Chapter 2. Basic C++ Syntax and Semantics
FAQ 2.01 What is the purpose of this chapter?
![]()
To present the fundamentals of C++ syntax and semantics.
This chapter provides a brief overview of C++ syntax and semantics. It covers topics such as main(), creating and using local, dynamically allocated, and static objects, passing C++ objects by reference, by value, and by pointer, default parameters, C++ stream I/O, using classes with operator overloading, using templates, using auto_ptr to prevent memory leaks, throwing and catching exceptions, and creating classes including member functions, const member functions, constructors, initialization lists, destructors, inheritance, the is-a conversion, and dynamic binding.
Experienced C++ programmers can skip this chapter.
FAQ 2.02 What are the basics of main()?
![]()
It's the application's main routine.
Object-oriented C++ programs consist mostly of classes, but there's always at least one C-like function: main(). main() is called more or less at the beginning of the program's execution, and when main() ends, the runtime system shuts down the program. main() always returns an int, as shown below:

main() has a special feature: There's an implicit return 0; at the end. Thus if the flow of control simply falls off the end of main(), the value 0 is implicitly returned to the operating system. Most operating systems interpret a return value of 0 to mean “program completed successfully.”
main() is the only function that has an implicit return 0; at the end. All other routines that return an int must have an explicit return statement that returns the appropriate int value.
Note that this example shows main() without any parameters. However, main() can optionally declare parameters so that it can access the command line arguments, just as in C.
FAQ 2.03 What are the basics of functions?
![]()
Functions are one of the important ways to decompose software into smaller, manageable chunks. Functions can have return values (for example, a function that computed a value might return that value), or they can return nothing. If they return nothing, the return type is stated as void and the function is sometimes called a procedure.
In the following example, function f() takes no parameters and returns nothing (that is, its return type is void), and function g() takes two parameters of type int and returns a value of type float.

FAQ 2.04 What are the basics of default parameters?
![]()
C++ allows functions to have default parameters. This is useful when a parameter should have a specified value when the caller does not supply a value. For example, suppose that the value 42 should be passed to the function f() when the caller does not supply a value. In that case, it would make the calling code somewhat simpler if this parameter value were supplied as a default value:

FAQ 2.05 What are the basics of local (auto) objects?
![]()
C++ extends the variable declaration syntax from built-in types (e.g., int i;) to objects of user-defined types. The syntax is the same: TypeName VariableName. For example, if the header file “Car.hpp” defines a user-defined type called Car, objects (variables) of class (type) Car can be created:

When control flows over the line labeled 1: Create an object, the runtime system creates a local (auto) object of class Car. The object is called a and can be accessed from the point where it is created to the } labeled 4: Destroy the object.
When control flows over the line labeled 2: Call a member function, the startEngine() member function (a.k.a. method) is called for object a. The compiler knows that a is of class Car so there is no need to indicate that the proper startEngine() member function is the one from the Car class. For example, there could be other classes that also have a startEngine() member function (Airplane, LawnMower, and so on), but the compiler will never get confused and call a member function from the wrong class.
When control flows over the line labeled 3: Call another member function, the tuneRadioTo() member function is called for object a. This line shows how parameters can be passed to member functions.
When control flows over the line labeled 4: Destroy the object, object a is automatically destroyed. If the Car class has some special cleanup activities that need to take place when an object goes away, the writer of the class would include a destructor in the class and the runtime system would automagically call the destructor (dtor) when the object goes away; see FAQ 20.03. Local objects such as a are sometimes called automatic objects or stack objects, and they are said to go out of scope at the } line.
UML uses the following notation to show a class Car that contains member functions startEngine() and tuneRadioTo():

FAQ 2.06 What are the basics of constructing objects using explicit parameters?
![]()
Constructors are special member functions that are called to initialize an object. If parameters are needed, the parameters can be supplied in the parentheses, (). If no parameters are needed on a local object, parentheses must not be provided. Here is an example:

When control flows over line 1, a local Car object is created and initialized by the class's default constructor. The default constructor is the constructor that can be called with no parameters (see FAQ 20.08).
When control flows over line 2, another local Car object is created and initialized, this time by passing two int parameters to a constructor of class Car. The parameters (100, 73) are presumably used to set up the object (e.g., initial values for various state variables). Line 1 and line 2 probably call different constructors (but see FAQ 2.04 on default parameters).
Note that in the following example b is not a Car object. Instead b is a function that returns a Car by value.

FAQ 2.07 What are the basics of dynamically allocated (new) objects?
![]()
C++ allows objects to be allocated dynamically using the new operator. Dynamic allocation is also known as allocating from the heap. As shown, a Car object can be allocated from the heap using the syntax new Car(). The result is stored in a CarPtr pointer. CarPtr is an alias for an auto_ptr, which is a “safe pointer type.” The typedef syntax establishes this alias relationship.

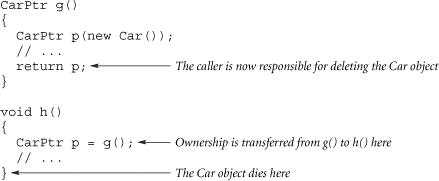
When control flows over the line labeled 1: Create an object, an object is created dynamically (from the heap). The object is pointed to by the pointer p. The object can be accessed from the point it is created until the CarPtr is destroyed at the } (line 4). Note however that the CarPtr can be returned to a caller. This line is analogous to (but not interchangeable with) the C code p = malloc(sizeof(Car)). Note that parameters can be passed to the constructor; e.g., p = new Car(100, 73);.
When control flows over the line labeled 2: Call a member function, the startEngine() member function is called for the object pointed to by p. The line labeled 3: Call another member function is similar, showing how to pass parameters to member functions of dynamically allocated objects.
When control flows over the line labeled 4: Destroy the Car object, the Car object pointed to by p is destroyed. If the Car class has a destructor, the runtime system automagically calls the destructor (dtor) when control flows over this line.
Note that dynamically allocated objects don't have to be destroyed in the same scope that created them. For example, if the function said return p;, the ownership of the Car object is passed back to the function's caller, meaning that the Car object won't be destroyed until the } of the caller (or the caller's caller if the caller does likewise, and so on):
Note to C programmers: It is generally considered bad form to use raw Car* pointers to hold the result of the new Car() operation. This is a big change from the way pointers are handled in the C language. There are many reasons for this change: the C++ approach makes “memory leaks” less likely (there is no explicit use of free(p) or delete p, so programmers don't have to worry about accidentally forgetting the deallocation code or jumping around the deallocation code), the C++ approach makes “dangling references” less likely (if C-like Car* pointers are used, there is a chance that someone will inadvertently access the memory of the Car object after it is deleted), and the C++ approach makes the code “exception safe” (if a C-like Car* were used, any routine that could throw an exception would have to be wrapped in a try...catch block; see FAQ 2.23).
FAQ 2.08 What are the basics of local objects within inner scopes?
![]()
C++ local objects die at the } in which they were created. This means they could die before the } that ends the function:

The line labeled 1: Create a Car object on each iteration is within the loop body, so a distinct Car object that is local to the loop body is created on each iteration.
Note that C++ allows loop variables (int i in the example) to be created inside the for parameters. Loop variables that are declared this way are local to the loop: they cannot be accessed after the } that terminates the for loop. This means that a subsequent for loop could use the same loop variable. Note that this is a new language feature, and compilers may not uniformly support this rule in all cases.
Also notice that, unlike C, variables do not have to be declared right after a {. It is not only allowable but also desirable to declare C++ variables just before they are first used. Doing so allows their initialization to be bypassed if the section of code they are in is bypassed, and it allows the introduction of other runtime variables in their initialization if the code is not bypassed. So there is never anything to lose, indeed there is sometimes something to gain, by declaring at first use.
FAQ 2.09 What are the basics of passing objects by reference?
![]()
Passing objects by reference is the most common way to pass objects to functions. C programmers often have a hard time adjusting to pass-by-reference, but it's generally worth the pain to make the transition.

Function f() illustrates pass-by-reference (the & between the type name and the parameter name indicates pass-by-reference). In this case, a is main()'s x object—not a copy of x nor a pointer to x, but another name for x itself. Therefore anything done to a is really done to x; for example a.startEngine() actually invokes x.startEngine().
Function g() illustrates pass-by-reference-to-const. Parameter b is the caller's object, just as before, but b has an additional restriction: it can only inspect the object, not mutate the object. This means g() has a look-but-no-touch agreement with its callers—g() guarantees to its callers that the object they pass will not be modified. For example, if a programmer erroneously called b.startEngine(), the compiler would detect the error and would issue a diagnostic at compile time (assuming startEngine() is not a const member function; see FAQ 2.17). Reference-to-const is similar in spirit to pass-by-value (see FAQ 2.10), but is implemented much more efficiently.
FAQ 2.10 What are the basics of passing objects by value?
![]()
Beware: passing objects by value can be dangerous in some situations. Often it is better to pass objects by reference-to-const (FAQ 2.09) than to pass them by value. For example, pass-by-value won't work if the destination type is an abstract base class (see FAQ 2.24) and can result in erroneous behavior at runtime if the parameter's class has derived classes (see FAQ 24.12, 28.04). However if the class of the parameter is guaranteed not to have derived classes, and if the function being called needs a local copy to work with, pass-by-value can be useful.

Since f()'s a is a copy of main()'s x, any changes to a are not reflected in x.
FAQ 2.11 What are the basics of passing objects by pointer?
![]()
Passing objects by pointer is not commonly used. The most common approaches are pass-by-reference and pass-by-auto_ptr. Pass-by-reference is used when the caller wants to retain ownership of the object (that is, when the caller wants to access the object after the call returns to the caller). Pass-by-auto_ptr is used when the caller wants to transfer ownership of the object to the called routine (that is, when the caller wants the object to get deleted before the called routine returns to the caller):

If the intent is for the caller to retain ownership of the object, pass-by-reference should generally be used. If the intent is for the ownership to be passed to the called routine, pass-by-auto_ptr should be used. About the only time pass-by-pointer should be used is when (1) the caller should retain ownership and (2) the called routine needs to handle “nothing was passed” (i.e., the NULL pointer) as a valid input. In the following example, note the explicit test to see if the pointer is NULL.

FAQ 2.12 What are the basics of stream output?
![]()
C++ supports C-style output, such as the printf() family of functions. However it is often better to use the native C++ output services. With the native C++ output services, output is directed to an output stream object. For example, cout is an output stream object that is attached to the process's standard output device, often to the terminal from which the program is run. Syntactically these C++ output services look as if they're shifting things into the output stream object. The <iostream> header is needed when using these services:

Line 1 prints the string "Hello world" followed by a newline character, '
'. This is analogous to the C statement, fprintf(stdout, "Hello world
"); thus cout is analogous to C's stdout, and cerr (not shown) is analogous to stderr.
Line 2 is logically equivalent to line 1: it prints the string “Hello world,” then it prints a newline character, '
'. This shows how the << operator can be cascaded—allowing multiple things to be printed with the same statement. This is analogous to the C construct fprintf(stdout, "%s%c", "Hello world", '
').
Line 3 also prints "Hello world" followed by a newline, but then it flushes the output buffer, forcing the characters to be sent to the operating system. This is normally not necessary with cout, but when output is being sent to a file it can be important to flush the output buffers at certain times, such as just before abort() is intentionally called. In C, flushing an output buffer is accomplished by calling fflush(stdout). Note that flushing the I/O buffers too much can slow down the application.
Line 4 is a shorthand version of line 3. The symbol endl prints a newline character, '
', followed by a flush symbol. Because endl flushes the buffer, it shouldn't be used very often since it can slow down the application.
FAQ 2.13 What are the basics of stream input?
![]()
C++ supports C-style input, such as the scanf() family of functions. However it is often better to use the native C++ input services. With the native C++ input services, information is read from an input stream object. For example, cin is an input stream object that is attached to the process's standard input device, often to the keyboard from which the program is run. Syntactically these C++ input services look as if they're shifting things from the input stream object. The <iostream> header is needed when using these services (the example uses stream output to prompt for the stream input):
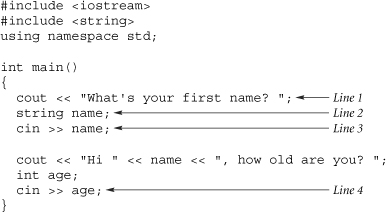
Line 1 prints the prompt. There is no need to flush the stream since cout takes care of that automatically when reading from cin (see the tie member function in the iostream documentation for how to do this with any arbitrary pair of streams).
Line 2 creates a string object called name. Class string is a standard class that replaces arrays of characters. string objects are safe, flexible, and high performance. This line also illustrates how C++ variables can be defined in the middle of the routine, which is a minor improvement over the C requirement that variables be defined at the beginning of the block.
Line 3 reads the user's first name from the standard input and stores the result in the string object called name. This line skips leading whitespace (spaces, tabs, newlines, and so on), then extracts and stores the whitespace-terminated word that follows into variable name. The analogous syntax in C would be fscanf(stdin, "%s", name), except the C++ version is safer (the C++ string object automatically expands its storage to accommodate as many characters as the user types in—there is no arbitrary limit and there is no danger of a memory overrun). Note that an entire line of input can be read using the syntax getline(cin, name);.
Line 4 reads an integer from the standard input and stores the result in the int object called age. The analogous syntax in C would be fscanf(stdin, "%d", &age), except the C++ version is simpler (there is no redundant "%d" format specifier since the C++ compiler knows that age is of type int, and there is no redundant address-of operator (&age) since the compiler passes the parameter age by reference).
FAQ 2.14 What are the basics of using classes that contain overloaded operators?
![]()
They're easy to use. But when you create your own, make sure the operators are intuitive and natural.
Here is an example that uses the standard string class:

The f() function takes two string objects that will remain unchanged (const string&; see FAQ 2.09).
Line 1 concatenates the first name, a space, and then the last name. This uses the overloaded + operator associated with class string.
Line 2 prints the resulting full name. This uses the overloaded << operator associated with class string.
FAQ 2.15 What are the basics of using container classes?
![]()
Templates are one of the most powerful code reuse mechanisms in C++. The most common use for templates is for containers. Container classes are used to create objects that hold other objects. There are many different container templates, including linked lists, vectors (arrays), sets, and maps. Container templates allow programmers to get the benefits of sophisticated data structures, such as binary trees that always stay balanced, hash tables, skip lists, and splay trees, without having to know anything at all about the details of those data structures.
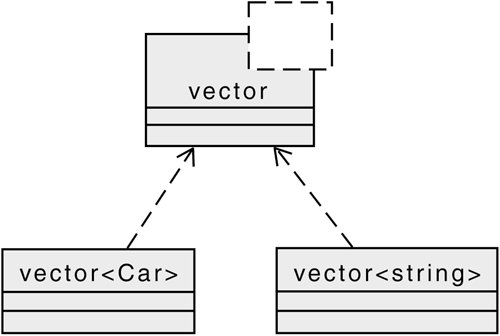
Templates look a little funny at first, but they're not that much different from normal classes once you get used to them. The only strange part is the angle brackets: a vector of Car is declared using the syntax vector<Car>. The typedef syntax is used for convenience: it creates easy-to-read synonyms such as CarList.

This sample code creates two vector objects: x is a vector of Car objects and y is a vector of string objects. This is analogous to creating two C-like arrays (Car x[3]; and string y[3];), but vector objects are more flexible, they can grow to an arbitrary size, they are safer, and they have a lot more services associated with them. See FAQ 28.13.
UML uses the following notation to show a template vector along with instantiations of that template vector<Car> and vector<string>.
FAQ 2.16 What are the basics of creating class header files?
![]()
The first step is to remember #ifndef.
When creating a class header file, the first thing to remember is to wrap the header in #ifndef, #define, and #endif lines, just as with C header files. The following shows the skeleton of the header file that defines C++ class Car.

This code might be stored in the header file "Car.hpp".
The public: and protected: parts of the class are different: normal user code (e.g., main()) can access only public: features. If normal user code tries to access anything in the protected: part, the user code would get a compile-time error (not a warning: a true error, something that would have to be fixed before getting the code to compile). This is called encapsulation, and is described further in FAQ 5.16.
Although public: and protected: are quite different with respect to encapsulation, they are very similar otherwise. The public: part can also contain data, and the protected: part can also contain member functions. In fact, they are completely symmetrical: data and member functions can be declared in either section. It's generally considered unwise (and unnecessary) to create public: data, but protected: member functions are fairly common and quite useful. For example, protected: member functions can be helper functions that are used mainly by the public: member functions (analogous to static functions within a module in C).
FAQ 2.17 What are the basics of defining a class?
![]()
By convention, the public: part goes first. The following example shows the header file that defines C++ class Car.

Line 1 declares a member function of class Car. This member function doesn't take any parameters. Note that C programmers use (void) to declare a function that takes no parameters, but this is not necessary in C++. Be warned that some C++ developers consider the (void) syntax in C++ code to be an indicator that the author of the code is still a warmed-over C programmer—that the author hasn't yet made the paradigm shift. This is an unfair judgment, but it might be wise to use () rather than (void) in C++ code.
Line 2 declares another member function, this time returning a bool (the bool data type has two values: true and false). The member function's name is designed to make sense in an if statement, e.g., if (myCar.isRunning())...The const on the right side means that the member function is an inspector—it promises not to change the object. This lets users know that the Car object won't suddenly change inside a statement such as if (myCar.isRunning()). It is a good idea to mark every member function that is logically an inspector with a const; otherwise the compiler will give error messages when someone calls one of these member functions via a reference-to-const or a pointer-to-const (see FAQ 2.09, 2.11).
Line 3 declares another member function, this time taking two parameters. Member functions that don't have a const on the right side are known as mutator member functions, since they can change the object. For example the statement myCar.tuneRadioTo("AM",770) probably makes changes to the Car object called myCar.
Line 4 declares a data member. By convention, data member names end with an underscore. This particular data member is presumably used by the isRunning() member function.
UML uses the following notation to show a class Car that contains member functions startEngine(), isRunning(), and tuneRadioTo(), and that contains data members called isRunning_, radioOnAM_, and radioFreq_:

FAQ 2.18 What are the basics of defining member functions?
![]()
Member functions are normally defined in the source file associated with the class (but see FAQ 13.01. For example, if the header file is called "Car.hpp", the source file might be called "Car.cpp". Here is an example of the header file Car.hpp:

Here is an example of the source file Car.cpp:
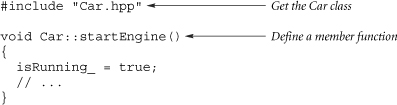
The line void Car::startEngine() tells the compiler that this is the definition of the startEngine() member function from the Car class. If this just said void startEngine() { ... } the compiler would think that a non-member function was being defined, as opposed to the startEngine() member function of the Car class.
The line isRunning_ = true; sets the protected: data member isRunning_ to true. If Car a; a.startEngine(); has been executed, this line would set a.isRunning_ to true (even though a.isRunning_ is protected: it does exist and can be accessed by member functions of the Car class).
FAQ 2.19 What are the basics of adding a constructor to a class?
![]()
A constructor (a.k.a. ctor) is a special member function that is called whenever an object of the class is created. This gives the class developer a chance to initialize the object's member data so that the rest of the member functions can assume that they have a coherent object to work with. Syntactically constructors are member functions with the same name as the class; they are not virtual, and they have no return type.
Like normal member functions, constructors are declared in the class's body, which normally appears in the class's header file. For example, the header file for class Car might be file Car.hpp. Here is an example showing the declaration of some constructors in header file Car.hpp:

The first constructor takes no parameters and is called whenever an object is created without parameters. For example, the first constructor is used to initialize the first two Car objects created in the following function , and the second constructor (the one that takes two parameters of type int) is used to initialize the third and fourth Car objects created in the following function f().

Constructors are often defined in the source file associated with the class. For example, the source file associated with class Car might be file "Car.cpp". Here is an example showing the definition of the first constructor in source file Car.cpp:

The line Car::Car() tells the compiler that this is the definition of a constructor of class Car. Thus constructors are normally of the form X::X(/*...*/).
The line : isRunning_ (false) initializes the protected: data member isRunning_ to false; radioOnAM_, radioFreq_, and horsepower_ are initialized similarly. This list of initializations between the : and the { is allowed only in constructors and is called an initialization list. Since the goal of the constructor is to initialize the object to a coherent state, all of an object's member variables should be initialized in every constructor.
Since the second constructor takes parameters, it probably uses these parameters to initialize the member variables in the Car object. For example the two parameters might be used to initialize the radio's frequency and the car's horsepower:

FAQ 2.20 What are the basics of adding a destructor to a class?
![]()
Every class can optionally have a destructor (a.k.a. dtor). A destructor is a special member function that is automatically called whenever an object of the class is destroyed. This feature of C++ allows the class developer to close any files the object has opened, release any memory the object has allocated, unlock any semaphores the object has locked, and so on. In general, this gives an object a chance to clean up after itself.
Syntactically a destructor is a member function whose name is a tilde character (~) followed by the name of the class. Like constructors, destructors cannot have a return type. Unlike constructors, destructors can, and often are declared with the virtual keyword, and a class can have only one destructor. Like all member functions, a destructor is declared in the class body, which normally appears in the class's header file. For example, the header file for class Car might be file Car.hpp.

Destructors are often defined in the source file for class Car, such as in file Car.cpp:
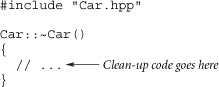
If a class doesn't have a destructor, the compiler conceptually gives the class a destructor that does nothing. Therefore if a class doesn't need to do anything special inside its destructor, the easiest thing to do is to not even declare a destructor. In fact, in applications that follow the guidelines of this book, a destructor is needed only in a relatively small percentage of the classes.
FAQ 2.21 What are the basics of defining a class that contains a pointer to an object allocated from the heap?
![]()
Overview: (1) Try to avoid this situation. (2) If it can't be avoided, use an auto_ptr.
Try to avoid defining a class that contains a pointer to an object allocated from the heap. For example, consider the situation where a car contains an engine. There are two choices: the preferred way would be for the engine object to be physically embedded inside the car object, and the undesirable way would be for the car object to contain a pointer to the engine object, where the car allocates the engine object from the heap. Here is a sample Engine class:

The car class shown in the following code, class Car, uses the preferred approach: each Car object physically contains its Engine object. Compared to using a pointer to an Engine allocated from the heap, the technique shown in class Car is easier, safer, and faster, and it uses less memory.

Although this is the preferred approach, sometimes it is necessary, or perhaps expedient, to allocate the inner object from the heap and have the outer object contain a pointer to the inner object. When this happens, an auto_ptr should be used:

Logically this second example is still a contains or has-a relationship, but physically the implementation is somewhat different. Note the three extra member functions that must be declared in the second version of class Car. These extra member functions are needed because an auto_ptr is used to hold the car's Engine object.
The most important message here is that it is much less dangerous to use auto_ptr than to use a raw hardware pointer, such as Car*. Thus the following technique should not be used.

The particular dangers of using raw hardware pointers are outlined later in the book, but for now simply use an auto_ptr as shown in the second example.
FAQ 2.22 What are the basics of global objects?
![]()
Although C++ allows global objects to be declared outside any class, it is generally better if global objects are declared as static data members of some class. Generally a static data member is declared in the protected: section of the class, and, if desired, public: static member functions are provided to get and/or set that protected: static data member.
For example, consider keeping track of the number of Car objects that currently exist. Since it would be quite cumbersome if every single Car object had to correctly maintain the current number of Car objects, it is better to store this value in a global variable, that is, as a static data member of the Car class. Since external users might want to find out how many Car objects exist, there should be a public: static member function to get that number. But since it would be improper for anyone but the Car class to change the value of this variable, there should not be a public: static member function to set the number of Car objects. The following class illustrates the static data member and the public: static access member function.

Note that static data members must be defined in a source file. It is a common C++ error to forget to define a static data member, and the symptoms are generally an error message at link time. For example, static data member Car::num_ might be defined in the file associated with class Car, such as file Car.cpp.
Unlike normal data members, it is possible to access static data members before the first object of the class is created. For example, it is possible to access static data member Car::num_ before the first Car object is created, as illustrated in the main() routine that follows:

The output of this main() routine is:
Before creating any cars, num() returns 0
After creating three cars, num() returns 3
It is also possible to use user-defined classes to define static data members. For example, if there were some sort of registry of Car objects and if the registry were conceptually a global variable, it would be better to define the registry as a static data member of the Car class. This is done just like the static int data member shown: just replace the type int with the type of the registry, and replace the initializer “= 0;” with whatever is appropriate as the initializer for the class of the registry.
FAQ 2.23 What are the basics of throwing and catching exceptions?
![]()
Exceptions are for handling errors. If a function cannot fulfill its promises for some reason, it should throw an exception. This style of reporting errors is different from the way many other programming languages report errors—many languages use a return code or error code that the caller is supposed to explicitly test. It sometimes takes a little while before new C++ programmers become comfortable with the C++ way of reporting errors.
In the example code, function processFile() is supposed to process the specified file. The file name is specified using an object of the standard string class. If the file name is not valid (for example, if it contains illegal characters) or if the file does not exist, processFile() cannot proceed, so it throws an exception. In the case of an invalid file name, processFile() throws an object of class BadFileName; in the case of a nonexistent file, it throws an object of class FileNotFound.
Functions isValidFileName() and fileExists() represent routines that determine if a given file name is valid and exists, respectively. As shown below, isValidFileName() always returns true (meaning “yes, the filename is valid”) and fileExists() always returns false (meaning “no, the file does not exist”), but in practice these routines would make system calls to determine the proper result.


try and catch are keywords. The code within the block after the try keyword is executed first. In this case, f() calls processFile(). In a real application, processFile() often succeeds (that is, it often returns normally without throwing an exception), in which case the runtime system continues processing the code in the try block, then skips the catch blocks and proceeds normally. In the case when an exception is thrown, control immediately jumps to the matching catch block. If there is no matching catch block in the caller, control immediately jumps back to the matching catch block in the caller's caller, caller's caller's caller, and so on, until it reaches the catch (...) block in main(), shown below. catch (...) is a special catch-all block: it matches all possible exceptions.

The throw() declarations after the signature of the various functions (e.g., throw() after the signature of function f() and throw(BadFilename, FileNotFound) after the signature of function processFile()) are the function's way of telling callers what it might throw. Functions that say throw() are effectively saying, “This function doesn't throw any exceptions.” Functions that say throw(BadFilename, FileNotFound) are effectively saying, “This function might throw a BadFilename object or a FileNotFound object but nothing else.”
FAQ 2.24 What are the basics of inheritance and dynamic binding?
![]()
Inheritance is a powerful tool that enables extensibility. It allows the software to capture the is-a or kind-of relationship (although as will be shown in FAQ 7.01, the phrase, “is substitutable for,” more accurately captures the true meaning of inheritance).
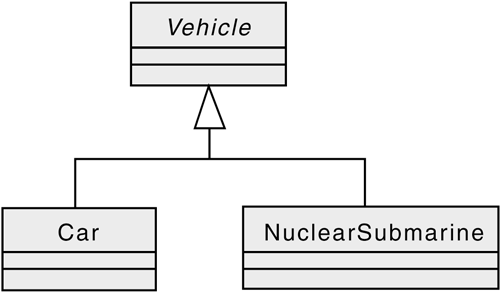
In the following example, class Vehicle is defined with = 0; after the declaration of the startEngine() member function. This syntax means that the startEngine() member function is pure virtual and the Vehicle class is an abstract base class, or ABC. In practice, this means that Vehicle is an important class from which other classes inherit, and those other derived classes are, in general, required to provide a startEngine() member function.

The idea with ABCs is to build the bulk of the application so that it knows about the ABCs but not the derived classes. For example, the following function is aware of the ABC Vehicle but is not aware of any of the derived classes.

If the ABCs are designed properly, a large percentage of the application will be written at that level. Then new derived classes can be added without impacting the bulk of the application. In other words, the goal is to minimize the ripple effect when adding new derived classes. For example, the following derived classes can be added without disturbing function f().

The reason these won't disturb the code in function f() (and recall, function f() represents the bulk of the application) is because of two features of C++: the is-a conversion and dynamic binding. The is-a conversion says that an object of a derived class, such as an object of class Car, can be passed as a base reference. For example, the following objects c and s can be passed to function f(). Thus the compiler allows a conversion from a derived class (e.g., a Car object) to a base class (e.g., a Vehicle reference).

The is-a conversion is always safe because inheritance means “is substitutable for.” That is, a Car is substitutable for a Vehicle, so it won't surprise function f() if v is in fact referring to a Car.
Dynamic binding is the flip side of the same coin. Whereas the is-a conversion safely converts from derived class to base class, dynamic binding safely converts from base class back to derived class. For example, the line v.startEngine() in function f() actually calls the appropriate startEngine() member function associated with the object. That is, when main() passes a NuclearSubmarine into f() (line f(s) in main()), v.startEngine() calls the startEngine() member function associated with class NuclearSubmarine. This is extremely powerful, since class NuclearSubmarine might have been written long after function f() was written and compiled and put into a library. In other words, dynamic binding allows old code (f()) to call new code (NuclearSubmarine::startEngine()) without the old code needing to be modified or even recompiled. This is the essence of extensibility: the ability to add new features to an application without significant impact to existing code. It is doable with C++, but only when the design considerations are carefully thought through ahead of time; it does not come free.
UML uses the following notation to show inheritance.