
Unsupervised algorithms are not unique to neural networks, as K-means, expectation maximization, and methods of moments are also examples of unsupervised learning algorithms. One common feature of all learning algorithms is the absence of mapping among variables in the current dataset; instead, one wishes to find a different meaning of this data, and that's the goal of any unsupervised learning algorithm.
While in supervised learning algorithms, we usually have a smaller number of outputs, for unsupervised learning, there is a need to produce an abstract data representation that may require a high number of outputs, but, except for classification tasks, their meaning is totally different than the one presented in the supervised learning. Usually, each output neuron is responsible for representing a feature or a class present in the input data. In most architectures, not all output neurons need to be activated at a time; only a restricted set of output neurons may fire, meaning that that neuron is able to better represent most of the information being fed at the neural input.
In this chapter, we are going to explore two unsupervised learning algorithms: competitive learning and Kohonen self-organizing maps.
As the name implies, competitive learning handles a competition between the output neurons to determine which one is the winner. In competitive learning, the winning neuron is usually determined by comparing the weights against the inputs (they have the same dimensionality). To facilitate understanding, suppose we want to train a single layer neural network with two inputs and four outputs:

Every output neuron is then connected to these two inputs, hence for each neuron there are two weights.
The competition starts after the data has been processed by the neurons. The winner neuron will be the one whose weights are near to the input values. One additional difference compared to the supervised learning algorithm is that only the winner neuron may update their weights, while the other ones remain unchanged. This is the so-called winner-takes-all rule. This intention to bring the neuron nearer to the input that caused it to win the competition.
Considering that every input neuron i is connected to all output neurons j through a weight wij, in our case, we would have a set of weights:
Provided that the weights of every neuron have the same dimensionality of the input data, let's consider all the input data points together in a plot with the weights of each neuron:

In this chart, let's consider the circles as the data points and the squares as the neuron weights. We can see that some data points are closer to certain weights, while others are farther but nearer to others. The neural network performs computations on the distance on the inputs and the weights:
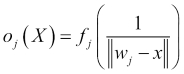
The result of this equation will determine how much stronger a neuron is against its competitors. The neuron whose weight distance to the input is the smaller is considered the winner. After many iterations, the weights are driven near enough to the data points that give more cause the corresponding neuron to win that the changes are either too small or the weights fall in a zig-zag setting. Finally, when the network is already trained, the chart takes another shape:

As can be seen, the neurons form centroids surrounding the points capable of making the corresponding neuron stronger than its competitors.
In an unsupervised neural network, the number of outputs is completely arbitrary. Sometimes only some neurons are able to change their weights, while in other cases, all the neurons may respond differently to the same input, causing the neural network to never learn. In these cases, it is recommended either to review the number of output neurons, or consider another type of unsupervised learning.
Two stopping conditions are preferable in competitive learning:
- Predefined number of epochs: This prevents our algorithm from running for a longer time without convergence
- Minimum value of weight update: Prevents the algorithm from running longer than necessary
This type of neural layer is particular, as the outputs won't be necessarily the same as its neuron's outputs. Only one neuron will be fired at a time, thereby requiring a special rule to calculate the outputs. So, let's create a new class called CompetitiveLayer that will inherit from OutputLayer and starting with two new attributes: winnerNeuron and winnerIndex:
public class CompetitiveLayer extends OutputLayer {
public Neuron winnerNeuron;
public int[] winnerIndex;
//…
}This new class of neural layer will override the method calc() and add some new particular methods to get the weights:
@Override
public void calc(){
if(input!=null && neuron!=null){
double[] result = new double[numberOfNeuronsInLayer];
for(int i=0;i<numberOfNeuronsInLayer;i++){
neuron.get(i).setInputs(this.input);
//perform the normal calculation
neuron.get(i).calc();
//calculate the distance and store in a vector
result[i]=getWeightDistance(i);
//sets all outputs to zero
try{
output.set(i,0.0);
}
catch(IndexOutOfBoundsException iobe){
output.add(0.0);
}
}
//determine the index and the neuron that was the winner
winnerIndex[0]=ArrayOperations.indexmin(result);
winnerNeuron=neuron.get(winnerIndex[0]);
// sets the output of this particular neuron to 1.0
output.set(winnerIndex[0], 1.0);
}
}In the next sections, we will define the class Kohonen for the Kohonen neural network. In this class, there will be an enum called distanceCalculation, which will have the different methods to calculate distance. In this chapter (and book), we'll stick to the Euclidian distance.
The distance between the weights of a particular neuron and the input is calculated by the method getWeightDistance( ), which is called inside the calc method:
public double getWeightDistance(int neuron){
double[] inputs = this.getInputs();
double[] weights = this.getNeuronWeights(neuron);
int n=this.numberOfInputs;
double result=0.0;
switch(distanceCalculation){
case EUCLIDIAN:
//for simplicity, let's consider only the euclidian distance
default:
for(int i=0;i<n;i++){
result+=Math.pow(inputs[i]-weights[i],2);
}
result=Math.sqrt(result);
}
return result;
}The method getNeuronWeights( ) returns the weights of the neuron corresponding to the index passed in the array. Since it is simple and to save space here, we invite the reader to see the code to check its implementation.