
Chapter 6
Automating Data Processing with Oozie
WHAT’S IN THIS CHAPTER?
- Understanding Oozie fundamentals
- Getting to know the main Oozie components and programming for them
- Understanding the overall Oozie execution model
- Understanding Oozie support for a Service Level Agreement
As you have learned in previous chapters, MapReduce jobs constitute the main execution engine of the Hadoop ecosystem. Over the years, solution architects have used Hadoop on complex projects. These architects have learned that utilizing MapReduce jobs without a higher-level framework for orchestration and control of their execution can result in complexities and potential pitfalls because of the following reasons:
- Many data processing algorithms require execution of several MapReduce jobs in a certain sequence. (For specific examples of this, see Chapter 3.) For simple tasks, a sequence might be known in advance. Many times, however, a sequence depends on the intermediate execution results of multiple jobs. Without using a higher-level framework for controlling sequence execution, management of these tasks becomes quite difficult.
- It is often advantageous to execute a collection of MapReduce jobs based on time, certain events, and the presence of certain resources (for example, HDFS files). Using MapReduce alone typically requires the manual execution of jobs, and the more tasks you have, the more complex this becomes.
You can alleviate these potential difficulties by leveraging the Apache Oozie Workflow engine. Oozie is comprised of the following four main functional components:
- Oozie Workflow — This component provides support for defining and executing a controlled sequence of MapReduce, Hive, and Pig jobs.
- Oozie Coordinator — This provides support for the automatic execution of Workflows based on the events and the presence of system resources.
- Oozie Bundles — This engine enables you to define and execute a “bundle” of applications, thus providing a way to batch together a set of Coordinator applications that can be managed together.
- Oozie Service Level Agreement (SLA) — This provides support for tracking the execution of Workflow applications.
In this chapter, you learn more about Oozie and its main components. You also learn about languages that are used for programming each component, and how those components work together to provide automation and management of Hadoop jobs. Finally, you learn how to build and parameterize Oozie artifacts (applications) for each component, and how to use support provided by Oozie for SLA tracking. The information in this chapter is the foundation for the Oozie end-to-end example covered in the Chapter 7.
GETTING TO KNOW OOZIE
Oozie is a workflow/coordination system that you can use to manage Apache Hadoop jobs. As shown in Figure 6-1, one of the main components of Oozie is the Oozie server — a web application that runs in a Java servlet container (the standard Oozie distribution is using Tomcat). This server supports reading and executing Workflows, Coordinators, Bundles, and SLA definitions. It implements a set of remote Web Services APIs that can be invoked from Oozie client components and third-party applications.
FIGURE 6-1: Main Oozie components

The execution of the server leverages a customizable database. This database contains Workflow, Coordinator, Bundle, and SLA definitions, as well as execution states and process variables. The list of currently supported databases includes MySQL, Oracle, and Apache Derby. The Oozie shared library component is located in the Oozie HOME directory and contains code used by the Oozie execution.
Finally, Oozie provides a command-line interface (CLI) that is based on a client component, which is a thin Java wrapper around Oozie Web Services APIs. These APIs can also be used from third-party applications that have sufficient permissions.
A single Oozie server implements all four functional Oozie components:
- Oozie Workflow
- Oozie Coordinator
- Oozie Bundle
- Oozie SLA
Every functional component of the Oozie server is described in this chapter, starting with what Oozie Workflow is and how you can use it.
OOZIE WORKFLOW
Oozie Workflow supports the design and execution of Directed Acyclic Graphs (DAGs) of actions.
An Oozie Workflow definition is based on the following main concepts:
- Action — This is a specification of an individual Workflow task/step. For example, an action can represent execution of code, a MapReduce job, a Hive script, and so on.
- Transition — This is a specification of which action can be executed once a given action is completed. It is a way to describe a dependency between actions.
- Workflow — This is a collection of actions and transitions arranged in a dependency sequence graph.
- Workflow application — This is an Oozie Workflow defined in Oozie Workflow language. The Oozie server interprets the Oozie Workflow application definition and stores it in the Oozie database.
- Workflow job — This is a process in the Oozie server that interprets (runs) the Oozie Workflow definition. An Oozie Workflow job controls the sequence and conditions of action submission.
Oozie also supports two types of actions:
- Synchronous — This action is executed on an execution thread of the Oozie server itself.
- Asynchronous — This action is executed on an Hadoop cluster in the form of a MapReduce (or Hive/Pig/Sqoop) job. The Oozie server initiates asynchronous action, and then waits for its completion.
Transitions in Oozie Workflow are governed by the following two types of conditions:
- Structural conditions — These are statically defined in a Workflow DAG (transitions and fork-join construct).
- Runtime execution conditions — These can use results of the execution of previous actions in the form of process variables (switch-case construct) and success/failure paths.
Oozie describes Workflows using the Hadoop Process Definition Language (hPDL), which is a dialect of XML inspired by the JBoss Business Process Modeling Language (jBPML). The schema elements shown in Figure 6-2 represent actions supported by hPDL.
FIGURE 6-2: hPDL schema
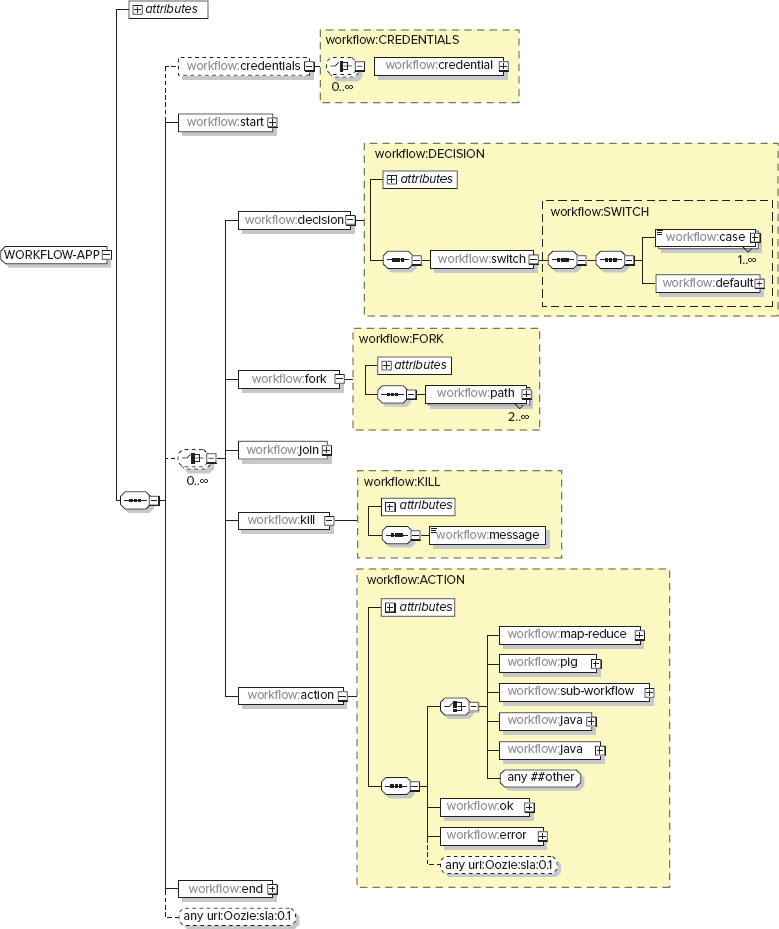
hPDL is a fairly compact language, and uses a limited number of flow control and action nodes. Oozie Workflow nodes can be either flow-control nodes or action nodes.
Flow-control nodes provide a way to control the Workflow execution path. Table 6-1 shows a summary of flow-control nodes.
TABLE 6-1: Flow-Control Nodes
| FLOW-CONTROL NODE | XML ELEMENT TYPE | DESCRIPTION |
| Start node | start | This specifies a starting point for an Oozie Workflow. |
| End node | end | This specifies an end point for an Oozie Workflow. |
| Decision node | decision | This expresses the “switch-case” logic. |
| Fork node | fork | This splits execution into multiple concurrent paths. |
| Join node | join | This specifies that Workflow execution waits until every concurrent execution path of a previous fork node arrives at the join node. |
| Sub-workflow node | sub-workflow | This invokes a sub-Workflow. |
| Kill node | kill | This forces an Oozie server to kill the current Workflow job. |
Action nodes provide a way for a Workflow to initiate the execution of a computation/processing task. Table 6-2 shows the action nodes provided by Oozie.
TABLE 6-2 Action Nodes

Oozie additionally supports an extensibility mechanism that enables you to create custom actions (see Chapter 8 for more about Oozie custom actions) that you can use as a new element of the Workflow language. Table 6-3 shows the currently available extension actions.
TABLE 6-3: Oozie Extension Actions

As mentioned earlier, Oozie supports two types of actions — synchronous or asynchronous. As indicated in Table 6-2 and Table 6-3, fs, Shell, ssh, and Email are implemented as synchronous actions, whereas the rest are asynchronous. The next section takes a closer look at how Oozie executes asynchronous actions.
Executing Asynchronous Activities in Oozie Workflow
All asynchronous actions are executed on an Hadoop cluster in the form of Hadoop MapReduce jobs. This enables Oozie to leverage the scalability, high-availability, and fault-tolerance benefits of a MapReduce implementation.
If you use Hadoop to execute computation/processing tasks triggered by a Workflow action, the Workflow job must wait until the computation/processing task completes before transitioning to the following node in the Workflow.
Oozie can detect completion of computation/processing tasks by using the following two mechanisms:
- Callback — When a computation or processing task is started by Oozie, it provides a unique callback URL to the task, and the task should invoke this callback to notify Oozie about its completion.
- Polling — In situations where the task failed to invoke the callback for any reason (for example, because of a transient network failure), Oozie has a mechanism to poll computation/processing tasks for completion.
Externalizing the execution of resource-intensive computations allows Oozie to conserve its server’s resources, ensuring that a single instance of an Oozie server can support thousands of jobs.
Oozie jobs are submitted to the Hadoop cluster using the Action/Executor pattern.
Each Oozie asynchronous action uses an appropriate Action/Executor pair. The Oozie Executor framework is at the heart of the Oozie server architecture. The examples in this section use the execution of an Oozie java action to examine the architecture of the Executor framework, starting with the Hello World Workflow example shown in Listing 6-1.
LISTING 6-1: Hello World Workflow
<workflow-app name="hello-world-wf" xmlns="uri:oozie:workflow:0.3"
xmlns:sla="uri:oozie:sla:0.1">
<start to="cluster"/>
<action name="cluster">
<java>
<prepare> [PREPARE SECTION] </prepare>
<main-class>HelloWorld</main-class>
<arg>[PROGRAM ARGUMENT]</arg>
<archive>[ARCHIVE SECTION]</archive>
<file>[FILE SECTION]</file>
</java>
<ok to="end "/>
<error to="kill "/>
</action>
<kill name="fail">
<message>
hello-world-wf failed
</message>
</kill>
<end name="end"/>
</workflow-app>This is a very simple Workflow that starts with an execution of the java action (the start node specifies the name of the first node to execute). This java action is implemented using HelloWorld class with specified program arguments. (Oozie will invoke a main method on this class, passing in program arguments.) With the <prepare>, <archive>, and <file> tags, you can specify additional information for class execution (which is described in more detail later in this chapter). If the class execution completes successfully (that is, with an exit code of 0), the transition will progress to an end action. Otherwise, the transition will progress to a kill action, and will produce a "hello-world-wf failed" message. Because a kill action has no explicit transition specified, the next action (end) will be invoked after the execution of the kill action. The end action will stop execution of the process.
As shown in Figure 6-3, processing of the java command starts with the invocation of the call method on the XCommand class. This method starts construction and submission of the MapReduce job for the java action.
FIGURE 6-3: Submission of a job for the java action in the Oozie Executor framework
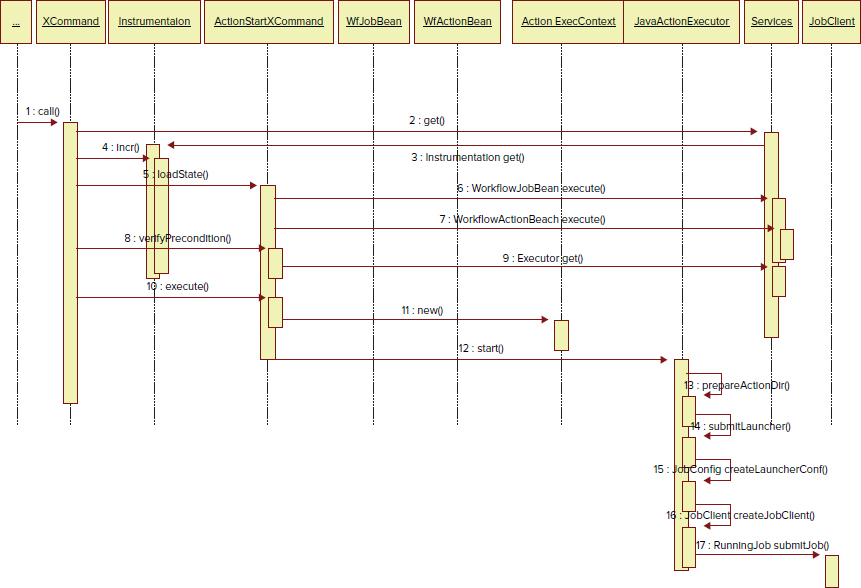
The method first obtains the instance of the Instrumentation class from the Services class, which maintains a pool of Instrumentation instances. This instance is used to set up timers, counters, variables, and locks for the job.
It then uses the loadState method of the ActionStartXCommand class to load the job configuration. The implementation of the ActionStartXCommand class achieves this by obtaining the Workflow object wfJob (class WorkflowJobBean) and action object wfAction (class WorkflowActionBean) from the Services class.
Next, the call method of XCommand uses the verifyPrecondition method of the ActionStartXCommand class to check the job status and obtain the instance of ActionExecutor (JavaActionExecutor, in this case) from the Services class, which maintains a pool of ActionExecutor instances.
Finally, the call method of XCommand uses the execute method of the ActionStartXCommand class to do the rest.
This method prepares the Hadoop job configuration, defines the retry policy, and creates the action execution context (class ActionExecutorContext), which serves as the container for the job configuration elements. It then invokes a start method on ActionExecutor (JavaActionExecutor, in this case) to complete the invocation.
The start method of ActionExecutor leverages a set of launchers to implement different steps of the action invocation. These launchers are created during ActionExecutor initialization, as shown in Listing 6-2.
LISTING 6-2: Launcher classes in JavaActionExecutor
protected List<Class> getLauncherClasses() {
List<Class> classes = new ArrayList<Class>();
classes.add(LauncherMapper.class);
classes.add(LauncherSecurityManager.class);
classes.add(LauncherException.class);
classes.add(LauncherMainException.class);
classes.add(FileSystemActions.class);
classes.add(PrepareActionsDriver.class);
classes.add(ActionStats.class);
classes.add(ActionType.class);
return classes;
} The launchers are responsible for the following:
- The PrepareActionsDriver class is used to parse the <prepare> XML fragment of the java action definition.
- The FileSystemActions class supports execution of the HDFS operations (delete, mkdir, and so on) during the preparation phase.
- The ActionType class is just the enumerator that specifies the type of possible action values (MAP_REDUCE, PIG, and HIVE).
- The LauncherMapper class is responsible for submitting the java action itself to the Hadoop cluster as a MapReduce job with a single mapper and no reducers.
- The LauncherSecurityManager is used to control security aspects of the Hadoop job.
The start method of ActionStartCommand first calls the prepareActionDir method that moves the launcher’s job jar from the Oozie server node to the action directory on HDFS, and then invokes the submitLauncher method.
This method first parses the action XML configuration to create the Hadoop objects Configuration and JobConf (using the HadoopAccessorService class). Once this is done, the submitLauncher method configures the LauncherMapper object by setting the main class (from the <java-main> java action element) and program arguments (from the <arg> java action elements).
Then, the submitLauncher method specifies the libraries (<archive> section) and files (<file> section) that will be moved to the Hadoop distributed cache. It sets up the credentials and named parameters, and creates an instance of the Hadoop JobClient class. The JobClient object is used by the java Executor to submit the Hadoop job to the cluster and implement the retry logic.
Finally, the submitLauncher method retrieves the submitted job URL from the JobConf instance. This URL is used by the Oozie server to track the job state in the Oozie console (which you learn more about in Chapter 7).
The Java class specified in the Oozie java action is actually invoked on the Hadoop cluster from the instance of the LauncherMapper class that implements the org.apache.hadoop.mapred.Mapper interface. In the map method (called only once), it retrieves the class name specified in the Oozie action definition, and invokes the main method of that class with the (simplified) code fragment, as shown in Listing 6-3.
LISTING 6-3: Invocation of java action main class on the Hadoop cluster
..............................................................
String mainClass = getJobConf().get(CONF_OOZIE_ACTION_MAIN_CLASS);
String[] args = getMainArguments(getJobConf());
Class klass = getJobConf().getClass(CONF_OOZIE_ACTION_MAIN_CLASS,
Object.class);
Method mainMethod = klass.getMethod("main", String[].class);
mainMethod.invoke(null, (Object) args);
...............................................................The MapReduceActionExecutor extends the JavaActionExecutor class by overriding several methods. The implementation of the setupActionConf method supports Streaming and Pipes parameters (if the map-reduce action specifies Pipes or Streaming APIs).
The implementation of the getLauncherClasses method adds main methods for different types of map-reduce invocations, including Pipes, Streaming, and so on, as shown in Listing 6-4.
LISTING 6-4: Launchers for the map-reduce action
protected List<Class> getLauncherClasses() {
List<Class> classes = super.getLauncherClasses();
classes.add(LauncherMain.class);
classes.add(MapReduceMain.class);
classes.add(StreamingMain.class);
classes.add(PipesMain.class);
return classes;
}So, when the jobClient.submitJob(launcherJobConf) is invoked in the submitLauncher method of the JavaActionExecutor (base) class, either the MapReduceMain, StreamingMain, or PipesMain launcher is used. As an example, for the Java map-reduce action, this would effectively result in running MapReduceMain.main, which starts a new MapReduce job on the cluster.
For Hive and Pig actions, the invocation steps are similar to the steps described previously, but the main launcher class is specific to each action. As an example, for the Pig action, the main launcher class is PigMain, which extends the class LauncherMain. In the PigMain class, the main, run, and runPigJob methods are sequentially invoked on a cluster. The runPigJob method invokes the PigRunner class (this class is not part of the Oozie distribution — it belongs to the Pig framework). This way, the control over the Workflow job execution is transferred to the Pig framework. That can result in several MapReduce jobs on the Hadoop cluster.
One of the important characteristics of the execution of an action is its retry and recovery implementations. The following section takes a closer look how Oozie retry and recovery works.
Oozie Recovery Capabilities
Oozie provides recovering capabilities for Workflow jobs that are leveraging the Hadoop cluster recovery capabilities. Once an action starts successfully, Oozie relies on MapReduce retry mechanisms. In the case where an action fails to start, Oozie applies different recovery strategies, depending on the nature of the failure. In the case of a transient failure (such as network problems, or a remote system temporarily being unavailable), Oozie sets the maximum retries and retry interval values, and then performs a retry. The number of retries and timer intervals for a type of action can be specified at the Oozie server level, and can be overridden on the Workflow level.
Table 6-4 shows the parameter names and default values.
TABLE 6-4: Oozie Retry Properties
| PROPERTY NAME | DEFAULT VALUE | DEFINED IN CLASS |
| oozie.wf.action.max.retries | 3 | org.apache.oozie.client. OozieClient |
| oozie.wf.action.retry.interval | 60 sec | org.apache.oozie.client. OozieClient |
The Oozie Workflow engine described thus far automates the execution of a group of MapReduce jobs defined as a structured group of Workflow actions. But it does not support the automatic start of Workflow jobs, their repeated execution, analysis of data dependencies between Workflow jobs, and so on. This functionality is supported by the Oozie Coordinator, which you learn more about shortly.
Now that you know what Oozie Workflow is and how it is executed, take a look at a Workflow’s life cycle.
Oozie Workflow Job Life Cycle
Once the Workflow application is loaded to the Workflow server, it becomes a Workflow job. As shown at Figure 6-4, possible states for a Workflow job are PREP, RUNNING, SUSPENDED, SUCCEEDED, KILLED, and FAILED.
FIGURE 6-4: Workflow job life cycle
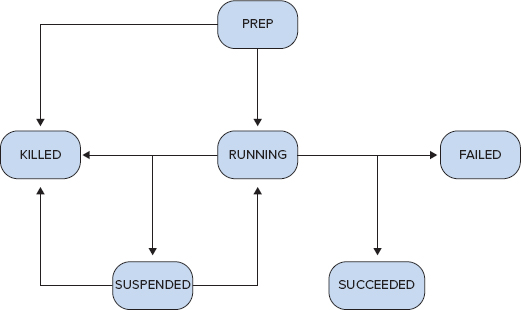
A loaded Workflow job is in the PREP state. A job in this state can be started (that is, in the RUNNING state) or deleted (that is, in the KILLED state). A running Workflow can be suspended by the user (SUSPENDED state), succeed (SUCCEEDED state), fail (FAILED state), or it can be killed by the user (KILLED state). A suspended job can be resumed (RUNNING state) or killed (KILLED state).
OOZIE COORDINATOR
The Oozie Coordinator supports the automated starting of Oozie Workflow processes. It is typically used for the design and execution of recurring invocations of Workflow processes triggered by time and/or data availability.
The Coordinator enables you to specify the conditions that trigger Workflow job execution. Those conditions can describe data availability, time, or external events that must be satisfied to initiate a job. The Coordinator also enables you to define dependencies between Workflow jobs that run regularly (including those that run at different time intervals) by defining outputs of multiple subsequent runs of a Workflow as the input to the next Workflow.
The execution of the Oozie Coordinator is based on the following concepts:
- Actual time — This is the time when a Coordinator job is started on a cluster.
- Nominal time — This is the time when a Coordinator job should start on a cluster. Although the nominal time and the actual time should match, in practice, the actual time may occur later than the nominal time because of unforeseen delays.
- Data set — This is the logical collection of data identifiable by a name. Each data instance can be referred to individually using a URI.
- Synchronous data set — This is the data set instance associated with a given time interval (that is, its nominal time).
- Input and output events — These are the definitions of data conditions used in a Coordinator application. The input event specifies the data set instance that should exist for a Coordinator action to start execution. The output event describes the data set instance that a particular Coordinator action should create on the HDFS.
- Coordinator action — This is a Workflow job associated with a set of conditions. A Coordinator action is created at the time specified in its definition. The action enters a waiting state until all required inputs for execution are satisfied, or until the waiting times out.
- Coordinator application — This is a program that triggers Workflow jobs when a set of conditions is met. An Oozie Coordinator application is defined by using a Coordinator language (which you learn about shortly).
- Coordinator job — This is a running instance of a Coordinator application.
Similar to Oozie Workflow, the Oozie Coordinator language is an XML dialect, as shown in the schema diagram in Figure 6-5.
FIGURE 6-5: Coordinator language schema

Table 6-5 summarizes the main elements and attributes of the XML Coordinator language. (Attributes are not shown in Figure 6-5.)
TABLE 6-5: Coordinator Language
| ELEMENT TYPE | DESCRIPTION | ATTRIBUTES AND SUB-ELEMENTS |
| coordinator-app | This is the top-level element of a Coordinator application. | name, frequency, start, end |
| controls | This specifies the execution policy for a Coordinator job. | timeout, concurrency, execution, throttle |
| action | This specifies the location of the single Workflow application and properties for that application. | workflow, app-path, configuration |
| dataset | This represents the collections of data referred to by a logical name. Data sets specify data dependences between Coordinator actions from different Coordinator applications. | name, frequency, initial-instance, uri-template,done-flag |
| input-events | This specifies the input conditions (in the form of data set instances) that are required to submit a Coordinator action. | name, dataset, start-instance, end-instance |
| output-events | This specifies the data set that should be produced by a Coordinator action. | name, dataset, instance |
The Coordinator controls element shown in Figure 6-5 enables you to specify a job’s execution policies. This element can contain the following sub-elements:
- timeout — This is the maximum time that a materialized action will be waiting for all additional conditions before being discarded. The default value of -1 means that the action will wait forever, which is not always the most desirable behavior. In this case, a large number of actions may be in a waiting state, and, at some point, all of them will start executing, which will overwhelm the whole system.
- concurrency — This is the maximum number of Coordinator jobs that can be running at the same time. The default value is 1.
- execution — This specifies the execution order for cases when multiple instances of the Coordinator job are simultaneously transitioning from a ready state to an execution state. Valid values include the following:
- FIFO (the default) — Oldest first
- LIFO — Newest first
- ONLYLAST — Discards all older materializations
- throttle (not shown in Figure 6-5) — This is the maximum number of Coordinator actions that are allowed to be waiting for all additional conditions concurrently.
Data sets are used for specifying input and output events for Coordinator applications. A dataset element (described in more detail later in this chapter) may contain the following attributes and sub-elements:
- name — This is the attribute used for referencing this data set from other Coordinator elements (events). The value of the name attribute must be a valid Java identifier.
- frequency — This is the attribute that represents the rate (in minutes) for creation (periodically) of subsequent instances of a data set. Frequency is commonly indicated using expressions such as ${5 * HOUR}.
- initial-instance — This is the attribute that specifies the time when the first instance of the data set should be created (that is, the data set baseline). Instances that follow will be created starting from that baseline using the time intervals specified by the frequency element. Each Coordinator application that uses the data set specifies the end time when it stops using the data set.
- uri-template — This is the sub-element that specifies the base identifier for the data set instances. The uri-template is usually constructed using expression language constants and variables. An example of expression language constants used for uri-template might be ${YEAR}/${MONTH}/${HOUR}. An example of variables for uri-template might be ${market}/${language}. Both constants and variables are resolved at run time. The difference is that the expression language constants are resolved by the Oozie server and are Coordinator job-independent, whereas variable values are specific for a given Coordinator job.
- done-flag — This is the sub-element that specifies the name of the file that is created to mark the completion of data set processing. If done-flag is not specified, Hadoop creates a _SUCCESS file in the data instance output directory. If the done-flag is set to empty, the Coordinator considers it an instance of a data set that is available if the output directory exists.
Listing 6-5 shows a simple example of dataset.
LISTING 6-5: Example of using a dataset
<dataset name="testDS" frequency="${coord:hours(10)}"
initial-instance="2013-03-02T08:00Z" timezone="${timezone}">
<uri-template>
${baseURI}/${YEAR}/${MONTH}/${DAY}/${HOUR}/${MINUTE}
</uri-template>
<done-flag>READY</done-flag>
</dataset>The dataset defined in Listing 6-5 has the frequency 10 hours (600 minutes). If the variable baseURI is defined as /user/profHdp/sample, the dataset defines the set of locations for the dataset instances shown in Listing 6-6.
LISTING 6-6: Data set instances directories
/user/profHdp/sample/2013/03/02/08/00
/user/profHdp/sample/2013/03/02/18/00
/user/profHdp/sample/2013/03/03/04/00
/user/profHdp/sample/2013/03/03/14/00
/user/profHdp/sample/2013/03/04/00/00
/user/profHdp/sample/2013/03/04/08/00The input-events element specifies the input conditions for a Coordinator application. As of this writing, such input conditions are restricted to availability of dataset instances. Input events can refer to multiple instances of multiple datasets.
input-events is specified with the <input-events> element, which can contain one or more <data-in> elements, each having the name attribute, the dataset attribute, and two sub-elements (<start-instance> and <end-instance>). Alternatively, instead of those two elements, input-events can use a single <instance> sub-element.
When both <start-instance> and <end-instance> elements are used, they specify the range of dataset instances that should be available to start a Coordinator job. Listing 6-7 shows an example.
LISTING 6-7: Example of the input-events
<input-events>
<data-in name="startLogProc" dataset="systemLog">
<start-instance>${coord:current(-3)}</start-instance>
<end-instance>${coord:current(0)}</end-instance>
</data-in>
<data-in name="startLogProc" dataset="applicationLog">
<start-instance>${coord:current(-6)}</start-instance>
<end-instance>${coord:current(0)}</end-instance>
</data-in>
</input-events>The input-events startLogProc in Listing 6-7 defines a dependency between two data sets: systemLog and applicationLog. It also specifies that the startLogProc event occurs only when three (-3) sequential instances of the systemLog data set and six (-6) instances of the applicationLog data set are available.
Figure 6-6 shows a time line for an example in Listing 6-7. If you assume that the Coordinator application A produces an instance of systemLog every two hours, and Coordinator application B produces the instance of the dataset applicationLog every hour, then application C (driven by the input event startLogProc) can start every six hours.
FIGURE 6-6: Time schedule for the input event
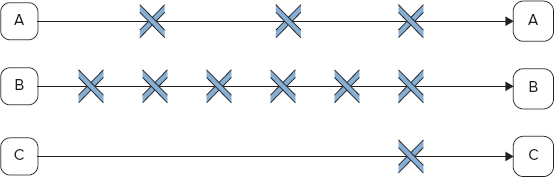
output-events specifies datasets that are produced by Coordinator jobs. Oozie does not enforce output_events, but rather allows an output dataset to be used in input_events for another Coordinator job. At that point, its availability on a cluster will be enforced.
Input and output events enable you to specify the interaction of Coordinator jobs via the datasets they produce and consume. That mechanism is referred to as an Oozie data pipeline. In Chapter 7, you see an example of Coordinator applications that compose such a data pipeline.
The Coordinator job can be in one of the following states: PREP, RUNNING, PREPSUSPENDED, SUSPENDED, PREPPAUSED, PAUSED, SUCCEEDED, DONWITHERROR, KILLED, and FAILED. Figure 6-7 shows all valid transitions between Coordinator job states.
FIGURE 6-7: Coordinator job life cycle

Following are key points to note in Figure 6-7:
- A loaded Coordinator job is in the PREP state.
- A job in the PREP state can be started (RUNNING state), suspended (PREPSUSPENDED), or reach a pause time (PREPPAUSED state) and deleted (KILLED state). A PREPSUSPENDED job can either resume (PREP state) or be deleted (KILLED state). A PREPPAUSED job can be killed (KILLED state) or a pause time can expire (PREP state).
- A running Coordinator job can be suspended (SUSPENDED state) or killed (KILLED state) by the user. It can succeed (SUCCEEDED state) or fail (FAILED state). When a user requests to kill a Coordinator job, Oozie sends a kill notification to all submitted Workflow jobs. If any Coordinator action finishes with a status that is not KILLED, Oozie puts the Coordinator job into the DONWITHERROR state. When pause time is reached for a running job, Oozie pauses it (PAUSED state). A suspended job can be resumed (RUNNING state) or killed (KILLED state).
- Finally, a paused job can be suspended (SUSPENDED state) or killed (KILLED state), or a pause can expire (RUNNING state).
Although the Oozie Coordinator provides a powerful mechanism for managing Oozie Workflows and defining conditions for their execution, in cases where there are many Coordinator applications, it becomes difficult to manage all of them. Oozie Bundle provides a convenient mechanism for “batching” multiple Coordinator applications, and managing them together.
OOZIE BUNDLE
Oozie Bundle is a top-level abstraction that enables you to group a set of Coordinator applications into a Bundle application (defined earlier in this chapter as a data pipeline). Coordinator applications grouped into a Bundle can be controlled (start/stop/suspend/resume/rerun) together as a whole. Bundle does not allow you to specify any explicit dependency among the Coordinator applications. Those dependencies are specified in Coordinator applications themselves through input and output events.
Oozie Bundle uses the following concepts:
- kick-off-time — This is the Bundle application starting time.
- Bundle action — This is a Coordinator job that is started by the Oozie server for a Coordinator application belonging to the Bundle.
- Bundle application — This is a collection of definitions that specifies a set of Coordinator applications that are included in the Bundle. A Bundle application is defined with the Oozie Bundle language.
- Bundle job — This is a process in the Oozie server that interprets (runs) an Oozie Bundle application. Before running a Bundle job, the corresponding Bundle application must be deployed to an Oozie server.
A Bundle is defined by using the Bundle language, which is an XML-based language. Figure 6-8 shows a schema for the Bundle language.
FIGURE 6-8: Bundle language schema
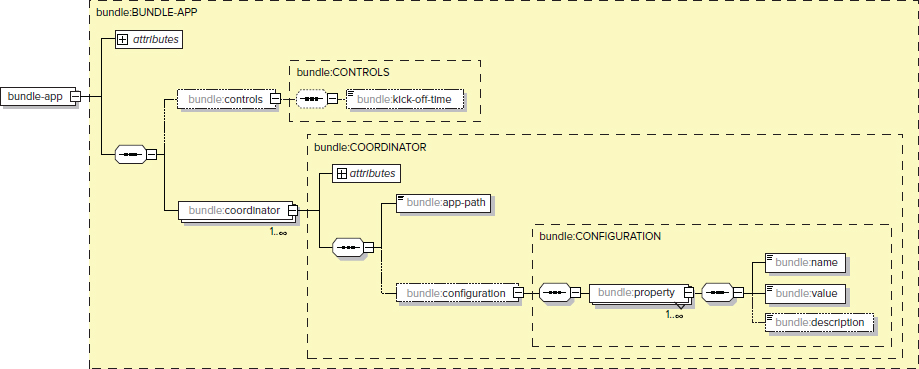
Table 6-6 shows the main top-level elements of the Bundle definition language.
TABLE 6-6: Bundle Language Elements
| ELEMENTS AND ATTRIBUTES | DESCRIPTION | ATTRIBUTES AND SUB-ELEMENTS |
| bundle-app | This is the top-level element of the Bundle application. | name, controls, coordinator |
| name | This is the attribute that specifies the name for the Bundle. For example, you can use it to refer to the Bundle application in the Hadoop CLI command. | |
| controls | This is an element that contains only one attribute — kick-off-time. That attribute specifies the start time for a Bundle application. | kick-off-time |
| coordinator | This element describes a Coordinator application included in the Bundle. A Bundle application can have multiple Coordinator elements. | name, app-path, configuration |
Every Bundle is identified by its name. Execution of a Bundle is specified by the controls element, which specifies a Bundle start time (or kick-off-time). A Bundle can contain one or more coordinator elements. For every coordinator element, it requires the following:
- name — This is the name of the Coordinator application. It can be used to refer to this application through a Bundle to control such actions as kill, suspend, or rerun.
- app-path — This sub-element specifies the location of Coordinator definitions (for example, the coordinator.xml file).
- configuration — This is an optional Hadoop configuration to parameterize corresponding Coordinator applications.
Listing 6-8 shows an example of a Bundle application that includes two Coordinator applications.
LISTING 6-8: Example of a Bundle application
<bundle-app name='weather-forecast'
xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance'
xmlns='uri:oozie:bundle:0.1'>
<controls>
<kick-off-time>${kickOffTime}</kick-off-time>
</controls>
<coordinator name='monitor-weather-datastream' >
<app-path>${'monitor-weather-coord-path}</app-path>
<property>
<name>monitor-time</name>
<value>60</value>
</property>
<property>
<name>lang</name>
<value>${LANG}</value>
</property>
<configuration>
</coordinator>
<coordinator name='calc-publish-forecast' >
<app-path>${'calc-publish-coord-path}</app-path>
<configuration>
<property>
<name>monitor-time</name>
<value>600</value>
</property>
<property>
<name>client-list</name>
<value>${LIST}</value>
</property>
</configuration>
</configuration>
</coordinator>
</bundle-app>The first application in Listing 6-8 monitors and pre-processes raw weather data, and it runs every 60 seconds, as specified in the <property> section. The second application calculates and publishes the weather forecast every 10 minutes. It is assumed that the output data sets from the first application are used to pass data to the second application. So, the Bundle groups applications together that create a data pipeline. From this example you can see that it makes perfect sense for operations to control those two applications together as a single unit.
As shown in Figure 6-9, at any time, a Bundle job can be in one of the following states: PREP, RUNNING, PREPSUSPENDED, SUSPENDED, PREPPAUSED, PAUSED, SUCCEEDED, DONWITHERROR, KILLED, FAILED.
FIGURE 6-9: Bundle application state transition
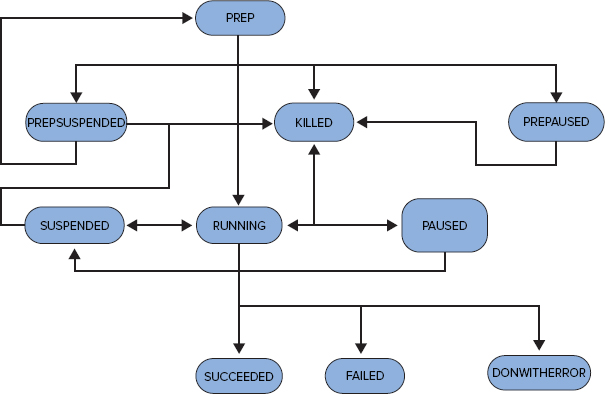
Following are key points to note in Figure 6-9:
- A loaded Bundle job is in the PREP state.
- A job in this state can be started (RUNNING state), suspended (PREPSUSPENDED state), reach a pause time (PREPPAUSED state), or be deleted (KILLED state). A PREPSUSPENDED job can either be resumed (PREP state) or deleted (KILLED state). A PREPPAUSED job can be killed (KILLED state), or a pause time can expire (PREP state).
- A running Bundle can be suspended (SUSPENDED state) or killed (KILLED state) by the user. It can succeed (SUCCEEDED state) or fail (FAILED state). When a pause time is reached for a running job, Oozie pauses the job (PAUSED state). If not all Coordinator jobs finish with the same status, Oozie puts the Bundle job into the DONWITHERROR state. A suspended job can be resumed (RUNNING state) or killed (KILLED state).
- Finally, a paused job can be suspended (SUSPENDED state) or killed (KILLED state), or a pause can expire (RUNNING state).
Now that you know the main components of Oozie and the way they are used, the next section looks at how Oozie’s JSP-like Expression Language (EL) can be used to parameterize the definitions of these components.
OOZIE PARAMETERIZATION WITH EXPRESSION LANGUAGE
All types of Oozie applications (Workflow, Coordinator, and Bundle) can be parameterized with Oozie Expression Language (EL). In this section, you learn about the most important EL constants and functions defined by Oozie specifications for Workflow, Coordinator, and Bundle applications.
Basic constants are the simplest elements of EL. Following are some examples:
- KB: 1024 — 1 kilobyte
- MB: 1024 * KB — 1 megabyte
- MINUTE — 1 minute
- HOUR — 1 hour
Additional EL constants include Hadoop constants, as in the following examples:
- RECORDS — This is the Hadoop record counters group name.
- MAP_IN — This is the Hadoop mapper input record counters name.
Some other constants include MAP_OUT, REDUCE_IN, REDUCE_OUT, and GROUPS.
Basic EL functions provide support for operations with string, data, encoding, and access to some configuration parameters. Following are some examples:
- concat(String s1, String s2) — This is a string concatenation.
- trim(String s) — This returns a trimmed version of a given string.
- urlEncode(String s) — This converts a string to the application/x-www-form-urlencoded MIME format.
Workflow Functions
Workflow EL functions provide access to Workflow parameters. Following are some examples:
- wf:id() — This returns the Oozie ID of the current Workflow job.
- wf:appPath() — This returns the application path of the current Workflow.
- wf:conf(String name) — This can be used to obtain the complete content of the configuration for the current Workflow.
- wf:callback(String stateVar) — This returns the callback URL for the current Workflow node for a given action. The parameter stateVar specifies the exit state for the action.
- wf:transition(String node) — If the node (action) was executed, this function returns the name of the transition node from the specified node.
Some other functions commonly used with Workflow include wf:lastErrorNode(), errorCode(String node), errorMessage(String message), wf:user(), and wf:group().
Coordinator Functions
Coordinator EL functions provide access to Coordinator parameters, as well as parameters of input events and output events. Following are some examples:
- coord:current(int n) — This is used to access the name of (n-th) data set instance in input and output events.
- coord:nominalTime() — This retrieves the time of the creation of a Coordinator action as specified in the Coordinator application definition.
- coord:dataIn(String name) — This resolves to all the URIs for the data set instances specified in an input event dataset section. This EL function is commonly used to pass the URIs of data set instances that will be consumed by a Workflow job triggered by a Coordinator action.
Some other commonly used Coordinator functions include coord:dataOut(String name), coord:actualTime(), and coord:user().
Bundle Functions
No specialized EL functions exist for Bundle, but a Bundle definition (along with Workflow and Coordinator definition) can use any of the basic EL functions described earlier.
Other EL Functions
MapReduce EL functions provide access to a MapReduce job’s execution statistics (counters). For example, hadoop:counters(String node) enables you to obtain the values of the counters for a job submitted by an Hadoop action node.
HDFS EL functions are used to query HDFS for files and directories. Following are some examples:
- fs:exists(String path) — This checks whether or not the specified path URI exists on HDFS.
- fs: fileSize(String path) — This returns the size of the specified file in bytes.
Other commonly used HDFS functions include fs:isDir(String path), fs:dirSize(String path), and fs:blockSize(String path).
When you use EL functions, you can significantly simplify access to Oozie and Hadoop functionality and data. You can also externalize most of the Oozie execution parameters. Instead of changing the Oozie application (Workflow/Coordinator/Bundle) every time a parameter (such as file location, timing, and so on) changes, you can externalize these parameters into a configuration file, and change just the configuration file without touching the applications. (Compare this to passing parameters to a Java application.)
Next, you look at the overall Oozie execution model — the way the Oozie server processes Bundle, Coordinator, and Workflow jobs.
OOZIE JOB EXECUTION MODEL
Figure 6-10 shows a simplified model that covers the execution of the Oozie Bundle, Coordinator, Workflow, and Workflow action, including submission of jobs from Oozie to the Hadoop cluster. This model does not show such details as state transition for Coordinator actions, or the difference between a Coordinator job, application, and action (which was discussed earlier in this chapter). Rather, you should concentrate more on the interaction between Oozie components (Bundle, Coordinator, and Workflow) up to the submission of Hadoop jobs (MapReduce, Hive, and Pig jobs) to the Hadoop cluster.
FIGURE 6-10: Oozie execution model
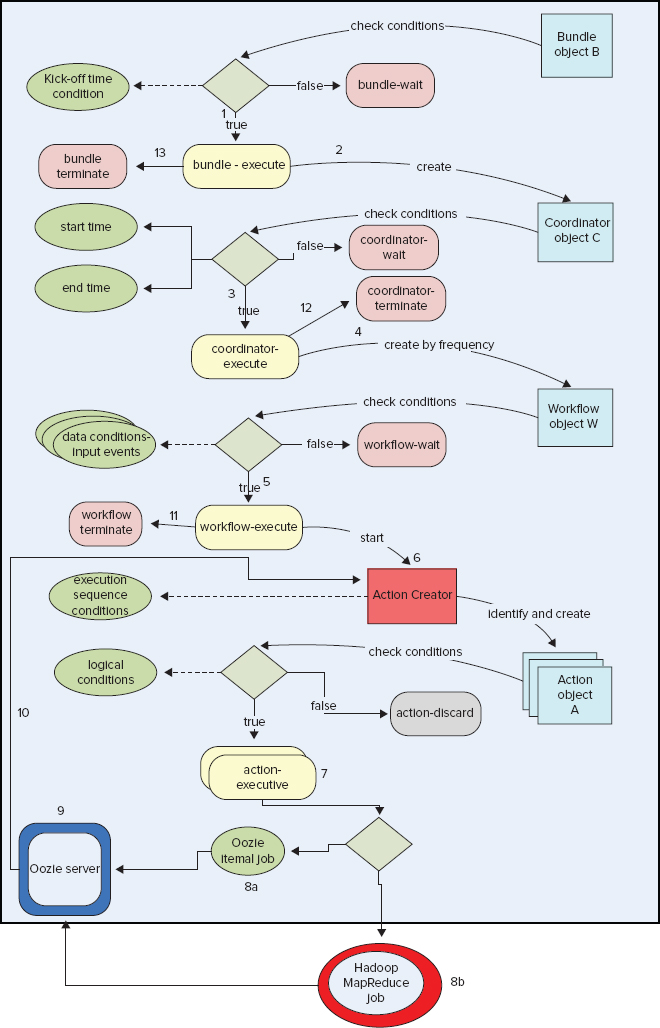
The execution model contains the following types of objects (those objects that represent jobs, not applications):
- Executable objects representing Oozie jobs (actions):
- Bundle objects
- Coordinator objects
- Workflow objects (the complete Workflow DAG)
- Workflow action objects
- Conditional objects defined in Oozie applications:
- Data conditions for Coordinator objects (expressed via data sets and input events)
- Time conditions for Coordinator objects (expressed via start, end, and frequency)
- Logical conditions for action objects (expressed with data-flow nodes)
- Execution sequence conditions for action objects (expressed via graph of nodes in Workflow)
- Concurrency conditions for Coordinator objects
Executable objects can be associated with conditions that are either satisfied or not satisfied. For example, the execution sequence condition for an action is satisfied if and only if all preceding actions in the Workflow DAG have been executed. Each executable object can be in one of two states:
- Wait state — It is waiting for conditions to be met before starting execution.
- Execution state — It is actually executing.
An object transition from wait state to the execution state occurs when all preconditions associated with that object are satisfied.
Some executable objects are associated with asynchronous actions (such as java actions, map-reduce actions, pig actions, hive actions, and sqoop actions), and, as a result, are further associated with Hadoop jobs. Other executable objects are associated with synchronous actions (such as fs actions, ssh actions, and email actions), and are executed directly on the Oozie server.
The Oozie execution model has global scope attributes (such as time), Coordinator scope attributes (such as Coordinator action concurrency, start time, and end time), Workflow scope attributes (defined and modified in Workflows), and action scope attributes (defined and modified in actions).
In the execution model, Oozie objects (based on their types) belong to one of the following levels:
- Bundle objects — These are nothing more than a set of Coordinator objects without any conditions. Bundle objects are created by the Oozie server from Bundle applications based on conditions specified there (kick-off-time).
- Coordinator objects — Each Coordinator object references one Workflow object, and it can define conditions for that Workflow object. Coordinator objects are created by the Oozie server from the Coordinator applications based on time conditions (start, end, and frequency). Coordinator objects can be waiting for the data and concurrency conditions to be satisfied before the appropriate Workflow object will be created. Coordinator objects can be associated with time conditions, data conditions (input events), concurrency conditions, and the Bundle in which they are contained.
- Workflow objects — A Workflow object contains a complete DAG of action nodes specifying execution and control-flow nodes, which govern the execution sequence and logical conditions. Workflow objects are created by the Oozie server from the standalone Workflow applications or from Bundle objects. Workflow objects can be associated with time conditions, Coordinator objects, or action objects.
- Action objects — These are created by the Oozie server from the Workflow objects. An action object represents an Oozie Workflow action, and can be associated with a Workflow object, logical conditions, and execution sequence conditions.
- Hadoop jobs — Hadoop jobs represent a unit of the Hadoop job associated with specific Workflow actions.
As shown in Figure 6-10, the execution model defines the way all these objects interact:
Knowing Oozie’s main components and the way they can be used is necessary for developing Oozie applications, but that is not enough for you to begin using Oozie. You must also know how to access the Oozie server so that you can deploy the components and interact with Oozie jobs that are running. In the next section, you learn what kinds of APIs the Oozie engine provides, and how to view the execution of Oozie jobs by using the Oozie console.
ACCESSING OOZIE
Oozie provides three basic programmatic ways for accessing the Oozie server:
- Oozie Web Services APIs (HTTP, REST, JSON API) — These provide full administrative and job management capabilities. Oozie Web Services APIs are used by Oozie tools, such as the Oozie execution console (which is examined in more detail later in this chapter).
- Oozie CLI tool — This is built on top of Web Services APIs and enables you to perform all common Workflow job operations. CLI APIs are typically used by administrators to manage Oozie execution, and by developers to script Oozie invocations.
- Oozie Java Client APIs — These are built on top of Web Services APIs and enable you to perform all common Workflow job operations. Additionally, the Client API includes a LocalOozie class that you may find useful for testing an Oozie from within an IDE, or for unit testing purposes. Java APIs provide a basis for integrating Oozie with other applications.
In addition to programmatic access, Oozie provides a convenient web application — the Oozie console shown in Figure 6-11.
FIGURE 6-11: Oozie console
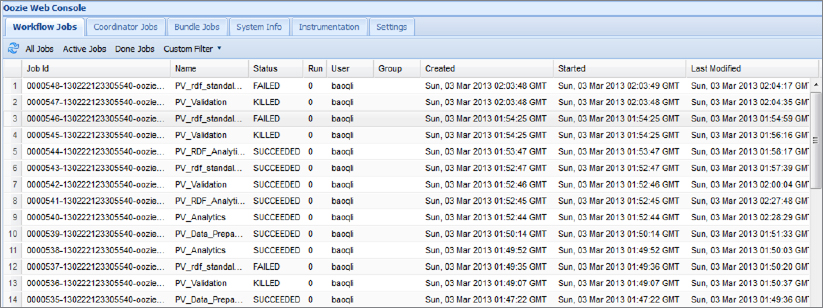
The basic view of the Oozie console lists currently running and completed Oozie jobs. (Using the tabs at the top of the screen, you can choose to view Workflow, Coordinator, or Bundle jobs.) For every job, you see the job ID, job name, completion status, run number, username, group name, start time, and last modified time. Clicking anywhere on the line for a job brings up a job detail view, as shown at Figure 6-12.
FIGURE 6-12: Oozie job execution details

This view enables you to see all the job-related information, and is generally useful for obtaining information about specific job execution. The top part of the screen contains several tabs that allow you to see overall information about the Oozie job, including job info, definition, configuration, and log. The bottom part of this screen contains information about job actions (specific to Workflow jobs). For every action, it provides basic information that includes action ID, its name, type, status, transition that was taken, start time, and end time.
Next you look at another important Oozie component — support for the Oozie Service Level Agreement (SLA).
OOZIE SLA
A Service Level Agreement (SLA) is a standard part of a software contract that specifies the quality of the product in measurable terms. More specifically, an SLA is often determined by business requirements, and depends on the nature of the software. For example, for an online web-based application, the SLA may include the average response time, as well as the maximum response time in 99 percent of requests, or system availability (for example, the system is available 95.95 percent of the time).
In an automated and auto-recovering environment such as Oozie, a traditional SLA may not be applicable, whereas some specific SLAs can make sense. Following are some SLA requirements that could be important for jobs running under Oozie control:
- Have some of the job instances been delayed (relative to a time specified in the Coordinator), and how long were the delays?
- Have some of the job instance execution times been outside specified limits, and how much were the deviations?
- What is the frequency and percentage of violating the start time and execution time?
- Did some job instances fail?
Oozie SLA provides a way to define, store, and track the desired SLA information for Oozie activities. The term “Oozie activity” here refers to any possible entity that can be tracked in different Oozie functional subsystems (for example, Coordinator and Workflow jobs and actions, Hadoop jobs submitted from Oozie, and so on). Currently, the Bundle specification does not support Oozie SLA.
Oozie SLA can be specified in the scope of a Coordinator application, Workflow application, and Workflow action. The specification becomes part of (Coordinator or Workflow) application definition, and is expressed as a fragment of an XML document. The SLA language is specified with the XML schema, as shown in Figure 6-13.
FIGURE 6-13: SLA language schema
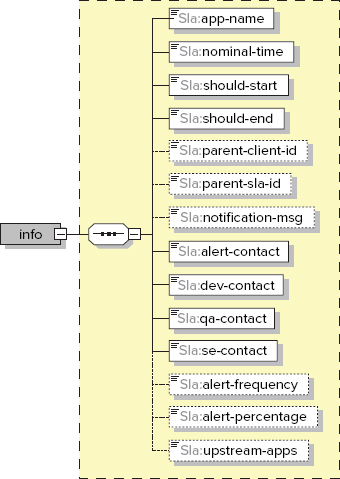
Table 6-7 describes the main Oozie SLA elements.
TABLE 6-7: Description of Oozie SLA Elements
| ELEMENT NAME | DESCRIPTION |
| Info | This is the root element of SLA definitions for Workflow or Coordinator. |
| app-name | This represents logical names with no namespace segregation done. It is up to the application developers to come up with a meaningful naming partition. For example, a package-naming structure similar to that used in Java could be used. The natural way to specify the value of an element in SLA is ${wf:name()}, or with the Coordinator application name. |
| nominal-time | This is the time specified in coordinator.xml to start a Coordinator action. In many cases, the value used for this element is ${coord:nominalTime()}. |
| should-start | This is the expected start time for this activity relative to nominal-time. For example, if the actual action is expected to start five minutes after the Coordinator job starts, the value can be specified as <sla:should-start>${5 *MINUTES}</sla:should-start>. |
| should-end | This is the expected end time for this SLA relative to nominal-time. For example, if an action is normally supposed to end two hours after the Coordinator job starts, the value can be specified as <sla:should-end>${2 * HOURS}</sla:should-end>. |
| parent-client-id, parent-sla-id | Processing entities (for example, Oozie Coordinator actions) may create/execute processing sub-entities (for example, Oozie Workflow jobs), and processing sub-entities may create/execute smaller processing sub-entities (for example, Oozie Workflow actions). Knowing that a processing sub-entity missed an SLA requirement may help to proactively identify bigger processing entities that may miss SLA requirements. SLAs traversing from a higher entity to a lower sub-entity may help you proactively identify SLA issues. An SLA violation for some processing entity may alert you to what else may be impacted because of the SLA miss. |
| The hierarchical information could also be used by any monitoring system to ignore SLA alerts for processing sub-entities if an alert for a higher processing entity has been triggered already. Parent-child relationships of SLA activities can be leveraged by the monitoring system to provide a holistic navigation through SLA activities. | |
| notification-msg, upstream-apps | This is additional information that can be appended to the SLA event. |
| alert-contact, dev-contact, qa-contact, se-contact | These are elements specifying contact information for each role. By providing the contact as part of the SLA registration event, any monitoring system will not have to deal with any registration/management of applications and e-mails. Applications that want to change the contact information must do this in the application SLA information. |
Specifying SLA requirements as part of the definition of activities themselves allows for simpler reading of the overall definition — both execution and SLA information are kept together.
When the SLA is included in Workflow/Coordinator definitions, each invocation of a corresponding action results in recording SLA information into the oozie.SLA_EVENTS table in the Oozie database. Figure 6-14 shows the SLA_EVENTS table definition.
FIGURE 6-14: SLA_EVENTS table
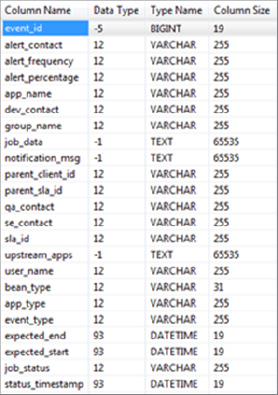
This table contains a field for each SLA XSD element, and some additional fields used for internal bookkeeping. The mapping between XSD elements and corresponding fields is straightforward, with the exceptions noted in Table 6-8.
TABLE 6-8: Special Mapping between XSD and SLA_EVENTS Table
| XSD ELEMENT | TABLE COLUMN |
| nominal-time | No column |
| should-start | expected_start = nominal-time + should_start |
| should-end | expected_end = nominal-time + should_end |
As shown in Table 6-8, the nominal-time element is not mapped to any column. Instead, the value written into the expected_start column is calculated as a sum of the value specified in the nominal-time element, plus an offset specified in the should-start element. Similarly, expected_end is calculated as nominal-time plus should-end.
Additionally, the SLA_EVENTS table includes the field status_timestamp that contains the timestamp of an SLA recording.
The sla_id field contains a foreign key to the tables COORD_JOBS and COORD_ACTIONS. These tables contain all temporal and state information for all Coordinator actions. Additionally, the table COORD_ACTIONS contains the foreign keys to the tables WF_JOBS and WF_ACTIONS, which contain all temporal and state characteristics for Workflow actions. As a result, using the field sla_id from the SLA_EVENTS table allows you to link an SLA event with Coordinator and Workflow jobs, as shown in Figure 6-15.
FIGURE 6-15: Oozie ER navigation from SLA_EVENTS table
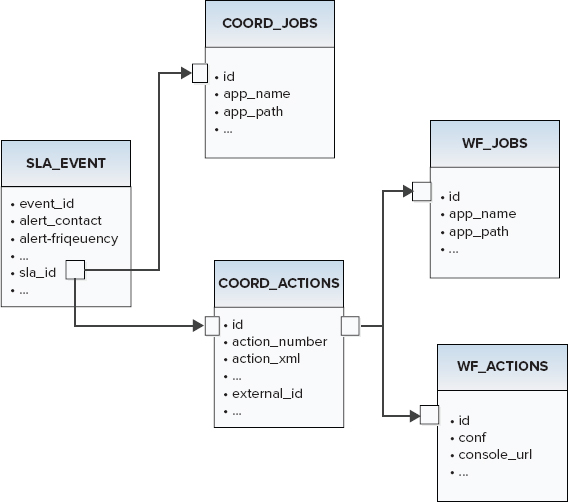
Table 6-9 shows some of the fields in the SLA_EVENTS table inserted by Oozie.
TABLE 6-9: SLA_EVENTS Fields Populated Automatically by Oozie
| FIELD | COMMENT |
| bean_type | This is the Java class responsible for logging data into the SLA_EVENTS table. The default class is SLAEventBean. It is possible to customize Oozie to use your own class for logging SLA events. |
| app_type | Possible values for this field include COORDINATOR_ACTION, WORKFLOW_JOB, and WORKFLOW_ACTION. |
| job_status | Possible values for this field include CREATED, STARTED, and SUCCEEDED. This corresponds to the different life-cycle phases of an Oozie action under SLA. Normally, each action has several records in the SLA_EVENTS table, with each record corresponding to one particular phase of the life cycle. |
Other fields include group_name, user_name, and status_timestamp.
Table fields in SLA_EVENTS (which correspond to the SLA XSD elements) are filed by Oozie based on the content of the SLA fragment of the Workfow or Coordinator. You can use Workflow and Coordinator ELs to make this content dynamic.
In addition, Oozie supports access to current SLA information through the Oozie CLI to allow specific SLA queries.
By default, Oozie SLA is disabled. It can be enabled by registering SLA XSD with Oozie. You do this by adding a reference to sla.xsd to oozie-site.xml, as shown in Listing 6-9.
LISTING 6-9: Enabling Oozie SLA
<property>
<name>oozie.service.SchemaService.wf.ext.schemas</name>
<value>oozie-sla-0.1.xsd </value>
</property>SUMMARY
This chapter has provided a broad overview of the main components of the Oozie server, their capabilities, and the way they interact with each other. The discussion showed the base functionality of Oozie Workflow, Coordinator, and Bundle components, as well as the functionality each provides.
You also learned about the Oozie Expression Language that allows you to parameterize Oozie job definitions with variables, built-in constants, and built-in functions. Additionally, you learned about Oozie APIs that provide both programmatic and manual access to the Oozie engine’s functionality, and can be used for starting, controlling, and interacting with Oozie’s job executions. Finally, you learned about Oozie SLA and the way it allows you to collect information about Oozie job execution.
This chapter covered a lot of territory. To bring together all this information, and to familiarize you with some programming details not covered in this overview, Chapter 7 provides a concrete example to lead you through a step-by-step description of how to build and execute Oozie Workflow, Coordinator, and SLA applications.