
Chapter 20. Constructors and Destructors
FAQ 20.01 What is the purpose of a constructor?
The constructor turns a pile of incoherent, arbitrary bits into a living object. It initializes the object's internal data members, but it may also allocate resources (memory, files, semaphores, sockets, and so on). The word “ctor” is shorthand for the word “constructor.”
The constructors for class X are member functions named X. Here is an example.

There can be more than one constructor for a class. Each constructor has the same name, so the compiler uses their signatures to uniquely identify them.
FAQ 20.02 What is C++'s constructor discipline?
A constructor is automatically called at the moment an object is created.
Descartes said, “I think, therefore I am.” The C++ variation of Descartes' statement is “I am, therefore I can think.” In other words, every object that exists (“I am”) has been initialized by one of the class's constructors (“I can think”). Except for pathological cases, by the time an object is accessible, it has already been initialized by its constructor.
The developers of a class provide a set of constructors that define how objects of that class can be initialized. When users create objects of that class, they must provide arguments that match the signature of one of the class's constructors. Constructors enhance encapsulation since they force users to create objects in one of the officially supported ways. Users cannot initialize an object's state directly, because this might place the object in an incoherent or illegal state.
In the example from the previous FAQ, the constructor for class Battery is the member function Battery::Battery(int initialCharge). This constructor initializes the protected: data member charge_ to the value passed as the parameter to the constructor. The constructor is called twice in main(), once when yourDiscountBattery is created and once when myNameBrandBattery is created.
FAQ 20.03 What is the purpose of a destructor?
The destructor is the last member function ever called for an object. The destructor's typical purpose is to release resources that the object is holding. The word “dtor” is shorthand for the word “destructor.”
A class can have at most one destructor. For a class named X, the destructor is a member function named ~X().
Just as a constructor turns a pile of incoherent, arbitrary bits into a living object, a destructor turns a living object into a pile of incoherent, arbitrary bits. A destructor blows an object to bits.
FAQ 20.04 What is C++'s destructor discipline?
If the class of an object has a destructor, C++ guarantees that the destructor is called when the object dies. A local (auto) object dies at the close of the block ({...}) in which it was created (that is, when it is conceptually popped from the runtime stack). An unbound temporary object dies at the end of the outermost expression in which the temporary was generated (often this is at the next ;). A member object dies when its containing object dies. An array element dies when its array dies. An object allocated via new (dynamically) dies when the object is deleted. With a static object, death occurs sometime after main() finishes.
Everything but dynamically allocated objects (that is, local objects, temporary objects, member objects, static objects, and array elements) are destructed in the reverse order of construction: first constructed is last destructed. In the following example, b's destructor is executed first, then a's destructor.

Warning: Do not use longjmp with C++ because it subverts the guarantee that destructors will be called.
FAQ 20.05 What happens when a destructor is executed?
The destructor automatically calls the destructors for all member objects and all immediate nonvirtual base classes. First, the destructor's body ({...}) is executed, then the destructors for member objects are called in the reverse order that the member objects appear in the class body, then the destructors for immediate base classes are called (in the reverse order they appear in the class declaration). Virtual base classes are special—their destructors are called at the end of the most derived class's destructor (only).
For example, suppose lock(int) and unlock(int) provide the primitives to manage mutual exclusion. The C++ interface to these primitives would be a Lock class, whose constructor calls lock(int) and whose destructor calls unlock(int).


A whimsical developer might rename class Lock to class Critical, so that if the user code declared an object named section, Lock lock(42) would then become Critical section(42). But regardless of the names of the class and its object, the important point is that there is no need to explicitly unlock the semaphore. This eliminates a potential (and dangerous!) source of errors.
FAQ 20.06 What is the purpose of a copy constructor?
It initializes an object by copying the state from another object of the same class.
Whenever an object is copied, another object (the copy) is created, so a constructor is called (see FAQ 20.02). This constructor is called the copy constructor. If the class of the object being copied is X, the copy constructor's signature is usually X::X(const X&).
One way to pronounce X(const X&) is X-X-ref (pretend the const is silent). The first X refers to the name of the member function, and the X-ref refers to the type of the parameter. Some people prefer the shorthand X-X-ref to the phrase copy constructor.
In the following example, the copy constructor is MyString::MyString(const MyString&). Notice how it initializes the new MyString object to be a copy of the source MyString object.

FAQ 20.07 When is a copy constructor invoked?
When an object is passed by value, returned by value, or explicitly copied. Here is an example showing all three situations.

The (annotated) output of this program is

Note that pass-by-value calls the copy constructor if the caller supplies another object of the same class. Supplying something else may invoke a different constructor. Similar comments apply to return-by-value.
FAQ 20.08 What is the “default constructor”?
It's the constructor that can be called with no arguments.
For a class Fred, the default constructor is often simply Fred::Fred(), since certainly that can be called (and in this case, must be called) with no arguments. However it is possible (and even likely) for a default constructor to take arguments, provided they are given default values.

In either case, the default constructor is called when an object is created without any initializers. For example, object x is created by calling Fred::Fred(int,int) with defaulted arguments (3,5).

Similarly the default constructor (in this case, including the defaulted parameters) is called for each element of an array. For example, each element of array a and vector b (see FAQ 28.13) is initialized by calling Fred::Fred(int,int) and passing the defaulted arguments (3,5). However, vectors are more powerful than arrays, since vectors can use something other than the default constructor when initializing the array elements (an especially important feature for those classes that don't have a default constructor). For example, the 10 elements of vector c are initialized with Fred(7,9) rather than the default choice of Fred(3,5):
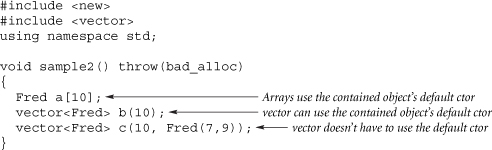
Note that adding an empty pair of parentheses after a declaration is not the same as calling the default constructor. In the following example, x is an object of class Fred, but y is declared to be a function that returns a Fred by value; y is not a Fred object.

FAQ 20.09 Should one constructor call another constructor as a primitive?
No. Even though it is possible, it won't do what the programmer wants.
Dragons be here: if a constructor of class Fred calls another constructor of class Fred, the compiler actually initializes a temporary local object of class Fred. It does not use the call to initialize the this object.
Both constructors can be combined by using a default parameter or their common code can be shared in a private: init() member function, but one constructor should not directly call another constructor. Here is an example of an init() function.

FAQ 20.10 Does the destructor for a derived class need to explicitly call the destructor of its base class?
No. The runtime system calls the destructor for the base class after the destructor for the derived class finishes executing.
Never call a destructor explicitly. The only exception to this is the fairly esoteric case of destructing an object that was initialized by the placement new operator (see FAQ 12.14).
FAQ 20.11 How can a local object be destructed before the end of its function?
![]()
The most important message is to not explicitly call a local object's destructor. The language guarantees that the object's destructor will be called again at the close of the scope in which the local was created (see FAQ 20.04). So if the destructor is called explicitly, it will be called again at the close of the scope, which can have disastrous results. Bang; you're dead.
The easiest way to make sure a local object is destructed before the end of its scope is to insert a pair of braces (that is, a new scope) so that the object will be destructed at the right time. For example, suppose the (desirable) side effect of destructing a local File object is to close the File. Now suppose a local File object needs to be closed before the end of the scope (i.e., the }) of its function. In this case simply add an extra pair of braces to scope the lifetime of the object:

In cases where this extra pair of braces cannot be added, add an extra member function that causes the destructor's desirable side effects to occur. This member function should mark the object so that the destructor, which will inevitably be called at the close of the object's scope, will be able to tell if the side effects have already happened. For example, a close() member function could be added to the File class, and that member function could be called where the file should be closed:

The close() member function could mark the object so the destructor knows not to reclose the file, such as setting the underlying file handle to some invalid value such as -1. To avoid duplication of code in the destructor and the close() member function, the destructor could simply call the close() member function, and the close() member function could check to see if the file handle is in the “already closed” state.
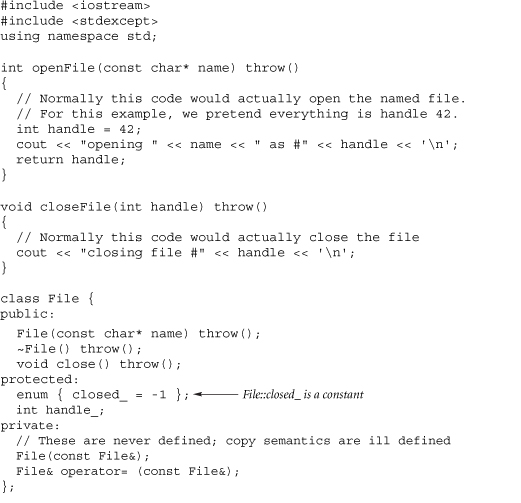

The output of this program follows.
====== without throwing an exception ======
opening sample.txt as #42
after open, before throw-or-close
closing file #42
after close
====== with throwing an exception =========
opening sample.txt as #42
after open, before throw-or-close
closing file #42
exception caught; note that the file still gets closed!
It is important to note that closeFile() is called exactly once per open file, whether or not an exception is thrown or the x.close() instruction is reached. Even if x.close() were explicitly called twice, the underlying file would only be closed once.
FAQ 20.12 What is a good way to provide intuitive, multiple constructors for a class?
Use the named constructor idiom.
Constructors always have the same name as the class, so the only way to differentiate between the various constructors of a class is by the parameter list. If there are numerous overloaded constructors, the differences can become somewhat subtle and subject to error.
With the named constructor idiom, all the constructors are declared as private: or protected:, and the class provides public: static member functions that return an object. These static member functions are the so-called named constructors. In general there is one such static member function for each different way to construct an object.
For example, consider a Point class that represents a position on a plane. There are two different constructors corresponding to the two common ways to specify a point on a plane: rectangular coordinates (X and Y) and polar coordinates (radius and angle). Unfortunately the parameters for these two coordinate systems are the same (two numbers), so the overloaded constructors would be ambiguous. For example, if someone created a point using Point(5.7, 1.2), the compiler wouldn't know which coordinate system (that is, which constructor) to use.
One way to solve this ambiguity is to use the named constructor idiom:

Now the users of Point have a clear and unambiguous syntax for creating Points in either coordinate system:

Note that the constructor(s) must be in the protected: section, not the private: section, if the class will have derived classes.
The Named Constructor Idiom can also be used to make sure objects are always created via new. In this case the public: static member functions (the named constructors) should allocate the object via new and should return a pointer to the allocated object.
FAQ 20.13 When the constructor of a base class calls a virtual function, why isn't the override called?
C++ is ensuring that member objects are initialized before they are used.
Objects of a derived class mature during construction. While the base class's constructor is executing, the object is merely a base class object. Later, when the derived class's constructor begins executing, the object matures into a derived class object. If a virtual function is invoked while the object is still immature, the immature version of the virtual function is called. It may sound confusing, but it's the only sensible way to do it without having across-the-board reference semantics.
For example, suppose class Derived overrides an inherited virtual function f(), and Base::Base() calls f(). Since the object is a Base during the execution of Base::Base(), Base::f() is invoked. If C++ allowed Base::Base() to call Derived::f(), Derived::f() might invoke member functions on a member object that had not yet been constructed!

The output of this program follows.
Base ctor
Base::f()
MemberObject ctor
Derived ctor
====
Derived::f()
MemberObject used
If C++ allowed Base::Base() to call Derived::f(), m_.fred() would be called before m_ was constructed.
C++ programmers need to be aware that Java does things quite differently, and therefore Java has a completely different problem. In Java, the derived class's override does get called when the base class's constructor invokes a method. This means that the derived class's override cannot assume that the derived class's constructor was run before the member function is called, so member variables that the derived class's constructor sets to some non-null state may in fact still be null when the override is called.
Neither the C++ approach nor the Java approach is a clear winner in terms of being intuitive and lacking surprises. So the most important point is to understand the differences and be prepared for a learning curve when moving between the two languages.
FAQ 20.14 When a base class destructor calls a virtual function, why isn't the override called?
C++ is helping ensure that member objects are not used after destruction.
Just as an object of a derived class matures into a derived class object during construction, it reverts back into a base class object during destruction.
Extending the example from the previous FAQ, if Base::~Base() calls f(), Base::f() is invoked (rather than Derived::f()) because the object has already reverted to a mere Base.
This is the right thing to do. If Base::~Base() could call Derived::f(), the destructed MemberObject would be used, leading to unpredictable results.
Many people don't think that this rule is intuitively obvious, either. Once again, it is an issue of reference semantics versus value semantics, and C++ was designed to maximize compatibility with C. And once again, Java does things differently, which causes its own set of problems.
FAQ 20.15 What is the purpose of placement new?
It's a way to pass parameters to the allocator rather than just to the constructor.
Allocating an object from the heap, such as new Fred(5,7), is a two-step process: first an appropriately sized and aligned block of uninitialized memory is allocated from the heap, then the constructor is called with the this pointer pointing to that block of memory. Parameters are often passed to the constructor (for example, the above example passes (5,7)), but occasionally parameters also must be passed to the allocation step. For example, if there was a special allocator that used a particular pool of memory, it might be necessary to pass a reference to that pool of memory to the allocation step, that is, to new itself: new(myPool) Fred(5,7).
Another common reason to pass a parameter for the allocation step is to pass a pointer to a particular preallocated region of memory. For example, if pointer p is a void* that points to a pile of memory that is at least sizeof(Fred) bytes long and is appropriately aligned, one could say new(p) Fred(5,7). This would construct a Fred object at the location pointed to by p (that is, it would pass p as the this pointer to Fred's constructor) and would ultimately return a Fred* that would point to the same location that void* p points to. For example,

Line 1 creates an array of sizeof(Fred) bytes of memory, which is big enough to hold a Fred object. Line 2 creates a pointer p that points to the first byte of this memory (experienced C programmers will note that this step is unnecessary; it's there only to make the code more obvious). Line 3 essentially calls the constructor Fred::Fred(). The this pointer in the Fred constructor is equal to p. The returned pointer f is equal to p.
Passing a void* pointer with the placement new syntax should be used only when it is essential to place an object at a particular location. For example, when writing an operating system, the placement new syntax could be used to place a Clock object at a particular memory-mapped I/O timer device. Neither the compiler nor the runtime system make any attempt to check whether the passed pointer points to a region of memory that is big enough and is properly aligned for the object being created. For example, if Fred objects need to be aligned on a 4-byte boundary but the supplied pointer p isn't properly aligned, it could be a serious (and subtle) disaster. You have been warned.
Also, the programmer takes sole responsibility to deallocate the object when the placement new syntax is used. This is done by explicitly calling the destructor, which is one of the few times a destructor should be called explicitly:
