
Input Validation
If there is one overarching, primary security principle, it is this: Never Trust the User. In fact, we should write it like this:
NEVER TRUST THE USER
We understand that taking this viewpoint may seem overly negative or pessimistic. After all, our users are the reason that we create products and services in the first place. It almost seems disloyal not to trust them, as if we’re an overly suspicious shopkeeper who plasters “Camera Surveillance 24/7” and “Shoplifters Will Be Prosecuted to the Full Extent of the Law” signs all over his store and keeps an eagle eye on anyone who walks in his door. And what makes matters even worse is that we want—actually, we need—our users to trust us. We ask a lot from them. We ask them for their e-mail addresses, hoping that they trust us enough not to turn around and sell them to spammers (or spam them ourselves). We ask them for their physical addresses and phone numbers. We ask them for their credit card numbers. If you’re like most people, you’ve probably entered data into a faceless corporate web site that you’d be hesitant about giving out even to your best friend. But while we ask for their trust, we offer none in return—in fact, we can offer none in return. It’s ironic that trust on the Web is a one-way street: if we did trust our users, we would become completely untrustworthy ourselves.
The first and best way you can defend your applications from potentially malicious users—and remember, you have to treat all users as potentially malicious—is to validate the data they input into your systems. Remember the wizard and the giant in the magic fruit orchard story from the last chapter. The wizard asked the giant to serve the villagers’ requests, but the wizard never explained what the limits of those requests should be. (To put it more specifically, he never explained what a “valid” request should be like versus an “invalid” request.) And as we all know, neither giants nor computers have much intelligence of their own; they only do exactly what we tell them to. We need to explicitly describe the format of a valid request input to keep our application from processing an invalid input, and thus potentially falling victim to an attack.
Blacklist Validation
Most peoples’ first instinct when coming up with an input validation approach is to list out all the inputs that are invalid (or create a pattern of invalid inputs) and then block anything that matches that list. The problem with this approach is that it’s extremely difficult to list out everything that should be blocked, especially in light of the fact that the list will probably change over time (and change often).
To draw a real-world analogy for this—yes, more real-world than wizards and giants and magical fruit orchards—imagine that instead of designing web applications for a living, you own a restaurant. You want your restaurant to be world-class, so you’ve hired a top-notch chef, purchased the nicest crystal wine glasses and silverware, and even contracted an interior design firm to decorate the dining area in a trendy, ultramodern style. A Michelin star (http://www.michelinguide.com/) is within your reach, but to get it you’ll have to impose a dress code on your customers. After all, you don’t want just any riffraff coming in off the street wearing cut-off jean shorts and combat boots. So, you instruct your maître d’ to politely decline to seat anyone who comes in wearing anything from this list of prohibitions:
![]() No shorts
No shorts
![]() No T-shirts
No T-shirts
![]() No jeans
No jeans
![]() No sweatpants
No sweatpants
![]() No hoodies
No hoodies
You figure this should just about cover the list of fashion faux pas, but to your shock and horror you come into your restaurant one night to find an entire table of customers dining barefoot. You hadn’t considered that anyone would want to do this before, and although you wish your maître d’ had had enough sense of his own not to let them in, you know it’s your own fault and not his. You make a quick addition to the list of restrictions so that this won’t happen again:
![]() No shorts
No shorts
![]() No T-shirts
No T-shirts
![]() No jeans
No jeans
![]() No sweatpants
No sweatpants
![]() No hoodies
No hoodies
![]() No bare feet
No bare feet
Sure that this time you’ve covered every possibility, you head home for the night, but when you come back in the next day, you get an even bigger shock. Your entire restaurant is completely deserted except for two tables. At one table, you see the same people who were barefoot last night, and this time they are indeed wearing shoes . . . but only shoes. No shirts, no pants, no anything else. And at the other table, you recognize the food critic from Bon Appétit magazine, scribbling notes into a pad and laughing to herself. At this point, you can pretty much kiss your Michelin star (if not your business license) goodbye.
This kind of validation logic, where you try to list out all the possible negative conditions you want to block, is called blacklist validation. Using blacklist validation on its own is almost never successful: as we just saw, it’s not easy to successfully list every possible condition you’d want to block, especially when the list is constantly in flux. Maybe you do manage to compile a huge, comprehensive list of every clothing style you want to ban from your restaurant, but then the new season of Jersey Shore starts up and you have to add five new pages to the list.
Another critical failure of the blacklist approach is that it’s impossible to list out every possible unwanted or malicious input value since there are so many different various ways to encode or escape input. For example, let’s say that you wanted to block any input value containing an apostrophe, since you know that attackers can use apostrophes to break out of database command strings and inject SQL attacks. Unfortunately, there are many ways to represent an apostrophe character besides just the normal “’”:
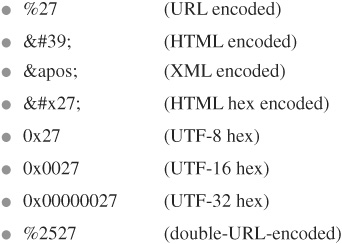
Even if you could completely block apostrophes in all their various representations, you also have to consider what would happen to any of your users who happen to have apostrophes in their names or street addresses. And it’s generally considered a good security practice to include punctuation characters in passwords as well since this increases the range of possible values that an attacker would need to guess.
A blacklisting approach gets even more difficult if you’re trying to use it to prevent users from accessing certain files or URLs. We’ll discuss this in more detail in the file security chapter, but for now consider just a handful of the infinite number of possible ways to encode the name of the web page www.site.cxx/my page.html:
![]() http://www.site.cxx/my page.html
http://www.site.cxx/my page.html
![]() http://www.site.cxx/My Page.html
http://www.site.cxx/My Page.html
![]() http://www.site.cxx/MY PAGE.HTML
http://www.site.cxx/MY PAGE.HTML
![]() http://www.site.cxx/my%20page.html
http://www.site.cxx/my%20page.html
![]() http://www.site.cxx:80/my page.html
http://www.site.cxx:80/my page.html
![]() http://www.site.cxx/./my page.html
http://www.site.cxx/./my page.html
Whitelist Validation
The same principle applies when you try to use blacklist validation alone to defend your web applications. Even if you could manage to list out every possible SQL injection or cross-site scripting attack string, someone could come up with a brand-new attack technique tomorrow and render your list obsolete. A much better strategy—whether you’re a programmer or a restaurateur—is to employ whitelist validation.
Instead of listing out and matching what should be blocked, as blacklist validation does, whitelist validation works by listing out and matching only what should be allowed. Any input that does not match an explicit allow-list or allow-pattern is rejected. For the restaurant, this might mean that you set a policy where men must wear a dress shirt, suit, and dress shoes; and women must wear an evening dress and pumps. Any deviation from this policy and you’re quickly shown the door. Now that we have a strategy in mind, let’s extend this approach to web application input validation.
Sometimes implementing a whitelist validation strategy is straightforward and simple. If you’re expecting the user to choose an input value from a short, predefined list, then you can easily just check the value against that list. Good candidates for this are any lists of values that are selected by radio buttons or drop-down lists. For example, let’s say you’re building a car configuration application. You want to give the user three choices for the exterior color: “Midnight Blue,” “Sunset Red,” or “Canary Yellow,” so you put these three values into a drop-down list. Your validation logic can simply check that the form value for the color field is “Midnight Blue,” “Sunset Red,” or “Canary Yellow.”
You might be wondering why you’d even need to apply validation logic in this case. After all, since the choices appear in a drop-down list, doesn’t the browser enforce this rule itself? There’s no way a user could send any value other than “Midnight Blue,” “Sunset Red,” or “Canary Yellow,” right? You may be surprised to learn that this is definitely not true, and this misconception leads to many exploitable vulnerabilities in web applications.
Although a browser might prevent users from selecting any value other than what you intended, that doesn’t necessarily mean that a browser is the only way to send data to a web application. Under the covers, the browser is just building HTTP requests, sending them to the web application, and processing the application’s HTTP responses. There’s absolutely nothing to prevent an attacker from manually crafting an HTTP request (or even easier, modifying an outgoing request that the browser has already gone to the trouble of creating itself) and then sending that to the target application. And there’s no way for the web application to tell that this has happened. All it knows it that it was expecting a request like this:

But what it got was a request like this:

While this might not seem like a huge security risk (beyond possibly crashing the web application, which, as we’ll discuss later in this chapter, is more of a problem than many people think), a message like this next one could exploit the database access logic and lead to a serious compromise of the application:

The key takeaway from this is that it’s impossible to defend the server-side logic of a web application by implementing defenses on the client side. Any validation logic that you put into client-side code can be completely bypassed by an attacker, whether it’s constraining the user’s input choices through the choice of user interface objects (that is, using drop-down lists and radio buttons instead of text fields) or something more elaborate like JavaScript regular expression validation.
And speaking of regular expressions, using regular expressions (or regexes) is one very good way of handling more complicated whitelist validation logic. For something simple like validating a choice of color for a new car, it’s easy enough just to check the incoming value against a predefined list. But to continue the car configuration example, let’s say that at the end of the configuration process, you ask the user for their e-mail address so that you can send them a quote for their new car. You certainly can’t check the address they give you against a predefined list of valid e-mail addresses. This is the kind of situation where regexes work well.
More Validation Practices
So far, we’ve talked about why you need to validate input, and how best to do it, but we haven’t yet answered two other important questions: what input to validate and where to validate it.
In terms of what input to validate, the short answer is: validate any untrusted input. This does beg the question of (and require a much longer answer): what input should be considered untrusted? Remember the primary security principle we laid out at the start of this chapter: never trust the user. To start, you must consider any input that you get directly from a user request to be tainted and potentially malicious. This includes not just web form control values as we’ve already discussed, but also any query string parameters, any cookie values, and any header values. All of these inputs are completely controllable by an attacker.
However, don’t take this to mean that all other sources of input besides web requests that come in directly from the user are automatically trustworthy. What about the data that you pull from your database? While you might suppose this is safe—after all, it’s your database—think about how that data got into that database in the first place. Was it built from user input? If so, you’re right back in the same situation. What if you got the data from some other company or organization? Can you trust them completely? (Hint: no, you can’t.) And where did they get the data from? Since you can’t guarantee that this data was validated before you got it, you need to assume that it’s potentially dangerous and validate it yourself.
A real-world example of this scenario is the Asprox SQL injection worm that started attacking web sites in 2008. The worm searched Google to find sites that were potentially vulnerable to injection attacks, and in a clever twist, when it found one, it did not pull out the victim’s data, but rather added its own data in. When the victim web application pulled data from its now-compromised database to display to users, it actually served them the Asprox worm’s injected malware.
This leads us to the second question we posed at the top of this section: Where is the best place to validate input? (In the case of the Asprox attacks, the victim web sites were exploited because they didn’t validate input anywhere, which is definitely not the right answer.) There are two schools of thought about this question. Some security professionals believe that the best place to validate input is right as it comes into the system, before it gets stored in any temporary variables or session state or passed to subroutines. This way, whenever you use the data, you know it has already been checked and is considered safe. The opposing viewpoint is that the best place to validate input is right before you use it. This way, you don’t have to rely on another module that might have failed or changed without your knowing it.
IMHO
In terms of the validate-early or validate-late debate, while I do see merit in both arguments, I have to come down on the side of the late validators. Again, it’s a matter of trust. When you validate early, every other module or routine that processes the data has to trust that the validation actually was performed and was performed correctly. A colleague of mine refers to this as the “Lettuce Issue.” She says that while the grocery store may claim to sell you pre-washed lettuce, she always washes it again herself before she makes her salads, since that’s the only way to really be sure. The same principle applies to input validation: give that user input a good thorough washing right before you use it.
The Defense-in-Depth Approach
Of course, another approach to consider would be to validate input both as it comes in and right before it’s used. This may have some additional impact on the application’s performance, but it will provide a more thorough defense-in-depth security stance.
If you’re unfamiliar with the concept of defense-in-depth, it essentially refers to a technique of mitigating the same vulnerabilities in multiple places and/or with multiple different defenses. This way, if a failure occurs at any one point, you’re not left completely vulnerable. For example, although we strongly discouraged you from using blacklist input validation as your only method of input validation, it does make a good defense-in-depth technique when used in combination with whitelist validation.
![]() Never trust the user!
Never trust the user!
![]() Validate all input coming from a user. This includes any part of an HTTP request that you’re processing: the header names and values, the cookie names and values, the querystring parameters, web form values, and any other data included in the message body.
Validate all input coming from a user. This includes any part of an HTTP request that you’re processing: the header names and values, the cookie names and values, the querystring parameters, web form values, and any other data included in the message body.
![]() Always use whitelist input validation to test input; that is, test whether an input does match an expected good format and reject it if it doesn’t. Avoid blacklist input validation; that is, testing whether an input matches an expected bad format and rejecting it if it does.
Always use whitelist input validation to test input; that is, test whether an input does match an expected good format and reject it if it doesn’t. Avoid blacklist input validation; that is, testing whether an input matches an expected bad format and rejecting it if it does.
![]() Never perform validation just on the client side—an attacker can easily bypass these controls. Always validate on the server side.
Never perform validation just on the client side—an attacker can easily bypass these controls. Always validate on the server side.
![]() Use regular expressions for more complicated validation logic like testing e-mail addresses. Unless you’re a regex expert, also consider using a regex from one of the public databases such as regexlib.com or a commercial regex development tool such as Regex Buddy.
Use regular expressions for more complicated validation logic like testing e-mail addresses. Unless you’re a regex expert, also consider using a regex from one of the public databases such as regexlib.com or a commercial regex development tool such as Regex Buddy.
![]() If you can afford the performance hit, validate input both as it comes into your application and again immediately before you use it. But if you can only do it in one place, do it immediately before use.
If you can afford the performance hit, validate input both as it comes into your application and again immediately before you use it. But if you can only do it in one place, do it immediately before use.