
![]()
Hibernate OGM Querying MongoDB
In previous chapters, we accomplished several tasks in order to organize and store our data in NoSQL MongoDB stores. Now we’ll make use of this data by applying different querying techniques to extract only the information we need from a NoSQL MongoDB store.
As I noted in Chapter 1, querying a NoSQL database is a delicate and complex task—there are different situations, and different approaches depending on the native support for NoSQL querying. For MongoDB, there are a number of querying options; it’s up to you to choose the one that meets your needs, depending on your queries’ complexity, performance parameters, and so on:
- Native query technology, which means using the MongoDB driver querying capabilities without involving Hibernate OGM or any other technology.
- Hibernate ORM/OGM for CRUD, in which Create/Read/Update/Delete operations are implemented by the Hibernate ORM engine.
- Hibernate Search/Apache Lucene, which uses a full-text indexing and query engine (Apache Lucene). Hibernate Search is a powerful querying mechanism with great performance and capabilities and provides a very easy-to-use bridge to Lucene. For complex queries and indexing support, this is the right choice.
- Hibernate OGM JP-QL parser, which uses uses Hibernate Search to retrieve the desired information from a MongoDB store, is good for simple queries. This JP-QL parser is in its infancy, so it will need time to become powerful and support complex queries.
- Other tools, such as DataNucleus, Morphia, and so on that won’t be covered in this book.
![]() Note Currently, Hibernate OGM via Hibernate Native API doesn’t provide support for Hibernate Criteria. Moreover, it doesn’t, via JPA, provide support for native and named queries.
Note Currently, Hibernate OGM via Hibernate Native API doesn’t provide support for Hibernate Criteria. Moreover, it doesn’t, via JPA, provide support for native and named queries.
We are going to delve into each of these querying possibilities and try to see how it works. We will focus on Hibernate OGM and discuss MongoDB from this perspective. For the sake of completeness, however, we’ll start this journey about querying MongoDB by first looking at basic MongoDB querying capabilities, and reserve the subject of Hibernate OGM till the second part of the chapter. In this way, you’ll get a complete picture of querying MongoDB and you’ll be better able to choose the appropriate querying solution for your needs.
As you probably know, MongoDB natively provides interactive support through the mongo shell (a full interactive JavaScript environment with a database interface for MongoDB), and programmatic support through the MongoDB driver (which is available for multiple programming languages, such as Java, Ruby, and PHP). In this section, we will skip the shell and concentrate on querying a MongoDB store using the MongoDB driver for Java. You’ll need the 2.8.0 version of this driver, which is available for download as a JAR named mongo-java-driver-2.8.0.jar at www.docs.mongodb.org/manual/applications/drivers/.
Before executing any query, you need to configure a MongoDB connection and create a database, then create a collection and populate it with data. For this, please go back to the section in Chapter 4 called “Java SE and Mongo DB—the HelloWorld Example.” Once you know how to connect and persist documents to a MongoDB store, you’re ready to perform queries.
We’ll create a collection called players and try some queries against it. Each document stores some tennis player data: name, surname, age, and birth date (and duplicate documents are allowed). After populating the collection with several documents, you can start with the well-known “select all” query. You can use the find method, which returns a cursor that contains a number of documents. As you can see, it’s very easy to iterate the results. This chunk of code uses find to extract all documents:
...
Mongo mongo = new Mongo("127.0.0.1", 27017);
DB db = mongo.getDB("players_db");
DBCollection dbCollection = db.getCollection("players");
...
System.out.println("Find all documents in collection:");
try (DBCursor cursor = dbCollection.find() ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
...
The result of this query is shown in Figure 6-1.

Figure 6-1. All documents of the players collection
![]() Note You can count how many documents are in a collection by calling the getCount method, like this: dbCollection.getCount();.
Note You can count how many documents are in a collection by calling the getCount method, like this: dbCollection.getCount();.
You can find a single document using the findOne method; this method doesn’t return a cursor. The snipped code is:
...
System.out.println("Find the first document in collection:");
DBObject first = dbCollection.findOne() ;
System.out.println(first);
...
The result will be the first document from the players collection, as shown in Figure 6-2.
![]()
Figure 6-2. Extracting the first document of the players collection
You can also execute conditional queries. For example, we can extract the documents corresponding to the player Rafael Nadal using the find method, like this:
...
System.out.println("Find Rafael Nadal documents:");
BasicDBObject query = new BasicDBObject("name", "Nadal").append("surname", "Rafael");
try (DBCursor cursor = dbCollection.find(query) ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
...
The results are shown in Figure 6-3.
![]()
Figure 6-3. Extracting only documents containing Rafael Nadal
The find method combined with the $gt (greater than) operator lets you extract all players whose age is greater than 25:
...
System.out.println("Find players with age > 25:");
BasicDBObject query = new BasicDBObject("age", new BasicDBObject("$gt", 25));
try (DBCursor cursor = dbCollection.find(query) ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
...
You can see the results in Figure 6-4.

Figure 6-4. Extracting only documents with age greater than 25
The find method combined with the $lt (less than) operator lets you extract all players whose age is less than 28:
...
System.out.println("Find players with age < 28:");
BasicDBObject query = new BasicDBObject("age", new BasicDBObject("$lt", 28));
try (DBCursor cursor = dbCollection.find(query) ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
...
The results are shown in Figure 6-5.

Figure 6-5. Extracting only documents with age less than 28
Extracting data that falls within (or outside of) an interval of values can be accomplished using the $gt and $lt, or $gte (greater than or equal) and $lte (less than or equal) operators and the find method. For example, you can obtain all players born between 1 January, 1982 and 31 December, 1985 like this:
...
System.out.println("JAVA - Find players with birthday between 1 January, 1982 - 31 December, 1985:");
Calendar calendar_begin = GregorianCalendar.getInstance();
calendar_begin.clear();
calendar_begin.set(1982, Calendar.JANUARY, 1);
Calendar calendar_end = GregorianCalendar.getInstance();
calendar_end.clear();
calendar_end.set(1985, Calendar.DECEMBER, 31);
BasicDBObject query = new BasicDBObject("birth", new BasicDBObject("$gte",
calendar_begin.getTime()).append("$lte", calendar_end.getTime()));
try (DBCursor cursor = dbCollection.find(query) ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
...
The results are shown in Figure 6-6:

Figure 6-6. Extracting only documents with births between 1 January, 1982 and 31 December, 1985
If you prefer to use Joda Time (a replacement for the Java date and time classes, available at http://joda-time.sourceforge.net), you can write the query like this:
System.out.println("JODA - Find players with birthday between 1 January, 1982 - 31 December, 1985:");
DateTime joda_calendar_begin = new DateTime(1982, 1, 1, 0, 0);
DateTime joda_calendar_end = new DateTime(1985, 12, 31, 0, 0);
query = new BasicDBObject("birth", new BasicDBObject("$gte", joda_calendar_begin.toDate()).append("$lte", joda_calendar_end.toDate()));
try (DBCursor cursor = dbCollection.find(query) ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
You can also extract data with specific values using the $in operator and the find method. For example, you can obtain all players with the ages 25, 27, and 30, like this:
...
System.out.println("Find players with ages: 25, 27, 30");
List<Integer> list = new ArrayList<>();
list.add(25);
list.add(27);
list.add(30);
BasicDBObject query = new BasicDBObject("age", new BasicDBObject("$in", list));
try (DBCursor cursor = dbCollection.find(query) ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
...
The result are shown in Figure 6-7.

Figure 6-7. Extracting only documents with age equal to 25, 27, or 30
When you need to extract data by negation, you can use the $ne (not equal) operator and the find method. For example, you can easily obtain all players with ages not equal to 27, like this:
...
System.out.println("Find players with ages different from: 27");
BasicDBObject query = new BasicDBObject("age", new BasicDBObject("$ne", 27));
try (DBCursor cursor = dbCollection.find(query) ) {
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
}
...
The results are shown in Figure 6-8:

Figure 6-8. Extracting only documents with age different from 27
In the previous examples, we created (inserted) and retrieved (read) data from MongoDB using MongoDB Java driver. You can accomplish an update accomplish by calling the save method. For example, you can replace Rafael Nadal with Rafael Nadal Parera, like this:
...
System.out.println("UPDATING ...");
BasicDBObject query = new BasicDBObject("name", "Nadal").append("surname", "Rafael");
try (DBCursor cursor = dbCollection.find(query)) {
while (cursor.hasNext()) {
DBObject item = cursor.next();
item.put("name", "Nadal Parera");
dbCollection.save(item);
}
}
...
And you can delete data by calling the remove method. For example, you can delete all occurrences of Roger Federer, like this:
...
System.out.println("DELETING ...");
BasicDBObject query = new BasicDBObject("name", "Federer").append("surname", "Roger");
try (DBCursor cursor = dbCollection.find(query)) {
while (cursor.hasNext()) {
DBObject item = cursor.next();
dbCollection.remove(item);
}
}
...
![]() Note For advanced queries using MongoDB drivers, see The Definitive Guide to MongoDB by Eelco Plugge, Tim Hawkins, and Peter Membrey (Apress, 2010). Visit www.apress.com/9781430230519.
Note For advanced queries using MongoDB drivers, see The Definitive Guide to MongoDB by Eelco Plugge, Tim Hawkins, and Peter Membrey (Apress, 2010). Visit www.apress.com/9781430230519.
The complete application containing the preceding snippets of code is available in the Apress repository and is named MONGODB_QUERY. It comes as a NetBeans project and was tested under Java 7.
Hibernate OGM and CRUD Operations
The four essential operations performed against a NoSQL database—Create, Read, Update and Delete—are available in Hibernate OGM out of the box. Actually, independently of JPA or the Hibernate Native API, Hibernate ORM delegates persistence and load queries to the OGM engine, which delegates CRUD operations to DatastoreProvider and GridDialect, and these interact with the NoSQL store.
In Chapters 3 and 4 you saw how to develop applications based on Hibernate OGM via the Hibernate Native API and Java Persistence API. It should be a piece of cake, therefore, to wrap the Players entity in Listing 6-1 into such an application.
Listing 6-1. The Players Entity
package hogm.hnapi.entity;
import java.io.Serializable;
...
@Entity
@Table(name = "atp_players")
@GenericGenerator(name = "mongodb_uuidgg", strategy = "uuid2")
public class Players implements Serializable {
@Id
@GeneratedValue(generator = "mongodb_uuidgg")
private String id;
@Column(name = "player_name")
private String name;
@Column(name = "player_surname")
private String surname;
@Column(name = "player_age")
private int age;
@Column(name = "player_birth")
@Temporal(javax.persistence.TemporalType.DATE)
private Date birth;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSurname() {
return surname;
}
public void setSurname(String surname) {
this.surname = surname;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
Once that’s done, you have access to CRUD operations. Suppose we have an instance of Players, named player
.Using Hibernate OGM via Hibernate Native API, you can obtain the Hibernate session with the getCurrentSession or openSession methods.
- To persist the player instance, use the persist method:
HibernateUtil.getSessionFactory().getCurrentSession().persist(player);
- To update the player instance, use the merge method:
HibernateUtil.getSessionFactory().getCurrentSession().merge(player);
- To find the player instance by id, use the find method:
HibernateUtil.getSessionFactory().getCurrentSession().get(Players.class, id );
- To delete the player instance, use the delete method:
HibernateUtil.getSessionFactory().getCurrentSession().delete(player);
You can try all of these methods in a sample application named HOGM_MONGODB_HNAPI_CRUD, available in the Apress repository. It comes as a NetBeans project and was tested under GlassFish 3 AS. The interface application looks like Figure 6-9.
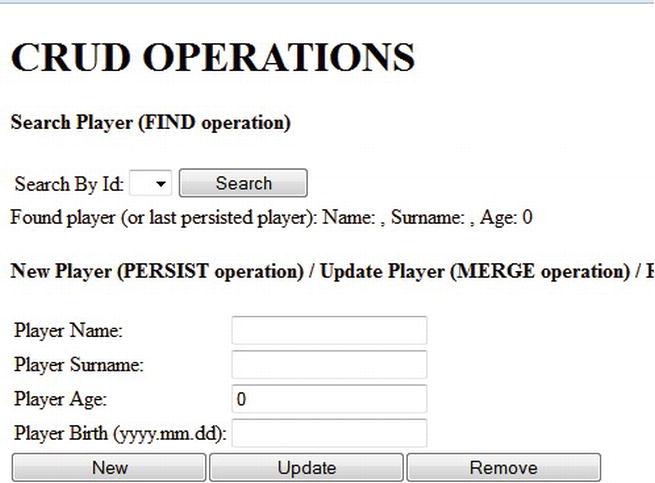
Figure 6-9. Testing Hibernate OGM and CRUD operations
Using Hibernate OGM via the Java Persistence API (em stands for EntityManager):
- To persist the player instance, use the persist method:
em.persist(player);
- To update the player instance, use the merge method:
em.merge(player);
- To find the player instance by id, use the find method:
em.find(Players.class, id );
- To delete the player instance, use the delete method:
em.delete (player);
You can try all of these methods in a sample application named HOGM_MONGODB_JPA_CRUD, available in the Apress repository. It comes as a NetBeans project and was tested under GlassFish 3 AS. The interface application looks like the one in Figure 6-9.
Hibernate Search and Apache Lucene
Basically, Hibernate/JPA and Apache Lucene deal with the same area—querying data. They both provide CRUD operations, a basic data unit (an entity in Hibernate, a document in Lucene) and the same programming concepts. The main difference lies in the fact that Hibernate/JPA promotes domain model-oriented programming, while Lucene deals with only a single, built-in data model—the Document class, which is too simple to describe complex associations. Combined, however, the two yield a higher-level API, named Hibernate Search.
Both Hibernate Search and Apache Lucene are powerful, robust technologies. While Apache Lucene is a full-text indexing and query engine with excellent query performance, Hibernate Search brings its power to the persistence domain model. The symbiosis works fairly well: Hibernate Search “squeezes” the query capabilities of Apache Lucene while providing support for the domain model and the synchronization of databases and indexes, and converting free text queries back to managed objects. Because our focus is on Hibernate OGM and MongoDB, I won’t provide a Hibernate Search or Apache Lucene tutorial. Instead we’ll get quickly to developing examples, and I’ll supply sufficient information for you to understand the new Hibernate Search/Apache Lucene annotations and classes, without going into detail. We are going to combine Hibernate ORM, OGM, and Search with Apache Lucene and MongoDB into applications with query capabilities so you can explore the complexity of the querying process. Once you have a functional application, you’ll be able to try a wide range of queries.
We will develop two applications. The first will be a Hibernate OGM/ via Hibernate Native API application and the second Hibernate OGM via JPA (details in Chapters 3 and 4). Both applications will follow a common, straightforward scenario: we’ll create an entity (and the corresponding POJO, specific only to Hibernate Native API), persist several instances to a MongoDB collection, and execute some query samples through Hibernate Search and Apache Lucene.
The POJO is named Players and is shown in Listing 6-2 (this POJO is mapped in an hbm.xml file).
Listing 6-2. The Players Class
public class Players {
private String id;
private String name;
private String surname;
private int age;
private Date birth;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSurname() {
return surname;
}
public void setSurname(String surname) {
this.surname = surname;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
And thePlayers.hbm.xml fileis shown in Listing 6-3.
Listing 6-3. Players.hbm.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" " http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd ">
<hibernate-mapping>
<class name="hogm.hnapi.pojo.Players" table="atp_players">
<id name="id" type="string">
<column name="id" />
<generator class="uuid2" />
</id>
<property name="name" type="string">
<column name="player_name"/>
</property>
<property name="surname" type="string">
<column name="player_surname"/>
</property>
<property name="age" type="int">
<column name="player_age"/>
</property>
<property name="birth" type="date">
<column name="player_birth"/>
</property>
</class>
</hibernate-mapping>
Or, if you prefer the entity version, the POJO becomes what’s shown in Listing 6-4. (This entity is used in both applications.)
Listing 6-4. The Entity Version of Players
import java.io.Serializable;
...
@Entity
@Table(name = "atp_players")
@GenericGenerator(name = "mongodb_uuidgg", strategy = "uuid2")
public class Players implements Serializable {
@Id
@GeneratedValue(generator = "mongodb_uuidgg")
private String id;
@Column(name = "player_name")
private String name;
@Column(name = "player_surname")
private String surname;
@Column(name = "player_age")
private int age;
@Column(name = "player_birth")
@Temporal(javax.persistence.TemporalType.DATE)
private Date birth;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSurname() {
return surname;
}
public void setSurname(String surname) {
this.surname = surname;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
Common Steps
No matter which application type (OGM via the Hibernate Native API or via JPA), there are a few common steps to add Hibernate Search or Apache Lucene support:
- In addition to the Hibernate OGM and MongoDB library (remember it from Chapter 1), we need to add at least two more JARs: hibernate-search-orm-4.2.0.Final.jar and avro-1.6.3.jar. Both are available in the Hibernate Search distribution, release 4.2.0 Final. Notice that many other JARs, including Apache Lucene and Object/Lucene core mapper, are available in Hibernate OGM and MongoDB library.
- Next, we need to focus on our POJO (or entity) class. This is the first step to bring Hibernate Search into the equation—Hibernate Search-specific configurations are expressed via annotations. More precisely, we need to use a couple of annotations for mapping the POJO (entity).
- We’ll use the @Indexed annotation to mark the Players class as indexable (searchable). Entities that are not annotated with @Indexed will be ignored by the indexing process.
- We then specify how the indexing will be done using the @Field annotation at the field or property level. There are a few supported attributes but, for now, it’s enough to indicate whether the field or property is indexed (using the index attribute); whether the field or property is analyzed (using the analyze attribute); and whether the field or property is stored in the Lucene index (using the store attribute). More attributes and detailed descriptions are available in the official documentation.
- Since we have a Date field, we need to know a few things about how Hibernate Search works with dates. Dates are stored as “yyyyMMddHHmmssSSS in GMT time (200611072203012 for Nov 7th of 2006 4:03PM and 12ms EST),” but we can specify the appropriate resolution for storing a date in the index using the @DateBridge annotation (the resolution can be DAY, HOUR, YEAR, MINUTE, SECOND, MONTH and MILISECOND). We use the YEAR resolution.
- For numerical fields, like player age, we can use the @NumericField annotation. This is optional, but it can be useful for enabling efficient range query, and in sorting, and to speed up queries.
- Finally, to indicate a field or property as the document id (primary key), we need to annotate it with @DocumentId. This annotation is optional for entities that already contain an @Id annotation.
- For our needs, the @Indexed, @Field, @NumericField, @DateBridge and @DocumentId annotations are enough to configure the indexing process. Listing 6-5 shows the Players POJO after it has been marked with the Hibernate Search annotations.
Listing 6-5. The Players POJO with Annotations
package hogm.hnapi.pojo;
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.DateBridge;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.NumericField;
import org.hibernate.search.annotations.Resolution;
import org.hibernate.search.annotations.Store;
...
@Indexed
public class Players {
@DocumentId
private String id;
@Field(index=Index.YES, analyze=Analyze.YES, store=Store.NO)
private String name;
@Field(index=Index.YES, analyze=Analyze.NO, store=Store.NO)
private String surname;
@NumericField
@Field(index=Index.YES, analyze=Analyze.NO, store=Store.NO)
private int age;
@Field(index=Index.YES, analyze=Analyze.NO, store=Store.NO)
@DateBridge(resolution = Resolution.YEAR)
private Date birth;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSurname() {
return surname;
}
public void setSurname(String surname) {
this.surname = surname;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
Or, if we apply these annotations to the Players entity, we get what’s shown in Listing 6-6.
Listing 6-6. The Entity Version of Players with Annotations
package hogm.hnapi.entity;
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.DateBridge;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.NumericField;
import org.hibernate.search.annotations.Resolution;
import org.hibernate.search.annotations.Store;
...
@Entity
@Indexed
@Table(name = "atp_players")
@GenericGenerator(name = "mongodb_uuidgg", strategy = "uuid2")
public class Players implements Serializable {
private static final long serialVersionUID = 1L;
@DocumentId
@Id
@GeneratedValue(generator = "mongodb_uuidgg")
private String id;
@Column(name = "player_name")
@Field(index=Index.YES, analyze=Analyze.YES, store=Store.NO)
private String name;
@Column(name = "player_surname")
@Field(index=Index.YES, analyze=Analyze.NO, store=Store.NO)
private String surname;
@Column(name = "player_age")
@NumericField
@Field(index=Index.YES, analyze=Analyze.NO, store=Store.NO)
private int age;
@Column(name = "player_birth")
@Field(index=Index.YES, analyze=Analyze.NO, store=Store.NO)
@DateBridge(resolution = Resolution.YEAR)
@Temporal(javax.persistence.TemporalType.DATE)
private Date birth;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSurname() {
return surname;
}
public void setSurname(String surname) {
this.surname = surname;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
- 3. Next, we have to provide some basic configuration information in hibernate.cfg.xml (or, in HibernateUtil) for OGM via the Hibernate Native API application, or in persistence.xml, for OGM via JPA.
We have to specify the directory provider; for Apache Lucene, a directory represents the type and place to store index files, and it comes bundled with a file system (FSDirectoryProvider) and an in-memory implementation (RAMDirectoryProvider), though it also supports custom implementations. Hibernate Search is responsible for the configuration and initialization of Lucene resources, including the directory via DirectoryProviders. We want easy access to index files (with the ability to physically inspect indexes with external tools, like Luke), so we’ll use the file system to store them by setting the hibernate.search.default.directory_provider property as filesystem. Besides the directory provider, we also have to specify the default base directory for all indexes via the hibernate.search.default.indexBase property. Finally, we can specify the locking strategy (in this case, the filesystem-level lock) by setting the hibernate.search.default.locking_strategy property to single; this is a Java object lock held in memory. Add these configurations in hibernate.cfg.xml (or in HibernateUtil) for OGM via the Hibernate Native API, or in persistence.xml for OGM via JPA, like this:
//in hibernate.cfg.xml
<property name="hibernate.search.default.directory_provider">filesystem</property>
<property name="hibernate.search.default.indexBase">./Indexes</property>
<property name="hibernate.search.default.locking_strategy">single</property>...
Or:
//in HibernateUtil
OgmConfiguration cfgogm = new OgmConfiguration();
...
cfgogm.setProperty("hibernate.search.default.directory_provider","filesystem");
cfgogm.setProperty("hibernate.search.default.indexBase","./Indexes");
cfgogm.setProperty("hibernate.search.default.locking_strategy", "single");
...
Or:
...
//in persistence.xml
<property name="hibernate.search.default.directory_provider" value="filesystem"/>
<property name="hibernate.search.default.indexBase" value="./Indexes"/>
<property name="hibernate.search.default.locking_strategy" value="single"/>
...
Finally, everything is configured and we are ready to start writing Lucene queries. But, from this point on, the code will be specific to each of the two applications. So let’s start with the OGM via Hibernate Native API application.
Hibernate Search/Apache Lucene Querying—OGM via Native API
The first goal is to write a “select all” query that will help you become familiar with Lucene style in an OGM via Native API application. Following a step-by-step approach, we can write such a query, like this:
- Create an org.hibernate.search.FullTextSession. This interface will spice up the Hibernate session with full-text search and indexing capabilities. This session provides two ways of writing queries: using the Hibernate Search query DSL (domain search language) or the native Lucene query. The code to accomplish this is:
FullTextSession fullTextSession =
Search.getFullTextSession(HibernateUtil.getSessionFactory().getCurrentSession()); - Create an org.hibernate.search.query.dsl.QueryBuilder and use the new session to obtain a query builder that helps to simplify the query definition. Notice that we indicate that our query affects only the Players class:
QueryBuilder queryBuilder = fullTextSession.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get(); - Create a Lucene query. As you’ll see in the official documentation, there are several ways to build a Lucene query using QueryBuilder. For this example, we can use the queryBuilder.all method, which is a simple approach for obtaining whole documents:
org.apache.lucene.search.Query query = queryBuilder.all().createQuery(); - Define a sort rule (optional). We can easily define a sort rule using the Lucene sort capabilities. For example, we might need to sort the extracted players by name:
org.apache.lucene.search.Sort sort = new Sort(new SortField("name", SortField.STRING)); - Wrap the Lucene query in an org.hibernate.FullTextQuery. In order to configure the sort rule and execute the query, we need to wrap the Lucene query into a FullTextQuery, like this:
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery(query, Players.class); - Specify the object lookup method and database retrieval method. For OGM you must specify object lookup and database retrieval methods (SKIP specifies to not check if objects are already present in the second level cache or in the persistence context; FIND_BY_ID loads each object by its identifier one by one):
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP, DatabaseRetrievalMethod.FIND_BY_ID); - Set the sort rule. You can set the sort rule by calling the setSort method:
fullTextQuery.setSort(sort); - Execute the query. Finally, we execute the query and obtain the results in a java.util.List:
List<Players> results = fullTextQuery.list(); - Optionally, clear up the session:
fullTextSession.clear();
We can put these nine steps in a method named selectAllAction to create our first Hibernate Search/Lucene query. You can find this method in a session bean, named SampleBean, in the package hogm.hnapi.ejb shown in Listing 6-7.
Listing 6-7. The selectAllAction Method
package hogm.hnapi.ejb;
...
public class SampleBean {
...
public List<Players> selectAllAction() {
log.info("Select all Players instance ...");
FullTextSession fullTextSession =
Search.getFullTextSession(HibernateUtil.getSessionFactory().getCurrentSession());
QueryBuilder queryBuilder = fullTextSession.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.all().createQuery();
org.apache.lucene.search.Sort sort = new Sort(new SortField("name", SortField.STRING));
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
fullTextQuery.setSort(sort);
List<Players> results = fullTextQuery.list();
fullTextSession.clear();
log.info("Search complete ...");
return results;
}
...
}
The nine steps can be used as a quick guide for writing many other kinds of queries. Now let’s see how to write some common queries:
- Select all players born in 1987. This query (and similar queries) can be easily written using three methods: queryBuilder.keyword, which indicates we’re searching for a specific word; TermContext.onField, which specifies in which Lucene field to look; and TermMatchingContext.matching, which tells what to look for. So, wrapping this query into a method named selectByYearAction looks like what’s shown in Listing 6-8.
Listing 6-8. The selectByYearAction Method
package hogm.hnapi.ejb;
...
public class SampleBean {
...
public List<Players> selectByYearAction() {
log.info("Search only Players instances 'born in 1987' ...");
Calendar calendar = GregorianCalendar.getInstance(TimeZone.getTimeZone("UTC"));
calendar.clear();
calendar.set(Calendar.YEAR, 1987);
FullTextSession fullTextSession =
Search.getFullTextSession(HibernateUtil.getSessionFactory().getCurrentSession());
QueryBuilder queryBuilder = fullTextSession.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query =
queryBuilder.keyword().onField("birth").matching(calendar.getTime()).createQuery();
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP, DatabaseRetrievalMethod.FIND_BY_ID);
List<Players> results = fullTextQuery.list();
fullTextSession.clear();
log.info("Search complete ...");
return results;
}
}
- Select only a player named Rafael Nadal. This query (and similar queries) searches for two words in two different fields, “Rafael” and “Nadal.” The query looks for the first word in the player_surname column (surname field), and for the second word in the player_name column (name field). For this, you can use one of the aggregation operators, named must. (Aggregations operators allow you to combine simple queries into more complex queries.) Wrapping the necessary code into a method named selectRafaelNadalAction shows this. The bool method indicates that we’ve created a Boolean query—a query that finds documents matching Boolean combinations of other queries. (See Listing 6-9.)
Listing 6-9. The selectRafaelNadalAction Method
package hogm.hnapi.ejb;
...
public class SampleBean {
...
public List<Players> selectRafaelNadalAction() {
log.info("Search only Players instances that have the name 'Nadal' and surname 'Rafael' ...");
FullTextSession fullTextSession =
Search.getFullTextSession(HibernateUtil.getSessionFactory().getCurrentSession());
QueryBuilder queryBuilder = fullTextSession.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.bool().must(queryBuilder.keyword()
.onField("name").matching("Nadal").createQuery()).must(queryBuilder.keyword()
.onField("surname").matching("Rafael").createQuery()).createQuery();
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
List<Players> results = fullTextQuery.list();
fullTextSession.clear();
log.info("Search complete ...");
return results;
}
}
- Select players with surnames starting with the letter ’J.’ This query (and similar queries) can be written using wildcards. The ? represents a single character and the * represents any character sequence. The TermContext.wildcard method indicates that a wildcard query follows. Wrapping the necessary code into a method named selectJAction shows this. (See Listing 6-10.)
Listing 6-10. The selectJAction Method
package hogm.hnapi.ejb;
...
public class SampleBean {
...
public List<Players> selectJAction() {
log.info("Search only Players that surnames begins with 'J' ...");
FullTextSession fullTextSession =
Search.getFullTextSession(HibernateUtil.getSessionFactory().getCurrentSession());
QueryBuilder queryBuilder = fullTextSession.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.keyword().wildcard()
.onField("surname").matching("J*").createQuery();
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
List<Players> results = fullTextQuery.list();
fullTextSession.clear();
log.info("Search complete ...");
return results;
}
}
- Select players with ages in the interval (25,28). This query (and similar queries) can be treated as range queries. Such a query searches for a value in an interval (boundaries included or not) or for a value below or above the interval boundary (boundaries included or not). You indicate that a range query follows by calling the QueryBuilder.range method. The interval is set by calling the from and to methods, and the interval’s boundaries can be excluded by calling the excludeLimit method. Wrapping the necessary code into a method named select25To28AgeAction will show this. (See Listing 6-11.)
Listing 6-11. The select25To28AgeAction Method
package hogm.hnapi.ejb;
...
public class SampleBean {
...
public List<Players> select25To28AgeAction() {
log.info("Search only Players that have ages between 25 and 28, excluding limits ...");
FullTextSession fullTextSession =
Search.getFullTextSession(HibernateUtil.getSessionFactory().getCurrentSession());
QueryBuilder queryBuilder = fullTextSession.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.range()
.onField("age").from(25).to(28).excludeLimit().createQuery();
FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
List<Players>results = fullTextQuery.list();
fullTextSession.clear();
log.info("Search complete ...");
return results;
}
}
![]() Note As you can see, you can easy model a range using the from, to, and excludeLimit methods. Beside these, Lucene provides the below and above methods. Using them in a logical approach, you can obtain the well-known operators “<” (less than), “>” (greater than), “<=” (less than or equal to)”, and “>=” greater than or equal to).
Note As you can see, you can easy model a range using the from, to, and excludeLimit methods. Beside these, Lucene provides the below and above methods. Using them in a logical approach, you can obtain the well-known operators “<” (less than), “>” (greater than), “<=” (less than or equal to)”, and “>=” greater than or equal to).
There are many other kinds of queries you can write, you just have to explore more documentation about Hibernate Search and Apache Lucene. For the queries mentioned, I developed a complete application that’s available in the Apress repository and is named HOGM_MONGODB_HNAPI_HS. It comes as a NetBeans project and was tested under GlassFish 3 AS. Figure 6-10 shows this application.
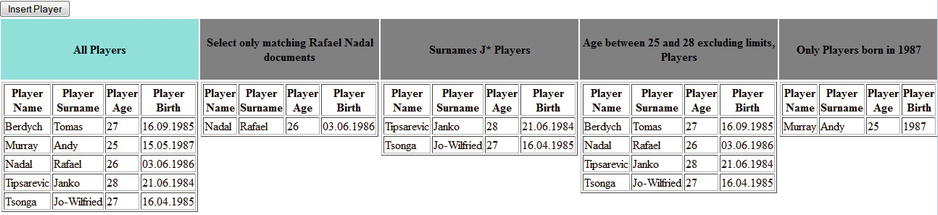
Figure 6-10. The HOGM_MONGODB_HNAPI_HS application
![]() Note You can rebuild the index (deleting it and then reloading all entities from the database) by calling the startAndWait method: fullTextSession.createIndexer().startAndWait();
Note You can rebuild the index (deleting it and then reloading all entities from the database) by calling the startAndWait method: fullTextSession.createIndexer().startAndWait();
When you have associations (or embedded objects), you need to provide a few more annotations. Associated objects (and embedded objects) can be indexed as part of the root entity index. For this, the association is marked with @IndexedEmbedded. When the association is bidirectional, the other side must be annotated with @ContainedIn. This helps Hibernate Search keep up to date the associations indexing process.
For example, let’s suppose that the Players entity is in a many-to-many association with the Tournaments entity (each player participates in multiple tournaments and each tournament contains multiple players). (And keep in mind that POJOs annotations are specified in .hbm.xml files.) The annotated POJOs are shown in Listing 6-12 and Listing 6-13.
Listing 6-12. The Players POJO
package hogm.hnapi.pojo
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.DateBridge;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.IndexedEmbedded;
import org.hibernate.search.annotations.Resolution;
import org.hibernate.search.annotations.Store;
...
@Indexed
public class Players {
@DocumentId
private String id;
@Field(index = Index.YES, analyze = Analyze.YES, store = Store.NO)
private String name;
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.NO)
private String surname;
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.NO)
private int age;
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.NO)
@DateBridge(resolution = Resolution.YEAR)
private Date birth;
@IndexedEmbedded
Collection<Tournaments> tournaments = new ArrayList<Tournaments>(0);
//getters and setters
...
}
Listing 6-13. The Tournaments POJO
package hogm.hnapi.pojo
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.ContainedIn;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.Store;
@Indexed
public class Tournaments {
@DocumentId
private String id;
@Field(index = Index.YES, analyze = Analyze.YES, store = Store.NO)
private String tournament;
@ContainedIn
Collection<Players> players = new ArrayList<Players>(0);
//getters and setters
...
}
Now wrap these POJOs into entities, as shown in Listing 6-14 and Listing 6-15.
Listing 6-14. The Players Entity
package hogm.hnapi.entity;
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.DateBridge;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.IndexedEmbedded;
import org.hibernate.search.annotations.Resolution;
import org.hibernate.search.annotations.Store;
@Entity
@Indexed
@Table(name = "atp_players")
@GenericGenerator(name = "mongodb_uuidgg", strategy = "uuid2")
public class Players implements Serializable {
@DocumentId
@Id
@GeneratedValue(generator = "mongodb_uuidgg")
private String id;
@Column(name = "player_name")
@Field(index = Index.YES, analyze = Analyze.YES, store = Store.NO)
private String name;
@Column(name = "player_surname")
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.NO)
private String surname;
@Column(name = "player_age")
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.NO)
private int age;
@Column(name = "player_birth")
@Field
@DateBridge(resolution = Resolution.YEAR)
@Temporal(javax.persistence.TemporalType.DATE)
private Date birth;
@ManyToMany(cascade = CascadeType.PERSIST,fetch=FetchType.EAGER)
@IndexedEmbedded
private Collection<Tournaments> tournaments= new ArrayList<Tournaments>(0);
//getters and setters
...
}
Listing 6-15. The Tournaments Entity
package hogm.hnapi.entity;
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.ContainedIn;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.Store;
@Entity
@Indexed
@Table(name = "atp_tournaments")
@GenericGenerator(name = "mongodb_uuidgg", strategy = "uuid2")
public class Tournaments implements Serializable {
@DocumentId
@Id
@GeneratedValue(generator = "mongodb_uuidgg")
private String id;
@Field(index = Index.YES, analyze = Analyze.YES, store = Store.NO)
private String tournament;
@ManyToMany(mappedBy = "tournaments", fetch = FetchType.EAGER)
@ContainedIn
private Collection<Players> players = new ArrayList<Players>(0);
//getters and setters
...
}
Now you can write Hibernate Search/Apache Lucene queries. (The official documentation can be a good place to start testing queries for associations.) For testing purposes, I’ve integrated the preceding POJOs and entities into an application named HOGM_MONGODB_HNAPI_ASSOCIATIONS_HS that can be downloaded from the Apress repository (there are two queries involved). It comes as a NetBeans project and was tested under GlassFish 3 AS. Figure 6-11 shows this application.

Figure 6-11. The HOGM_MONGODB_HNAPI_ASSOCIATIONS_HS application
![]() Note You can easily drop a MongoDB database from the shell by typing the command db.dropDatabase();.
Note You can easily drop a MongoDB database from the shell by typing the command db.dropDatabase();.
Hibernate Search/Apache Lucene Querying—OGM via JPA
Remember the “select all” query we wrote earlier? This time, we’ll write the same query for an application based on OGM via JPA. The steps for accomplishing this task are:
- Create an org.hibernate.search.jpa.FullTextEntityManager. This interface spices up the OGM EntityManager with full-text search and indexing capabilities. Here’s the code to accomplish this (em is the EntityManager instance):
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em); - Create an org.hibernate.search.query.dsl.QueryBuilder. Use the new entity manager to obtain a query builder that will help simplify the query definition. Note that you indicate that the query affects only the Players class:
QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get(); - Create a Lucene query. As the official documentation shows, there are several ways to build a Lucene query using queryBuilder. For this example, we can use the queryBuilder.all method, which is a simple approach for obtaining whole documents:
org.apache.lucene.search.Query query = queryBuilder.all().createQuery(); - Define a sort rule (optional). You can easily define a sort rule using the Lucene sort capabilities. For example, you may need to sort the extracted players by name:
org.apache.lucene.search.Sort sort = new Sort(new SortField("name", SortField.STRING)); - Wrap the Lucene query in an org.hibernate.FullTextQuery. In order to set the sort rule and execute the query, you need to wrap the Lucene query in a FullTextQuery, like this:
FullTextQuery fullTextQuery = fullTextEntityManager.createFullTextQuery(query, Players.class); - Specify the object lookup method and the database retrieval method. For OGM, you must specify object lookup and database retrieval methods, like this:
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP, DatabaseRetrievalMethod.FIND_BY_ID); - Set the sort rule. You can set the sort rule by calling the setSort method, like so:
fullTextQuery.setSort(sort); - Execute the query. Finally, you can execute the query and obtain the results in a java.util.List:
...
List<Players> results = fullTextQuery.getResultList();
... - Clear up the session (optional):
fullTextEntityManager.clear();
Now, you can put these nine steps in a method named selectAllAction to obtain the Hibernate Search/Lucene query shown in Listing 6-16.
Listing 6-16. The selectAllAction Method
package hogm.jpa.ejb;
...
public class SampleBean {
...
public List<Players> selectAllAction() {
log.info("Select all Players instance ...");
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Sort sort = new Sort(new SortField("name", SortField.STRING));
org.apache.lucene.search.Query query = queryBuilder.all().createQuery();
FullTextQuery fullTextQuery = fullTextEntityManager.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
fullTextQuery.setSort(sort);
List<Players> results = fullTextQuery.getResultList();
fullTextEntityManager.clear();
log.info("Search complete ...");
return results;
}
}
The nine steps can be used as a quick guide for writing many other kinds of queries. In addition, you can see how to write some common queries (these are the same queries from the section “Hibernate Search/Apache Lucene Querying OGM via Native API,” rewritten for the OGM via JPA case).
- Select all players born in 1987. This query (and similar queries) can be easily written using three methods: QueryBuilder.keyword, which indicates we’re searching for a specific word; TermContext.onField, whichspecifies in which Lucene field to look; and TermMatchingContext.matching, which tells what to look for. So, wrapping this query into a method named selectByYearAction looks like what’s shown in Listing 6-17.
Listing 6-17. The selectByYearAction Method
package hogm.jpa.ejb;
...
public class SampleBean {
...
public List<Players> selectByYearAction() {
log.info("Search only Players instances born in 1987 ...");
Calendar calendar = GregorianCalendar.getInstance(TimeZone.getTimeZone("UTC"));
calendar.clear();
calendar.set(Calendar.YEAR, 1987);
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.keyword()
.onField("birth").matching(calendar.getTime()).createQuery();
FullTextQuery fullTextQuery = fullTextEntityManager.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
List<Players> results = fullTextQuery.getResultList();
fullTextEntityManager.clear();
log.info("Search complete ...");
return results;
}
}
- Select only the player named Rafael Nadal. This query (and similar queries) searches for two words in two different fields, “Rafael” and “Nadal.” The query looks for the first word in the player_surname column (surname field), and for the second word in the player_name column (name field). For this, you can use one of the aggregation operators, named must. Wrapping the necessary code into a method named selectRafaelNadalAction shows this. The bool method indicates that we have created a Boolean query. (See Listing 6-18.)
Listing 6-18. The selectRafaelNadalAction Method
package hogm.jpa.ejb;
...
public class SampleBean {
...
public List<Players> selectRafaelNadalAction() {
log.info("Search only Players instances that have the name 'Nadal' and surname 'Rafael' ...");
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory().
buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.bool().must(queryBuilder.keyword()
.onField("name").matching("Nadal").createQuery()).must(queryBuilder.keyword()
.onField("surname").matching("Rafael").createQuery()).createQuery();
FullTextQuery fullTextQuery = fullTextEntityManager.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
List<Players> results = fullTextQuery.getResultList();
fullTextEntityManager.clear();
log.info("Search complete ...");
return results;
}
}
- Select players with surnames starting with the letter 'J.' This query (and similar queries) can be written using wildcards. The ? represents a single character and the * represents any character sequence. The TermContext.wildcard method indicates that a wildcard query follows. Wrapping the necessary code into a method named selectJAction will show this. (See Listing 6-19.)
Listing 6-19. The selectJAction Method
package hogm.jpa.ejb;
...
public class SampleBean {
...
public List<Players> selectJAction() {
log.info("Search only Players that surnames begins with 'J' ...");
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.keyword().wildcard()
.onField("surname").matching("J*").createQuery();
FullTextQuery fullTextQuery = fullTextEntityManager.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
List<Players> results = fullTextQuery.getResultList();
fullTextEntityManager.clear();
log.info("Search complete ...");
return results;
}
}
- Select players with ages in the interval (25,28). This query (and similar queries) can be treated as range queries. Such a query searches for a value in an interval (boundaries included or not) or for a value below or above the interval boundary (boundaries included or not). You indicate that a range query follows by calling the queryBuilder.range method. The interval is set by calling the from and to methods, and the interval’s boundaries can be excluded by calling the excludeLimit method. Wrapping the necessary code into a method named select25To28AgeAction will show this. (See Listing 6-20.)
Listing 6-20. The select25To28AgeAction Method
package hogm.jpa.ejb;
...
public class SampleBean {
...
public List<Players> select25To28AgeAction() {
log.info("Search only Players that have ages between 25 and 28, excluding limits ...");
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
QueryBuilder queryBuilder = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity(Players.class).get();
org.apache.lucene.search.Query query = queryBuilder.range().onField("age")
.from(25).to(28).excludeLimit().createQuery();
FullTextQuery fullTextQuery = fullTextEntityManager.createFullTextQuery(query, Players.class);
fullTextQuery.initializeObjectsWith(ObjectLookupMethod.SKIP,
DatabaseRetrievalMethod.FIND_BY_ID);
List<Players> results = fullTextQuery.getResultList();
fullTextEntityManager.clear();
log.info("Search complete ...");
return results;
}
}
There are many other kinds of queries you can write, you just have to delve into the available documentation about Hibernate Search and Apache Lucene. For the queries covered, I developed a complete application that’s available in the Apress repository and is named HOGM_MONGODB_JPA_HS. It comes as a NetBeans project and was tested under GlassFish 3 AS. Figure 6-12 shows this application.
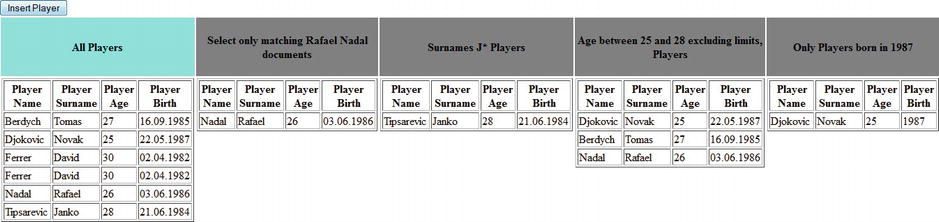
Figure 6-12. The HOGM_MONGODB_JPA_HS application
![]() Note You can rebuild the index (deleting it and then reloading all entities from the database) by calling the startAndWait method: fullTextEntityManager.createIndexer().startAndWait();
Note You can rebuild the index (deleting it and then reloading all entities from the database) by calling the startAndWait method: fullTextEntityManager.createIndexer().startAndWait();
When you have associations (or embedded objects), you need to provide a few more annotations. Associated objects (and embedded objects) can be indexed as part of the root entity index. For this, the association is marked with @IndexedEmbedded. When the association is bidirectional, the other side must be annotated with @ContainedIn. This helps Hibernate Search keep the associations indexing process up to date.
For example, let’s suppose that the Players entity is in a many-to-many association with the Tournaments entity (each player participates in multiple tournaments and each tournament contains multiple players). The annotated Players entity listing is shown in Listing 6-21.
Listing 6-21. The Annotated Players Entity
package hogm.jpa.entity;
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.DateBridge;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.IndexedEmbedded;
import org.hibernate.search.annotations.Resolution;
import org.hibernate.search.annotations.Store;
@Entity
@Indexed
@Table(name = "atp_players")
@GenericGenerator(name = "mongodb_uuidgg", strategy = "uuid2")
public class Players implements Serializable {
@DocumentId
@Id
@GeneratedValue(generator = "mongodb_uuidgg")
private String id;
@Column(name = "player_name")
@Field(index = Index.YES, analyze = Analyze.YES, store = Store.NO)
private String name;
@Column(name = "player_surname")
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.NO)
private String surname;
@Column(name = "player_age")
@Field(index = Index.YES, analyze = Analyze.NO, store = Store.NO)
private int age;
@Column(name = "player_birth")
@Field
@DateBridge(resolution = Resolution.YEAR)
@Temporal(javax.persistence.TemporalType.DATE)
private Date birth;
@ManyToMany(cascade = CascadeType.PERSIST,fetch=FetchType.EAGER)
@IndexedEmbedded
private Collection<Tournaments> tournaments= new ArrayList<Tournaments>(0);
//getters and setters
...
}
And the Tournaments entity is shown in Listing 6-22.
Listing 6-22. The Annotated Tournaments Entity
package hogm.jpa.entity;
import org.hibernate.search.annotations.Analyze;
import org.hibernate.search.annotations.ContainedIn;
import org.hibernate.search.annotations.DocumentId;
import org.hibernate.search.annotations.Field;
import org.hibernate.search.annotations.Index;
import org.hibernate.search.annotations.Indexed;
import org.hibernate.search.annotations.Store;
@Entity
@Indexed
@Table(name = "atp_tournaments")
@GenericGenerator(name = "mongodb_uuidgg", strategy = "uuid2")
public class Tournaments implements Serializable {
@DocumentId
@Id
@GeneratedValue(generator = "mongodb_uuidgg")
private String id;
@Field(index = Index.YES, analyze = Analyze.YES, store = Store.NO)
private String tournament;
@ManyToMany(mappedBy = "tournaments", fetch = FetchType.EAGER)
@ContainedIn
private Collection<Players> players = new ArrayList<Players>(0);
//getters and setters
...
}
Now you can write Hibernate Search/Apache Lucene queries. (The official documentation can be a good place to start testing queries for associations.) For testing purposes, I’ve integrated the preceding entities into an application named HOGM_MONGODB_JPA_ASOCIATIONS_HS that can be downloaded from the Apress repository (there are two queries involved). It comes as a NetBeans project and was tested under GlassFish 3 AS. Figure 6-13 shows this application.

Figure 6-13. The HOGM_MONGODB_JPA_ASSOCIATIONS_HS application
We stop here, but this may be just the beginning of your exploration of the amazing power of Hibernate Search and Apache Lucene combined. I’ve given you a starting point for querying MongoDB collections via OGM and Hibernate Search/Apache Lucene. From this point forward, it’s up to you how much you go in the Hibernate Search/Apache Lucene territory.
According to the Hibernate OGM documentation, version 4.0.0Beta1 includes a JP-QL basic parser capable of converting simple queries using Hibernate Search. Currently, there are several limitations in using it, iincluding:
- No join, aggregation, or other relational operations are implied.
- The Hibernate Session API is used (JPA integration is coming).
- The target entities and properties are indexed by Hibernate Search (currently there’s no validation).
I tried to work around these limitations, but have not been able to develop a functional application to exploit the JP-QL parser for simple queries. I tried, for the Players entity annotated with @Indexed, @Field, and so on, a simple query, like this:
Query query = HibernateUtil.getSessionFactory().getCurrentSession().createQuery("from Players p");
Unfortunately, my multiple approaches failed with one single and annoying error: java.lang.NullPointerException. The indexing process seems to work fine, but the query results list is always null.
Anyway, this is not such a big issue, since the JP-QL parser is very young and, by the time you read this section, this information may well be obsolete. The JP-QL parser may be more generous with its query support by then. For now, you can use the MongoDB Java driver and, of course, Hibernate Search and Apache Lucene.
Summary
After all the hard work of the previous chapters, in this chapter we gathered the fruits. We were able to work with the stored data by writing queries against MongoDB databases. In particular, in this chapter, you learned how to write queries using Hibernate Search/Apache Lucene and the MongoDB Java driver. My aim was to provide the basic information about writing a pure MongoDB Java driver application and an OGM via Native API and/or via JPA application ready to query a MongoDB database.