
Not everything in an image or text—or in general, any data—is equally relevant from the perspective of insights that we need to draw from it. For example, consider a task where we are trying to predict the next word in a sequence of a verbose statement like Alice and Alya are friends. Alice lives in France and works in Paris. Alya is British and works in London. Alice prefers to buy books written in French, whereas Alya prefers books in _____.
When this example is given to a human, even a child with decent language proficiency can very well predict the next word will most probably be English. Mathematically, and in the context of deep learning, this can similarly be ascertained by creating a vector embedding of these words and then computing the results using vector mathematics, as follows:
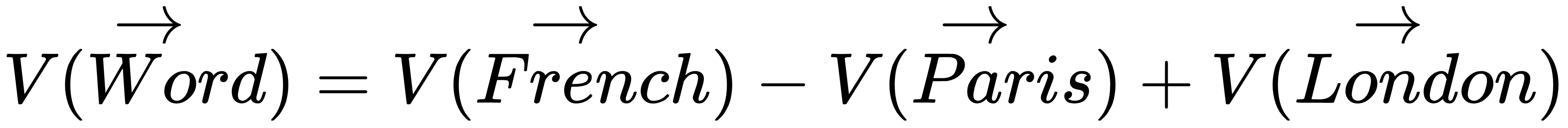
Here, V(Word) is the vector embedding for the required word; similarly, V(French), V(Paris), and V(London) are the required vector embeddings for the words French, Paris, and London, respectively.
There may not be an existing vector exactly matching the vector we obtained just now in the form of  ; but if we try to find the one closest to the so obtained
; but if we try to find the one closest to the so obtained  that exists and find the representative word using reverse indexing, that word would most likely be the same as what we as humans thought of earlier, that is, English.
that exists and find the representative word using reverse indexing, that word would most likely be the same as what we as humans thought of earlier, that is, English.
Though we have helped get the same results, both cognitively and through deep learning approaches, the input in both the cases was not the same. To humans, we had given the exact sentence as to the computer, but for deep learning applications, we had carefully picked the correct words (French, Paris, and London) and their right position in the equation to get the results. Imagine how we can very easily realize the right words to pay attention to in order to understand the correct context, and hence we have the results; but in the current form, it was not possible for our deep learning approach to do the same.
Now there are quite sophisticated algorithms in language modeling using different variants and architectures of RNN, such as LSTM and Seq2Seq, respectively. These could have solved this problem and got the right solution, but they are most effective in shorter and more direct sentences, such as Paris is to French what London is to _____. In order to correctly understand a long sentence and generate the correct result, it is important to have a mechanism to teach the architecture whereby specific words need to be paid more attention to in a long sequence of words. This is called the attention mechanism in deep learning, and it is applicable to many types of deep learning applications but in slightly different ways.
In fact, to be more precise, even we had to process the preceding information in layers, first understanding that the last sentence is about Alya. Then we can identify and extract Alya's city, then that for Alice, and so on. Such a layered way of human thinking is analogous to stacking in deep learning, and hence in similar applications, stacked architectures are quite common.
In this chapter, we will cover the following topics:
- Attention mechanism for image captioning
- Types of attention (Hard, and Soft Attentions)
- Using attention to improve visual models
- Recurrent models of visual attention