
3
How the Internet Works

Before you jump into hunting for bugs, let’s take some time to understand how the internet works. Finding web vulnerabilities is all about exploiting weaknesses in this technology, so all good hackers should have a solid understanding of it. If you’re already familiar with these processes, feel free to skip ahead to my discussion of the internet’s security controls.
The following question provides a good starting place: what happens when you enter www.google.com in your browser? In other words, how does your browser know how to go from a domain name, like google.com, to the web page you’re looking for? Let’s find out.
The Client-Server Model
The internet is composed of two kind of devices: clients and servers. Clients request resources or services, and servers provide those resources and services. When you visit a website with your browser, it acts as a client and requests a web page from a web server. The web server will then send your browser the web page (Figure 3-1).

Figure 3-1: Internet clients request resources from servers.
A web page is nothing more than a collection of resources or files sent by the web server. For example, at the very least, the server will send your browser a text file written in Hypertext Markup Language (HTML), the language that tells your browser what to display. Most web pages also include Cascading Style Sheets (CSS) files to make them pretty. Sometimes web pages also contain JavaScript (JS) files, which enable sites to animate the web page and react to user input without going through the server. For example, JavaScript can resize images as users scroll through the page and validate a user input on the client side before sending it to the server. Finally, your browser might receive embedded resources, such as images and videos. Your browser will combine these resources to display the web page you see.
Servers don’t just return web pages to the user, either. Web APIs enable applications to request the data of other systems. This enables applications to interact with each other and share data and resources in a controlled way. For example, Twitter’s APIs allow other websites to send requests to Twitter’s servers to retrieve data such as lists of public tweets and their authors. APIs power many internet functionalities beyond this, and we’ll revisit them, along with their security issues, in Chapter 24.
The Domain Name System
How do your browser and other web clients know where to find these resources? Well, every device connected to the internet has a unique Internet Protocol (IP) address that other devices can use to find it. However, IP addresses are made up of numbers and letters that are hard for humans to remember. For example, the older format of IP addresses, IPv4, looks like this: 123.45.67.89. The new version, IPv6, looks even more complicated: 2001:db8::ff00:42:8329.
This is where the Domain Name System (DNS) comes in. A DNS server functions as the phone book for the internet, translating domain names into IP addresses (Figure 3-2). When you enter a domain name in your browser, a DNS server must first convert the domain name into an IP address. Our browser asks the DNS server, “Which IP address is this domain located at?”

Figure 3-2: A DNS server will translate a domain name to an IP address.
Internet Ports
After your browser acquires the correct IP address, it will attempt to connect to that IP address via a port. A port is a logical division on devices that identifies a specific network service. We identify ports by their port numbers, which can range from 0 to 65,535.
Ports allow a server to provide multiple services to the internet at the same time. Because conventions exist for the traffic received on certain ports, port numbers also allow the server to quickly forward arriving internet messages to a corresponding service for processing. For example, if an internet client connects to port 80, the web server understands that the client wishes to access its web services (Figure 3-3).
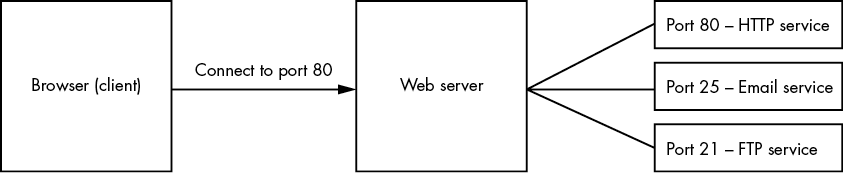
Figure 3-3: Ports allow servers to provide multiple services. Port numbers help forward client requests to the right service.
By default, we use port 80 for HTTP messages and port 443 for HTTPS, the encrypted version of HTTP.
HTTP Requests and Responses
Once a connection is established, the browser and server communicate via the HyperText Transfer Protocol (HTTP). HTTP is a set of rules that specifies how to structure and interpret internet messages, and how web clients and web servers should exchange information.
When your browser wants to interact with a server, it sends the server an HTTP request. There are different types of HTTP requests, and the two most common are GET and POST. By convention, GET requests retrieve data from the server, while POST requests submit data to it. Other common HTTP methods include OPTIONS, used to request permitted HTTP methods for a given URL; PUT, used to update a resource; and DELETE, used to delete a resource.
Here is an example GET request that asks the server for the home page of www.google.com:
GET / HTTP/1.1
Host: www.google.com
User-Agent: Mozilla/5.0
Accept: text/html,application/xhtml+xml,application/xml
Accept-Language: en-US
Accept-Encoding: gzip, deflate
Connection: closeLet’s walk through the structure of this request, since you’ll be seeing a lot of these in this book. All HTTP requests are composed of a request line, request headers, and an optional request body. The preceding example contains only the request line and headers.
The request line is the first line of the HTTP request. It specifies the request method, the requested URL, and the version of HTTP used. Here, you can see that the client is sending an HTTP GET request to the home page of www.google.com using HTTP version 1.1.
The rest of the lines are HTTP request headers. These are used to pass additional information about the request to the server. This allows the server to customize results sent to the client. In the preceding example, the Host header specifies the hostname of the request. The User-Agent header contains the operating system and software version of the requesting software, such as the user’s web browser. The Accept, Accept-Language, and Accept-Encoding headers tell the server which format the responses should be in. And the Connection header tells the server whether the network connection should stay open after the server responds.
You might see a few other common headers in requests. The Cookie header is used to send cookies from the client to the server. The Referer header specifies the address of the previous web page that linked to the current page. And the Authorization header contains credentials to authenticate a user to a server.
After the server receives the request, it will try to fulfill it. The server will return all the resources used to construct your web page by using HTTP responses. An HTTP response contains multiple things: an HTTP status code to indicate whether the request succeeded; HTTP headers, which are bits of information that browsers and servers use to communicate with each other about authentication, content format, and security policies; and the HTTP response body, or the actual web content that you requested. The web content could include HTML code, CSS style sheets, JavaScript code, images, and more.
Here is an example of an HTTP response:
1 HTTP/1.1 200 OK
2 Date: Tue, 31 Aug 2021 17:38:14 GMT
[...]
3 Content-Type: text/html; charset=UTF-8
4 Server: gws
5 Content-Length: 190532
<!doctype html>
[...]
<title>Google</title>
[...]
<html>Notice the 200 OK message on the first line 1. This is the status code. An HTTP status code in the 200 range indicates a successful request. A status code in the 300 range indicates a redirect to another page, whereas the 400 range indicates an error on the client’s part, like a request for a nonexistent page. The 500 range means that the server itself ran into an error.
As a bug bounty hunter, you should always keep an eye on these status codes, because they can tell you a lot about how the server is operating. For example, a status code of 403 means that the resource is forbidden to you. This might mean that sensitive data is hidden on the page that you could reach if you can bypass the access controls.
The next few lines separated by a colon (:) in the response are the HTTP response headers. They allow the server to pass additional information about the response to the client. In this case, you can see that the time of the response was Tue, 31 Aug 2021 17:38:14 GMT 2. The Content-Type header indicates the file type of the response body. In this case, The Content-Type of this page is text/html 3. The server version is Google Web Server (gws) 4, and the Content-Length is 190,532 bytes 5. Usually, additional response headers will specify the content’s format, language, and security policies.
In addition to these, you might encounter a few other common response headers. The Set-Cookie header is sent by the server to the client to set a cookie. The Location header indicates the URL to which to redirect the page. The Access-Control-Allow-Origin header indicates which origins can access the page’s content. (We will talk about this more in Chapter 19.) Content-Security-Policy controls the origin of the resources the browser is allowed to load, while the X-Frame-Options header indicates whether the page can be loaded within an iframe (discussed further in Chapter 8).
The data after the blank line is the response body. It contains the actual content of the web page, such as the HTML and JavaScript code. Once your browser receives all the information needed to construct the web page, it will render everything for you.
Internet Security Controls
Now that you have a high-level understanding of how information is communicated over the internet, let’s dive into some fundamental security controls that protect it from attackers. To hunt for bugs effectively, you will often need to come up with creative ways to bypass these controls, so you’ll first need to understand how they work.
Content Encoding
Data transferred in HTTP requests and responses isn’t always transmitted in the form of plain old text. Websites often encode their messages in different ways to prevent data corruption.
Data encoding is used as a way to transfer binary data reliably across machines that have limited support for different content types. Characters used for encoding are common characters not used as controlled characters in internet protocols. So when you encode content using common encoding schemes, you can be confident that your data is going to arrive at its destination uncorrupted. In contrast, when you transfer your data in its original state, the data might be screwed up when internet protocols misinterpret special characters in the message.
Base64 encoding is one of the most common ways of encoding data. It’s often used to transport images and encrypted information within web messages. This is the base64-encoded version of the string "Content Encoding":
Q29udGVudCBFbmNvZGluZw==Base64 encoding’s character set includes the uppercase alphabet characters A to Z, the lowercase alphabet characters a to z, the number characters 0 to 9, the characters + and /, and finally, the = character for padding. Base64url encoding is a modified version of base64 used for the URL format. It’s similar to base64, but uses different non-alphanumeric characters and omits padding.
Another popular encoding method is hex encoding. Hexadecimal encoding, or hex, is a way of representing characters in a base-16 format, where characters range from 0 to F. Hex encoding takes up more space and is less efficient than base64 but provides for a more human-readable encoded string. This is the hex-encoded version of the string "Content Encoding"; you can see that it takes up more characters than its base64 counterpart:
436f6e74656e7420456e636f64696e67URL encoding is a way of converting characters into a format that is more easily transmitted over the internet. Each character in a URL-encoded string can be represented by its designated hex number preceded by a % symbol. See Wikipedia for more information about URL encoding: https://en.wikipedia.org/wiki/Percent-encoding.
For example, the word localhost can be represented with its URL-encoded equivalent, %6c%6f%63%61%6c%68%6f%73%74. You can calculate a hostname’s URL-encoded equivalent by using a URL calculator like URL Decode and Encode (https://www.urlencoder.org/).
We’ll cover a couple of additional types of character encoding—octal encoding and dword encoding—when we discuss SSRFs in Chapter 13. When you see encoded content while investigating a site, always try to decode it to discover what the website is trying to communicate. You can use Burp Suite’s decoder to decode encoded content. We’ll cover how to do this in the next chapter. Alternatively, you can use CyberChef (https://gchq.github.io/CyberChef/) to decode both base64 content and other types of encoded content.
Servers sometimes also encrypt their content before transmission. This keeps the data private between the client and server and prevents anyone who intercepts the traffic from eavesdropping on the messages.
Session Management and HTTP Cookies
Why is it that you don’t have to re-log in every time you close your email tab? It’s because the website remembers your session. Session management is a process that allows the server to handle multiple requests from the same user without asking the user to log in again.
Websites maintain a session for each logged-in user, and a new session starts when you log in to the website (Figure 3-4). The server will assign an associated session ID for your browser that serves as proof of your identity. The session ID is usually a long and unpredictable sequence designed to be unguessable. When you log out, the server ends the session and revokes the session ID. The website might also end sessions periodically if you don’t manually log out.

Figure 3-4: After you log in, the server creates a session for you and issues a session ID, which uniquely identifies a session.
Most websites use cookies to communicate session information in HTTP requests. HTTP cookies are small pieces of data that web servers send to your browser. When you log in to a site, the server creates a session for you and sends the session ID to your browser as a cookie. After receiving a cookie, your browser stores it and includes it in every request to the same server (Figure 3-5).
That’s how the server knows it’s you! After the cookie for the session is generated, the server will track it and use it to validate your identity. Finally, when you log out, the server will invalidate the session cookie so that it cannot be used again. The next time you log in, the server will create a new session and a new associated session cookie for you.

Figure 3-5: Your session ID correlates with session information that is stored on the server.
Token-Based Authentication
In session-based authentication, the server stores your information and uses a corresponding session ID to validate your identity, whereas a token-based authentication system stores this info directly in some sort of token. Instead of storing your information server-side and querying it using a session ID, tokens allow servers to deduce your identity by decoding the token itself. This way, applications won’t have to store and maintain session information server-side.
This system comes with a risk: if the server uses information contained in the token to determine the user’s identity, couldn’t users modify the information in the tokens and log in as someone else? To prevent token forgery attacks like these, some applications encrypt their tokens, or encode the token so that it can be read by only the application itself or other authorized parties. If the user can’t understand the contents of the token, they probably can’t tamper with it effectively either. Encrypting or encoding a token does not prevent token forgery completely. There are ways that an attacker can tamper with an encrypted token without understanding its contents. But it’s a lot more difficult than tampering with a plaintext token. Attackers can often decode encoded tokens to tamper with them.
Another more reliable way applications protect the integrity of a token is by signing the token and verifying the token signature when it arrives at the server. Signatures are used to verify the integrity of a piece of data. They are special strings that can be generated only if you know a secret key. Since there is no way of generating a valid signature without the secret key, and only the server knows what the secret key is, a valid signature suggests that the token is probably not altered by the client or any third party. Although the implementations by applications can vary, token-based authentication works like this:
- The user logs in with their credentials.
- The server validates those credentials and provides the user with a signed token.
- The user sends the token with every request to prove their identity.
- Upon receiving and validating the token, the server reads the user’s identity information from the token and responds with confidential data.
JSON Web Tokens
The JSON Web Token (JWT) is one of the most commonly used types of authentication tokens. It has three components: a header, a payload, and a signature.
The header identifies the algorithm used to generate the signature. It’s a base64url-encoded string containing the algorithm name. Here’s what a JWT header looks like:
eyBhbGcgOiBIUzI1NiwgdHlwIDogSldUIH0KThis string is the base64url-encoded version of this text:
{ "alg" : "HS256", "typ" : "JWT" }The payload section contains information about the user’s identity. This section, too, is base64url encoded before being used in the token. Here’s an example of the payload section, which is the base64url-encoded string of { "user_name" : "admin", }:
eyB1c2VyX25hbWUgOiBhZG1pbiB9CgFinally, the signature section validates that the user hasn’t tampered with the token. It’s calculated by concatenating the header with the payload, then signing it with the algorithm specified in the header, and a secret key. Here’s what a JWT signature looks like:
4Hb/6ibbViPOzq9SJflsNGPWSk6B8F6EqVrkNjpXh7MFor this specific token, the signature was generated by signing the string eyBhbGcgOiBIUzI1NiwgdHlwIDogSldUIH0K.eyB1c2VyX25hbWUgOiBhZG1pbiB9Cg with the HS256 algorithm using the secret key key. The complete token concatenates each section (the header, payload, and signature), separating them with a period (.):
eyBhbGcgOiBIUzI1NiwgdHlwIDogSldUIH0K.eyB1c2VyX25hbWUgOiBhZG1pbiB9Cg.4Hb/6ibbViPOzq9SJflsNGPWSk6B8F6EqVrkNjpXh7MWhen implemented correctly, JSON web tokens provide a secure way to identify the user. When the token arrives at the server, the server can verify that the token has not been tampered with by checking that the signature is correct. Then the server can deduce the user’s identity by using the information contained in the payload section. And since the user does not have access to the secret key used to sign the token, they cannot alter the payload and sign the token themselves.
But if implemented incorrectly, there are ways that an attacker can bypass the security mechanism and forge arbitrary tokens.
Manipulating the alg Field
Sometimes applications fail to verify a token’s signature after it arrives at the server. This allows an attacker to simply bypass the security mechanism by providing an invalid or blank signature.
One way that attackers can forge their own tokens is by tampering with the alg field of the token header, which lists the algorithm used to encode the signature. If the application does not restrict the algorithm type used in the JWT, an attacker can specify which algorithm to use, which could compromise the security of the token.
JWT supports a none option for the algorithm type. If the alg field is set to none, even tokens with empty signature sections would be considered valid. Consider, for example, the following token:
eyAiYWxnIiA6ICJOb25lIiwgInR5cCIgOiAiSldUIiB9Cg.eyB1c2VyX25hbWUgOiBhZG1pbiB9Cg.This token is simply the base64url-encoded versions of these two blobs, with no signature present:
{ "alg" : "none", "typ" : "JWT" } { "user" : "admin" }This feature was originally used for debugging purposes, but if not turned off in a production environment, it would allow attackers to forge any token they want and impersonate anyone on the site.
Another way attackers can exploit the alg field is by changing the type of algorithm used. The two most common types of signing algorithms used for JWTs are HMAC and RSA. HMAC requires the token to be signed with a key and then later verified with the same key. When using RSA, the token would first be created with a private key, then verified with the corresponding public key, which anyone can read. It is critical that the secret key for HMAC tokens and the private key for RSA tokens be kept a secret.
Now let’s say that an application was originally designed to use RSA tokens. The tokens are signed with a private key A, which is kept a secret from the public. Then the tokens are verified with public key B, which is available to anyone. This is okay as long as the tokens are always treated as RSA tokens. Now if the attacker changes the alg field to HMAC, they might be able to create valid tokens by signing the forged tokens with the RSA public key, B. When the signing algorithm is switched to HMAC, the token is still verified with the RSA public key B, but this time, the token can be signed with the same public key too.
Brute-Forcing the Key
It could also be possible to guess, or brute-force, the key used to sign a JWT. The attacker has a lot of information to start with: the algorithm used to sign the token, the payload that was signed, and the resulting signature. If the key used to sign the token is not complex enough, they might be able to brute-force it easily. If an attacker is not able to brute-force the key, they might try leaking the secret key instead. If another vulnerability, like a directory traversal, external entity attack (XXE), or SSRF exists that allows the attacker to read the file where the key value is stored, the attacker can steal the key and sign arbitrary tokens of their choosing. We’ll talk about these vulnerabilities in later chapters.
Reading Sensitive Information
Since JSON web tokens are used for access control, they often contain information about the user. If the token is not encrypted, anyone can base64-decode the token and read the token’s payload. If the token contains sensitive information, it might become a source of information leaks. A properly implemented signature section of the JSON web token provides data integrity, not confidentiality.
These are just a few examples of JWT security issues. For more examples of JWT vulnerabilities, use the search term JWT security issues. The security of any authentication mechanism depends not only on its design, but also its implementation. JWTs can be secure, but only if implemented properly.
The Same-Origin Policy
The same-origin policy (SOP) is a rule that restricts how a script from one origin can interact with the resources of a different origin. In one sentence, the SOP is this: a script from page A can access data from page B only if the pages are of the same origin. This rule protects modern web applications and prevents many common web vulnerabilities.
Two URLs are said to have the same origin if they share the same protocol, hostname, and port number. Let’s look at some examples. Page A is at this URL:
- https://medium.com/@vickieli
It uses HTTPS, which, remember, uses port 443 by default. Now look at the following pages to determine which has the same origin as page A, according to the SOP:
- https://medium.com/
- http://medium.com/
- https://twitter.com/@vickieli7
- https://medium.com:8080/@vickieli
The https://medium.com/ URL is of the same origin as page A, because the two pages share the same origin, protocol, hostname, and port number. The other three pages do not share the same origin as page A. http://medium.com/ is of a different origin from page A, because their protocols differ. https://medium.com/ uses HTTPS, whereas http://medium.com/ uses HTTP. https://twitter.com/@vickieli7 is of a different origin as well, because it has a different hostname. Finally, https://medium.com:8080/@vickieli is of a different origin because it uses port 8080, instead of port 443.
Now let’s consider an example to see how SOP protects us. Imagine that you’re logged in to your banking site at onlinebank.com. Unfortunately, you click on a malicious site, attacker.com, in the same browser.
The malicious site issues a GET request to onlinebank.com to retrieve your personal information. Since you’re logged into the bank, your browser automatically includes your cookies in every request you send to onlinebank.com, even if the request is generated by a script on a malicious site. Since the request contains a valid session ID, the server of onlinebank.com fulfills the request by sending the HTML page containing your info. The malicious script then reads and retrieves the private email addresses, home addresses, and banking information contained on the page.
Luckily, the SOP will prevent the malicious script hosted on attacker.com from reading the HTML data returned from onlinebank.com. This keeps the malicious script on page A from obtaining sensitive information embedded within page B.
Learn to Program
You should now have a solid background to help you understand most of the vulnerabilities we will cover. Before you set up your hacking tools, I recommend that you learn to program. Programming skills are helpful, because hunting for bugs involves many repetitive tasks, and by learning a programming language such as Python or shell scripting, you can automate these tasks to save yourself a lot of time.
You should also learn to read JavaScript, the language with which most sites are written. Reading the JavaScript of a site can teach you about how it works, giving you a fast track to finding bugs. Many top hackers say that their secret sauce is that they read JavaScript and search for hidden endpoints, insecure programming logic, and secret keys. I’ve also found many vulnerabilities by reading JavaScript source code.
Codecademy is a good resource for learning how to program. If you prefer to read a book instead, Learn Python the Hard Way by Zed Shaw (Addison-Wesley Professional, 2013) is a great way to learn Python. And reading Eloquent JavaScript, Third Edition, by Marijn Haverbeke (No Starch Press, 2019) is one of the best ways to master JavaScript.