
The WHERE clause is the second clause of the SQL SELECT statement that we’ll now discuss in detail. The FROM clause, which we covered in the previous chapter, introduced the central concept behind SQL: tabular structures. It is the first clause that the database system parses and executes when we run an SQL query. A tabular structure is produced by the FROM clause using tables, joins, views, or subqueries. This tabular structure is referred to as the result set of the FROM clause.
The WHERE clause is optional. When it’s used, it acts as a filter on the rows of the result set produced by the FROM clause. The WHERE clause allows us to obtain a result set containing only the data that we’re really interested in, when the entire result set would contain more data than we need. In addition, the WHERE clause, more than any other, determines whether our query performs efficiently.
The WHERE clause is all about true conditions. Its basic syntax is:
WHERE condition that evaluates as TRUE
As we’ve learned, a condition is some expression that can be evaluated by the database system. The result of the evaluation will be one of TRUE, FALSE, or UNKNOWN. We’ll cover these one at a time, starting with TRUE.
A typical WHERE condition looks like this:
SELECT
name
FROM
teams
WHERE
id = 9
In this query, as we now know from Chapter 3, the result set produced by the FROM clause consists of all the rows of the teams table. After the FROM clause has produced a result set, the WHERE clause filters the result set rows, using the id = 9 condition. The WHERE clause evaluates the truth of the condition for every row, in effect comparing each row’s id column value to the constant value 9. The really neat part about this evaluation is that it happens all at once. You may think of the database system actually examining one value after another, and this mental picture is really not too far off the mark. There is, however, no sequence involved; it is just as correct to think of it happening on all rows simultaneously.
So what is the end result? No doubt you’re ahead of me here. Amongst all the rows in the teams table, the given condition will be TRUE for only one of them. For all the other rows, it will be FALSE. All the other rows are said to be filtered out by the WHERE condition.
But what if we want the other rows? Suppose we want the names of all teams who aren’t team 9?
There are two approaches:
-
WHERE NOT id = 9The
NOTkeyword inverts the truthfulness of the condition. -
WHERE id <> 9This is the not equals comparison operator. You can, if you wish, read it as “less than or greater than,” and this would be accurate.
Notice what we’ve done in both cases. We want all rows where the condition id = 9 is FALSE, but we wrote the WHERE clause in such a way that the condition evaluates as TRUE for the rows we want, in keeping with the general syntax:
WHERE condition that evaluates as TRUE
More specifically, the WHERE clause condition can include a NOT keyword, and, as we shall see in a moment, several conditions that are logically connected together to form a compound condition.
Besides TRUE and FALSE, there is one other result that’s possible when a condition is evaluated in SQL: UNKNOWN.
A condition evaluates as UNKNOWN if the database system is unable to figure out whether it’s TRUE or FALSE. In order to see UNKNOWN in action, we’ll need a good example, and for that, we’ll use yet another of our sample applications.
Important: A Couple of MySQL Gotchas
You would expect that with a concept as simple as equals or not equals, everything should work the same way. Regrettably, MySQL handles this slightly differently to the perceived norm. Let’s recap the scenario: we want all rows where id is not equal to 9.
The first way is to say NOT id = 9, which we expect to be TRUE for every row except one. Unfortunately, MySQL applies the NOT to the id column value first, before comparing to 9. In effect, MySQL evaluates it as:
WHERE ( NOT id ) = 9
MySQL—for reasons we’ll not go into—treats 0 and FALSE interchangeably, and any other number as TRUE, which it equates with 1. If id actually had the value of 0 (which no identifier should), then NOT id would be 1. For all other values, NOT id would be 0. And 0 isn’t equal to 9.
Be careful using NOT. Unless you’re sure, enclose whatever comes after NOT in parentheses. The following will work as expected in all database systems:
WHERE NOT ( id = 9 )
A better choice is to avoid using NOT altogether. Just use the not equals operator:
WHERE id <> 9
Also, avoid using MySQL’s version of the not equals operator, shown below:
WHERE id != 42
Note that using != is specific to MySQL and incompatible with other database systems.
So far, we’ve seen the Teams application, briefly, in Chapter 1, and the Content Management System application, in more detail, in Chapter 2 and Chapter 3.
Our next sample application, Shopping Carts, supports an online store for a web site, where site visitors can select items from an inventory and place them into shopping carts when ordering. Anyone who’s ever made a purchase on the Web will already be familiar with the general features of online shopping carts. In case you’re thinking that shopping carts are complex—and they are—our Shopping Carts sample application is very simple in comparison to a real one. It’s not meant to be industrial strength; it’s just a sample application, intended to allow us to learn SQL.
The first table we’ll look at in the Shopping Carts application is the items table. This table will contain all the items that we plan to make available for purchase online. Figure 4.1 shows the items table after its initial load of data.

Notice that some of the prices are empty in the diagram. These empty values are actually NULL. I haven’t discussed NULL in detail yet, although we met NULL briefly in Chapter 3: NULLs were returned by outer joins in the columns of unmatched rows.
Tip: To Create the Items Table
The SQL script to create the items table and add data to it is available in the download for the book. The file is called Cart_01_Comparison_operators.sql. It’s also found in the section called “Shopping Carts” in Appendix C.
What does it mean that the price of certain items is NULL? Simply that the price for that item is not known—yet. Obviously, we can’t sell an item with an unknown price, so we’ll have to supply a price value for these items eventually. NULL can have several interpretations, including unknown and not applicable. In the case of outer joins, NULLs in columns of unmatched rows are best understood as missing. In the items table example, the price column is NULL for items to which we’ve not yet been assigned a price, so the best interpretation is unknown.
How does all this talk about NULL relate to conditions in the WHERE clause? Let’s look at a sample query:
Here the WHERE clause consists of just one condition: the value of the price column must be 9.37 for that row to be returned in the result set. And the result set, shown in Figure 4.2, produced by this query is exactly what we’d expect.

As we learned earlier, the condition in the WHERE clause is evaluated on each row, and only those rows where the condition evaluates as TRUE are retained. So what happens when the WHERE clause is evaluated for items that have NULL in the price column? For these rows, the evaluation is UNKNOWN.
A condition evaluates as UNKNOWN if the database system cannot figure out whether it is TRUE or FALSE. The only situations where the evaluation comes out as UNKNOWN involve NULL.
When the WHERE clause condition, price = 9.37, is evaluated for items that have NULL in the price column, the evaluation is UNKNOWN. The database system cannot determine that NULL is equal to 9.37—because NULL isn’t equal to anything—and yet it also cannot determine that NULL is not equal to 9.37—because NULL isn’t not equal to anything either. It's confusing, certainly, but it’s just how standard SQL defines NULL. NULL is not equal to anything, not even another NULL. Any comparison involving NULL evaluates as UNKNOWN. So the result of the evaluation is UNKNOWN.
Don’t let this confuse you. NULLs are tricky, but all you have to remember is that the WHERE clause wants only those conditions which evaluate as TRUE. Rows for which the WHERE conditions evaluate either FALSE or UNKNOWN are filtered out.
WHERE clause conditions can utilize many other operators besides equal and not equal. These other operators are mostly straightforward and work just as we would expect them to.
When making a comparison between two values, SQL—as well as being able to determine whether the values are equal—can also determine whether a value is greater than the other, or less than the other.
Here’s a typical example that compares whether one number (integer or decimal) is less than another:
This sample query will return the name and type for any items that have a price less than ten (dollars). An item with a price of 9.37 would be included in the result set by the WHERE clause filtering operation, because 9.37 is less than 10.00.
Inequality operators also work on other data types, too. For example, you can compare two character strings:
WHERE name < 'C'
This is a perfectly good WHERE condition, which compares the values in the name column with the string ‘C’ and returns TRUE for all names that start with ‘A’ or ‘B’ because those name values are considered less than the value ‘C.’
For any comparison, a database uses a natural or inherent sequencing for the type of values being compared. With this in mind, comparing which value is less than the other can be seen as determining which of the values comes first in the natural sequence. For numbers, it’s the standard numeric sequence, (zero, one, two, etc) and for strings, it’s the alphabetical, or, more correctly, the collating sequence.
Note: Collations
Collations in SQL are determined by very specific rules involving the sequence of characters in a character set. We’re accustomed to think of the English alphabet as consisting of twenty-six simple letters from A to Z. Actually, there are 52, if you count lower case letters too. But there are also a few other letters, such as the accented é in the word résumé. Obviously, é with an accent is not the same as e without an accent; they are different characters. The question now is: does résumé (a noun meaning summary) come before or after the word resume (a verb meaning to begin again)? It’s the collating sequence that decides.
Collations exist to support many languages and character sets. All database systems have default collations, and these are safe to use without you even knowing about them. For more information, consult your manual for information specific to the database system you’re using. You can also find general information about collating sequences at Wikipedia.
Besides comparing numbers and strings, we can also compare dates using the equals and not equals operators (= and <>). For example, consider this WHERE clause:
WHERE created >= '2009-04-03'
For each row, the created column value is compared to the date constant value of 2009-04-03, and the row will be filtered out if the WHERE condition is not evaluated as TRUE. In other words, earlier dates are filtered out. We saw that the sequence for numbers is numeric (0, 1, 2, etc), and the sequence for strings is alphabetic (as defined by the collation). The sequence for date values is chronological. So 2008-12-30 comes before 2009-02-28, which comes before 2009-03-02.
Notice that the operator used in the example above is greater than or equal to. In total, there are six comparison operators in SQL, as shown in Table 4.1.
Table 4.1. Comparison operators in SQL
= |
equal to |
<> |
not equal to |
< |
less than |
<= |
less than or equal to |
> |
greater than |
>= |
greater than or equal to |
Remember, these can be applied to numbers, strings, and dates, but in each case, a specific sequence is used.
The LIKE operator implements pattern matching in SQL: it allows you to search for a pattern in a string (usually in a column defined as a string column), in which portions of the string value are represented by wildcard characters. These are a small set of symbolic characters representing one or more missing characters.
For example, consider the query:
The results of this query are shown in Figure 4.3.
In standard SQL, LIKE has two wildcards: the percent sign (%), which stands for zero or more characters, and the underscore (_), which stands for exactly one character. Notice how in the query above, name values which satisfied the WHERE condition each start with the characters thing, followed by zero or more additional characters. Thus, these values match the pattern specified by the LIKE string, so the condition evaluates as TRUE.

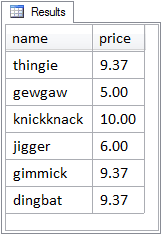
The purpose of the BETWEEN operator is to enable a range test to see whether or not a value is between two other values in its sequence of comparison. A typical example is:
SELECT
name
, price
FROM
items
WHERE
price BETWEEN 5.00 AND 10.00
The way BETWEEN works here is fairly obvious. Items are included in the result set if their price is between 5.00 and 10.00, as the result set in Figure 4.4 shows.
The BETWEEN range test is actually equivalent to the following compound condition, in which two conditions—in this case 5.00 <= price and price <= 10.00—are combined:
WHERE 5.00 <= price AND price <= 10.00
There are two important aspects to note here.
-
The first is the sequence.
5.00has to be less than or equal toprice, andpricehas to be less than or equal to10.00. In other words, the smaller value comes first, and the larger value comes last, with the value being tested coming between them. If the actual value does not lie between the endpoints, theBETWEENcondition evaluates asFALSE. -
The second important detail to notice is that the endpoints are included.

Here are two examples which will illustrate the flavor or correct usage of BETWEEN.[3] In the first example, we want to return all entries posted in the last five days:
WHERE created BETWEEN CURRENT_DATE AND CURRENT_DATE - INTERVAL 5 DAY
Here, CURRENT_DATE is a special SQL keyword that always corresponds to the current date when the query is run. Furthermore, the CURRENT_DATE - INTERVAL 5 DAY expression is the standard SQL way of doing date arithmetic (because that’s a minus sign rather than a hyphen). Yet this WHERE clause fails to return any rows at all, even though we know that there are rows in the table with a created value within the last five days. What’s going on?
Let’s assume that the CURRENT_DATE is 2009-03-20, which would mean that CURRENT_DATE - INTERVAL 5 DAY is 2009-03-15. The WHERE clause is then equivalent to:
WHERE created BETWEEN '2009-03-20' AND '2009-03-15'
This might look okay, but it isn’t. Syntactically, it’s fine, but semantically, it’s flawed. The flaw can be seen more easily if we rewrite the BETWEEN condition using the equivalent compound condition:
WHERE '2009-03-20' <= created AND created <= '2009-03-15'
Now, there may be some rows with a created value that is greater than or equal to 2009-03-20. There may also be some rows with a created value that is less than or equal to 2009-03-15. However, the same created value, on any given row, cannot simultaneously satisfy both conditions. Our mistake is to have placed the larger value first. Remember, with dates, smaller means chronologically earlier. The original WHERE clause should have been written with the earlier date first, like this:
WHERE created BETWEEN CURRENT_DATE - INTERVAL 5 DAY AND CURRENT_DATE
Our second example of correct BETWEEN usage concerns the endpoints. Consider the following WHERE clause, intended to return all entries for February 2009:
WHERE created BETWEEN '2009-02-01' AND '2009-03-01'
This is fine, except that it includes entries posted on the first of March, which is outside the date range we’re aiming for. Immediately, you might think to rewrite this as follows:
WHERE created BETWEEN '2009-02-01' AND '2009-02-28'
This is correct, but inflexible. If we wanted to generalize this so that it returns rows for any given month, we would need to calculate the last day of the month; this can become extremely hairy, as anyone can attest who’s coded a general date expression that takes February 29 into consideration. The best-practice approach in these cases, then, is to abandon the BETWEEN construction and code an open-ended upper endpoint compound condition:
WHERE '2009-02-01' <= dateposted AND dateposted < '2009-03-01'
Notice that the second comparison operator is solely less than, not less than or equal. All values of created greater than or equal to 2009-02-01 and up to, but not including, 2009-03-01, are returned.
The compound condition is usually written like this, for convenience:
WHERE created >= '2009-02-01' AND created < '2009-03-01'
The only requirement then is to calculate the date of the first day of the following month, rather than try to figure out when the last day of the month in question is.
Compound conditions—multiple conditions that are joined together—in the WHERE clause are common. Here’s an example:
SELECT
id
, name
, billaddr
FROM
customers
WHERE
name = 'A. Jones' OR 'B. Smith'
It’s clear what is meant here—return all rows from the customers table that have a name value of 'A.Jones' or 'B.Smith'. Unfortunately, this produces a syntax error, because 'B.Smith', by itself, is not a condition except in MySQL. In MySQL the string is interpreted by itself as FALSE, so the compound condition above is equivalent to “name equals 'A.Jones' (which may or may not be true), or FALSE.”
The correct way to write the compound condition shown above would be:
WHERE name = 'A.Jones' OR name = 'B.Smith'
Tip: To Create the Customers Table
The SQL script to create the customers table and add data to it is available in the download for the book. The file is called Cart_04_ANDs_and_ORs.sql. It’s also found in the section called “Shopping Carts” in Appendix C.
For convenience, Table 4.2 and Table 4.3 illustrate how compound conditions are evaluated.
Table 4.2. AND Truth Table
| Combination | Result |
|---|---|
TRUE AND TRUE |
TRUE |
TRUE AND FALSE |
FALSE |
FALSE AND TRUE |
FALSE |
FALSE AND FALSE |
FALSE |
Table 4.3. OR Truth Table
| Combination | Result |
|---|---|
TRUE OR TRUE |
TRUE |
TRUE OR FALSE |
TRUE |
FALSE OR TRUE |
TRUE |
FALSE OR FALSE |
FALSE |
Logically, these evaluations work just as you would expect them to. Sequence does not matter, so TRUE AND FALSE evaluates the same as FALSE AND TRUE, and TRUE OR FALSE evaluates the same as FALSE OR TRUE, as you can see. One way to remember them is that AND means both, while OR means either. With AND, both conditions must be TRUE for the compound condition to evaluate as TRUE, while with OR, either condition can be TRUE for the compound condition to evaluate as TRUE.
There are actually more complex truth tables than these, which involve the third logical possibility in SQL: UNKNOWN. However UNKNOWN, as mentioned previously, only comes up when NULLs are involved, and for the time being we shall leave them to one side in our exploration. Just keep in mind that UNKNOWN is not TRUE, and that the WHERE clause wants only TRUE to keep a row in the result set—FALSE and UNKNOWN are filtered out.
Note: Queens and Hearts
Let’s step into a real-world application of AND and OR. An ordinary deck of playing cards consists of four suits (Spades, Hearts, Diamonds, and Clubs) of 13 cards each (Ace, 2 through 10, Jack, Queen, and King). There is only one card that is both a Queen AND a Heart. The only card that satisfies these combined conditions is the Queen of Hearts.
There are 16 Queens OR Hearts. Not 17. There are four Queens, and there are 13 Hearts, but only 16 Queens and Hearts in total. This is because the combined conditions—be they AND or OR—are evaluated on each card separately. If the connector is OR, then 15 of those cards will evaluate either TRUE OR FALSE or FALSE OR TRUE. Only one will evaluate TRUE AND TRUE, which is still just TRUE, and which doesn’t make two cards out of one.
So there are only 16 Queens and Hearts, and we can see now that this use of and in the above title “Queens and Hearts” really means OR. And there is only one Queen of Hearts, because in this term, of means AND. After you do it for a while, you can see SQL everywhere.
Here’s a typical WHERE clause that combines AND and OR:
WHERE
customers.name = 'A.Jones' OR customers.name = 'B.Smith'
AND items.name = 'thingum'
The intent of this WHERE clause is to return thingums for either A.Jones or B.Smith. However the results of this query will actually return all thingums purchased by B.Smith, and all items for A.Jones. It is another example of an SQL statement that is syntactically okay, but semantically flawed. In this case, the reason for the semantic error is that AND takes precedence over OR when they are combined.
In other words, the compound condition is evaluated as though it had parentheses, like this:
WHERE
customers.name = 'A.Jones'
OR ( customers.name = 'B.Smith' AND items.name = 'thingum' )
Do you see how that works? The AND is evaluated first, and the expression in parentheses will evaluate to TRUE only if both conditions inside the parentheses are TRUE—the customer has to be B.Smith, and the item name has to be 'thingum.' Then the OR is evaluated with the other condition, customers.name = 'A.Jones.' So no matter what the item's name is, if the customer is A.Jones, the row will be returned.
The above example should therefore be rewritten, with explicit parentheses, like this:
WHERE
( customers.name = 'A.Jones' OR customers.name = 'B.Smith' )
AND items.name = 'thingum'
Tip: Use Parentheses When Mixing AND and OR
The best practice rule for combining AND and OR is always to use parentheses to ensure your intended combinations of conditions.
Note: WHERE 1=1
You may see in a web application a WHERE clause that includes the condition 1=1 and wonder what in the world is going on. For example consider the following:
WHERE
1=1
AND type = 'widgets'
AND price BETWEEN 10.00 AND 20.00
You usually find this in queries associated with search forms; it’s basically a way to simplify your application code.
If you have a search form where the conditions are optional, you’ll need a way of determining if a condition will require an AND to create a compound condition. The first condition, of course, won’t require an AND.
So rather than complicate your application code that creates the query with logic to determine if each condition should include an AND, if you always start the WHERE clause with 1=1 (which always evaluates as true), you can safely add AND to all conditions.
There’s another version of this trick using WHERE 1=0 for compound conditions using OR, like so:
WHERE
1=0
OR name LIKE '%Toledo%'
OR billaddr LIKE '%Toledo%'
OR shipaddr LIKE '%Toledo%'
Just like the 1=1 trick, you can safely add or remove conditions without worrying if an OR is required.
You’ll recall this example from the section on AND and OR:
WHERE
( customers.name = 'A.Jones' OR customers.name = 'B.Smith' )
AND items.name = 'thingum'
There’s another way to write this:
WHERE
customers.name IN ( 'A.Jones' , 'B.Smith' )
AND items.name = 'thingum'
In this version, we’ve moved the parentheses to be part of the IN condition rather than being used to control the evaluation priority of AND and OR. The IN condition syntax consists of an expression, followed by the keyword IN, followed by a list of values in parentheses. If any of the values in the list is equal to the expression, then the IN condition evaluates as TRUE. Should you wish to set the condition to check if a value is not in a list of values, you can prefix the IN condition with the NOT keyword:
WHERE NOT ( customers.name IN ( 'A.Jones', 'B.Smith' ) )
You could also write this as:
WHERE
customers.name NOT IN ('A.Jones', 'B.Smith')
Note that while the NOT keyword can be used with an IN condition in these two ways, this doesn’t always apply to other operators. For example, it’s perfectly okay to write:
WHERE NOT ( customers.name = 'A.Jones' )
However, it’s not okay to write:
WHERE customers.name NOT = 'A.Jones'
Another reason I prefer to place NOT in front of a parenthesized condition is that it’s easier to spot it in a busy WHERE clause (that is, one which has many conditions) than a NOT keyword buried inside a condition.
The list of values used in an IN condition may be supplied by a subquery. As we saw in Chapter 3, a subquery simply produces a tabular structure as its result set. A list of values is merely another fine example of a tabular structure, albeit a structure with only one column. Take, for example, a query that uses a subquery to provide the values for the IN condition:
SELECT
name
FROM
items
WHERE
id IN (
SELECT
cartitems.item_id
FROM
carts
INNER JOIN cartitems
ON cartitems.cart_id = carts.id
WHERE
carts.customer_id = 750
)
The subquery returns only one column, the item_id column from the cartitems table. There’s a WHERE clause in the subquery, which filters out all carts that don’t belong to customer 750. The values in the item_id column, but only for the filtered cart items, become the list of values for the IN condition; that way the outer or main query will return the names of all items for the selected customer.
This example again illustrates how to understand what a query with a subquery is doing: read the subquery first, to understand what it produces, and then read the outer query, to see how it uses the subquery result set.
Since this chapter is all about the WHERE clause, this is the appropriate context in which to discuss the concept of correlation. In this context, a subquery correlates (co-relates) to its parent query if the subquery refers to—and is therefore dependent on—the parent to be valid.
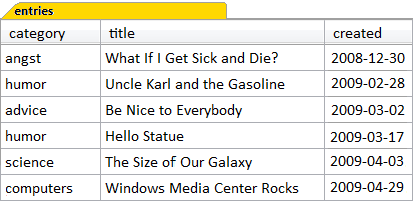
A correlated subquery can’t be run by itself, because it makes reference—via a correlation variable— to the outer or main query. To demonstrate, let’s work through an example based on the entries table in the Content Management System application that we saw in Chapter 3. This is shown in Figure 4.5.
The example will use this table in the outer query, and have a correlated subquery that obtains the latest entry in each category based on the created date:
SELECT
category
, title
, created
FROM
entries AS t
WHERE
created = (
SELECT
MAX(created)
FROM
entries
WHERE
category = t.category
)
Let’s start looking at this by reviewing the subquery first. There are two features to note here:
-
The subquery has a
WHEREcondition ofcategory = t.category. The “t” is the correlation variable, and it’s defined in the outer or main query as a table alias for theentriestable. -
You’ll also notice the
MAXkeyword in the subquery’sSELECTclause. We haven’t covered aggregate functions yet, of whichMAXis one, although we did see another one,COUNT, in Chapter 2. In this case,MAXsimply returns the highest value in the named column—the latestcreateddate.
Note: AS Means Alias
AS is a versatile keyword. It allows you to create an alias for almost any database object you can reference in a SELECT statement. In the example above, it creates an alias for a table. It can also alias a column, a view, and a subquery.
In essence, what this query does can be paraphrased as: “return the category, title, and created date of all entries, but only if the created date for the entry being returned is the latest created date for all the entries in that particular category.” Or, in brief, return the most recent entry in each category. The correlation ensures that the particular category is taken into consideration to determine the latest date, which is then used to compare to the date on each entry, as shown in Figure 4.6.
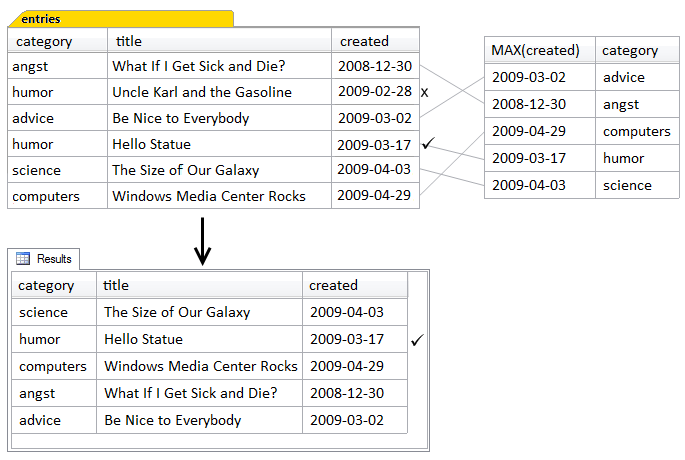
In this example, a comparison is made between each entry’s created value, and the maximum created value of all rows in that category, as produced by the subquery. If that entry contains the same date for its category as found by the subquery, it’s returned in the result set. If it’s not the same date, it’s discarded.
Because this is a very simple example, only one category actually has more than one entry: humor. The subquery determines that “Hello Statue” has the most recently created date, and thus discards "Uncle Karl and the Gasoline."
If Figure 4.6 reminds you of Figure 3.11 (which demonstrated how an inner join worked), remember that the distinguishing characteristic of a correlated subquery is that it’s tied to an object in the outer or main query, and can’t be run on its own. Joins, on the other hand, are part of the main query.
Aside from that, the inner join and the correlated subquery are quite similar. In the join, the rows of the categories and entries tables were joined, based on the comparison of their category columns in the join condition. In the correlated subquery, the rows of the entries table are compared to the rows of the tabular result set produced by the correlated subquery, and if this somehow reminds you of a join, full marks. In fact, correlated subqueries can usually be rewritten as joins.
Here’s the equivalent query written using a join instead of a correlated subquery:
SELECT
t.category
, t.title
, t.created
FROM
entries AS t
INNER JOIN (
SELECT
category
, MAX(created) AS maxdate
FROM
entries
GROUP BY
category
) AS m
ON m.category = t.category AND m.maxdate = t.created
The join version employs a subquery as a derived table, containing a GROUP BY clause. We’ll cover the GROUP BY clause in detail in Chapter 5, but for now, please just note that the purpose of the GROUP BY here is to produce one row per category. So the subquery produces a tabular result set consisting of one row per category, and each row will have that category’s latest date, which is given the column alias maxdate. Then the derived table, called m, is joined to the entries table, which uses the table alias t. Notice that there are two join conditions. You can see both of these conditions in the correlated subquery version, too—one inside the subquery (the category correlation), and the other in the WHERE clause (where maxdate in the subquery should equal the created date in the outer query).
An EXISTS condition is very similar to an IN condition with a subquery. The difference is that the EXISTS condition’s subquery merely needs to return any rows, be it a million or just one, in order for the EXISTS condition to evaluate to TRUE. Furthermore, it does not matter what columns make up those rows—merely that some rows exist (hence the name).
To demonstrate the use of EXISTS, we’ll use the Shopping Cart sample application again, but this time focus on the customers and their carts. To put these terms in context here, a customer is a person who has registered on the web site, and a cart is the collection of items that the customer has selected for purchase. Let’s say we want to find all the customers who have yet to create a cart. The key idea here is the not part of the requirement, so we’ll use NOT EXISTS in the solution:
SELECT
name
FROM
customers
WHERE
NOT EXISTS (
SELECT
1
FROM
carts
WHERE
carts.customer_id = customers.id
)
As you can see, we're using a correlated subquery again within the WHERE clause. This time, the correlation variable is not a table alias, but rather just the name of the table in the outer query. In other words, the subquery will return rows from the carts table where the cart’s customer_id column is the same as the id column in the customers table in the outer or main query. If a customer has one or more carts, as returned by the subquery, EXISTS would evaluate to TRUE. However, we're using NOT EXISTS in the main query so a customer's name will only be included in the result set if there are no carts for the customer returned by the subquery, exactly as required.
But what, you may well ask, is SELECT 1 all about? Well, as noted earlier, the EXISTS condition does not care which columns are selected, so SELECT 1 simply returns a column containing the numeric constant 1. The subquery could just as easily have selected the customer_id column. EXISTS will evaluate TRUE or FALSE, no matter which columns the subquery selects. We’ll cover the SELECT clause in detail in Chapter 7.
The query above can be rewritten using a NOT IN condition rather than a NOT EXISTS condition, if required. In fact, it can be written in two different ways using NOT IN. The first way is to use an uncorrelated subquery:
SELECT
name
FROM
customers
WHERE
NOT (
id IN (
SELECT
customer_id
FROM
carts
)
)
The second way uses a correlated subquery:
SELECT
name
FROM
customers AS t
WHERE
NOT (
id IN (
SELECT
customer_id
FROM
carts
WHERE
customer_id = t.customer_id
)
)
Which is better? That’s the subject of the next section: performance.
Incidentally, the same query can also be rewritten as a LEFT OUTER JOIN with a test for an unmatched row. We saw in the previous chapter that a left outer join will return NULLs in the columns of the right table for unmatched rows. In this case, we want customers without a cart, and the query is:
SELECT
customers.name
FROM
customers
LEFT OUTER JOIN carts
ON customers.id = carts.customer_id
WHERE
carts.customer_id IS NULL
Because it’s a left outer join, this query returns rows from the left table—in this case, customers—with matching rows, if any, from the right table. If there are no matching rows, then the columns in the result set which would have contained values from the right table are set to NULL. So then, if we test for NULL in the right table’s join column, this will allow the WHERE clause to filter out all the matched rows, leaving only the unmatched rows. In other words, testing for NULL effectively returns customers without a cart.
Note that the correct syntax to test for NULL is: IS NULL. You cannot use the equals operator (WHERE carts.customer_id = NULL), because NULL is not equal to anything.
We’ve just seen four different ways to write an SQL query to achieve a specific result:
-
NOT EXISTS -
NOT IN(uncorrelated) -
NOT IN(correlated) -
LEFT OUTER JOINwith anIS NULLtest
In practice, which of these is the best approach to take? Generally, you should let the database system optimize your queries for performance. The database optimizer—the part of the database system which parses our SQL, and then figures out how to obtain the data as efficiently as possible—is a lot smarter than many people think. It may realize that it doesn’t have to retrieve any carts at all!
Let’s consider what the LEFT OUTER JOIN version of the previous example is doing. The query will retrieve all carts for all customers, including customers who have no cart (since it’s a LEFT OUTER JOIN); then the WHERE clause throws away all rows retrieved, except those rows for customers who have no cart. Seems wasteful, doesn’t it? And it might well be … if it were an accurate portrayal. It’s unnecessary to actually retrieve any cart rows; what’s needed is simply to know which customers don’t have one. So the left outer join with an IS NULL test is the same, semantically, as the NOT EXISTS version.
What about the correlated and uncorrelated subqueries using the NOT IN condition? How will they perform? Here’s one way to think about what they’re doing: the uncorrelated subquery retrieves a list of customer_ids from all carts, and then, in the outer query, checks each customer’s id against this list, keeping those customers whose id is not in the list. The correlated subquery retrieves the customer_id from individual cart rows, but only the cart rows for that customer. Yet in the end, the correlated query will actually have retrieved all the cart rows too (like the uncorrelated query did), even though it keeps only those customers who don’t have a cart, as well. So it would seem that these queries, too, might wastefully retrieve all carts.
Intuition alone cannot lead us to a happy conclusion here. Our next step might be to test all versions and see how they fare. More often than not, they will all perform the same; ultimately, we’ll need to base our analysis on some facts, and for that, we need to do some research. See the section called “Performance Problems and Obtaining Help” in Appendix A for some ideas on how to proceed.
Indexing is the number one solution to poor performance.
Indexes are a special way of organizing information about the data in the database tables. In a sense, indexes are additional data, much the same way that the index at the back of a book is additional information about what’s in the book. Indexes are used by the database optimizer to find rows quickly. An index is built on a specific table column, and sometimes on more than one column.
A quick search for a topic in the index of a book will tell you which page/s it’s on, and then you can simply jump right to those pages. Similarly, if the database optimizer is looking for the cart rows for customer 880, the index can tell the optimizer where those rows are located. The important part about this is that the database optimizer does not need to read through all the rows in the table. It just goes directly to the desired rows.
Reading through all the rows in a table is called doing a table scan. Generally, this is to be avoided, although it must be done if you actually need to retrieve all the rows in the table. Using an index is known as performing an indexed retrieval and is—compared to a table scan—much, much faster (especially if it needs to be repeated many times, such as for every customer).
Where do indexes come from? We have to create them. As this is one of those database administration topics we won’t be covering in this book, you should consult the documentation for your particular database system if you’d like to investigate indexes. The important points to note, with regard to WHERE clause performance, are listed below:
-
Primary keys already have an index (by definition). There is no need to create an additional index on a primary key. Primary keys will be discussed in Chapter 10.
-
Foreign keys need to have an index declared (usually). Foreign keys will be discussed in Chapter 10.
-
Columns used in the
ONclause of joins are almost invariably either primary or foreign keys; in those instances where they’re not, they’ll typically benefit from having an index declared. -
Search conditions—conditions in the
WHEREclause—will usually benefit from having an index declared.
In time, you’ll gain a complete understanding of these concepts, so don’t worry if you’re feeling a little overwhelmed. Just remember, when you do encounter your first performance problem, to see the section called “Performance Problems and Obtaining Help” in Appendix A.
To tie this back to the recent customer example, you’ll recall that we had four different ways to write the SQL to find customers without a cart. Knowing that indexes are used by the database optimizer to improve performance, we can finally see that the cart rows, as hinted, do not actually need to be retrieved at all. The optimizer simply needs to know if a particular cart row exists. It can determine which customers have no cart by looking only at the data in the indexes, a much faster way of locating the cart than queries that require a table scan.
We covered a lot of ground in this chapter, but the main points that you should take away from it are:
-
The
WHEREclause acts as a filter on the rows of the tabular result set produced by theFROMclause. -
The
WHEREclause consists of one or more conditions, which are applied to each row produced by theFROMclause; each condition must evaluate toTRUEin order for that row to be accepted and not filtered out. These conditions can be combined withANDandORto make compound conditions. Sometimes we need to useNOTto specify the condition that we want to apply to the rows. -
WHEREclause conditions can use comparison operators,INlists,INwith a subquery, andEXISTSwith a subquery. -
Performance depends largely on indexing and not quite so much on the actual syntax of the SQL statement. Queries can often be written in different ways to achieve the same result.
In Chapter 5, we'll look at the GROUP BY clause, which operates on the rows produced by the FROM clause that weren’t filtered out by the WHERE clause.