
20. Standard Template Library (STL)
Objectives
In this chapter you’ll learn:
![]() To be able to use the STL containers, container adapters and “near containers.”
To be able to use the STL containers, container adapters and “near containers.”
![]() To be able to program with the dozens of STL algorithms.
To be able to program with the dozens of STL algorithms.
![]() To understand how algorithms use iterators to access the elements of STL containers.
To understand how algorithms use iterators to access the elements of STL containers.
![]() To become familiar with the STL resources available on the Internet and the World Wide Web.
To become familiar with the STL resources available on the Internet and the World Wide Web.
The shapes a bright container can contain!
—Theodore Roethke
Journey over all the universe in a map.
—Miguel de Cervantes
O! thou hast damnable iteration, and art indeed able to corrupt a saint.
—William Shakespeare
That great dust heap called “history.”
—Augustine Birrell
The historian is a prophet in reverse.
—Friedrich von Schlegel
Attempt the end, and never stand to doubt; Nothing’s so hard but search will find it out.
—Robert Herrick
Outline
We’ve repeatedly emphasized the importance of software reuse. Recognizing that many data structures and algorithms commonly are used by C++ programmers, the C++ standard committee added the Standard Template Library (STL) to the C++ Standard Library. The STL defines powerful, template-based, reusable components that implement many common data structures and algorithms used to process those data structures. The STL offers proof of concept for generic programming with templates—introduced in Chapter 14, Templates. [Note: In industry, the features presented in this chapter are often referred to as the Standard Template Library or STL. However, these terms are not used in the C++ standard document, because these features are simply considered to be part of the C++ Standard Library.]
The STL was developed by Alexander Stepanov and Meng Lee at Hewlett-Packard and is based on their research in the field of generic programming, with significant contributions from David Musser. As you’ll see, the STL was conceived and designed for performance and flexibility.
This chapter introduces the STL and discusses its three key components—containers (popular templatized data structures), iterators and algorithms. The STL containers are data structures capable of storing objects of almost any data type (there are some restrictions). We’ll see that there are three styles of container classes—first-class containers, adapters and near containers.
Performance Tip 20.1
For any particular application, several different STL containers might be appropriate. Select the most appropriate container that achieves the best performance (i.e., balance of speed and size) for that application. Efficiency was a crucial consideration in the STL’s design.
Performance Tip 20.2
Standard Library capabilities are implemented to operate efficiently across many applications. For some applications with unique performance requirements, it might be necessary to write your own customized implementations.
Each STL container has associated member functions. A subset of these member functions is defined in all STL containers. We illustrate most of this common functionality in our examples of STL containers vector (a dynamically resizable array which we introduced in Chapter 7, Arrays and Vectors), list (a doubly linked list) and deque (a double-ended queue, pronounced “deck”). We introduce container-specific functionality in examples for each of the other STL containers.
STL iterators, which have properties similar to those of pointers, are used by programs to manipulate the STL-container elements. In fact, standard arrays can be manipulated by STL algorithms, using standard pointers as iterators. We’ll see that manipulating containers with iterators is convenient and provides tremendous expressive power when combined with STL algorithms—in some cases, reducing many lines of code to a single statement. There are five categories of iterators, each of which we discuss in Section 20.1.2 and use throughout this chapter.
STL algorithms are functions that perform such common data manipulations as searching, sorting and comparing elements (or entire containers). The STL provides approximately 70 algorithms. Most of them use iterators to access container elements. Each algorithm has minimum requirements for the types of iterators that can be used with it. We’ll see that each first-class container supports specific iterator types, some more powerful than others. A container’s supported iterator type determines whether the container can be used with a specific algorithm. Iterators encapsulate the mechanism used to access container elements. This encapsulation enables many of the STL algorithms to be applied to several containers without regard for the underlying container implementation. As long as a container’s iterators support the minimum requirements of the algorithm, then the algorithm can process that container’s elements. This also enables programmers to create new algorithms that can process the elements of multiple container types.
Software Engineering Observation 20.1
The STL approach allows general programs to be written so that the code does not depend on the underlying container. Such a programming style is called generic programming.
Data structures like linked lists, queues, stacks and trees carefully weave objects together with pointers. Pointer-based code is complex, and the slightest omission or oversight can lead to serious memory-access violations and memory-leak errors with no compiler complaints. Implementing additional data structures, such as deques, priority queues, sets and maps, requires substantial extra work. In addition, if many programmers on a large project implement similar containers and algorithms for different tasks, the code becomes difficult to modify, maintain and debug. An advantage of the STL is that programmers can reuse the STL containers, iterators and algorithms to implement common data representations and manipulations. This reuse can save substantial development time, money and effort.
Software Engineering Observation 20.2
Avoid reinventing the wheel; program with the reusable components of the C++ Standard Library. STL includes many of the most popular data structures as containers and provides various popular algorithms to process data in these containers.
Error-Prevention Tip 20.1
When programming pointer-based data structures and algorithms, we must do our own debugging and testing to be sure our data structures, classes and algorithms function properly. It is easy to make errors when manipulating pointers at this low level. Memory leaks and memory-access violations are common in such custom code. For most programmers, and for most of the applications they will need to write, the prepackaged, templatized containers of the STL are sufficient. Using the STL helps programmers reduce testing and debugging time. One caution is that, for large projects, template compile time can be significant.
This chapter introduces the STL. It is by no means complete or comprehensive. However, it is a friendly, accessible chapter that should convince you of the value of the STL in software reuse and encourage further study.
The STL container types are shown in Fig. 20.1. The containers are divided into three major categories—sequence containers, associative containers and container adapters.

The sequence containers represent linear data structures, such as vectors and linked lists. Associative containers are nonlinear containers that typically can locate elements stored in the containers quickly. Such containers can store sets of values or key/value pairs. The sequence containers and associative containers are collectively referred to as the first-class containers. Stacks and queues actually are constrained versions of sequential containers. For this reason, STL implements stacks and queues as container adapters that enable a program to view a sequential container in a constrained manner. There are other container types that are considered “near containers”—C-like pointer-based arrays (discussed in Chapter 7), bitsets for maintaining sets of flag values and valarrays for performing high-speed mathematical vector operations (this last class is optimized for computation performance and is not as flexible as the first-class containers). These types are considered “near containers” because they exhibit capabilities similar to those of the first-class containers, but do not support all the first-class-container capabilities. Type string (discussed in Chapter 18) supports the same functionality as a sequence container, but stores only character data.
Most STL containers provide similar functionality. Many generic operations, such as member function size, apply to all containers, and other operations apply to subsets of similar containers. This encourages extensibility of the STL with new classes. Figure 20.2 describes the functions common to all Standard Library containers. [Note: Overloaded operators operator<, operator<=, operator>, operator>=, operator== and operator!= are not provided for priority_queues.]

The header files for each of the Standard Library containers are shown in Fig. 20.3. The contents of these header files are all in namespace std.

Figure 20.4 shows the common typedefs (to create synonyms or aliases for lengthy type names) found in first-class containers. These typedefs are used in generic declarations of variables, parameters to functions and return values from functions. For example, value_type in each container is always a typedef that represents the type of value stored in the container.


Performance Tip 20.3
STL generally avoids inheritance and virtual functions in favor of using generic programming with templates to achieve better execution-time performance.
When preparing to use an STL container, it is important to ensure that the type of element being stored in the container supports a minimum set of functionality. When an element is inserted into a container, a copy of that element is made. For this reason, the element type should provide its own copy constructor and assignment operator. [Note: This is required only if default memberwise copy and default memberwise assignment do not perform proper copy and assignment operations for the element type.] Also, the associative containers and many algorithms require elements to be compared. For this reason, the element type should provide an equality operator (==) and a less-than operator (<).
Software Engineering Observation 20.3
The STL containers technically do not require their elements to be comparable with the equality and less-than operators unless a program uses a container member function that must compare the container elements (e.g., the sort function in class list). Unfortunately, some prestandard C++ compilers are not capable of ignoring parts of a template that are not used in a particular program. On compilers with this problem, you may not be able to use the STL containers with objects of classes that do not define overloaded less-than and equality operators.
Iterators have many features in common with pointers and are used to point to the elements of first-class containers (and for a few other purposes, as we’ll see). Iterators hold state information sensitive to the particular containers on which they operate; thus, iterators are implemented appropriately for each type of container. Certain iterator operations are uniform across containers. For example, the dereferencing operator (*) dereferences an iterator so that you can use the element to which it points. The ++ operation on an iterator moves it to the next element of the container (much as incrementing a pointer into an array aims the pointer at the next element of the array).
STL first-class containers provide member functions begin and end. Function begin returns an iterator pointing to the first element of the container. Function end returns an iterator pointing to the first element past the end of the container (an element that doesn’t exist). If iterator i points to a particular element, then ++i points to the “next” element and *i refers to the element pointed to by i. The iterator resulting from end is typically used in an equality or inequality comparison to determine whether the “moving iterator” (i in this case) has reached the end of the container.
We use an object of type iterator to refer to a container element that can be modified. We use an object of type const_iterator to refer to a container element that cannot be modified.
We use iterators with sequences (also called ranges). These sequences can be in containers, or they can be input sequences or output sequences. The program of Fig. 20.5 demonstrates input from the standard input (a sequence of data for input into a program), using an istream_iterator, and output to the standard output (a sequence of data for output from a program), using an ostream_iterator. The program inputs two integers from the user at the keyboard and displays the sum of the integers.1
Fig. 20.5 Input and output stream iterators.
1 // Fig. 20.5: fig20_05.cpp
2 // Demonstrating input and output with iterators.
3 #include <iostream>
4 using std::cout;
5 using std::cin;
6 using std::endl;
7
8 #include <iterator> // ostream_iterator and istream_iterator
9
10 int main()
11 {
12 cout << "Enter two integers: ";
13
14 // create istream_iterator for reading int values from cin
15 std::istream_iterator< int > inputInt( cin );
16
17 int number1 = *inputInt; // read int from standard input
18 ++inputInt; // move iterator to next input value
19 int number2 = *inputInt; // read int from standard input
20
21 // create ostream_iterator for writing int values to cout
22 std::ostream_iterator< int > outputInt( cout );
23
24 cout << "The sum is: " ;
25 *outputInt = number1 + number2; // output result to cout
26 cout << endl;
27 return 0;
28 } // end main
Enter two integers: 12 25
The sum is: 37
Line 15 creates an istream_iterator that is capable of extracting (inputting) int values in a type-safe manner from the standard input object cin. Line 17 dereferences iterator inputInt to read the first integer from cin and assigns that integer to number1. Note that the dereferencing operator * applied to inputInt gets the value from the stream associated with inputInt; this is similar to dereferencing a pointer. Line 18 positions iterator inputInt to the next value in the input stream. Line 19 inputs the next integer from inputInt and assigns it to number2.
Line 22 creates an ostream_iterator that is capable of inserting (outputting) int values in the standard output object cout. Line 25 outputs an integer to cout by assigning to *outputInt the sum of number1 and number2. Notice the use of the dereferencing operator * to use *outputInt as an lvalue in the assignment statement. If you want to output another value using outputInt, the iterator must be incremented with ++ (both the prefix and postfix increment can be used, but the prefix form should be preferred for performance reasons).
Error-Prevention Tip 20.2
The * (dereferencing) operator of any const iterator returns a const reference to the container element, disallowing the use of non-const member functions.
Figure 20.6 shows the categories of STL iterators. Each category provides a specific set of functionality. Figure 20.7 illustrates the hierarchy of iterator categories. As you follow the hierarchy from top to bottom, each iterator category supports all the functionality of the categories above it in the figure. Thus the “weakest” iterator types are at the top and the most powerful one is at the bottom. Note that this is not an inheritance hierarchy.

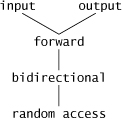
The iterator category that each container supports determines whether that container can be used with specific algorithms in the STL. Containers that support random-access iterators can be used with all algorithms in the STL. As we’ll see, pointers into arrays can be used in place of iterators in most STL algorithms, including those that require random-access iterators. Figure 20.8 shows the iterator category of each of the STL containers. Note that vectors, deques, lists, sets, multisets, maps, multimaps (i.e., the first-class containers), strings and arrays are traversable with iterators.
Fig. 20.8 Iterator types supported by each Standard Library container.
|
Container |
Type of iterator supported |
|
|---|---|---|
|
Sequence containers (first class) |
||
|
|
random access |
|
|
|
random access |
|
|
|
bidirectional |
|
|
Associative containers (first class) |
||
|
|
bidirectional |
|
|
|
bidirectional |
|
|
|
bidirectional |
|
|
|
bidirectional |
|
|
Container adapters |
||
|
|
no iterators supported |
|
|
|
no iterators supported |
|
|
|
no iterators supported |
|
Software Engineering Observation 20.4
Using the “weakest iterator” that yields acceptable performance helps produce maximally reusable components. For example, if an algorithm requires only forward iterators, it can be used with any container that supports forward iterators, bidirectional iterators or random-access iterators. However, an algorithm that requires random-access iterators can be used only with containers that have random-access iterators.
Figure 20.9 shows the predefined iterator typedefs that are found in the class definitions of the STL containers. Not every typedef is defined for every container. We use const versions of the iterators for traversing read-only containers. We use reverse iterators to traverse containers in the reverse direction.
Figure 20.10 shows some operations that can be performed on each iterator type. Note that the operations for each iterator type include all operations preceding that type in the figure. Note also that, for input iterators and output iterators, it is not possible to save the iterator and then use the saved value later.
Fig. 20.10 Iterator operations for each type of iterator.
|
Iterator operation |
Description |
|---|---|
|
All iterators |
|
|
|
Preincrement an iterator. |
|
|
Postincrement an iterator. |
|
Input iterators |
|
|
|
Dereference an iterator. |
|
|
Assign one iterator to another. |
|
|
Compare iterators for equality. |
|
|
Compare iterators for inequality. |
|
Output iterators |
|
|
|
Dereference an iterator. |
|
|
Assign one iterator to another. |
|
Forward iterators |
Forward iterators provide all the functionality of both input iterators and output iterators. |
|
Bidirectional iterators |
|
|
|
Predecrement an iterator. |
|
|
Postdecrement an iterator. |
|
Random-access iterators |
|
|
|
Increment the iterator |
|
|
Decrement the iterator |
|
|
Expression value is an iterator positioned at |
|
|
Expression value is an iterator positioned at |
|
|
Expression value is an integer representing the distance between two elements in the same container. |
|
|
Return a reference to the element offset from |
|
|
Return |
|
|
Return |
|
|
Return |
|
|
Return |
STL algorithms can be used generically across a variety of containers. STL provides many algorithms you’ll use frequently to manipulate containers. Inserting, deleting, searching, sorting and others are appropriate for some or all of the STL containers.
The STL includes approximately 70 standard algorithms. We provide live-code examples of most of these and summarize the others in tables. The algorithms operate on container elements only indirectly through iterators. Many algorithms operate on sequences of elements defined by pairs of iterators—a first iterator pointing to the first element of the sequence and a second iterator pointing to one element past the last element of the sequence. Also, it is possible to create your own new algorithms that operate in a similar fashion so they can be used with the STL containers and iterators.
Algorithms often return iterators that indicate the results of the algorithms. Algorithm find, for example, locates an element and returns an iterator to that element. If the element is not found, find returns the “one past the end” iterator that was passed in to define the end of the range to be searched, which can be tested to determine whether an element was not found. The find algorithm can be used with any first-class STL container. STL algorithms create yet another opportunity for reuse—using the rich collection of popular algorithms can save programmers much time and effort.
If an algorithm uses less powerful iterators, the algorithm can also be used with containers that support more powerful iterators. Some algorithms demand powerful iterators; e.g., sort demands random-access iterators.
Software Engineering Observation 20.5
The STL is implemented concisely. Until now, class designers would have associated the algorithms with the containers by making the algorithms member functions of the containers. The STL takes a different approach. The algorithms are separated from the containers and operate on elements of the containers only indirectly through iterators. This separation makes it easier to write generic algorithms applicable to many container classes.
Software Engineering Observation 20.6
The STL is extensible. It is straightforward to add new algorithms and to do so without changes to STL containers.
Software Engineering Observation 20.7
STL algorithms can operate on STL containers and on pointer-based, C-like arrays.
Portability Tip 20.2
Because STL algorithms process containers only indirectly through iterators, one algorithm can often be used with many different containers.
Figure 20.11 shows many of the mutating-sequence algorithms—i.e., the algorithms that result in modifications of the containers to which the algorithms are applied.
Fig. 20.11 Mutating-sequence algorithms.
|
Mutating-sequence algorithms |
||
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Figure 20.12 shows many of the nonmodifying sequence algorithms—i.e., the algorithms that do not result in modifications of the containers to which they are applied. Figure 20.13 shows the numerical algorithms of the header file <numeric>.
The C++ Standard Template Library provides three sequence containers—vector, list and deque. Class template vector and class template deque both are based on arrays. Class template list implements a linked-list data structure.
One of the most popular containers in the STL is vector. Recall that we introduced class template vector in Chapter 7 as a more robust type of array. A vector changes size dynamically. Unlike C and C++ “raw” arrays (see Chapter 7), vectors can be assigned to one another. This is not possible with pointer-based, C-like arrays, because those array names are constant pointers and cannot be the targets of assignments. Just as with C arrays, vector subscripting does not perform automatic range checking, but class template vector does provide this capability via member function at (also discussed in Chapter 7).
Performance Tip 20.4
Insertion at the back of a vector is efficient. The vector simply grows, if necessary, to accommodate the new item. It is expensive to insert (or delete) an element in the middle of a vector—the entire portion of the vector after the insertion (or deletion) point must be moved, because vector elements occupy contiguous cells in memory just as C or C++ “raw” arrays do.
Figure 20.2 presented the operations common to all the STL containers. Beyond these operations, each container typically provides a variety of other capabilities. Many of these capabilities are common to several containers, but they are not always equally efficient for each container. You must choose the container most appropriate for the application.
Performance Tip 20.5
Applications that require frequent insertions and deletions at both ends of a container normally use a deque rather than a vector. Although we can insert and delete elements at the front and back of both a vector and a deque, class deque is more efficient than vector for doing insertions and deletions at the front.
Performance Tip 20.6
Applications with frequent insertions and deletions in the middle and/or at the extremes of a container normally use a list, due to its efficient implementation of insertion and deletion anywhere in the data structure.
In addition to the common operations described in Fig. 20.2, the sequence containers have several other common operations—front to return a reference to the first element in a non-empty container, back to return a reference to the last element in a non-empty container, push_back to insert a new element at the end of the container and pop_back to remove the last element of the container.
Class template vector provides a data structure with contiguous memory locations. This enables efficient, direct access to any element of a vector via the subscript operator [], exactly as with a C or C++ “raw” array. Class template vector is most commonly used when the data in the container must be easily accessible via a subscript or will be sorted. When a vector’s memory is exhausted, the vector allocates a larger contiguous area of memory, copies the original elements into the new memory and deallocates the old memory.
Performance Tip 20.8
Objects of class template vector provide rapid indexed access with the overloaded subscript operator [] because they are stored in contiguous memory like a C or C++ raw array.
An important part of every container is the type of iterator it supports. This determines which algorithms can be applied to the container. A vector supports random-access iterators—i.e., all iterator operations shown in Fig. 20.10 can be applied to a vector iterator. All STL algorithms can operate on a vector. The iterators for a vector are sometimes implemented as pointers to elements of the vector. Each STL algorithm that takes iterator arguments requires those iterators to provide a minimum level of functionality. If an algorithm requires a forward iterator, for example, that algorithm can operate on any container that provides forward iterators, bidirectional iterators or random-access iterators. As long as the container supports the algorithm’s minimum iterator functionality, the algorithm can operate on the container.
Figure 20.14 illustrates several functions of the vector class template. Many of these functions are available in every first-class container. You must include header file <vector> to use class template vector.
Fig. 20.14 Standard Library vector class template.
1 // Fig. 20.14: fig20_14.cpp
2 // Demonstrating Standard Library vector class template.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <vector> // vector class-template definition
8 using std::vector;
9
10 // prototype for function template printVector
11 template < typename T > void printVector( const vector< T > &integers2 );
12
13 int main()
14 {
15 const int SIZE = 6; // define array size
16 int array[ SIZE ] = { 1, 2, 3, 4, 5, 6 }; // initialize array
17 vector< int > integers; // create vector of ints
18
19 cout << "The initial size of integers is: " << integers.size()
20 << "
The initial capacity of integers is: " << integers.capacity();
21
22 // function push_back is in every sequence collection
23 integers.push_back( 2 );
24 integers.push_back( 3 );
25 integers.push_back( 4 );
26
27 cout << "
The size of integers is: " << integers.size()
28 << "
The capacity of integers is: " << integers.capacity();
29 cout << "
Output array using pointer notation: ";
30
31 // display array using pointer notation
32 for ( int *ptr = array; ptr != array + SIZE; ptr++ )
33 cout << *ptr << ' ';
34
35 cout << "
Output vector using iterator notation: ";
36 printVector( integers );
37 cout << "
Reversed contents of vector integers: ";
38
39 // two const reverse iterators
40 vector< int >::const_reverse_iterator reverseIterator;
41 vector< int >::const_reverse_iterator tempIterator = integers.rend();
42
43 // display vector in reverse order using reverse_iterator
44 for ( reverseIterator = integers.rbegin();
45 reverseIterator!= tempIterator; ++reverseIterator )
46 cout << *reverseIterator << ' ';
47
48 cout << endl;
49 return 0;
50 } // end main
51
52 // function template for outputting vector elements
53 template < typename T > void printVector( const vector< T > &integers2 )
54 {
55 typename vector< T >::const_iterator constIterator; // const_iterator
56
57 // display vector elements using const_iterator
58 for ( constIterator = integers2.begin();
59 constIterator != integers2.end(); ++constIterator )
60 cout << *constIterator << ' ';
61 } // end function printVector
The initial size of integers is: 0
The initial capacity of integers is: 0
The size of integers is: 3
The capacity of integers is: 4
Output array using pointer notation: 1 2 3 4 5 6
Output vector using iterator notation: 2 3 4
Reversed contents of vector integers: 4 3 2
Line 17 defines an instance called integers of class template vector that stores int values. When this object is instantiated, an empty vector is created with size 0 (i.e., the number of elements stored in the vector) and capacity 0 (i.e., the number of elements that can be stored without allocating more memory to the vector).
Lines 19 and 20 demonstrate the size and capacity functions; each initially returns 0 for vector v in this example. Function size—available in every container—returns the number of elements currently stored in the container. Function capacity returns the number of elements that can be stored in the vector before the vector needs to dynamically resize itself to accommodate more elements.
Lines 23–25 use function push_back—available in all sequence containers—to add an element to the end of the vector. If an element is added to a full vector, the vector increases its size—some STL implementations have the vector double its capacity.
Performance Tip 20.10
It can be wasteful to double a vector’s size when more space is needed. For example, a full vector of 1,000,000 elements resizes to accommodate 2,000,000 elements when a new element is added. This leaves 999,999 unused elements. Programmers can use resize and reserve to control space usage better.
Lines 27 and 28 use size and capacity to illustrate the new size and capacity of the vector after the three push_back operations. Function size returns 3—the number of elements added to the vector. Function capacity returns 4, indicating that we can add one more element before the vector needs to add more memory. When we added the first element, the vector allocated space for one element, and the size became 1 to indicate that the vector contained only one element. When we added the second element, the capacity doubled to 2 and the size became 2 as well. When we added the third element, the capacity doubled again to 4. So we can actually add another element before the vector needs to allocation more space. When the vector eventually fills its allocated capacity and the program attempts to add one more element to the vector, the vector will double its capacity to 8 elements.
The manner in which a vector grows to accommodate more elements—a time consuming operation—is not specified by the C++ Standard Document. C++ library implementors use various clever schemes to minimize the overhead of resizing a vector. Hence, the output of this program may vary, depending on the version of vector that comes with your compiler. Some library implementors allocate a large initial capacity. If a vector stores a small number of elements, such capacity may be a waste of space. However, it can greatly improve performance if a program adds many elements to a vector and does not have to reallocate memory to accommodate those elements. This is a classic space–time trade-off. Library implementors must balance the amount of memory used against the amount of time required to perform various vector operations.
Lines 32–33 demonstrate how to output the contents of an array using pointers and pointer arithmetic. Line 36 calls function printVector (defined in lines 53–61) to output the contents of a vector using iterators. Function template printVector receives a const reference to a vector (integers2) as its argument. Line 55 defines a const_iterator called constIterator that iterates through the vector and outputs its contents. Notice that the declaration in line 55 is prefixed with the keyword typename. Because printVector is a function template and vector< T > will be specialized differently for each function-template specialization, the compiler cannot tell at compile time whether or not vector< T >::const_iterator is a type. In particular specialization, const_iterator could be a static variable. The compiler needs this information to compile the program correctly. Therefore, you must tell the compiler that a qualified name, when the qualifier is a dependent type, is expected to be a type in every specialization.
A const_iterator enables the program to read the elements of the vector, but does not allow the program to modify the elements. The for statement in lines 58–60 initializes constIterator using vector member function begin, which returns a const_iterator to the first element in the vector—there is another version of begin that returns an iterator that can be used for non-const containers. Note that a const_iterator is returned because the identifier integers2 was declared const in the parameter list of function printVector. The loop continues as long as constIterator has not reached the end of the vector. This is determined by comparing constIterator to the result of integers2.end(), which returns an iterator indicating the location past the last element of the vector. If constIterator is equal to this value, the end of the vector has been reached. Functions begin and end are available for all first-class containers. The body of the loop dereferences iterator constIterator to get the value in the current element of the vector. Remember that the iterator acts like a pointer to the element and that operator * is overloaded to return a reference to the element. The expression ++constIterator (line 59) positions the iterator to the next element of the vector.
Performance Tip 20.11
Use prefix increment when applied to STL iterators because the prefix increment operator does not return a value that must be stored in a temporary object.
Error-Prevention Tip 20.4
Only random-access iterators support <. It is better to use != and end to test for the end of a container.
Line 40 declares a const_reverse_iterator that can be used to iterate through a vector backward. Line 41 declares a const_reverse_iterator variable tempIterator and initializes it to the iterator returned by function rend (i.e., the iterator for the ending point when iterating through the container in reverse). All first-class containers support this type of iterator. Lines 44–46 use a for statement similar to that in function printVector to iterate through the vector. In this loop, function rbegin (i.e., the iterator for the starting point when iterating through the container in reverse) and tempIterator delineate the range of elements to output. As with functions begin and end, rbegin and rend can return a const_reverse_iterator or a reverse_iterator, based on whether or not the container is constant.
Figure 20.15 illustrates functions that enable retrieval and manipulation of the elements of a vector. Line 17 uses an overloaded vector constructor that takes two iterators as arguments to initialize integers. Remember that pointers into an array can be used as iterators. Line 17 initializes integers with the contents of array from location array up to—but not including—location array + SIZE.
Fig. 20.15 vector class template element-manipulation functions.
1 // Fig. 20.15: fig20_15.cpp
2 // Testing Standard Library vector class template
3 // element-manipulation functions.
4 #include <iostream>
5 using std::cout;
6 using std::endl;
7
8 #include <vector> // vector class-template definition
9 #include <algorithm> // copy algorithm
10 #include <iterator> // ostream_iterator iterator
11 #include <stdexcept> // out_of_range exception
12
13 int main()
14 {
15 const int SIZE = 6;
16 int array[ SIZE ] = { 1, 2, 3, 4, 5, 6 };
17 std::vector< int > integers( array, array + SIZE );
18 std::ostream_iterator< int > output( cout, " " );
19
20 cout << "Vector integers contains: ";
21 std::copy( integers.begin(), integers.end(), output );
22
23 cout << "
First element of integers: " << integers.front()
24 << "
Last element of integers: " << integers.back();
25
26 integers[ 0 ] = 7; // set first element to 7
27 integers.at( 2 ) = 10; // set element at position 2 to 10
28
29 // insert 22 as 2nd element
30 integers.insert( integers.begin() + 1, 22 );
31
32 cout << "
Contents of vector integers after changes: ";
33 std::copy( integers.begin(), integers.end(), output );
34
35 // access out-of-range element
36 try
37 {
38 integers.at( 100 ) = 777;
39 } // end try
40 catch ( std::out_of_range &outOfRange ) // out_of_range exception
41 {
42 cout << "
Exception: " << outOfRange.what();
43 } // end catch
44
45 // erase first element
46 integers.erase( integers.begin() );
47 cout << "
Vector integers after erasing first element: ";
48 std::copy( integers.begin(), integers.end(), output );
49
50 // erase remaining elements
51 integers.erase( integers.begin(), integers.end() );
52 cout << "
After erasing all elements, vector integers "
53 << ( integers.empty() ? "is" : "is not" ) << " empty";
54
55 // insert elements from array
56 integers.insert( integers.begin(), array, array + SIZE );
57 cout << "
Contents of vector integers before clear: ";
58 std::copy( integers.begin(), integers.end(), output );
59
60 // empty integers; clear calls erase to empty a collection
61 integers.clear();
62 cout << "
After clear, vector integers "
63 << ( integers.empty() ? "is" : "is not" ) << " empty" << endl;
64 return 0;
65 } // end main
Vector integers contains: 1 2 3 4 5 6
First element of integers: 1
Last element of integers: 6
Contents of vector integers after changes: 7 22 2 10 4 5 6
Exception: invalid vector<T> subscript
Vector integers after erasing first element: 22 2 10 4 5 6
After erasing all elements, vector integers is empty
Contents of vector integers before clear: 1 2 3 4 5 6
After clear, vector integers is empty
Line 18 defines an ostream_iterator called output that can be used to output integers separated by single spaces via cout. An ostream_iterator< int > is a type-safe output mechanism that outputs only values of type int or a compatible type. The first argument to the constructor specifies the output stream, and the second argument is a string specifying the separator for the values output—in this case, the string contains a space character. We use the ostream_iterator (defined in header <iterator>) to output the contents of the vector in this example.
Line 21 uses algorithm copy from the Standard Library to output the entire contents of vector integers to the standard output. Algorithm copy copies each element in the container starting with the location specified by the iterator in its first argument and continuing up to—but not including—the location specified by the iterator in its second argument. The first and second arguments must satisfy input iterator requirements—they must be iterators through which values can be read from a container. Also, applying ++ to the first iterator must eventually cause it to reach the second iterator argument in the container. The elements are copied to the location specified by the output iterator (i.e., an iterator through which a value can be stored or output) specified as the last argument. In this case, the output iterator is an ostream_iterator (output) that is attached to cout, so the elements are copied to the standard output. To use the algorithms of the Standard Library, you must include the header file <algorithm>.
Lines 23–24 use functions front and back (available for all sequence containers) to determine the vector’s first and last elements, respectively. Notice the difference between functions front and begin. Function front returns a reference to the first element in the vector, while function begin returns a random access iterator pointing to the first element in the vector. Also notice the difference between functions back and end. Function back returns a reference to the last element in the vector, while function end returns a random access iterator pointing to the end of the vector (the location after the last element).
Common Programming Error 20.3
The vector must not be empty; otherwise, results of the front and back functions are undefined.
Lines 26–27 illustrate two ways to subscript through a vector (which also can be used with the deque containers). Line 26 uses the subscript operator that is overloaded to return either a reference to the value at the specified location or a constant reference to that value, depending on whether the container is constant. Function at (line 27) performs the same operation, but with bounds checking. Function at first checks the value supplied as an argument and determines whether it is in the bounds of the vector. If not, function at throws an out_of_bounds exception defined in header <stdexcept> (as demonstrated in lines 36–43). Figure 20.16 shows some of the STL exception types. (The Standard Library exception types are discussed in Chapter 16, Exception Handling.)
Fig. 20.16 Some STL exception types.
|
STL exception types |
Description |
|---|---|
|
|
Indicates when subscript is out of range—e.g., when an invalid subscript is specified to |
|
|
Indicates an invalid argument was passed to a function. |
|
|
Indicates an attempt to create too long a container, |
|
|
Indicates that an attempt to allocate memory with |
Line 30 uses one of the three overloaded insert functions provided by each sequence container. Line 30 inserts the value 22 before the element at the location specified by the iterator in the first argument. In this example, the iterator is pointing to the second element of the vector, so 22 is inserted as the second element and the original second element becomes the third element of the vector. Other versions of insert allow inserting multiple copies of the same value starting at a particular position in the container, or inserting a range of values from another container (or array), starting at a particular position in the original container.
Lines 46 and 51 use the two erase functions that are available in all first-class containers. Line 46 indicates that the element at the location specified by the iterator argument should be removed from the container (in this example, the element at the beginning of the vector). Line 51 specifies that all elements in the range starting with the location of the first argument up to—but not including—the location of the second argument should be erased from the container. In this example, all the elements are erased from the vector. Line 53 uses function empty (available for all containers and adapters) to confirm that the vector is empty.
Common Programming Error 20.4
Erasing an element that contains a pointer to a dynamically allocated object does not delete that object; this can lead to a memory leak.
Line 56 demonstrates the version of function insert that uses the second and third arguments to specify the starting location and ending location in a sequence of values (possibly from another container; in this case, from array of integers array) that should be inserted into the vector. Remember that the ending location specifies the position in the sequence after the last element to be inserted; copying is performed up to—but not including—this location.
Finally, line 61 uses function clear (found in all first-class containers) to empty the vector. This function calls the version of erase used in line 51 to empty the vector.
[Note: Other functions that are common to all containers and common to all sequence containers have not yet been covered. We’ll cover most of these in the next few sections. We’ll also cover many functions that are specific to each container.]
The list sequence container provides an efficient implementation for insertion and deletion operations at any location in the container. If most of the insertions and deletions occur at the ends of the container, the deque data structure (Section 20.2.3) provides a more efficient implementation. Class template list is implemented as a doubly linked list—every node in the list contains a pointer to the previous node in the list and to the next node in the list. This enables class template list to support bidirectional iterators that allow the container to be traversed both forward and backward. Any algorithm that requires input, output, forward or bidirectional iterators can operate on a list. Many list member functions manipulate the elements of the container as an ordered set of elements.
In addition to the member functions of all STL containers in Fig. 20.2 and the common member functions of all sequence containers discussed in Section 20.2, class template list provides nine other member functions—splice, push_front, pop_front, remove, remove_if, unique, merge, reverse and sort. Several of these member functions are list-optimized implementations of STL algorithms presented in Section 20.5. Figure 20.17 demonstrates several features of class list. Remember that many of the functions presented in Figs. 20.14–20.15 can be used with class list. Header file <list> must be included to use class list.
Fig. 20.17 Standard Library list class template.
1 // Fig. 20.17: fig20_17.cpp
2 // Standard library list class template test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <list> // list class-template definition
8 #include <algorithm> // copy algorithm
9 #include <iterator> // ostream_iterator
10
11 // prototype for function template printList
12 template < typename T > void printList( const std::list< T > &listRef );
13
14 int main()
15 {
16 const int SIZE = 4;
17 int array[ SIZE ] = { 2, 6, 4, 8 };
18 std::list< int > values; // create list of ints
19 std::list< int > otherValues; // create list of ints
20
21 // insert items in values
22 values.push_front( 1 );
23 values.push_front( 2 );
24 values.push_back( 4 );
25 values.push_back( 3 );
26
27 cout << "values contains: ";
28 printList( values );
29
30 values.sort(); // sort values
31 cout << "
values after sorting contains: ";
32 printList( values );
33
34 // insert elements of array into otherValues
35 otherValues.insert( otherValues.begin(), array, array + SIZE );
36 cout << "
After insert, otherValues contains: ";
37 printList( otherValues );
38
39 // remove otherValues elements and insert at end of values
40 values.splice( values.end(), otherValues );
41 cout << "
After splice, values contains: ";
42 printList( values );
43
44 values.sort(); // sort values
45 cout << "
After sort, values contains: ";
46 printList( values );
47
48 // insert elements of array into otherValues
49 otherValues.insert( otherValues.begin(), array, array + SIZE );
50 otherValues.sort();
51 cout << "
After insert and sort, otherValues contains: ";
52 printList( otherValues );
53
54 // remove otherValues elements and insert into values in sorted order
55 values.merge( otherValues );
56 cout << "
After merge:
values contains: ";
57 printList( values );
58 cout << "
otherValues contains: ";
59 printList( otherValues );
60
61 values.pop_front(); // remove element from front
62 values.pop_back(); // remove element from back
63 cout << "
After pop_front and pop_back:
values contains: "
64 printList( values );
65
66 values.unique(); // remove duplicate elements
67 cout << "
After unique, values contains: ";
68 printList( values );
69
70 // swap elements of values and otherValues
71 values.swap( otherValues );
72 cout << "
After swap:
values contains: ";
73 printList( values );
74 cout << "
otherValues contains: ";
75 printList( otherValues );
76
77 // replace contents of values with elements of otherValues
78 values.assign( otherValues.begin(), otherValues.end() );
79 cout << "
After assign, values contains: ";
80 printList( values );
81
82 // remove otherValues elements and insert into values in sorted order
83 values.merge( otherValues );
84 cout << "
After merge, values contains: ";
85 printList( values );
86
87 values.remove( 4 ); // remove all 4s
88 cout << "
After remove( 4 ), values contains: ";
89 printList( values );
90 cout << endl;
91 return 0;
92 } // end main
93
94 // printList function template definition; uses
95 // ostream_iterator and copy algorithm to output list elements
96 template < typename T > void printList( const std::list< T > &listRef )
97 {
98 if ( listRef.empty() ) // list is empty
99 cout << "List is empty";
100 else
101 {
102 std::ostream_iterator< T > output( cout, " " );
103 std::copy( listRef.begin(), listRef.end(), output );
104 } // end else
105 } // end function printList
values contains: 2 1 4 3
values after sorting contains: 1 2 3 4
After insert, otherValues contains: 2 6 4 8
After splice, values contains: 1 2 3 4 2 6 4 8
After sort, values contains: 1 2 2 3 4 4 6 8
After insert and sort, otherValues contains: 2 4 6 8
After merge:
values contains: 1 2 2 2 3 4 4 4 6 6 8 8
otherValues contains: List is empty
After pop_front and pop_back:
values contains: 2 2 2 3 4 4 4 6 6 8
After unique, values contains: 2 3 4 6 8
After swap:
values contains: List is empty
otherValues contains: 2 3 4 6 8
After assign, values contains: 2 3 4 6 8
After merge, values contains: 2 2 3 3 4 4 6 6 8 8
After remove( 4 ), values contains: 2 2 3 3 6 6 8 8
Lines 18–19 instantiate two list objects capable of storing integers. Lines 22–23 use function push_front to insert integers at the beginning of values. Function push_front is specific to classes list and deque (not to vector). Lines 24–25 use function push_back to insert integers at the end of values. Remember that function push_back is common to all sequence containers.
Line 30 uses list member function sort to arrange the elements in the list in ascending order. [Note: This is different from the sort in the STL algorithms.] A second version of function sort allows you to supply a binary predicate function that takes two arguments (values in the list), performs a comparison and returns a bool value indicating the result. This function determines the order in which the elements of the list are sorted. This version could be particularly useful for a list that stores pointers rather than values. [Note: We demonstrate a unary predicate function in Fig. 20.28. A unary predicate function takes a single argument, performs a comparison using that argument and returns a bool value indicating the result.]
Line 40 uses list function splice to remove the elements in otherValues and insert them into values before the iterator position specified as the first argument. There are two other versions of this function. Function splice with three arguments allows one element to be removed from the container specified as the second argument from the location specified by the iterator in the third argument. Function splice with four arguments uses the last two arguments to specify a range of locations that should be removed from the container in the second argument and placed at the location specified in the first argument.
After inserting more elements in otherValues and sorting both values and otherValues, line 55 uses list member function merge to remove all elements of otherValues and insert them in sorted order into values. Both lists must be sorted in the same order before this operation is performed. A second version of merge enables you to supply a predicate function that takes two arguments (values in the list) and returns a bool value. The predicate function specifies the sorting order used by merge.
Line 61 uses list function pop_front to remove the first element in the list. Line 62 uses function pop_back (available for all sequence containers) to remove the last element in the list.
Line 66 uses list function unique to remove duplicate elements in the list. The list should be in sorted order (so that all duplicates are side by side) before this operation is performed, to guarantee that all duplicates are eliminated. A second version of unique enables you to supply a predicate function that takes two arguments (values in the list) and returns a bool value specifying whether two elements are equal.
Line 71 uses function swap (available to all containers) to exchange the contents of values with the contents of otherValues.
Line 78 uses list function assign to replace the contents of values with the contents of otherValues in the range specified by the two iterator arguments. A second version of assign replaces the original contents with copies of the value specified in the second argument. The first argument of the function specifies the number of copies. Line 87 uses list function remove to delete all copies of the value 4 from the list.
Class deque provides many of the benefits of a vector and a list in one container. The term deque is short for “double-ended queue.” Class deque is implemented to provide efficient indexed access (using subscripting) for reading and modifying its elements, much like a vector. Class deque is also implemented for efficient insertion and deletion operations at its front and back, much like a list (although a list is also capable of efficient insertions and deletions in the middle of the list). Class deque provides support for random-access iterators, so deques can be used with all STL algorithms. One of the most common uses of a deque is to maintain a first-in, first-out queue of elements. In fact, a deque is the default underlying implementation for the queue adaptor (Section 20.4.2).
Additional storage for a deque can be allocated at either end of the deque in blocks of memory that are typically maintained as an array of pointers to those blocks.2 Due to the noncontiguous memory layout of a deque, a deque iterator must be more intelligent than the pointers that are used to iterate through vectors or pointer-based arrays.
Performance Tip 20.14
Insertions and deletions in the middle of a deque are optimized to minimize the number of elements copied, so it is more efficient than a vector but less efficient than a list for this kind of modification.
Class deque provides the same basic operations as class vector, but adds member functions push_front and pop_front to allow insertion and deletion at the beginning of the deque, respectively.
Figure 20.18 demonstrates features of class deque. Remember that many of the functions presented in Fig. 20.14, Fig. 20.15 and Fig. 20.17 also can be used with class deque. Header file <deque> must be included to use class deque.
Fig. 20.18 Standard Library deque class template.
1 // Fig. 20.18: fig20_18.cpp
2 // Standard Library class deque test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <deque> // deque class-template definition
8 #include <algorithm> // copy algorithm
9 #include <iterator> // ostream_iterator
10
11 int main()
12 {
13 std::deque< double > values; // create deque of doubles
14 std::ostream_iterator< double > output( cout, " " );
15
16 // insert elements in values
17 values.push_front( 2.2 );
18 values.push_front( 3.5 );
19 values.push_back( 1.1 );
20
21 cout << "values contains: ";
22
23 // use subscript operator to obtain elements of values
24 for ( unsigned int i = 0; i < values.size(); i++ )
25 cout << values[ i ] << ' ';
26
27 values.pop_front(); // remove first element
28 cout << "
After pop_front, values contains: ";
29 std::copy( values.begin(), values.end(), output );
30
31 // use subscript operator to modify element at location 1
32 values[ 1 ] = 5.4;
33 cout << "
After values[ 1 ] = 5.4, values contains: ";
34 std::copy( values.begin(), values.end(), output );
35 cout << endl;
36 return 0;
37 } // end main
values contains: 3.5 2.2 1.1
After pop_front, values contains: 2.2 1.1
After values[ 1 ] = 5.4, values contains: 2.2 5.4
Line 13 instantiates a deque that can store double values. Lines 17–19 use functions push_front and push_back to insert elements at the beginning and end of the deque. Remember that push_back is available for all sequence containers, but push_front is available only for class list and class deque.
The for statement in lines 24–25 uses the subscript operator to retrieve the value in each element of the deque for output. Note that the condition uses function size to ensure that we do not attempt to access an element outside the bounds of the deque.
Line 27 uses function pop_front to demonstrate removing the first element of the deque. Remember that pop_front is available only for class list and class deque (not for class vector).
Line 32 uses the subscript operator to create an lvalue. This enables values to be assigned directly to any element of the deque.
The STL’s associative containers provide direct access to store and retrieve elements via keys (often called search keys). The four associative containers are multiset, set, multimap and map. Each associative container maintains its keys in sorted order. Iterating through an associative container traverses it in the sort order for that container. Classes multiset and set provide operations for manipulating sets of values where the values are the keys—there is not a separate value associated with each key. The primary difference between a multiset and a set is that a multiset allows duplicate keys and a set does not. Classes multimap and map provide operations for manipulating values associated with keys (these values are sometimes referred to as mapped values). The primary difference between a multimap and a map is that a multimap allows duplicate keys with associated values to be stored and a map allows only unique keys with associated values. In addition to the common member functions of all containers presented in Fig. 20.2, all associative containers also support several other member functions, including find, lower_bound, upper_bound and count. Examples of each of the associative containers and the common associative container member functions are presented in the next several subsections.
The multiset associative container provides fast storage and retrieval of keys and allows duplicate keys. The ordering of the elements is determined by a comparator function object. For example, in an integer multiset, elements can be sorted in ascending order by ordering the keys with comparator function object less< int >. We discuss function objects in detail in Section 20.7. The data type of the keys in all associative containers must support comparison properly based on the comparator function object specified—keys sorted with less< T > must support comparison with operator<. If the keys used in the associative containers are of user-defined data types, those types must supply the appropriate comparison operators. A multiset supports bidirectional iterators (but not random-access iterators).
Figure 20.19 demonstrates the multiset associative container for a multiset of integers sorted in ascending order. Header file <set> must be included to use class multiset. Containers multiset and set provide the same basic functionality.
Fig. 20.19 Standard Library multiset class template.
1 // Fig. 20.19: fig20_19.cpp
2 // Testing Standard Library class multiset
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <set> // multiset class-template definition
8
9 // define short name for multiset type used in this program
10 typedef std::multiset< int, std::less< int > > Ims;
11
12 #include <algorithm> // copy algorithm
13 #include <iterator> // ostream_iterator
14
15 int main()
16 {
17 const int SIZE = 10;
18 int a[ SIZE ] = { 7, 22, 9, 1, 18, 30, 100, 22, 85, 13 };
19 Ims intMultiset; // Ims is typedef for "integer multiset"
20 std::ostream_iterator< int > output( cout, " " );
21
22 cout << "There are currently " << intMultiset.count( 15 )
23 << " values of 15 in the multiset
";
24
25 intMultiset.insert( 15 ); // insert 15 in intMultiset
26 intMultiset.insert( 15 ); // insert 15 in intMultiset
27 cout << "After inserts, there are " << intMultiset.count( 15 )
28 << " values of 15 in the multiset
";
29
30 // iterator that cannot be used to change element values
31 Ims::const_iterator result;
32
33 // find 15 in intMultiset; find returns iterator
34 result = intMultiset.find( 15 );
35
36 if ( result != intMultiset.end() ) // if iterator not at end
37 cout << "Found value 15
"; // found search value 15
38
39 // find 20 in intMultiset; find returns iterator
40 result = intMultiset.find( 20 );
41
42 if ( result == intMultiset.end() ) // will be true hence
43 cout << "Did not find value 20
"; // did not find 20
44
45 // insert elements of array a into intMultiset
46 intMultiset.insert( a, a + SIZE );
47 cout << "
After insert, intMultiset contains:
";
48 std::copy( intMultiset.begin(), intMultiset.end(), output );
49
50 // determine lower and upper bound of 22 in intMultiset
51 cout << "
Lower bound of 22: "
52 << *( intMultiset.lower_bound( 22 ) );
53 cout << "
Upper bound of 22: " << *( intMultiset.upper_bound( 22 ) );
54
55 // p represents pair of const_iterators
56 std::pair< Ims::const_iterator, Ims::const_iterator > p;
57
58 // use equal_range to determine lower and upper bound
59 // of 22 in intMultiset
60 p = intMultiset.equal_range( 22 );
61
62 cout << "
equal_range of 22:" << "
Lower bound: "
63 << *( p.first ) << "
Upper bound: " << *( p.second );
64 cout << endl;
65 return 0;
66 } // end main
There are currently 0 values of 15 in the multiset
After inserts, there are 2 values of 15 in the multiset
Found value 15
Did not find value 20
After insert, intMultiset contains:
1 7 9 13 15 15 18 22 22 30 85 100
Lower bound of 22: 22
Upper bound of 22: 30
equal_range of 22:
Lower bound: 22
Upper bound: 30
Line 10 uses a typedef to create a new type name (alias) for a multiset of integers ordered in ascending order, using the function object less< int >. Ascending order is the default for a multiset, so std::less< int > can be omitted in line 10. This new type (Ims) is then used to instantiate an integer multiset object, intMultiset (line 19).
Good Programming Practice 20.1
Use typedefs to make code with long type names (such as multisets) easier to read.
The output statement in line 22 uses function count (available to all associative containers) to count the number of occurrences of the value 15 currently in the multiset.
Lines 25–26 use one of the three versions of function insert to add the value 15 to the multiset twice. A second version of insert takes an iterator and a value as arguments and begins the search for the insertion point from the iterator position specified. A third version of insert takes two iterators as arguments that specify a range of values to add to the multiset from another container.
Line 34 uses function find (available to all associative containers) to locate the value 15 in the multiset. Function find returns an iterator or a const_iterator pointing to the earliest location at which the value is found. If the value is not found, find returns an iterator or a const_iterator equal to the value returned by a call to end. Line 42 demonstrates this case.
Line 46 uses function insert to insert the elements of array a into the multiset. In line 48, the copy algorithm copies the elements of the multiset to the standard output. Note that the elements are displayed in ascending order.
Lines 52 and 53 use functions lower_bound and upper_bound (available in all associative containers) to locate the earliest occurrence of the value 22 in the multiset and the element after the last occurrence of the value 22 in the multiset. Both functions return iterators or const_iterators pointing to the appropriate location or the iterator returned by end if the value is not in the multiset.
Line 56 instantiates an instance of class pair called p. Objects of class pair are used to associate pairs of values. In this example, the contents of a pair are two const_iterators for our integer-based multiset. The purpose of p is to store the return value of multiset function equal_range that returns a pair containing the results of both a lower_bound and an upper_bound operation. Type pair contains two public data members called first and second.
Line 60 uses function equal_range to determine the lower_bound and upper_bound of 22 in the multiset. Line 63 uses p.first and p.second, respectively, to access the lower_bound and upper_bound. We dereferenced the iterators to output the values at the locations returned from equal_range.
The set associative container is used for fast storage and retrieval of unique keys. The implementation of a set is identical to that of a multiset, except that a set must have unique keys. Therefore, if an attempt is made to insert a duplicate key into a set, the duplicate is ignored; because this is the intended mathematical behavior of a set, we do not identify it as a common programming error. A set supports bidirectional iterators (but not random-access iterators). Figure 20.20 demonstrates a set of doubles. Header file <set> must be included to use class set.
Fig. 20.20 Standard Library set class template.
1 // Fig. 20.20: fig20_20.cpp
2 // Standard Library class set test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <set>
8
9 // define short name for set type used in this program
10 typedef std::set< double, std::less< double > > DoubleSet;
11
12 #include <algorithm>
13 #include <iterator> // ostream_iterator
14
15 int main()
16 {
17 const int SIZE = 5;
18 double a[ SIZE ] = { 2.1, 4.2, 9.5, 2.1, 3.7 };
19 DoubleSet doubleSet( a, a + SIZE );
20 std::ostream_iterator< double > output( cout, " " );
21
22 cout << "doubleSet contains: ";
23 std::copy( doubleSet.begin(), doubleSet.end(), output );
24
25 // p represents pair containing const_iterator and bool
26 std::pair< DoubleSet::const_iterator, bool > p;
27
28 // insert 13.8 in doubleSet; insert returns pair in which
29 // p.first represents location of 13.8 in doubleSet and
30 // p.second represents whether 13.8 was inserted
31 p = doubleSet.insert( 13.8 ); // value not in set
32 cout << "
" << *( p.first )
33 << ( p.second ? " was" : " was not" ) << " inserted";
34 cout << "
doubleSet contains: ";
35 std::copy( doubleSet.begin(), doubleSet.end(), output );
36
37 // insert 9.5 in doubleSet
38 p = doubleSet.insert( 9.5 ); // value already in set
39 cout << "
" << *( p.first )
40 << ( p.second ? " was" : " was not" ) << " inserted";
41 cout << "
doubleSet contains: ";
42 std::copy( doubleSet.begin(), doubleSet.end(), output );
doubleSet contains: 2.1 3.7 4.2 9.5
13.8 was inserted
doubleSet contains: 2.1 3.7 4.2 9.5 13.8
9.5 was not inserted
doubleSet contains: 2.1 3.7 4.2 9.5 13.8
Line 10 uses typedef to create a new type name (DoubleSet) for a set of double values ordered in ascending order, using the function object less< double >.
Line 19 uses the new type DoubleSet to instantiate object doubleSet. The constructor call takes the elements in array a between a and a + SIZE (i.e., the entire array) and inserts them into the set. Line 23 uses algorithm copy to output the contents of the set. Notice that the value 2.1—which appeared twice in array a—appears only once in doubleSet. This is because container set does not allow duplicates.
Line 26 defines a pair consisting of a const_iterator for a DoubleSet and a bool value. This object stores the result of a call to set function insert.
Line 31 uses function insert to place the value 13.8 in the set. The returned pair, p, contains an iterator p.first pointing to the value 13.8 in the set and a bool value that is true if the value was inserted and false if the value was not inserted (because it was already in the set). In this case, 13.8 was not in the set, so it was inserted. Line 38 attempts to insert 9.5, which is already in the set. The output of lines 39–40 shows that 9.5 was not inserted.
The multimap associative container is used for fast storage and retrieval of keys and associated values (often called key/value pairs). Many of the functions used with multisets and sets are also used with multimaps and maps. The elements of multimaps and maps are pairs of keys and values instead of individual values. When inserting into a multimap or map, a pair object that contains the key and the value is used. The ordering of the keys is determined by a comparator function object. For example, in a multimap that uses integers as the key type, keys can be sorted in ascending order by ordering them with comparator function object less< int >. Duplicate keys are allowed in a multimap, so multiple values can be associated with a single key. This is often called a one-to-many relationship. For example, in a credit-card transaction-processing system, one credit-card account can have many associated transactions; in a university, one student can take many courses, and one professor can teach many students; in the military, one rank (like “private”) has many people. A multimap supports bidirectional iterators, but not random-access iterators. Figure 20.21 demonstrates the multimap associative container. Header file <map> must be included to use class multimap.
Fig. 20.21 Standard Library multimap class template.
1 // Fig. 20.21: fig20_21.cpp
2 // Standard Library class multimap test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <map> // map class-template definition
8
9 // define short name for multimap type used in this program
10 typedef std::multimap< int, double, std::less< int > > Mmid;
11
12 int main()
13 {
14 Mmid pairs; // declare the multimap pairs
15
16 cout << "There are currently " << pairs.count( 15 )
17 << " pairs with key 15 in the multimap
";
18
19 // insert two value_type objects in pairs
20 pairs.insert( Mmid::value_type( 15, 2.7 ) );
21 pairs.insert( Mmid::value_type( 15, 99.3 ) );
22
23 cout << "After inserts, there are " << pairs.count( 15 )
24 << " pairs with key 15
";
25
26 // insert five value_type objects in pairs
27 pairs.insert( Mmid::value_type( 30, 111.11 ) );
28 pairs.insert( Mmid::value_type( 10, 22.22 ) );
29 pairs.insert( Mmid::value_type( 25, 33.333 ) );
30 pairs.insert( Mmid::value_type( 20, 9.345 ) );
31 pairs.insert( Mmid::value_type( 5, 77.54 ) );
32
33 cout << "Multimap pairs contains:
Key Value
";
34
35 // use const_iterator to walk through elements of pairs
36 for ( Mmid::const_iterator iter = pairs.begin();
37 iter != pairs.end(); ++iter )
38 cout << iter->first << ' ' << iter->second << '
';
39
40 cout << endl;
41 return 0;
42 } // end main
There are currently 0 pairs with key 15 in the multimap
After inserts, there are 2 pairs with key 15
Multimap pairs contains:
Key Value
5 77.54
10 22.22
15 2.7
15 99.3
20 9.345
25 33.333
30 111.11
Performance Tip 20.15
A multimap is implemented to efficiently locate all values paired with a given key.
Line 10 uses typedef to define alias Mmid for a multimap type in which the key type is int, the type of a key’s associated value is double and the elements are ordered in ascending order. Line 14 uses the new type to instantiate a multimap called pairs. Line 16 uses function count to determine the number of key/value pairs with a key of 15.
Line 20 uses function insert to add a new key/value pair to the multimap. The expression Mmid::value_type( 15, 2.7 ) creates a pair object in which first is the key (15) of type int and second is the value (2.7) of type double. The type Mmid::value_type is defined as part of the typedef for the multimap. Line 21 inserts another pair object with the key 15 and the value 99.3. Then lines 23–24 output the number of pairs with key 15.
Lines 27–31 insert five additional pairs into the multimap. The for statement in lines 36–38 outputs the contents of the multimap, including both keys and values. Line 38 uses the const_iterator called iter to access the members of the pair in each element of the multimap. Notice in the output that the keys appear in ascending order.
The map associative container performs fast storage and retrieval of unique keys and associated values. Duplicate keys are not allowed—a single value can be associated with each key. This is called a one-to-one mapping. For example, a company that uses unique employee numbers, such as 100, 200 and 300, might have a map that associates employee numbers with their telephone extensions—4321, 4115 and 5217, respectively. With a map you specify the key and get back the associated data quickly. A map is also known as an associative array. Providing the key in a map’s subscript operator [] locates the value associated with that key in the map. Insertions and deletions can be made anywhere in a map.
Figure 20.22 demonstrates the map associative container and uses the same features as Fig. 20.21 to demonstrate the subscript operator. Header file <map> must be included to
Fig. 20.22 Standard Library map class template.
1 // Fig. 20.22: fig20_22.cpp
2 // Standard Library class map test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <map> // map class-template definition
8
9 // define short name for map type used in this program
10 typedef std::map< int, double, std::less< int > > Mid;
11
12 int main()
13 {
14 Mid pairs;
15
16 // insert eight value_type objects in pairs
17 pairs.insert( Mid::value_type( 15, 2.7 ) );
18 pairs.insert( Mid::value_type( 30, 111.11 ) );
19 pairs.insert( Mid::value_type( 5, 1010.1 ) );
20 pairs.insert( Mid::value_type( 10, 22.22 ) );
21 pairs.insert( Mid::value_type( 25, 33.333 ) );
22 pairs.insert( Mid::value_type( 5, 77.54 ) ); // dup ignored
23 pairs.insert( Mid::value_type( 20, 9.345 ) );
24 pairs.insert( Mid::value_type( 15, 99.3 ) ); // dup ignored
25
26 cout << "pairs contains:
Key Value
";
27
28 // use const_iterator to walk through elements of pairs
29 for ( Mid::const_iterator iter = pairs.begin();
30 iter != pairs.end(); ++iter )
31 cout << iter->first << ' ' << iter->second << '
';
32
33 pairs[ 25 ] = 9999.99; // use subscripting to change value for key 25
34 pairs[ 40 ] = 8765.43; // use subscripting to insert value for key 40
35
36 cout << "
After subscript operations, pairs contains:
Key Value
";
37
38 // use const_iterator to walk through elements of pairs
39 for ( Mid::const_iterator iter2 = pairs.begin();
40 iter2 != pairs.end(); ++iter2 )
41 cout << iter2->first << ' ' << iter2->second << '
';
42
43 cout << endl;
44 return 0;
45 } // end main
pairs contains:
Key Value
5 1010.1
10 22.22
15 2.7
20 9.345
25 33.333
30 111.11
After subscript operations, pairs contains:
Key Value
5 1010.1
10 22.22
15 2.7
20 9.345
25 9999.99
30 111.11
40 8765.43
use class map. Lines 33—34 use the subscript operator of class map. When the subscript is a key that is already in the map (line 33), the operator returns a reference to the associated value. When the subscript is a key that is not in the map (line 34), the operator inserts the key in the map and returns a reference that can be used to associate a value with that key. Line 33 replaces the value for the key 25 (previously 33.333 as specified in line 21) with a new value, 9999.99. Line 34 inserts a new key/value pair in the map (called creating an association).
The STL provides three container adapters—stack, queue and priority_queue. Adapters are not first-class containers, because they do not provide the actual data-structure implementation in which elements can be stored and because adapters do not support iterators. The benefit of an adapter class is that you can choose an appropriate underlying data structure. All three adapter classes provide member functions push and pop that properly insert an element into each adapter data structure and properly remove an element from each adapter data structure. The next several subsections provide examples of the adapter classes.
Class stack enables insertions into and deletions from the underlying data structure at one end (commonly referred to as a last-in, first-out data structure). A stack can be implemented with any of the sequence containers: vector, list and deque. This example creates three integer stacks, using each of the sequence containers of the Standard Library as the underlying data structure to represent the stack. By default, a stack is implemented with a deque. The stack operations are push to insert an element at the top of the stack (implemented by calling function push_back of the underlying container), pop to remove the top element of the stack (implemented by calling function pop_back of the underlying container), top to get a reference to the top element of the stack (implemented by calling function back of the underlying container), empty to determine whether the stack is empty (implemented by calling function empty of the underlying container) and size to get the number of elements in the stack (implemented by calling function size of the underlying container).
Performance Tip 20.16
Each of the common operations of a stack is implemented as an inline function that calls the appropriate function of the underlying container. This avoids the overhead of a second function call.
Performance Tip 20.17
For the best performance, use class vector as the underlying container for a stack.
Figure 20.23 demonstrates the stack adapter class. Header file <stack> must be included to use class stack.
Fig. 20.23 Standard Library stack adapter class.
1 // Fig. 20.23: fig20_23.cpp
2 // Standard Library adapter stack test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <stack> // stack adapter definition
8 #include <vector> // vector class-template definition
9 #include <list> // list class-template definition
10
11 // pushElements function-template prototype
12 template< typename T > void pushElements( T &stackRef );
13
14 // popElements function-template prototype
15 template< typename T > void popElements( T &stackRef );
16
17 int main()
18 {
19 // stack with default underlying deque
20 std::stack< int > intDequeStack;
21
22 // stack with underlying vector
23 std::stack< int, std::vector< int > > intVectorStack;
24
25 // stack with underlying list
26 std::stack< int, std::list< int > > intListStack;
27
28 // push the values 0-9 onto each stack
29 cout << "Pushing onto intDequeStack: " ;
30 pushElements( intDequeStack );
31 cout << "
Pushing onto intVectorStack: ";
32 pushElements( intVectorStack );
33 cout << "
Pushing onto intListStack: ";
34 pushElements( intListStack );
35 cout << endl << endl;
36
37 // display and remove elements from each stack
38 cout << "Popping from intDequeStack: ";
39 popElements( intDequeStack );
40 cout << "
Popping from intVectorStack: ";
41 popElements( intVectorStack );
42 cout << "
Popping from intListStack: ";
43 popElements( intListStack );
44 cout << endl;
45 return 0;
46 } // end main
47
48 // push elements onto stack object to which stackRef refers
49 template< typename T > void pushElements( T &stackRef )
50 {
51 for ( int i = 0; i < 10; i++ )
52 {
53 stackRef.push( i ); // push element onto stack
54 cout << stackRef.top() << ' '; // view (and display) top element
55 } // end for
56 } // end function pushElements
57
58 // pop elements from stack object to which stackRef refers
59 template< typename T > void popElements( T &stackRef )
60 {
61 while ( !stackRef.empty() )
62 {
63 cout << stackRef.top() << ' '; // view (and display) top element
64 stackRef.pop(); // remove top element
65 } // end while
66 } // end function popElements
Pushing onto intDequeStack: 0 1 2 3 4 5 6 7 8 9
Pushing onto intVectorStack: 0 1 2 3 4 5 6 7 8 9
Pushing onto intListStack: 0 1 2 3 4 5 6 7 8 9
Popping from intDequeStack: 9 8 7 6 5 4 3 2 1 0
Popping from intVectorStack: 9 8 7 6 5 4 3 2 1 0
Popping from intListStack: 9 8 7 6 5 4 3 2 1 0
Lines 20, 23 and 26 instantiate three integer stacks. Line 20 specifies a stack of integers that uses the default deque container as its underlying data structure. Line 23 specifies a stack of integers that uses a vector of integers as its underlying data structure. Line 26 specifies a stack of integers that uses a list of integers as its underlying data structure.
Function pushElements (lines 49–56) pushes the elements onto each stack. Line 53 uses function push (available in each adapter class) to place an integer on top of the stack. Line 54 uses stack function top to retrieve the top element of the stack for output. Function top does not remove the top element.
Function popElements (lines 59–66) pops the elements off each stack. Line 63 uses stack function top to retrieve the top element of the stack for output. Line 64 uses function pop (available in each adapter class) to remove the top element of the stack. Function pop does not return a value.
Class queue enables insertions at the back of the underlying data structure and deletions from the front (commonly referred to as a first-in, first-out data structure). A queue can be implemented with STL data structure list or deque. By default, a queue is implemented with a deque. The common queue operations are push to insert an element at the back of the queue (implemented by calling function push_back of the underlying container), pop to remove the element at the front of the queue (implemented by calling function pop_front of the underlying container), front to get a reference to the first element in the queue (implemented by calling function front of the underlying container), back to get a reference to the last element in the queue (implemented by calling function back of the underlying container), empty to determine whether the queue is empty (implemented by calling function empty of the underlying container) and size to get the number of elements in the queue (implemented by calling function size of the underlying container).
Performance Tip 20.18
Each of the common operations of a queue is implemented as an inline function that calls the appropriate function of the underlying container. This avoids the overhead of a second function call.
Performance Tip 20.19
For the best performance, use class deque as the underlying container for a queue.
Figure 20.24 demonstrates the queue adapter class. Header file <queue> must be included to use a queue.
Fig. 20.24 Standard Library queue adapter class templates.
1 // Fig. 20.24: fig20_24.cpp
2 // Standard Library adapter queue test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <queue> // queue adapter definition
8
9 int main()
10 {
11 std::queue< double > values; // queue with doubles
12
13 // push elements onto queue values
14 values.push( 3.2 );
15 values.push( 9.8 );
16 values.push( 5.4 );
17
18 cout << "Popping from values: ";
19
20 // pop elements from queue
21 while ( !values.empty() )
22 {
23 cout << values.front() << ' '; // view front element
24 values.pop(); // remove element
25 } // end while
26
27 cout << endl;
28 return 0;
29 } // end main
Popping from values: 3.2 9.8 5.4
Line 11 instantiates a queue that stores double values. Lines 14–16 use function push to add elements to the queue. The while statement in lines 21–25 uses function empty (available in all containers) to determine whether the queue is empty (line 21). While there are more elements in the queue, line 23 uses queue function front to read (but not remove) the first element in the queue for output. Line 24 removes the first element in the queue with function pop (available in all adapter classes).
Class priority_queue provides functionality that enables insertions in sorted order into the underlying data structure and deletions from the front of the underlying data structure. A priority_queue can be implemented with STL sequence containers vector or deque. By default, a priority_queue is implemented with a vector as the underlying container. When elements are added to a priority_queue, they are inserted in priority order, such that the highest-priority element (i.e., the largest value) will be the first element removed from the priority_queue. This is usually accomplished via a sorting technique called heapsort that always maintains the largest value (i.e., highest-priority element) at the front of the data structure—such a data structure is called a heap. The comparison of elements is performed with comparator function object less< T > by default, but you can supply a different comparator.
There are several common priority_queue operations. push inserts an element at the appropriate location based on priority order of the priority_queue (implemented by calling function push_back of the underlying container, then reordering the elements using heapsort). pop removes the highest-priority element of the priority_queue (implemented by calling function pop_back of the underlying container after removing the top element of the heap). top gets a reference to the top element of the priority_queue (implemented by calling function front of the underlying container). empty determines whether the priority_queue is empty (implemented by calling function empty of the underlying container). size gets the number of elements in the priority_queue (implemented by calling function size of the underlying container).
Performance Tip 20.20
Each of the common operations of a priority_queue is implemented as an inline function that calls the appropriate function of the underlying container. This avoids the overhead of a second function call.
Performance Tip 20.21
For the best performance, use class vector as the underlying container for a priority_queue.
Figure 20.25 demonstrates the priority_queue adapter class. Header file <queue> must be included to use class priority_queue.
Fig. 20.25 Standard Library priority_queue adapter class.
1 // Fig. 20.25: fig20_25.cpp
2 // Standard Library adapter priority_queue test program.
3 #include <iostream>
4 using std::cout;
5 using std::endl;
6
7 #include <queue> // priority_queue adapter definition
8
9 int main()
10 {
11 std::priority_queue< double > priorities; // create priority_queue
12
13 // push elements onto priorities
14 priorities.push( 3.2 );
15 priorities.push( 9.8 );
16 priorities.push( 5.4 );
17
18 cout << "Popping from priorities: ";
19
20 // pop element from priority_queue
21 while ( !priorities.empty() )
22 {
23 cout << priorities.top() << ' '; // view top element
24 priorities.pop(); // remove top element
25 } // end while
26
27 cout << endl;
28 return 0;
29 } // end main
Popping from priorities: 9.8 5.4 3.2
Line 11 instantiates a priority_queue that stores double values and uses a vector as the underlying data structure. Lines 14–16 use function push to add elements to the priority_queue. The while statement in lines 21–25 uses function empty (available in all containers) to determine whether the priority_queue is empty (line 21). While there are more elements, line 23 uses priority_queue function top to retrieve the highest-priority element in the priority_queue for output. Line 24 removes the highest-priority element in the priority_queue with function pop (available in all adapter classes).
Until the STL, class libraries of containers and algorithms were essentially incompatible among vendors. Early container libraries generally used inheritance and polymorphism, with the associated overhead of virtual function calls. Early libraries built the algorithms into the container classes as class behaviors. The STL separates the algorithms from the containers. This makes it much easier to add new algorithms. With the STL, the elements of containers are accessed through iterators. The next several subsections demonstrate many of the STL algorithms.
Performance Tip 20.22
The STL is implemented for efficiency. It avoids the overhead of virtual function calls.
Software Engineering Observation 20.8
STL algorithms do not depend on the implementation details of the containers on which they operate. As long as the container’s (or array’s) iterators satisfy the requirements of the algorithm, STL algorithms can work on C-style, pointer-based arrays, on STL containers and on user-defined data structures.