
In the previous section, we have derived the formula for the size for each slice in a convolutional layer. As we discussed, one of the advantages of convolutional layers is that they reduce the number of parameters needed, improving performance and reducing over-fitting. After a convolutional operation, another operation is often performed—pooling. The most classical example is called max-pooling, and this means creating (2 x 2) grids on each slice, and picking the neuron with the maximum activation value in each grid, discarding the rest. It is immediate that such an operation discards 75% of the neurons, keeping only the neurons that contribute the most in each cell.
There are two parameters for each pooling layer, similar to the stride and padding parameters found in convolutional layers, and they are the size of the cell and the stride. One typical choice is to choose a cell size of 2 and a stride of 2, though it is not uncommon to pick a cell size of 3 and a stride of 2, creating some overlap. It should be noted, however, that if the cell size is too large, the pooling layer may be discarding too much information and is not helpful. We can derive a formula for the output of a pooling layer, similar to the one we derived for convolutional layers. Let's call, like before, I the size of the input slice, F the size of the cell (also called the receptive field), S the size of the stride, and O the size of the output. Pooling layers typically do not use any padding. Then we obtain in each dimension:


Pooling layers do not change the depth of the volume of the layer, keeping the same number of slices, since the pooling operation is performed in each slice independently.
It should also be noted that, similar to how we can use different activation functions, we can also use different pooling operations. Taking the max is one of the most common operations, but it is not uncommon to take the average of all the values, or even an L 2 measure, which is the square root of the sum of all the squares. In practice, max-pooling often performs better, since it retains the most relevant structures in the image.
It should be noted, however, that while pooling layers are still very much used, one can sometimes achieve similar or better results by simply using convolutional layers with larger strides instead of pooling layers (see, for example, J. Springerberg, A. Dosovitskiy, T. Brox, and M. Riedmiller, Striving for Simplicity: The All Convolutional Net, (2015), https://arxiv.org/pdf/1412.6806.pdf).
However, if pooling layers are used, they are generally used in the middle of a sequence of a few convolutional layers, generally after every other convolutional operation.
It is also important to note that pooling layers add no new parameters, since they are simply extracting values (like the max) without needing additional weights or biases:
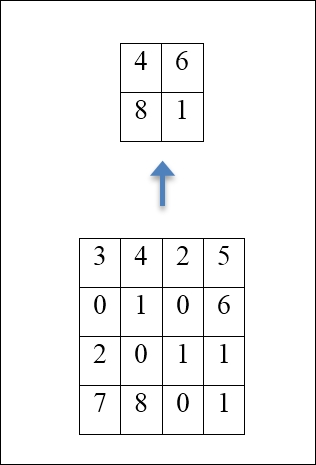
An example of a max-pool layer: the maximum from each 2x2 cell is calculated to generate a new layer.