
It is easy to imagine an environment in which an essential model of a real-time system could be directly implemented. The essential model would be compiled or interpreted into working code exactly like the source code for a high-level language program. In addition to the localized decisions made by a typical compiler, the essential model compiler would make decisions with a broader scope. The compiler, for example, would distribute executable instructions among a set of target machines, organizing the code for each target machine into an optimal set of concurrent tasks.
Alas, a general-purpose real-time implementation environment with this broad a scope has not yet been created. Consequently the systems modeling process must go beyond the essential model and describe details of the implementation. This chapter presents a set of guidelines for implementation modeling, guidelines that are quite different from the essential modeling heuristics presented in Volume 2. The differences stem from a fundamental distinction between essential models and implementation models — the essential model is an original creation, while the implementation model is derived from the essential model. Because of this distinction, implementation modeling heuristics all take some feature of the essential model as a point of reference.
The guidelines we will present in this chapter are minimization of essential model distortion, satisfactory approximation to essential model behavior, top-down allocation to implementation technology, classification of the essential model by implementation resources, and data abstraction from the essential model. These provide an overall framework for our approach to implementation modeling and underlie many of the more specific guidelines to be presented in the following chapters.
A distortion of an essential model is a change in its organization based on some criterion other than the system’s subject matter. Take as an example an essential model that includes the periodic modification of a satellite’s attitude based on some pre-arranged schedule. This portion of the model can be thought of as the essential response to New Satellite Attitude is Required, and is represented by Figure 1.1.
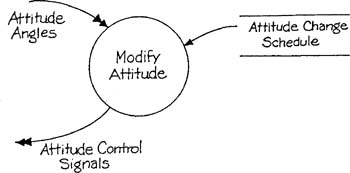
In a contemporary satellite, the logic to perform this job would probably be implemented on a single on-board microprocessor. There is in this case no distortion of the essential model; a single essential model element (an event response) translates into a single implementation element (a task within a processor) and thus the essential model organization is preserved. Except for a comment indicating the technology choice, the implementation model would be identical to Figure 1.1.
The implementation of attitude modification would have been quite different in one of the early satellites. Because of the weight and delicacy of early 1960’s processor hardware, control of satellites was typically performed via telemetry from a ground station. The model in Figure 1.2 illustrates this more distorted implementation strategy. The single essential model element has become two separate elements of the implementation, the I/O circuitry on the satellite and the control logic on the ground. A partitioning, a new interface, and a synchronization requirement have been introduced, none of which are required by the system’s basic subject matter.
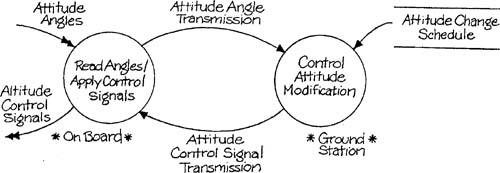
The heuristic of minimum distortion states that, all other things being equal, an implementation with less distortion of the essential model is better than one with greater distortion. In the two examples cited above, of course, all other things are not equal — modern processors allow for less distortion of this essential model than did the processors of the early 1960’s. There are two reasons for the usefulness of this criterion. First, the essential model, by definition, is the clearest possible picture of the required behavior of the system. An implementation model with the same structure as the essential model is therefore the clearest possible implementation. In addition, since the success of an implementation model depends on its verifiability, the quality assurance process will be more effective if the implementation model differs as little as possible from the essential model. Second, the essential model is constructed with minimal interfaces. An implementation that respects these interfaces is desirable, since interfaces are typically the most vulnerable part of a system [1].
The essential model contains no implementation details, or, to put it another way, the essential model assumes ideal implementation technology. Consider Figure 1.3, which is extracted from the Defect Inspection System essential model (Appendix D in Volume 2). The figure can be interpreted as, When the edge of the sheet is under the chopper, the Chop signal will be issued at that very instant. The ideal of zero time delay cannot be realized by actual implementation technology — it can only be approximated. Therefore any implementation strategy must be evaluated as to its ability to provide a satisfactory approximation to the ideal, by calculation, simulation, or experimentation. In Figure 1.3, for example, suppose that the operation of the chopper requires the activation of a task. In a multitasking implementation, the activation of a higher-priority task could delay chopper operation and thus affect product quality.

The assumption of zero response time is only one of the idealizations of the essential model. The control and data flows on the model are assumed to travel at infinite speed, and the stores on the essential model are assumed to have unlimited memory capacity.
The heuristic of satisfactory approximation to essential model behavior states that each idealization made within the essential model must be identified, and the approximation achieved by the corresponding portion of the proposed implementation must be evaluated. In some cases the evaluation is straightforward. The permissible delay-time limits corresponding to Figure 1.3 are a function of the chopper characteristics, the conveyer speed, and the required sheet size tolerance. In other cases, however, it is not easy to determine when an approximation is satisfactory. Some approximations involve not satisfaction of requirements but ease of use or economy of operation. Human-computer interfaces, for instance, are notoriously “soft” in terms of response-time limit determination.
We will use the term allocation to refer to a mapping of some portion of an essential model to a unit of implementation technology. Figures 1.1 and 1.2 in this chapter illustrate an allocation; the event response of Figure 1.1 is mapped into the on-board I/O circuitry and into a task in a ground-based computer.
The heuristic of top-down allocation in its simplest form merely states that allocation to higher-level implementation units should precede allocation to lower-level ones. In practice, however, applying this criterion requires techniques for carrying out the allocation (which will be discussed in Chapters 3 and 4) and a classification scheme for implementation units. We have classified implementation units into three stages or levels — the processor stage, the task stage, and the module stage.[*] The overall organization of the implementation model is based on these stages.
A processor is a person or a machine that can carry out instructions and store data. (The human as a potential processor is not a typical focus of real-time systems development. Nevertheless, using a human processor is sometimes the most feasible way of implementing a portion of an essential model). Machines that may be processors run the gamut from simple analogue or digital circuits through microprocessors to minis, mainframes, and “supercomputers.” The processor stage of the implementation model is represented as a network of processors to which the essential model has been allocated. Because a processor provides its own execution and storage resources, true concurrency of operation is possible within this stage; all the processors may be active simultaneously.
A task is a set of instructions that is manipulated (started, stopped, interrupted, and resumed) as a unit by the system software of a processor. Batch programs, on-line interactive tasks, and interrupt handlers all qualify as tasks under our definition. The task stage of the implementation model is represented as a set of networks of tasks, one network per processor. Each task network describes the distribution to individual tasks of the portion of the essential model carried out by a processor. A task depends on the processor within which it operates for execution and storage resources. Therefore a task network can be capable of concurrency of operation if the processor has multiple CPUs, or if the processor shares its resources among the tasks to simulate concurrency.
A module is a set of instructions that is activated as a unit by the control logic within a task in a mutually exclusive fashion (only one module may be active at a time); subprograms, functions, subroutines, and procedures all qualify as modules under our definition. This definition of a module obviously precludes concurrency among the modules within a task. The module stage of the implementation model is represented as a set of module hierarchies, one hierarchy per task. Each module hierarchy describes the distribution to individual modules of the portion of the essential model carried out by the task.
Figure 1.4 suggests the overall structure of an implementation model. Notice that the processor stage and the task stage may each correspond to multiple levels within a leveled set of transformation schemas (Volume 1, Chapters 6 and 12). As an example, a transformation within the task stage may represent either an individual task, or a group of tasks with some common characteristics.
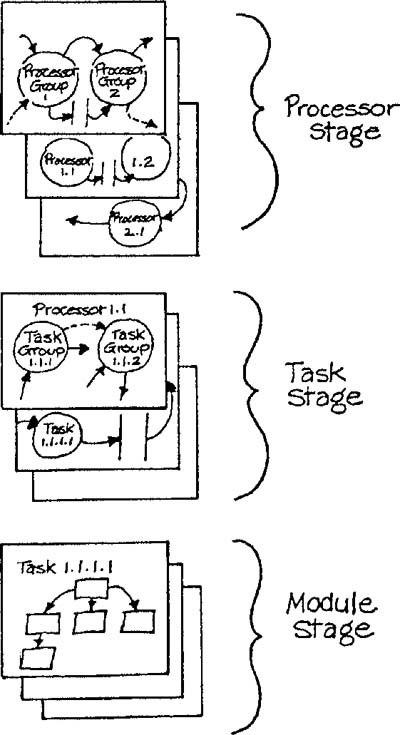
The classification scheme just described clearly doesn’t fit all implementation environments perfectly; it is itself implementation-dependent. An analog circuit, for example, has no internal structure corresponding clearly to a task or module stage. An element of computation within an array processor, to take another example, may be neither a task nor a module, but is an important unit of organization. It is possible that future developments in implementation technology will render part or all of this scheme obsolete. Nevertheless, we feel that the framework presented here will be useful for the majority of real-time implementations for the near future.
Top-down allocation is a useful heuristic because the great complexity of constructing a typical implementation model requires mapping the essential model onto an implementation in stages. One of the most complex tasks is allocating so as to ensure that portions of the model requiring concurrent execution are not assigned to elements of the technology prohibiting concurrency. The stages we have described are based on concurrency characteristics, with the processor stage being truly concurrent, the task stage simulating concurrency, and the module stage prohibiting concurrency. In this way, one of the most difficult problems of real-time system design — namely, the correct management of concurrency — can be approached by progressively modifying the concurrency shown on the essential model to account for the concurrency characteristics of the implementation technology.
The previous section alluded to techniques for the allocation process, but did not describe the rationale for a particular allocation decision. On what basis, for example, does a developer decide to use two microprocessors rather than one for a particular implementation? We describe the decision-making process as classification by use of implementation resources. The type of classification referred to is an organization of portions of the essential model by a criterion related to implementation technology rather than to the system’s subject matter. The classification can be based on either qualitative or quantitative grounds.
As an example of qualitative classification, consider the overall configuration of a remote data entry terminal. An implementer might choose two microprocessors with very different characteristics, one with an extended arithmetic instruction set to handle local computations, and a “stripped-down” micro to handle data communications. This choice implies a classification of the associated essential model into those portions that involve arithmetic and those that do not — a classification that may have little relationship to the essential model’s organization but that will influence allocation decisions.
Quantitative classification can be illustrated by the need to distribute a process control system among two microprocessors in order to avoid processor overload. Here the microprocessors have the same qualitative characteristics, but neither has the processing power to run the entire system. This distribution requirement implies a classification of essential model transformations according to their “weight” in contributing to processor load. As with the case of the arithmetic and non-arithmetic micros, this classification is relevant for allocation but unrelated to the essential model’s organization.
In addition to the distinction between qualitative and quantitative classification, there are characteristically different classifications at different stages of the implementation model. Classification at the processor stage will typically involve physical characteristics of the hardware — available instruction set, proximity to the physical environment of the system, and so on. Task-level classification may be made on the basis of activation and timing aspects of a task. Classification at the module level is more likely to focus on logical or mathematical characteristics, such as common use of a parsing or integration algorithm or a table structure.
The heuristic of classification by use of implementation resources states that at each stage of the model it is necessary to identify the relevant implementation resources, and to use the resulting classification to guide the allocation process. The criterion is useful because it allows the designer to maximize the use of expensive resources.
The essential model is organized around a natural level of detail for a system, that of responses to external events and of groupings of closely related responses. It is possible, by examining an essential model, to identify alternate possibilities for organization. Some of these alternate organizations can be quite subject-matter specific. Consider two events from the Bottle-Filling System essential model (Appendix B in Volume 2), Operator Turns Line On and Operator Removes Bottle. The portion of the response to these two events that involves checking the weight sensor and the bottle contact is identical. By identifying portions of the two event responses as a single unit, we have generalized to create a data abstraction [2], consisting of the weight and bottle contact readings, around which we may organize a portion of the implementation.
Consider another data abstraction, this one involving the SILLY system (Appendix C in Volume 2). Displaying the trigger word and displaying a logic state are closely related, since the logic state composition (0 or 1 for each channel) is a subset of the trigger word composition (0, 1, or “don’t care” for each channel). The data composite consisting of the trigger word and the logic state could be displayed by common processing logic. The abstraction here is somewhat broader in scope than the previous one, since it treats as a unit two data elements that were considered separate in the essential model.
An abstraction may be broad enough in scope so as not to be subject-matter specific. Consider a “display line” derived from the SILLY system, but defined as any set of characters that could be displayed on one line of a display. An abstraction this broad could define processing logic that is completely application-independent.
The heuristic of data abstraction from the essential model states that the essential model should be searched for common elements that will identify potential implementation resources. Note that this criterion starts from the essential model rather than from an existing resource but ultimately has the same goal as classification of implementation resources — that is, effective resource utilization.
A close examination of the heuristics just presented reveals many possibilities for conflict. For example, allocating the portions of the essential model involving complex arithmetic to a separate processor may optimize the use of processor resources but distort the organization of the essential model considerably. Implementation modeling is critically important for visualizing and exploring the consequences of such conflicts. In fact, one can define implementation modeling as the process of finding an optimum resolution among a set of conflicting objectives. Formulating this optimization problem analytically is beyond our abilities — this is the fundamental reason why an “essential model compiler” is not currently available. However, the modeling tools presented in Volume 1 and the heuristics presented in this volume make the problem solvable by systems developers.
The creation of an implementation model is fundamentally an activity of derivation, of mapping the contents of an essential model into an implementation environment. This mapping process is most effective when guided by implementation modeling heuristics. In this chapter, we have set out the heuristics that we feel are most broadly applicable. In the remaining chapters of this volume we will explore the application of these guidelines in more detail to specific modeling situations.
Chapter 1: References
[*] In the first printing of Volume 1, Chapter 5, The Modeling Process, we referred to these three stages as the Processor Environment Model, the Process Environment Model, and the Procedure Organization Model, respectively.