
One of the advanced features included in MySQL is replication. Using this feature, you can have multiple servers storing the same data. You might do this for performance reasons, for reliability, or for ease of backups. Additionally, you might choose to make use of replication simply to spread your database load across multiple servers you already own, instead of one (new) large server.
Replicating a database can provide fault tolerance. If your master server fails, a slave can be treated as a hot backup and immediately be turned into the master.
In a system in which most operations involve reading data, but not writing data, replication can improve performance by routing queries to a number of machines. You might be trying to reduce load by performing queries on lightly loaded machines, or you might be trying to reduce network transmissions by sending queries to a geographically nearby machine. If your database queries are mainly fairly simple, even a simple rotating load-balancing algorithm can spread the load effectively. If some of your queries require extensive processing, you will probably have to investigate more sophisticated application-level load balancing.
A related use of replication to assist performance is in making backups. As mentioned in Chapter 14, “Backup and Disaster Recovery,” backups can take a long time for a large database. Using replication, you can stop a slave and generate a backup of its data without affecting performance for other users.
Replication can take various forms. The MySQL implementation is a directional master-slave relationship. One server is called the master. One or more other servers are called slaves to a particular master. The master controls what data is stored in the system while the slaves try to mirror that content.
The replication process relies on the binary log on the master. This log stores details of every query executed on the server since logging was enabled. Slaves are sent queries from the master's binary log to apply to their own stored data.
You would generally perform all write operations directly on the master and share read operations among all the slaves or even the master and the slaves. This is usually achieved by designing this logic into your application.
It is important to note that if you are adding replication to an existing database with stored data, the binary log may be incomplete. Binary logging is not enabled by default, so the server may not have been logging when you began adding data to the system. To start replicating, you need all slaves to have the same data that the master had when binary logging began. We will look at this subject in more detail later in this chapter.
After being started with consistent data, the slaves connect to the master and apply any changes appearing in the master's binary log to their own data. A thread on the slave connects to a thread on the master and requests new events. These are stored in a relay log on the slave. A separate thread on the slave reads events from the local relay log and executes the queries on the local mirror of the data.
Because the master and slaves can start at different times (because new servers can be added to the system while queries are being performed and because network connections can fail or become a bottleneck), slaves need to be able to keep track of where they are in the log of updates to be performed. It is important that atomic transactions are honored and updates are performed in order. For most applications, as long as the database moves from one consistent state to another, it is less important if the data being read is a few seconds or minutes out of date.
If you are considering using replication, you need to understand how it works. Updates are asynchronous and do not happen in real time. Queries sent to different servers can give different results for some time after an update is made. This can be seen as a negative, but the positive side is that if you have a slave running on a portable device or an unreliable network, it will happily operate for long periods between updating data from the master.
Replication was added in a fairly recent version of MySQL (3.23.15). It is therefore a feature that still improves with nearly every version that is released. If you intend to use replication, it would be a good idea to be using an up-to-date version of MySQL on all machines.
It is possible to have some combinations of versions running in master-slave relationships together, but this adds an extra level of uncertainty and is best avoided where possible. You can run into problems in which functions, such as PASSWORD(), have changed between versions if you try to make different versions work together.
If you really need to have different versions on the same system, a matrix of combinations of master and slave versions that can work together is available in the documentation here:
Most replication systems use multiple machines on one internal network. If you are using machines connected via the public Internet, think carefully about the security implications. As a practical starting point, make sure that the port you are using for MySQL is accessible for any machines you need to connect through a firewall (3306 is the default port).
Assuming that you have a recent version of MySQL installed on your machines and one or more databases you want replicated, the following steps are required to set up a single master with one or more slaves.
It is good practice to create users with only the permissions that they need for their tasks, rather than using the root user for everything, as we discussed in Chapter 1, “Installing MySQL.” You therefore need a user for replication activity on the master server.
If you are going to populate your slaves initially by using LOAD TABLE FROM MASTER or LOAD DATA FROM MASTER, your replication user needs a special set of permissions. The following GRANT statement (run on the master) will create a user with the permissions required for the startup tools to connect:
grant replication slave, reload, super, select
on logs.*
to replication@"%" identified by 'password';
(Note that this example uses the logs database. You should change this to the name of your database, and obviously you should change the password to something more secure.)
After the initial copy from master to slave is complete, the replication user will not need so many permissions. If you are populating your slaves from a backup or reducing the user's permissions after the initial copying is complete, the user needs only the replication permission, so the following query will create a user named replication that can connect from any of the slave servers (and any other machines):
grant replication slave on logs.* to replication@"%" identified by 'password';
The syntax for GRANT queries was covered in Chapter 11, “Managing User Privileges.” The permission replication slave was added to MySQL 4.0.2 and is specifically for this purpose. For older versions of MySQL, use the permission file.
The query as shown will allow access only to the database named logs. If you want all databases on this machine to be able to be replicated, use *.* instead of logs.*.
Your master server needs to have binary logging enabled. If you have read the installation instructions in this book, you have hopefully already enabled it because it has other uses beyond replication. To check that it is on, you can run a SHOW VARIABLES query. You can simply type
show variables;
to get a complete list, but for concise output, type the following:
show variables like "log_bin";
If binary logging is off, add log-bin to your options file as shown in the example in Listing 1.1. The options file will be named my.ini or my.cnf, depending on which operating-system conventions you have followed.
Edit your my.ini/my.cnf file to give your master server a unique id. At a minimum, your options file should now look like this:
[mysqld]
log-bin
server-id=1
The server-id is a unique identifier for each of your MySQL servers. It must be a positive integer, but the choice of 1 here was completely arbitrary.
If you have edited your options file, you will need to restart the server for changes to take effect.
To start replication, you need three things:
• A complete, consistent snapshot of the current database
• The name of the master server's binary log file
• The offset into the binary log where the server is currently
Exactly how you grab these will vary a little depending on whether you are using MyISAM or InnoDB tables and how averse you are to stopping access to the database for a period.
For MyISAM tables, you can grab a snapshot after you start each slave. See the section “Start Slaves,” later in this chapter. This method is not very efficient, though, particularly if you have a large amount of data and many slaves. For each slave, the LOAD DATA FROM MASTER query will obtain a lock on the master's data and hold it until a complete copy has been transmitted. You can lock the databases for a much shorter time by making the snapshot manually via the file system. This will also allow you to use one snapshot to start as many slaves as required, reducing time when the server is locked.
For InnoDB tables, you do not have the option of running a LOAD DATA FROM MASTER query. You can make a file-system snapshot or buy the hot backup tool.
If you are making a file-system snapshot, you first need to make sure that the stored data is consistent and up-to-date by running the following query:
flush tables with read lock;
This will also lock the table, barring any writes until you unlock it.
You can get the current binary log file and offset from the following query:
show master status;
The output should look something like this:
You need to record the contents of the first column (the binary log file name) and the second column (the offset into the binary log). If these are empty, you will be using an empty string for the filename and 4 for the offset.
To create a snapshot of a MyISAM table, simply copy the directory that contains the data using an archiving program. On Unix, type something like this to get a snapshot of our logs database:
tar -cvf /tmp/snapshot.tar /path/mysql/data/logs
On Windows, use WinZip or a similar archiving tool to grab a copy of the directory C:mysqldatalogs.
After the copy is complete, you can re-enable write access to the database by typing this:
unlock tables;
The employee table we have been using throughout this book (like most tables the authors use on projects) is an InnoDB table. If you have purchased the (commercial) InnoDB hot backup tool, it is perfect for this task. It is available from Innobase Oy at
Without this tool, the safest approach is to flush and lock the database with the following queries. Use
flush tables with read lock;
and then display and record the binary log file and offset (as for MyISAM):
show master status;
Without unlocking the database, shut it down and make a copy of the directory that relates to that database inside your MySQL data directory. For InnoDB tables, you will also need to copy across the data files and logs. After the snapshot is complete, you can restart and unlock the database.
Each slave needs a unique server id. Edit your options file (my.cnf/my.ini) to add a line like this one to each:
server-id=2
The id must be a positive integer, but as long as no two are the same, it does not matter what you choose. If you are going to have more than a handful of servers running, an escalating sequence is probably your best hope of keeping them unique.
If you are working from a file-system snapshot, you need to copy the files into the appropriate places on the slave server. If you are working with more than one operating system, remember to consider filename capitalization.
Editing your options file or copying across InnoDB files will require you to restart your slave server.
To start a slave that was set up as described here, you will need to run the following queries:
change master to master_host='server',
master_user='replication',
master_password='password',
master_log_file='server-bin.000007',
master_log_pos=211;
start slave;
In this example, the word server is the hostname of the master server. The word replication is the username of the user we created to do the replication tasks. That user's password should go in place of password. The binary log file name and offset fill out the parameters required.
The START SLAVE query launches the slave's replication threads, causing it to try to connect to the master and collect updates.
If you have copied a snapshot via the file system, you should be able to run some matching queries against the master and slave to check that the replication is working correctly. Make a small update to the master and check that it is mirrored on the slave.
If the tables you are replicating are relatively small MyISAM tables, you can create and populate them via a query like
load table logs.logJan2003 from master;
to copy a single table or
load data from master;
to copy all tables onto this slave.
After you have replication working, entering queries manually to configure replication is not practical, even if you restart only occasionally. The same information can go in your options file with a slightly different syntax.
Your slave's my.ini or my.cnf file could look something like this:
[mysqld]
server-id = 2
master-host = server
master-user = replication
master-password = password
replicate-do-db = logs
The most common use for replication is load balancing in a system in which there are large numbers of reads and a relatively small number of writes. Most replication setups involve a single master and a small number of slaves, but in some situations, more complicated installations are justified.
If you plan a large number of slaves or have machines spread over many locations, it might make sense to have a cascading system in which one server acts as master for some of your slaves. One or more of the slaves then acts as a master for a further set of slaves. Figure 16.1 shows a single master (machine number 1) acting as a master to machines 2 though 6. Some of these slaves, in turn, act as masters to other sets of slaves.
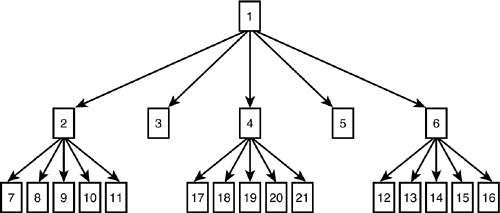
An arrangement like this saves load on the main master server and reduces network traffic on the links that lead to that machine. Depending on the ratio of reads to writes in your application, this can provide a great deal of scalability without much complexity.
It is fairly straightforward to have any number of slaves and even to have multiple masters, as long as each machine is a master in one relationship and a slave in another. As long as you build your application knowing that there will be times when some servers are missing recent updates, you can treat the system much like you would a single database server.
Things get more complicated when you have a circular relationship in which multiple servers are accepting write queries and updates are being replicated in more than one direction. The simplest circular relationship is a pair of machines, both acting as masters and both acting as slaves. Changes can be made to either machine and replicated to the other. You need to be very careful when writing an application for this sort of system.
Because changes are applied asynchronously, you can end up with conflicting auto increment fields, clashing unique ids, and inconsistent data. In some applications, this arrangement may work well. For instance, a data logging application with few relationships between tables that requires high throughput and availability may be willing to sacrifice consistency.
The current replication features are very robust. The features are bundled in the standard distribution (unlike most commercial databases) and have been used extensively in high-volume environments. Users you will have heard of include Slashdot, Yahoo!, and Google.
Having said that, the features are still relatively new, and there are some rough edges. As you have already seen, the process for setting up a new slave with a snapshot is not very user-friendly. The treatment of MyISAM tables and InnoDB tables is not consistent.
In general, you need to approach replication with a degree of care. The feature works and works well, but can be tricky to initially set up because different systems and setups vary. We generally recommend that you use the newest available versions of MySQL.
Some of these problems will be solved when MyISAM gets a hot backup tool like InnoDB's. Other features planned for future MySQL versions include multimastering—the capability of a slave to mirror two masters and resolve conflicts—and built-in failover and load-balancing features. Currently, you need to handle failover and load balancing in your application or buy a third-party clustering tool, such as Emic Application Cluster from www.emicnetworks.com.
There are some replication-related settings in the options file that are currently unimplemented. These include options for setting up SSL connections between slaves and masters. If your replication is done over a public network, this will make operating securely easier. Currently, if you want to make secure connections, you need to use another product, such as Stunnel.
• Replication is not suitable for all occasions, but if you have a busy application with a high read-to-write ratio, it can be an excellent scaling tool.
• Remember that updates are not applied to slaves in real time. Each copy of a table should move from one consistent state to another, but reads from different servers may give dated results while a slave updates.
• The most useful replication-related queries are START SLAVE, LOAD TABLE name FROM MASTER, LOAD DATA FROM MASTER, SHOW MASTER STATUS, SHOW SLAVE STATUS, and SHOW SLAVE HOSTS.