
6.2 Customer Churn
Researchers have a strong interest in the causes of customer churn or switching behaviors. In the mobile telephony industry, Kim and Yoon [1] adopted a binomial logit model to investigate the causes for customers switching carriers. The dependent variable of the model recorded the churning behavior (1 for switching, 0 for staying). These authors assumed that customers switch carriers because the utility of churning is greater than no churning. The utility can be expressed as
(6.1) ![]()
where ![]() denotes service attributes and
denotes service attributes and ![]() denotes individual-specific characteristics, and
denotes individual-specific characteristics, and
(6.2) ![]()
The probability of the nth subscriber to churn can be expressed as
(6.3) ![]()
Since the unobserved part, ![]() , could be identically and independently distributed (i.i.d.) following a logistic distribution, a binomial logit model is suitable to model the utility and the probability of churning. The model is expressed as follows:
, could be identically and independently distributed (i.i.d.) following a logistic distribution, a binomial logit model is suitable to model the utility and the probability of churning. The model is expressed as follows:
(6.4) ![]()
where ![]() is the probability that the nth subscriber will switch from the jth carrier to another,
is the probability that the nth subscriber will switch from the jth carrier to another, ![]() is a vector of explanatory variables, and
is a vector of explanatory variables, and ![]() denotes the cumulative logistic distribution function. For the explanatory variables, the authors included service attributes, such as call quality and price level, and demographic and phone usage characteristics, such as income, age, and subscription duration.
denotes the cumulative logistic distribution function. For the explanatory variables, the authors included service attributes, such as call quality and price level, and demographic and phone usage characteristics, such as income, age, and subscription duration.
Since whether to churn or not is a binary decision, logistic regression remains the popular method used. [2] adopted a hierarchical logistic regression to investigate the relationship between satisfaction, switching risk, objective and subjective knowledge, and likelihood of defection. Buckinx and Van den Poel [3] argued that, unlike in contractual settings where companies can detect when customers totally defect, in non-contractual settings customers may only display partial defection, such as decreasing some of their purchase from current shops. In a retailing industry, these authors used logistic regression to classify partial defectors and non-partial defectors. The authors included as independent variables the observed purchase behavior and customer information, including interpurchase time, frequency of purchase, monetary indicators, shopping behavior across product categories, brand purchase and promotional behavior, length of relationship, timing of shopping, mode of payment, and customer demographics. In the insurance industry, Brockett et al. [5] used logistic regression to estimate the probability of policy holders' total simultaneous cancellation. In the telecommunications industry, [4] adopted two binary logistic regressions to explore churn determinants, including customer dissatisfaction, switching costs and service usage, and the mediating role of customer status (active, non-use, and suspended).
Besides logistic regression, the binary classification problem of churning could be modeled by techniques from data mining and machine learning. For churn classification purposes, Buckinx and Van den Poel [3] adopted MacKay's Bayesian automatic relevance determination (ARD) neural network and random forests as proposed in Breiman [12]. These authors selected Mackay's Bayesian ARD neural network framework because it has the appealing property of providing a Bayesian hyperparameter per input variable, representing the importance of the variable. Lemmens and Croux [6] adopted bagging and boosting classification trees to predict churn in the wireless telecommunications industry. These authors evaluated the predictive accuracy of their churn model not only on the misclassification rate but also on the Gini coefficient and the top-decile lift. [7] used two cost-sensitive classifiers, the AdaCost boosting and the cost-sensitive decision tree, to predict churn in the financial services industry. These authors also compared the prediction accuracy of the proposed techniques to other classification methods, such as logistic regression, decision trees, and neural networks.
In the telecommunications industry, service usage duration is possibly correlated with customer attrition behavior and ignoring this condition will lead to biased estimation. In a market experiment, Danaher [8] developed time series analysis to model two phenomena, attrition and usage, conditional on retention. Following Hausman and Wise [13] and extending their models to multiple time periods, the author used linear regression to explain the cell phone airtime usage. The model was expressed as
(6.5) ![]()
where the independent variables ![]() change with time, and the error term
change with time, and the error term ![]() is i.i.d. with an individual component
is i.i.d. with an individual component ![]() and an uncorrelated time effect
and an uncorrelated time effect ![]() . The properties of the error term are
. The properties of the error term are
(6.6) ![]()
(6.7) ![]()
The author considered that a decreasing trend of service usage may influence customers' intention to continue with the contract and induce faster attrition. Thus, following the approach by Hausman and Wise [13] and Winer [14], the author defined an indicator variable ![]() (1, if person
(1, if person ![]() remains in the trial at time
remains in the trial at time ![]() ; 0, if the person drops out) to incorporate attrition effects that depend on usage. Then,
; 0, if the person drops out) to incorporate attrition effects that depend on usage. Then, ![]() is defined to be observed if
is defined to be observed if
where ![]() is a matrix containing variables that do not affect
is a matrix containing variables that do not affect ![]() but do influence the probability of observing
but do influence the probability of observing ![]() . Substituting for
. Substituting for ![]() in Equation 6.8 gives
in Equation 6.8 gives
(6.9) ![]()
where ![]() , and
, and ![]() . The author assumed that
. The author assumed that ![]() is normally distributed with mean 0 and variance
is normally distributed with mean 0 and variance ![]() and
and ![]() . As was done by Hausman and Wise [13], the author normalized the variance of
. As was done by Hausman and Wise [13], the author normalized the variance of ![]() by setting it to 1, so that the models for the retention and attrition probabilities can be given by the probit model as
by setting it to 1, so that the models for the retention and attrition probabilities can be given by the probit model as
(6.10) ![]()
where ![]() is the standard normal distribution function. For the usage model, the author included independent variables, such as service access price and usage price, demographic variables, and dummy variables for three of the year's four quarters. For the attrition model, the author included the same independent variables as the usage model for the identifiability purpose of the Hausman and Wise model.
is the standard normal distribution function. For the usage model, the author included independent variables, such as service access price and usage price, demographic variables, and dummy variables for three of the year's four quarters. For the attrition model, the author included the same independent variables as the usage model for the identifiability purpose of the Hausman and Wise model.
Since the purpose of customer churn models is to understand the occurrence and time for customer attrition, the family of survival analysis includes popular techniques for such modeling. Parametric survival models usually assume a baseline distribution of certain forms, such as the exponential or Weibull distribution. Dekimpe and Degraeve [9] applied a hazard-rate model to analyze the attrition rate of volunteers with the Belgian Red Cross. These authors assumed an exponential form for the lifetime distribution which assumes a homogeneous population and does not assume any time dependence. Following Dekimpe and Degraeve's baseline model, let T denote the random duration of a volunteer with probability density function ![]() , cumulative distribution function
, cumulative distribution function ![]() , and hazard function
, and hazard function ![]() :
:
(6.11) ![]()
(6.12) ![]()
(6.13) ![]()
The authors stated that they knew during what months the volunteers joined and left but did not know the timing of these events within a given month. To account for the discrete nature of the data, the authors defined monthly grouping intervals ![]() , and
, and ![]() , and recorded quitting in duration interval
, and recorded quitting in duration interval ![]() as
as ![]() . They addressed that the likelihood contribution of any volunteer
. They addressed that the likelihood contribution of any volunteer ![]() can be expressed as
can be expressed as
(6.14) 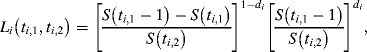
where ![]() equals the total number of months with the Red Cross, and
equals the total number of months with the Red Cross, and ![]() is the number of months the volunteer had been with the Red Cross before a certain time.
is the number of months the volunteer had been with the Red Cross before a certain time. ![]() , is the survival function and gives the probability that volunteer
, is the survival function and gives the probability that volunteer ![]() stays for at least
stays for at least ![]() periods; and
periods; and ![]() is a censoring dummy variable which equals 0 if the volunteer has left and 1 if the volunteer is still active. After substituting the expression for the survival function of the exponential distribution, the log-likelihood for a set of N volunteers (who are all assumed to have the same mean quitting rate λ) is then equal to
is a censoring dummy variable which equals 0 if the volunteer has left and 1 if the volunteer is still active. After substituting the expression for the survival function of the exponential distribution, the log-likelihood for a set of N volunteers (who are all assumed to have the same mean quitting rate λ) is then equal to
(6.15) 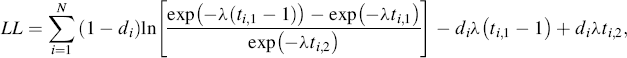
which is maximized to get an estimate of λ. The covariates examined are cohort, gender, age when joining as an active volunteer, education level when joining, and seniority.
Jamal and Bucklin [10] adopted a Weibull hazard model with time-varying covariates to predict customer churn. The Weibull distribution gives a smoothly increasing function of duration time, and churn rate is shown to be an increasing function of duration time. These authors stated that the Weibull hazard probability (conditional probability of churn) of customer ![]() at duration time
at duration time ![]() conditional on
conditional on ![]() belonging to segment
belonging to segment ![]() is given by
is given by
(6.16) ![]()
where
![]()
is the baseline hazard function for segment ![]() with Weibull distribution parameters
with Weibull distribution parameters ![]() and
and ![]() ,
, ![]() are the customer and time-specific covariates, and
are the customer and time-specific covariates, and ![]() are the response parameters for segment
are the response parameters for segment ![]() . The authors gave the likelihood contribution of observation
. The authors gave the likelihood contribution of observation ![]() for customer
for customer ![]() at time period
at time period ![]() conditional on
conditional on ![]() belonging to segment
belonging to segment ![]() as
as
(6.17) ![]()
where ![]() is the survival probability,
is the survival probability, ![]() the probability density function, and
the probability density function, and ![]() an indicator variable for censoring. The unconditional likelihood contribution of customer
an indicator variable for censoring. The unconditional likelihood contribution of customer ![]() over all the
over all the ![]() observations is expressed as
observations is expressed as
(6.18) ![]()
where ![]() is the number of latent segments and
is the number of latent segments and ![]() is the prior probability of segment
is the prior probability of segment ![]() , parameterized as
, parameterized as
![]()
where ![]() . The model parameters were estimated using maximum likelihood estimation. The covariates examined included customer service experience, failure recovery, and payment equity.
. The model parameters were estimated using maximum likelihood estimation. The covariates examined included customer service experience, failure recovery, and payment equity.
The proportional hazards model [15] incorporates the effects of individual customer covariates but assumes a common hazard function of which each individual hazard function is a multiple. Van den Poel and Larivière [11] adopted a proportional hazards model to analyze customer attrition in the context of the European financial services industry. These authors combined three categories of predictors of churn behavior, namely, customer behavior, customer demographics, and macroenvironment, into the independent variables and allowed these variables to take different values over time. Brockett et al. [5] used proportional hazards models to understand sequential policy cancellations. These authors modeled the time between first cancellation notification and the final complete withdrawal by assuming that there is a baseline distribution for the time a customer will take for defection, and the relative risk of an individual customer defecting completely changes from this baseline according to his/her particular set of individual household covariates. The authors adopted the empirically based Breslow estimator [16] to estimate the parameters.
Hadden et al. [17] and Neslin et al. [18] provided an overview of the techniques used in customer churn prediction. Hadden et al. [17] proposed a five-stage churn management framework, including identification of the best data, data semantics, feature selection, development of predictive model, and validation of results. To develop a predictive model for customer churn, these authors reviewed traditional methods, including decision trees, neural networks, regression analysis, Bayesian network classifiers, semi-Markov processes, support vector machine, K-nearest neighbor (KNN), and soft computing, including fuzzy logic, evolutionary computation, artificial neural networks, probabilistic computing, and their combinations. Based on a tournament, Neslin et al. [18] tried to identify the most suitable methodological approaches for predicting customer churn. These authors considered methods such as logistic regression, decision trees, neural nets, discriminant analysis, cluster analysis, and Bayesian analysis.
6.2.1 Empirical Example: Customer Churn
One of the many critical questions a firm needs to answer is related to whether that firm can predict why and when a customer is likely to churn. In this example we will focus on an example from a typical B2B firm with a contractual basis with its customers. In this case the firm is actually able to observe when the customer churns from the database. However, we do observe the entire lifetime of every customer in the database. Instead we only observe whether or not the customer defected from the firm in the first two years of the relationship (or 730 days). For all customers who have not defected from the firm, we only observe a censored lifetime of 730 days. Thus, in this example we want to model the drivers of customer churn to try and understand if there is a difference between the customers who have already left the firm and the customers who have yet to leave the firm. At the end of this example we should be able to do the following:
The information we need for this model includes the following list of variables:
| Variable | |
| Customer | Customer number (from 1 to 500) |
| Duration | The time in days that the acquired prospect has been or was a customer, right-censored at 730 d |
| Censor | 1 if the customer was still a customer at the end of the observation window, 0 otherwise |
| Avg_Ret_Exp | Average number of dollars spent on marketing efforts to try and retain that customer per month |
| Avg_Ret_Exp_SQ | Square of the average number of dollars spent on marketing efforts to try and retain that customer per month |
| Total_Crossbuy | The total number of categories the customer has purchased from during the customer's lifetime |
| Total_Freq | The total number of purchase occasions the customer had with the firm in the customer's lifetime |
| Total_Freq_SQ | The square of the total number of purchase occasions the customer had with the firm in the customer's lifetime |
| Industry | 1 if the prospect is in the B2B industry, 0 otherwise |
| Revenue | Annual sales revenue of the prospect's firm (in millions of dollars) |
| Employees | Number of employees in the prospect's firm |
In this case we will be using both Duration and Censor as our dependent variables and the remaining variables as our independent variables. Since we actually observe a customer's defection from the firm, we can choose a modeling framework with an observed dependent variable. In the case where the relationship between the customer and firm was non-contractual we would have to model the probability of customer churn as a stochastic process (see the empirical example on lifetime duration in Chapter 4 for a description of modeling this process). For this case we will choose an accelerated failure time (AFT) model. AFT models are parametric models that provide an alternative to modeling failure time data using a proportional hazards model (PHM). As a result we can model them as a linear model with the time until failure (Duration) transformed by the logarithmic function. We get a model of the following format:
![]()
where ln(Durationi) is the natural logarithm of the duration of customer i, Xi is a matrix of the time-invariant independent variables for each customer i, β is a vector of parameter estimates, σ is the estimated scale parameter, and εi is the random disturbance term. In the case we will be estimating the values of β and σ. We note here that if the value of σ is 1 and there are no censored values (i.e., every customer churns during the time window) we merely have an OLS regression where the dependent variable is transformed by the natural logarithm function and the independent variables are linear. However, given the censored nature of the data, we cannot use an OLS regression. For the purpose of this example we choose to estimate the model with a log-normal distribution in Duration, where the estimated distribution of Duration can take many different forms (e.g., Weibull, log-normal, exponential, etc.). Also note here that we are not choosing the distribution of ln(Distribution) or ε. The selection of the distribution for all AFT models is always in the original time variable and not in the transformed variable or the random disturbance term. When we estimate the model we get the following results:

As we can see from the results, all of the independent variables with the exception of Industry are significant at p < 0.05. We find that Avg_Ret_Exp is positive with a diminishing return, suggesting that the higher the average monthly spending on retention efforts (to a threshold), the longer the duration before the customer is likely to churn. We find that Total_Crossbuy is positive, suggesting that the more categories a customer purchases, the longer the expected lifetime. We find that Total_Freq is positive with a diminishing return, suggesting (similar to average retention expense) that the more frequently a customer purchases (to a threshold), the longer the customer's expected lifetime. This means that customers who do not purchase very frequently are not likely to stay long and customers who purchase very frequently are likely to exhaust their need to purchase quickly and leave earlier as well. It is the customers who purchase at a moderate frequency that are likely to have the longest lifetime with the firm. We find that Revenue and Employees are positively related, the expected duration of the customer lifetime meaning that customers who have higher revenue and more employees are more likely to have a longer duration with the firm. Finally, we see a scale value σ of 0.158. The scale value is merely an estimated value that helps to scale the random disturbance term. While for some distributions it can affect the shape of the hazard function, in this case given a log-normal distribution of Duration, changes in the scale parameter only serve to compress or stretch the hazard function.
It is also important to understand exactly how changes in the drivers of customer duration are likely to lead to either increases or decreases in that customer's expected duration. To do this we need to understand how to interpret the parameter coefficients from the AFT model. We see that we have a model format with a logged dependent variable of time and linear independent variables (log-linear format). As a result, we see that the ratio of survival times between the baseline and current case is the following:
![]()
where T(·) is the hazard model, Xi is the value of the focal independent variable for customer i, δ is the change in the value of the independent variable, and exp(·) is the exponential function. When the change in the value of the independent variable is only 1, we see that the above function simplifies to
![]()
When we compute the ratio for each of the statistically significant variables we get the following results for an increase in 1 unit of the independent variable:
| Variable | Duration ratio |
| Avg_Ret_Exp | (0.0088−0.0004*Avg_Ret_Exp) |
| Total_Crossbuy | 1.103 |
| Total_Freq | (0.027−0.002*Total_Freq) |
| Revenue | 1.004 |
| Employees | 1.0004 |
We gain the following insights from the ratios. With regard to Avg_Ret_Exp, we see that the ratio is dependent on the level of Avg_Ret_Exp. This is due to the fact that we include both the level and squared terms for Avg_Ret_Exp. For example, if we usually spend $15 on a given customer per month, by spending $16 we should see an increase in the expected duration by exp(0.0088−0.0004*15) = exp(0.0028) = 1.003. This means that by increasing our spending from $15 to $16, we should see an increase in expected duration by 0.3%. Also, it is important to note that this will vary depending on the initial level of Avg_Ret_Exp. With regard to Total_Crossbuy, we see that for each increase in cross-buy by one category, the expected duration should increase by 10.3%. With regard to Total_Freq, we see that the ratio is dependent on the level of Total_Freq. This is due to the fact that we include both the level and squared terms (similar to the case for Avg_Ret_Exp) for Total_Freq. For example, if we see a customer who has purchased five times in his/her lifetime, by purchasing a sixth time we should see an increase in the expected duration by exp(0.027−0.002*5) = exp(0.017) = 1.017. This means that when we see the customer increase total purchases from five to six, we should see an increase in expected duration by 1.7%. Again, it is important to note that this will vary depending on the initial level of Total_Freq. With regard to Revenue, we see that for each increase in Revenue by $1 million the expected duration should increase by 0.4%. Finally, with regard to Employees, we see that for each increase in Employees by one person the expected duration should increase by 0.04%.
Our next step is to determine how well the model does at explaining the expected duration of a customer. Since we have not observed the churn of 268 customers, we only predict the expected duration for the 232 customers we actually observe churning from the customer database and compare the actual durations we observe to the predicted durations. We make the prediction of duration using the following equation:
![]()
where exp(·) is the exponential function, Xi is the matrix of independent variables, and β is the vector of estimated coefficients from the modeling exercise. Once we have the predicted duration value for each of the customers who already churned, we compute the MAD using the following formula:
![]()
We find that MAD = 76.7. This means that on average each of our predictions of Duration deviates from the actual value by about 77 days. If we were to instead use the mean value of Duration (502.68) as our prediction for all the customers who churned (this would be the benchmark model case), we would get MAD = 142.4, or about 142 days. As we can see, our model does a significantly better job of predicting the length of time until customer churn than the benchmark case.
While we cannot determine the predictive accuracy of our model against the actual durations of the customers who have yet to churn without waiting for them to churn, we can see if our model does a good job of classifying customers as churning within the observed time window or being censored at the end of the time window. In this case we give a value of 1 to actual churn (Act_Ch) when a customer has a duration of less than 730, and 0 when the customer has a censored duration of 730. We then give a value of 1 to predicted churn (Pred_Ch) when the prediction of the customer duration is less than 730, and 0 when the prediction of customer duration is greater than or equal to 730. We can then compare the hit rate between the predicted and actual values of churn as in the following table:

As we can see from the table, our in-sample model accurately predicts 86.2% of the customers who have not churned (231/268) and 83.6% of the customers who already churned (194/232). This is a significant increase in the predictive capability of a random guess model1 which would be only 53.6% accurate for this dataset. Since our model is significantly better than the best alternative, in this case a random guess model, we determine that the predictive accuracy of the model is good. If there are other benchmark models available for comparison, the ‘best’ model would be the one which provides the highest accuracy of both the churn and not churn, or in other words the prediction would provide the highest sum of the diagonal. In this case the sum of the diagonal is 425 and it is accurate 85.0% of the time (425/500).
6.2.2 How Do You Implement it?
In this example we used PROC LIFEREG from SAS to estimate the AFT model to explain the drivers of customer churn. While we did use SAS to implement the modeling framework, programs such as GAUSS, MATLAB, and R can be used as well.