
Yellowstone: A Dedicated Resource for Earth System Science
National Center for Atmospheric Research
University of Wyoming
Center for Ocean-Land-Atmosphere Studies
8.1.2 Sponsor and Program Background
8.5.1 Operating Systems and System Management
8.5.2 Disk Filesystem and Tape Archive
8.6 Workload and Application Performance
8.6.1 Application Domain Descriptions
8.7.2 Reliability, Uptime, and Utilization
8.9.2 Early Experience in Operation
8.11 Acknowledgments and Contributions
Climate and weather modeling have been recognized as one of the great computational grand challenges as far back as 1950, when the ENIAC system was used to perform the first numerical simulations of a highly simplified set of nonlinear atmospheric equations [6]. Developing hand in hand with improved observational platforms such as weather satellites, computer forecasts have become steadily more skillful, saving lives and reducing property losses through earlier warning times and more accurate predictions. In 1956, scientists first began computer-based simulations of the climate using a general circulation of the atmosphere [40]. The realism of such models improved in subsequent decades as computer capabilities increased, and when combined with new observations and improved theoretical understanding, this work slowly and convincingly revealed the role of anthropogenic carbon dioxide in changing the Earth’s climate.
Now, with the Yellowstone supercomputer and associated cyberinfrastructure, science is poised to take the next step in advancing the understanding of how our planet works by dramatically accelerating the advancement of Earth System science. When viewed in the context of the increasingly severe impacts on society of natural disasters and the catastrophic long-term implications of climate change, the sense of urgency to develop an integrated and improved understanding of our planet becomes clear.
The Yellowstone environment provides dedicated petascale computational and data resources to the U.S. atmospheric science communities, enabling dramatic improvements in resolution, better representations of physical processes, longer simulation length, and better statistics for a broad spectrum of important Earth System science applications. The deployment of Yellowstone advances three crucial scientific capabilities. First, long-term climate studies can routinely account for small-scale ocean eddies that influence atmospheric weather patterns and transport heat and nutrients throughout the world’s oceans. Second, scientists can begin improving the representation of clouds – perhaps the greatest source of uncertainty remaining in climate system models. Third, scientists can study the regional impacts of climate change more effectively using simulations with nested grids at meteorological resolutions. This capability will help scientists investigate the connection between climate and hurricane frequency and strength, study the localized effects of regional climate change on agriculture and water supplies, and investigate numerous other computationally demanding Earth System processes. Solar researchers will be able to use vastly enhanced computer models of the Sun that enable the first-ever simulations of the full life cycle of sunspot assemblages, unlock the mechanisms behind the 11-year solar cycle, model coronal mass ejections, and understand the role of solar variability in climate.
Yellowstone is housed at the NCAR-Wyoming Supercomputing Center (NWSC) in Cheyenne, Wyoming. The NWSC data center is funded by the National Science Foundation (NSF) and the State of Wyoming, and is operated by the National Center for Atmospheric Research. The NWSC and Yellowstone resulted from a partnership between the University Corporation for Atmospheric Research (UCAR), the State of Wyoming, the University of Wyoming, the Wyoming Business Council, Cheyenne LEADS, and Cheyenne Light Fuel and Power Company. University of Wyoming researchers are using their share of Yellowstone to study changes in Wyoming’s regional climate and hydrology, the design of proposed local wind turbine farms, seismic hazards, and the long-term stability of carbon sequestration sites in the region.
8.1.2 Sponsor and Program Background
The National Center for Atmospheric Research (NCAR) is a federally funded research and development center devoted to advancing the atmospheric and related sciences. NCAR’s mission is to understand the behavior of the atmosphere and the physical, biological, and societal systems that interact with and depend on it. The NSF is NCAR’s primary sponsor, and significant additional support is provided by other U.S. government agencies, other national governments, and the private sector. Beyond its core science mission, NCAR develops and maintains a variety of services and facilities used by scientists, including state-of-the-art supercomputers and databases, community-driven computer models of weather and climate, and observational platforms including aircraft, radar, and spacecraft. NCAR is managed by the University Corporation for Atmospheric Research (UCAR), a non-profit research and education institution with a mission to support, enhance, and extend the capabilities of the university community, nationally and internationally, and to foster the transfer of knowledge and technology for the betterment of life on Earth.
NCAR’s supercomputing and data resources are operated by the Computational and Information Systems Laboratory (CISL), which provides HPC services to 78 UCAR member universities, 26 UCAR affiliate universities, NCAR scientists, and the larger geosciences community. Originally founded in 1964, CISL has been involved in supercomputing since the very beginning: it installed and managed a Control Data Corporation 6600 system, widely regarded as the first supercomputer. Today, CISL manages high-performance production and experimental computing systems, a High-Performance Storage System (HPSS) archival system, the Research Data Archive (RDA), networking and connectivity to the NSF’s XSEDE, and information technologies that support scientific communities. CISL provides numerous services that include around-the-clock operational support of its balanced, data-centric cyberinfrastructure; curation of research dataset libraries; development and support of discipline-specific tools for the atmospheric and related sciences; the computational science expertise required to develop new algorithms needed to efficiently execute large, long-running numerical simulations and to assimilate observations for purposes of prediction; and education, outreach, and training activities to support and enhance the diversity of the user community.
Because of NCAR’s focus on its discipline-specific science mission, it was possible to conceive and effectively co-design both the computing facility and the computational and storage systems it would house. In its entirety, this process took nearly a decade.
In 2003, NCAR recognized that the demands of future high-performance computing (HPC) systems would exceed the capabilities of its facilities and infrastructure. In December 2005, after weighing its options, UCAR decided to pursue new construction. UCAR began a competitive process for prospective regional partners, ultimately selecting a partnership proposal by the State and University of Wyoming in January 2007 to build the NCAR-Wyoming Supercomputing Center (NWSC). Using the NSF’s guidelines for major research equipment and facilities construction, NCAR and Wyoming developed a roadmap and preliminary plans for the facility in 2008. NCAR developed facility design criteria, and via RFI and RFP processes, selected the facility’s architectural and engineering firms by February 2009. In parallel, a panel assembled to identify and articulate overarching scientific objectives, then published a science justification in September 2009. The NWSC Project Development Plan was completed and the preliminary design review was conducted in October 2009. By February 2010, the facility’s design documents were completed and assessed by an external peer-review panel. A Project Execution Plan was developed and the final Facility Design Review was conducted in March 2010.
Formal groundbreaking ceremonies were held on June 15, 2010. Construction proceeded at a rapid pace and the facility’s superstructure was completed before the onset of winter. An external panel assessed the project’s status in February 2011. The building underwent final inspections in August 2011, integrated systems testing in September, and UCAR accepted the facility in October. In November 2011, CISL installed the first equipment in the facility: two StorageTek SL8500 Modular Library Systems, each with a capacity of 10,000 tape cartridges. Installation of the Yellowstone equipment began in May 2012. The NWSC Grand Opening was held on October 15, 2012. The entire construction project was completed on time and under budget.

FIGURE 8.1: Nearly a decade of planning produced the 1.5-petaflops Yellowstone system and the energy-efficient NCAR-Wyoming Supercomputing Center in Cheyenne, Wyoming.
The procurement of the first petascale HPC environment at NWSC provided a unique opportunity to design a forward-looking, data-centric system. The procurement of the Yellowstone environment began at the end of 2010 with the release of a fixed-price best-value RFP that solicited three key components: an HPC system, a centralized filesystem, and data analysis and visualization systems, each to be maintained and operated over at least a four-year lifetime. The NCAR HPSS data archive and Ethernet networking infrastructure were enhanced via separate subcontracts.
The benchmark suite used during the Yellowstone procurement process was designed to mirror the science needs of the NCAR user community [27]. To assemble the benchmark suite, CISL convened a Scientific Advisory Panel and a Technical Evaluation Team. These two groups worked together to identify a set of application and synthetic benchmarks capable of measuring the machine performance characteristics relevant to our science code base. The suite was based primarily on prominent applications, although a set of synthetic interconnect and I/O benchmarks were included to help interpret application benchmark results.
Initial vendor proposals were received in April 2011, and the procurement team began an intensive evaluation of the proposed solutions and benchmark results. After reaching a consensus, UCAR negotiated terms, obtained NSF approval, and awarded the Yellowstone subcontract to IBM in November 2011 [47]. At the time of the award, the two key technologies of the Yellowstone environment had not been released: the Intel Xeon E5 processor and Mellanox FDR InfiniBand. CISL and UCAR made the strategic decision to wait for these technologies to gain their performance advantages. Equipment delivery began in May 2012 and was completed by the end of June. IBM, Mellanox, and CISL engineers assembled the systems then performed software installation and configuration through the summer. Acceptance testing began in August, and the system received provisional acceptance in September 2012.
The Yellowstone environment consists of end-to-end petascale cyberinfrastructure designed with the recognition that data access – not flops – is the limiting factor for the scientific disciplines it serves. Its data-centric design (a) reallocated system resources to minimize data motion, (b) increased the I/O bandwidth between system components, and (c) brought more elements of the workflow under a single job scheduling system: goals long advocated for balanced systems [5]. Four aspects of the system design were influenced by these considerations: the use of a centralized disk storage system, disk storage capacity, I/O bandwidth, and analysis system characteristics.
Figure 8.2 shows that the central storage system, called the Globally Accessible Data Environment (GLADE), is the heart of the Yellowstone environment, with the systems for supercomputing, analysis and visualization, HPSS archive, data transfer, and science gateways all connected to it. GLADE eliminates the need to copy data in scientific workflows, saving file transfer overheads and disk costs. Centralizing storage is also more flexible and easier to administer, but it comes at the expense of complicating the system interconnect design. GLADE serves as the data crossroads for the system, and it provides plentiful throughput and space for scientists to run analysis workflows without resorting to using the tape archive as a slow file server.
The size and I/O bandwidth of GLADE was dictated by several interrelated factors: the relative cost of centralized disk storage to computing nodes, the ratio of I/O bandwidth to storage volume presented by storage appliances available at the time of procurement, the anticipated data production rate of the supercomputer for the anticipated science workload in terms of sustained flops per output bytes, and the 100:1 ratio of disk storage to system memory recommended by Bell et al. [5]. While these factors are interrelated, the relationships are generally linear, permitting a reasonable estimate of a balance point. In terms of budget allocation, this estimate of a balanced system implied that 20% of the system cost would go to central storage, 75% to computing nodes, and 5% to data analysis nodes. Given the aspect ratio of high performance storage appliances, this yielded an I/O bandwidth for Yellowstone lower than that projected for our most data-intensive applications, and substantially less than that suggested by Amdahl’s law [5], but adequate for most NCAR applications.
The data-centric considerations also influenced the design of Yellowstone’s data analysis and visualization systems, where memory size on some nodes was increased to one terabyte to reduce the amount of disk I/O in data analysis workflows. Placing the compute and analysis resources within the scope of a single scheduler instance enabled users to implement cross-platform workflows using familiar job submission tools.
Early production experience supports many of these design choices. A tangible measure of its success was demonstrated by its immediate high utilization despite providing a 30-fold increase in capacity compared to its predecessor. The tape archive net growth rate of 250 terabytes/week is substantially lower than the projected “business as usual” rate of 450 terabytes/week, a material realization of an anticipated cost saving. Steady-state disk storage growth rates are generally tracking with the central file system size that was chosen. Synchronous I/O overheads are reportedly under 10% for many data-intensive simulations, such as the MPAS model, another desired outcome of Yellowstone’s data-centric design.
The primary computation resource of the complex at NWSC is Yellowstone, a 1.5-petaflops IBM iDataPlex cluster supercomputer with 72,576 Intel Xeon E5 processor cores and a full fat tree Mellanox FDR Infiniband interconnect. The data analysis and visualization clusters Geyser and Caldera perform scientific analysis on the simulation output. Geyser is designed for big data analysis, while the Caldera analysis cluster additionally offers parallel visualization or GPGPU computation. Likewise, Pronghorn is a system with Intel Xeon Phi coprocessors available for evaluation of the applicability of Intel many-core coprocessors to Earth System science applications. Important subsets of post-processed simulation results can be shared with the scientific community via allocated storage on GLADE’s “projects” filesystem, either through direct access from the analysis servers or through the attached Data Transfer or Science Gateways. Data of long-term significance is stored on the HPSS data archive.
Finally, test systems have proven invaluable to CISL for refining administrative procedures and installing and testing new firmware and software before their introduction on production systems. The test systems for the Yellowstone environment are comprised of a 32-node iDataPlex computational cluster (Yellowstone test) with two GPU-computation nodes (Caldera test), one large-memory node (Geyser test), one Phi node (Pronghorn test), two GPFS NSD servers, a DCS3700 storage subsystem, and three Mellanox SX6036 FDR InfiniBand switches.
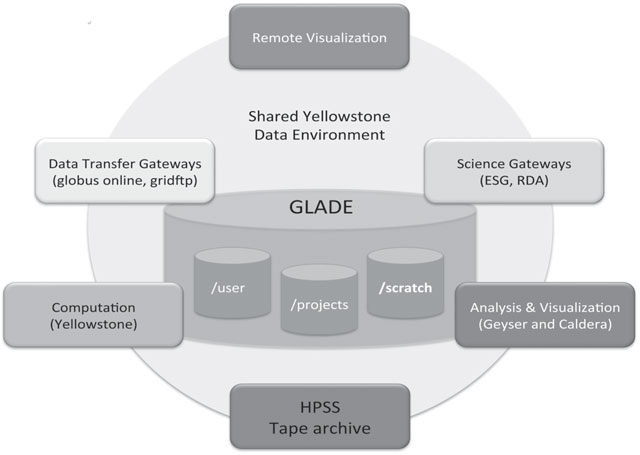
FIGURE 8.2: High-level architecture of NCAR’s data-centric environment.
The Yellowstone supercomputer consists of 4,536 dual-socket 1U IBM dx360 M4 diskless nodes with 2.6-GHz Intel Xeon E5-2670 8-core (Sandy Bridge EP) processors. Each node has 32 gigabytes of DDR3-1600 memory, or 2 gigabytes per core, for an aggregate memory size of 145.1 terabytes. Each node has a single-port Mellanox ConnectX-3 FDR adapter, and the nodes are interconnected via a full-bandwidth full fat tree network. Physically, Yellowstone’s computational nodes and level 1 switches are housed in 63 cabinets, with an additional 9 cabinets required for the 648-port Mellanox IB director (levels 2 and 3) switches. An administrative Ethernet and about two dozen other special-purpose nodes are used for user login and interactive access and operational and administrative system management. Finally, a smaller, standalone 28-teraflops system, Erebus, is dedicated to producing twice-daily, 10-km-resolution numerical weather predictions over the Antarctic continent to support Antarctic scientific operations.
The system architecture of the 16-node Caldera and Pronghorn systems is quite similar to Yellowstone’s, except that each node has 64 gigabytes of DDR3-1600 memory and dual PCIe-attached coprocessors. The nodes in each system are interconnected by a level-1 full fat tree IB network. Caldera is equipped with two NVIDIA Tesla M2070Q graphics processing units per node. Each Pronghorn node is equipped with dual Intel Xeon Phi 5110P coprocessors, each with 61 cores and 8 gigabytes of onboard memory.
Geyser is designed for big-data analysis, and is comprised of 16 IBM x3850 X5 nodes, each equipped with four, 10-core Intel Xeon E7–4870 (Westmere-EX) processors, one NVIDIA Quadro 6000 graphics processing unit, 1,024 gigabytes of DDR3-1066 memory, two single-port Mellanox ConnectX-3 FDR adapters, and a dual-port 10GigE Ethernet adapter.
The hardware component details for Yellowstone, Erebus, Caldera, Pronghorn, and Geyser are summarized in Table 8.1. Information on the Intel processors used in the complex can be found at [24, 25, 26]; background on IBM hardware at [19, 20, 21]; and information regarding NVIDIA’s accelerators at [38, 39].
The racks in the IBM iDataPlex have a unique shallow-rack design that effectively provides 100U of device-mounting space in the same floor space as a standard 42U rack [51, 18]. The shallow depth provides efficient airflow and reduces cooling costs. Each rack contains 72 compute nodes, 4 InfiniBand switches, 2 Ethernet switches, and two 60-Amp, 3-phase intelligent power distribution units. Designed for a maximum power load of 29.9 kW, each Yellowstone rack consumes 17.5 kW while running NCAR’s production workload. The racks are equipped with the optional Rear Door Heat eXchanger which, using the NWSC’s 18°C (65°F) chilled water at a flow rate of 8 gallons per minute, keep Yellowstone’s output temperature room neutral.
Yellowstone’s interconnect is a single-plane, three-tier full fat-tree topology comprised of Mellanox 56-Gbps FDR 4X InfiniBand components. This topology provides a maximum hop count of five between arbitrary nodes in the Yellowstone system and a theoretical bisection bandwidth of 30.9 terabytes/second.
The first tier of the system’s interconnect topology utilizes 252, 36-port Mellanox SX6036 leaf switches, also called “top-of-rack” or TOR switches, with one copper downlink to each of 18 associated compute nodes, and 18 fiber uplinks to the level two switches. Nodes that share a TOR switch are termed an “A-group”: there are four TOR switches (and therefore four A-groups) in a fully populated iDataPlex rack of 72 nodes, and a total of 252 A-groups in Yellowstone. The upper two tiers of the interconnect topology are housed in nine 648-port Mellanox SX6536 director switches, each of which can contain 36, 36-port SX6036 “leaf” modules, each with 18 downward-facing links. Of the 36 leaf modules available in each director switch, only 29 are populated to fill out Yellowstone’s Tier 2 interconnect. Processors that are interconnected at the Tier 2 level form an association that is termed a “B-group.” There are 18x18 or 324 nodes in a B-group and a total 14 B-groups in Yellowstone. In the Tier 3 layer, 18 “spine” switch modules in each director switch receive the Tier 2 uplinks and interconnect them in a crossbar.
TABLE 8.1: Key hardware attributes of the Yellowstone environment.

Each TOR switch has two fiber uplinks connecting it to two different leaf modules on each director switch. In a true fat tree, both links would go to the same leaf module on each director. This small difference technically makes Yellowstone, from a routing perspective, a “quasi” fat tree (QFT). The advantage of this QFT connection strategy is that larger B-groups, i.e., 18 TOR vs. 9 TOR in size, allow more nodes to communicate through Tier 1 and 2 switches and avoid spine traffic altogether. This improves the probability that smaller jobs will be supported by localized interconnect fabric, reducing the number of hops, and lowers application interference effects of crossing the Tier-3 spine.

FIGURE 8.3: Conceptual diagram of Yellowstone switch hierarchy showing the compute nodes at the top, the 252 Tier 1 TOR SX6036 IB switches, and the nine SX6536 director switches that form the Tier 2 and Tier 3 of the interconnect hierarchy.
Figure 8.3 shows a high-level diagram of Yellowstone’s switch hierarchy. NCAR is currently working with Mellanox on a new QFT routing algorithm that will deliver full fat tree performance for a Yellowstones QFT network. This is expected to be available in the second half of 2014.
Yellowstone’s interconnect is not a completely symmetric fat-tree topology. A 29th leaf module in each of the director switches contains a total of 21 direct FDR IB connections to Yellowstone’s login and administrative nodes and 24 connections to GLADE for I/O to the GPFS filesystems. This asymmetry complicates using the fat tree (ftree) routing algorithm in OpenSM. At the time of this writing, the ftree routing algorithm cannot be used, and Yellowstone’s OpenSM system is configured to use up-down scatter ports routing, with LMC=1 (two logical channels per physical link). Mellanox is currently developing new routing engine enhancements, referred to as routing engine chains, that will optimize routing and minimize collisions for asymmetric topologies such as Yellowstone’s.
GLADE contains a Mellanox SX6512 FDR InfiniBand switch with 24 FDR links providing I/O connectivity to Yellowstone’s SX6536 switches and ultimately to each of Yellowstone’s nodes. Geyser, Caldera, and Pronghorn share a 216-port Mellanox SX6512 FDR InfiniBand director switch. Each Caldera and Pronghorn node has one, and each Geyser node has two FDR InfiniBand links to the director switch. Six FDR links from the DAV SX6512 director switch to GLADE provide a theoretical aggregate bidirectional I/O bandwidth of 81 gigabytes/second [32, 33, 34]. As noted previously, Yellowstone’s integrated IB fabric allows data to be shared across all systems, which is increasingly important for supporting complex scientific workflows.
The GLADE storage cluster consists of 20 IBM x3650 M4 servers, each equipped with two 8-core Intel Xeon E5-2670 processors, a single-port Mellanox ConnectX-3 FDR adapter, either 32 gigabytes or 64 gigabytes of DDR3-1600 memory, and 76 IBM System Storage DCS3700 controller units each with a single EXP3700 expansion chassis. The DCS3700/EXP3700 is a modular, scalable disk storage controller and expansion chassis; each assembly can accommodate 60 NL-SAS drives in a 4U space. In GLADEs current configuration, four DCS3700 controllers, four EXP3700 expansion units, and an NSD server are mounted in each of a pair of neighboring 19-inch racks, while each DCS3700 controller and EXP3700 expansion chassis is twin tailed via 6 Gbps SAS to the pair of IBM x3650 M4 NSD servers and contains ninety 3-terabyte near-line SAS disk drives.
The GLADE storage cluster is designed to provide more than 90 gigabytes per second bandwidth over InfiniBand to the Yellowstone compute nodes. Figure 8.4 provides a schematic diagram of a GLADE building block. Nine storage building blocks are configured to support scratch space and dedicated project spaces. An additional half building block supports user directory spaces. Finally, GLADE provides access to additional services through a 10 Gbps IP-based network.
This section discusses important software components of the Yellowstone system, including the operating system, parallel filesystem, system monitoring software, and programming environment. Table 8.2 provides a more detailed summary of software components with current version numbers included. CISL keeps software levels consistent across the Yellowstone, Caldera, Geyser and Pronghorn clusters. Older and newer test compiler versions are made available to the user community via the Modules environment.

FIGURE 8.4: GLADE storage configuration.
8.5.1 Operating Systems and System Management
Yellowstone and GLADE use the Red Hat Enterprise Linux (RHEL) 6 Operating System. One variant, called RHEL Server OS, uses the traditional stateful model where the OS resides on a direct-attached hard drive and state is maintained across reboots. RHEL Server is used on all nodes of GLADE, Geyser, Caldera, and Pronghorn clusters, and on Yellowstone’s login and infrastructure nodes. Yellowstone’s compute nodes use a stateless operating system called RHEL for HPC that does not store the OS or its state locally. Rather, the operating system is loaded onto the node over the network when the system is booted, eliminating the OS’s need for direct-attached disks. The advantages of using a stateless OS are that it ensures consistency in the operating system content across thousands of compute nodes and centralizes all OS maintenance activities for them.
The RHEL Server OS instances are maintained through three stateful management nodes, and an NFS storage appliance provides centralized storage for administrative functions. The Yellowstone environment is managed using the Extreme Cloud Administration Toolkit or xCAT, an open-source cluster management and provisioning tool that also provides an interface for hardware control, discovery, and operating system deployment. Initial installation of a consistent stateful image on the non-management nodes is achieved by updating the image definition within xCAT. Configuration management software keeps the stateful nodes consistent after deployment. Logs from stateful nodes are sent to a central system log server rather than storing them locally.
TABLE 8.2: Yellowstone software matrix.
Software |
Current Installed Version |
Operating System |
RHEL 6.4 |
Parallel Filesystem |
IBM GPFS 3.5.0-13 |
Compiler and Tools |
Intel Cluster Studio 12.1.5.339 (Fortran, C, C++) |
PGI CDK Cluster Development Kit 13.3 (Fortran, C, C++) |
|
PGI Accelerator CDK 13.3 (OpenACC, CUDA Fortran, CUDA) |
|
PathScale EKOPath Compiler Suite 5.0.0 (Fortran, C, C++) |
|
Debugger |
TotalView 8.12.0-1 |
MPI |
IBM Parallel Environment 1.3.0.7 |
InfiniBand |
Mellanox OFED 2.0-3.0.0.3 |
Mellanox Unified Fabric Manager 4.6.0-13 |
|
OpenSM 4.0.5.MLNX20130808.c2b40b1-0.1 |
|
Job Scheduler/Resource Manager |
IBM Platform LSF 9.1.1.1 |
Cluster Management |
xCAT 2.8.4 |
TABLE 8.3: GLADE filesystem configurations.
Scratch |
Projects |
User |
5 PB total space |
9.9 PB total space, |
844 TB total space, |
4 MB block size |
4 MB block size |
512 KB block size |
10 TB quota per user, 90 day purge policy |
500 GB allocation per user Large project allocation by request 2 PB allocated to data collections, e.g., RDA, ESG, CDP |
10 GB allocation per user Small project allocation by request 10 TB home space Application software repository Snapshots, backups |
Yellowstone resources are scheduled and managed via the Load Sharing Facility (LSF), a commercial job scheduler and resource manager that provides a comprehensive set of intelligent, policy-driven scheduling features that enable the efficient use of the Yellowstone infrastructure resources.
8.5.2 Disk Filesystem and Tape Archive
The GLADE storage cluster uses IBM’s GPFS parallel filesystem configured into three filesystems supporting scratch, allocatable project spaces, and user directories. Table 8.3 provides a summary of GLADE filesystem attributes. The two largest filesystems in GLADE, scratch and projects, are configured with large, 4-megabyte blocks and span 9 storage building blocks, while the third, smaller user filesystem is configured with small 512-kilobyte blocks contained within a half-sized storage building block. Storage allocations are controlled using a mixture of user/group-based quotas and a unique feature of GPFS: filesets, or virtual containers.
NCAR’s HPC environment uses GPFS’s Multicluster feature to provide access to the GLADE file systems for clusters external to GLADE. This provides GPFS access to clusters outside the administrative domain, GPFS access to clusters over the 10-Gbps ethernet network, and stability for GLADE while other HPC clusters are offline for maintenance.
The HPSS tape archive consists of four Oracle SL8500 robotic tape libraries, two at the NWSC in Cheyenne, Wyoming, and two at NCAR’s Mesa Laboratory Computing Facility in Boulder, Colorado. These libraries have a total of over 34,000 tape cartridge slots. Using current tape technology, the total capacity of the archive is over 170 petabytes. The archives are federated with production core servers located at the NWSC and two data mover servers located at the MLCF. The long-range plan is to store nearly all of the data at the NWSC and use the MLCF for business continuity purposes. The system includes 50 T10000C tape drives, 95 T10000B tape drives, 500 terabytes of disk cache, and an aggregate I/O bandwidth greater than 6 Gbps.
The Yellowstone system is monitored by a variety of tools [8]. The Nagios monitoring framework provides infrastructure-level monitoring, event notification, and problem resolution guidance. Splunk is a commercial product for collecting and analyzing machine data. Splunk helps correlate system logs across multiple clusters to reveal patterns that point toward system issues. Ganglia is an effective distributed monitoring system for high-performance clusters. Its scalability and hierarchical design provide significant flexibility. Ganglia is used in the GLADE environment to both monitor the GPFS servers and track the performance and usage profiles of the GPFS filesystems. The gpfsmond daemon was developed locally to monitor GPFS state on all client nodes and help system administrators identify problem nodes before widespread problems occur. Every five minutes, this daemon gathers the current GPFS state then examines the state of GPFS mount points. If any are found not mounted or stale, it will attempt to remount them and reports this status.
NCAR’s HPC environment uses a tiered and scalable approach to system-level monitoring. Each cluster has its own Nagios instance that monitors its critical components. Events requiring action are fed to a central Nagios instance that is monitored 7x24. Nagios’ ability to attach procedural documentation to an event allows operations staff to take the proper corrective actions. The Ganglia system had to be scaled out to handle the volume of metric updates, as a single Ganglia server could easily be saturated by the volume of metric updates in a petascale system. For Yellowstone, Ganglia and Nagios client hosts were evenly distributed over six servers using the InfiniBand fabric.
The Yellowstone environment supports four compiler families (Intel, PGI, PathScale, and GNU), three primary languages (Fortran, C, and C++), and the Python language. The compilation and runtime environment is designed to manage the architectural differences between the Intel Xeon (Sandy Bridge and Westmere) and Xeon Phi processors. Programming of NVIDIA-based GPUs on Caldera is provided via the CUDA programming language and through OpenGL for traditional GPU-enhanced visualization applications.
The user environment is managed with the Lmod modules implementation [30], custom wrapper scripts, and settings exported into the user environment. This allows for streamlined control, automated documentation, version control, and customization, while accommodating both novice and expert users. All supported software libraries on the system are compiled with versions specific to the supported compilers. When a user loads a module, their environment is updated to use software built against the compiler currently in their environment. Furthermore, CISL automatically includes necessary Rpath information into the binaries via wrapper scripts for the compilers. This avoids users needing to locate the correct runtime library paths after they have compiled applications.
8.6 Workload and Application Performance
Yellowstone’s computing resources are partitioned among the following four distinct communities: modelers participating in the Climate Simulation Laboratory (CSL) (28%); researchers at U.S. universities and scientific institutions (29%); NCAR scientists (29%); and geosciences researchers at the University of Wyoming (13%). In addition, 1% is reserved for special purposes such as benchmarking and other testing.
Each of these communities has distinct needs and usage patterns. The CSL is dedicated to large-scale and long-running simulations of Earth’s climate system that produce large amounts of model data, often conducted by distributed teams of researchers. The university community allocation supports U.S.-based researchers who have NSF awards in the atmospheric or related sciences, as well as graduate student and postdoctoral research projects. These projects range from small- to large-scale and from paleoclimate to ocean modeling to weather prediction to solar physics. University users include a larger proportion of new users, as well as users of community models. NCAR staff researchers have similarly wide-ranging areas of scientific interest. While smaller in size, the NCAR community has a larger proportion of expert users and application developers. Finally, the Wyoming community encompasses a broader set of disciplines in the geosciences, notably including solid Earth physics, but this group is concentrated in a smaller number of users. Collectively, these communities represent a much tighter disciplinary focus than is typical on other petascale systems (see Figure 8.5).

FIGURE 8.5: Chart of current Yellowstone resource usage by discipline, illustrating the dominance of climate, atmosphere, and ocean science.
8.6.1 Application Domain Descriptions
Climate Science
Climate-related simulations represent nearly half the workload on Yellowstone. Climate models are typically run from decadal to millennial scales, and they require 64-bit precision computations for accuracy. The primary climate model used at NCAR is the Community Earth System Model (CESM), a fully coupled, community-developed, global climate model [31]. CESM couples components of the Earth System including the atmosphere, atmospheric chemistry, land surface, sea ice, land ice (glaciers), and the oceans - each of which may use different grids - by exchanging regridded fluxes and material quantities through the flux coupler application. CESM has scaled to tens of thousands of processors on a variety of platforms [12].
CESM is integrated with an ecosystem of related modeling and prediction efforts. CESM can be run in data assimilation mode using NCAR’s Data Assimilation Research Testbed (DART) to study climate predictability. The Nested Regional Climate Model (NRCM) combines CESM with the Weather Research and Forecasting (WRF) model that runs embedded on a high-resolution mesh over an area of interest to better simulate regional climate variability and change. The Whole Atmosphere Community Climate Model (WACCM) is also part of the family of CESM models. WACCM spans the lower, middle, and upper atmosphere to enable investigations of atmospheric chemistry including the effects and contributions of solar variability and the solar cycle. Finally, an emerging model that bridges climate, regional climate, and weather studies is the Model for Prediction Across Scales (MPAS), a joint effort of NCAR and Los Alamos National Laboratory [42]. MPAS is well suited for global mesoscale atmosphere and ocean simulations.
Weather Prediction and Atmospheric Chemistry
Studies in the closely related areas of numerical weather prediction, atmospheric chemistry, and mesoscale meteorology together comprise the second-largest area of activity on Yellowstone. The WRF model [35] is an open-source, collaboratively developed, numerical weather forecasting model used in operational, research, and educational settings. WRF has a large user base in the environmental sciences. It features two dynamical solvers: the Advanced Research WRF (ARW) model, developed by NCAR’s Mesoscale and Microscale Meteorology Division [41], and the Nonhydrostatic Mesoscale Model (NMM) solver developed by the National Centers for Environmental Prediction (NCEP). WRF has a three-dimensional variational (3DVAR) data assimilation system, and its WRF-Chem variant couples it with processes that govern the behavior of atmospheric trace gases and aerosols. WRF-Chem is used to study regional-scale air quality and cloud-scale interactions.
Ocean Sciences
A representative application from computational oceanography is the Parallel Ocean Program (POP), a flexible and widely used ocean general circulation model developed at Los Alamos National Laboratory [44]. POP solves the 3-D primitive equations for ocean dynamics under the hydrostatic and Boussinesq approximations. Spatial derivatives are computed using finitedifference discretizations that are formulated for generalized orthogonal coordinates. Time integration of the model is split into two parts. The three-dimensional vertically varying (baroclinic) tendencies are integrated explicitly using a leapfrog scheme. The fast modes of the vertically uniform (barotropic) component are integrated implicitly using a two-dimensional preconditioned conjugate gradient (PCG) solver. While the baroclinic component scales well, at high processor counts, POP is dominated by the MPI reduction operations associated with this PCG solve. The Mellanox Fabric Collective Accelerator feature can offload these MPI collective communications and significantly improve POP’s scalability on Yellowstone.
Geospace Sciences
The Sun-Earth System is studied at NCAR with a set of loosely coupled models that operate at vastly different length-scales and physical conditions. Magnetohydrodynamics (MHD) applications, such as the MPS/University of Chicago Radiative MHD (MURaM), are used for realistic simulations of solar magneto-convection and related activity in the photosphere [50]. Other aspects of solar interactions are examined via computational fluid dynamics methods, such as those embodied in ZEUS-3D [9]. The Thermosphere Ionosphere Electrodynamics General Circulation Model (TIE-GCM) is a first-principles model of the coupled thermosphere and ionosphere system [46], and the related Thermosphere Ionosphere Mesosphere Electrodynamics GCM (TIME-GCM) extends the simulation boundary down to an altitude of 30 km to include processes in the mesosphere and upper stratosphere.
Fluid Dynamics and Turbulence
Turbulence plays an important role in a variety of geophysical flows, and the large-eddy simulation (LES) and direct numerical simulation (DNS) approaches to modeling turbulence appear frequently on Yellowstone. NCAR’s LES model, for example, is used to study mixing in a wide variety of physical contexts, including ocean layers, land-surface interactions with the planetary boundary layer, and in cloud physics. LES uses as its basic numerical algorithm a mixed pseudo-spectral finite difference code with third-order Runge-Kutta time stepping [36]. LES scales well to tens of thousands of cores using a hybrid MPI-OpenMP scheme in which work in the vertical (finite difference) direction is partitioned across MPI processes, and the horizontal (pseudo-spectral) dimension is distributed across OpenMP threads.
Earth Sciences
Early research by University of Wyoming researchers has focused on seismology. For instance, the Anelastic Wave Propagation - Olsen, Day, Cui (AWP-ODC) model is a portable, highly scalable application that simulates the dynamic ruptures and wave propagation through the Earth’s crust during an earthquake using a staggered-grid finite difference scheme [3]. The widely used SPECFEM3D code [45], which uses a continuous Galerkin spectral-element method, was used to study earthquake wave propagation through sedimentary basins.
Data Assimilation Systems
Yellowstone allowed NCAR user communities to expand their models in two dimensions: (a) running at higher resolutions and (b) increasing ensemble size to improve statistics or apply ensemble-based data assimilation methods to achieve better forecasts. NCAR’s DART is a framework that provides ensemble-based data assimilation capabilities to geophysical models through a set of specified interfaces. DART works with a growing number of models, including WRF and CESM’s atmospheric component CAM, combining them with a diverse and growing set of observation types [2]. Other models running on Yellowstone also have data assimilation capabilities. For example, WRFDA provides variational data assimilation capabilities for the WRF model [52]. Another example is the FWSDA model, described below, for studying earthquake hazards and mitigation.
This section describes the performance of CESM and WRF benchmarks, which represent the largest components of Yellowstone’s application workload.
High-Resolution CESM on Yellowstone
The simulation rate and scaling efficiency of high-resolution CESM are shown in Figure 8.6, which was generated by version 1.1.0 rel4 of CESM configured with the 0.25°-resolution CAM-SE (atmosphere) and CLM3.5 (land surface) models and the 0.1°-resolution POP (ocean) and CICE (sea ice) models. The timings measured the cost to perform a five-day simulation of this configuration and excluded any initialization or I/O time.
Shown in the top panel of Figure 8.6 is the simulation rate in years per wall-clock day (SYPD) as a function of processor count. Depending on the particular science question, climate simulations can range in length from decades to several hundred years. As can be seen below, Yellowstone attained a simulation rate of 1.16 SYPD on 11,274 cores, while 1.95 SYPD were achieved on 23,404 cores. A minimum simulation rate of 1 SYPD is generally considered necessary to perform a climate experiment within a reasonable time.
The bottom panel of Figure 8.6 is the cost in thousands of CPU-hours per simulated year (KCPU/yr) as a function of core count. Considering only those configurations that achieve at least 1 SYPD, the minimum cost of 229 KCPU/yr is achieved at 14,276 cores with an integration rate of 1.49 SYPD, while the 23,404-core configuration costs 290 KCPU/yr integrating at 1.95 SYPD. The scalability of CESM on Yellowstone is illustrated by this performance measurement: the configuration with the greatest simulation rate, 23,404 cores, was only 26% more expensive than the 11,274-core configuration.
WRF Scaling
The scaling and performance of the WRF Version 3.5 meteorological model was studied on Yellowstone in both MPI-only and MPI-OpenMP hybrid modes. The benchmark simulated weather events leading up to hurricane Katrina and ran for one hour or 1,200 time steps. The 1 km North American problem domain included the Gulf of Mexico, and contained 3,665 x 2,894 grid points and 35 terrain-following vertical levels. No initialization or disk I/O times were measured in this benchmark.
On Yellowstone, hybrid runs gave some marginal performance benefits vs. MPI-only. In most cases, however, run-to-run variability increased substantially compared to MPI-only runs. The benchmark measures the simulation speed, defined as the ratio between simulated and wall clock time. Only speeds significantly greater than 10 are considered useful for forecasting purposes. The results in Figure 8.7 show that WRF scaled well on Yellowstone for this problem up to about 20,000 cores, achieving an integration rate nearly 50 times wall clock at 65,536 cores. See [28, 10, 53] for further details.

FIGURE 8.6: These charts show (a) the simulation rate and (b) the CPU-hours cost as a function of core count for high-resolution CESM on Yellowstone.
When Yellowstone entered production in December 2012, more than 1,800 user accounts and 424 projects had already been established. These included active users migrated from NCAR’s previous system, Bluefire, as well as projects reviewed and allocated prior to Yellowstone’s arrival. By July 2013, the user community had grown by a third, to more than 2,400 users and 651 projects.
The system’s normal production workload includes a spectrum of job sizes. As can be seen in Figure 8.8, a small but demanding set of capability-oriented projects consumed more than 70% of Yellowstone’s delivered core-hours for high-resolution climate and weather models, while 80% of projects on Yellowstone completed their science objectives with smaller-scale jobs using fewer than 2,048 cores. This pattern is expected to persist throughout the system’s lifetime [16].
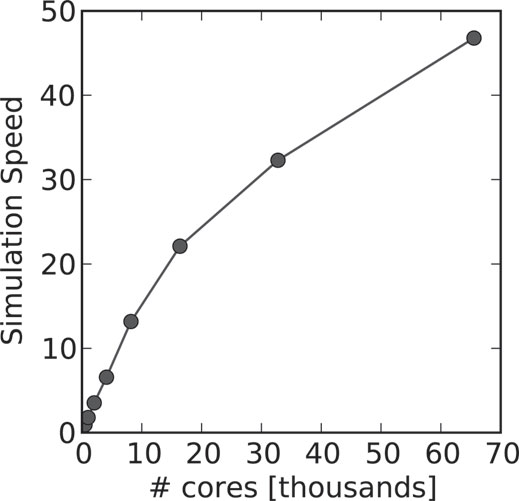
FIGURE 8.7: Strong scaling of WRF for the 1 km Katrina problem from 512 to 65,536 cores on Yellowstone.
The data-intensive components of the Yellowstone environment have also been instrumented to better understand their usage patterns [17]. This data includes job accounting statistics for the Geyser and Caldera analysis clusters and weekly storage accounting data for the GLADE central file systems and the HPSS tape archive. While trailing HPC use, HPSS growth seems to have stabilized at 200-300 terabytes per week (Figure 8.9). Prior to the Yellowstone procurement, CISL estimated an archive growth rate of approximately 450 terabytes per week.
The growth in disk storage usage is also being tracked (Figure 8.10). Ignoring transients that occurred before March 2013, GLADE storage use across all filesystems has been growing steadily at a rate of 350 terabytes per month, and it surpassed 5 petabytes total by November 2013. Roughly half of this growth is in the /project filesystem, which serves as longer-term storage of high-value datasets to increase science impact. If this trend continues, the GLADE system could be full by the middle of 2016, even with the planned capacity increases. In response, modifications to future storage allocation and retention policies may be required.

FIGURE 8.8: Distribution of projects and Yellowstone usage, according to project’s largest jobs.
8.7.2 Reliability, Uptime, and Utilization
From a contractual standpoint, the key reliability metrics for the systems in the Yellowstone environment are availability and mean time between system failure (MTBSF). The target thresholds were 99% and 24 days for GLADE; and 98% and 16 days for Yellowstone, Caldera, and Geyser.
During the early months of production, NCAR, IBM, and Mellanox collaborated closely to identify and resolve key reliability issues that often accompany the deployment of petascale systems. Perhaps the most challenging were those surrounding Yellowstone’s FDR InfiniBand fabric, including fabric instability and routing engine reconfiguration and refinement, which affected early-user job success rates and application performance reproducibility. The end-user impact was mitigated by extensive efforts by Mellanox and IBM to optimize the OpenSM configuration. Fabric reliability issues were found to be the result of an early manufacturing problem with the FDR optical cables that caused some links to run at sub-FDR speeds and to experience higher-than-expected cable failure rates. To address these issues, a complete replacement of Yellowstone’s optical cables was performed between September 30 and October 9, 2013.
Other system reliability issues included: refinement of the routing engine configuration; management of application-induced out-of-memory conditions; and scaling and start-up issues with the IBM Parallel Environment runtime system and its interaction with the LSF workload management system. Despite these issues, by spring 2013, Yellowstone was maintaining an availability in excess of 99% with daily-average user utilization generally over 90%.

FIGURE 8.9: Weekly growth of CISL’s HPSS archive. The downward trend in March and April was caused by a major data deletion effort unrelated to Yellowstone use.
As with past NCAR systems, early access to Yellowstone was provided to large-scale Accelerated Scientific Discovery (ASD) projects selected from the university and NCAR communities based on their potential to produce scientific breakthroughs. These 11 projects exhibited a diversity of scientific problems, algorithms, and computational scales that also served to stress-test the Yellowstone system, as would be typical in a “friendly user” period. This section describes some of these projects with their preliminary scientific findings and their computational experiences.
Regional-Scale Prediction of Future Climate and Air Quality
As modern society becomes increasingly complex, it becomes increasingly vulnerable to changes in air quality, weather, and climate. These changes emphasize the need for reliable projections of future climate and air quality on regional to local scales. Reliable projections require the use of regional models with a horizontal resolution consistent with the scale of the processes of interest. They also require simulations spanning multiple years to quantify the interannual variability and provide statistically significant projections. Simulations of this type are thus an enormous challenge to supercomputing systems.
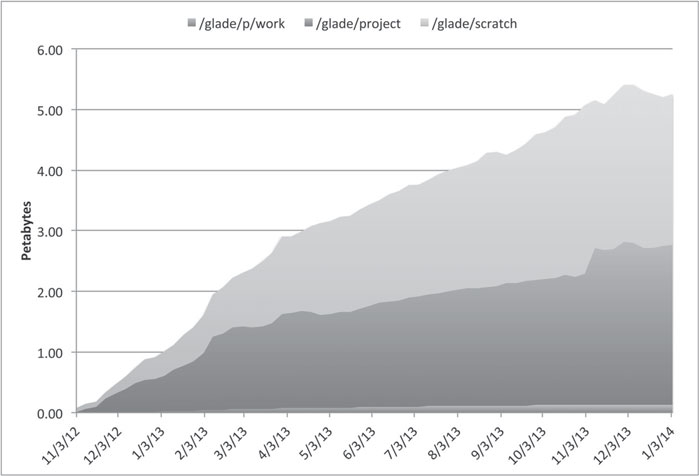
FIGURE 8.10: Growth in GLADE file systems usage since the start of Yellowstone. Data shown is cumulative across filesystems.
With support of NCAR’s Accelerated Scientific Discovery program, a set of high-resolution (12-km) simulations was run using the fully coupled nested regional climate model with chemistry (NRCM-Chem) to predict changes in air quality and climate over the U.S. between present time and the 2050s. NRCM-Chem is based on the regional WRF Model with Chemistry (WRFChem) version 3.3, which is a fully coupled chemical transport model [15], and has been updated to include all climate-relevant processes and feedbacks. The simulations follow the IPCC A2 climate and RCP8.5 precursor emission scenario with about 8 W/m2 radiative forcing by 2100, but large reductions in short-lived pollutant emissions in the developed world.
As shown in Figure 8.11, these simulations provide in-depth analysis of future air quality and chemistry-climate feedbacks. They supplement the global simulations performed in recent assessments of future climate and composition and, in particular, quantify the ability of global models at moderate horizontal resolution to capture regional air quality characteristics. In addition, these high-resolution simulations are used to identify how specific local meteorological flows, e.g., in the vicinity of topography, affect local to regional chemistry. They will also contrast the chemical importance of specific events such as heat waves in present and future climate conditions. To assess the impacts of changes in emissions versus changes in climate on air quality, sensitivity simulations for the 2050s were run where anthropogenic emissions were held at present-time levels. Future simulations without chemistry are used to quantify changes in weather patterns and climate associated with atmospheric composition.

FIGURE 8.11: Average daily maximum surface ozone during summertime over the U.S. for present day (a), a future climate and pollutant emission scenario (b), and a future climate scenario with emissions kept at present-day levels (c). Difference plots are shown in (d)-(f). Results indicate that a warming climate will aggravate ozone pollution over the United States in the middle of the century (see panels a, c, and f). However, if emissions of pollutants continue to decline, U.S. ozone levels should improve even as temperatures rise (panels a, b, and d).
A High-Resolution Coupled Climate Experiment
The current generation of coupled general circulation models (CGCMs) is designed to perform century and multi-century simulations, including ensembles that span the uncertainty associated with natural variability or parameter sensitivity. With previous computing capabilities, models have been limited to grid spacings of around 1°(∼ 100 km). These models adequately resolve large-scale modes of climate variability (such as the El-Ni˜no Southern Oscillation), but do not capture smaller-scale features that have important local impacts and may feed back to the large-scale climate. For example, it would be useful to know how the statistics of tropical cyclones and polar lows change over time in response to changes in the large-scale climate state.

FIGURE 8.12: Snapshot showing latent heat flux overlaid on sea surface temperature from year 14 of the high resolution CESM run. Note the influence of Gulf Stream meanders on a cold-air outbreak in the Northwest Atlantic (upper left) and a cold temperature wake beneath a tropical cyclone in the Indian Ocean (lower right). Previously, neither feature has been well simulated by lower-resolution climate models.
The deployment of Yellowstone presented an opportunity to perform a multi-decadal run of a much higher-resolution CGCM. As shown in Figure 8.12, such a simulation can be used to study climate interactions at all scales down to oceanic and atmospheric mesoscale (i.e., tens of kilometers). It can also potentially act as a benchmark for comparing various high-resolution regional modeling approaches. In this ASD experiment, the CESM was used for a century-long climate simulation under present-day (year 2000) greenhouse gas conditions. The experiment coupled a 25-km-resolution land surface and atmosphere based on the Community Atmosphere Model (CAM5), and 10-km-resolution sea ice and ocean models based on the Parallel Ocean Program (POP2) - perhaps the longest run with CAM5-enabled CESM at this resolution of ocean and atmosphere - allowing analysis of variability on seasonal to decadal timescales.
The experiment was more computationally intensive than many previous high-resolution simulations, largely because of the additional computational cost of adding prognostic aerosol equations in the CAM5 model. Use of the highly scalable spectral element atmospheric dynamical core within CAM5 allowed for faster throughput than was possible with previous dynamical cores [11]. The experiment ran on 23,404 cores of Yellowstone and the first 60 simulated years consumed 25 million CPU-hours over three months. The core count was chosen to maximize the model throughput while also keeping the computational cost reasonable. A throughput of 2.0 SYPD was obtained by carefully load-balancing between the model components, some of which can run concurrently. The I/O for this run was substantial, adding an approximately 6.5% overhead to the run, and generating approximately one terabyte of data per wall-clock day. The simulation output is now being examined by climate scientists specializing in atmospheric, oceanic, and sea-ice processes. Results from a preliminary analysis show that the high-resolution simulation captures more cases where the ocean drives atmospheric variability than previous low-resolution runs. Amongst the scientific results, there is a better spectrum of El-Ni˜no variability in the high-resolution model, compared to a complementary run at lower resolution [43]. To assist collaborative analysis, these data are made available to the community via NCAR’s Earth System Grid portal [14].
Resolving Mesoscale Features in Coupled Climate Simulations
On Yellowstone, an international project led by the Center for Ocean-Land-Atmosphere Studies has been exploring the effect of explicitly resolving mesoscale features in the atmosphere on coupled climate predictions for lead-times of a few days to several seasons. Coupling allows testing of the hypothesis that the insensitivity of certain climate features to changes in resolution seen in Project Athena [23] - such as intraseasonal variability in the tropical Indian and Pacific Ocean sectors - is due to the absence of an air-sea feedback. Similarly, increasing atmospheric model resolution in the coupled prediction system can improve forecast accuracy and reliability of known deficiencies in the operational forecasts. As an example, the simulation and prediction of the Madden-Julian Oscillation remains a challenge in operational coupled prediction systems (e.g., Kim et al. 2014) which may be due in part to insufficient horizontal and vertical resolution in the atmosphere [22]. Additionally, the high data storage capacity of Yellowstone’s central file system, GLADE, has allowed researchers to retain a far more extensive suite of variables. This capability has already paid important dividends scientifically, as retaining hourly rainfall rates for the highest-resolution simulations (16 km) has allowed investigation of the detailed structure of tropical cyclones, demonstrating the clear presence of an eye, a fact that was not apparent in earlier work.
Full Wave Seismic Data Assimilation
Earthquake hazard analysis and mitigation depends on seismology to quantify ground motion and failure due to earthquakes. Scientists have developed and tested a new physics-based seismic wave propagation model, known as full-wave seismic data assimilation (FWSDA), that assimilates increasingly high-quality broadband seismic waveform observations [7]. The study performed on Yellowstone is part of a collaborative project between the University of Wyoming and the Southern California Earthquake Center (SCEC) with the goal of refining the seismic velocity and attenuation structure of the San Andreas Fault Near Parkfield, California. It was carried out at several supercomputer centers in the U.S., including the NWSC.
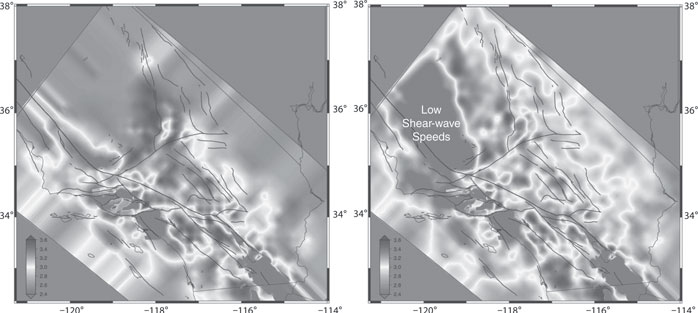
FIGURE 8.13: Shearwave speeds at 2 miles below the surface using conventional seismology (left) and FWSDA (right), showing new areas of vulnerability farther from the fault, on the left side of the simulated domain.
The project demonstrated the ability of the new model to make significantly more reliable predictions of ground shaking, especially in regions with complex 3D geological structures. For example, the shear-wave speed of the subsurface is highly correlated with shaking: regions with lower shear-wave speed often experience stronger shaking during a large earthquake. The plots in Figure 8.13 indicate the predicted shear-wave speed at 2 miles below the surface near Parkfield in Southern California. Here, the light and dark areas indicate the distribution of high and low shear-wave speeds. The plot on the left shows predicted shear-wave speeds using conventional seismology techniques that are only accurate near the faults. The plot on the right uses the new model that assimilates numerous waveform observations and more accurately predicts shear-wave speeds farther away from the faults. The model and its outputs are now being used to more precisely constrain the plate-tectonic processes of lithospheric creation, deformation, magmatism, and destruction to improve imaging of seismic sources.
The FWSDA model used a tetrahedral mesh with 1.4 million elements that conforms to the irregular surface topography in the Parkfield area. The mesh was refined in regions around the San Andreas Fault zone and in regions close to the surface where the seismic velocity is low and the wavelength is short. A 5,000-time-step simulation costs approximately 45 minutes on 2,400 cores of Yellowstone. Data from 600 earthquakes in the Parkfield area was assimilated and required 2,400 simulations per iteration, costing approximately 4 million core-hours per iteration. A total of 3 iterations were run in the first year, requiring approximately 12 million core-hours on Yellowstone. The experiment’s storage requirement is proportional to the total number of tetrahedral elements, the number of time steps, and the number of earthquakes. For this experiment, the space-time storage for a single earthquake required 2.6 terabytes of disk space. Volume renderings of the 3D Earth structure model were generated using the NWSC’s data analysis and visualization clusters equipped with the open-source software Paraview and the Visualization Toolkit by Kit-ware Inc.
Toward Global Cloud-Resolving Models
The Model for Prediction Across Scales (MPAS), collaboratively developed by NCAR and Los Alamos National Laboratory, is designed to perform global cloud-resolving atmosphere simulations. It is comprised of geophysical fluidflow solvers for the atmosphere and ocean that use unstructured spherical centroidal Voronoi meshes to tile the globe. The meshes, nominally hexagons, allow for both quasi-uniform tiling of the sphere in an icosahedral-mesh configuration, or a variable-resolution tiling where the change in resolution is gradual and in which there are no hanging nodes. This contrasts with traditional nested grid or adaptive mesh refinement (AMR) techniques that use cell division for refinement.
Three weather events were studied using global MPAS simulations: (a) a very intense extratropical cyclone (see Figure 8.14) and an associated series of isolated tornadic storms that occurred over North America during the period of 23-30 October, 2010; (b) the period of 27 August through 2 September, 2010, during which several hurricanes occurred in the Atlantic Basin; and (c) a very strong Madden-Julian Oscillation (MJO) event observed in the Indian Ocean and maritime continent region during 15 January through 4 February, 2009.
Simulations of each event were performed on meshes with 3, 7.5, 15, and 30 km cell spacing. The most ambitious component of these experiments is the 3 km simulations where convection is explicitly resolved to produce fine-scale convective structures similar to those observed in nature. Specifically, isolated severe convective cells were produced in the warm sector ahead of the strong cold front in the October 2010 simulation; the observed hurricanes (Daniel, Earl, and Fiona) were well simulated in the August case; and a strong MJO was produced in the longer (20-day) simulation of the 2009 MJO. Observed mountain-wave activity was also reproduced. The fine-scale convective structures were resolved at a level commensurate with state-of-theart cloud models using similar mesh resolution. The MJO simulation provides further evidence that convective-scale dynamics play an important role in MJO dynamics: the coarser mesh simulations using parameterized convection produced much poorer representations of the MJO. Further analysis is underway to understand the connection between the convective systems and the larger-scale MJO signal.
On Yellowstone, the 3 km simulations were typically performed on either 16K or 32K cores with an integration rate of somewhat greater than 2 and 4 simulated days per wall clock day, respectively. This mesh is composed of about 2.7 billion cells, and 144,000 time steps were required for the 20-day simulation of the MJO event. These high-resolution variable mesh simulations, along with the lower-resolution uniform-mesh results, will be used to evaluate the suitability of the variable-resolution meshes for future weather prediction and climate applications.

FIGURE 8.14: The panels show 6-hour precipitation totals for Tropical Cyclone Richard (25 October, 2010) for four experiments with MPAS that test the effects of resolution and physics parameterization choices. In variable-resolution grids, a challenge is to design convective schemes that turn off in refined regions where their assumptions become poor. In this case it seems that the Kain-Fritsch (KF) convective scheme is not too dependent on grid size between 7.5 and 15 km, which is promising. At 3 km resolution, no convective parameterization is needed because the dynamics resolve the deep convection.
The Magnetic Field of the Quiet Sun
While sunspots are the most prominent manifestation of solar magnetism, they cover only a small fraction of the solar surface: the remainder is not free from magnetic field, but it is organized on very small scales below the resolving power of current solar telescopes. These regions of the solar surface are referred to as the “Quiet Sun,” and their properties are mostly independent of the solar cycle, in contrast to the “Active Sun” that shows a strong modulation of area occupied by sunspots throughout the 11-year solar cycle. A series of high-resolution numerical simulations of the solar photosphere has been run on Yellowstone to study the origin and properties of the Quiet Sun’s magnetic field (see Figure 8.15). In these simulations, a mixed-polarity magnetic field is maintained through a small-scale dynamo process that involves magnetic field amplification in chaotic flows. Using large eddy simulations of radiative magnetohydrodynamics, these models for the first time reached an overall magnetization of the photosphere that is consistent with the level inferred from observations. The downward extrapolation of these photospheric models into the solar convection zone implies that even during phases of low solar activity, the magnetic field is close to having an equipartition of kinetic and magnetic energy throughout most of the solar convection zone.

FIGURE 8.15: Results from a 4 km simulation of the Quiet Sun, with a domain size of 6,144 x 6,144 x 3,072 km. Left: Emergent intensity showing the solar granulation pattern. Right: Vertical magnetic field at the visible surface of the sun (optical depth of unity). Magnetic field is organized in mostly sheet-like features and even in the Quiet Sun can reach a field strength exceeding 2,000 G. These regions typically show a brightness enhancement.
The Yellowstone supercomputer is located in the NCAR Wyoming Supercomputing Center (NWSC), five miles west of Cheyenne, Wyoming. Three key goals drove the NWSC’s design: flexibility, sustainability, and energy efficiency. Flexibility is important because the future directions of IT heat loads and system design are difficult to predict. Sustainability and energy efficiency not only make sense financially, but also align with the environmental mission of the research center. The success of this design approach can be measured in part by the outside recognition of the NWSC. The facility has been certified at a Leadership in Energy Efficiency and Design (LEED) Gold level, which is difficult for a computing facility to achieve. The NWSC’s “green” design won the Uptime Institute’s Green Enterprise IT first-place award for Facility Design Implementation [48], Best Project award in the Green Project Category from Engineering News Record [37], and received the top award in the “Green” Data Center category from Data Center Dynamics [4].

FIGURE 8.16: The NCAR-Wyoming Supercomputing Center (NWSC), located in Cheyenne, Wyoming, houses supercomputers and equipment dedicated to research in atmospheric and related science. The facility opened its doors in October 2012, and has garnered numerous awards for its sustainable design and energy efficiency.
The NSF required a facility design for NWSC with a minimum useful life of 20 years. So a modular and flexible design strategy was adopted to minimize risk. A site was selected with sufficient room to accommodate potential expansion over the facility’s lifetime. The initial building shell was made large enough to accommodate a conservative 10-year system power growth projection, the longest that could be made with any confidence. The initial electrical and mechanical components were provisioned for only a 5-year time horizon.
The flexibility of the NWSC was enhanced by several important design details. Conduits and equipment pads were installed to accommodate future equipment expansions and avoid expensive alterations. Pathways between loading docks and the machine room were designed to eliminate installation bottlenecks. The 10-foot raised floor in NWSC’s dual computer rooms simplifies the installation and maintenance of liquid cooling systems and electrical components without disrupting production systems.
The NWSC was constructed with a holistic approach to sustainability: materials selection, construction practices, and water conservation all played key roles. The project made extensive use of regionally sourced concrete and precast panel systems. More than 510 tons of recycled concrete, 60 tons of recycled wood, and 26 tons of recycled metals were used in the facility’s construction. More than 70% of all construction waste was recycled. Construction techniques such as continuous insulation on steel and precast concrete panel systems ensured a tight building envelope, and along with rigorous testing [49], reduced the amount of energy required for heating, cooling, and humidification.
Further, the building design reduced power needed for lighting by optimizing all relevant factors: building placement, ratio of windows to insulated walls, atrium space, skylights, exterior solar shades, and daylight-responsive electric lighting controls.
Water conservation and run-off management are critical elements of sustainability in Wyoming’s arid environment. The facility’s cooling towers employ a zero liquid discharge approach that reduces water use by 40% [13]. Plantings around the facility are primarily native grasses and xeric plants that eliminate the need for irrigation. And the facility makes extensive use of bioswales [29], shallow, sloping landscape features that safely transport water during rainstorms or snow melts. These effective features blend in with the rolling prairie that surrounds the facility.
The facility design team systematically evaluated the efficiency and cost of mechanical cooling systems, water and air delivery methods, and electrical distribution strategies. It was clear that future HPC systems would employ various forms of liquid cooling, so indirect evaporative cooling was a particularly efficient, flexible, and cost-effective choice as Wyoming’s cool, dry climate supports the use of evaporative cooling techniques for most of the year. Evaporative cooling was key to the NWSC achieving a projected Power Use Efficiency (PUE) [4] as low as 1.1, while staying within recommended ASHRAE TC9.9 [1] conditions.
Eliminating flow restrictions in the system and reducing pressure drops was another important efficiency strategy. Fan-wall technology and ductless, air-based cooling provide large air flow volume with very low pressure drops. Oversized piping and using 45°pipe bends achieved efficiency gains in the chilled water system. Variable frequency drive (VFD) fans and pumps, used throughout, provided two significant benefits. First, when coupled with the building automation system, VFD cooling components can dynamically meet the variable demands of modern computing systems. Second, the power consumed by fans and pumps has a cubic relationship to velocity: there is a distinct power advantage to operating at low speeds.
Energy losses in the facility’s electrical distribution systems were reduced by using high-efficiency oil-immersed transformers and by stepping the voltage directly down from the 24,900-volt utility supply to the 480 volts required at the rack level. The uninterruptible power supply at the NWSC was sized to protect only the systems sensitive to power interruptions, such as disks.
Finally, the efficiency of the facility design was modeled and validated at a 4 MW building load using eQuest DOE version 2.2 software, then compared to a traditional facility design. This modeling effort showed that the facility design would consume 29.8% less energy and cost 28.9% less to operate than a conventionally designed data center.
8.9.2 Early Experience in Operation
Yellowstone is the first HPC system installed at NWSC, and its selection occurred as the computing facility was nearing completion. This allowed CISL to manage the system fit-up costs while completing the building. As Yellowstone came online, operations staff tuned the efficiency of the facility. The PUE has trended below 1.2 during this tuning process, and appears to be approaching ∼ 1.1. Given that the NWSC was designed for a worst-case initial load as high as 4 MW, and that Yellowstone normally operates at or below 1.2 MW, achieving a low PUE is a significant achievement. Additionally, the facility responds directly to both changes in outside conditions and considerable changes in IT load. Yellowstone incorporates a number of energy-saving features that can impact PUE: during idle times, Yellowstone’s power consumption can drop to 300 KW.
The construction and provisioning of NWSC offered a unique opportunity to provide research and education opportunities for electrical and mechanical engineering students through CISL’s Summer Internships in Parallel Computational Science (SIParCS) program. While the facility was under construction, one student created an energy model of the facility, while another evaluated vendors’ proposals using a computational fluid dynamics (CFD) model of the computer room floor. The next summer two SIParCS interns compared the results of the energy model to actual facility data and verified the CFD model with measurements. During summer 2013, a graduate student provided both engineering and statistical analyses of facility performance using a full year of operational data.
As scientists strive to model and understand the physical, chemical, biological, and human components that govern the climate system in ever-greater detail across a range of timescales, the HPC community must continue to provide increasingly powerful cyber-resources tailored to these objectives. Contained within the Yellowstone experience are some clues to the future challenges facing the HPC community. The sheer number of components in modern large-scale supercomputers requires a relentless focus on scalability and fault-tolerance at the application, system software, and hardware levels.
Rising power requirements and utility costs tax the ability to deploy systems at the necessary scale and put an increasing premium on energy efficiency in all areas. HPC architecture changes, including many-core systems and new classes of memory and storage, provide both opportunities and challenges, requiring innovation in both system and application design.
Future systems may be so complex and costly that scientists may need to modify how they approach basic issues such as calculation correctness and reproducibility. New metrics of system performance that capture the growing importance of bandwidth and energy consumption relative to flops will be critical in advancing system designs. Regardless, the scientific adventure in numerical atmospheric science that began with ENIAC and continued through the CDC6600, the Cray 1A, and down to Yellowstone today, is in some ways, only just beginning.
8.11 Acknowledgments and Contributions
No decade-long project like this can be accomplished without the contribution of too many people and organizations to list conveniently. However, we especially want to acknowledge all the NSF, NCAR, and State and University of Wyoming people, past and present, who were tireless in their commitment to making the dream of NWSC and Yellowstone a reality. We include those who went on to operate it and push it toward its design goals, and also those at other organizations who provided their enthusiasm, oversight, critiques, and advice throughout the project’s duration. Further, the authors want to acknowledge the hard work of our private sector colleagues for their contributions to making the project a success, and the many authors and contributors who, either through writing or editing, helped shape this chapter. Some of the work presented here was performed under National Science Foundation award numbers M0856145, ATM-0830068, AGS-1134932, EAR-0944206, and ACI-0941735.
[1] American Society of Heating, Refrigeration and Air-Conditioning Engineers, Inc. ASHRAE Environmental Guidelines for Datacom Equipment, 2008. http://www.ashrae.org.
[2] J. Anderson, T. Hoar, H. Liu K. Raeder, N. Collins, R. Torn, and A. Arellano. The data assimilation research testbed: A community facility. Bulletin of the American Meteorological Society, 90: 1283–1296, 2009. doi:10.1175/2009BAMS2618.1.
[3] AWP-ODC. http://hpgeoc.sdsc.edu/AWPODC/, August 2013.
[4] C. Belady, A. Rawson, J. Pfleuger, and T. Cader. The green grid data center power efficiency metrics: PUE and DCiE. White Paper No. 6, 2008.
[5] G. Bell, J. Gray, and A. Szalay. Petascale computational systems. Computer, 39(110-112): 1337–1351, 2006.
[6] J. Charney, R. Fjörtoft, and J. Von Neumann. Numerical integration of the barotropic vorticity equation. Tellus, 2(4):237–254, 1950.
[7] P. Chen. Full-wave seismic data assimilation: A unified methodology for seismic waveform inversion. In Y.G. Li, editor, Imaging, Modeling and Assimilation in Seismology, pages 19–64. Higher Education Press and Walter de Gruyter GmbH & Co., 2012.
[8] Yellowstone. http://www2.cisl.ucar.edu/resources/yellowstone/, 2013.
[9] D. Clarke. What is ZEUS-3D? http://www.ica.smu.ca/zeus3d/documents/whatiszeus.pdf, August 2013. Saint Mary’s University.
[10] D. Del Vento and C. G. Kruse. Optimizing performance of the weather research and forecasting model at large core counts: an investigation into hybrid parallelism and domain decomposition. In Proceedings of AMS 2014, 2014.
[11] J. M. Dennis, J. Edwards, K. J. Evans, O. Guba, P. Lauritzen, A. Mirin, A. St-Cyr, M. A. Taylor, and P. Worley. CAM-SE: A scalable spectral element dynamical core for the community atmosphere model. International Journal of High Performance Computing Applications, 26(1):74–89, 2012.
[12] J. M. Dennis, M. Vertenstein, P. Worley, A. Mirin, A. Craig, R. Jacob, and S. Mickelson. Computational performance of ultra-high-resolution capability in the community earth system model. International Journal of High Performance Computing Applications, 26(1):5–16, 2012.
[13] D. Duke. ZLD: New silica based inhibitor chemistry permits cost effective water conservation for HVAC and industrial cooling towers. International Water Conference IWC Report 07-11, 2011.
[14] Earth System Grid website. http://www.earthsystemgrid.org, 2013.
[15] G. Grell, S. Peckham, R. Schmitz, S. McKeen, G. Frost, W. Skamarock, and B. Eder. Fully coupled “online” chemistry within the wrf model. Atmospheric Environment, 39(37):6957–6975, 2005.
[16] D. L. Hart. Deep and wide metrics for HPC resource capability and project usage. In SC’11 State of the Practice Reports, Seattle, WA, 2011. doi:10.1145/2063348.2063350.
[17] D. L. Hart, P. Gillman, and E. Thanhardt. Concurrency Computat.: Pract. Experiences (26) 2210–2224, 2014. doi: 10.1002/cpe.3228.
[18] IBM rear door heat eXchanger for the iDataPlex rack, installation and maintenance guide. Technical Report P/N 49Y2134, IBM Corporation, March 2009.
[19] IBM x3650 M4. http://www-03.ibm.com/systems/x/hardware/rack/x3650m4/, Aug. 2013.
[20] IBM x3850 X5. http://www-03.ibm.com/systems/x/hardware/enterprise/x3850x5/, Aug. 2013.
[21] IBM system x iDataPlex dx360 M4. IBM Redbooks Product Guide, Aug. 2013.
[22] Hye-Mi Kim, Peter J. Webster, Violeta E. Toma, and Daehyun Kim, 2014: Predictability and prediction skill of the MJO in two operational forecasting systems. J. Climate, 27, 5364–5378. doi: 10.1175.JCLI-D-13-00480.1.
[23] J. L. Kinter III, D. Achuthavarier, J. M. Adams, E. L. Altshuler, B. A. Cash, P. Dirmeyer, B. Doty, B. Huang, L. Marx, J. Manganello, C. Stan, T. Wakefield, E. K. Jin, T. Palmer, M. Hamrud, T. Jung, M. Miller, P. Towers, N. Wedi, M. Satoh, H. Tomita, C. Kodama, Y. Yamada, P. Andrews, T. Baer, M. Ezell, C. Halloy, D. John, B. Loftis, and K. Wong. Revolutionizing climate modeling– project athena: A multi-institutional, international collaboration. Bull. Amer. Met. Soc., 94: 231–245, 2013.
[24] Intel Xeon E5-2670 (Sandy Bridge EP). http://ark.intel.com/products/64595/Intel-Xeon-Processor-E5-2670–20M-Cache-2_60-GHz-8_00-GTs-Intel-QPI, Aug. 2013.
[25] Intel Xeon E7–4870 (Westmere EX). http://ark.intel.com/products/53579/Intel-Xeon-Processor-E7–4870–30M-Cache-2_40-GHz-6_40-GTs-Intel-QPI, Aug. 2013.
[26] Intel xeon Phi 5110P coprocessor. http://ark.intel.com/products/71992/Intel-Xeon-Phi-Coprocessor-5110P-8GB-1_053-GHz-60-core, Aug. 2013.
[27] R. C. Kelly, S. S. Ghosh, S. Liu, D. Del Vento, and R. A. Valent. The NWSC benchmark suite using scientific throughput to measure supercomputer performance. In SC’11 State of the Practice Reports, Seattle, WA, 2011. doi: 10.1145/2063348.2063358.
[28] C. G. Kruse, D. Del Vento, R. Montuoro, M. Lubin, and S. McMillian. Evaluation of WRF scaling to several thousand cores on the yellowstone supercomputer. Work presented at FRCRC HPC Symposium 2013, Laramie, WY.
[29] P. M. Loechl et al. Design schematics for a sustainable parking lot. Technical Report ERDC/CERL TR-03-12, US Army Corps of Engineers, Research and Developing Center, Construction Engineering Research Laboratory, Champaign, IL, 2003.
[30] R. McLay, K. W. Schulz, W. L. Barth, and T. Minyard. Best practices for the deployment and management of production HPC clusters. In SC’11 State of the Practice Reports, page 11, New York, NY, 2011. ACM. doi:10.1145/2063348.2063360.
[31] G. Meehl, W. Washington, J. Arblaster, A. Hu, H. Teng, J. Kay, A. Gettelman, D. Lawrence, B. Sanderson, and W. Strand. Climate change projections in cesm1 (cam5) compared to ccsm4. J. Climate, volume 26, issue 17, pp. 6287–6308. doi:10.1175/JCLI-D-12-00572.1.
[32] SX6536. http://www.mellanox.com/page/products_dyn?product_family=122&menu_section=49, Aug. 2013.
[33] SX6512. http://www.mellanox.com/page/products_dyn?product_family=137&mtag=sx6512, Aug. 2013.
[34] SX6036. http://www.mellanox.com/page/products_dyn?product_family=132&menu_section=49, Aug. 2013.
[35] J. Michalakes, J. Dudhia, D. Gill, T. Henderson, J. Klemp, W. Skamarock, and W. Wang. The weather research and forecast model: software architecture and performance. In Proceedings of the 11th ECMWF Workshop on the Use of High Performance Computing In Meteorology, volume 25. World Scientific, 2004.
[36] C-H. Moeng and P.P. Sullivan. Large eddy simulation. Encyclopedia of Atmospheric Sciences, http://www.mmm.ucar.edu/applications/les/les.php.
[37] Climate Research Spurred by Green Design of Supercomputing Center. http://mountainstates.construction.com/mountainstates_construction_projects/2012/1022-climate-research-will-be-spurred-by-green-design-ofnew-supercomputing-center.asp, 2013.
[38] NVIDIA Quadro 6000. http://www.nvidia.com/object/product-quadro-6000-us.html, Aug. 2013.
[39] NVIDIA M2070Q. http://www.nvidia.com/docs/IO/43395/NV_DS_Tesla_M2050_M2070_Apr10_LowRes.pdf, Apr. 2010.
[40] N. A. Phillips. The general circulation of the atmosphere: A numerical experiment. Quarterly J. Royal Meteorological Society, 82: 123–164, 1956.
[41] W. C. Skamarock and J. B. Klemp. A time-split nonhydrostatic atmospheric model for weather research and forecasting applications. Journal of Computational Physics, 227(7):3465–3485, 2008.
[42] W.C. Skamarock, J.B. Klemp, M.G. Duda, L. Fowler, S-H. Park, and T.D. Ringler. A multi-scale nonhydrostatic atmospheric model using centroidal voronoi tesselations and c-grid staggering. Monthly Weather Review, 240: 3090–3105, 2012. doi:10.1175/MWR-D-11-00215.1.
[43] Small, R.J. et al. (2014), A new synoptic scale resolving global climate simulation using the Community Earth System Model, J. Adv. Model. Earth Sys., 06. doi: 10.1002/2014 MS000363.
[44] R. Smith, P. Jones, B. Briegleb, F. Bryan, G. Danabasoglu, J. Dennis, J. Dukowicz, C. Eden, B. Fox-Kemper, P. Gent, M. Hecht, S. Jayne, M. Jochum, W. Large, K. Lindsay, M. Maltrud, N. Norton, S. Peacock, M. Vertenstein, and S. Yeager. The Parallel Ocean Program (POP) reference manual: Ocean component of the Community Climate System Model (CCSM). Technical Report LAUR-10-01853, Los Alamos National Laboratory, March 2010.
[45] SPECFEM3D. http://www.geodynamics.org/cig/software/specfem3d, August 2013.
[46] TIEGCM v1.94 model description. http://www.hao.ucar.edu/modeling/tgcm/doc/description/model_description.pdf, Aug. 2013.
[47] NCAR selects IBM for key components of new supercomputing center. http://www2.ucar.edu/atmosnews/news/5662/ncar-selects-ibm-key-components-new-supercomputing-center, Nov. 2011.
[48] 2013 Green Enterprise IT award honorees. http://symposium.uptimeinstitute.com/geit-awards, 2013.
[49] U.S. Army Corps of Engineers air leakage test protocol for building envelopes.
[50] A. Vögler, S. Shelyag, M. Schüssler, F. Cattaneo, T. Emonet, and T. Linde. Simulations of magneto-convection in the solar photosphere: Equations, methods, and results of the MURaM code. Astron. & Astrophys., 429: 335–351, 2005.
[51] D. Watts and M. Bachmaier. Implementing an IBM system x iDataPlex solution. Technical Report SG24-7629-04, IBM International Technical Support Organization, June 2012.
[52] WRFDA users page. http://www.mmm.ucar.edu/wrf/users/wrfda/, Aug. 2013.
[53] Optimizing WRF performance. https://www2.cisl.ucar.edu/resources/software/models/wrf_optimization.