generic type and accepts one type argument that specifies the list element type—line 15 declares list as a List of String. Note that lines 18 and 23 each use an implicit call to the list’s toString method to output the list contents in the format shown on the second and fourth lines of the output.
Fig. 16.8. Collections method sort.

Sorting in Descending Order
Figure 16.9 sorts the same list of strings used in Fig. 16.8 in descending order. The example introduces the Comparator interface, which is used for sorting a Collection’s elements in a different order. Line 21 calls Collections’s method sort to order the List in descending order. The static Collections method reverseOrder returns a Comparator object that orders the collection’s elements in reverse order.
Fig. 16.9. Collections method sort with a Comparator object.

Sorting with a Comparator
Figure 16.10 creates a custom Comparator class, named TimeComparator, that implements interface Comparator to compare two Time2 objects. Class Time2, declared in Fig. 8.5, represents times with hours, minutes and seconds.
Fig. 16.10. Custom Comparator class that compares two Time2 objects.

Class TimeComparator implements interface Comparator, a generic type that takes one argument (in this case Time2). Method compare (lines 7–26) performs comparisons between Time2 objects. Line 9 compares the two hours of the Time2 objects. If the hours are different (line 12), then we return this value. If this value is positive, then the first hour is greater than the second and the first time is greater than the second. If this value is negative, then the first hour is less than the second and the first time is less than the second. If this value is zero, the hours are the same and we must test the minutes (and maybe the seconds) to determine which time is greater.
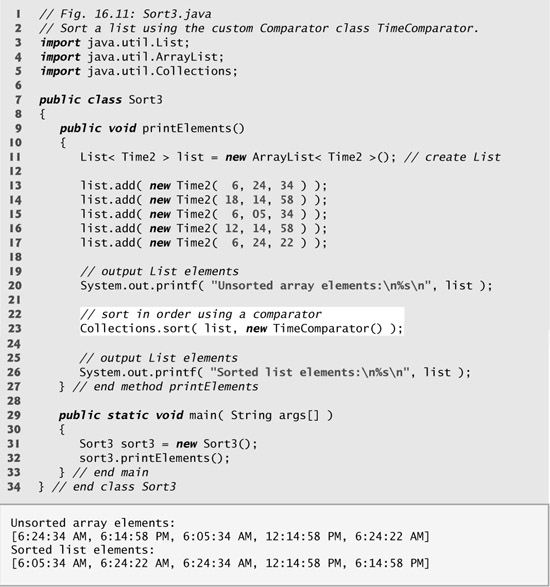
Figure 16.11 sorts a list using the custom Comparator class TimeComparator. Line 11 creates an ArrayList of Time2 objects. Recall that both ArrayList and List are generic types and accept a type argument that specifies the element type of the collection. Lines 13–17 create five Time2 objects and add them to this list. Line 23 calls method sort, passing it an object of our TimeComparator class (Fig. 16.10).
Fig. 16.11. Collections method sort with a custom Comparator object.
16.6.2 Algorithm shuffle
Algorithm shuffle randomly orders a List’s elements. In Chapter 7, we presented a card shuffling and dealing simulation that used a loop to shuffle a deck of cards. In Fig. 16.12, we use algorithm shuffle to shuffle a deck of Card objects that might be used in a card game simulator.
Fig. 16.12. Card shuffling and dealing with Collections method shuffle.



Class Card (lines 8–41) represents a card in a deck of cards. Each Card has a face and a suit. Lines 10–12 declare two enum types—Face and Suit—which represent the face and the suit of the card, respectively. Method toString (lines 37–40) returns a String containing the face and suit of the Card separated by the string "of ". When an enum constant is converted to a string, the constant’s identifier is used as the string representation. Normally we would use all uppercase letters for enum constants. In this example, we chose to use capital letters for only the first letter of each enum constant because we want the card to be displayed with initial capital letters for the face and the suit (e.g., "Ace of Spades").
Lines 55–62 populate the deck array with cards that have unique face and suit combinations. Both Face and Suit are public static enum types of class Card. To use these enum types outside of class Card, you must qualify each enum’s type name with the name of the class in which it resides (i.e., Card) and a dot (.) separator. Hence, lines 55 and 57 use Card.Suit and Card.Face to declare the control variables of the for statements. Recall that method values of an enum type returns an array that contains all the constants of the enum type. Lines 55–62 use enhanced for statements to construct 52 new Cards.
The shuffling occurs in line 65, which calls static method shuffle of class Collections to shuffle the elements of the array. Method shuffle requires a List argument, so we must obtain a List view of the array before we can shuffle it. Line 64 invokes static method asList of class Arrays to get a List view of the deck array.
Method printCards (lines 69–75) displays the deck of cards in two columns. In each iteration of the loop, lines 73–74 output a card left justified in a 20-character field followed by either a newline or an empty string based on the number of cards output so far. If the number of cards is even, a newline is output; otherwise, a tab is output.
16.6.3 Algorithms reverse, fill, copy, max and min
Class Collections provides algorithms for reversing, filling and copying Lists. Algorithm reverse reverses the order of the elements in a List, and algorithm fill overwrites elements in a List with a specified value. The fill operation is useful for reinitializing a List. Algorithm copy takes two arguments—a destination List and a source List. Each source List element is copied to the destination List. The destination List must be at least as long as the source List; otherwise, an IndexOutOfBoundsException occurs. If the destination List is longer, the elements not overwritten are unchanged.
Each algorithm we’ve seen so far operates on Lists. Algorithms min and max operate on any Collection—min returns the smallest element in a Collection, and algorithm max returns the largest element in a Collection. Both algorithms can be called with a Comparator object as a second argument to perform custom comparisons of objects, such as the TimeComparator in Fig. 16.11. Figure 16.13 demonstrates the use of algorithms reverse, fill, copy, min and max. Note that the generic type List is declared to store Characters.
Fig. 16.13. Collections methods reverse, fill, copy, max and min.

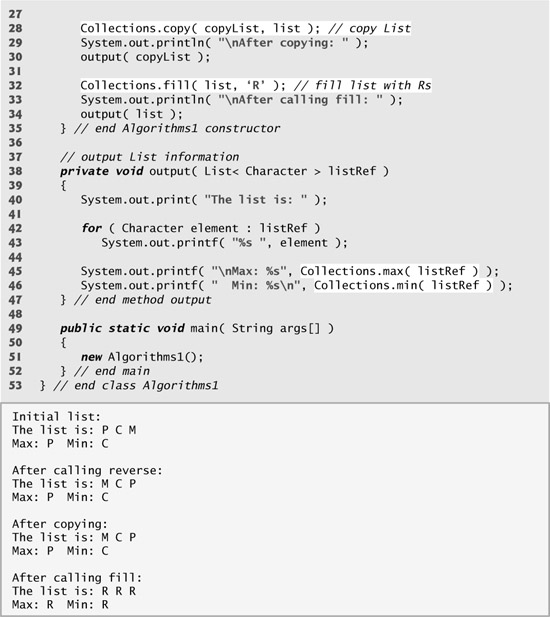
Line 24 calls Collections method reverse to reverse the order of list. Method reverse takes one List argument. In this case, list is a List view of array letters. Array letters now has its elements in reverse order. Line 28 copies the elements of list into copyList, using Collections method copy. Changes to copyList do not change letters, because copyList is a separate List that is not a List view for letters. Method copy requires two List arguments. Line 32 calls Collections method fill to place the string "R" in each element of list. Because list is a List view of letters, this operation changes each element in letters to "R". Method fill requires a List for the first argument and an Object for the second argument. Lines 45–46 call Collections methods max and min to find the largest and the smallest element of the collection, respectively. Recall that a List is a Collection, so lines 45–46 can pass a List to methods max and min.
16.6.4 Algorithm binarySearch
The high-speed binary search algorithm is built into the Java collections framework as a static method of class Collections. The binarySearch algorithm locates an object in a List (i.e., a LinkedList, a Vector or an ArrayList). If the object is found, its index is returned. If the object is not found, binarySearch returns a negative value. Algorithm binarySearch determines this negative value by first calculating the insertion point and making its sign negative. Then, binarySearch subtracts 1 from the insertion point to obtain the return value, which guarantees that method binarySearch returns positive numbers (>= 0) if and only if the object is found. If multiple elements in the list match the search key, there is no guarantee which one will be located first. Figure 16.14 uses the binarySearch algorithm to search for a series of strings in an ArrayList.
Fig. 16.14. Collections method binarySearch.


Recall that both List and ArrayList are generic types (lines 12 and 17). Collections method binarySearch expects the list’s elements to be sorted in ascending order, so line 18 in the constructor sorts the list with Collections method sort. If the list’s elements are not sorted, the result is undefined. Line 19 outputs the sorted list. Method search (lines 23–31) is called from main to perform the searches. Each search calls method printSearchResults (lines 34–45) to perform the search and output the results. Line 39 calls Collections method binarySearch to search list for the specified key. Method binarySearch takes a List as the first argument and an Object as the second argument. Lines 41–44 output the results of the search. An overloaded version of binarySearch takes a Comparator object as its third argument, which specifies how binarySearch should compare elements.
16.6.5 Algorithms addAll, frequency and disjoint
Class Collections also provides the algorithms addAll, frequency and disjoint. Algorithm addAll takes two arguments—a Collection into which to insert the new element(s) and an array that provides elements to be inserted. Algorithm frequency takes two arguments—a Collection to be searched and an Object to be searched for in the collection. Method frequency returns the number of times that the second argument appears in the collection. Algorithm disjoint takes two Collections and returns true if they have no elements in common. Figure 16.15 demonstrates the use of algorithms addAll, frequency and disjoint.
Fig. 16.15. Collections method addAll, frequency and disjoint.


Line 19 initializes list with elements in array colors, and lines 20–22 add Strings "black", "red" and "green" to vector. Line 31 invokes method addAll to add elements in array colors to vector. Line 40 gets the frequency of String "red" in Collection vector using method frequency. Note that lines 41–42 use the new printf method to print the frequency. Line 45 invokes method disjoint to test whether Collections list and vector have elements in common.
16.7 Stack Class of Package java.util
In this section, we investigate class Stack in the Java utilities package (java.util). Section 16.5.3 discussed class Vector, which implements a dynamically resizable array. Class Stack extends class Vector to implement a stack data structure. Autoboxing occurs when you add a primitive type to a Stack, because class Stack stores only references to objects. Figure 16.16 demonstrates several Stack methods. For the details of class Stack, visit java.sun.com/javase/6/docs/api/java/util/Stack.html.
Fig. 16.16. Stack class of package java.util.

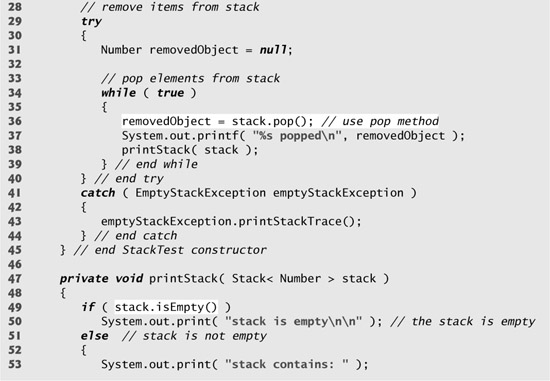

Line 10 of the constructor creates an empty Stack of type Number. Class Number (in package java.lang) is the superclass of most wrapper classes (e.g., Integer, Double) for the primitive types. By creating a Stack of Number, objects of any class that extends the Number class can be pushed onto the stack. Lines 19, 21, 23 and 25 each call Stack method push to add objects to the top of the stack. Note the literals 12L (line 13) and 1.0F (line 15). Any integer literal that has the suffix L is a long value. An integer literal without a suffix is an int value. Similarly, any floating-point literal that has the suffix F is a float value. A floating-point literal without a suffix is a double value. You can learn more about numeric literals in the Java Language Specification at java.sun.com/docs/books/jls/second_edition/html/expressions.doc.html#224125.
An infinite loop (lines 34–39) calls Stack method pop to remove the top element of the stack. The method returns a Number reference to the removed element. If there are no elements in the Stack, method pop throws an EmptyStackException, which terminates the loop. Class Stack also declares method peek. This method returns the top element of the stack without popping the element off the stack.
Line 49 calls Stack method isEmpty (inherited by Stack from class Vector) to determine whether the stack is empty. If it is empty, the method returns true; otherwise, the method returns false.
Method printStack (lines 47–61) uses the enhanced for statement to iterate through the elements in the stack. The current top of the stack (the last value pushed onto the stack) is the first value printed. Because class Stack extends class Vector, the entire public interface of class Vector is available to clients of class Stack.
![]()
Because Stack extends Vector, all public Vector methods can be called on Stack objects, even if the methods do not represent conventional stack operations. For example, Vector method add can be used to insert an element anywhere in a stack—an operation that could “corrupt” the stack. When manipulating a Stack, only methods push and pop should be used to add elements to and remove elements from the Stack, respectively.
16.8 Class PriorityQueue and Interface Queue
In this section we investigate interface Queue and class PriorityQueue in the Java utilities package (java.util). Queue, a new collection interface introduced in Java SE 5, extends interface Collection and provides additional operations for inserting, removing and inspecting elements in a queue. PriorityQueue, one of the classes that implements the Queue interface, orders elements by their natural ordering as specified by Comparable elements’ compareTo method or by a Comparator object that is supplied through the constructor.
Class PriorityQueue provides functionality that enables insertions in sorted order into the underlying data structure and deletions from the front of the underlying data structure. When adding elements to a PriorityQueue, the elements are inserted in priority order such that the highest-priority element (i.e., the largest value) will be the first element removed from the PriorityQueue.
The common PriorityQueue operations are offer to insert an element at the appropriate location based on priority order, poll to remove the highest-priority element of the priority queue (i.e., the head of the queue), peek to get a reference to the highest-priority element of the priority queue (without removing that element), clear to remove all elements in the priority queue and size to get the number of elements in the priority queue. Figure 16.17 demonstrates the PriorityQueue class.
Fig. 16.17. PriorityQueue test program.

Line 10 creates a PriorityQueue that stores Doubles with an initial capacity of 11 elements and orders the elements according to the object’s natural ordering (the defaults for a PriorityQueue). Note that PriorityQueue is a generic class and that line 10 instantiates a PriorityQueue with a type argument Double. Class PriorityQueue provides five additional constructors. One of these takes an int and a Comparator object to create a PriorityQueue with the initial capacity specified by the int and the ordering by the Comparator. Lines 13–15 use method offer to add elements to the priority queue. Method offer throws a NullPointException if the program attempts to add a null object to the queue. The loop in lines 20–24 uses method size to determine whether the priority queue is empty (line 20). While there are more elements, line 22 uses PriorityQueue method peek to retrieve the highest-priority element in the queue for output (without actually removing the element from the queue). Line 23 removes the highest-priority element in the queue with method poll.
16.9 Sets
A Set is a Collection that contains unique elements (i.e., no duplicate elements). The collections framework contains several Set implementations, including HashSet and TreeSet. HashSet stores its elements in a hash table, and TreeSet stores its elements in a tree. The concept of hash tables is presented in Section 16.10. Figure 16.18 uses a HashSet to remove duplicate strings from a List. Recall that both List and Collection are generic types, so line 18 creates a List that contains String objects, and line 24 passes a Collection of Strings to method printNonDuplicates.
Fig. 16.18. HashSet used to remove duplicate values from array of strings.
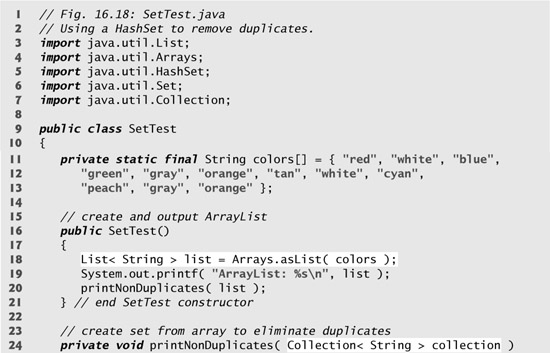
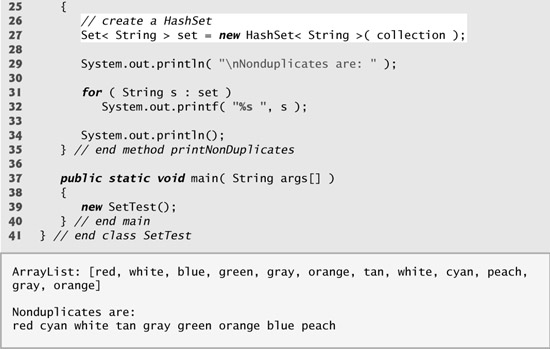
Method printNonDuplicates (lines 24–35), which is called from the constructor, takes a Collection argument. Line 27 constructs a HashSet from the Collection argument. Note that both Set and HashSet are generic types. By definition, Sets do not contain any duplicates, so when the HashSet is constructed, it removes any duplicates in the Collection. Lines 31–32 output elements in the Set.
Sorted Sets
The collections framework also includes interface SortedSet (which extends Set) for sets that maintain their elements in sorted order—either the elements’ natural order (e.g., numbers are in ascending order) or an order specified by a Comparator. Class TreeSet implements SortedSet. The program in Fig. 16.19 places strings into a TreeSet. The strings are sorted as they are added to the TreeSet. This example also demonstrates range-view methods, which enable a program to view a portion of a collection.
Fig. 16.19. Using SortedSets and TreeSets.


Lines 16–17 of the constructor create a TreeSet of Strings that contains the elements of array names and assigns the SortedSet to variable tree. Both SortedSet and TreeSet are generic types. Line 20 outputs the initial set of strings using method printSet (lines 36–42), which we discuss momentarily. Line 24 calls TreeSet method headSet to get a subset of the TreeSet in which every element is less than "orange". The view returned from headSet is then output with printSet. If any changes are made to the subset, they will also be made to the original TreeSet, because the subset returned by headSet is a view of the TreeSet.
Line 28 calls TreeSet method tailSet to get a subset in which each element is greater than or equal to "orange", then outputs the result. Any changes made through the tailSet view are made to the original TreeSet. Lines 31–32 call SortedSet methods first and last to get the smallest and largest elements of the set, respectively.
Method printSet (lines 36–42) accepts a SortedSet as an argument and prints it. Lines 38–39 print each element of the SortedSet using the enhanced for statement.
16.10 Maps
Maps associate keys to values and cannot contain duplicate keys (i.e., each key can map to only one value; this is called one-to-one mapping). Maps differ from Sets in that Maps contain keys and values, whereas Sets contain only values. Three of the several classes that implement interface Map are Hashtable, HashMap and TreeMap. Hashtables and HashMaps store elements in hash tables, and TreeMaps store elements in trees. This section discusses hash tables and provides an example that uses a HashMap to store keyPvalue pairs. Interface SortedMap extends Map and maintains its keys in sorted order—either the elements’ natural order or an order specified by a Comparator. Class TreeMap implements SortedMap.
Map Implementation with Hash Tables
Object-oriented programming languages facilitate creating new types. When a program creates objects of new or existing types, it may need to store and retrieve them efficiently. Storing and retrieving information with arrays is efficient if some aspect of your data directly matches a numerical key value and if the keys are unique and tightly packed. If you have 100 employees with nine-digit social security numbers and you want to store and retrieve employee data by using the social security number as a key, the task would require an array with one billion elements, because there are one billion unique nine-digit numbers (000,000,000–999,999,999). This is impractical for virtually all applications that use social security numbers as keys. A program that had an array that large could achieve high performance for both storing and retrieving employee records by simply using the social security number as the array index.
Numerous applications have this problem—namely, that either the keys are of the wrong type (e.g., not positive integers that correspond to array subscripts) or they are of the right type, but sparsely spread over a huge range. What is needed is a high-speed scheme for converting keys such as social security numbers, inventory part numbers and the like into unique array indices. Then, when an application needs to store something, the scheme could convert the application’s key rapidly into an index, and the record could be stored at that slot in the array. Retrieval is accomplished the same way: Once the application has a key for which it wants to retrieve a data record, the application simply applies the conversion to the key—this produces the array index where the data is stored and retrieved.
The scheme we describe here is the basis of a technique called hashing. Why the name? When we convert a key into an array index, we literally scramble the bits, forming a kind of “mishmashed,” or hashed, number. The number actually has no real significance beyond its usefulness in storing and retrieving a particular data record.
A glitch in the scheme is called a collision—this occurs when two different keys “hash into” the same cell (or element) in the array. We cannot store two values in the same space, so we need to find an alternative home for all values beyond the first that hash to a particular array index. There are many schemes for doing this. One is to “hash again” (i.e., to apply another hashing transformation to the key to provide a next candidate cell in the array). The hashing process is designed to distribute the values throughout the table, so the assumption is that an available cell will be found with just a few hashes.
Another scheme uses one hash to locate the first candidate cell. If that cell is occupied, successive cells are searched in order until an available cell is found. Retrieval works the same way: The key is hashed once to determine the initial location and check whether it contains the desired data. If it does, the search is finished. If it does not, successive cells are searched linearly until the desired data is found.
The most popular solution to hash-table collisions is to have each cell of the table be a hash “bucket,” typically a linked list of all the key/value pairs that hash to that cell. This is the solution that Java’s Hashtable and HashMap classes (from package java.util) implement. Both Hashtable and HashMap implement the Map interface. The primary differences between them are that HashMap is unsynchronized (multiple threads should not modify a HashMap concurrently), and allows null keys and null values.
A hash table’s load factor affects the performance of hashing schemes. The load factor is the ratio of the number of occupied cells in the hash table to the total number of cells in the hash table. The closer this ratio gets to 1.0, the greater the chance of collisions.
Performance Tip 16.7
![]()
The load factor in a hash table is a classic example of a memory-space/execution-time trade-off: By increasing the load factor, we get better memory utilization, but the program runs slower, due to increased hashing collisions. By decreasing the load factor, we get better program speed, because of reduced hashing collisions, but we get poorer memory utilization, because a larger portion of the hash table remains empty.
Hash tables are complex to program. Java provides classes Hashtable and HashMap to enable programmers to use hashing without having to implement hash table mechanisms. This concept is profoundly important in our study of object-oriented programming. As discussed in earlier chapters, classes encapsulate and hide complexity (i.e., implementation details) and offer user-friendly interfaces. Properly crafting classes to exhibit such behavior is one of the most valued skills in the field of object-oriented programming. Figure 16.20 uses a HashMap to count the number of occurrences of each word in a string.
Fig. 16.20. HashMaps and Maps.



Line 17 creates an empty HashMap with a default initial capacity (16 elements) and a default load factor (0.75)—these defaults are built into the implementation of HashMap. When the number of occupied slots in the HashMap becomes greater than the capacity times the load factor, the capacity is doubled automatically. Note that HashMap is a generic class that takes two type arguments. The first specifies the type of key (i.e., String), and the second the type of value (i.e., Integer). Recall that the type arguments passed to a generic class must be reference types, hence the second type argument is Integer, not int. Line 18 creates a Scanner that reads user input from the standard input stream. Line 19 calls method createMap (lines 24–46), which uses a map to store the number of occurrences of each word in the sentence. Line 27 invokes method nextLine of scanner to obtain the user input, and line 30 creates a StringTokenizer to break the input string into its component individual words. This StringTokenizer constructor takes a string argument and creates a StringTokenizer for that string and will use the white space to separate the string. The condition in the while statement in lines 33–45 uses StringTokenizer method hasMoreTokens to determine whether there are more tokens in the string being tokenized. If so, line 35 converts the next token to lowercase letters. The next token is obtained with a call to StringTokenizer method nextToken that returns a String. [Note: Section 25.6 discusses class StringTokenizer in detail.] Then line 38 calls Map method containsKey to determine whether the word is in the map (and thus has occurred previously in the string). If the Map does not contain a mapping for the word, line 44 uses Map method put to create a new entry in the map, with the word as the key and an Integer object containing 1 as the value. Note that autoboxing occurs when the program passes integer 1 to method put, because the map stores the number of occurrences of the word as Integer. If the word does exist in the map, line 40 uses Map method get to obtain the key’s associated value (the count) in the map. Line 41 increments that value and uses put to replace the key’s associated value in the map. Method put returns the prior value associated with the key, or null if the key was not in the map.
Method displayMap (lines 49–64) displays all the entries in the map. It uses HashMap method keySet (line 51) to get a set of the keys. The keys have type String in the map, so method keySet returns a generic type Set with type parameter specified to be String. Line 54 creates a TreeSet of the keys, in which the keys are sorted. The loop in lines 59–60 accesses each key and its value in the map. Line 60 displays each key and its value using format specifier %-10s to left justify each key and format specifier %10s to right justify each value. Note that the keys are displayed in ascending order. Line 63 calls Map method size to get the number of key–value pairs in the Map. Line 64 calls isEmpty, which returns a boolean indicating whether the Map is empty.
16.11 Properties Class
A Properties object is a persistent Hashtable that normally stores key–value pairs of strings—assuming that you use methods setProperty and getProperty to manipulate the table rather than inherited Hashtable methods put and get. By “persistent,” we mean that the Properties object can be written to an output stream (possibly a file) and read back in through an input stream. A common use of Properties objects in prior versions of Java was to maintain application-configuration data or user preferences for applications. [Note: The Preferences API (package java.util.prefs) is meant to replace this particular use of class Properties but is beyond the scope of this book. To learn more, visit java.sun.com/javase/6/docs/technotes/guides/preferences/index.html.]
Class Properties extends class Hashtable. Figure 16.21 demonstrates several methods of class Properties.
Fig. 16.21. Properties class of package java.util.



Line 16 uses the no-argument constructor to create an empty Properties table with no default properties. Class Properties also provides an overloaded constructor that receives a reference to a Properties object containing default property values. Lines 19 and 20 each call Properties method setProperty to store a value for the specified key. If the key does not exist in the table, setProperty returns null; otherwise, it returns the previous value for that key.
Line 41 calls Properties method getProperty to locate the value associated with the specified key. If the key is not found in this Properties object, getProperty returns null. An overloaded version of this method receives a second argument that specifies the default value to return if getProperty cannot locate the key.
Line 57 calls Properties method store to save the contents of the Properties object to the OutputStream object specified as the first argument (in this case, FileOutputStream output). The second argument, a String, is a description of the Properties object. Class Properties also provides method list, which takes a PrintStream argument. This method is useful for displaying the list of properties.
Line 75 calls Properties method load to restore the contents of the Properties object from the InputStream specified as the first argument (in this case, a FileInputStream). Line 89 calls Properties method keySet to obtain a Set of the property names. Line 94 obtains the value of a property by passing a key to method getProperty.
16.12 Synchronized Collections
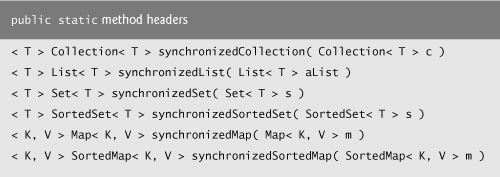
In Chapter 18, we discuss multithreading. Except for Vector and Hashtable, the collections in the collections framework are unsynchronized by default, so they can operate efficiently when multithreading is not required. Because they are unsynchronized, however, concurrent access to a Collection by multiple threads could cause indeterminate results or fatal errors. To prevent potential threading problems, synchronization wrappers are used for collections that might be accessed by multiple threads. A wrapper object receives method calls, adds thread synchronization (to prevent concurrent access to the collection) and delegates the calls to the wrapped collection object. The Collections API provides a set of static methods for wrapping collections as synchronized versions. Method headers for the synchronization wrappers are listed in Fig. 16.22. Details about these methods are available at java.sun.com/javase/6/docs/api/java/util/Collections.html. All these methods take a generic type and return a synchronized view of the generic type. For example, the following code creates a synchronized List (list2) that stores String objects:
List< String > list1 = new ArrayList< String >();
List< String > list2 = Collections.synchronizedList( list1 );
Fig. 16.22. Synchronization wrapper methods.
16.13 Unmodifiable Collections
The Collections API provides a set of static methods that create unmodifiable wrappers for collections. Unmodifiable wrappers throw UnsupportedOperationExceptions if attempts are made to modify the collection. Headers for these methods are listed in Fig. 16.23. Details about these methods are available at java.sun.com/javase/6/docs/api/java/util/Collections.html. All these methods take a generic type and return an unmodifiable view of the generic type. For example, the following code creates an unmodifiable List (list2) that stores String objects:
List< String > list1 = new ArrayList< String >();
List< String > list2 = Collections.unmodifiableList( list1 );
Fig. 16.23. Unmodifiable wrapper methods.

Software Engineering Observation 16.5
![]()
You can use an unmodifiable wrapper to create a collection that offers read-only access to others, while allowing read–write access to yourself. You do this simply by giving others a reference to the unmodifiable wrapper while retaining for yourself a reference to the original collection.
16.14 Abstract Implementations
The collections framework provides various abstract implementations of Collection interfaces from which the programmer can quickly “flesh out” complete customized implementations. These abstract implementations include a thin Collection implementation called an AbstractCollection, a thin List implementation that allows random access to its elements called an AbstractList, a thin Map implementation called an AbstractMap, a thin List implementation that allows sequential access to its elements called an AbstractSequentialList, a thin Set implementation called an AbstractSet and a thin Queue implementation called AbstractQueue. You can learn more about these classes at java.sun.com/javase/6/docs/api/java/util/package-summary.html.
To write a custom implementation, you can extend the abstract implementation that best meets your needs, and implement each of the class’s abstract methods. Then, if your collection is to be modifiable, override any concrete methods that prevent modification.
16.15 Wrap-Up
This chapter introduced the Java collections framework. You learned how to use class Arrays to perform array manipulations. You learned the collection hierarchy and how to use the collections framework interfaces to program with collections polymorphically. You also learned several predefined algorithms for manipulating collections. In the next chapter, you will continue your study of GUI concepts, building on the techniques you learned in Chapter 11.