
Chapter 13. Inline Functions
FAQ 13.01 What is the purpose of inline functions?
![]()
In some cases, inline functions make a compute-bound application run faster.
In a broad sense, the idea behind inline functions is to insert the code of a called function at the point where the function is called. If done carefully, this can improve the application's performance in exchange for increased compile time and possibly (but not always) an increase in the size of the generated binary executables. As usual, the devil is in the details. Read the fine print; it does make a difference.
It is useful to distinguish between “inline,” a keyword qualifier that is simply a request to the compiler, and “inlined,” which refers to actual inline expansion of the function. The expansion is more important than the request, because the costs and benefits are associated with the expansion.
Fortunately C++ programmers normally don't need to worry whether an inline function actually is inlined, since the C++ language guarantees that the semantics of a function cannot be changed by the compiler just because it is or isn't inlined. This is an important guarantee that changes the way compilers might optimize code otherwise.
C programmers may notice a similarity between inline functions and #define macros. But don't push that analogy too far, as they are different in some important ways. For example, since inline functions are part of the language, it is generally possible to step through them in a debugger, whereas macros are notoriously difficult to debug. Also, macro parameters that have side effects can cause surprises if the parameter appears more than once (or not at all) in the body of the macro, whereas inline functions don't have these problems. Finally, macros are always expanded, but inline functions aren't always inlined.
FAQ 13.02 What is the connection between the keyword “inline” and “inlined” functions?
![]()
Fans of Alice's Adventures in Wonderland will appreciate that a function decorated with the keyword inline may not be inlined, but an inlined function may not have been specified as inline, while the only sure way to be inlined is to not exist at all!
A function can be decorated with the inline keyword either in the class definition or in its own definition if the definition physically occurs before the function is invoked. The compiler does not promise that an inline function will be inlined, and the details of when/when not are compiler-dependent. For example, many compilers won't actually inline recursive and/or very long inline functions. So an inline function may not be inlined.
On the other hand, any function that is defined within the class body will be treated implicitly as an inline function with or without the explicit inline keyword. Again, there is no guarantee that it will be inlined, but the compiler will try anyway. So some functions are inlined without the inline keyword.
Finally, compiler-generated default constructors, copy constructors, destructors, and assignment operators are treated as inline, and often (but not always) they end up being inlined because they usually don't do anything tricky. These are the functions that are usually inlined, and they don't even explicitly appear in the code.
FAQ 13.03 Are there any special rules about inlining?
Yes. Here are a few rules about inlining.
- Any source file that contains usage of an
inlinefunction must contain the function's definition. - An
inlinefunction must be identically defined everywhere. The easy way to do this is to define it once, preferably in the class header file, and include the definition as needed. The hard way is to carefully redefine the function everywhere and learn the one-definition rule (see FAQ 13.04). But even the easy way has a potential glitch, so read FAQ 13.04 regardless. main()cannot beinline.
But these are just language rules that tell how to do inline functions. To find out when to do inline functions, read the rest of this chapter.
FAQ 13.04 What is the one-definition rule (ODR)?
![]()
The ODR says that C++ constructs must be identically defined in every compilation unit in which they are used.
For example, if source file foo.cpp and source file bar.cpp are in the same program and class Fred appears in both source files, then class Fred has to be identically defined in the two source files. Similarly, the definition of an inline function must be the same in the two source files.
Here's what “identically defined” means. With respect to the ODR, two definitions contained in different source files are said to be identically defined if and only if they are token-for-token identical and the tokens have the same meaning in both source files. The last clause is important: it warns that merely including the same definition in two places isn't good enough to prevent ODR problems, because the tokens (such as typedefs) can have different meanings in the different locations. Note that “identically defined” does not mean character-by-character equivalence. For example, two definitions can have different whitespace or different comments yet still be “identical.”
FAQ 13.05 What are some performance considerations with inline functions?
Here are some important facts about inlined functions.
- They might improve performance, or they might make it worse (see FAQ 13.06).
- They might cause the size of the executable to increase, or they might make it smaller (see FAQ 13.07).
- When they are nontrivial, they probably will complicate the development effort if employed too early in the development cycle. Provisions to use them can be made early but the final decision should be made later (see FAQ 13.08).
- When they are provided to third-party programmers, they can make it difficult to maintain binary compatibility between releases of the software (see FAQ 13.09).
The only dangerous idea about inlining is the attitude that says, “Fast is good, slow is bad; inlining is faster, so everything should be inlined.” If only life were that simple.
FAQ 13.06 Do inlined functions improve performance?
Inlined functions sometimes improve overall performance, but there are other cases where they make it worse.
It is reasonable to define functions as inline when they are on the critical path of a CPU-bound application. For example, if a program is network bound (spending most of the time waiting for the network) or I/O bound (spending most of the time waiting for the disk), inlining might not make a significant impact in the application's performance since processor performance might not be relevant. Even in cases when the program is CPU bound, there is no point in worrying about optimizing a function unless it is on a critical execution path, that is, unless it is taking up a major portion of the time consumed by the program.
In cases where processor optimization is relevant, inline functions can speed up processing in three ways:
- Eliminating the overhead associated with the function call instruction
- Eliminating the overhead associated with pushing and popping parameters
- Allowing the compiler to optimize the code outside the function call more efficiently
The first point is worth pursuing only in very exceptional circumstances because the overhead of the call instruction itself is normally quite small. However, the call instruction can have some expensive side effects that can be eliminated when the call is inlined. For example, if the called routine is not inlined, accessing the called routine's executable code can cause a page fault (a page fault happens in virtual memory operating systems when some chunk of the application is temporarily stored on disk rather than in memory). In extreme cases, this can cause a situation called thrashing, a situation in which most of the time is spent handling page faults. Even when a page fault does not occur (that is, when the executable code of the called routine is already in memory), the code of the called routine might not be in the processor's cache, a situation called a cache miss. Cache misses can be expensive on certain CPU-bound applications.
The second point can be important, because value semantics can have considerable overhead. A function with many formal parameters, whether they use value semantics or not, can do quite a bit of stack pushing and popping. Even if the parameter is a simple built-in type such as int or char, there is some nontrivial overhead. For example, parameters of built-in types are often located in one of the processor's registers, so the caller has to move the parameter out of the register onto the stack, and the called routine often pulls it back off the stack into a register, and when the call is finished, the caller pulls it back off the stack into its original register. All that can normally be eliminated if the call is inlined.
The third point, also known as procedural integration, is typically the major source of improvement. By letting the compiler see more code at once (by integrating the called procedure into the calling code), optimizer can often do a better job: it can often generate more efficient code.
But performance can be lost as well as gained. Sometimes inlined functions lead to larger binary files that cause thrashing on virtual memory operating systems (see FAQ 13.07). But there are other times where the paging performance is actually improved, because inlining can provide locality of reference and a smaller working set as well as, paradoxically, smaller executables.
FAQ 13.07 Do inlined functions increase the size of the executable code?
Sometimes yes, sometimes no.
When large functions are inlined, the executable generally grows larger. However when small functions are inlined, the executable can actually become smaller, since the amount of executable code needed to call a function, including pushing all the registers and parameters, can be larger than the amount of code that would have been generated had the call been inlined.
Consider the following example. With optimization turned on, the size of the generated code was 33% smaller when the member functions were inlined compared to when they were not inlined.

FAQ 13.08 Why shouldn't the inlining decision be made when the code is first written?
Except for trivial access member functions, the information for making intelligent inlining decisions usually comes from profiling actual code, not from the developer's intuition.
Intuition is a crummy guide when it comes to performance. There are so many issues to consider that vary with the compiler, operating system, hardware, and system configuration that very few programmers can anticipate exactly where the bottlenecks will occur. Chapter 33, “High-Performance Software,” discusses this in more detail.
But even if the bottlenecks are known ahead of time, using inline on nontrivial functions early in the development cycle can add significant frustrations to the edit-compile-debug cycle. Since inline functions normally are defined in header files, when an inline function is changed the compiler will normally recompile every source file (for example, every .cpp file) that includes that function. This often means recompiling the world, which can take a long, long time on a medium or large project.
FAQ 13.09 What happens when a programmer uses an inlined function obtained from a third party?
![]()
It makes it harder for that third party to maintain binary compatibility between releases of the third party's software.
The code of an inlined function is copied into the user's executables. So subsequent changes to the inlined function require recompilation of the user's code, which can be painful or even politically impossible if there is a vendor-customer relationship.
For example, vendors who want to provide their customers with binary-compatible releases of a library must avoid changing any inline functions that are accessible to their customers. Typically this is done by considering the implementation of any inline functions that have been shipped to customers to be “frozen”—frozen code can never, ever change. Recall that the compiler-synthesized construction, assignment, and destruction routines are implicitly inline (see FAQ 13.02), so achieving binary compatibility requires these routines to be explicitly defined as non-inline. For example, if the compiler defines them as inline, and if the class layout ever changes, they will change from release to release. This includes relatively innocuous changes to the class layout, such as adding or removing a private: data member.
Another, more subtle, problem is the potential breakdown of information hiding. For example, users of an inline function must have a copy of the source code, and that copy gets bound into their program. Think about that for a second. Maybe they haven't read this book, and maybe they don't understand the importance of respecting interfaces. Maybe they rely on the implementation rather than the specification; giving them the code opens up that opportunity. If so, the implementation techniques are turned into concrete. This makes life harder.
FAQ 13.10 Is there an easy way to swap between inline and non-inline code?
![]()
Yes, with a little macro magic.
Most projects should turn off inlining during development. That is, they use a compiler option that causes the compiler to not inline any inline functions. This can make the code easier to debug, but it still doesn't help the edit-compile-debug problem mentioned in FAQ 13.08. For example, turning off inline expansion via a compiler option does not improve compile-time performance—the compiler still has to parse the body of every inline function in a header every time a source file is compiled that includes the header. Furthermore, depending on the compiler, turning off inline expansion may increase code bulk—the compiler may create duplicate static copies of each inline function seen by the compiler during every compilation unit. Finally, and probably most important, turning off inline expansion doesn't help the “recompile the world” problem (see FAQ 13.08) since the inline functions are still in the include files.
Although macros are evil, this is one of the areas where they can be used to bypass the compile-time overhead mentioned in FAQ 13.08. The strategy is straightforward. First, define all inline functions outside the class body in a separate file (call this the .inl file or .ipp file). Then, in the .inl file, change the keyword inline to the preprocessor symbol INLINE. Finally, conditionally #include the .inl file from either the bottom of the .hpp file or from the .cpp file, depending on whether or not INLINE should become inline or nothing.
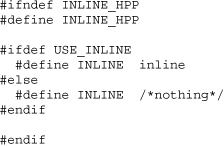
In the following example, inline.hpp defines a macro INLINE to be either the keyword inline or nothing, depending on whether the USE_INLINE symbol is #defined. For example, if the compiler supports the -D option as a way to #define a symbol, compiling with -DUSE_INLINE causes INLINE to become inline. Here is file inline.hpp.
File Fred.hpp defines class Fred with two member functions, f() and g(). If the symbol USE_INLINE is #defined, file Fred.inl is #included from Fred.hpp. Here is file Fred.hpp.

File Fred.inl defines Fred::f() preceded with the symbol INLINE. Note that Fred.inl does not #include "Fred.hpp". Here is file Fred.inl.

File Fred.cpp defines Fred::g() as non-inline. If the symbol USE_INLINE is not #defined, file Fred.inl is #included from Fred.cpp. Here is file Fred.cpp.

It is important to note that users of Fred don't have to be aware of the .inl file. For example, if file UserCode.cpp uses a Fred object, it won't need to change due to the INLINE magic. Here is a sample file that uses a Fred object, file UserCode.cpp.

This strategy can be easily modified to allow class-specific inlining. Simply replace the line #include "inline.hpp" with the contents of that file, then change USE_INLINE to USE_INLINE_Fred and INLINE to INLINE_Fred throughout.