
Chapter 34. COM and ActiveX
FAQ 34.01 Who should read this chapter?
![]()
Developers who are wondering about COM and ActiveX and how to take advantage of them.
The purpose of this chapter is to provide C++ developers with an introduction to COM and ActiveX. Long-time Unix developers will want to read it to get an overview of COM and ActiveX and the role they play in building C++ applications for Windows. Windows developers who have not taken the COM plunge will want to read this chapter to see how they can exploit COM and ActiveX to build reusable components that are easy to share in the Windows environment.
FAQ 34.02 What is the Component Object Model?
![]()
The Component Object Model (COM) is the Windows standard that defines—at the most fundamental level—what components are, how they are identified, how they are located, how they are loaded, how they are accessed, and how they communicate. COM is the most widely used component model in the world.
In this context, components are reusable chunks of software with well-defined interfaces and encapsulated implementations, are defined in a language-independent manner, and are distributed in binary form.
To better understand COM, it is crucial to bear in mind that it is not an object-oriented language but rather a standard for defining components (however, the components are often referred to as objects). C++ is a programming language with a compiler. COM is a set of programming conventions. Therefore, many of the things that the C++ compiler does automatically COM requires the programmer to do manually. For example, the C++ compiler/linker can guarantee that all class names are unique. COM, on the other hand, relies on a mechanism that generates unique class names (called Class Identifiers; see FAQ 34.08) independent of any compile time or link time checks.
COM is language independent in that it does not prescribe any particular programming language for either developing or using COM classes. COM provides location transparency in that it allows callers to create and access COM objects without regard for where the objects are running (whether they are in the same process or in other processes or even on remote machines).
COM has survived and is thriving due to the growing interest in component technology. COM is important because it is the core technology on which all other ActiveX and OLE technologies are built. And understanding COM is the key to understanding and effectively exploiting all the other ActiveX and OLE technologies.
FAQ 34.03 What are ActiveX and OLE?
![]()
In the beginning, OLE stood for Object Linking and Embedding. OLE2 was an umbrella term that covered a family of Microsoft technologies for building software components and linking applications:
• Component Object Model (COM), Structured Storage
• Uniform Data Transfer, Drag and Drop
• Error Reporting and Exception Handling
• OLE Automation
• OLE Compound Documents
• OLE Custom Controls (OCXs)
At the time OLE was popular, the future of the desktop computer was GUIs and compound documents. You might even remember that OLE and OpenDoc (from IBM and Apple) were jousting to see who would rule the compound document kingdom.
Well, since that time, the Internet and the World Wide Web have replaced compound documents as the future of desktop computing, and ActiveX (which is web-centric) has replaced OLE (which is compound-document-centric) as the marketing buzzword du jour. OLE still exists, but these days its meaning is restricted to compound document technology.
ActiveX is a loosely defined umbrella term Microsoft uses to refer to a number of initiatives and technologies related to (but not limited to) the Web/Internet and Microsoft's component strategy. The important thing to remember is that ActiveX is a marketing term whose meaning can (and does) shift as it suits the suits in Redmond.
The aspects of ActiveX discussed in this book are those that are related to Microsoft's component strategy. This chapter does not try to explain and justify the numerous ambiguities surrounding ActiveX—call your local Microsoft representatives and ask them for an explanation.
FAQ 34.04 What does the name Component Object Model mean?
![]()
Microsoft's component architecture.
Component:Refers to the fact that COM defines reusable chunks of software in a language-independent manner according to a binary object model.
Object:Refers to the fact that the software components being defined resemble objects in the sense that they have a well-defined interface that encapsulates the implementation and allows multiple instances to be created and used.
Model:Refers to the fact that COM is primarily a specification (rather than an implementation) of how to build and use component objects.
COM provides a way of defining components in a way that is more or less language independent, location independent, operating system independent, and hardware independent.
By the way, there is an equally valid and less grandiose way of looking at COM. COM can be viewed simply as a packaging technology that consists of a set of conventions and supporting libraries that allow chunks of software to locate one another and interact in an object-oriented manner. It is sometimes worthwhile to remember this, since it helps to explain why COM is the way it is.
FAQ 34.05 What is a “binary object model”?
![]()
Component architecture defined at the machine level.
COM is called a binary object model because the COM specification defines how objects are laid out in memory (hence binary). This permits any programming language or any development tool to create a COM object as long as it is capable of laying out the memory in a manner that conforms with the COM specification and calling the appropriate COM routines.
Compare this to an object-oriented language, like C++, which defines classes and objects using a language object model. Specifically, C++ defines what constitutes a legal class definition in terms of the syntax and semantics of a programming language and then leaves it up to the compiler to translate the source code into an executable program.
In reality, COM is not Windows-specific; there are COM implementations for other operating systems (in particular, Software AG has ported COM/DCOM to Sun Solaris, 64-bit Digital Unix, and IBM's OS 390), but COM was designed with Windows as its first and foremost priority.
FAQ 34.06 What are the key features of COM?
![]()
Language transparency, location transparency, program to the interface rather than to the implementation, unique naming of classes and interfaces, meta data, and a system registry.
Language transparency: COM defines object interfaces in a manner that is independent of any particular programming language. This means that a caller can use a COM object without knowing or caring what programming language it is implemented in. Conversely, the COM class can be implemented in a variety of programming languages without concern for what programming language will be used by callers.
Location transparency: COM provides the infrastructure so that callers can create and access COM objects no matter whether the COM object is running in the caller's process as an in-process object or running in another process on the same computer or running remotely on another computer.
Interface definition: A COM interface is a set of related methods that have a well-defined contract but no implementation (see FAQ 34.09). The signatures for the methods of a COM interface can be defined using a programming language (such as C++ and C) or the Microsoft Interface Definition Language (MIDL), which is based on the Distributed Computing Environment Interface Definition Language (DCE IDL) specification of the Open Software Foundation.
Unique Naming of Classes and Interfaces: COM classes and interfaces have unique “names” called globally unique identifiers (GUIDs; see FAQ 34.07). Unique names are required so that the names of components being developed by different groups in different organizations and in different parts of the world do not accidentally clash.
Meta data: COM provides support for meta data (that is, information about interfaces and classes) in the form of type libraries (see FAQ 34.29). Type libraries contain machine-readable definitions of COM interfaces and/or COM classes and can be accessed programmatically at runtime.
System Registry: COM stores static information about classes, interfaces, and type libraries in a registry so that it can be looked up at runtime. The information in the registry can be accessed prior to any objects being created. In fact, the registry contains the information necessary for loading COM servers (see FAQ 34.12), locating class objects, and creating COM objects. The registry is a hierarchy of key/value pairs and contains information such as the name of the file containing a COM class and the name of the file that contains a type library that defines a particular COM interface.
FAQ 34.07 What are GUIDs?
![]()
Unique names that are about as user friendly as a bar code.
Globally Unique Identifiers (GUIDs) are 128-bit, globally unique identifiers (in this context, “globally” literally means globally).
GUIDs are based on the universally unique identifiers developed and used by OSF for DCE. COM uses GUIDs for several purposes but the two most important are Class Identifiers and Interface Identifiers. Class Identifiers (CLSIDs) are used to give COM classes unique class names. Similarly, Interface Identifiers (IIDs) are used to give unique names to COM interfaces.
Since GUIDs identify COM classes and COM interfaces, they are part of the definition of the class or interface and must be available to the calling program. This is usually done by distributing the GUIDs in header files and/or Type Libraries.
Although GUIDs are 128-bit numbers, they are usually referred to using mnemonics (i.e., symbolic names). Hey, look, there are a couple of GUIDs going by right now.

This defines two GUIDs using the COM macro DEFINE_GUID. The macro has several parameters—the first parameter defines the mnemonic for the GUID and the remaining parameters define the 128-bit number (the numbers can be generated using the COM utility program guidgen.exe).
The first GUID defines an interface identifier called IID_IStack for the COM interface IStack. The second GUID defines a class identifier called CLSID_CoStack for the COM class CoStack. After these definitions, the GUIDs can be referred to using IID_IStack and CLSID_CoStack without having to write out the 128-bit number.
COM uses class identifiers in the same way C++ uses class names. For example, when a caller wishes to create a COM object, it specifies the CLSID for the COM class and COM uses this CLSID to locate and create the correct type of COM object.
Besides class identifiers and interface identifiers, COM defines several other types of GUIDs including Type Library Identifiers (LIBIDs) and Category Identifiers (CATIDs).
FAQ 34.08 Why does COM need GUIDs (and CLSIDs and IIDs)?
![]()
To uniquely identify software components.
In C++, classes have names and the name of a class must be unique in the context of a linked program (otherwise the compiler or the linker will detect the duplicate names and report an error). Namespaces have been added to C++ to reduce the chances of name conflicts, but they don't eliminate the possibility of name conflicts. If there are name conflicts, you have to come up with some way to make all the class names unique before you can get your program to compile and link.
The situation is slightly more complex with COM. With COM, you have thousands of developers working around the world and defining thousands of components that are delivered to users as binary components. Imagine if COM used nice short text names (like C++ does) for class names and interface names. How many COM classes and COM interfaces, worldwide, do you think would be called String? List? Date? So, the chances of name clashes are high.
Furthermore, COM classes are delivered to you as binary components, so you can't modify them to resolve name conflicts. After all, what are you going to do? Edit the binary? That seems a little extreme. Or maybe you could call the vendor and have them change the name of the class and ship you a new version? That's impractical.
So the solution is to have names that are 128 bits long (giving a namespace of 2128 unique names) and to employ a method that makes sure that everyone generates different names. One of these methods is to have programmers use the utility program guidgen.exe to generate GUIDs. This program generates GUIDs based on unique information built into the network card of the computer. Another method is to call the COM routine CoCreateGuid to generate new GUIDs (there are some other methods we won't discuss here, but you get the general idea).
Of course these methods can be compromised, but in practice, the likelihood of two developers creating duplicate GUIDs is so small that no one worries about it.
FAQ 34.09 What is an interface?
![]()
Pure specification without any implementation.
A COM interface is a set of related methods that have a well-defined contract but have no implementation. A COM class implements one or more interfaces, and all the services a COM class exports are defined by the interfaces it implements. Callers access the services of a COM object by calling the methods defined by its interfaces. COM interfaces serve to decouple the caller's view of the services provided by a COM class from how the COM class implements those interfaces.
In C++ terms, an interface is an abstract class that defines a set of public, pure virtual functions and contains no data members. By convention, the names of COM interfaces begin with a capital I (for interface). The following interface is called IUnknown and it defines three methods—QueryInterface, AddRef, and Release (for more information on IUnknown, see FAQ 34.10).

COM interfaces and COM classes are distinct concepts, and COM interfaces are specified independently of any particular COM class and independently of any particular implementation of the interface. In this way, COM interfaces resemble Java interfaces. Unfortunately, C++ provides only one construct, the class, for representing classes and interfaces, and therefore a certain amount of programmer discipline is required when using C++ to achieve the same effect.
Once defined, a COM interface and its contract can never change. Thus, every implementation of the interface must satisfy the same contract no matter what programming language is used, no matter what operating system is used, no matter what data structures are used, and no matter what performance optimizations are performed. In this way, objects and their callers can work together even when they are implemented by different people using different tools and working in different organizations and who don't know or communicate with each other. In other words, COM interfaces are substitutable.
Notice that an interface cannot define concrete data members (whereas C++ permits data members to be declared in the class body). However, an interface can define get/set member functions, thus indicating that there is some abstract state that can be manipulated through the interface. The COM class that implements the interface is responsible for defining the concrete data members.
A key element of the COM standard is the binary specification of COM interfaces. A COM interface is an array of function pointers similar to the virtual function table generated by most C++ compilers. With COM interfaces, unlike C++ virtual function tables, the location of the interface pointer is not linked to the location of the object's data. COM makes the location of the COM object's data invisible to the caller in the interests of decoupling and guaranteeing language and location transparency. This separation of the interface from the concrete data promotes location transparency because it means that a COM interface can be accessed by a caller (through a proxy) even when the actual COM object (and the object's data) is located in another process.
Microsoft has defined a set of COM interfaces (usually referred to as the standard interfaces) that cover a wide range of services including object creation, memory allocation, structured storage, and compound documents, and more are being added all the time. You can define your own interfaces, too; these are referred to as custom interfaces.
FAQ 34.10 What is the IUnknown interface?
![]()
The IUnknown interface is the interface from which all other interfaces are derived. Here is the C++ definition of the IUnknown interface.

The IUnknown interface defines the following three methods.
QueryInterface:Allows the caller to dynamically discover whether a particular object supports a particular interface. The caller passes the IID of the interface it is looking for toQueryInterface(viariid, which is a reference to an IID), and if the COM object implements the specified interface,QueryInterfacereturns a pointer to it (viappv, which is a pointer to a pointer to a void); otherwise it returnsNULL.AddRef:Increments the reference count of a COM object, and the object uses this reference count to know when it can remove itself from memory.Release:Decrements the reference count of a COM object and causes the object to destroy itself when the reference count is reduced to zero.
The pervasive nature of this interface has a profound impact on COM.
First, a COM object that has multiple interfaces may have multiple implementations of the IUnknown interface. This is because each interface is derived from IUnknown and therefore might have its own implementation of IUnknown.
Second, all calls to QueryInterface for a single COM object must behave in the same manner at all times. For example, if at one point QueryInterface returns non-NULL when asked whether this COM object supports the IStack interface, then it must always return a valid interface pointer and cannot return NULL. As another example, suppose a caller has a pointer to one interface of a COM object and uses that interface pointer to call QueryInterface to ask if that object supports IStack. Then, all the other implementations of QueryInterface provided by all the other interfaces of the COM object must respond in the same manner (it would be illegal for some implementations of QueryInterface to return an interface pointer and for other implementations to return NULL).
Third, in a very loose sense, QueryInterface is similar to the RTTI mechanism of C++. It is the mechanism by which a caller gains access to the other services defined by an object.
Fourth, AddRef and Release point to the fact that the lifetimes of COM objects are controlled through reference counting. Thus, AddRef must be called whenever an interface pointer for a COM object is created or copied, and Release must be called whenever an interface pointer is destroyed (by the way, AddRef is called implicitly by CoCreateInstance() and QueryInterface()).
Fifth, the IID for IUnknown, is called IID_IUnknown, and it is defined in the COM header files since it is a standard interface defined by Microsoft.
FAQ 34.11 How many ways are there to specify COM interfaces?
![]()
For better or worse there are several ways to define a COM interface.
Suppose we want to define the interface IStack, which provides facilities for pushing and popping integers. One technique is to define the COM interface as a C++ abstract base class.
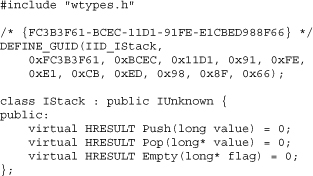
This technique would be the most familiar to C++ programmers. Notice how IStack is derived from IUnknown (all COM interfaces must be derived either directly or indirectly from IUnknown). The problem with this definition is that it is language specific and can't be used by callers written in other languages. Also you'd have to provide code for marshaling the parameters if the caller using IStack and the COM object implementing IStack were running in different processes.
Another technique is to define the interface using a set of COM-defined macros. This technique defines the interface in a manner that hides the differences between programming languages (e.g., C and C++) and operating systems (e.g., Windows and Macintosh).
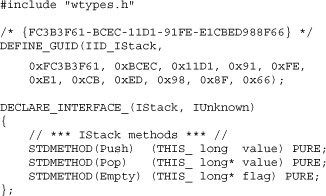
The tags such as DECLARE_INTERFACE_, STDMETHOD, THIS_, and PURE are COM macros that expand differently based on the operating system and programming language. This is a better approach than the pure C++ approach because it allows the same interface definition to be used in multiple environments without changes. But you'd still have to provide code for marshaling the parameters if the caller using IStack and the COM object implementing IStack were running in different processes.
A third technique is to define the interface using the Microsoft Interface Definition Language (MIDL). MIDL allows interfaces to be defined in a language-independent manner. MIDL is based on DCE's IDL syntax and includes extensions to support COM programming. MIDL is used for defining COM interfaces, defining what interfaces a COM class implements (see FAQ 34.12), defining dispatch interfaces (see FAQ 34.25), and generating type libraries (see FAQ 34.29). Here is the MIDL definition of the IStack interface.

MDL has some major advantages.
• MIDL is language independent.
• MIDL clearly separates interface from implementation.
• MIDL provides Microsoft-specific features that are not found in other IDLs.
• The MIDL compiler can automatically generate proxies and stubs (see FAQ 34.15 for more information regarding proxies and stubs) capable of marshaling parameters across process boundaries. More specifically, for a caller running in one process to talk to a COM object in another process, the COM communication layer needs to understand the exact size and nature of the data involved in the interprocess communication. COM provides built-in support for marshaling standard interfaces (such as IUnknown). However, no such built-in support exists for custom interfaces (such as IStack). By defining a COM interface using MIDL and compiling it with the MIDL compiler, you get source code for a proxy/stub DLL as a by-product. The communication layer uses this proxy/stub pair to marshal parameters between objects and their callers.
MIDL also has some limitations, including the fact that it is relatively complex, all out parameters must be pointers (which is an issue only for programmers and programming languages who are pointer challenged), function name overloading is not supported, and the return type for methods in object interfaces must be an HRESULT (although methods can return any number of results by defining one or more parameters as out parameters or in/out parameters).
Define interfaces using MIDL when possible: it is the most general and the easiest to work with.
FAQ 34.12 What are COM classes and COM objects?
![]()
The concrete implementation of one or more COM interfaces.
A COM class is a body of code that implements all the functions of at least one COM interface. Every COM class has a unique CLSID and callers use the unique CLSID when they want to create objects that are instances of the COM class.
In the following example, the COM class CoStack implements the IUnknown interface and the IStack interface. The following code fragment declares the external interface including the CLSID for CoStack, the IStack interface, and the IID for the IStack interface.
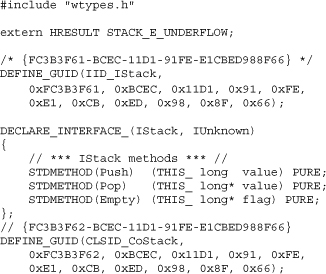
Class CoStack declares all the methods of the IUnknown interface (by the way, ULONG is a typedef for unsigned long) and the IStack interface. It also declares two private data members—refCnt_ is used to implement reference counting for the object and data_ is the data structure used to hold the elements of the stack.

Note that class CoStack has a constructor even though the COM specification does not define constructors for COM classes. In this case, the implementation is taking advantage of a C++ feature. In particular, the C++ constructor initializes the data structures of the C++ object, which happens to initialize the data structures of the COM object at the same time. The lesson here is that class CoStack is a mix of COM features and C++ features, and sometimes it is hard to tell them apart.
The COM class implements the three methods of the IUnknown interface. QueryInterface tests to see if the caller is requesting one of the two interfaces that this class implements. If the caller is requesting a legitimate interface for this class, QueryInterface returns a pointer to that interface; otherwise, it returns NULL. Notice that QueryInterface copies an interface pointer so that it calls AddRef. AddRef increments the reference count for this object. Release decrements the reference count and destroys the object if the reference count is zero.

The COM class also implements the methods of the IStack interface. These all look pretty normal except for the fact that the return values for the methods are status codes (S_OK if the call succeeds, STACK_E_UNDERFLOW if an underflow condition is detected).

Every COM class has a class object that acts as the meta class for the COM class. The most important function that the class object plays is that it provides the class factory for its COM class by implementing the IClassFactory interface (or the IClassFactory2 interface). Here is the class object for class CoStack (some details have been left out of this example code).

The class object is registered in the system registry (see FAQ 34.06) and is used during object creation. Callers create COM objects by calling the API function CoGetClassObject, obtaining a pointer to the class object's IClassFactory interface, and calling CreateInstance (callers may also call CoCreateInstance, which is a helper function that performs this series of actions).
Every COM class and its class object live within a COM server (on Windows this means either a DLL or an EXE), which contains the executable code that implements the class and the class object. When the COM server is a DLL, COM locates and loads the DLL when the caller creates the first object of any class that lives within the server. When the COM server is an EXE, COM locates and runs the EXE when the caller creates the first object of any class that lives within the server.
Most COM classes implement more than one interface. Typically this is done in C++ using nested classes or multiple inheritance. For details, refer to a book dedicated to COM.
FAQ 34.13 How hard is it for callers to create and use a COM object?
![]()
Not that hard. To create and use a COM object, a caller needs to
• Include the external interface of the COM class. In this case the caller declares the IID for the IStack interface, the CLSID for CoStack, and the IStack interface. Usually all these declarations are provided by the writer of the COM class in an include file.
• Create the object (line 1). The program calls CoCreateInstance passing it the class identifier for the COM class that is being created (CLSID_CoStack in this case), the interface identifier for IUnknown (IID_IUnknown), and a pointer to an interface pointer (&unknownPtr in this case), which CoCreateInstance uses to return a pointer to the IUnknown interface for the newly created object.
• Query the object for one or more of its interfaces (line 2). The program calls QueryInterface passing it the interface identifier for the interface it wants access to (IID_IStack in this case) and a pointer to an interface pointer (&stackPtr in this case), which QueryInterface uses to return a pointer to the requested interface for the object (the interface pointer is NULL if the object does not support the requested interface).
• Use the services provided by the interface (lines 3 and 4). The program calls the Push and Pop methods of the IStack interface using the interface pointer returned by QueryInterface.
• Release the object (lines 5 and 6). The program holds two interface pointers for the Stack object (stackPtr and unknownPtr in this case), and therefore it calls Release once for each interface pointer it holds.

The caller must take a couple of steps to initialize COM and signal when it is finished using COM:
- Initialize COM (line 7). The program loads the COM libraries by calling
CoInitialize. - Uninitialize COM (line 8). The program unloads the COM libraries by calling
CoUninitialize.

Of course, there are a zillion details that we don't have space to go into here.
FAQ 34.14 How does COM provide language transparency?
![]()
The COM binary object model.
COM is language independent due to its binary specification of how COM classes and interfaces are laid out in memory. For example, the binary definition of an interface is a pointer to a table of function pointers.
Thus, even though the examples use C++ to define the IUnknown and IStack interfaces, the key step is for the C++ compiler to turn the C++ class definitions into a pointer to a table of function pointers (or a virtual function table).
This binary definition of classes and interfaces makes it possible for any language that can create the correct memory structures to define COM classes and interfaces. For example, the C language can define a COM interface using structs and pointers to functions; many other languages use similar features. Languages that cannot build these constructs cannot be used for defining COM classes.
This binary specification also means that a COM class can be used by any programming language that can call functions using a function pointer. Clearly, C++ and C are capable of this trick.
All this makes C++ a natural programming language for defining and using COM classes since C++ compilers are capable of automatically constructing the virtual function tables (so that the programmer does not have to lay them out by hand) and calling functions through virtual function tables.
Of course, other programming languages and development environments can automate the definition of COM classes in the same way. For instance, Visual Basic can be used for creating COM classes since the Visual Basic development environment can interpret the Visual Basic code and emit the correct interface declarations, class declarations, MIDL code, and so on.
FAQ 34.15 How does COM provide location transparency?
![]()
Proxies and stubs.
COM provides location transparency because a caller can use a COM object without knowing or caring where the object is running. The object could be running in the same process or in another process running on the same machine or in another process running on another machine (this is where Distributed COM comes into play; see FAQ 34.39).
COM facilitates location transparency by defining an architecture that uses proxies and stubs for linking callers to COM objects in a location-transparent manner and marshaling parameters between callers and objects. A proxy is an object that runs in the caller's address space and serves as a surrogate for the actual object. The proxy has an interface that is identical to the interface of the actual object. Stubs are objects that run in the server process where a COM object is running and handle all member function calls coming from other processes.
During execution, when a caller creates a COM object in another process, the COM runtime system also creates a proxy for the just created object in the caller's address space and a stub object in the server process. The caller is then given an interface pointer to the corresponding interface on the proxy object. When the caller calls a member function using this interface pointer, the proxy object transmits the parameters to the stub object, which makes the actual call on the corresponding interface of the actual COM object. Similarly, any results are returned from the COM object to the stub object, which transmits them to the proxy object, which returns them to the calling program.
Marshaling refers to the transmission of parameters from the caller to the object and the transmission of return values back again along with conversion of the parameters and return values, as necessary. There are two types of marshaling. Standard marshaling is provided by COM, and it is provided, by default, for all standard interfaces. Custom marshaling is defined by programmers for situations that standard marshaling does not cover (e.g., marshal a data type that the standard marshaler doesn't understand) and for performing optimizations that standard marshaling does not support.
This architecture defines the roles and responsibilities of the proxies and stubs and defines how they are created and destroyed and how parameters are marshaled between the caller and the COM object. Proxies and stubs can also come into play when the caller and the object are running on separate threads in the same process. Except for highly specialized situations, proxies and stubs are invisible to programmers and can be ignored.
FAQ 34.16 What types of errors occur due to reference counting?
![]()
Reference counting is a powerful mechanism, but it can lead to errors that are extremely hard to detect.
First, a caller might call AddRef too often or forget to call Release. In this case, there is a memory leak since the COM object never knows when to destroy itself.
Second, a caller might call Release too often. In this case, the reference count of the COM object is reduced to zero prematurely, and the COM object destroys itself leaving a dangling pointer since other callers have interface pointers to the COM object.
Reference counting is made more complicated by performance optimizations. For example, sometimes it is not necessary to call AddRef and Release for a temporary interface pointer if it is going to be created and destroyed within the lifetime of another interface pointer. This sort of optimization creates a dependency between the two interface pointers, and in the future it can become the source of a reference counting error if some invariant associated with the dependency changes.
None of this should be a surprise to C++ programmers. After all, C++ programmers have to deal with the same conditions in C++ programs if the calls to new and delete are not properly coordinated. Forgetting to call delete results in memory leaks and calling delete prematurely results in dangling pointers.
However, the situation in COM is more insidious since COM components can be running in different processes than the ones their callers are running in. For example, a memory leak caused by a caller running in one process may result in a server process continuing to run when it should have shut down, thus consuming operating system resources as well as memory resources. Or worse, a bug in one caller can release a server process prematurely, causing it to shut down while it is still being used by other callers.
Note that Distributed COM (see FAQs 34.39, 34.40) has a security option that performs callbacks to the client to authenticate distributed reference count calls, ensuring that objects are not released maliciously.
FAQ 34.17 What mechanism does COM define for error handling?
![]()
COM sends us right back to the Dark Ages, since COM functions return error codes for doing error handling. Or, stated in a positive way, COM defines a mechanism for handling errors that is language and location transparent and is consistent with its binary standard.
The return value of most COM methods (AddRef and Release are two exceptions) is an HRESULT (a “handle to a result object”). An HRESULT is a 32-bit value that is divided into three fields. The first field (1 bit) can be tested to determine whether or not a function succeeded. The second field (15 bits) indicates what subsystem returned the error code. The third field (16 bits) is the return code. The biggest drawback of using this mechanism is that it requires the caller to explicitly test the value of the HRESULT after each COM method call.
Just because COM uses HRESULT does not prevent programmers from using C++ exception handling in the C++ code within the implementation of a method of a COM class, provided the exceptions are caught and handled by the COM method. In any event, C++ exceptions cannot be used for transmitting the error to the caller or to another COM object.
FAQ 34.18 How are interfaces versioned?
![]()
This is one of the more straightforward elements of COM—YOU CAN'T.
Interface versioning refers to the COM conventions for changing and modifying interfaces. COM's rule for versioning interfaces is simple: interfaces cannot be versioned; a modified interface is a new interface with a new and unique IID.
In this context, modifying an interface includes any change to the interface's specification, including adding or removing methods, adding or removing parameters, or changing the contract for a method (even if none of its parameters change). At the same time, the rule does not prevent multiple implementations for the same interface, as long as all the implementations satisfy the interface's contract.
The reasoning behind the rule regarding versioning interfaces is to maintain backward compatibility and guarantee that there are no conflicts between existing interfaces and new interfaces. The rule makes a lot of sense since it allows callers to program to a well-defined interface knowing that the interface will never change.
The fact that COM interfaces can't be versioned is really no different from the current situation with C++ class libraries, except that it is presented in a slightly different way. Suppose a system defines a COM interface called IDate for handling date-related information. Later the interface is modified, producing IDate2. Also suppose that there is a C++ class library that has a Date class and people write programs using the Date class. Now the vendor of the class library releases a new and improved C++ class library (version 2) with a Date class with a modified interface. Under these circumstances, what are the trade-offs between the C++ approach and the COM approach?
First, suppose the new version of Date simply adds methods so that it is completely substitutable with the earlier version. In the case of COM, existing callers continue to use IDate and new callers can choose between IDate and IDate2. In the case of the C++ class library, existing callers and new callers simply use version 2 of class Date. Easy.
Second, suppose the new version of Date is not completely backward compatible with the older version. In the case of COM, existing callers continue to use IDate and new callers can choose between IDate and IDate2. We might also decide to review some of the existing caller code and revise it to use IDate2. The choices are almost the same for the caller code using the C++ class library. Existing callers continue to use class Date Version One and new callers can choose between class Date Version One and class Date Version Two. We might also decide to review some of the existing caller code and revise it to use class Date Version Two (instead of class Date Version One).
In some ways, the COM approach is better. If one subsystem of a program uses the COM interface IDate and another subsystem of a program uses the COM interface IDate2, no incompatibilities occur when the subsystems are linked together. In contrast, if the two subsystems use different and incompatible versions of the C++ class Date, linking the two subsystems probably will create some conflicts. Typically this sort of problem forces the users of the C++ class library to choose between the two incompatible versions of the Date class, which may require one of the subsystems to be updated.
In the case of COM the two interfaces are distinguished using 128-bit IIDs, and in the case of C++ the two interfaces need to be distinguished by their names. In the end, both approaches amount to pretty much the same thing, and each has its champions.
FAQ 34.19 Is COM object oriented?
![]()
Yes, COM delivers all the major benefits of object technology (although some purists disagree).
Each COM class has a unique class identifier and implements one or more interfaces. An interface is a group of functions that provide a set of related services. A COM object is an instance of a COM class. A COM class can be used to create many separate COM objects. These definitions are similar to C++ where classes have unique identifiers and objects are instances of classes.
Most developers using COM could not care less about whether or not COM is “truly” object oriented. As far as they are concerned, it gives them the benefits of object orientation and that is all that counts:
• You can define classes.
• You can use the classes to create objects.
• The classes have well-defined interfaces and the implementations of the classes are fully encapsulated.
• Interfaces can be defined using inheritance and interface pointers are polymorphic.
FAQ 34.20 What is the biggest problem with COM?
![]()
Complete confusion for beginners.
Programmers can expect to experience a COM haze when they first work with COM. This comes from having to mentally juggle all the different issues:
• COM is relatively large and has its own way of doing things, and often its approach is unlike other systems (including C++ and CORBA).
• COM terminology is Humpty-Dumpty terminology (if you remember, Humpty-Dumpty said, “When I use a word it means just what I choose it to mean—neither more nor less”). Thus, COM uses many of the same terms as C++ and other object technologies but uses them in its own way. This can lead to misunderstandings.
• Most COM examples are written in C++, and this makes it hard to figure out where COM stops and where C++ begins. Programmers often find themselves wondering which of the five C++ classes in a COM example represent COM interfaces, which ones represent COM classes, and which ones are internal classes that are used only within the implementation of the COM classes.
• Different C++ class libraries use different approaches for declaring and implementing COM classes and offer different trade-offs. Some class libraries (like MFC, the Microsoft Foundation Class library) use numerous macros for defining COM classes, whereas other libraries (like ATL, the ActiveX Template Library) use C++ templates.
• There are numerous ways of declaring and implementing COM classes, and it is sometimes hard to figure out how they fit together. Examples in books don't always make it clear whether they are describing a new and distinct feature of COM or are simply describing another way of implementing a feature described earlier.
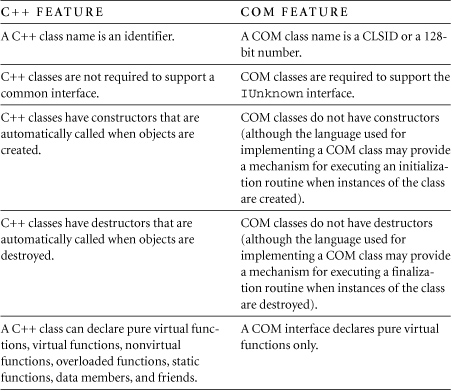
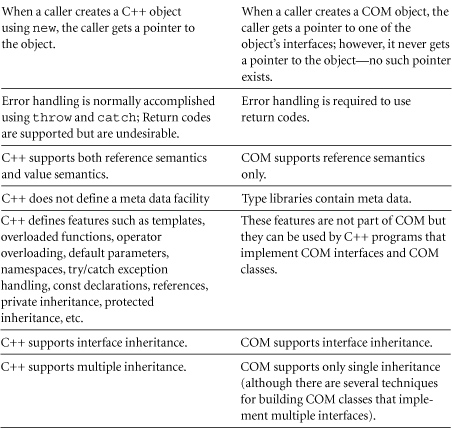
FAQ 34.21 What are the major differences between COM and C++?
![]()
COM is a component standard while C++ is an object-oriented language, and even though they have much in common, they really do have different roles in life.
As a programming language, C++ defines classes and objects, defines a complete syntax and semantics, and has a compiler that translates source text into executable code. In addition, C++ has a relatively small runtime system and restricts its view of the world to the objects in a single process.
As a component standard, COM defines classes and objects, has a minimal syntax and a minimal compiler (the MIDL compiler) for defining interfaces, defines an architecture for creating, locating, and accessing objects running in different processes, defines interfaces for marshaling parameters when calls are made to a different process (see FAQ 34.15 for more information regarding marshaling), and defines several threading models.
Therefore COM and C++ are completely different in their scope, but fortunately, they are compatible technologies: COM is well suited to defining components and interfaces, and C++ provides a rich language for implementing components and classes.


FAQ 34.22 When should a class be defined as a COM class?
![]()
Here are some guidelines.
- The development organization needs to buy into the idea of adopting a component-oriented architecture based on COM; otherwise, it can be pretty lonely if you're the only wolf in the pack trying to use COM. The development organization must also buy into the idea of using one of the 32-bit Windows operating systems (probably Windows NT) as a development and deployment platform.
- Start by developing a system or application architecture and make your decisions regarding where and when to use COM based on the architecture. Don't worry about deciding where to use COM on a class-by-class basis. Instead, look for the larger components of your system and think about the interfaces to these components. Try out subsystems as a first approximation.
For example, it might not make sense to define an Account class, whereas it might make sense to define an Account server. The Account server might run as an out-of-process COM server that can be shared by multiple callers and exposes a rich set of domain objects including account objects, customer objects, sales objects, invoice objects, and so on (where all of these objects are COM objects).
- Sticking with the software architecture theme, use COM when the goal is to improve reliability by running the classes/objects in a separate process or on a separate machine. For example, running the caller and the COM objects in the same process allows a bug in one to bring down the other. Using COM to run the objects/services in separate processes helps to protect the objects from the callers and the callers from the objects—if one of them crashes it does not necessarily bring down the other.
- Use COM when language transparency is important. Use COM when the callers and the objects might be written in different programming languages.
- Use COM when location transparency is important or when the objects need to be shared by callers running in separate processes. Use COM when it is important to be able to rehost the classes/objects in an in-process server, in a local server, or in a remote server without affecting the callers.
- Define the interfaces for your components from the caller's perspective rather than from the perspective of the developer. Limit the number of COM classes to classes that are visible from outside the component. For example, if the component includes account objects, customer objects, sales objects, and invoice objects, the component might internally utilize many other C++ classes for accessing a database and caching data, but there may be no reason to expose these internal C++ classes as COM classes.
- Be aware of performance issues and the fact the COM is sensitive to whether or not the caller and the object are running in the same process and whether or not the caller and the object are using the same threading model. For example, calling a method of a COM object that is running in process and is using a compatible threading model takes about the same amount of time as calling a virtual function of a C++ object (tens of millions of calls per second). For callers and servers using different threading models, the time cost is greater (tens of thousands of calls per second).
- Be aware of packaging issues. Multiple COM classes are packaged into a COM server, and the server is loaded/activated when the first COM object is created using the server. Since loading/activating a COM server can be time-consuming, make sure that all related COM classes are packaged together in the same server. That means that after the first COM object is created using the server, the time needed to create other objects will be less because the server is already loaded/activated. Putting related COM classes into separate servers can hurt performance.
- If the COM objects are expected to be running in an out-of-process server, then define the interfaces to accommodate it. For example, provide methods that get/set multiple properties in one call to minimize the number of round-trip method calls that must cross process boundaries.
FAQ 34.23 What is Automation?
![]()
Automation is a set of facilities that sits on top of COM and that can be used by programming tools that cannot use the lower-level COM interfaces and facilities (such as high-level scripting tools).
The goals for Automation and COM are almost identical: define components with well-defined interfaces in a location-transparent and language-independent manner.
The main difference between Automation and COM is that Automation is targeted at enabling callers that are high-level scripting tools to manipulate objects, whereas COM is targeted at lower-level languages such as C++ and C.
Automation was originally developed to allow Visual Basic to bind to COM components through a special interface. The name “Automation” is something of an anachronism since Automation has grown beyond its original goals of simply allowing scripting languages to automate common tasks. Automation is becoming more important with the growing use of scripting languages in Web browsers, server side scripting, and office suites.
FAQ 34.24 What are dispatch interfaces?
![]()
The interfaces exposed by Automation objects. In particular, Automation objects expose dispatch interfaces rather than vtable interfaces.
There are two different kinds of COM interfaces. First, there are vtable interfaces, which work well for callers written in C++ (and, ironically, Visual Basic). Vtable interfaces are normal (nondispatch) COM interfaces, and they get their name from the fact that their binary layout is the same as the binary layout of the virtual function table (vtable) produced by most C++ compilers.
Second, there are dispatch interfaces. Dispatch interfaces get their name from the fact that they are implemented using the COM interface IDispatch.
Dispatch interfaces make it much easier for tools such as Visual Basic and PowerBuilder to be adapted to use and support dispatch interfaces compared to using and supporting vtable interfaces for COM objects. Today, higher-level scripting languages such as Visual Basic for Applications and VBScript rely on dispatch interfaces, while Visual Basic supports both vtable interfaces and dispatch interfaces.
A dispatch interface allows callers to query an object at runtime for a list of its Automation methods and parameters and then invoke these methods. This facility is vital for allowing callers to invoke methods on objects when the methods were not known when the caller was compiled.
COM objects that expose dispatch interfaces are referred to as Automation objects or Automation servers. Callers that use Automation objects are referred to as Automation controllers. Automation objects are COM objects in every sense. They have a CLSID and a class factory, they implement IUnknown, their lifetime is controlled by reference counting, they can be implemented as in-process servers (in DLLs) or as out-of-process servers (in EXEs). It is important to realize that Automation is a protocol built on top of COM; in many ways, Automation is reminiscent of CORBA's Dynamic Invocation Interface (DII).
FAQ 34.25 When should a class expose a Dispatch interface?
![]()
When its callers say so.
The most obvious reason for implementing dispatch interfaces is that certain tools (such as VBScript, JScript, and older versions of Visual Basic) can interact with COM objects only through dispatch interfaces. Furthermore, ActiveX Controls (see FAQ 34.33) are required to expose their properties and methods through dispatch interfaces.
Dispatch interfaces define both dispatch methods and dispatch properties. Because COM interfaces can define only COM methods and dispatch interfaces are implemented using the IDispatch interface, dispatch properties are “virtual properties”: they are manipulated indirectly by calling the methods of the IDispatch interface (see FAQ 34.27). Note that the programming language used by the caller may make it appear as if the property is being manipulated directly, but underneath it is still using COM methods. This illustrates, once again, that dispatch interfaces are at a higher level of abstraction than vtable interfaces and that Automation is a protocol that is implemented in terms of COM.
Dispatch interfaces can be declared using IDL. Here is the Microsoft IDL definition of the IStack dispatch interface.

The dispinterface statement is used to create type information for a dispatch interface. For this reason, dispatch interfaces must be declared inside library declarations. Dispatch interfaces, like all other COM interfaces, must have an IID, and it is declared using the [uuid] attribute.
Dispatch interfaces are derived from IDispatch (the dispinterface statement implicitly derives the interface from IDispatch). The declarations for the IDispatch interface are loaded from the Automation type library using the statement importlib("stdole32.tlb");.
The dispinterface statement has two sections; one for declaring properties and one for declaring methods. Each property must have an Automation-compatible type (see FAQ 34.32). The types of the parameters and return value for each method must also be Automation-compatible. Every method and property has a DISPID, which is assigned using the [id] attribute.
You may have noticed that the syntax for the dispinterface statement is unlike other IDL statements. This is because the dispinterface statement was originally part of an earlier tool called the Object Definition Language (ODL), which has been merged into Microsoft IDL.
Dispatch interfaces use Type Library Marshaling (see FAQ 34.29) using the built-in Automation Marshaler; therefore the MIDL compiler does not need to generate proxy/stub code.
The best way for COM classes to expose dispatch interfaces is as dual interfaces. As discussed in FAQ 34.31, this allows a COM class to have its cake and eat it, too.
FAQ 34.26 How does Automation work?
![]()
The IDispatch interface is what makes Automation work.
The IDispatch interface is a regular COM interface and is declared as follows.

When a caller wants to call a dispatch method defined by an Automation server, it first calls the server's implementation of IDispatch::GetIDsOfNames, supplying it with the string name of the dispatch method it wants to call. The result returned by GetIDsOfNames is the Dispatch Identifier (DISPID) for that dispatch method. The caller then calls the dispatch method by calling IDispatch::Invoke, supplying it with the DISPID for the dispatch method, the type of each parameter, and the values of each parameter. The implementation of IDispatch::Invoke performs a table lookup using the DISPID and executes the dispatch method.
When a caller wants to access a dispatch property, it first calls the server's implementation of IDispatch::GetIDsOfNames, supplying it with the string name of the dispatch property it wants to access. The result returned by GetIDsOfNames is the DISPID for that dispatch property. The caller then calls IDispatch::Invoke and supplies it with a flag indicating whether it wants to get the value of the dispatch property or set a new value for the dispatch property. The implementation of IDispatch::Invoke performs a table lookup using the DISPID and accesses the corresponding dispatch property.
Once a caller obtains a DISPID for a particular dispatch method (or property), it can cache it and use it repeatedly for calling the same method (or accessing the same property) without having to bother calling GetIDsOfNames again for that dispatch method (or dispatch property).
The good news is that most callers never call Invoke directly (the calls to Invoke are usually hidden behind a layer of abstraction). In the case of environments like Visual Basic, the Visual Basic syntax hides all the interactions with IDispatch. In the case of programming languages like C++, the development environment should automatically generate “automation proxy classes” that hide all the interactions with IDispatch. If your development environment cannot automatically generate automation proxy classes, you can always build them yourself.
FAQ 34.27 How does Invoke accomplish all of this?
![]()
IDispatch::Invoke declares a very general interface that has a large number of formal arguments that allow the caller to specify a wide range of parameters—including the DISPID for the operation, the type of operation (method call versus property get versus property put), the return value, exception information, and so on. The Automation object's implementation of IDispatch::Invoke must unpackage these parameters, call the method or access the property, and handle any errors that occur. When the property or method returns, the Automation object passes its return value back to the caller through another parameter of IDispatch::Invoke.
Invoke is similar in spirit to printf: callers pass a bunch of information, and the implementation of IDispatch::Invoke (like printf) ends up interpreting the incoming parameters to decide what to do. This makes IDispatch:: Invoke capable of doing almost anything.
After IDispatch::Invoke interprets the parameters passed to it, it calls a method defined by the server—in this way IDispatch::Invoke does nothing. All IDispatch::Invoke does is look up the right routine, and that routine performs the useful work.
Notice that dispatch interfaces reverse the usual notions associated with COM interfaces. COM interfaces tend to have a small set of well-defined methods that are semantically related to one another. Dispatch interfaces tend to group together a large number of methods that are not necessarily related and funnel them through the IDispatch interface.
FAQ 34.28 What is a type library?
![]()
A type library is a compiled version of an IDL file that can be accessed programmatically.
COM provides a facility called type libraries that allows programs to dynamically access interface definitions and query for information on interfaces, components, methods, and parameters. Most Automation components create type libraries. A type library has a unique identifier (that is, a GUID) called a LIBID.
Type libraries can be generated by the Microsoft IDL compiler. After creating the type library, it can be included in the application as a resource or it can be a stand-alone file (in which case, the file name of the type library needs to be registered in the system registry so that the type library can be located when necessary).
COM defines interfaces for creating type information (ICreateTypeInfo, ICreateTypeInfo2), accessing type information (ITypeInfo, ITypeInfo2), creating type libraries (ICreateTypeLib, ICreateTypeLib2), and accessing type libraries (ITypeLib, ITypeLib2).
A caller can ask a COM object at runtime if it supports the ITypeInfo interface. Through this interface, the caller can interrogate the object to find out what methods and properties it provides. This facility is useful for scripting languages.
FAQ 34.29 What are the benefits of using type libraries?
![]()
Discover type information for a COM class without having to load the class.
A type library is the Automation standard for describing the objects, properties, and methods exposed by an Automation object. Type libraries provide important benefits.
• Type checking can be performed at compile time. This helps developers of Automation callers to write fast, correct code to access objects.
• Type browsers can scan the type library, allowing others to see the characteristics of the classes.
• Browsers and compilers can use the type information to display and access the classes.
• Automation callers that cannot use vtable interfaces can read and cache DISPIDs at compile time, improving runtime performance.
• Visual Basic applications can take advantage of early binding by creating objects with specific interface types, rather than the generic Object type.
• Implementation of IDispatch::Invoke for the interface is faster and easier.
• Access to out-of-process servers is improved because Automation uses information from the type library to package the parameters that are passed to an object in another process.
Another benefit of type libraries is type library marshaling. Type library marshaling allows a custom interface to use the built-in Automation marshaler for the IDispatch interface, thus avoiding the need to build a proxy/stub DLL for the custom interface and then having to register it on each machine—the Automation marshaler is automatically available on Windows machines. To use this option, you need only register a type library for the interface on the client machines and restrict the interface to using the Automation–compatible data types (see FAQ 34.32).
FAQ 34.30 How do type libraries improve performance?
![]()
The Automation controller can avoid calling GetIDsOfNames at runtime.
An Automation controller can bind to a dispatch interface in one of two ways. One way is for the Automation controller to get the DISPIDs by calling the IDispatch:: GetIDsOfNames function. This is called late binding because the controller binds to the property or method at runtime. Late binding works when nothing is known about the dispatch interface at compile time.
The other way is for the Automation controller to use ID binding. When using ID binding, the Automation controller extracts type information about the Automation object from its type library and maps the names of dispatch methods and properties to DISPIDs. More specifically, the DISPID of each property or method is fixed and is part of the object's type description. If the object is described in a type library, an Automation controller can read the DISPIDs from the type library and does not have to call GetIDsOfNames at runtime.
FAQ 34.31 What are dual interfaces?
![]()
A great way to have your cake and eat it, too.
A dual interface is an interface that combines a dispatch interface and a direct vtable interface.
One advantage of dual interfaces is that they let the caller choose the binding mechanism it wants to use. Scripting languages can use the dispatch interface while C++ callers can use the direct vtable interface. This means that objects that export dual interfaces are more useful since they can be used by a wider range of callers. IDispatch offers support for late binding, whereas vtable binding offers much higher performance because the method is called directly instead of going through IDispatch::Invoke.
IDL supports the definition of dual interfaces. This is done by deriving the interface from IDispatch and attaching the [dual] attribute to the interface statement (notice that the dispinterface statement is not used). Here is the IDL declaration of IStack suitable for a dual interface.

Since dual interfaces are COM interfaces, they must abide by the rules for COM interfaces.
• A dual interface must have an IID, and it is declared using the [uuid] attribute.
• The return type for a method is HRESULT, and all other results need to be returned through the parameter list (see pop and empty).
Since dual interfaces are dispatch interfaces, they must abide by the rules for dispatch interfaces.
• The declarations for the IDispatch interface are loaded from the Automation type library using the statement importlib("stdole32.tlb");.
• Each method has a DISPID, which is assigned using the [id] attribute.
• The types of the parameters for each method must be Automation-compatible data types.
• Dual interfaces are able to use type library marshaling (see FAQ 34.29) so that the interface can be accessed across process boundaries or across machine boundaries automatically (this is not automatically true for all custom-defined vtable interfaces). This is done using the type library for the interface in conjunction with a generic universal proxy/stub implementation.
A dual interface inherits from IDispatch and also implicitly inherits from IUnknown (since IDispatch inherits from IUnknown). At a binary level, the first three entries in the vtable are the members of IUnknown, the next four entries are the members of IDispatch, and the subsequent entries are pointers to the custom methods of the dual interface. Thus Automation controllers can access the IDispatch interface (including GetIDsOfNames and Invoke) since the entries for the dispatch interface are at the same locations in the vtable whether or not this is a dual interface. Other callers who are aware of dual interfaces can bind directly to the custom methods in the COM interface. Information about the physical layout of the vtable is obtained from a type library or a header file.
Direct vtable binding can be two to five times faster than Automation binding for in-process calls.
FAQ 34.32 What limitations are there on dual interfaces?
![]()
The primary limitation of dual interfaces is that arguments and return types are restricted to the Automation-compatible data types:
• boolean
• unsigned char
• short, int, long
• float, double
• currency, Date
• text strings
• status codes
• pointers to COM interfaces
• pointers to dispatch interfaces
• arrays of these types
• references to these types
These data types are defined by COM; they are not C++ data types, although there is a mapping from these data types to C++ data types. The reason that dual interfaces are restricted to these data types is that these are the data types that can be passed to IDispatch::Invoke, and every custom method of a dual interface has a corresponding automation method that is invoked using IDispatch::Invoke.
FAQ 34.33 What are OLE custom controls and ActiveX controls?
![]()
The word “control” has evolved in the same way the term OLE has evolved. About the only thing that can be said for sure is that a control is a software component. Early controls tended to be used as GUI widgets in Visual Basic programs, but now there are many non-GUI controls and they are used in non-Visual Basic programs. Controls are in-process objects and must execute in some kind of control container (see FAQ 34.35), a program specially designed for hosting controls and working with controls.
In the beginning there were Visual Basic Controls (VBXs). VBXs are a mechanism for packaging non-Visual Basic code (usually C routines) and calling them from 16-bit versions of Visual Basic. As such, VBXs are DLLs written in a prescribed manner so that they can be easily incorporated into and called from Visual Basic programs.
And VBXs begat OLE Custom Controls (or OCXs). OCXs have a number of advantages over VBXs.
• OCXs are based on COM, which means that they take advantage of all of the COM facilities for defining interfaces, developing components, creating components, and accessing components.
• OCXs are 32-bit custom controls (VBXs were 16-bit). Therefore OCXs are better suited to 32-bit applications and 32-bit Windows operating systems.
• OCXs can be written in any language that can be used for writing COM components (VBXs were almost always written in C).
• OCXs can be used from any program that is a custom control container (VBXs were pretty much limited to being used from Visual Basic).
• The OCX architecture defines a large number of mandatory interfaces that an OCX must support, and these interfaces provide a great deal of integration between the OCX and the control container.
And OCXs begat ActiveX Controls. ActiveX controls are a slimmed-down version of OCXs that are better suited to Web-based applications. The ActiveX architecture defines a minimal set of interfaces for an ActiveX control and, in fact, ActiveX controls are required to implement only one interface: IUnknown. All other interfaces are optional. More specifically,
• An ActiveX Control must have a CLSID (required for all COM objects).
• An ActiveX Control must support the IUnknown interface (required for all COM objects).
• An ActiveX Control must have a class object that implements IClassFactory (required for all COM objects).
• An ActiveX Control must expose its properties, methods, and events via dispatch interfaces or dual interfaces. In other words, ActiveX Controls are Automation objects.
• If a control has any persistent state, it must, as a minimum, implement either IPersistStream or IPersistStreamInit. The latter is used when a control wants to know when it is created new as opposed to being reloaded from an existing persistent state
• An ActiveX Control must be a self-registering, in-process component that implements the routines DllRegisterServer and DllUnregisterServer.
• An ActiveX Control must use the component categories API to register itself as a control, and it must register the component categories it requires a control container to support and any categories the control implements.
FAQ 34.34 Why do ActiveX controls differ from OLE custom controls?
![]()
Mostly to support the World Wide Web.
First, some background. OCXs are COM components that must implement many well-defined COM interfaces. This has both good and bad consequences. It is good because it means that OLE control containers (see FAQ 34.35) can rely on every OCX implementing a core set of interfaces, allowing the Control Container and the OCX to interact seamlessly and provide richer interactions with the user. It is bad because it makes OCXs into fairly heavyweight objects and it makes writing OCXs fairly complicated (but tools are evolving to ease this problem).
The OCX architecture makes several assumptions. First, it assumes that when an OCX is loaded, its state information is available on a local file system. Second, the OCX architecture provides for only synchronous loading of OCX state information. For desktop components this is irrelevant since it is assumed that the control container and the OCX are loaded onto the same machine.
Then the Web exploded and everything changed. It is no longer safe to assume that the control container and the control reside on the same machine. Instead, the control may reside on another machine and the control container may have to dynamically download the control across the Web/Internet.
For these reasons (and many more), the ActiveX control architecture replaced the OCX architecture. As mentioned already, ActiveX controls dispense with most of the baggage associated with OCXs. This permits smaller executables so that ActiveX control can be downloaded over the Web/Internet faster.
While the ActiveX architecture makes ActiveX controls more Web/Internet friendly, it has side effects. For example, now control containers have to be “smarter” since they have to “negotiate” with every ActiveX control to determine its capabilities. This, in turn, sometimes results in less integration between the control and its container than was previously possible using the OCX architecture.
The ActiveX architecture also supports situations where the control's state information is stored on a distant machine across the Web/Internet. In particular, the ActiveX architecture defines interfaces for asynchronously loading a control's state information and asynchronous notification of the container regarding the progress of loading this information
FAQ 34.35 What is a control container?
![]()
An ActiveX control container is an application or component capable of hosting (or containing) an ActiveX control. Control containers must implement a mandatory set of COM interfaces for hosting and interacting with ActiveX controls. Control containers may also implement a number of optional COM interfaces, depending on the functionality they provide and the level of integration they wish to provide.
Control containers cannot rely on an ActiveX control supporting any specific interfaces other than IUnknown. Determining what interfaces an ActiveX control supports is part of the negotiation process that occurs between a control container and a control.
Control containers must degrade gracefully when an ActiveX control does not support a particular interface, even if this means it cannot perform its designated job. At a minimum, “degrade gracefully” means that the control container continues to operate and does not fail. As you can see, the ActiveX architecture assigns many responsibilities to the control container.
Some containers provide container-specific private interfaces for additional functionality or improved performance. Controls that rely on container-specific interfaces should also work without the container-specific interfaces so that the control can function in different containers.
FAQ 34.36 What are component categories?
![]()
Component categories are a COM mechanism that allows a control to register the types of services it provides. Although the following discussion is phrased in terms of controls and control containers, it applies to any COM component and any COM caller.
Component categories are particularly valuable for control containers since it allows them to determine the capabilities of a control without having to create the control and enter into a lengthy discovery process involving querying the components for the interfaces it supports.
Every component category has a unique category identifier or CATID (which is a GUID) and a list of interfaces a control must implement before it can belong to that component category. Any control that implements all the interfaces defined for a particular component category is then able to register itself as belonging to and supporting the component category.
This permits control containers to look up the component categories for a particular control in the system registry and immediately determine whether or not it provides the services the control container requires so that the control container can adapt its behavior as necessary.
FAQ 34.37 What are events?
![]()
Asynchronous actions that are fired by ActiveX controls and handled by control containers.
ActiveX Controls (and OCXs) define “events” in addition to properties and methods. Events are asynchronous actions that are fired by the ActiveX control and are handled by the control container. An event is like a method in that it has a name, parameters, and a return value, and is implemented using Automation. Events are different from methods in that methods are defined by the control and implemented by the control, whereas events are defined by the control and implemented by the control container.
Some events are GUI events: if the user clicks on a button that is an ActiveX control, the button could fire an event notifying its control container. Other events are database events: if an ActiveX control is bound to a record in a database and the record is updated by another program, the control could fire an event notifying its control container and the container might query the database and update its display. Many other asynchronous actions can be implemented as events including timer events and network events.
Events are asynchronous. In this context, asynchronous means that the control can fire the event at any time and the firing of the event is not initiated by (or stimulated by) the control container. Asynchronous does not mean nonblocking, as it might in the context of asynchronous message queueing.
FAQ 34.38 What is DCOM?
![]()
Distributed COM—the distributed version of COM.
Distributed COM extends COM to support communication between callers and components that are located on different computers. DCOM does not really change much about how callers create and interact with COM objects, and therefore, DCOM lets callers remain unaware of where a COM object is running. The one noticeable difference is, of course, that network latency means that accessing a remote object is slower than accessing a local object. DCOM does introduce some differences, especially in the areas of security and the registry.
DCOM uses reference counting and pinging (pinging is a technique whereby one computer or one program sends ping messages to another computer or another program to determine whether or not it is running and to verify that there is a valid connection between the two) to handle garbage collection of objects and the servers in which the objects are running. As always, callers call AddRef when they obtain pointers to interfaces and call Release when they no longer need the pointer to the interface. When the reference count on an object hits zero, it can be garbage collected and its resources can be freed. Since reference-counting schemes are vulnerable to machine crashes and network problems, DCOM also uses a mechanism that sends pings on a computer-by-computer basis to detect nonexistent callers and dangling references so that unneeded objects can be garbage collected.
Although DCOM extends COM across machine boundaries it does not try to solve every possible distributed programming problem. Some of these other problems are handled by Microsoft Transaction Server and Microsoft Message Queueing.
Software AG has ported DCOM to Sun Solaris, 64-bit Digital Unix, and IBM's OS 390.
FAQ 34.39 How stable is DCOM's infrastructure?
![]()
DCOM is based on the Distributed Computing Environment (DCE) Remote Procedure Call (RPC) mechanism, thus inheriting a stable and proven cross-platform communication protocol. DCE RPC has been in use for a number of years and has proven its worth.
Although DCE RPC is complex, it brings a wealth of capabilities to DCOM. DCOM uses DCE-compatible RPCs for marshaling data and operates over a variety of protocols including TCP/IP, IPX, UDP, and NetBIOS (see FAQ 34.15 for more information regarding marshaling). Although DCOM uses DCE as its RPC mechanism by default, much of DCOM can be overridden and customized. For instance, a DCOM system might handle data marshaling on its own or it might decide not to use DCE at all and provide its own RPC mechanism.
DCOM includes a distributed security mechanism providing authentication and data encryption. DCOM includes provision for using naming services for locating class and objects on other machines, including both Domain Name System (DNS) and Active Directory with NT 5.0.
FAQ 34.40 What is COM+?
![]()
It is the second generation of COM.
The purpose of COM+ is to make it easier to write COM-based components and applications using any COM+-compliant programming language. COM+ attempts to make the development of COM components more like developing language-specific components. The tools you use and the COM+ runtime take care of turning those classes into COM+ components and applications. For example, a C++ development environment that is COM+ compliant can produce a COM+ class from a C++ class, and a Visual Basic development environment that is COM+ compliant can produce a COM+ class from a Visual Basic class. COM+ is language neutral and doesn't care what syntax is used to implement a component—that's up to the tools you use.
When using a COM+-compliant tool there is no need to explicitly write a class factory—the COM+ runtime provides one. Nor is it necessary to create a type library—COM+-aware languages and tools use the COM+ runtime to generate meta data that fully describe the COM+ class. In COM+, there is no need to specify the CLSID and other GUIDs explicitly—COM+ tools generate them and may use GUIDs internally, but programmers generally use class names in the source code.
A COM+ class, unlike a COM class, defines data members, properties, methods, and events. Data members and properties collectively describe an object's state. Methods are the actions that may be performed on an object. Events are notifications that something interesting has happened. COM+, unlike COM, defines a common set of data types no matter what language is used. Your tool may need to provide some sort of mapping between its native type definitions and those used by COM+. In addition, COM+ classes are completely described by meta data, and COM+ can use this information to coerce values you supply into the types it expects.
COM+ methods allow overloading of method names within a COM+ class. Methods in COM+ can be decorated with modifiers such as static and virtual. Static methods are class methods rather than instance methods. Virtual methods are object methods that can be overridden in derived classes. COM+ also recognizes two special types of methods: constructors and destructors.
COM+ lets programmers use two types of inheritance, interface inheritance and implementation inheritance. COM+ retains the notion of interfaces, and interfaces are still the recommended way to define the public behavior of COM+ classes. In implementation inheritance, a COM+ class inherits both interface and implementation from another COM+ class. COM+ supports single implementation inheritance and does not permit multiple inheritance of COM+ classes.
COM+ understands exceptions. COM+ allows the types of exceptions that may be thrown by a method to be specified. Whenever boundaries between COM+ and nonCOM+ execution environments are encountered, exceptions are translated to and from COM IErrorInfo, Win32 Structured Exception Handling, or C++ exceptions as needed.
Another key concept for COM+ is interception. Whenever the compiler sees a method being called or a property being accessed, it generates a call to the COM+ object services rather than generating a direct call to the class code. This lets COM+ intercept and manage all method invocations and property accesses between callers and components. This can be used by external services. For example, a performance-monitoring service could log the number of calls to each method and the time required to process the calls. A security service could determine whether the caller was authorized to call a particular function.
From the caller's perspective, COM+ objects are created using the same mechanism used to allocate native objects. For example, a C++ program uses syntax such as new Fred(). Furthermore, the object reference is managed by COM+. When the program is finished with the reference, it just sets the pointer to NULL and COM+ takes care of cleaning up the object. This means that COM-style reference counting is not needed—COM+ takes care of it.
It is important to note that all COM+ objects are COM objects. Furthermore, Microsoft will add some new features and keywords to its C++ specifically for writing COM+ classes and supporting the services described here.