
Semantic MediaWiki in applied life science and industry: building an Enterprise Encyclopaedia
Abstract:
The popularity of Wikipedia makes it a very enticing model for capturing shared knowledge inside large distributed organisations. However, building an Enterprise Encyclopaedia comes with unique challenges of flexibility, data integration and usability. We propose an approach to overcome these challenges using Semantic MediaWiki, augmenting the mature knowledge sharing capabilities of a wiki with the structure of semantic web principles. We provide simple guidelines to control the scope of the wiki, simplify the users' experiences with capturing their knowledge, and integrate the solution within an enterprise environment. Finally, we illustrate the benefits of this solution with enterprise search and life sciences applications.
16.1 Introduction
Silos are still very present in large decentralised organisations such as global pharmaceutical companies. The reasons they persist after decades of awareness are multiple: legacy systems too costly to change, cultural differences, political games, or simply because of disconnects between local and global needs. Far from improving knowledge sharing, omnipresent collaboration tools often turn into little more than fancy documents management systems. Knowledge remains hidden under piles of reports and spreadsheets.
As a result, users tend to spend a large amount of their time on trivial tasks such as finding a link to some team portal or looking up the meaning of an acronym. A 2009 survey found it took an average of 38 minutes to locate a document [1]. Overzealous search engines provide little relief: how useful are 2000 hits on documents including a team's name when all you are looking for is the home page of that team?
The majority of these tasks come down to questions such as 'where is what', 'who knows what', and the ever popular 'if we only knew what we knew'. In this context, the idea of an Enterprise Encyclopaedia becomes particularly attractive.
16.2 Wiki-based Enterprise Encyclopaedia
The goal of an Enterprise Encyclopaedia is to capture the shared knowledge from employees about a business: which entities are involved (systems, hardware, software, people, or organisations) and how they relate to one another (context).
Traditional knowledge management techniques have tried (and mostly failed) to provide solutions to this problem for decades, particularly in the collection, organisation and search of text and spreadsheet documents. In recent years, wikis have emerged as a practical way to capture knowledge collaboratively. However, they suffer from a reputation of turning quickly into unstructured and little used repositories. They are difficult to organise and even harder to maintain [2,3].
The first instinct for users is to collect whatever documents they have into a digital library and rely on search to sort it out. To break that perception, it is necessary to teach them to make the wiki their document. This requires a lot of hand holding and training. Part of that perception comes from the lack of quick and easy ways to get people over the stage of importing what they know in the wiki. Wikis work particularly well once they are in maintenance mode, when users just add new pages or edit them when needed. They are more complicated when users are faced with the task of first uploading what they know into blank pages. There is also a tendency to use Wikipedia as a benchmark. 'If Wikipedia can be successful, setting up our own wiki will make it successful.' This approach overlooks Wikipedia's infrastructure and network of collaborators (humans and bots), developed over years of growing demands.
In an enterprise context, wikis need to provide more than a collaborative equivalent of a word processor. The content they hold has to be accessible both to individuals and other systems, through queries in addition to search. What we need is practical knowledge sharing; make it easy for people to share what they know, integrate with other sources and automate when possible. In our experience, Semantic MediaWiki provides a good balance of tools to that end.
16.3 Semantic MediaWiki
The Johnson & Johnson Pharmaceutical Research & Development, L.L.C. is exploring the use of Semantic MediaWiki (SMW) as a data integration tool with applications to guiding queries in a linked data framework for translational research, simplifying enterprise search and improving knowledge sharing in a decentralised organisation. Semantic MediaWiki was initially released in 2005 as an extension to MediaWiki designed to add semantic annotations to wiki text, in effect turning wikis into collaborative databases. MediaWiki itself enjoys some popularity in life sciences. It is used in many biowikis and more notably, in Wikipedia [4,5,14]. The Semantic MediaWiki extension is now at the core of a flurry of other extensions, developed by an active community of developers and used by hundreds of sites [6].
16.3.1 Flexibility
At the confluence of R&D and IT, change is unavoidable. Capturing and understanding concepts involved in a business is a moving target. Flexibility is assured by MediaWiki core functionalities:
![]() complete edit history on any page;
complete edit history on any page;
![]() redirects (renaming pages without breaking links);
redirects (renaming pages without breaking links);
![]() a differentiation between actual and wanted pages (and their reports in special pages);
a differentiation between actual and wanted pages (and their reports in special pages);
![]() a vast library of free extensions;
a vast library of free extensions;
These features are born out of real needs in collaborative knowledge management and make MediaWiki a solid base for an Enterprise Encyclopaedia. The addition of Semantic MediaWiki's simple system of annotations augments this flexibility, as it is generic enough to adapt to most applications. Semantic relationships are much more than the system of tags and simple taxonomies often found in content management systems. They can be seen as tags with meaning, turning each wiki page as the subject of these relationships. For example, the page about the acronym 'BU' may be annotated with an embedded semantic property in the format: [[Has meaning::Business Unit]]. This annotation creates a triple between the subject (the page titled 'BU'), the object ('Business Unit') and a predicate (the relationship 'Has meaning'). Figure 16.1 shows an example of semantic annotations using the 'Browse Properties' view of a wiki page. This default view allows for a visual inspection of annotations captured in a wiki page as well as links to view linked pages and query for pages with the same annotations. This view is generated automatically by Semantic MediaWiki and is independent from the actual wiki page.

Figure 16.1 An example of semantic annotations. The 'Browse Properties' view of a wiki page provides a summary of semantic properties available for query inside of a wiki page
Semantic MediaWiki also provides a mechanism to query these properties, turning a wiki into a free form, collaborative database. Creating complete applications within the wiki comes down to selecting the right annotations. For example, adding a URL property to pages instantly turns a wiki into a social bookmarking tool. Add a date to create blogs or new feeds or add a geographic location to create an event planner. With the help of some extensions such as Semantic Forms and Semantic Results Formats, Semantic MediaWiki allows for a wide range of applications, such as question and answer tools, glossaries or asset management systems. Finally, a significant part of MediaWiki's flexibility comes from several hundred extensions developed by a very active community to extend its capabilities.
16.3.2 Import and export of content
Useful content for an Enterprise Encyclopaedia rarely exists in a vacuum. Fortunately, many MediaWiki extensions exist to simplify import of content.
Semantic Forms make manual entries as easy as possible. Using forms to encapsulate semantic annotations allows standardised capture and display of structured content and avoids presenting users with a blank page. Figure 16.2 shows an example of form. Form fields support several customisation parameters to mark them as required, control their display type (pull down list, text field, text area) and enable auto completion from categories, properties, and even external sources to the wiki. Using the optional HeaderTabs extension, it is also possible to simplify complex forms by grouping fields into tabs.
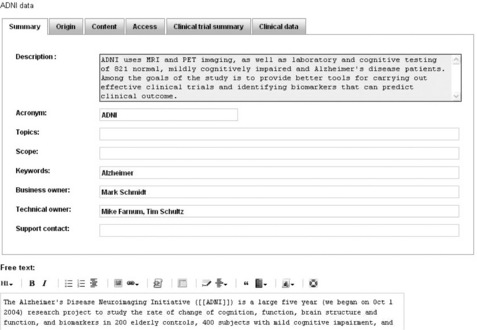
Figure 16.2 Semantic Form in action. The form elements define a standard list of annotations for a page category while the free text area allows for capture of manual text and annotations
The Data Transfer extension allows the creation of pages in bulk from XML or CSV files. Batch creation of pages from files is critical to help users when content is already available in a structured form. The External Data extension allows embedding of live content from remote sources directly inside wiki pages. The extension supports XML or JSON feeds, as well as MySQL and LDAP connections.
Several specialised extensions are also available. For instance the Pubmed extension shown in Figure 16.3 allows the retrieval of full citations from Pubmed using a list of identifiers. Similar extensions exist for RSS feeds or social networks.
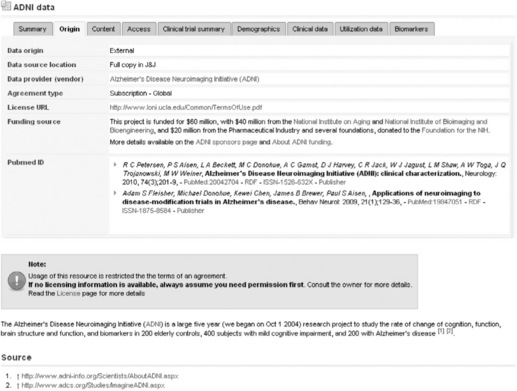
Figure 16.3 Page template corresponding to the form in Figure 16.2. The abstracts listed in the Pubmed ID field were automatically extracted from a query to the Pubmed database using only two identifiers.
Finally, the Application Programming Interface (API) provided by MediaWiki allows more elaborate automation. Programs (or Bots) can perform maintenance updates in an unattended fashion and handle issues such as detecting broken links or correcting spelling and capitalisation [7]. Encyclopaedic knowledge is meant to be consumed in many ways, presented differently for different audiences. Similarly, several extensions allow export of content in various formats.
A key feature of Semantic MediaWiki is the capability to query semantic annotations like a database in addition to the traditional search. The default query mechanism allows the formatting of query results inside wiki pages as lists and tables, but also as links to comma separated values (CSV) files, RSS feeds and JSON files. The optional Semantic Result Formats extension adds many more formats such as tag clouds, graphs, charts, timelines, calendars, or maps.
16.3.3 Ease of use
The last category of extensions making Semantic MediaWiki such a good fit to build an Enterprise Encyclopaedia covers interface customisations and improvements to user experience. Extensions such as ContributionCredits improve trust and credibility by giving visible credits to the authors of wiki pages and providing readers with an individual to contact for more questions on the topic of a page. Other improvements include authentication frameworks, to remove the need to login and lower the barrier of entry for new users, navigation improvements such as tabbed content or social profiles complete with activity history and a system of points to encourage participation.
A particularly noteworthy effort to improve usability of Semantic MediaWiki is the Halo extension [9], which provides a complete makeover of advanced functionalities, including a customised rich text editor, inline forms and menus to edit properties and manage an ontology, an advanced access control mechanism and improved maintenance and data integration options. Halo and related extensions are both available as individual modules and as a packaged version of Semantic MediaWiki called SMW + .
In the end, the array of extensions available to MediaWiki makes it possible to customise the wiki to the needs of the users and provides the necessary tools to fit it easily in a growing ecosystem of social networks within the enterprise.
16.3.4 Design choices
Our internal wiki, named KnowIt, started initially as a small knowledge base to help with documentation of systems within J&J Pharmaceutical Research & Development, with categories such as applications, databases or servers. The home page for the wiki is shown in Figure 16.4, and Figures 16.5 and 16.6 show an example of an individual page.

Figure 16.4 The KnowIt landing page. The home page of the wiki provides customised links based on semantic annotations captured in user profiles about their location, their group memberships and professional interests
Figure 16.5 The layout of KnowIt pages is focused on content. Search and navigation options are always available at the top of pages
KnowIt was launched in 2008, with content from previous attempts at a knowledge base about informatics systems dating back to 2002. That initial content provided a useful base to seed the wiki with a few thousand pages worth of useful information [8]. The transition to Semantic MediaWiki was prompted by the need to capture more contextual information about these systems, such as people and organisations involved, geographic locations or vocabularies. It was also necessary to keep the knowledge base flexible enough to adapt to inevitable changes in R&D. Gradually, the system has been outgrowing its initial scope and is turning slowly into an encyclopaedia of 'shared' knowledge within Johnson & Johnson.
16.3.5 Control the scope
From a strategic point of view, the choice of focusing on 'shared' information made sense as it reduced the scope of the wiki to content generic enough to be shared openly in the enterprise without going through multiple layers of access rights. It allows users to focus on what should be easily shared and keep sensitive material in places where they are already secured. From a more practical point of view, KnowIt acts as a directory of 'where is what' instead of trying to replicate every piece of information possible. In this context, 'shared' information includes categories such as links to internal portals, dictionaries of acronyms, names of teams and external partners. Given the potential breadth of topics, another key decision was to start small and let user needs drive the type of content made available. This ensures that the content of the wiki is always useful to users and that no expansion is made without someone asking for it.
16.3.6 Follow simple guidelines
Setting some ground rules was also helpful with the design of the wiki. Although it is possible to allow semantic annotations anywhere on wiki pages, doing so would require every contributor to be familiar with the names of properties. It is both impractical and unrealistic to expect users will be experts in the structure of the wiki. Using the Semantic Forms extension added a much-needed level of abstraction over semantic annotations and ensured that users can focus on content instead of having to struggle with annotations directly. At the same time, the Free Text area available in most forms allows more advanced users to capture additional annotations not covered by the forms. This is an important feature as it allows the wiki to adapt to exceptions to the structure provided by the forms.
Semantic Forms work best when wiki pages are modelled after the idea of classes through the use of MediaWiki's built-in system of categories. By restricting categories to represent only the nature of a page (what a page is about), and setting the limit to only one category per page, it is possible to take full advantage of Semantic MediaWiki's basic inference model. For example, if Acronyms can be defined as a subcategory of Definitions, a query for any page in the Definition category will also return pages in the Acronym category.
This design choice has a few consequences on the behaviour of the wiki.
![]() With one category per page, it makes sense to have only template per category and at least one form. Semantic Forms includes a convenient wizard to create forms and templates from a list of semantic properties. The association of a category, form, template and properties is what defines a 'class' in Semantic MediaWiki.
With one category per page, it makes sense to have only template per category and at least one form. Semantic Forms includes a convenient wizard to create forms and templates from a list of semantic properties. The association of a category, form, template and properties is what defines a 'class' in Semantic MediaWiki.
![]() Creating a single 'top' category for all categories associated with forms makes it possible to separate semantic content from other pages such as portals or index pages. This is useful when trying to get an accurate count of wiki pages.
Creating a single 'top' category for all categories associated with forms makes it possible to separate semantic content from other pages such as portals or index pages. This is useful when trying to get an accurate count of wiki pages.
Identifying a core set of semantic properties common to all categories is useful to simplify reporting and navigation between pages.
![]() Description: a short summary of what a page is about.
Description: a short summary of what a page is about.
![]() Topics: tags to define a flexible classification of content inside pages (examples of topics are 'chemistry', 'biology', 'sequencing').
Topics: tags to define a flexible classification of content inside pages (examples of topics are 'chemistry', 'biology', 'sequencing').
![]() Scope: tags to indicate for whom a page is relevant (examples of scopes are individuals, teams, functions, companies).
Scope: tags to indicate for whom a page is relevant (examples of scopes are individuals, teams, functions, companies).
In addition to the core set, a few standard properties can help overcome some limitations of Semantic MediaWiki.
![]() Page title (text): pattern matching in semantic queries is allowed only for properties of type text. Creating a text version of the page title as a property allows queries such as 'all pages starting with the letter A', which can be useful for creating a table of contents or alphabetical indices.
Page title (text): pattern matching in semantic queries is allowed only for properties of type text. Creating a text version of the page title as a property allows queries such as 'all pages starting with the letter A', which can be useful for creating a table of contents or alphabetical indices.
![]() Class name (text): creating a redundant property for the category of pages allows running of queries on a single category, without inheritance.
Class name (text): creating a redundant property for the category of pages allows running of queries on a single category, without inheritance.
![]() Related to: it is useful to define a 'catch all' property on certain pages to capture relationships that have not yet been formally defined. Regular reviews of values provided by users for this property are useful to identify properties that should be made more explicit inside forms.
Related to: it is useful to define a 'catch all' property on certain pages to capture relationships that have not yet been formally defined. Regular reviews of values provided by users for this property are useful to identify properties that should be made more explicit inside forms.
16.3.7 Simplify the user experience
Choosing the right mix of extensions is not enough to ensure participation. In order to be successful, an Enterprise Encyclopaedia has to find a place in the flow of a casual user, which means it has to fit within the ecosystem of tools they use daily to find and share information. Customisation of the visual theme of the wiki (its skin) is necessary to allow content to be embedded in remote sites, viewed from mobile devices or printed if necessary. For example, the interface needs to provide options to share content using email, forums and whatever micro-blogging platform is used internally. By providing options to share content from the wiki to other tools in use in the enterprise, the number of necessary steps to share content is reduced and adoption is improved. Similarly, shortcuts need to be put in place to simplify the creation of pages such as bookmarklets or links from popular portals. Finally, content of the wiki needs to be available from enterprise search engines to allow users to navigate seamlessly to the wiki from their search.
Reducing the barrier to entry also means adjusting the vocabulary of the interface itself to be more readily understandable. Fortunately, MediaWiki provides simple ways to change just about every label and message used in its interface. Changing 'watchlists' to 'alerts' or 'talk pages' to 'comments' can make a difference between features being ignored or used. In some cases, it was also necessary to move away from the default pages provided by MediaWiki to display alerts or recent changes and provide our own, simplified version instead. Many of these advanced pages appear too technical and cumbersome for casual users. Some advanced maintenance tasks such as creating redirections to and from a page or managing disambiguation can be made more accessible with the help of a few forms and extensions. For example, the CreateRedirect extension provides users with a simple form to create aliases to pages instead of expecting them to manually create a blank page and use the right syntax to establish a re-direction to another page.
Finally, there is an on-going debate about the value of a rich text editor in a wiki. Rich text editors can simplify the user experience by providing a familiar editing environment. On the other hand, they encourage copy and paste from word processors or web pages, at the cost of formatting issues, which can quickly become frustrating. MediaWiki supports both options. Although CKeditor, as provided by the Halo extension [9], is currently one of the most advanced rich text editors supported by Semantic MediaWiki, we decided to use a markup editor such as MarkltUp for the convenience of features such as menus and templates to simplify common tasks related to wiki markup.
16.3.8 Implementation – what to expect
Semantic MediaWiki is a good illustration of the type of integration issues that can arise when working with open source projects. It can be difficult to find an extension that works exactly the way you need it to. The good news is that there are hundreds of extensions to choose from and it is relatively easy to find one that behaves very close to what you need, and customise it if needed. On the other hand, the lack of maturity of certain extensions means that making them fit seamlessly in a wiki can be a frustrating experience. It is necessary to decide early if features provided by an extension are absolutely necessary and to keep customisations to minimum. If customisations are required, keep track of changes to external code and work with the original authors of the extension to push for integration if possible. Furthermore, the lack of detailed documentation is an on-going issue with any open source project. Fortunately, the community around Semantic MediaWiki is active and responsive to questions and requests.
16.3.9 Knowledge mapping
One of the major obstacles to using Semantic MediaWiki as an encyclopaedia is that it requires the relatively hard work of breaking information into pages and linking them together. Semantic Forms does make this task easier, but it still requires a lot of effort to get people used to the idea. This is especially visible when someone is trying to transfer their knowledge into a relatively empty area of a wiki. Under ideal conditions, users would have that content already available in a spreadsheet ready to load with the Data Transfer extension, assuming there is not a lot of overlap with the current content of the wiki. In practice, users have reports, presentation slides or emails, which make it hard to break into a structured collection of pages. For example, a system configuration report would have to be mapped into individual pages about servers, applications, databases, service accounts and so on. Once that hurdle is passed, the payoff is worth the effort. Being able to query wiki content like a database is vastly superior to the idea of search, but, in order to show this to users in a convincing way, someone has to go through the painful job of manual updates, data curation and individual interviews to import that content for them.
Mapping relationships between people, organisations and other topics is a crucial step towards building a rich map of expertise in an organisation. As the graph of relationships is coming from both automated and manual inputs, the links between people and content tend to be more relevant than automated categorisations performed by search engines. The quality of these relationships was confirmed empirically by observing improved search results when the content of the wiki was added to an enterprise search engine. Another side effect of using Semantic MediaWiki is the increased pressure for disambiguation, shared vocabularies, and lightweight ontology building. As page titles are required to be unique, ambiguities in content quickly become visible and need to be resolved. This becomes visible, for example, when the same name is used by different users to reference a web application, a database or a system as a whole. The payoff from disambiguation efforts is that it allows content to be shared using simple, human readable URLs. The wiki provides stable URLs for concepts and can act as both a social bookmarking tool and a URL shortener in plain English. For example, the URL http://wikiname.company.com/John_Smith is easier to re-use in other applications and is easier to remember than http://directory.company.com/profiles/userid=123456.
16.3.10 Enterprise IT considerations
Even though KnowIt started as an experiment, it was deployed with proper security and disclaimers in place. We were fortunate to benefit from an internal policy of 'innovation time' and develop the knowledge base as an approved project. This allowed us to get buy-in from a growing number of stakeholders from the information technology department, management and power users. By deciding to let use cases and practical user needs drive the development of expansions to the wiki, it was possible to keep demonstrating its usefulness while at the same time, increasing exposure through internal communication channels and external publications. It also helped being prepared and anticipating the usual objections to new technologies, such as security, workflow and compatibility with environments and applications already in use.
Microsoft SharePoint
Microsoft SharePoint is difficult to avoid in an enterprise environment, in particular in life sciences. Most of the big pharmaceutical companies are using SharePoint as a platform to collaborate and share data [10]. SharePoint is often compared to a Swiss Army knife in its approach to collaboration. In addition to its core document management capabilities and Microsoft Office compatibility, it provides a set of tools such as discussion areas, blogs and wikis. These tools are simple by design and require consultants and third-party modules in order to complete their features. By Microsoft's own admission, 'About $8 should be spent on consultants and third party tools for every 1$ spent on licenses' [11,12].
The document-centric design of SharePoint governance and customisations keep it from turning into another disorganised file storage. By contrast, the data-centric design of Semantic MediaWiki requires an effort of knowledge mapping from users, and in turn, a significant effort to assist them in extracting knowledge into individual wiki pages instead of uploading documents and relying on search alone to sort things out.
Semantic MediaWiki can coexist with SharePoint as a complement. Integration is possible in both directions. The wiki provides XML representations of queries to its content using simple URLs. SharePoint provides web parts capable of consuming that XML content from generic format (using XLST to render the results) or using specialised formats such as RSS feeds. Extracting content from SharePoint into the wiki is possible using web services. However, at this time, importing content from SharePoint requires some development, as there is no MediaWiki extension available to perform this task out of the box (although extensions such as Data Import provide basic mechanisms to connect to REST or SOAP services and could be used as the start of a SharePoint specific extension).
Security
MediaWiki has the reputation of being a weak security model, partly because of the many warnings visible on extensions designed to augment security. The security model used by MediaWiki is in fact robust when applied as intended, using groups and roles, although it lacks the level of granularity of other collaboration tools. However, more granular security models are available, such as the Access Control List from the Halo extension [9].
To reduce the likelihood of vandalism, already rare within a corporate environment, anonymous access was replaced by identified user names based on an Enterprise Directory. Using network accounts removed the need for keeping track of separate passwords.
Workflow
Based on earlier experience with collaborative knowledge bases, the editorial workflow model was deliberately left open, making full use of alerts and education instead of various levels of approval. This policy reduces bottlenecks, fosters collaboration and, overall, increases quality of the content and accountability of authors, as changes are made available immediately, with the name of authors visible to everyone.
Performance
On the administrative side, running MediaWiki as a server requires maintenance tasks such as keeping up with updates of extensions, managing custom code when necessary, and most importantly, tuning performance through various caching techniques at the database, PHP and web server levels [13]. Beyond simple performance tuning, scalability becomes a concern as the wiki grows. At this stage of development, KnowIt is far from reaching its limit. Wikis such as Proteopedia [14] are ten times larger with no noticeable performance issue. A wide range of options are available to evolve the architecture of the system with increasing demands, from investigating cloud-based deployments to distributing content across a network of synchronised databases or making heavier use of triple stores as more efficient storage and query solutions.
16.3.11 Linked data integration
With its many options to import and export content, Semantic MediaWiki is a good platform for data integration. In an encyclopaedia model, wiki pages become starting places around a topic, hubs to and from multiple resources. The wiki provides the means to bring content from remote sources together and augment it with annotations. Information about these sources still has to be collected manually, starting with the locations of the data sources, the formats of data they contain and proper credential or access rights. Once sources of content are identified, synchronisation of remote content with local annotations may become necessary. By providing a uniform Application Programming Interface (API) and support for multiple vocabularies, Linked Data principles can help simplify such synchronisations. Linked data is a term used to describe assertions encoded in a semantic format that is compatible with both humans and computers (and is discussed in Chapter 19 by Bildtsen et al. and Chapter 18 by Wild). The greatest source of flexibility in Semantic MediaWiki, and an underutilised feature, is its capacity to produce and consume Linked Data.
Authoring Linked Data with Semantic Mediawiki
As of Semantic MediaWiki 1.6, semantic annotations can be stored directly in any SPARQL 1.1 compatible triple store. This will enable an easier integration with third-party triple stores. Earlier versions relied on a triple store connector, which provided live synchronisation of wiki content with a triple store running parallel to the wiki [15]. In both cases, the result is a near seamless production of Linked Data formats: RDF export of semantic annotations and queries, and OWL export of categories and properties defined in the wiki. This lets users focus on content through a familiar wiki interface and relegates Linked Data considerations to automated export formats. Most importantly, storing semantic annotations inside a triple store opens up more advanced capacities, such as the use of rules and inference engines. It also enables the use of the SPARQL query language to go beyond the limitation of the built-in query language in Semantic MediaWiki and enable more complex queries.
It is also worth noting that more lightweight approaches to making semantic annotations available externally are also emerging. Using RDFa or microdata formats, they will allow seamless augmentation of existing wiki pages in formats recognised by web browsers and search engines [16].
Consuming Linked Data content
Various options also exist to query and embed Linked Data content into wiki pages. From emerging extensions such as RDFIO or LinkedWiki, to more stable solutions such as the Halo extension, they do not stop at simply embedding the result of SPARQL queries inside wiki pages. Instead, they allow import of remote annotation to augment wiki pages [9,15].
These Linked Data extensions are only steps toward using wikis to build mashups between multiple sources [17] or a fully dynamic encyclopaedia defined as collections of assertions with their provenance, such as demonstrated by Shortipedia [18].
16.3.12 Applications of Linked Data integration
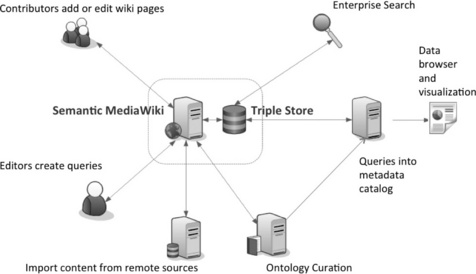
KnowIt is making use of the default RAP triple store provided with Semantic MediaWiki prior to version 1.6. It is also using the SPARQL Query extension to form queries and provide simple links to results in several formats (CSV, XML, JSON) directly from the wiki [15]. Figure 16.7 gives an overview of the system. The Semantic MediaWiki side of the system provides an interface to capture manual annotations from users. Synchronised automatically when a user makes a change in the wiki, the triple store side of the system provides an interface to other applications using SPARQL queries.
16.3.13 Incremental indexing of enterprise search
As a first application, we created an XML connector from KnowIt to our enterprise search engine. SPARQL queries to the wiki can now be used to control which content should be indexed. Integration with existing search engines is important as it allows content of the wiki to be seamlessly available to users unfamiliar with the wiki. For instance, this allows scientists to search for data sources that contain terms such as 'gene sequencing' and 'proteins' and see a resulting list of all relevant data sources internal and external to the enterprise.
Although this application is possible using the basic query mechanism from Semantic MediaWiki, SPARQL queries make it possible to formulate elaborate filters on pages to update, and index them based on modification date or other criteria. Eventually, this mechanism will allow us to filter out pages that should not be indexed, and will provide the search engine complete semantic annotations when RDF content is available. This allows a reduction of the impact of crawling on the server, better use of network bandwidth and better control of what to index [19].
16.3.14 Linked Data queries for translational research
Finding sources of data with content of interest inside a large research organisation is often a challenging task. A typical experience for a scientist involved finding out about the data source and associated applications by word of mouth, looking for the owner of the data in order to gain access to it, which may require an in-depth discussion of the terms and conditions of the license agreement, and finally installation of new software tools on their desktop. If a scientist was interested in an external data source they would need access to IT resources to bring a copy of the data in-house and potentially provide an interface, as well as discussing the licensing terms and conditions with the legal department. These challenges will only become more prevalent as pharmaceutical companies increasingly embrace external innovation and are confronted with the need to reconcile many internal and external data sources.
KnowIt plays a central role in an internally developed Linked Data framework by exposing meta-data related to data sources of interest and by providing a catalogue of Linked Data services to other applications [19,20]. To help build these services, we developed a C# library that provides other developers in the organisation with tools to discover and query the biomedical semantic web in a unified manner and re-use the discovered data in a multitude of research applications. Details provided by scientists and system owners inside the wiki augment catalogue this information such as the contact information for a data source, ontological concepts that comprise the data source's universe of discourse, licensing requirements and connection details, preferably via SPARQL endpoints. The combination of Semantic MediaWiki and the C# library create a framework of detailed provenance information from which Linked Data triples are derived. Eventually, paired with triple stores, and tools for mapping relational databases to RDF, this framework will allow us to access the mass of information available in our organisation seamlessly, regardless of location or format.
Two applications were designed to demonstrate this framework. First, we extracted a high-level, static visual map of relationships between data sources. Next, we developed a plug-in for Johnson & Johnson's Third Dimension Explorer, a research tool for visualising and mining large sets of complex biomedical data [21]. The plug-in utilises metadata in KnowIt to render an interactive visualisation of the data source landscape. Unlike the static map, the plug-in performs a clustering of data source attributes, such as ontological concepts and content, expressed by each data source in order to group similar data sources together.
From the Third Dimension Explorer interface, researchers can explore the visually rendered map of data sources, issue queries to each data source's SPARQL endpoint, and aggregate query results. Figure 16.8 shows an example of a contextual menu with information about the origin, contact information, licensing details and content extracted from KnowIt. Adding a new data source to the query tool becomes as simple as adding a new page in the wiki. The query application also provides access to query wizards to other internal biological, chemical and clinical data warehouses. This permits users to refine queries in a single data source as well as retrieve known information for a single entity across multiple domains.
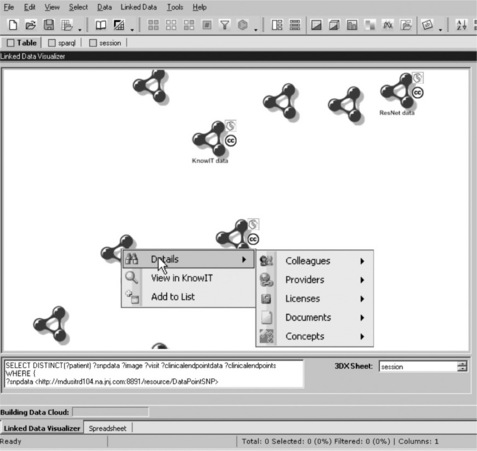
Figure 16.8 Wiki-based contextual menus. Information about data sources inside the query application is augmented with details managed inside KnowIt
This application illustrates the full benefits of building a semantic Enterprise Encyclopaedia. Thanks to Semantic MediaWiki, the encyclopaedia serves as a backbone for openly exposing meta-data about biomedical data sources in a way that can be programmatically exploited across a multitude of applications within J&J.
16.4 Conclusion and future directions
Three years into using Semantic MediaWiki as a base for an Enterprise Encyclopaedia, usage is still ramping up, already expanding beyond the original informatics user base into topics relevant to the whole organisation. However, many areas of improvements remain.
Queries in many formats do not replace the power of an interactive, visual exploration of relationships graph captured in the wiki. Although many attempts have been made to visualise relationships in a wiki, very few make good use of semantic annotations provided by Semantic MediaWiki. Wiki-based visualisation tools at this point are mainly the product of academic research, using methods and tools developed for the occasion of the research. There is still a need for a robust browser to explore semantic relationships in an interactive way, with the layers, filters and links that would be required of that type of visualisation.
Similarly, although many bots exist to help automate maintenance tasks in a MediaWiki instance, we were not able to find examples of bots designed to work specifically for the maintenance of Semantic MediaWiki content. With the exception of the Gardening tools provided with the Halo Extension, creating a bot to perform batch updates of annotations or synchronisation of content with remote sources still requires the customisation of bots designed to work with text operations (search and replace strings) instead of semantic operations (remove or add values to semantic properties).
Finally, making queries more user-friendly would help a lot with adoption. Building queries still requires certain knowledge of available properties and how they relate to categories in the wiki. Additionally, there is no easy way at the moment to save the result of a query as a new page, which would be very helpful for users to share and comment on the results of their queries. An interesting example of this type of saved queries can be found in the Woogle extension, where users can persist with interesting search results, promote or remove individual results and comment the result page itself as a wiki page [22].
Regarding KnowIt as an Enterprise Encyclopaedia, several challenges remain. As is the case with many wiki projects, fostering the right levels of participation requires a constant effort of education, community outreach and usability improvements. Overall, Semantic MediaWiki provides a flexible yet structured platform to experiment with many aspects of enterprise data integration and knowledge sharing, in a way that can be immediately useful. The open source aspect of the software makes it ideal to experiment with ideas quickly, customise extensions to meet local requirements and provide unique features at a very low cost.
16.5 Acknowledgements
The system presented here is the result of contributions from many people over a long period of time. We would like to thank current and past contributors for their patience, ideas and support. In particular, Keith McCormick and Joerg Wegner for their ideas about user experience and tireless advocacy of KnowIt, Susie Stephens, Tim Schultz and Rudi Veerbeck for extending the use of a meta-data catalogue into a Linked Data framework, Joe Ciervo for developing the XML connector to the enterprise search engine and Dimitris Agrafiotis, Bob Gruninger, Ed Jaeger, Brian Johnson, Mario Dolbec, and Emmanouil Skoufos for their approval and support.
16.6. References
[1] , 'Employees in Companies with 10,000 + Workers Spend 38 Minutes Per Document Search. Recommind Inc. survey. 11 August 2011; 11 May 2009. http://www.recommind.com/node/667
[2] Shehan Poole, E., Grudin, J., 'A taxonomy of Wiki genres in enterprise settings. Proceedings of the 6th International Symposium on Wikis and Open Collaboration (WikiSym '10). ACM, New York, NY, USA. 2010:4, doi: 10.1145/1832772.1832792. [Article 14,].
[3] Caya P and Nielsen J. 'Enterprise 2.0: Social Software on Intranets –A Report From the Front Lines of Enterprise Community, Collaboration, and Social Networking Projects'.
[4] Boulos, M. Semantic Wikis: A Comprehensible Introduction with Examples from the Health Sciences'. Journal of Emerging Technologies in Web Intelligence. 1(1), 2009.
[5] Huss, J.W., 3rd., Lindenbaum, P., Martone, M., Roberts, D., Pizarro, A., Valafar, F., Hogenesch, J.B., Su, A.I. 'The Gene Wiki: community intelligence applied to human gene annotation'. Nucleic Acids Research. 2009.
[6] Krotzsch, M., Vrandecic, D., Volkel, M., 'Semantic MediaWiki. Isabel Cruz, Stefan Decker, Dean Allemang, Chris Preist, Daniel Schwabe, Peter Mika, Mike Uschold, Lora Aroyo. Proceedings of the 5th International Semantic Web Conference (ISWC-06). Springer, 2006.
[7] , Wikipedia: Creating a bot. Wikipedia manual. 11 August 2011 22 July 2011. http://en.wikipedia.org/wiki/Wikipedia:Creating_a_bot
[8] Alquier, L., McCormick, K., Jaeger, E., knowI, T., a semantic informatics knowledge management system. Proceedings of the 5th International Symposium on Wikis and Open Collaboration (Orlando, Florida, 25–27 October 2009). WikiSym '09. ACM, New York, NY, 1–5, 2009. [http://doi.acm.org/10.1145/1641309.1641340].
[9] Halo extension. Semanticweb.org, 29 October 2010. http://semanticweb.org/wiki/Halo_Extension. [8 July 2011].
[10] Basset, H. The Swiss Army knife for information professionals. August-September: Research Information review; 2010.
[11] Sampson, M. The cost of SharePoint. Michael Sampson on Collaboration; 7 March 2011. [4 August 2011.].
[12] Jackson, J. SharePoint has its limits. ComputerWorld. 28 April 2010. [04 August 2011.].
[13] Hansch, D. Semantic MediaWiki performance tuning. SMW + forum. Ontoprise.com, 11 August 2011. http://smwforum.ontoprise.com/smwforum/index.php/Performance_Tuning.
[14] Bolser, D. BioWiki. BioInformatics.org, 1 April 2011. http://www.bioinformatics.org/wiki/BioWiki#tab=BioWiki_Table. [10 August 2011].
[15] Krötzsch, M. 'SPARQL and RDF stores for SMW'. SemanticMediaWiki.org, 2 August 2011. http://semantic-mediawiki.org/wiki/SPARQL_and_RDF_stores_for_SMW.
[16] Pabitha, P. Vignesh Nandha Kumar KR, Pandurangan N, Vijayakumar R and Rajaram M, 'Semantic Search in Wiki using HTML5 Microdata for Semantic Annotation'. I JCSI International Journal of Computer Science. 2011; 8(3):1.
[17] Lord, P. 'Linking genes to diseases with a SNPedia-Gene Wiki mashup'. Uduak Grace Thomas genomeweb; 5 August 2011. [By].
[18] Vrandecic, D., Ratnakar, V., Krotzsch, M., Gil, Y., 'Shortipedia: Aggregating and Curating Semantic Web Data. Semantic Web Challenge, 2010.
[19] Alquier L, Schultz T and Stephens S. 'Exploration of a Data Landscape using a Collaborative Linked Data Framework'. In Proceedings of The Future of the Web for Collaborative Science, WWW2010 (Raleigh, North Carolina, 26 April 2010).
[20] Alquier, L., 'Driving a Linked Data Framework with Semantic Wikis', Bio-IT World 2011, (Boston, Massachusetts, 12, April 2011.
[21] Agrafiotis, D.K., et al. Advanced biological and chemical discovery (ABCD): centralizing discovery knowledge in an inherently decentralized world'. Journal of Chemical Information and Modeling. 47(6), 2007. [1999–2014. Epub 2007 Nov 1.].
[22] Happel, H.-J., 'Social search and need-driven knowledge sharing in Wikis with Woogle. Proceedings of the 5th International Symposium on Wikis and Open Collaboration, 2009. [WikiSym 09].