
![]()
The previous chapters in this book focused on topics such as creating a database, strategically implementing tablespaces, managing users, basic security, tables, indexes, and constraints. In those chapters, you were presented with several SQL queries, which accessed the data dictionary views in order to
- show what users are in the database and if any of their passwords expired
- display the owners of each table and associated privileges
- show the settings of various database parameters
- determine which columns have foreign key constraints defined on them
- display tablespaces and associated data files and space usage
In this regard, Oracle’s data dictionary is vast and robust. Almost every conceivable piece of information about your database is available for retrieval. The data dictionary stores critical information about the physical characteristics of the database, users, objects, and dynamic performance metrics. A senior-level DBA must possess an expert knowledge of the data dictionary.
This chapter is a turning point in the book, dividing it between basic DBA tasks and more advanced topics. It’s appropriate at this time to dive into the details of the inner workings of the data dictionary. Knowledge of these workings will provide a foundation for understanding your environment, extracting pertinent information, and doing your job.
The first few sections of this chapter detail the architecture of the data dictionary and how it is created. Also shown are the relationships between logical objects and physical structures and how they relate to specific data dictionary views. These understandings will serve as a basis for writing SQL queries to extract the information that you’ll need to be a more efficient and effective DBA. Finally, several examples are presented, illustrating how DBAs use the data dictionary.
Data Dictionary Architecture
If you inherit a database and are asked to maintain and manage it, typically you’ll inspect the contents of the data dictionary to determine the physical structure of the database and see what events are currently transacting. Toward this end, Oracle provides two general categories of read-only data dictionary views:
- The contents of your database, such as users, tables, indexes, constraints, and privileges. These are sometimes referred to as the static CDB/DBA/ALL/USER data dictionary views, and they’re based on internal tables stored in the SYSTEM tablespace. The term static, in this sense, means that the information within these views only changes as you make changes to your database, such as adding a user, creating a table, or modifying a column.
- A real-time view of activity in the database, such as users connected to the database, SQL currently executing, memory usage, locks, and I/O statistics. These views are based on virtual memory tables and are referred to as the dynamic performance views. The information in these views is continuously updated by Oracle as events take place within the database. The views are also sometimes called the V$ or GV$ views.
These types of data dictionary views are described in further detail in the next two sections.
Static Views
Oracle refers to a subset of the data dictionary views as static. These views are based on physical tables maintained internally by Oracle. Oracle’s documentation states that these views are static in the sense that the data they contain don’t change at a rapid rate (at least, not compared with the dynamic V$ and GV$ views).
The term static can sometimes be a misnomer. For example, the DBA_SEGMENTS and DBA_EXTENTS views change dynamically as the amount of data in your database grows and shrinks. Regardless, Oracle has made the distinction between static and dynamic, and it’s important to understand this architectural nuance when querying the data dictionary. Prior to Oracle Database 12c, there were only three levels of static views:
- USER
- ALL
- DBA
Starting with Oracle Database 12c, there is a fourth level that is applicable when using the container/pluggable database feature:
- CDB
The USER views contain information available to the current user. For example, the USER_TABLES view contains information about tables owned by the current user. No special privileges are required to select from the USER-level views.
At the next level are the ALL static views. The ALL views show you all object information the current user has access to. For example, the ALL_TABLES view displays all database tables on which the current user can perform any type of DML operation. No special privileges are required to query from the ALL-level views.
Next are the DBA static views. The DBA views contain metadata describing all objects in the database (regardless of ownership or access privilege). To access the DBA views, a DBA role or SELECT_CATALOG_ROLE must be granted to the current user.
The CDB-level views are only applicable if you’re using the pluggable database feature. This level provides information about all pluggable databases within a container database (hence the acronym CDB). Starting with Oracle Database 12c, you’ll notice that many of the static data dictionary and dynamic performance views have a new column, CON_ID. This column uniquely identifies each pluggable database within a container database.
![]() Tip See Chapter 23 for a full discussion of pluggable databases. Unless otherwise noted, this chapter focuses on the DBA/ALL/USER-level views. Just keep in mind that if you’re working with Oracle Database 12c and pluggable databases, you may need to access the CDB-level views when reporting on all pluggable databases within a container database.
Tip See Chapter 23 for a full discussion of pluggable databases. Unless otherwise noted, this chapter focuses on the DBA/ALL/USER-level views. Just keep in mind that if you’re working with Oracle Database 12c and pluggable databases, you may need to access the CDB-level views when reporting on all pluggable databases within a container database.
The static views are based on internal Oracle tables, such as USER$, TAB$, and IND$. If you have access to the SYS schema, you can view underlying tables directly via SQL. For most situations, you only need to access the static views that are based on the underlying internal tables.
The data dictionary tables (such as USER$, TAB$, IND$) are created during the execution of the CREATE DATABASE command. As part of creating a database, the sql.bsq file is executed, which builds these internal data dictionary tables. The sql.bsq file is generally located in the ORACLE_HOME/rdbms/admin directory; you can view it via an OS editing utility (such as vi, in Linux/Unix, or Notepad, in Windows).
The static views are created when you run the catalog.sql script (usually, you run this script once the CREATE DATABASE operation succeeds). The catalog.sql script is located in the ORACLE_HOME/rdbms/admin directory. Figure 10-1 shows the process of creating the static data dictionary views.
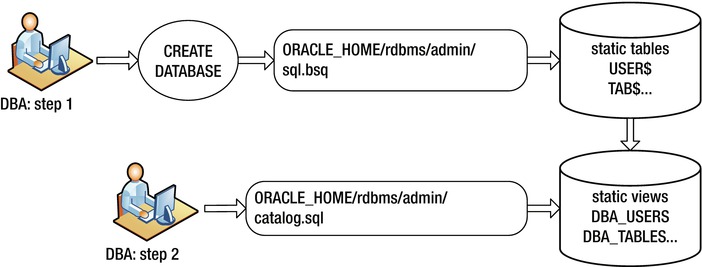
Figure 10-1. Creating the static data dictionary views
You can view the creation scripts of the static views by querying the TEXT column of DBA_VIEWS; for example,
SQL > set long 5000
SQL > select text from dba_views where view_name = 'DBA_VIEWS';
Here is the output:
select u.name, o.name, v.textlength, v.text, t.typetextlength, t.typetext,
t.oidtextlength, t.oidtext, t.typeowner, t.typename,
decode(bitand(v.property, 134217728), 134217728,
(select sv.name from superobj$ h, "_CURRENT_EDITION_OBJ" sv
where h.subobj# = o.obj# and h.superobj# = sv.obj#), null),
decode(bitand(v.property, 32), 32, 'Y', 'N'),
decode(bitand(v.property, 16384), 16384, 'Y', 'N'),
decode(bitand(v.property/4294967296, 134217728), 134217728, 'Y', 'N'),
decode(bitand(o.flags,8),8,'CURRENT_USER','DEFINER')
from sys."_CURRENT_EDITION_OBJ" o, sys.view$ v, sys.user$ u, sys.typed_view$ t
where o.obj# = v.obj#
and o.obj# = t.obj#(+)
and o.owner# = u.user#
![]() Note If you manually create a database (not using the dbca utility), you must be connected as the SYS schema when you run the catalog.sql and catproc.sql scripts. The SYS schema is the owner of all objects in the data dictionary.
Note If you manually create a database (not using the dbca utility), you must be connected as the SYS schema when you run the catalog.sql and catproc.sql scripts. The SYS schema is the owner of all objects in the data dictionary.
Dynamic Performance Views
The dynamic performance data dictionary views are colloquially referred to as the V$ and GV$ views. These views are constantly updated by Oracle and reflect the current condition of the instance and database. Dynamic views are critical for diagnosing real-time performance issues.
The V$ and GV$ views are indirectly based on underlying X$ tables, which are internal memory structures that are instantiated when you start your Oracle instance. Some of the V$ views are available the moment the Oracle instance is started. For example, V$PARAMETER contains meaningful data after the STARTUP NOMOUNT command has been issued, and doesn’t require the database to be mounted or open. Other dynamic views (such as V$CONTROLFILE) depend on information in the control file and therefore contain significant information only after the database has been mounted. Some V$ views (such as V$BH) provide kernel-processing information and thus have useful results only after the database has been opened.
At the top layer, the V$ views are actually synonyms that point to underlying SYS.V_$ views. At the next layer down, the SYS.V_$ objects are views created on top of another layer of SYS.V$ views. The SYS.V$ views in turn are based on the SYS.GV$ views. At the bottom layer, the SYS.GV$ views are based on the X$ memory structures.
The top-level V$ synonyms and SYS.V_$ views are created when you run the catalog.sql script, which you usually do after the database is initially created. Figure 10-2 shows the process for creating the V$ dynamic performance views.

Figure 10-2. Creating the V$ dynamic performance data dictionary views
Accessing the V$ views through the topmost synonyms is usually adequate for dynamic performance information needs. On rare occasions, you’ll want to query internal information that may not be available through the V$ views. In these situations it’s critical to understand the X$ underpinnings.
If you work with Oracle RAC, you should be familiar with the GV$ global views. These views provide global dynamic performance information regarding all instances in a cluster (whereas the V$ views are instance specific). The GV$ views contain an INST_ID column for identifying specific instances in a clustered environment.
You can display the V$ and GV$ view definitions by querying the VIEW_DEFINITION column of the V$FIXED_VIEW_DEFINITION view. For instance, this query displays the definition of the V$CONTROLFILE:
select view_definition
from v$fixed_view_definition
where view_name = 'V$CONTROLFILE';
Here is the output:
select STATUS, NAME, IS_RECOVERY_DEST_FILE, BLOCK_SIZE, FILE_SIZE_BLKS,
CON_ID from GV$CONTROLFILE where inst_id = USERENV('Instance')
A Different View of Metadata
DBAs commonly face the following types of database issues:
- An insert into a table fails because a tablespace can’t extend.
- The database is refusing connections because the maximum number of sessions is exceeded.
- An application is hung, apparently because of some sort of locking issue.
- A PL/SQL statement is failing, with a memory error.
- RMAN backups haven’t succeeded for 2 days.
- A user is trying to update a record, but a unique key constraint violation is thrown.
- An SQL statement has been running for hours longer than normal.
- Application users have reported that performance seems sluggish and that something must be wrong with the database.
The prior list is a small sample of the typical issues a DBA encounters on a daily basis. A certain amount of knowledge is required to be able to efficiently diagnose and handle these types of problems. A fundamental piece of that knowledge is an understanding of Oracle’s physical structures and corresponding logical components.
For example, if a table can’t extend because a tablespace is full, what knowledge do you rely on to solve this problem? You need to understand that when a database is created, it contains multiple logical space containers called tablespaces. Each tablespace consists of one or more physical data files. Each data file consists of many OS blocks. Each table consists of a segment, and every segment contains one or more extents. As a segment needs space, it allocates additional extents within a physical data file.
Once you understand the logical and physical concepts involved, you intuitively look in data dictionary views such as DBA_TABLES, DBA_SEGMENTS, DBA_TABLESPACES, and DBA_DATA_FILES to pinpoint the issue and add space as required. In a wide variety of troubleshooting scenarios, your understanding of the relationships of various logical and physical constructs will allow you to focus on querying views that will help you quickly resolve the problem at hand. To that end, inspect Figure 10-3. This diagram describes the relationships between logical and physical structures in an Oracle database. The rounded rectangle shapes represent logical constructs, and the sharp-cornered rectangles are physical files.
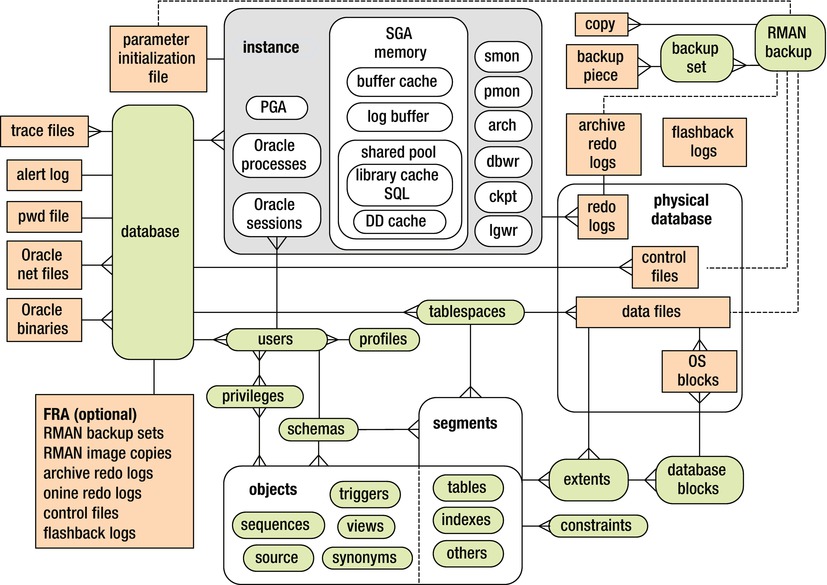
Figure 10-3. Oracle database logical and physical structure relationships
![]() Tip Logical objects are only viewable from SQL after the database has been started. In contrast, physical objects can be viewed via OS utilities even if the instance is not started.
Tip Logical objects are only viewable from SQL after the database has been started. In contrast, physical objects can be viewed via OS utilities even if the instance is not started.
Figure 10-3 doesn’t show all the relationships of all logical and physical aspects of an Oracle database. Rather, it focuses on components that you’re most likely to encounter on a daily basis. This base relational diagram forms a foundation for leveraging of Oracle’s data dictionary infrastructure.
Keep an image of Figure 10-3 open in your mind; now, juxtapose it with Figure 10-4.

Figure 10-4. Relationships of commonly used data dictionary views
Voila, these data dictionary views map very closely to almost all the logical and physical elements of an Oracle database. Figure 10-4 doesn’t show every data dictionary view. Indeed, the figure barely scratches the surface. However, this diagram does provide you with a secure foundation on which to build your understanding of how to leverage the data dictionary views to get the data you need to do your job.
The diagram does show relationships between views, but it doesn’t specify which columns to use when joining views together. You’ll have to describe the tables and make an educated guess as to how the views should be joined. For example, suppose you want to display the data files associated with tablespaces that aren’t locally managed. That requires joining DBA_TABLESPACES to DBA_DATA_FILES. If you inspect those two views, you’ll notice that each contains a TABLESPACE_NAME column, which allows you to write a query as follows:
select a.tablespace_name, a.extent_management, b.file_name
from dba_tablespaces a,
dba_data_files b
where a.tablespace_name = b.tablespace_name
and a.extent_management != 'LOCAL';
It’s generally somewhat obvious how to join the views. Use the diagram as a guide for where to start looking for information and how to write SQL queries that will provide answers to problems and expand your knowledge of Oracle’s internal architecture and inner workings. This anchors your problem-solving skills on a solid foundation. Once you firmly understand the relationships of Oracle’s logical and physical components and how this relates to the data dictionary, you can confidently address any type of database issue.
![]() Note As of Oracle Database 12c, there are several thousand CDB/DBA/ALL/USER static views and more than 700 V$ dynamic performance views.
Note As of Oracle Database 12c, there are several thousand CDB/DBA/ALL/USER static views and more than 700 V$ dynamic performance views.
A Few Creative Uses of the Data Dictionary
In nearly every chapter of this book, you’ll find several SQL examples of how to leverage the data dictionary to better understand concepts and resolve problems. Having said that, it’s worth showing a few offbeat examples of how DBAs leverage the data dictionary. The next few sections do just that. Keep in mind that this is just the tip of the iceberg: there are an endless number of queries and techniques that DBAs employ to extract and use data dictionary information.
Derivable Documentation
Sometimes, if you’re troubleshooting an issue and are under pressure, you need to quickly extract information from the data dictionary to help resolve the problem. However, you may not know the exact name of a data dictionary view or its associated columns. If you’re like me, it’s impossible to keep all the data dictionary view names and column names in your head. Additionally, I work with databases from versions 8 through 12c, and it’s difficult to keep track of which particular view may be available with a given release of Oracle.
Books and posters can provide this information, but if you can’t find exactly what you’re looking for, you can use the documentation contained in the data dictionary itself. You can query from three views, in particular:
- DBA_OBJECTS
- DICTIONARY
- DICT_COLUMNS
If you know roughly the name of the view from which you want to select information, you can first query from DBA_OBJECTS. For instance, if you’re troubleshooting an issue regarding materialized views, and you can’t remember the exact names of the data dictionary views associated with materialized views, you can do this:
select object_name
from dba_objects
where object_name like '%MV%'
and owner = 'SYS';
That may be enough to get you in the ballpark. But, often you need more information about each view. This is when the DICTIONARY and DICT_COLUMNS views can be invaluable. The DICTIONARY view stores the names of the data dictionary views. It has two columns:
SQL > desc dictionary
Name Null? Type
----------------------------------------- -------- ----------------------------
TABLE_NAME VARCHAR2(30)
COMMENTS VARCHAR2(4000)
For example, say you’re troubleshooting an issue with materialized views, and you want to determine the names of data dictionary views related to the materialized view feature. You can run a query such as this:
select table_name, comments
from dictionary
where table_name like '%MV%';
Here is a snippet of the output:
TABLE_NAME COMMENTS
------------------------- -------------------------------------------------------
DBA_MVIEW_LOGS All materialized view logs in the database
DBA_MVIEWS All materialized views in the database
DBA_MVIEW_ANALYSIS Description of the materialized views accessible to dba
DBA_MVIEW_COMMENTS Comments on all materialized views in the database
In this manner, you can quickly determine which view you need to access. If you want further information about the view, you can describe it; for example,
SQL > desc dba_mviews
If that doesn’t give you enough information regarding the column names, you can query the D ICT_COLUMNS view. This view provides comments about the columns of a data dictionary view; for example,
select column_name, comments
from dict_columns
where table_name = 'DBA_MVIEWS';
Here is a fraction of the output:
COLUMN_NAME COMMENTS
----------------------- ---------------------------------------------
OWNER Owner of the materialized view
MVIEW_NAME Name of the materialized view
CONTAINER_NAME Name of the materialized view container table
QUERY The defining query that the materialized view instantiates
In this way, you can generate and view documentation regarding most data dictionary objects. The technique allows you to quickly identify appropriate views and the columns that may help you in a troubleshooting situation.
You may find yourself in an environment that contains hundreds of databases located on dozens of different servers. In such a scenario, you want to ensure that you don’t run the wrong commands or connect to the wrong database, or both. When performing DBA tasks, it’s prudent to verify that you’re connected as the appropriate account and to the correct database. You can run the following types of SQL commands to verify the currently connected user and database information:
SQL > show user;
SQL > select * from user_users;
SQL > select name from v$database;
SQL > select instance_name, host_name from v$instance;
As shown in Chapter 3, an efficient way of staying aware of your environment is to set your SQL*Plus prompt automatically, via the login.sql script, to display user and instance information. This example manually sets the SQL prompt:
SQL > set sqlprompt '&_USER.@&_CONNECT_IDENTIFIER. > '
Here is what the SQL prompt now looks like:
SYS@O12C>
You can also use the SYS_CONTEXT built-in SQL function to extract information from the data dictionary regarding details about your currently connected session. The general syntax for this function is as follows:
SYS_CONTEXT(' <namespace > ',' <parameter > ',[length])
This example displays the user, authentication method, host, and instance:
select
sys_context('USERENV','CURRENT_USER') usr
,sys_context('USERENV','AUTHENTICATION_METHOD') auth_mth
,sys_context('USERENV','HOST') host
,sys_context('USERENV','INSTANCE_NAME') inst
from dual;
U SERENV is a built-in Oracle namespace. More than 50 parameters are available when you use the USERENV namespace with the SYS_CONTEXT function. Table 10-1 describes some of the more useful parameters. See the Oracle SQL Language Reference Guide, which can be freely downloaded from the Technology Network area of the Oracle web site (http://otn.oracle.com), for a complete list of parameters.
Table 10-1. Useful USERENV Parameters Available with SYS_CONTEXT
| Parameter Name | Description |
|---|---|
| AUTHENTICATED_IDENTITY | Identity used in authentication |
| AUTHENTICATION_METHOD | Method of authentication |
| CON_ID | Container identifier |
| CON_NAME | Container name |
| CURRENT_USER | Username for the currently active session |
| DB_NAME | Name specified by the DB_NAME initialization parameter |
| DB_UNIQUE_NAME | Name specified by the DB_UNIQUE_NAME initialization parameter |
| HOST | Hostname for the machine on which the client initiated the database connection |
| INSTANCE_NAME | Instance name |
| IP_ADDRESS | IP address of the machine on which the client initiated the database connection |
| ISDBA | TRUE if the user authenticated with DBA privileges through the OS or password file |
| NLS_DATE_FORMAT | Date format for the session |
| OS_USER | OS user from the machine on which the client initiated the database connection |
| SERVER_HOST | Hostname of the machine on which the database instance is running |
| SERVICE_NAME | Service name for the connection |
| SID | Session identifier |
| TERMINAL | OS identifier for the client terminal |
DETERMINING YOUR ENVIRONMENT’S DETAILS
Sometimes, when deploying code through various development, test, beta, and production environments, it’s handy to be prompted as to whether you’re in the correct environment. The technique for accomplishing this requires two files: answer_yes.sql and answer_no.sql. Here are the contents of answer_yes.sql:
-- answer_yes.sql
PROMPT
PROMPT Continuing...
And, here is answer_no.sql:
-- answer_no.sql
PROMPT
PROMPT Quitting and discarding changes...
ROLLBACK;
EXIT;
Now, you can insert the following code into the first part of your deployment script; the code will prompt you as to whether you’re in the right environment and if you want to continue:
WHENEVER SQLERROR EXIT FAILURE ROLLBACK;
WHENEVER OSERROR EXIT FAILURE ROLLBACK;
select host_name from v$instance;
select name as db_name from v$database;
SHOW user;
SET ECHO OFF;
PROMPT
ACCEPT answer PROMPT 'Correct environment? Enter yes to continue: '
@@answer_&answer..sql
If you type in yes, then the answer_yes.sql script will execute, and you will continue to run any other scripts you call. If you type in no, then the answer_no.sql script will run, and you will exit from SQL*Plus and end up at the OS prompt. If you press the Enter key without typing either, you will also exit and return to the OS prompt.
Displaying Table Row Counts
When you’re investigating performance or space issues, it’s useful to display each table’s row count. To calculate row counts manually, you would write a query such as this for each table that you own:
SQL > select count(*) from < table_name>;
Manually crafting the SQL is time-consuming and error prone. In this situation it’s more efficient to use SQL to generate the SQL required to solve the problem. To that end, this next example dynamically selects the required text, based on information in the DBA_TABLES view. An output file is spooled that contains the dynamically generated SQL. Run the following SQL code as a DBA-privileged schema. Note that this script contains SQL*Plus-specific commands, such as UNDEFINE and SPOOL. The script prompts you each time for a username:
UNDEFINE user
SPOOL tabcount_&&user..sql
SET LINESIZE 132 PAGESIZE 0 TRIMSPO OFF VERIFY OFF FEED OFF TERM OFF
SELECT
'SELECT RPAD(' || '''' || table_name || '''' ||',30)'
|| ',' || ' COUNT(*) FROM &&user..' || table_name || ';'
FROM dba_tables
WHERE owner = UPPER('&&user')
ORDER BY 1;
SPO OFF;
SET TERM ON
@@tabcount_&&user..sql
SET VERIFY ON FEED ON
This code generates a file, named tabcount_ < user > .sql, that contains the SQL statements that select row counts from all tables in the specified schema. If the username you provide to the script is INVUSER, then you can manually run the generated script as follows:
SQL > @tabcount_invuser.sql
Keep in mind that if the table row counts are high, this script can take a long time to run (several minutes).
Developers and DBAs often use SQL to generate SQL statements. This is a useful technique when you need to apply the same SQL process (repetitively) to many different objects, such as all tables in a schema. If you don’t have access to DBA-level views, you can query the USER_TABLES view; for example,
SPO tabcount.sql
SET LINESIZE 132 PAGESIZE 0 TRIMSPO OFF VERIFY OFF FEED OFF TERM OFF
SELECT
'SELECT RPAD(' || '''' || table_name || '''' ||',30)'
|| ',' || ' COUNT(*) FROM ' || table_name || ';'
FROM user_tables
ORDER BY 1;
SPO OFF;
SET TERM ON
@@tabcount.sql
SET VERIFY ON FEED ON
If you have accurate statistics, you can query the NUM_ROWS column of the CDB/DBA/ALL/USER_TABLES views. This column normally has a close row count if statistics are generated on a regular basis. The following query selects NUM_ROWS from the USER_TABLES view:
SQL > select table_name, num_rows from user_tables;
One final note: if you have partitioned tables and want to show row counts by partition, use the next few lines of SQL and PL/SQL code to generate the SQL required:
UNDEFINE user
SET SERVEROUT ON SIZE 1000000 VERIFY OFF
SPO part_count_&&user..txt
DECLARE
counter NUMBER;
sql_stmt VARCHAR2(1000);
CURSOR c1 IS
SELECT table_name, partition_name
FROM dba_tab_partitions
WHERE table_owner = UPPER('&&user'),
BEGIN
FOR r1 IN c1 LOOP
sql_stmt := 'SELECT COUNT(*) FROM &&user..' || r1.table_name
||' PARTITION ( '||r1.partition_name ||' )';
EXECUTE IMMEDIATE sql_stmt INTO counter;
DBMS_OUTPUT.PUT_LINE(RPAD(r1.table_name
||'('||r1.partition_name||')',30) ||' '||TO_CHAR(counter));
END LOOP;
END;
/
SPO OFF
MANUALLY GENERATING STATISTICS
If you want to generate statistics for a table, use the DBMS_STATS package. This example generates statistics for a user and a table:
SQL > exec dbms_stats.gather_table_stats(ownname=> 'MV_MAINT',-
tabname= > 'F_SALES',-
cascade= > true,estimate_percent=> 20,degree=> 4);
You can generate statistics for all objects for a user with the following code:
SQL > exec dbms_stats.gather_schema_stats(ownname = > 'MV_MAINT',-
estimate_percent = > DBMS_STATS.AUTO_SAMPLE_SIZE,-
degree = > DBMS_STATS.AUTO_DEGREE,-
cascade = > true);
The prior code instructs Oracle to estimate the percentage of the table to be sampled with the ESTIMATE_PERCENT parameter, using DBMS_STATS.AUTO_SAMPLE_SIZE. Oracle also chooses the appropriate degree of parallelism with the DEGREE parameter setting of DBMS_STATS.AUTO_DEGREE. The CASCADE parameter instructs Oracle to generate statistics for indexes.
Keep in mind that it’s possible that Oracle won’t choose the optimal auto sample size. Oracle may choose 10 percent, but you may have experience with setting a low percentage, such as 5 percent, and know that is an acceptable number. In these situations, don’t use the AUTO_SAMPLE_SIZE; explicitly provide a number instead.
Showing Primary Key and Foreign Key Relationships
Sometimes when you’re diagnosing constraint issues, it’s useful to display data dictionary information regarding what primary key constraint is associated with a foreign key constraint. For example, perhaps you’re attempting to insert into a child table, and an error is thrown indicating that the parent key doesn’t exist, and you want to display more information about the parent key constraint.
The following script queries the DBA_CONSTRAINTS data dictionary view to determine the parent primary key constraints that are related to child foreign key constraints. You need to provide as input to the script the owner of the table and the child table for which you wish to display primary key constraints:
select
a.constraint_type cons_type
,a.table_name child_table
,a.constraint_name child_cons
,b.table_name parent_table
,b.constraint_name parent_cons
,b.constraint_type cons_type
from dba_constraints a
,dba_constraints b
where a.owner = upper('&owner')
and a.table_name = upper('&table_name')
and a.constraint_type = 'R'
and a.r_owner = b.owner
and a.r_constraint_name = b.constraint_name;
The preceding script prompts you for two SQL*Plus ampersand variables (OWNER, TABLE_NAME); if you aren’t using SQL*Plus, then you may need to modify the script with the appropriate values before you run it.
The following output shows that there are two foreign key constraints. It also shows the parent table primary key constraints:
C CHILD_TABLE CHILD_CONS PARENT_TABLE PARENT_CONS C
- --------------- ------------------- --------------- ------------------- -
R REG_COMPANIES REG_COMPANIES_FK2 D_COMPANIES D_COMPANIES_PK P
R REG_COMPANIES REG_COMPANIES_FK1 CLUSTER_BUCKETS CLUSTER_BUCKETS_PK P
When the CONSTRAINT_TYPE column (of DBA/ALL/USER_CONSTRAINTS) contains an R value, this indicates that the row describes a referential integrity constraint, which means that the child table constraint references a primary key constraint. You use the technique of joining to the same table twice to retrieve the primary key constraint information. The child constraint columns (R_OWNER, R_CONSTRAINT_NAME) match with another row in the DBA_CONSTRAINTS view that contains the primary key information.
You can also do the reverse of the prior query in this section; for a primary key constraint, you want to find the foreign key columns (if any) that correlate to it. The next script takes the primary key record and looks to see if it has any child records with a constraint type of R. When you run this script, you’re prompted for the primary key table owner and name:
select
b.table_name primary_key_table
,a.table_name fk_child_table
,a.constraint_name fk_child_table_constraint
from dba_constraints a
,dba_constraints b
where a.r_constraint_name = b.constraint_name
and a.r_owner = b.owner
and a.constraint_type = 'R'
and b.owner = upper('&table_owner')
and b.table_name = upper('&table_name'),
Here is some sample output:
PRIMARY_KEY_TABLE FK_CHILD_TABLE FK_CHILD_TABLE_CONSTRAINT
-------------------- -------------------- ------------------------------
CLUSTER_BUCKETS CB_AD_ASSOC CB_AD_ASSOC_FK1
CLUSTER_BUCKETS CLUSTER_CONTACTS CLUSTER_CONTACTS_FK1
CLUSTER_BUCKETS CLUSTER_NOTES CLUSTER_NOTES_FK1
Displaying Object Dependencies
Say you need to drop a table, but before you drop it, you want to display any objects that are dependent on it. For example, you may have a table that has synonyms, views, materialized views, functions, procedures, and triggers that rely on it. Before making the change, you want to review what other objects are dependent on the table. You can use the D BA_DEPENDENCIES data dictionary view to display object dependencies. The following query prompts you for a username and an object name:
select ' + ' || lpad(' ',level + 2) || type || ' ' || owner || '.' || name dep_tree
from dba_dependencies
connect by prior owner = referenced_owner and prior name = referenced_name
and prior type = referenced_type
start with referenced_owner = upper('&object_owner')
and referenced_name = upper('&object_name')
and owner is not null;
In the output each object listed has a dependency on the object you entered. Lines are indented to show the dependency of an object on the object in the preceding line:
DEP_TREE
------------------------------------------------------------
+ TRIGGER STAR2.D_COMPANIES_BU_TR1
+ MATERIALIZED VIEW CIA.CB_RAD_COUNTS
+ SYNONYM STAR1.D_COMPANIES
+ SYNONYM CIA.D_COMPANIES
+ MATERIALIZED VIEW CIA.CB_RAD_COUNTS
In this example the object being analyzed is a table named D_COMPANIES. Several synonyms, materialized views, and one trigger are dependent on this table. For instance, the materialized view C B_RAD_COUNTS, owned by CIA, is dependent on the synonym D_COMPANIES, owned by CIA, which in turn is dependent on the D_COMPANIES synonym, owned by STAR1.
The D BA_DEPENDENCIES view contains a hierarchical relationship between the OWNER, NAME and TYPE columns and their referenced column names of REFERENCED_OWNER, REFERENCED_NAME, and REFERENCED_TYPE. Oracle provides a number of constructs to perform hierarchical queries. For instance, START WITH and CONNECT BY allow you to identify a starting point in a tree and walk either up or down the hierarchical relationship.
The previous SQL query in this section operates on only one object. If you want to inspect every object in a schema, you can use SQL to generate SQL to create scripts that display all dependencies for a schema’s objects. The piece of code in the next example does that. For formatting and output, the code uses some constructs specific to SQL*Plus, such as setting the page sizes and line size and spooling the output:
UNDEFINE owner
SET LINESIZE 132 PAGESIZE 0 VERIFY OFF FEEDBACK OFF TIMING OFF
SPO dep_dyn_&&owner..sql
SELECT 'SPO dep_dyn_&&owner..txt' FROM DUAL;
--
SELECT
'PROMPT ' || '_____________________________'|| CHR(10) ||
'PROMPT ' || object_type || ': ' || object_name || CHR(10) ||
'SELECT ' || '''' || ' + ' || '''' || ' ' || '|| LPAD(' || '''' || ' '
|| '''' || ',level + 3)' || CHR(10) || ' || type || ' || '''' || ' ' || '''' ||
' || owner || ' || '''' || '.' || '''' || ' || name' || CHR(10) ||
' FROM dba_dependencies ' || CHR(10) ||
' CONNECT BY PRIOR owner = referenced_owner AND prior name = referenced_name '
|| CHR(10) ||
' AND prior type = referenced_type ' || CHR(10) ||
' START WITH referenced_owner = ' || '''' || UPPER('&&owner') || '''' || CHR(10) ||
' AND referenced_name = ' || '''' || object_name || '''' || CHR(10) ||
' AND owner IS NOT NULL;'
FROM dba_objects
WHERE owner = UPPER('&&owner')
AND object_type NOT IN ('INDEX','INDEX PARTITION','TABLE PARTITION'),
--
SELECT 'SPO OFF' FROM dual;
SPO OFF
SET VERIFY ON LINESIZE 80 FEEDBACK ON
You should now have a script named dep_dyn_ <owner > .sql, created in the same directory from which you run the script. This script contains all the SQL required to display dependencies on objects in the owner you entered. Run the script to display object dependencies. In this example, the owner is CIA:
SQL > @dep_dyn_cia.sql
When the script runs, it spools a file with the format dep_dyn_ < owner > .txt. You can open that text file with an OS editor to view its contents. Here is a sample of the output from this example:
TABLE: DOMAIN_NAMES
+ FUNCTION STAR2.GET_DERIVED_COMPANY
+ TRIGGER STAR2.DOMAIN_NAMES_BU_TR1
+ SYNONYM CIA_APP.DOMAIN_NAMES
This output shows that the table DOMAIN_NAMES has three objects that are dependent on it: a function, a trigger, and a synonym.
THE DUAL TABLE
The DUAL table is part of the data dictionary. This table contains one row and one column and is useful when you want to return a row and you don’t have to retrieve data from a particular table. In other words, you just want to return a value. For example, you can perform arithmetic operations, as follows:
SQL > select 34*.15 from dual;
34*.15
----------
5.1
Other common uses are selecting from DUAL to show the current date or to display some text within an SQL script.
Summary
Sometimes, you’re handed an old database that has been running for years, and it’s up to you to manage and maintain it. In some scenarios, you aren’t given any documentation regarding the users and objects in the database. Even if you have documentation, it may not be accurate or up-to-date. In these situations, the data dictionary quickly becomes your source of documentation. You can use it to extract user information, the physical structure of the database, security information, objects and owners, currently connected users, and so on.
Oracle provides static and dynamic views in the data dictionary. The static views contain information about the objects in the database. The dynamic performance views offer a real-time window into events currently transacting in the database. These views provide information about currently connected users, SQL executing, where resources are being consumed, and so on. DBAs use these views extensively to monitor and troubleshoot performance issues.
The book now turns its attention toward specialized Oracle features, such as large objects, partitioning, Data Pump, and external tables. These topics are covered in the next several chapters.