
7.2 Customer win-back
Strauss and Friege [1] provided a conceptual framework for lost customers' regain management which consists of analysis, actions, and controlling. To determine which customers are worthy of regaining, these authors proposed the second lifetime value (SLTV). In the controlling process, they proposed to maximize the regain profit (RP) function
(7.1) ![]()
where ![]() is the number of lost customers attempted to regain for segment
is the number of lost customers attempted to regain for segment ![]() ,
, ![]() is the regain ratio which is a function influenced by the regain cost, and
is the regain ratio which is a function influenced by the regain cost, and ![]() ,
, ![]() , and
, and ![]() are various costs occurred for regaining lapsed customers.
are various costs occurred for regaining lapsed customers.
Thomas et al. [2] investigated the best price strategy for reacquisition of lapsed customers. Different from the proportional hazards model, the proposed model used in Thomas et al. [2] is called ‘split hazard model.’ These authors focused on the second life of lapsed customers and linked the reacquisition and duration of second life together. The authors specified a probit model for the probability of reacquisition as
(7.2) ![]()
where the latent variable ![]() is modeled with a linear specification as
is modeled with a linear specification as
To examine the effects of price changes on the probability of relationship termination, the authors adopted the continuous Markov process assumption that the probability of the customer terminating the relationship at any point in time is independent of the current duration. They separated a customer's second lifetime into many ‘subspells’ and assumed that the duration of a subspell does not depend on the length of a prior subspell. The authors modeled the duration for customer i during subspell ![]() with a conditional regression
with a conditional regression
(7.4) ![]()
where ![]() is the latent duration of relationship and
is the latent duration of relationship and ![]() is the censoring value. They specified the latent duration of subspell
is the censoring value. They specified the latent duration of subspell ![]() of customer
of customer ![]() as
as
To link reacquisition and duration of second lifetime together, the authors specified the errors of the two models, respectively, as
(7.6) ![]()
(7.7) ![]()
where ![]() ,
, ![]() , and
, and ![]() and
and ![]() represent customer-specific preferences. The authors also allowed the distributions of customer-specific preferences to be correlated so that
represent customer-specific preferences. The authors also allowed the distributions of customer-specific preferences to be correlated so that ![]() where
where
(7.8) ![]()
In this way, customers' preference to be reacquired is correlated with customers' preference for the duration of the relationship. In summary, the authors specified the error variances of Equations 7.3 and 7.5 as:
(7.9) ![]()
(7.10) ![]()
The authors estimated the variance component specification in a Bayesian framework by using Markov chain Monte Carlo methods.
Customer win-back is still a new field and needs further research. Intuitively, customer win-back concerns the reacquisition probability and the duration of customer second lifetime. Researchers should consider developing suitable models to link the two processes together. In addition, most companies consider lapsed customers dead and do not store any past information of these customers, which presents a big challenge for customer win-back modeling.
7.2.1 Empirical Example: Customer Win-back
In order to understand whether we should try to win back a lost customer, we need to develop a set of models which describe the reacquisition and second customer life cycle process. This will involve three different models: the reacquisition model, second duration model, and second CLV model. Once we have the results from the three models, we will have a better understanding of how to reacquire customers and which lost customers are worth reacquisition. The three models we will estimate are the following:
(7.11) ![]()
(7.12) ![]()
(7.13) 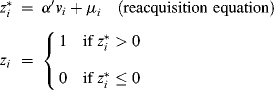
where ![]() is a latent variable indicating customer i's utility to engage in a second relationship with a firm,
is a latent variable indicating customer i's utility to engage in a second relationship with a firm, ![]() an indicator variable showing whether customer i is reacquired (
an indicator variable showing whether customer i is reacquired (![]() ) or not (
) or not (![]() ),
), ![]() a vector of covariates affecting the reacquisition of customer i,
a vector of covariates affecting the reacquisition of customer i, ![]() the second duration of customer i's relationship with the firm,
the second duration of customer i's relationship with the firm, ![]() a vector of covariates affecting the second duration of customer i's relationship with the firm,
a vector of covariates affecting the second duration of customer i's relationship with the firm, ![]() the second CLV of customer i,
the second CLV of customer i, ![]() a vector of covariates affecting customer i's second CLV,
a vector of covariates affecting customer i's second CLV, ![]() a vector of parameters, and
a vector of parameters, and ![]() and
and ![]() error terms. Given that the modeling framework is recursive in nature, we can estimate it in a stepwise fashion. Thus, we will proceed in the following manner. There will be three subsections (similar to the estimation in Chapter 5) in this empirical example. The first subsection will describe and estimate the reacquisition model, the second will describe and estimate the second duration model, and the third will describe and estimate the second CLV model.
error terms. Given that the modeling framework is recursive in nature, we can estimate it in a stepwise fashion. Thus, we will proceed in the following manner. There will be three subsections (similar to the estimation in Chapter 5) in this empirical example. The first subsection will describe and estimate the reacquisition model, the second will describe and estimate the second duration model, and the third will describe and estimate the second CLV model.
7.2.1.1 Reacquisition Model
The key question we want to answer with regard to customer acquisition here is whether we can determine which future prospects have the highest likelihood of reacquisition. To do this we first need to know which previously lost customers were reacquired and which were not. In the dataset provided for this chapter we have a binary variable which identifies whether or not a previously lost customer was reacquired by the firm (and hence became a customer again) and a set of drivers which are likely to help explain a customer's decision to rejoin the firm. A random sample of 500 previously lost customers (some of whom became customers again) was taken from a B2C firm. The information we need for our reacquisition model includes the following list of variables:
| Dependent variable | |
| Reacquire | 1 if the customer is reacquired, 0 if not |
| Independent variables | |
| Duration_1 | Time in days of the customer's first life cycle with the company |
| Offer | The value of the offer provided to the customer for reacquisition |
| Duration_lapse | Time in days since the customer was lost to when the offer to reacquire was given |
| Price_Change | The increase (or decrease) in price of the subscription the customer received between the first life cycle and the second life cycle, 0 if not reacquired |
| Gender | 1 if male, 0 if female |
| Age | Age in years of the customer at the time of the attempt to reacquire |
In this case, we have a binary dependent variable (Reacquire) which tells us whether the prospect did join again (= 1) or did not (= 0). We also have six independent variables that we believe will be drivers of reacquisition. First, we have how long the customer lasted in the relationship the first time around (Duration_1). Second, we have the value of the offer that the firm provided the customer to entice the lapsed customer to readopt (Offer). Third, we have the time since the customer left the relationship with the firm to the time of the offer (Duration_lapse). Fourth, we have the change in subscription price of the new subscription in the second lifetime from the subscription price in the first lifetime (Price_Change). Finally, we have two variables which describe the lapsed customer's demographics. These include both the Gender and Age of the customer.
First, we need to model the probability that a prospect will be reacquired. Since our dependent variable (Reacquire) is binary and we need an error structure that is similar to the second duration and second CLV models (both normally distributed), we select a probit regression for this model. Choosing a logistic regression would require us to transform the model output before integrating the results with the other two equations. In this case the y variable is Reacquire and the x variables represent the nine independent variables in our database. When we run the probit regression we get the following result:

As we can see from the results, five of the six independent variables are significant at a p-value of 5% or better – with the only non-significant variable being Gender. First, this means that the longer the customer's initial relationship with the firm (Duration_1), the higher the likelihood of reacquisition. Second, the results show that the higher the Offer made for the former customer to rejoin, the more likely the reacquisition. Third, the results show that the longer the time since the first customer relationship lapsed (Duration_Lapse), the less likely the customer will be reacquired. Finally, the results show that the older the customer (Age), the less likely the customer will be reacquired.
Now that we have determined the drivers of customer reacquisition we need to use the output of the model to determine our model's predictive accuracy. To do this we need to use the estimates we obtained from the reacquisition model to help us determine the predicted probability that each customer will be reacquired. We use the parameter estimates from the reacquisition model and values for the x variables for each customer to predict whether a customer is likely to be reacquired. For a probit regression we must apply the proper probability function
![]()
where X is the matrix of variables, β is the vector of coefficients, μ is the mean of the error distribution (in this case 0), σ is the standard deviation of the error distribution (in this case 1 since it is a standard normal distribution), and erf is the error function which is equal to
![]()
Once we compute the probability of reacquisition, we need to create a cutoff value to determine at which point we are going to divide the customers into the two groups – predicted to reacquire and predicted not to reacquire. There is no rule that explicitly tells us what that cutoff number should be. Often by default we select 0.5 since it is equidistant from 0 and 1. However, it is also reasonable to check multiple cutoff values and choose the one that provides the best predictive accuracy for the dataset. By using 0.5 as the cutoff for our example, any customer whose predicted probability of reacquisition is greater than or equal to 0.5 is classified as predicted to be reacquired and the rest are predicted not to be reacquired. To determine the predictive accuracy we compare the predicted to the actual reacquisition values in a 2 × 2 table. For our sample of 500 customers we get the following table:

As we can see from the table, our in-sample model accurately predicts 83.9% of the customers who chose not to readopt (172/205) and 88.1% of the customers who chose to readopt (260/295). For the prediction of customers who did chose to reacquire the product and for the prediction of customers who chose not to reacquire the product, this is a significant increase in the predictive capability of a random guess model1 which would be only 59% accurate for this dataset. To determine overall model prediction performance we look at the diagonal and see that overall our prediction accuracy is 86.4% (432/500). Given that the model in general predicts better than the random guess model, we would determine that the model prediction is good.
As a result we now know how analyzing a customer's past lifetime duration, the time since that customer disadopted, the level of the offer we provide the customer to incentivize readoption, and customer characteristics are likely to either increase or decrease the likelihood of readoption. And we also know that these drivers do a good job in helping us predict whether a customer is going to readopt or not.
7.2.1.2 Second Duration Model
The second step of this process is to estimate the second duration model. The purpose of this model is to understand the drivers that describe the length of time a customer is likely to be a customer for the second time, conditional on the fact that readoption occurred. Thus the equation takes the following format:
![]()
This equation shows us that the expected second duration is a function of the probability that the customer is reacquired multiplied by the expected value of second duration given that the customer was reacquired. If we were to merely run a regression with Duration_2 as the dependent variable and ignore the probability that the customer will readopt, we would get biased estimates due to a potential sample selection bias.
Sample selection bias is a problem that is common in many marketing problems and has to be statistically accounted for in many modeling frameworks. In this case the customer has a choice as to whether or not to reacquire the product before deciding how long the second relationship will last. If we were to ignore this choice we would bias the estimates from the model and we would have less precise predictions for the value of Duration_2. To account for this issue we need to be able to predict the value of both the probability of Reacquisition (what we did in the first step of this example) and the expected value of Duration_2 given that the customer is expected to readopt. To account for this issue we use a two-stage modeling framework similar to that described earlier in this chapter and found in Reinartz et al. [4].
We will use the output and predictions of the probit model from the first step of this example to create a new variable, λ, which will represent the correlation in the error structure across the two equations. This variable, also known as the sample selection correction variable, will then be used as an independent variable in the Duration_2 model to remove the sample selection bias in the estimates. To compute λ we use the following equation, also known as the inverse Mills ratio:
![]()
In this equation ϕ represents the normal probability density function, Φ represents the normal cumulative density function, X represents the value of the variables in the reacquisition model, and β represents the coefficients derived from the estimation of the reacquisition model.
Finally, we want to estimate a regression model for Duration_2 and include the variable λ as an additional independent variable. This is done in a straightforward manner using the following equation:
![]()
In this case Duration_2 is the value of the second duration, γ is the matrix of variables used to help explain the value of Duration_2, α are the coefficients for the independent variables, μ is the coefficient on the inverse Mills ratio, λ is the inverse Mills ratio, and ε is the error term. Thus, for this example we will use the following list of variables:
| Dependent variable | |
| Duration_2 | Time in days of the customer's second life cycle with the company, 0 if not reacquired |
| Independent variables | |
| Duration_1 | Time in days of the customer's first life cycle with the company |
| Offer | The value of the offer provided to the customer for reacquisition |
| Duration_lapse | Time in days since the customer was lost to when the offer to reacquire was given |
| Price_Change | The increase (decrease) in price of the subscription the customer received between the first life cycle and the second life cycle, 0 if not reacquired |
| Gender | 1 if male, 0 if female |
| Age | Age in years of the customer at the time of the attempt to reacquire |
| Lambda (λ) | The computed inverse Mills ratio from the reacquisition model |
When we estimate the second-stage of the model, we get the following parameter estimates from the second of the two equations (the parameter estimates for the reacquisition model are detailed in the first part of this example):

We gain the following insights from the results. We see that λ is positive and significant. We can interpret this to mean that there is a potential selection bias problem since the error term of our selection equation is correlated positively with the error term of our regression equation. We also see that all other variables of the Duration_2 model are significant, meaning that we have likely uncovered many of the drivers of second duration.
We find that Duration_1 is positive, suggesting that the longer the customer's first lifetime with the company, the longer the second lifetime the customer will have with the company. We find that Offer is positive, suggesting that the higher the offer amount (i.e., the greater the incentive), the longer the second lifetime duration. We find that the longer the time since the customer disadopted from the first relationship with the company (Duration_lapse), the shorter the second lifetime with the company. We find that when the price the customer pays for the product in the second lifetime is lower (Price_Change < 0), the second lifetime duration of the customer is longer. Finally, we find that male customers or younger customers are more likely to have a longer second lifetime than female customers or older customers.
Our next step is to predict the value of Duration_2 to see how well our model compares to the actual values. We do this by starting with the equation for expected duration at the beginning of this example:
![]()
In this case Φ is the normal CDF distribution, X is the matrix of independent variable values from the Reacquisition equation, β is the vector of parameter estimates from the Reacquisition equation, γ is the matrix of independent variables from the Duration_2 equation, α is the vector of parameter estimates from the Duration_2 equation, μ is the parameter estimate for the inverse Mills ratio, and λ is the inverse Mills ratio. Once we have predicted the Duration_2 value for each of the customers (both those we reacquired and those we did not reacquire) we want to compare this to the actual value from the database. We do this by computing the MAD. The equation is as follows:
![]()
We find for all customers that MAD = 67.88. This means that on average each of our predictions of Duration_2 deviates from the actual value by about 68 days. If we were to instead use the mean value of Duration_2 (394.61) across all customers as our prediction for all second lifetimes (this would be the benchmark model case), we would find that MAD = 353.01, or about 353 days. As we can see, our model does a significantly better job of predicting the length of the customer relationship than the benchmark case.
7.2.1.3 SCLV Model
The third step of this process is to estimate the SCLV model. The purpose of this model is to understand the drivers that describe the expected value of the customer's second lifetime value. Thus the equation takes the following format:
![]()
This equation shows us that the expected SCLV is a function of the probability that the customer is reacquired multiplied by the expected value of SCLV given that the customer was reacquired and the estimated second duration of the customer's relationship with the firm. Again, if we were to merely run a regression with SCLV as the dependent variable and ignore the probability that the customer will be reacquired and the estimated second duration, we would get biased estimates due to a potential sample selection bias.
Thus, we will use the λ variable as an additional variable in the model, which is computed using the following equation:
![]()
In this equation ϕ represents the normal PDF, Φ represents the normal CDF, X represents the value of the variables in the reacquisition model, and β represents the coefficients derived from the estimation of the reacquisition model.
We will also use the expected value of Duration_2 from the second step of this example in our SCLV model. The expected value of Duration_2 is merely computed as
![]()
Finally, we want to estimate a regression model for SCLV and include the variables λ and E(Duration_2) as additional independent variables. This is done in a straightforward manner using the following equation:
![]()
In this case SCLV is the value of the second lifetime, γ is the matrix of variables used to help explain the value of SCLV, α are the coefficients for the independent variables, μ is the coefficient on the inverse Mills ratio, λ is the inverse Mills ratio, ρ is the coefficient on the expected second duration, Durâtion_2 is the expected second duration, and ε is the error term. Thus, for this example we will use the following list of variables:
| Dependent variable | |
| SCLV | The CLV of the customer in the second life cycle |
| Independent variables | |
| Duration_1 | Time in days of the customer's first life cycle with the company |
| Offer | The value of the offer provided to the customer for reacquisition |
| Price_Change | The increase (or decrease) in price of the subscription the customer received between the first life cycle and the second life cycle, 0 if not reacquired |
| Gender | 1 if male, 0 if female |
| Age | Age in years of the customer at the time of the attempt to reacquire |
| Lambda (λ) | The computed inverse Mills ratio from the reacquisition model |
| Durâtion_2 | The expected number of days the customer will be with the firm for the second lifetime |
When we estimate the third stage of the model, we get the following parameter estimates (the parameter estimates for the reacquisition model are detailed in the first part of this example and the parameter estimates of the second duration model are detailed in the second part):

We gain the following insights from the results. We see that λ is positive and significant. We can interpret this to mean that there is a potential selection bias problem since the error term of our selection equation is correlated positively with the error term of our regression equation. We also see that all other variables of the SCLV model are significant, meaning that we have likely uncovered many of the drivers of second customer lifetime value.
We find that Duration_1 is positive, suggesting that the longer the duration of the first relationship, the higher the expected SCLV. We find that the higher the incentive provided to the customer for reacquisition (Offer), the higher the expected SCLV. We find that when the price the customer pays for the product in the second lifetime is lower (Price_Change < 0), SCLV is higher. We find that customers who are male or who are younger are more likely to have a higher SCLV. Finally, we find the coefficient on expected second duration to be positive, suggesting that customers who are in the relationship longer the second time around are more likely to profitable.
Our next step is to predict the value of SCLV to see how well our model compares to the actual values. We do this by starting with the equation for expected SCLV at the beginning of this example:
![]()
In this case Φ is the normal CDF distribution, X is the matrix of independent variable values from the Reacquisition equation, β is the vector of parameter estimates from the Reacquisition equation, γ is the matrix of independent variables from the SCLV equation, α is the vector of parameter estimates from the SCLV equation, μ is the parameter estimate for the inverse Mills ratio, λ is the inverse Mills ratio, ρ is the coefficient on the expected second duration, and Durâtion_2 is the expected second duration. Once we have predicted the SCLV value for each of the customers we want to compare this to the actual value from the database. We do this by computing the MAD. The equation is as follows:
![]()
We find for all the customers that MAD = 140.59. This means that on average each of our predictions of SCLV deviates from the actual value by about $140.59. If we were to instead use the mean value of SCLV ($730.15) across all customers as our prediction (this would be the benchmark model case), we would find that MAD = 630.23, or $630.23. As we can see, our model does a significantly better job of predicting the expected profit of customers than the benchmark case.
7.2.2 How Do You Implement it?
For this empirical exercise several different methods were used. First, to estimate the probit regression for the reacquisition model we used PROC Logistic in SAS with the probit link function. Second, to estimate the censored regression for both the second duration model and the SCLV model in the second and third steps we used PROC Reg in SAS. There are numerous other programs such as MATLAB, GAUSS, and R which could be used to estimate these models.