
Chapter 33. High-Performance Software
FAQ 33.01 Is bad performance a result of bad design or bad coding?
All too often, bad performance is due to bad design.
When bad performance is due to bad coding practices, the correction is relatively inexpensive. However, when OO has been used improperly, the design is usually broken and performance problems are not easily repaired.
Improper inheritance is a common cause. When inheritance is used improperly, the design often becomes brittle and performance-related changes are prohibitively expensive. For example, some designs use inheritance as the means to put objects into a container. To put objects in a List, for example, they inherit from a particular base class, often called ListElement, ListItem, or Listable. The apparent motivation is to share the next pointer among all the derived classes, but the cost is enormous. In particular, the List class loses type safety (not all things that are listable should be linked into the same list), and most important, user code becomes tacitly aware of the technique used to implement the list. This implementation dependency can inhibit performance tuning. These costs are manageable on a small (“toy”) project, but in a larger, more sophisticated application or system, the costs of improper inheritance become unbearable.
A better solution for the container problem is to use templates for type safety and design a proper abstraction that hides the “listness” from users. If abstractions are properly designed, the answer to “Would it disturb user code if I changed this particular data structure from a linked list to an array?” is “No.” This means that the abstraction allows late life-cycle performance tuning, since it allows changing data structures or algorithms on an individual container-by-container basis. Code sharing among template classes can be accomplished by inheriting from a nontemplate base class.
FAQ 33.02 What are some techniques for improving performance?
![]()
The first step is knowing where the bottleneck is and then trying some of the following techniques. For example, if the bottleneck is CPU cycles, the application is said to be CPU bound; if the bottleneck is the network, the application is said to be network bound. Applications can also be database bound, I/O bound, memory space bound (a.k.a. thrashing), and so on. The important insight is that the techniques that work in one situation will either be a waste of time or perhaps even make performance worse in another situation. Measure, measure, measure. Then make your changes.
One technique that sometimes helps is reducing the number of expensive operations by using more CPU cycles. If the application is I/O bound, database bound, or network bound, making the application run fast means minimizing these expensive operations even if that might increase the number of CPU cycles consumed. For example, implementing a caching scheme increases the number of CPU cycles consumed, but it can reduce the number of expensive database operations required.
Another technique that can sometimes make an application run faster is making it more flexible. A flexible system can often be twisted to work around unnecessary requests that hit the database or network. This is counterintuitive: most developers equate increased flexibility with greater processing overhead. Nonetheless, flexibility can help make things faster in many (but not all) situations.
If the application is network bound or database bound, it may help to increase the granularity of objects that are transmitted through the wire and/or to a database and to decrease the granularity of in-memory-only objects.
If the application is thrashing (that is, using most of the computer's available memory), the goal is to reduce the size of the working set (that is, the number of pages that need to be in memory to execute the application's typical operation). There are two normal cases: either the pages that need to be in memory are mostly code or they are mostly data. In the case where most pages of memory are code pages, paradoxically making more functions inline can sometimes help. This is because the goal is to reduce the working set, not to reduce the size of the executable. If the application has improved locality, the working set can sometimes go down even though the application's executable size goes up. This is counterintuitive: most developers assume that applications that are thrashing need to be made smaller. Measure, measure, measure.
Another technique that can sometimes reduce thrashing is reorganizing the physical placement of member functions within source files. For example, a profiling tool can determine which member functions are called often and which are called rarely; then the commonly used member functions can be moved into a single source file. Even though this makes it harder to find all the member functions of a class, it has the effect of bringing all the commonly used code into the same group of memory pages, thus reducing the size of the working set.
In the case where most pages of memory are data, caches should be avoided, deeply nested function calls should be avoided, freestore should be limited, and care should be taken to avoid fragmenting memory. And of course memory leaks should be plugged (see FAQ 31.01).
If the bottleneck is the machine's CPU (that is, the application is CPU bound), start with limiting unnecessary use of freestore and using initialization lists in constructors (see FAQ 22.01). Most of the remaining FAQs in this chapter deal with CPU-bound applications, but some also help database-bound, I/O-bound, network-bound, and memory-bound applications as well.
In any event, the process cannot even begin until everyone agrees on the problem. The tuning effort should be focused on areas that deliver the most bang per hour invested.
FAQ 33.03 What is an advantage of using pointers and references?
Flexibility, with a likely cost in CPU cycles.
Almost all flexibility in software comes with an extra layer of indirection (arrays, dynamic data structures, recursion, and so on). Not surprisingly, dynamic binding also depends on an extra layer of indirection. So using pointers and references, as opposed to using local and member objects directly, offers additional flexibility in the form of polymorphism and dynamic binding (see FAQ 5.04).
Here is a small hierarchy with a base class and a derived class.

Here is a class whose objects have-a pair of Derived objects. One of these has-a relationships uses a pointer to an object allocated from the heap (remote ownership; see FAQ 30.08); the other uses a direct member object.

Note that the behavior of Fred::method() depends on which type of object is pointed to by member x_. Even though the constructor initializes x_ to point to a Derived object, other member functions may change this pointer so that it points to an object of a different derived class, thus changing the behavior of Fred::method() as the following example shows. First, here is a second derived class.

Here is a member function of class Fred that changes pointer x_ so that it points to a Derived2 object rather than a Derived object.

This shows the flexibility advantages of using pointers and freestore. If the application is database bound or network bound or I/O bound, this sort of flexibility can be used to improve performance in some cases (see FAQ 33.02). However if the application is CPU bound and the Fred object happens to be a bottleneck, read the next FAQ.
FAQ 33.04 What is a disadvantage of lots of references and pointers?
In some cases, they may degrade the application's performance if it is CPU bound.
In the previous FAQ, member y_ is a Derived object rather than a pointer to an object. In addition to reducing flexibility, embedding an object inside another object like this makes it more expensive to copy a Fred object (the state of the Derived object must be copied, rather than just a pointer to the object). However objects are usually accessed more often than they are copied, so reducing the number of layers of indirection can make the application perform better.
One way that embedding an object inside another (as in y_ in the previous FAQ) can improve performance over using a pointer (as in x_ in the previous FAQ) is by inlining virtual function calls. Virtual function calls can be inlined only when the compiler can statically bind to the function, that is, when it knows the object's exact class. If a function doesn't do very much (a good candidate for inlining), then inline expansion of the function can improve performance significantly. As an extreme example, a simple fetch function (which might occur in a member function that gets a data member's value) might do only 3 CPU cycles worth of work, yet including the overhead of the virtual function call might cost a total of 30 cycles. In this case, it would take 27 + 3 cycles to do 3 cycles worth of work. If this were on a critical path and the operation could be inlined, reducing the overhead of this operation by a factor of 10 could be significant.
In the example that follows, the call x.sample() in main() can be statically bound to Fred::sample(), because the exact class of local object x is known to be Fred. Furthermore, since that member function is defined inline, the call can be inlined. Similarly the call d_.f() in Fred::sample() is known statically to invoke Derived::f(), this time because member d_ is known to be exactly a Derived; since Derived::f() is also inline, the call can be inlined. Thus the entire call graph starting at main()'s x.sample() collapses into nothing: the only code that will be executed is the code that happens to be within Derived::f(). However the call to b_->f() in sample2() cannot be inlined even though b_ apparently points to a Derived, since the compiler has to assume that some other member function might change b_ so that it points to some other derived class (see FAQ 33.03).


Not all compilers are guaranteed to perform these optimizations, but many do in practice.
FAQ 33.05 How else can member objects improve performance over pointers?
By reducing the number of freestore allocations and the fragmentation of memory.
In a CPU-bound application, freestore operations are generally very slow primitives: the more objects that are allocated from the freestore, the worse the performance. By moving the member object physically inside the outer object, as shown in d_ in FAQ 33.04, there are fewer freestore operations.
In addition, memory can become fragmented when the freestore is used excessively. For example, an entire page of memory may need to be brought into RAM just because a small piece is being used, even though 99% of the page is not being used. If this happens frequently, it can lead to thrashing, which can significantly degrade performance. By moving the member object physically inside the outer object, as shown in FAQ 33.04 the memory is less fragmented.
In some extreme performance-sensitive applications, cache misses can be a significant problem. In these cases, data structures must be carefully laid out to minimize the number of cache lines that need to be brought into the CPU, which again means minimizing fragmentation.
FAQ 33.06 Which is better, ++i or i++?
++i is better unless the old value of i is needed.
The expression i++ usually returns a copy of the old state of i. This requires that an unnecessary copy be created, as well as an unnecessary destruction of that copy. For built-in types (for example, int), the optimizer can eliminate the extra copies, but for user-defined (class) types, the compiler retains the extra constructor and destructor.
If the old value of i is needed, i++ may be appropriate; but if it's going to be discarded, ++i makes more sense. Here's an example.

The output of this program follows.
![]()
The postfix increment creates two copies of the Number—the local object inside Number::operator++(int)—and the return value of the same (a smarter compiler would notice that the returned object is always the local variable old, thus avoiding one of the two temporary copies). The final output line is the destruction of main()'s n.
Note that the postfix increment operator, Number::operator++(int), can be made to return void rather than the Number's former state. This puts the performance of n++ on a par with ++n but forfeits the ability to use n++ in an expression.
FAQ 33.07 What is the performance difference between Fred x(5); and Fred y = 5; and Fred z = Fred(5);?
In practice, none. Therefore, use the one that looks most intuitive. This looks-most-intuitive notion depends on the situation—there is no one-size-fits-all guideline as to which is best.
Each of the three declarations initializes an object of type Fred using the single-parameter constructor that takes an int (that is, Fred::Fred(int)). Even though the last two definitions use the equal sign, none of them use Fred's assignment operator. In practice, none of them creates extra temporaries either.

For most commercial-grade C++ compilers, the copy constructor is not called and the output of the program is as follows.
![]()
Because they cause the same code to be generated, use the one that looks right. If class Fred is actually Fraction and 5 is the value of the numerator, the clearest is the second or third. If Fred is actually Array and 5 is the length of the Array, the clearest is the first or the third.
Note that if the user cannot access the copy constructor (for example, if the copy constructor is private:), only the first example is legal. Assuming that the compiler makes the appropriate optimization (a fairly safe assumption), the copy constructor isn't actually called; the user needs access to it as if it were called.
FAQ 33.08 What kinds of applications should consider using final classes and final member functions?
Performance-sensitive applications that are CPU bound.
Final classes and final member functions can squeeze a bit of extra CPU performance out of flexible applications. They are useful only in applications that are CPU bound (see FAQ 33.02) and even there, only on the critical path through those applications.
FAQ 33.09 What is a final class?
A final class (also known as a leaf class) is a class that permanently forbids derived classes.
A class should be declared final only if the designers have decided to permanently forbid any future classes from deriving from the final class. A class should not be declared final merely because it doesn't happen to have any derived classes in the current application. An example follows.
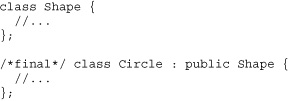
C++ doesn't support a keyword for “final,” so a comment is typically used. This means that the finality of a class is enforced by code reviews rather than by the compiler. However, it is not hard to get the compiler to enforce the class's finality: simply make the constructors private: and provide public: static create() member functions (the named constructor idiom; see FAQ 16.08). This will prevent derived classes from existing since the derived class wouldn't be able to call the (private:) constructor of the final class.
A final class should not have any protected: data members—all its data members should be private:. Similarly, a final class should not declare any new virtual functions (though it often overrides inherited virtual functions).
Caution should be used before declaring a class to be final. Nonetheless, doing so is sometimes useful, as demonstrated in FAQ 33.12.
FAQ 33.10 What is a final member function?
A final member function (also known as a leaf member function) is a member function that derived classes are permanently forbidden from overriding.
A member function should be declared final only if the designers have decided to permanently forbid any future class from overriding the member function. A member function should not be declared final merely because it doesn't happen to be overridden in the current application. An example follows.

Non-virtual member functions are implicitly final since a non-virtual member function should generally not be redefined in a derived class (see FAQ 29.02). Similarly, all member functions of a final class are implicitly final member functions because a final class isn't allowed to have derived classes (see FAQ 33.09).
As with classes, the finality of member functions is enforced by code reviews rather than by the compiler.
A final member function should not be marked with the virtual keyword even if it happens to be an override of a virtual function. If the final member function is not an override of a virtual from a base class, the easiest way to make it final is to not use the virtual keyword.
Caution should be used before declaring a member function to be final. Nonetheless doing so is sometimes useful, as demonstrated in FAQ 33.12.
FAQ 33.11 How can final classes and final member functions improve performance?
By eliminating the overhead associated with dynamic binding.
Final member functions can be called using full qualification (“::”). This allows the compiler to employ static binding, thereby reducing or even eliminating the cost of dynamic binding. If care is taken, this can allow virtual functions to be inlined, thus effectively eliminating the CPU overhead associated with the added flexibility brought by virtual functions. An example follows.

The full qualification (that is, the Circle:: part of c.Circle::draw()) is safe because final member functions are never overridden in derived classes. Function sample(Circle&) would also be safe if class Circle were final, since all members of a final class, including Circle::draw(), are implicitly final.
Note that it is (hopefully) somewhat uncommon to have lots of functions that take derived class references, such as sample(Circle&) in the example (see FAQ 33.14).
FAQ 33.12 When should a nonfinal virtual function be invoked with a fully qualified name?
Almost never. The one situation where full qualification is appropriate and useful is where a derived class needs to invoke a member function from a base class. In this case the derived class uses full qualification (“::”) to make sure the base class member is invoked, particularly in cases when the member function has been overridden in a derived class.
However, normal user code should avoid full qualification. That is, when x is a Fred& and f() is a virtual member function of class Fred, normal user code should use x.f() rather than x.Fred::f(). This is because full qualification subverts dynamic binding. If the actual class of the referent is something derived from Fred, the wrong member function may be invoked. An example follows.

In sample(Circle& c), if c actually refers to a derived class of Circle that overrides the hide() member function, the call to c.Circle::hide() invokes the wrong member function.

FAQ 33.13 Should full qualification be used when calling another member function of the same class?
Only if the called member function is a final member function.
If D::f() calls this->g(), full qualification (for example, this->D::g()) should be used only if D::g() is a final member function or D is a final class.

Although it seems as if D::f() should be able to use full qualification when calling D::g(), such a thing is dangerous and invokes the wrong function in some cases. For example, if the this object were actually of a further derived class that has an override of g(), the wrong function would be invoked:

Note that this is simply a specialization of the guideline presented in FAQ 33.12.
FAQ 33.14 Do final classes and final member functions cause a lot of code duplication?
![]()
Some, but in practice the cost is insignificant if the application is designed according to the guidelines presented in this FAQ.
First, here is a description of the problem we're trying to solve. It seems inevitable that someone someday somewhere may come up with a reason to inherit from a final class and/or override a final member function. When this becomes desirable, the workaround will probably involve some code duplication. From the example in FAQ 33.12, if someone someday somewhere found it useful to override the Circle::draw() member function, they would instead have to copy the Circle class's code and create a modified draw() member function.
This code duplication has a nonzero cost. Indeed in small projects the volume of code within the derived classes is a significant portion of the whole system, which means that the cost can be noticeable on a small enough project. And for those unfortunate souls who believe that inheritance is for reuse (it's not; see FAQ 8.12), disallowing inheritance is equivalent to saying, “Don't reuse this.”
However, on a large project that is designed according to the principles in this book, the cost of this sort of code duplication is normally insignificant, especially if final classes and member functions are used judiciously (see FAQs 33.09, 33.10). This is one of the many ways in which large projects differ from small projects. In particular, in a large project the most important goal is the stability of the design, not the reusability of the code; and within the code the most important asset is the code that uses base class references, not the code in the derived classes. On small projects, reuse is more important than stability, and the code within the derived classes is a large portion of the total, but that mentality is not scalable. Applying a small project mentality to a large project is a recipe for project failure. When working on a large project, do not extrapolate lessons learned on small projects (see FAQ 39.08).
A key design goal of most OO applications, especially large OO applications, is to allow new derived classes to be added without affecting existing code (remember: stability, not reuse per se). Part of this goal is achieved by building the bulk of the software so that it is ignorant of the derived classes. What this normally boils down to is making most parameters to be references/pointers to the abstract base classes rather than references/pointers to the concrete derived classes. Continuing the example from FAQ 33.09 the application as a whole should contain very few (ideally no) functions with parameters of type Circle& or Circle*; a much larger number of functions should take parameters of type Shape& or Shape*.
The next step in a good OO design is minimize the amount of complex decision logic within the functions (see FAQ 27.03). Part of this goal can be achieved by including important functionality of the derived classes in the base class's interface. This is a balancing act—adding too many member functions to the base class makes it difficult for some derived classes, but adding too few requires the users of the base class to use dynamic typing. Nonetheless, the flexibility and value of the system rest on the ability of the designer to find the best possible balance.
The result of applying these rules is both stability and reuse. But the reuse is what the derived classes can give, not what they can get. The reuse is the reuse of all the code that uses the abstract base class references and pointers, which (hopefully) is the bulk of the system. In other words, the derived classes don't inherit so that they can have what the base class has; they inherit so that they can be what the base class is. Inheritance is not about what the derived class can get; it is about providing a stable and consistent set of semantics to users of base class references and pointers. Inheritance is not for reuse (see FAQ 8.12).
FAQ 33.15 Why do some developers dislike final member functions and final classes?
![]()
Because they don't see the big picture and/or because they don't follow the design guidelines presented in FAQ 13.14.
Suppose class Circle inherits from abstract base class Shape, and suppose Circle is declared to be final (see FAQ 33.09 for the code). If the system was designed using the principles from FAQ 33.14, then there are very few Circle& used in the application as a whole. Therefore, there is no inherent pressure for new classes to inherit from Circle; they can just as easily inherit from Shape.
Even if a new derived class could have benefited from inheriting some code from Circle, the code bulk of class Circle would be very small compared to the rest of the system, particularly on large systems, so any cost savings would be insignificant. The larger the system, the less significance any individual class has.
The moral is to focus on the big picture.
FAQ 33.16 Can a programming language—rather than just the compiler—affect the performance of software?
Yes.
Sometimes it is assumed that software performance is limited only by the compiler, not by the programming language. However, this is generally not the case. The efficiency of the executable is, at least in part, due to the language as well as the compiler. For example, compilers for dynamically typed OO languages cannot statically resolve member function invocations, because every member function is virtual and every object is passed by pointer. Therefore, every member function dispatch needs to go through the dynamic-binding mechanism, which generally costs a function call. Thus, a member function with 10 statements in many OO languages almost necessarily costs at least 10 function calls. The efficiency of the dynamic-binding mechanism can be improved, but it rarely can be improved enough to inline-expand these calls (a technique called customization can alleviate some of these issues in dynamically typed OO programming languages).
Languages such as C++ require the compiler to work harder, since not all member functions are necessarily virtual, and even if they are all virtual, not all objects are allocated from the heap. In addition, statically bound member functions can be expanded inline (see FAQ 13.01).