
In this chapter we will review the basic principles of database design and normalization. A well-designed database minimizes redundancy without losing any data. That is, we aim to use the least amount of storage space for our database while still maintaining all links between data.
We will cover the following:
• Database concepts and terminology
• Database design principles
• Normalization and the normal forms
• Database design exercises
To understand the principles we will look at in this chapter, we need to establish some basic concepts and terminology.
The very basics of what we are trying to model are entities and relationships. Entities are the things in the real world that we will store information about in the database. For example, we might choose to store information about employees and the departments they work for. In this case, an employee would be one entity and a department would be another. Relationships are the links between these entities. For example, an employee works for a department. Works-for is the relationship between the employee and department entities.
Relationships come in different degrees. They can be one-to-one, one-to-many (or many-to-one depending on the direction you are looking at it from), or many-to-many. A one-to-one relationship connects exactly two entities. If employees in this organization had a cubicle each, this would be a one-to-one relationship. The works-for relationship is usually a many-to-one relationship in this example. That is, many employees work for a single department, but each employee works for only one department. These two relationships are shown in Figure 3.1.
Figure 3.1. The is-located-in relationship is one-to-one. The works-for relationship is many-to-one.

Note that the entities, the relationships, and the degree of the relationships depend on your environment and the business rules you are trying to model. For example, in some companies, employees may work for more than one department. In that case, the works-for relationship would be many-to-many. If anybody shares a cubicle or anybody has an office instead, the is-located-in relationship is not one-to-one.
When you are coming up with a database design, you must take these rules into account for the system you are modeling. No two systems will be exactly the same.
MySQL is a relational database management system (RDBMS)—that is, it supports databases that consist of a set of relations. A relation in this sense is not your auntie, but a table of data. Note that the terms table and relation mean the same thing. In this book, we will use the more common term table. If you have ever used a spreadsheet, each sheet is typically a table of data. A sample table is shown in Figure 3.2.
Figure 3.2. The employee table stores employee IDs, names, jobs, and the department each employee works for.

As you can see, this particular table holds data about employees at a particular company. (We have not shown data for all the employees, just some examples.)
In database tables, each column or attribute describes some piece of data that each record in the table has. The terms column and attribute are used fairly interchangeably, but a column is really part of a table, whereas an attribute relates to the real-world entity that the table is modeling. In Figure 3.2 you can see that each employee has an employeeID, a name, a job, and a departmentID. These are the columns of the employee table, sometimes also called the attributes of the employee table.
Look again at the employee table. Each row in the table represents a single employee record. You may hear these called rows, records, or tuples. Each row in the table consists of a value for each column in the table.
A superkey is a column (or set of columns) that can be used to identify a row in a table. A key is a minimal superkey. For example, look at the employee table. We could use the employeeID and the name together to identify any row in the table. We could also use the set of all the columns (employeeID, name, job, departmentID). These are both superkeys.
However, we don't need all those columns to identify a row. We need only (for example) the employeeID. This is a minimal superkey—that is, a minimized set of columns that can be used to identify a single row. So, employeeID is a key.
Look at the employee table again. We could identify an employee by name or by employeeID. These are both keys. We call these candidate keys because they are candidates from which we will choose the primary key. The primary key is the column or set of columns that we will use to identify a single row from within a table. In this case we will make employeeID the primary key. This will make a better key than name because it is common to have two people with the same name.
Foreign keys represent the links between tables. For example, if you look back at Figure 3.2, you can see that the departmentID column holds a department number. This is a foreign key: The full set of information about each department will be held in a separate table, with the departmentID as the primary key in that table.
The term functional dependency comes up less often than the ones previously mentioned, but we will need to understand it to understand the normalization process that we will discuss in a minute.
If there is a functional dependency between column A and column B in a given table, which may be written A → B, then the value of column A determines the value of column B. For example, in the employee table, the employeeID functionally determines the name (and all the other attributes in this particular example).
The term schema or database schema simply means the structure or design of the database—that is, the form of the database without any data in it. If you like, the schema is a blueprint for the data in the database.
We can describe the schema for a single table in the following way:
employee(employeeID, name, job, departmentID)
In this book, we will follow the convention of using a solid underline for the attributes that represent the primary key and a broken underline for any attributes that represent foreign keys. Primary keys that are also foreign keys will have both a solid and a broken underline.
When we design a database, we need to take two important things into account:
• What information needs to be stored? That is, what things or entities do we need to store information about?
• What questions will we ask of the database? (These are called queries.)
When thinking about these questions, we must bear in mind the business rules of the business we are trying to model—that is, what the things are that we need to store data about and what specifically the links are between them.
Along with these questions, we need to structure our database in such a way that it avoids structural problems such as redundancy and data anomalies.
When designing our schema, we want to do so in such a way that we minimize redundancy of data without losing any data. By redundancy, I mean data that is repeated in different rows of a table or in different tables in the database.
Imagine that rather than having an employee table and a department table, we have a single table called employeeDepartment. We can accomplish this by adding a single departmentName column to the employee table so that the schema looks like this:
employeeDepartment(employeeID, name, job, departmentID, departmentName)
For each employee who works in the Department with the number 128, Research and Development, we will repeat the data “128, Research and Development,” as shown in Figure 3.3. This will be the same for each department in the company.

We can change this design as shown here:
employee(employeeID, name, job, departmentID)
department(departmentID, name)
In this case, each department name is stored in the database only once, rather than many times, minimizing storage space and avoiding some problems.
Note that we must leave the departmentID in the employee table; otherwise, we lose information from the schema, and in this case, we would lose the link between an employee and the department the employee works for. In improving the schema, we must always bear these twin goals in mind—that is, reducing repetition of data without losing any information.
Anomalies present a slightly more complex concept. Anomalies are problems that arise in the data due to a flaw in the database design. There are three types of anomalies that may arise, and we will consider how they occur with the flawed schema shown in Figure 3.3.
Insertion anomalies occur when we try to insert data into a flawed table. Imagine that we have a new employee starting at the company. When we insert the employee's details into the employeeDepartment table, we must insert both his department id and his department name. What happens if we insert data that does not match what is already in the table, for example, by entering an employee as working for Department 42, Development? It will not be obvious which of the rows in the database is correct. This is an insertion anomaly.
Deletion anomalies occur when we delete data from a flawed schema. Imagine that all the employees of Department 128 leave on the same day (walking out in disgust, perhaps). When we delete these employee records, we no longer have any record that Department 128 exists or what its name is. This is a deletion anomaly.
Update anomalies occur when we change data in a flawed schema. Imagine that Department 128 decides to change its name to Emerging Technologies. We must change this data for every employee who works for this department. We might easily miss one. If we do miss one (or more), this is an update anomaly.
A final rule for good database design is that we should avoid schema designs that have large numbers of empty attributes. For example, if we want to note that one in every hundred or so of our employees has some special qualification, we would not add a column to the employee table to store this information because for 99 employees, this would be NULL. We would instead add a new table storing only employeeIDs and qualifications for those employees who have those qualifications.
Normalization is a process we can use to remove design flaws from a database. In normalization, we describe a number of normal forms, which are sets of rules describing what we should and should not do in our table structures. The normalization process consists of breaking tables into smaller tables that form a better design.
To follow the normalization process, we take our database design through the different forms in order. Generally, each form subsumes the one below it. For example, for a database schema to be in second normal form, it must also be in first normal form. For a schema to be in third normal form, it must be in second normal form and so on. At each stage, we add more rules that the schema must satisfy.
The first normal form, sometimes called 1NF, states that each attribute or column value must be atomic. That is, each attribute must contain a single value, not a set of values or another database row.
Consider the table shown in Figure 3.4.
Figure 3.4. This schema design is not in first normal form because it contains sets of values in the skill column.

This is an unnormalized version of the employee table we looked at earlier. As you can see, it has one extra column, called skill, which lists the skills of each employee.
Each value in this column contains a set of values—that is, rather than containing an atomic value such as Java, it contains a list of values such as C, Perl, Java. This violates the rules of first normal form.
To put this schema in first normal form, we need to turn the values in the skill column into atomic values. There are a couple of ways we can do this. The first, and perhaps most obvious, way is shown in Figure 3.5.
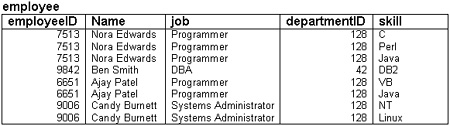
Here we have made one row per skill. This schema is now in first normal form.
Obviously, this arrangement is far from ideal because we have a great deal of redundancy—for each skill-employee combination, we store all the employee details.
A better solution, and the right way to put this data into first normal form, is shown in Figure 3.6.

In this example, we have split the skills off to form a separate table that only links employee ids and individual skills. This gets rid of the redundancy problem.
You might ask how we would know to arrive at the second solution. There are two answers. One is experience. The second is that if we take the schema in Figure 3.5 and continue with the normalization process, we will end up with the schema in Figure 3.6. The benefit of experience allows us to look ahead and just go straight to this design, but it is perfectly valid to continue with the process.
After we have a schema in first normal form, we can move to the higher forms, which are slightly harder to understand.
A schema is said to be in second normal form (also called 2NF) if all attributes that are not part of the primary key are fully functionally dependent on the primary key, and the schema is already in first normal form. What does this mean? It means that each non-key attribute must be functionally dependent on all parts of the key. That is, if the primary key is made up of multiple columns, every other attribute in the table must be dependent on the combination of these columns.
Let's look at an example to try to make things clearer.
Look at Figure 3.5. This is the schema that has one line in the employee table per skill. This table is in first normal form, but it is not in second normal form. Why not?
What is the primary key for this table? We know that the primary key must uniquely identify a single row in a table. In this case, the only way we can do this is by using the combination of the employeeID and the skill. With the skills set up in this way, the employeeID is not enough to uniquely identify a row—for example, the employeeID 7513 identifies three rows. However, the combination of employeeID and skill will identify a single row, so we use these two together as our primary key. This gives us the following schema:
employee(employeeID, name, job,
![]() , skill)
, skill)
We must next ask ourselves, “What are the functional dependencies here?” We have employeeID, skill → name, job, departmentID
but we also have
employeeID → name, job, departmentID
In other words, we can determine the name, job, and departmentID from the employeeID alone. This means that these attributes are partially functionally dependent on the primary key, rather than fully functionally dependent on the primary key. That is, you can determine these attributes from a part of the primary key without needing the whole primary key. Hence, this schema is not in second normal form.
The next question is, “How can we put it into second normal form?”
We need to decompose the table into tables in which all the non-key attributes are fully functionally dependent on the key. It is fairly obvious that we can achieve this by breaking the table into two tables, to wit:
employee(employeeID, name, job,
![]() )
)
employeeSkills(
![]() , skill)
, skill)
This is the schema that we had back in Figure 3.6.
As already discussed, this schema is in first normal form because the values are all atomic. It is also in second normal form because each non-key attribute is now functionally dependent on all parts of the keys.
You may sometimes hear the saying “Normalization is about the key, the whole key, and nothing but the key.” Second normal form tells us that attributes must depend on the whole key. Third normal form tells us that attributes must depend on nothing but the key.
Formally, for a schema to be in third normal form (3NF), we must remove all transitive dependencies, and the schema must already be in second normal form. Okay, so what's a transitive dependency?
Look back at Figure 3.3. This has the following schema:
employeeDepartment(employeeID, name, job, departmentID, departmentName)
This schema contains the following functional dependencies:
employeeID → name, job, departmentID, departmentName
departmentID → departmentName
The primary key is employeeID, and all the attributes are fully functionally dependent on it—this is easy to see because there is only one attribute in the primary key!
However, we can see that we have
employeeID → departmentName
employeeID → departmentID
and
departmentID → departmentName
Note also that the attribute departmentID is not a key.
This relationship means that the functional dependency employeeID → departmentName is a transitive dependency. Effectively, it has a middle step (the departmentID → departmentName dependency).
To get to third normal form, we need to remove this transitive dependency.
As with the previous normal forms, to convert to third normal form we decompose this table into multiple tables. Again, in this case, it is pretty obvious what we should do. We convert the schema to two tables, employee and department, like this:
employee(employeeID, name, job,
![]() )
)
department(departmentID, departmentName)
This brings us back to the schema for employee that we had in Figure 3.2 to begin with. It is in third normal form.
Another way of describing third normal form is to say that formally, if a schema is in third normal form, then for every functional dependency in every table, either
• The left side of the functional dependency is a superkey (that is, a key that is not necessarily minimal).
or
• The right side of the functional dependency is part of any key of that table.
The second part doesn't come up terribly often! In most cases, all the functional dependencies will be covered by the first rule.
The final normal form we will consider—briefly—is Boyce-Codd normal form, sometimes called BCNF. This is a variation on third normal form. We looked at two rules previously. For a relation to be in BCNF, it must be in third normal form and come under the first of the two rules. That is, all the functional dependencies must have a superkey on the left side.
This is most frequently the case without our having to take any extra steps, as in this example. If we have a dependency that breaks this rule, we must again decompose as we did to get into 1NF, 2NF, and 3NF.
To round up, here's what we covered in this chapter.
• Entities are things, and relationships are the links between them.
• Relations or tables hold a set of data in tabular form.
• Columns belonging to tables describe the attributes that each data item possesses.
• Rows in tables hold data items with values for each column in a table.
• Keys are used to identify a single row.
• Functional dependencies identify which attributes determine the values of other attributes.
• Schemas are the blueprints for a database.
• Minimize redundancy without losing data.
• Insertion, deletion, and update anomalies are problems that occur when trying to insert, delete, or update data in a table with a flawed structure.
• Avoid designs that will lead to large quantities of null values.
• Normalization is a formal process for improving database design.
• First normal form (1NF) means atomic column or attribute values.
• Second normal form (2NF) means that all attributes outside the key must depend on the whole key.
• Third normal form (3NF) means no transitive dependencies.
• Boyce-Codd normal form (BCNF) means that all attributes must be functionally determined by a superkey.
In Chapter 4, “Creating Databases, Tables, and Indexes,” we will take a database schema and turn it into an actual MySQL database.