
Chapter 10
A Lightweight Dynamic Optimization Methodology for Embedded Wireless Sensor Networks*
Advancements in semiconductor technology, as predicted by Moore's law, have enabled high transistor density in a small chip area resulting in the miniaturization of embedded systems (e.g., embedded sensor nodes). Embedded wireless sensor networks (EWSNs) are envisioned as distributed computing systems, which are proliferating in many application domains (e.g., defense, health care, surveillance systems), each with varying application requirements that can be defined by high-level application metrics (e.g., lifetime, reliability). However, the diversity of EWSN application domains makes it difficult for commercial off-the-shelf (COTS) embedded sensor nodes to meet these application requirements.
Since COTS embedded sensor nodes are mass-produced to optimize cost, many COTS embedded sensor nodes possess tunable parameters (e.g., processor voltage and frequency, sensing frequency), whose values can be tuned for application specialization [69]. The EWSN application designers (those who design, manage, or deploy the EWSN for an application) are typically biologists, teachers, farmers, and household consumers that are experts within their application domain, but have limited technical expertise. Given the large design space and operating constraints, determining appropriate parameter values (operating state) can be a daunting and/or time-consuming task for nonexpert application managers. Typically, embedded sensor node vendors assign initial generic tunable parameter value settings; however, no one tunable parameter value setting is appropriate for all applications. To assist the EWSN managers with parameter tuning to best fit the application requirements, an automated parameter tuning process is required.
Parameter optimization is the process of assigning appropriate (optimal or near-optimal) tunable parameter value settings to meet application requirements. Parameter optimizations can be static or dynamic. Static optimizations assign parameter values at deployment, and these values remain fixed for the lifetime of the sensor node. One of the challenges associated with static optimizations is accurately determining the tunable parameter value settings using environmental stimuli prediction/simulation. Furthermore, static optimizations are not appropriate for applications with varying environmental stimuli. Alternatively, dynamic optimizations assign (and reassign/change) parameter values during runtime enabling the sensor node to adapt to changing environmental stimuli, and thus more accurately meet application requirements.
EWSN dynamic optimizations present additional challenges as compared to traditional processor or memory (cache) dynamic optimizations because sensor nodes have more tunable parameters and a larger design space. The dynamic profiling and optimization (DPOP) project aims to address these challenges and complexities associated with sensor-based system design through the use of automated optimization methods [321]. The DPOP project has gathered dynamic profiling statistics from a sensor-based system; however, the parameter optimization process has not been addressed.
In this chapter, we investigate parameter optimization using dynamic profiling data already collected from the platform. We analyze several dynamic optimization methods and evaluate algorithms that provide a good operating state without significantly depleting the battery energy. We explore a large design space with many tunable parameters and values, which provide a fine-grained design space, enabling embedded sensor nodes to more closely meet application requirements as compared to smaller, more course-grained design spaces. Gordon-Ross et al. [329] showed that finer-grained design spaces contain interesting design alternatives and result in increased benefits in the cache subsystem (though similar trends follow for other subsystems). However, the large design space exacerbates optimization challenges, taking into consideration an embedded sensor node's constrained memory and computational resources. Considering the embedded sensor node's limited battery life, energy-efficient computing is always of paramount significance. Therefore, optimization algorithms that conserve energy by minimizing design space exploration to find a good operating state are critical, especially for large design spaces and highly constrained systems. Additionally, rapidly changing application requirements and environmental stimuli coupled with limited battery reserves necessitates a highly responsive and low overhead methodology.
Our main contributions in this chapter are as follows:
- We propose a lightweight dynamic optimization methodology that intelligently selects appropriate initial tunable parameter value settings by evaluating application requirements, the relative importance of these requirements with respect to each other, and the magnitude in which each parameter effects each requirement. This one-shot operating state obtained from appropriate initial parameter value settings provides a high-quality operating state with minimal design space exploration for highly constrained applications. Results reveal that the one-shot operating state is within 8% of the optimal operating state averaged over several different application domains and design spaces.
- We present a dynamic optimization methodology to iteratively improve the one-shot operating state to provide an optimal or near-optimal operating state for less constrained applications. Our dynamic optimization methodology combines the initial tunable parameter value settings with an intelligent exploration ordering of tunable parameter values and an exploration arrangement of tunable parameters (since some parameters are more critical for an application than others and thus should be explored first [330] (e.g., the transmission power parameter may be more critical for a lifetime-sensitive application than for processor voltage)).
- We architect a lightweight online greedy algorithm that leverages intelligent parameter arrangement to iteratively explore the design space, resulting in an operating state within 2% of the optimal operating state while exploring only 0.04% of the design space.
This work has a broad impact on EWSN design and deployment. Our work enables nonexpert application managers to leverage our dynamic optimization methodology to automatically tailor the embedded sensor node tunable parameters to best meet the application requirements with little design time effort. Our proposed methodology is suitable for all EWSN applications ranging from highly constrained to highly flexible applications. The one-shot operating state provides a good operating state for highly constrained applications, whereas greedy exploration of the parameters provides improvement over the one-shot operating state to determine a high-quality operating state for less constrained applications. Our initial parameter value settings, parameter arrangement, and exploration ordering techniques are also applicable to other systems or application domains (e.g., cache tuning) with different application requirements and different tunable parameters.
The remainder of this chapter is organized as follows. Section 10.1 overviews the related work. Section 10.2 presents our dynamic optimization methodology along with the state space and objective function formulation. We describe our dynamic optimization methodology's steps and algorithms in Section 10.3. Experimental results are presented in Section 10.4. Finally, Section 10.5 concludes the chapter.
10.1 Related Work
There exists much research in the area of dynamic optimizations [186–188, 330], but most previous work targets the processor or memory (cache) in computer systems. There exists little previous work on EWSN dynamic optimization, which presents more challenges given a unique design space, design constraints, platform particulars, and external influences from the EWSN's operating environment.
In the area of DPOP, Sridharan and Lysecky [300] dynamically profiled an EWSN's operating environment to gather profiling statistics; however, they did not describe a methodology to leverage these profiling statistics for dynamic optimization. Shenoy et al. [331] investigated profiling methods for dynamically monitoring sensor-based platforms with respect to network traffic and energy consumption, but did not explore dynamic optimizations. In prior work, Munir and Gordon-Ross [23, 69] proposed a Markov decision process (MDP)-based methodology for optimal sensor node parameter tuning to meet application requirements as a first step toward EWSN dynamic optimization. The MDP-based methodology required high computational and memory resources for large design spaces and needed a high-performance base station node (sink node) to compute the optimal operating state for large design spaces. The operating states determined at the base station were then communicated to the other sensor nodes. The high resource requirements made the MDP-based methodology infeasible for autonomous dynamic optimization for large design spaces given the constrained resources of individual sensor nodes. Kogekar et al. [227] proposed dynamic software reconfiguration to adapt software to new operating conditions; however, their work did not consider sensor node tunable parameters and application requirements. Verma [311] investigated simulated annealing (SA) and particle swarm optimization (PSO)-based parameter tuning for EWSNs and observed that SA performed better than PSO because PSO often quickly converged to local minima. Although there exists work on optimization of EWSNs, our work uses multiobjective optimization and fine-grained design space to find optimal (or near-optimal) sensor node operating states that meet application requirements.
One of the prominent dynamic optimization techniques for reducing energy consumption is dynamic voltage and frequency scaling (DVFS). Several previous works explored DVFS in EWSNs. Min et al. [225] utilized a voltage scheduler, running in tandem with the operating system's task scheduler, to perform DVFS based on an a priori prediction of the sensor node's workload and resulted in a 60% reduction in energy consumption. Similarly, Yuan and Qu [226] used additional transmitted data packet information to select appropriate processor voltage and frequency values. Although DVFS is a method for dynamic optimization, DVFS considers only two sensor node tunable parameters (processor voltage and frequency). In this chapter, we expand the embedded sensor node parameter tuning space, which provides a finer-grained design space, enabling embedded sensor nodes to more closely meet application requirements.
Some dynamic optimization work utilized dynamic power management for energy conservation in EWSNs. Wang et al. [332] proposed a strategy for optimizing mobile sensor node placement to meet coverage and energy requirements. Their strategy utilized dynamic power management to optimize the sensor nodes' sleep state transitions for energy conservation. Ning and Cassandras [333] presented a link layer dynamic optimization approach for energy conservation in EWSNs by minimizing the idle listening time. Their approach utilized traffic statistics to optimally control the receiver sleep interval. In our work, we incorporate energy conservation by switching the sensors, processors, and transceivers to low power, idle modes when these components are not actively sensing, processing, and communicating, respectively.
Although there exists work on EWSN optimizations, dynamic optimization requires further research. Specifically, there is a need for lightweight dynamic optimization methodologies for sensor node parameter tuning considering a sensor node's limited energy and storage. Furthermore, sensor node tunable parameter arrangement and exploration order require further investigation. Our work provides contribution to the dynamic optimization of EWSNs by proposing a lightweight dynamic optimization methodology for EWSNs in addition to a sensor node's tunable parameter arrangement and exploration order techniques.
10.2 Dynamic Optimization Methodology
In this section, we give an overview of our dynamic optimization methodology along with the state space and objective function formulation for the methodology.
10.2.1 Overview
Figure 10.1 depicts our dynamic optimization methodology for distributed EWSNs. EWSN designers evaluate application requirements and capture these requirements as high-level application metrics (e.g., lifetime, throughput, reliability) and associated weight factors. The weight factors signify the weightage/importance of application metrics with respect to each other. The sensor nodes use application metrics and weight factors to determine an appropriate operating state (tunable parameter value settings) by leveraging an application metrics estimation model. The application metrics estimation model (elaborated in Chapter 3) estimates high-level application metrics from low-level sensor node parameters and sensor node hardware-specific internals.

Figure 10.1 A lightweight dynamic optimization methodology per sensor node for EWSNs
Figure 10.1 shows the per sensor node dynamic optimization process (encompassed by the dashed circle), which is orchestrated by the dynamic optimization controller. The process consists of two operating modes: the one-shot mode wherein the sensor node operating state is directly determined by initial parameter value settings and the improvement mode wherein the operating state is iteratively improved using an online optimization algorithm. The dynamic optimization process consists of three steps. In the first step corresponding to the one-shot mode, the dynamic optimization controller intelligently determines the initial parameter value settings (operating state) and exploration order (ascending or descending), which is critical in reducing the number of states explored in the third step. In the one-shot mode, the dynamic optimization process is complete and the sensor node transitions directly to the operating state specified by the initial parameter value settings. The second step corresponds to the improvement mode, which determines the parameter arrangement based on application metric weight factors (e.g., explore processor voltage, frequency, and then sensing frequency). This parameter arrangement reduces the design space exploration time using an optimization algorithm in the third step to determine a good quality operating state. The third step corresponds to the improvement mode and invokes an online optimization algorithm for parameter exploration to iteratively improve the operating state to more closely meet application requirements as compared to the one-shot's operating state. The online optimization algorithm leverages the intelligent initial parameter value settings, exploration order, and parameter arrangement.
A dynamic profiler records profiling statistics (e.g., processor voltage, wireless channel condition, radio transmission power) given the current operating state and environmental stimuli and passes these profiling statistics to the dynamic optimization controller. The dynamic optimization controller processes the profiling statistics to determine whether the current operating state meets the application requirements. If the application requirements are not met, the dynamic optimization controller reinvokes the dynamic optimization process to determine a new operating state. This feedback process continues to ensure that the application requirements are best met under changing environmental stimuli. We point out that our current work describes the dynamic optimization methodology; however, incorporation of profiling statistics to provide feedback is part of our future work.
10.2.2 State Space
The state space ![]() for our dynamic optimization methodology given
for our dynamic optimization methodology given ![]() tunable parameters is defined as
tunable parameters is defined as
where ![]() denotes the state space for tunable parameter
denotes the state space for tunable parameter ![]() and
and ![]() denotes the Cartesian product. Each tunable parameter's state space
denotes the Cartesian product. Each tunable parameter's state space ![]() consists of
consists of ![]() values
values
where ![]() denotes the tunable parameter
denotes the tunable parameter ![]() 's state space cardinality (the number of tunable values in
's state space cardinality (the number of tunable values in ![]() ).
). ![]() is a set of
is a set of ![]() -tuples formed by taking one tunable parameter value from each tunable parameter. A single
-tuples formed by taking one tunable parameter value from each tunable parameter. A single ![]() -tuple
-tuple ![]() is given as
is given as
Each ![]() -tuple represents a sensor note operating state. We point out that some
-tuple represents a sensor note operating state. We point out that some ![]() -tuples in
-tuples in ![]() may not be feasible (such as invalid combinations of processor voltage and frequency) and can be regarded as do not care tuples.
may not be feasible (such as invalid combinations of processor voltage and frequency) and can be regarded as do not care tuples.
10.2.3 Optimization Objection Function
The sensor node dynamic optimization problem can be formulated as
where ![]() represents the objective function and captures application metrics and weight factors and is given as
represents the objective function and captures application metrics and weight factors and is given as

where ![]() and
and ![]() denote the objective function and weight factor for the
denote the objective function and weight factor for the ![]() application metric, respectively, given that there are
application metric, respectively, given that there are ![]() application metrics.
application metrics.
For our dynamic optimization methodology, we consider three application metrics (![]() ): lifetime, throughput, and reliability, whose objective functions are represented by
): lifetime, throughput, and reliability, whose objective functions are represented by ![]() ,
, ![]() , and
, and ![]() , respectively. We define
, respectively. We define ![]() (Fig. 10.2) using the piecewise linear function
(Fig. 10.2) using the piecewise linear function

where ![]() denotes the lifetime offered by state
denotes the lifetime offered by state ![]() , the constant parameters
, the constant parameters ![]() and
and ![]() denote the desired minimum and maximum lifetime, and the constant parameters
denote the desired minimum and maximum lifetime, and the constant parameters ![]() and
and ![]() denote the acceptable minimum and maximum lifetime. The piecewise linear objective function provides EWSN designers with a flexible application requirement specification, as it allows both desirable and acceptable ranges [310]. The objective function reward gradient (slope) would be greater in the desired range than the acceptable range; however, there would be no reward/gain for operating outside the acceptable range. The constant parameters
denote the acceptable minimum and maximum lifetime. The piecewise linear objective function provides EWSN designers with a flexible application requirement specification, as it allows both desirable and acceptable ranges [310]. The objective function reward gradient (slope) would be greater in the desired range than the acceptable range; however, there would be no reward/gain for operating outside the acceptable range. The constant parameters ![]() ,
, ![]() , and
, and ![]() in Eq. (10.6) denote the
in Eq. (10.6) denote the ![]() value at
value at ![]() ,
, ![]() , and
, and ![]() , respectively (constant parameters are assigned by the EWSN designer based on the minimum and maximum acceptable/desired values of application metrics). The
, respectively (constant parameters are assigned by the EWSN designer based on the minimum and maximum acceptable/desired values of application metrics). The ![]() and
and ![]() can be defined similar to Eq. (10.6).
can be defined similar to Eq. (10.6).

Figure 10.2 Lifetime objective function 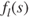
The objective function characterization enables the reward/gain calculation from operating in a given state based on the high-level metric values offered by the state. Although different characterization of objective functions results in different reward values from different states, our dynamic optimization methodology selects a high-quality operating state from the design space to maximize the given objective function value. We consider piecewise linear objective functions as a typical example from the possible objective functions (e.g., linear, piecewise linear, nonlinear) to illustrate our dynamic optimization methodology, though other characterizations of objective functions work equally well for our methodology.
10.3 Algorithms for Dynamic Optimization Methodology
In this section, we describe our dynamic optimization methodology's three steps (Fig. 10.1) and associated algorithms.
10.3.1 Initial Tunable Parameter Value Settings and Exploration Order
The first step of our dynamic optimization methodology determines initial tunable parameter value settings and exploration order (ascending or descending). These initial tunable parameter value settings results in a high-quality operating state in one-shot, hence the name one-shot mode (Fig. 10.1). The algorithm calculates the application metric objective function values for the first and last values in the set of tunable values for each tunable parameter while other tunable parameters are set to an arbitrary initial setting (either first or last value). We point out that the tunable values for a tunable parameter can be arranged in an ascending order (e.g., for processor voltage ![]() (V)). This objective function values calculation determines the effectiveness of setting a particular tunable parameter value in meeting the desired objective (e.g., lifetime). The tunable parameter setting that gives a higher objective function value is selected as the initial parameter value for that tunable parameter. The exploration order for that tunable parameter is set to descending if the last value in the set of tunable values (e.g.,
(V)). This objective function values calculation determines the effectiveness of setting a particular tunable parameter value in meeting the desired objective (e.g., lifetime). The tunable parameter setting that gives a higher objective function value is selected as the initial parameter value for that tunable parameter. The exploration order for that tunable parameter is set to descending if the last value in the set of tunable values (e.g., ![]() in our previous example) gives a higher objective function value or ascending otherwise. This exploration order selection helps in reducing design space exploration for a greedy-based optimization algorithm (step 3), which stops exploring a tunable parameter as soon as a tunable parameter setting gives a lower objective function value than the initial setting. This initial parameter value setting and exploration order determination procedure are then repeated for all other tunable parameters and application metrics.
in our previous example) gives a higher objective function value or ascending otherwise. This exploration order selection helps in reducing design space exploration for a greedy-based optimization algorithm (step 3), which stops exploring a tunable parameter as soon as a tunable parameter setting gives a lower objective function value than the initial setting. This initial parameter value setting and exploration order determination procedure are then repeated for all other tunable parameters and application metrics.
Algorithm 6 describes our technique to determine initial tunable parameter value settings and exploration order (first step of our dynamic optimization methodology). The algorithm takes as input the objective function ![]() , the number of tunable parameters
, the number of tunable parameters ![]() , the number of values for each tunable parameter
, the number of values for each tunable parameter ![]() , the number of application metrics
, the number of application metrics ![]() , and
, and ![]() where
where ![]() represents a vector containing the tunable parameters,
represents a vector containing the tunable parameters, ![]() . For each application metric
. For each application metric ![]() , the algorithm calculates vectors
, the algorithm calculates vectors ![]() and
and ![]() (where
(where ![]() denotes the exploration direction (ascending or descending)), which store the initial value settings and exploration order, respectively, for the tunable parameters. The algorithm determines the
denotes the exploration direction (ascending or descending)), which store the initial value settings and exploration order, respectively, for the tunable parameters. The algorithm determines the ![]() application metric objective function values
application metric objective function values ![]() and
and ![]() where the parameter being explored
where the parameter being explored ![]() is assigned its first
is assigned its first ![]() and last
and last ![]() tunable values, respectively, and the rest of the tunable parameters
tunable values, respectively, and the rest of the tunable parameters ![]() are assigned initial values (lines 3 and 4).
are assigned initial values (lines 3 and 4). ![]() stores the difference between
stores the difference between ![]() and
and ![]() . If
. If ![]() ,
, ![]() results in a greater (or equal when
results in a greater (or equal when ![]() ) objective function value as compared to
) objective function value as compared to ![]() for parameter
for parameter ![]() (i.e., the objective function value decreases as the parameter value decreases). Therefore, to reduce the number of states explored while considering that the greedy algorithm (Section 10.3.3) stops exploring a tunable parameter if a tunable parameter's value yields a comparatively lower objective function value,
(i.e., the objective function value decreases as the parameter value decreases). Therefore, to reduce the number of states explored while considering that the greedy algorithm (Section 10.3.3) stops exploring a tunable parameter if a tunable parameter's value yields a comparatively lower objective function value, ![]() 's exploration order must be descending (lines 6–8). The algorithm assigns
's exploration order must be descending (lines 6–8). The algorithm assigns ![]() as the initial value of
as the initial value of ![]() for the
for the ![]() application metric (line 9). If
application metric (line 9). If ![]() , the algorithm assigns the exploration order as ascending for
, the algorithm assigns the exploration order as ascending for ![]() and
and ![]() as the initial value setting of
as the initial value setting of ![]() (lines 11–13). This
(lines 11–13). This ![]() calculation procedure is repeated for all
calculation procedure is repeated for all ![]() application metrics and all
application metrics and all ![]() tunable parameters (lines 1–16).
tunable parameters (lines 1–16).

10.3.2 Parameter Arrangement
Depending on the application metric weight factors, some parameters are more critical to meeting application requirements than other parameters. For example, sensing frequency is a critical parameter for applications with a high responsiveness weight factor, and therefore, sensing frequency should be explored first. In this section, we describe a technique for parameter arrangement such that parameters are explored in an order characterized by the parameters' impact on application metrics based on relative weight factors. This parameter arrangement technique (step 2) is part of the improvement mode, which is suitable for relatively less constrained applications that would benefit from a higher quality operating state than the one-shot mode's operating state (Fig. 10.1).
The parameter arrangement step determines an arrangement for the tunable parameters corresponding to each application metric, which dictates the order in which the parameters will be explored. This arrangement is based on the difference between the application metric's objective function values corresponding to the first and last values of the tunable parameters, which is calculated in step 1 (i.e., the tunable parameter that gives the highest difference in an application metric's objective function values is the first parameter in the arrangement vector for that application metric). For an arrangement that considers all application metrics, the tunable parameters' order is set in accordance with application metrics' weight factors such that the tunable parameters having a greater effect on application metrics with higher weight factors are situated before parameters having a lesser affect on application metrics with lower weight factors in the arrangement. We point out that the effect of the tunable parameters on an application metric is determined from the objective function value calculations as described in step 1. The arrangement that considers all application metrics selects the first few tunable parameters corresponding to each application metric, starting from the application metric with the highest weight factor such that no parameters are repeated in the final intelligent parameter arrangement. For example, if processor voltage is among the first few tunable parameters corresponding to two application metrics, then the processor voltage setting corresponding to the application metric with the greater weight factor is selected, whereas the processor voltage setting corresponding to the application metric with the lower weight factor is ignored in the final intelligent parameter arrangement. Step 3 (online optimization algorithm) uses this intelligent parameter arrangement for further design space exploration. The mathematical details of the parameter arrangement step are as follows.
Our parameter arrangement technique is based on calculations performed in Algorithm 6. We define
where ![]() is a vector containing
is a vector containing ![]() arranged in descending order by their respective values and is given as
arranged in descending order by their respective values and is given as
The tunable parameter arrangement vector ![]() corresponding to
corresponding to ![]() (one-to-one correspondence) is given by
(one-to-one correspondence) is given by
An intelligent parameter arrangement ![]() must consider all application metrics' weight factors with higher importance given to the higher weight factors, that is,
must consider all application metrics' weight factors with higher importance given to the higher weight factors, that is,
where ![]() denotes the number of tunable parameters taken from
denotes the number of tunable parameters taken from ![]() such that
such that ![]() . Our technique allows taking more tunable parameters from parameter arrangement vectors corresponding to higher weight factor application metrics:
. Our technique allows taking more tunable parameters from parameter arrangement vectors corresponding to higher weight factor application metrics: ![]() . In Eq. (10.10),
. In Eq. (10.10), ![]() tunable parameters are taken from vector
tunable parameters are taken from vector ![]() , then
, then ![]() from vector
from vector ![]() , and so on to
, and so on to ![]() from vector
from vector ![]() such that
such that ![]() . In other words, we select those tunable parameters from parameter arrangement vectors corresponding to the lower weight factors that are not already selected from parameter arrangement vectors corresponding to the higher weight factors (i.e.,
. In other words, we select those tunable parameters from parameter arrangement vectors corresponding to the lower weight factors that are not already selected from parameter arrangement vectors corresponding to the higher weight factors (i.e., ![]() comprises of disjoint or nonoverlapping tunable parameters corresponding to each application metric).
comprises of disjoint or nonoverlapping tunable parameters corresponding to each application metric).
In the situation where weight factor ![]() is much greater than all other weight factors, an intelligent parameter arrangement
is much greater than all other weight factors, an intelligent parameter arrangement ![]() would correspond to the parameter arrangement for the application metric with weight factor
would correspond to the parameter arrangement for the application metric with weight factor ![]()
The initial parameter value vector ![]() and the exploration order (ascending or descending) vector
and the exploration order (ascending or descending) vector ![]() corresponding to
corresponding to ![]() (Eq. (10.10)) can be determined from
(Eq. (10.10)) can be determined from ![]() (Eq. (10.10)),
(Eq. (10.10)), ![]() , and
, and ![]() (Algorithm 6) by examining the tunable parameter from
(Algorithm 6) by examining the tunable parameter from ![]() and determining the tunable parameter's initial value setting from
and determining the tunable parameter's initial value setting from ![]() and exploration order from
and exploration order from ![]() .
.
10.3.3 Online Optimization Algorithm
Step 3 of our dynamic optimization methodology, which also belongs to the improvement mode, iteratively improves the one-shot operating state. This step leverages information from steps 1 and 2 and uses a greedy optimization algorithm for tunable parameters exploration in an effort to determine a better operating state than the one obtained from step 1 (Section 10.3.1). The greedy algorithm explores the tunable parameters in the order determined in step 2. The greedy algorithm stops exploring a tunable parameter as soon as a tunable parameter setting yields a lower objective function value as compared to the previous tunable parameter setting for that tunable parameter, and hence named as greedy. This greedy approach helps in reducing design space exploration to determine an operating state. Although we propose a greedy algorithm for design space exploration, any other algorithm can be used in step 3.
Algorithm 7 depicts our online greedy optimization algorithm, which leverages the initial parameter value settings (Section 10.3.1), parameter value exploration order (Section 10.3.1), and parameter arrangement (Section 10.3.2). The algorithm takes as input the objective function ![]() , the number of tunable parameters
, the number of tunable parameters ![]() , the number of values for each tunable parameter
, the number of values for each tunable parameter ![]() , the intelligent tunable parameter arrangement vector
, the intelligent tunable parameter arrangement vector ![]() , the tunable parameters' initial value vector
, the tunable parameters' initial value vector ![]() , and the tunable parameter's exploration order (ascending or descending) vector
, and the tunable parameter's exploration order (ascending or descending) vector ![]() . The algorithm initializes state
. The algorithm initializes state ![]() from
from ![]() (line 1) and
(line 1) and ![]() with
with ![]() 's objective function value (line 2). The algorithm explores each parameter in
's objective function value (line 2). The algorithm explores each parameter in ![]() where
where ![]() (Eq. (10.10)) in ascending or descending order as given by
(Eq. (10.10)) in ascending or descending order as given by ![]() (lines 3 and 4). For each tunable parameter
(lines 3 and 4). For each tunable parameter ![]() (line 5), the algorithm assigns
(line 5), the algorithm assigns ![]() the objective function value from the current state
the objective function value from the current state ![]() (line 6). The current state
(line 6). The current state ![]() denotes tunable parameter value settings and can be written as
denotes tunable parameter value settings and can be written as
where ![]() denotes the parameter value corresponding to the tunable parameter
denotes the parameter value corresponding to the tunable parameter ![]() being explored and set
being explored and set ![]() denotes the parameter value settings other than the current tunable parameter
denotes the parameter value settings other than the current tunable parameter ![]() being explored and is given by
being explored and is given by
where ![]() denotes the initial value of the parameter as given by
denotes the initial value of the parameter as given by ![]() and
and ![]() denotes the best found value of
denotes the best found value of ![]() after exploring
after exploring ![]() (lines 5–13 of Algorithm 7).
(lines 5–13 of Algorithm 7).

If ![]() (the objection function value increases),
(the objection function value increases), ![]() is assigned to
is assigned to ![]() and the state
and the state ![]() is assigned to state
is assigned to state ![]() (lines 7–9). If
(lines 7–9). If ![]() , the algorithm stops exploring the current parameter
, the algorithm stops exploring the current parameter ![]() and starts exploring the next tunable parameter (lines 10–12). The algorithm returns the best found objective function value
and starts exploring the next tunable parameter (lines 10–12). The algorithm returns the best found objective function value ![]() and the state
and the state ![]() corresponding to
corresponding to ![]() .
.
10.3.4 Computational Complexity
The computational complexity for our dynamic optimization methodology is ![]() , which is comprised of the intelligent initial parameter value settings and exploration ordering (Algorithm 6)
, which is comprised of the intelligent initial parameter value settings and exploration ordering (Algorithm 6) ![]() , parameter arrangement
, parameter arrangement ![]() (sorting
(sorting ![]() (Eq. (10.8)) contributes the
(Eq. (10.8)) contributes the ![]() factor) (Section 10.3.2), and the online optimization algorithm for parameter exploration (Algorithm 7)
factor) (Section 10.3.2), and the online optimization algorithm for parameter exploration (Algorithm 7) ![]() . Assuming that the number of tunable parameters
. Assuming that the number of tunable parameters ![]() is larger than the number of parameter's tunable values
is larger than the number of parameter's tunable values ![]() , the computational complexity of our methodology can be given as
, the computational complexity of our methodology can be given as ![]() . This complexity reveals that our proposed methodology is lightweight and is thus feasible for implementation on sensor nodes with tight resource constraints.
. This complexity reveals that our proposed methodology is lightweight and is thus feasible for implementation on sensor nodes with tight resource constraints.
10.4 Experimental Results
In this section, we describe the experimental setup and results for three application domains: security/defense, health care, and ambient conditions monitoring. The results include the percentage improvements attained by our initial tunable parameter settings (one-shot operating state) over other alternative initial value settings, and a comparison of our greedy algorithm (which leverages intelligent initial parameter settings, exploration order, and parameter arrangement) for design space exploration with other variants of a greedy algorithm and SA. This section also presents an execution time and data memory analysis to verify the complexity of our dynamic optimization methodology.
10.4.1 Experimental Setup
Our experimental setup is based on the Crossbow IRIS mote platform [80] with a battery capacity of 2000 mA h using two AA alkaline batteries. The IRIS mote platform integrates an Atmel ATmega1281 microcontroller [77], an MTS400 sensor board [75] with Sensirion SHT1x temperature and humidity sensors [76], and an Atmel AT86RF230 low-power 2.4-GHz transceiver [78]. Table 10.1 shows the sensor node hardware-specific values, corresponding to the IRIS mote platform, which are used by the application metrics estimation model [76–78, 80].
Table 10.1 Crossbow IRIS mote platform hardware specifications
| Notation | Description | Value |
| Battery voltage | 3.6 V | |
| Battery capacity | 2000 mA h | |
| Processing instructions per bit | 5 | |
| Sensing resolution bits | 24 | |
| Transceiver voltage | 3 V | |
| Transceiver data rate | 250 kbps | |
| Transceiver receive current | 15.5 mA | |
| Transceiver sleep current | 20 nA | |
| Sensing board voltage | 3 V | |
| Sensing measurement current | 550 |
|
| Sensing measurement time | 55 ms | |
| Sensing sleep current | 0.3 |
We analyze six tunable parameters: processor voltage ![]() , processor frequency
, processor frequency ![]() , sensing frequency
, sensing frequency ![]() , packet size
, packet size ![]() , packet transmission interval
, packet transmission interval ![]() , and transceiver transmission power
, and transceiver transmission power ![]() . In order to explore the fidelity of our methodology across small and large design spaces, we consider two design space cardinalities (number of states in the design space):
. In order to explore the fidelity of our methodology across small and large design spaces, we consider two design space cardinalities (number of states in the design space): ![]() and
and ![]() . The tunable parameters for
. The tunable parameters for ![]() are
are ![]() (V),
(V), ![]() (MHz) [77],
(MHz) [77], ![]() (samples/s) [76],
(samples/s) [76], ![]() (B),
(B), ![]() (s), and
(s), and ![]() (dB m) [78]. The tunable parameters for
(dB m) [78]. The tunable parameters for ![]() are
are ![]() (V),
(V), ![]() (MHz) [77],
(MHz) [77], ![]() (samples/s) [76],
(samples/s) [76], ![]() (B),
(B), ![]() (s), and
(s), and ![]() (dB m) [78]. All state space tuples are feasible for
(dB m) [78]. All state space tuples are feasible for ![]() , whereas
, whereas ![]() contains 7779 infeasible state space tuples because all
contains 7779 infeasible state space tuples because all ![]() and
and ![]() pairs are not feasible.
pairs are not feasible.
In order to evaluate the robustness of our methodology across different applications with varying application metric weight factors, we model three sample application domains: a security/defense system, a healthcare application, and an ambient conditions monitoring application. We assign application-specific values for the desirable minimum ![]() , desirable maximum
, desirable maximum ![]() , acceptable minimum
, acceptable minimum ![]() , and acceptable maximum
, and acceptable maximum ![]() objective function parameter values for application metrics (Section 10.2.3) as shown in Table 10.2. We specify the objective function parameters as a multiple of base units for lifetime, throughput, and reliability. We assume one lifetime unit is equal to 5 days, one throughput unit is equal to 20 kbps, and one reliability unit is equal to 0.05 (percentage of error-free packet transmissions).
objective function parameter values for application metrics (Section 10.2.3) as shown in Table 10.2. We specify the objective function parameters as a multiple of base units for lifetime, throughput, and reliability. We assume one lifetime unit is equal to 5 days, one throughput unit is equal to 20 kbps, and one reliability unit is equal to 0.05 (percentage of error-free packet transmissions).
Table 10.2 Desirable minimum ![]() , desirable maximum
, desirable maximum ![]() , acceptable minimum
, acceptable minimum ![]() , and acceptable maximum
, and acceptable maximum ![]() objective function parameter values for a security/defense (defense) system, health care, and an ambient conditions monitoring application
objective function parameter values for a security/defense (defense) system, health care, and an ambient conditions monitoring application
| Notation | Defense (units) | Health care (units) | Ambient monitoring (units) |
| 8 | 12 | 6 | |
| 30 | 32 | 40 | |
| 1 | 2 | 3 | |
| 36 | 40 | 60 | |
| 20 | 19 | 15 | |
| 34 | 36 | 29 | |
| 0.5 | 0.4 | 0.05 | |
| 45 | 47 | 35 | |
| 14 | 12 | 11 | |
| 19.8 | 17 | 16 | |
| 10 | 8 | 6 | |
| 20 | 20 | 20 |
One lifetime unit = 5 days, one throughput unit = 20 kbps, one reliability unit = 0.05
In order to evaluate our one-shot dynamic optimization solution quality, we compare the solution from the one-shot initial parameter settings ![]() with the solutions obtained from the following four potential initial parameter value settings (although any feasible
with the solutions obtained from the following four potential initial parameter value settings (although any feasible ![]() -tuple
-tuple ![]() can be taken as the initial parameter settings):
can be taken as the initial parameter settings):
 assigns the first parameter value for each tunable parameter, that is,
assigns the first parameter value for each tunable parameter, that is,  .
. assigns the last parameter value for each tunable parameter, that is,
assigns the last parameter value for each tunable parameter, that is,  .
. assigns the middle parameter value for each tunable parameter, that is,
assigns the middle parameter value for each tunable parameter, that is,  .
. assigns a random value for each tunable parameter, that is,
assigns a random value for each tunable parameter, that is,  where
where  denotes a function to generate a random/pseudorandom integer and % denotes the modulus operator.
denotes a function to generate a random/pseudorandom integer and % denotes the modulus operator.
Although we analyzed our methodology for the IRIS motes platform, three application domains, and two design spaces, our algorithms are equally applicable to any platform, application domain, and design space. Since the constant assignments for the minimum and maximum desirable values and weight factors are application dependent and designer specified, appropriate assignments can be made for any application given the application's specific requirements. Finally, since the number of tunable parameters and the parameters' possible/allowed tunable values dictates the size of the design space, we evaluate both large and small design spaces but any sized design space could be evaluated by varying the number of tunable parameters and associated values.
10.4.2 Results
In this section, we present results for percentage improvements attained by our dynamic optimization methodology over other optimization methodologies. We implemented our dynamic optimization methodology in C++. To evaluate the effectiveness of our one-shot solution, we compare the one-shot solution's results with four alternative initial parameter arrangements (Section 10.4.1). We normalize the objective function values corresponding to the operating states attained by our dynamic optimization methodology with respect to the optimal solution obtained using an exhaustive search. We compare the relative complexity of our one-shot dynamic optimization methodology with two other dynamic optimization methodologies, which leverage greedy- and SA-based algorithms for design space exploration [316]. Although for brevity we present results for only a subset of the initial parameter value settings, application domains, and design spaces, we observed that results for extensive application domains, design spaces, and initial parameter settings revealed similar trends.
10.4.2.1 Percentage Improvements of One-Shot Over Other Initial Parameter Settings
Table 10.3 depicts the percentage improvements attained by the one-shot parameter settings ![]() over other parameter settings for different application domains and weight factors. We point out that different weight factors could result in different percentage improvements; however, we observed similar trends for other weight factors. Table 10.3 shows that one-shot initial parameter settings can result in as high as 155% improvement as compared to other initial value settings. We observe that some arbitrary settings may give a comparable or even a better solution for a particular application domain, application metric weight factors, and design space cardinality, but that arbitrary setting would not scale to other application domains, application metric weight factors, and design space cardinalities. For example,
over other parameter settings for different application domains and weight factors. We point out that different weight factors could result in different percentage improvements; however, we observed similar trends for other weight factors. Table 10.3 shows that one-shot initial parameter settings can result in as high as 155% improvement as compared to other initial value settings. We observe that some arbitrary settings may give a comparable or even a better solution for a particular application domain, application metric weight factors, and design space cardinality, but that arbitrary setting would not scale to other application domains, application metric weight factors, and design space cardinalities. For example, ![]() obtains a 12% better quality solution than
obtains a 12% better quality solution than ![]() for the ambient conditions monitoring application for
for the ambient conditions monitoring application for ![]() , but yields a 10% lower quality solution for the security/defense and healthcare applications for
, but yields a 10% lower quality solution for the security/defense and healthcare applications for ![]() , and a 57%, 31%, and 20% lower quality solution than
, and a 57%, 31%, and 20% lower quality solution than ![]() for the security/defense, health care, and ambient conditions monitoring applications, respectively, for
for the security/defense, health care, and ambient conditions monitoring applications, respectively, for ![]() . The percentage improvement attained by
. The percentage improvement attained by ![]() over all application domains and design spaces is 33% on average. Our one-shot methodology is the first approach (to the best of our knowledge) to intelligent initial tunable parameter value settings for sensor nodes to provide a good quality operating state, as arbitrary initial parameter value settings typically result in a poor operating state. Results reveal that on average
over all application domains and design spaces is 33% on average. Our one-shot methodology is the first approach (to the best of our knowledge) to intelligent initial tunable parameter value settings for sensor nodes to provide a good quality operating state, as arbitrary initial parameter value settings typically result in a poor operating state. Results reveal that on average ![]() gives a solution within 8% of the optimal solution obtained from exhaustive search.
gives a solution within 8% of the optimal solution obtained from exhaustive search.
Table 10.3 Percentage improvements attained by one-shot (![]() ) over other initial parameter settings for
) over other initial parameter settings for ![]() and
and ![]()
| Application domain | ||||||||
| Security/defense | 155 | 10 | 57 | 29 | 148 | 0.3 | 10 | 92 |
| Health care | 78 | 7 | 31 | 11 | 73 | 0.3 | 10 | 45 |
| Ambient conditions monitoring | 52 | 6 | 20 | 7 | 15 | 18 | ||
The percentage improvement attained by ![]() over all application domains and design spaces is 33% on average. Our one-shot methodology is the first approach (to the best of our knowledge) to intelligent initial tunable parameter value settings for sensor nodes to provide a good quality operating state, as arbitrary initial parameter value settings typically result in a poor operating state. Results reveal that on average
over all application domains and design spaces is 33% on average. Our one-shot methodology is the first approach (to the best of our knowledge) to intelligent initial tunable parameter value settings for sensor nodes to provide a good quality operating state, as arbitrary initial parameter value settings typically result in a poor operating state. Results reveal that on average ![]() gives a solution within 8% of the optimal solution obtained from an exhaustive search [73].
gives a solution within 8% of the optimal solution obtained from an exhaustive search [73].
10.4.2.2 Comparison of One-Shot with Greedy Variants and SA-Based Dynamic Optimization Methodologies
In order to investigate the effectiveness of our one-shot methodology, we compare the one-shot solution's quality (indicated by the attained objective function value) with two other dynamic optimization methodologies, which leverage SA-based and greedy-based (denoted by ![]() where
where ![]() stands for ascending order of parameter exploration) exploration of design space. We assign initial parameter value settings for greedy- and SA-based methodologies as
stands for ascending order of parameter exploration) exploration of design space. We assign initial parameter value settings for greedy- and SA-based methodologies as ![]() and
and ![]() , respectively. Note that, for brevity, we present results for
, respectively. Note that, for brevity, we present results for ![]() and
and ![]() ; however, other initial parameter settings such as
; however, other initial parameter settings such as ![]() and
and ![]() would yield similar trends when combined with greedy-based and SA-based design space exploration.
would yield similar trends when combined with greedy-based and SA-based design space exploration.
Figure 10.3 shows the objective function value normalized to the optimal solution (obtained from exhaustive search) versus the number of states explored for the one-shot, ![]() , and SA algorithms for a security/defense system for
, and SA algorithms for a security/defense system for ![]() . The one-shot solution is within 1.8% of the optimal solution obtained from exhaustive search. The figure shows that
. The one-shot solution is within 1.8% of the optimal solution obtained from exhaustive search. The figure shows that ![]() and SA explore 11 states (1.51% of the design space) and 10 states (1.37% of the design space), respectively, to attain an equivalent or better quality solution than the one-shot solution. Although greedy- and SA-based methodologies explore few states to reach a comparable solution as that of our one-shot methodology, the one-shot methodology is suitable when design space exploration is not an option due to an extremely large design space and/or extremely stringent computational, memory, and timing constraints. These results indicate that other arbitrary initial value settings (e.g.,
and SA explore 11 states (1.51% of the design space) and 10 states (1.37% of the design space), respectively, to attain an equivalent or better quality solution than the one-shot solution. Although greedy- and SA-based methodologies explore few states to reach a comparable solution as that of our one-shot methodology, the one-shot methodology is suitable when design space exploration is not an option due to an extremely large design space and/or extremely stringent computational, memory, and timing constraints. These results indicate that other arbitrary initial value settings (e.g., ![]() ,
, ![]() ) do not provide a good quality operating state and necessitate design space exploration by online algorithms (e.g., greedy) to provide a good quality operating state. We point out that if the greedy- and SA-based methodologies leverage our one-shot initial tunable parameter value settings
) do not provide a good quality operating state and necessitate design space exploration by online algorithms (e.g., greedy) to provide a good quality operating state. We point out that if the greedy- and SA-based methodologies leverage our one-shot initial tunable parameter value settings ![]() , further improvements over the one-shot solution can produce a very good quality (optimal or near-optimal) operating state [316].
, further improvements over the one-shot solution can produce a very good quality (optimal or near-optimal) operating state [316].

Figure 10.3 Objective function value normalized to the optimal solution for a varying number of states explored for one-shot, greedy, and SA algorithms for a security/defense system where  ,
,  ,
,  , and
, and 
Figure 10.4 shows the objective function value normalized to the optimal solution versus the number of states explored for a security/defense system for ![]() . The one-shot solution is within 8.6% of the optimal solution. The figure shows that
. The one-shot solution is within 8.6% of the optimal solution. The figure shows that ![]() converges to a lower quality solution than the one-shot solution after exploring 9 states (0.029% of the design space) and SA explores 8 states (0.026% of the design space) to yield a better quality solution than the one-shot solution. These results reveal that the greedy exploration of parameters may not necessarily attain a better quality solution than our one-shot solution.
converges to a lower quality solution than the one-shot solution after exploring 9 states (0.029% of the design space) and SA explores 8 states (0.026% of the design space) to yield a better quality solution than the one-shot solution. These results reveal that the greedy exploration of parameters may not necessarily attain a better quality solution than our one-shot solution.

Figure 10.4 Objective function value normalized to the optimal solution for a varying number of states explored for one-shot, greedy, and SA algorithms for a security/defense system where  ,
,  ,
,  , and
, and 
Figure 10.5 shows the objective function value normalized to the optimal solution versus the number of states explored for a healthcare application for ![]() . The one-shot solution is within 2.1% of the optimal solution. The figure shows that
. The one-shot solution is within 2.1% of the optimal solution. The figure shows that ![]() converges to an almost equal quality solution as compared to the one-shot solution after exploring 11 states (1.5% of the design space) and SA explores 10 states (1.4% of the design space) to yield an almost equal quality solution as compared to the one-shot solution. These results indicate that further exploration of the design space is required to find an equivalent quality solution as compared to one-shot if the intelligent initial value settings leveraged by one-shot is not used.
converges to an almost equal quality solution as compared to the one-shot solution after exploring 11 states (1.5% of the design space) and SA explores 10 states (1.4% of the design space) to yield an almost equal quality solution as compared to the one-shot solution. These results indicate that further exploration of the design space is required to find an equivalent quality solution as compared to one-shot if the intelligent initial value settings leveraged by one-shot is not used.

Figure 10.5 Objective function value normalized to the optimal solution for a varying number of states explored for one-shot, greedy, and SA algorithms for a healthcare application where  ,
,  ,
,  , and
, and 
Figure 10.6 shows the objective function value normalized to the optimal solution versus the number of states explored for a healthcare application for ![]() . The one-shot solution is within 1.6% of the optimal solution. The figure shows that
. The one-shot solution is within 1.6% of the optimal solution. The figure shows that ![]() converges to a lower quality solution than the one-shot solution after exploring 9 states (0.029% of the design space) and SA explores 6 states (0.019% of the design space) to yield a better quality solution than the one-shot solution. These results confirm that the greedy exploration of parameters may not necessarily attain a better quality solution than our one-shot solution.
converges to a lower quality solution than the one-shot solution after exploring 9 states (0.029% of the design space) and SA explores 6 states (0.019% of the design space) to yield a better quality solution than the one-shot solution. These results confirm that the greedy exploration of parameters may not necessarily attain a better quality solution than our one-shot solution.

Figure 10.6 Objective function value normalized to the optimal solution for a varying number of states explored for one-shot, greedy, and SA algorithms for a healthcare application where  ,
,  ,
,  , and
, and 
Figure 10.7 shows the objective function value normalized to the optimal solution versus the number of states explored for an ambient conditions monitoring application for ![]() . The one-shot solution is within 7.7% of the optimal solution. The figure shows that
. The one-shot solution is within 7.7% of the optimal solution. The figure shows that ![]() and SA converge to an equivalent or better quality solution than the one-shot solution after exploring 4 states (0.549% of the design space) and 10 states (1.37% of the design space). These results again confirm that the greedy- and SA-based exploration can provide improved results over the one-shot solution, but requires additional state exploration.
and SA converge to an equivalent or better quality solution than the one-shot solution after exploring 4 states (0.549% of the design space) and 10 states (1.37% of the design space). These results again confirm that the greedy- and SA-based exploration can provide improved results over the one-shot solution, but requires additional state exploration.

Figure 10.7 Objective function value normalized to the optimal solution for a varying number of states explored for one-shot, greedy, and SA algorithms for an ambient conditions monitoring application where  ,
,  ,
,  , and
, and 
Figure 10.8 shows the objective function value normalized to the optimal solution versus the number of states explored for an ambient conditions monitoring application for ![]() . The one-shot solution is within 24.7% of the optimal solution. The figure shows that both
. The one-shot solution is within 24.7% of the optimal solution. The figure shows that both ![]() and SA converge to an equivalent or better quality solution than the one-shot solution after exploring 3 states (0.01% of the design space). These results indicate that both greedy and SA can give good quality solutions after exploring a very small percentage of the design space and both greedy-based and SA-based methods enable lightweight dynamic optimizations [316]. The results also indicate that the one-shot solution provides a good quality solution when further design space exploration is not possible due to resource constraints.
and SA converge to an equivalent or better quality solution than the one-shot solution after exploring 3 states (0.01% of the design space). These results indicate that both greedy and SA can give good quality solutions after exploring a very small percentage of the design space and both greedy-based and SA-based methods enable lightweight dynamic optimizations [316]. The results also indicate that the one-shot solution provides a good quality solution when further design space exploration is not possible due to resource constraints.

Figure 10.8 Objective function value normalized to the optimal solution for a varying number of states explored for one-shot, greedy, and SA algorithms for an ambient conditions monitoring application where  ,
,  ,
,  , and
, and 
10.4.2.3 Comparison of Optimized Greedy (GD) with Greedy Variants and SA-Based Dynamic Optimization Methodologies
For comparison purposes, we implemented an SA-based algorithm, our greedy online optimization algorithm (GD) (which leverages intelligent initial parameter value selection, exploration ordering, and parameter arrangement), and several other greedy online algorithm variations (Table 10.4) in C++. We compare our results with SA to provide relative comparisons of our dynamic optimization methodology with another methodology that leverages an SA-based online optimization algorithm and arbitrary initial value settings. We point out that step 3 of our dynamic optimization methodology can use any lightweight algorithm (e.g., greedy-based, SA-based) in the improvement mode (Fig. 10.1). Although we present SA for comparison with the greedy algorithm, both of these algorithms are equally applicable to our dynamic optimization methodology. We compare GD results with different greedy algorithm variations (Table 10.4) to provide an insight into how initial parameter value settings, exploration ordering, and parameter arrangement affect the final operating state quality. We normalize the objective function value (corresponding to the operating state) attained by the algorithms with respect to the optimal solution (objective function value corresponding to the optimal operating state) obtained from an exhaustive search.
Table 10.4 Greedy algorithms with different parameter arrangements and exploration orders
| Notation | Description |
| GD | Greedy algorithm with parameter exploration order |
| Explores parameter values in ascending order with arrangement |
|
| Explores parameter values in ascending order with arrangement |
|
| Explores parameter values in ascending order with arrangement |
|
| Explores parameter values in descending order with arrangement |
|
| Explores parameter values in descending order with arrangement |
|
| Explores parameter values in descending order with arrangement |
Figure 10.9 shows the objective function values normalized to the optimal solution for SA and greedy algorithms versus the number of states explored for a security/defense system for ![]() . Results indicate that
. Results indicate that ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and GD converge to a steady-state solution (objective function value corresponding to the operating state) after exploring 11, 10, 11, 10, 10, 9, and 8 states, respectively. We point out that we do not plot the results for each iteration and greedy algorithm variations for brevity; however, we obtained the results for all iterations and greedy algorithm variations. These convergence results show that GD converges to a final operating state slightly faster than other greedy algorithms, exploring only 1.1% of the design space.
, and GD converge to a steady-state solution (objective function value corresponding to the operating state) after exploring 11, 10, 11, 10, 10, 9, and 8 states, respectively. We point out that we do not plot the results for each iteration and greedy algorithm variations for brevity; however, we obtained the results for all iterations and greedy algorithm variations. These convergence results show that GD converges to a final operating state slightly faster than other greedy algorithms, exploring only 1.1% of the design space. ![]() and
and ![]() converge to almost equal quality solutions as
converge to almost equal quality solutions as ![]() and
and ![]() showing that ascending or descending parameter values exploration and parameter arrangements do not significantly impact the solution quality for this application for
showing that ascending or descending parameter values exploration and parameter arrangements do not significantly impact the solution quality for this application for ![]() = 729.
= 729.

Figure 10.9 Objective function values normalized to the optimal solution for a varying number of states explored for SA and the greedy algorithms for a security/defense system where  ,
,  ,
,  , and
, and 
Results also indicate that the SA algorithm outperforms all greedy algorithms and converges to the optimal solution after exploring 400 states or 55% of the design space. Figure 10.9 also verifies the ability of our methodology to determine a good quality, near-optimal solution in one-shot that is within 1.4% of the optimal solution. GD achieves only a 1.8% improvement over the initial state after exploring 8 states.
Figure 10.10 shows the objective function values normalized to the optimal solution for SA and greedy algorithms versus the number of states explored for a security/defense system for ![]() . Results reveal that GD converges to the final solution by exploring only 0.04% of the design space.
. Results reveal that GD converges to the final solution by exploring only 0.04% of the design space. ![]() ,
, ![]() , and
, and ![]() converge to better solutions than
converge to better solutions than ![]() ,
, ![]() , and
, and ![]() showing that descending parameter values exploration and parameter arrangements
showing that descending parameter values exploration and parameter arrangements ![]() ,
, ![]() , and
, and ![]() are better for this application as compared to the ascending parameter values exploration and parameter arrangements
are better for this application as compared to the ascending parameter values exploration and parameter arrangements ![]() ,
, ![]() , and
, and ![]() . This difference is because a descending exploration order tends to select higher tunable parameter values, which increases the throughput considerably as compared to lower tunable parameter values. Since throughput has been assigned a higher weight factor for this application than the lifetime, better overall objective function values are attained.
. This difference is because a descending exploration order tends to select higher tunable parameter values, which increases the throughput considerably as compared to lower tunable parameter values. Since throughput has been assigned a higher weight factor for this application than the lifetime, better overall objective function values are attained.

Figure 10.10 Objective function values normalized to the optimal solution for a varying number of states explored for SA and greedy algorithms for a security/defense system where  ,
,  ,
,  , and
, and 
Comparing Figs. 10.10 and 10.9 reveals that the design space size also affects the solution quality in addition to the parameter value exploration order and parameter arrangement. For example, for ![]() , the ascending and descending parameter values exploration order and parameter arrangement result in comparable quality solutions, whereas for
, the ascending and descending parameter values exploration order and parameter arrangement result in comparable quality solutions, whereas for ![]() , the descending parameter values exploration order results in higher quality solutions. Again, the SA algorithm outperforms all greedy algorithms and converges to the optimal solution for
, the descending parameter values exploration order results in higher quality solutions. Again, the SA algorithm outperforms all greedy algorithms and converges to the optimal solution for ![]() after exploring 100 states or 0.3% of the design space. Figure 10.10 also verifies the ability of our methodology to determine a good quality, near-optimal solution in one-shot that is within 9% of the optimal solution. GD achieves only a 0.3% improvement over the initial state (one-shot solution) after exploring 11 states.
after exploring 100 states or 0.3% of the design space. Figure 10.10 also verifies the ability of our methodology to determine a good quality, near-optimal solution in one-shot that is within 9% of the optimal solution. GD achieves only a 0.3% improvement over the initial state (one-shot solution) after exploring 11 states.
Results for a healthcare application for ![]() reveal that GD converges to the final solution slightly faster than other greedy algorithms, exploring only 1% of the design space. The SA algorithm outperforms the greedy algorithm variants after exploring 400 states or 55% of the design space for
reveal that GD converges to the final solution slightly faster than other greedy algorithms, exploring only 1% of the design space. The SA algorithm outperforms the greedy algorithm variants after exploring 400 states or 55% of the design space for ![]() , but the SA improvement over the greedy algorithm variants is insignificant as the greedy algorithm variants attain near-optimal solutions. Results indicate that the one-shot solution is within 2% of the optimal solution. GD achieves only a 2% improvement over the one-shot solution after exploring 8 states.
, but the SA improvement over the greedy algorithm variants is insignificant as the greedy algorithm variants attain near-optimal solutions. Results indicate that the one-shot solution is within 2% of the optimal solution. GD achieves only a 2% improvement over the one-shot solution after exploring 8 states.
Results for a healthcare application for ![]() reveal that GD converges to the final solution by exploring only 0.0257% of the design space. The SA algorithm outperforms all greedy algorithms and converges to the optimal solution after exploring 100 states (0.3% of the design space). The one-shot solution is within 1.5% of the optimal solution. GD achieves only a 0.2% improvement over the one-shot solution after exploring 8 states.
reveal that GD converges to the final solution by exploring only 0.0257% of the design space. The SA algorithm outperforms all greedy algorithms and converges to the optimal solution after exploring 100 states (0.3% of the design space). The one-shot solution is within 1.5% of the optimal solution. GD achieves only a 0.2% improvement over the one-shot solution after exploring 8 states.
Figure 10.11 shows the objective function values normalized to the optimal solution versus the number of states explored for an ambient conditions monitoring application for ![]() . Results reveal that GD converges to the final solution slightly faster than other greedy algorithms, exploring only 1.1% of the design space.
. Results reveal that GD converges to the final solution slightly faster than other greedy algorithms, exploring only 1.1% of the design space. ![]() ,
, ![]() , and
, and ![]() converge to a higher quality solution than
converge to a higher quality solution than ![]() ,
, ![]() , and
, and ![]() because the ascending exploration order tends to select lower tunable parameter values, which results in comparatively larger lifetime values as compared to higher tunable parameter values. This higher lifetime results in higher lifetime objective function values and thus higher overall objective function values. We observe that the greedy algorithm variants result in higher quality solutions after exploring more states than the one attained by GD since
because the ascending exploration order tends to select lower tunable parameter values, which results in comparatively larger lifetime values as compared to higher tunable parameter values. This higher lifetime results in higher lifetime objective function values and thus higher overall objective function values. We observe that the greedy algorithm variants result in higher quality solutions after exploring more states than the one attained by GD since ![]() ,
, ![]() ,
, ![]() , and
, and ![]() attain the optimal solution for
attain the optimal solution for ![]() . This observation reveals that other arbitrary parameter arrangements and exploration orders may obtain better solutions than GD, but those arbitrary arrangements and exploration orders would not scale for different application domains with different weight factors and for different design space cardinalities. The SA algorithm outperforms
. This observation reveals that other arbitrary parameter arrangements and exploration orders may obtain better solutions than GD, but those arbitrary arrangements and exploration orders would not scale for different application domains with different weight factors and for different design space cardinalities. The SA algorithm outperforms ![]() ,
, ![]() , and GD after exploring 400 states (55% of the design space).
, and GD after exploring 400 states (55% of the design space). ![]() ,
, ![]() ,
, ![]() , and
, and ![]() attain optimal solutions. Our one-shot solution is within 8% of the optimal solution. GD achieves only a 2% improvement over the one-shot solution after exploring 8 states.
attain optimal solutions. Our one-shot solution is within 8% of the optimal solution. GD achieves only a 2% improvement over the one-shot solution after exploring 8 states.

Figure 10.11 Objective function values normalized to the optimal solution for a varying number of states explored for SA and greedy algorithms for an ambient conditions monitoring application where  ,
,  ,
,  , and
, and 
Results for an ambient conditions monitoring application for ![]() indicate that GD converges to the optimal solution after exploring 13 states (0.04% of design space), with a 17% improvement over the one-shot solution. The one-shot solution is within 14% of the optimal solution.
indicate that GD converges to the optimal solution after exploring 13 states (0.04% of design space), with a 17% improvement over the one-shot solution. The one-shot solution is within 14% of the optimal solution. ![]() ,
, ![]() , and
, and ![]() converge to a better solution than
converge to a better solution than ![]() ,
, ![]() , and
, and ![]() for similar reasons as
for similar reasons as ![]() . The one-shot solution is within 14% of the optimal solution. SA converges to a near-optimal solution after exploring 400 states (1.3% of the design space).
. The one-shot solution is within 14% of the optimal solution. SA converges to a near-optimal solution after exploring 400 states (1.3% of the design space).
The results for different application domains and design spaces verify that the one-shot mode provides a high-quality solution that is within 8% of the optimal solution averaged over all application domains and design space cardinalities. These results also verify that improvements can be achieved over the one-shot solution during the improvement mode. The results indicate that GD may explore more states than other greedy algorithms if state exploration provides a noticeable improvement over the one-shot solution. The results also provide an insight into the convergence rates and reveal that even though the design space cardinality increases by 43![]() , both heuristic algorithms (greedy and SA) still explore only a small percentage of the design space and result in high-quality solutions. Furthermore, although SA outperforms the greedy algorithms after exploring a comparatively larger portion of the design space, GD still provides an optimal or near-optimal solution with significantly less design space exploration. These results advocate the use of GD as a design space exploration algorithm for constrained applications, whereas SA can be used for relatively less constrained applications. We point out that both GD and SA are online algorithms for dynamic optimization and are suitable for larger design spaces as compared to other stochastic algorithms, such as MDP-based algorithms, which are only suitable for restricted (comparatively smaller) design spaces [69].
, both heuristic algorithms (greedy and SA) still explore only a small percentage of the design space and result in high-quality solutions. Furthermore, although SA outperforms the greedy algorithms after exploring a comparatively larger portion of the design space, GD still provides an optimal or near-optimal solution with significantly less design space exploration. These results advocate the use of GD as a design space exploration algorithm for constrained applications, whereas SA can be used for relatively less constrained applications. We point out that both GD and SA are online algorithms for dynamic optimization and are suitable for larger design spaces as compared to other stochastic algorithms, such as MDP-based algorithms, which are only suitable for restricted (comparatively smaller) design spaces [69].
10.4.2.4 Computational Complexity
We analyze the relative complexity of the algorithms by measuring their execution time and data memory requirements. We perform data memory analysis for each step of our dynamic optimization methodology. Our data memory analysis assumes an 8-bit processor for sensor nodes with integer data types requiring 2 B of storage and float data types requiring 4 B of storage. Analysis reveals that the one-shot solution (step 1) requires only 150, 188, 248, and 416 B, whereas step 2 requires 94, 140, 200, and 494 B for (number of tunable parameters ![]() , number of application metrics
, number of application metrics ![]() ) equal to (3, 2), (3, 3), (6, 3), and (6, 6), respectively. GD in step 3 requires 458, 528, 574, 870, and 886 B, whereas SA in step 3 requires 514, 582, 624, 920, and 936 B of storage for design space cardinalities of 8, 81, 729, 31,104, and 46,656, respectively.
) equal to (3, 2), (3, 3), (6, 3), and (6, 6), respectively. GD in step 3 requires 458, 528, 574, 870, and 886 B, whereas SA in step 3 requires 514, 582, 624, 920, and 936 B of storage for design space cardinalities of 8, 81, 729, 31,104, and 46,656, respectively.
The data memory analysis shows that SA has comparatively larger memory requirements than the greedy algorithm. Our analysis reveals that the data memory requirements for all three steps of our dynamic optimization methodology increase linearly as the number of tunable parameters, tunable values, and application metrics, and thus the design space, increase. The analysis verifies that although all three steps of our dynamic optimization methodology have low data memory requirements, the one-shot solution in step 1 requires 361% less memory on average.
We measured the execution time for all three steps of our dynamic optimization methodology averaged over 10,000 runs (to smooth any discrepancies in execution time due to operating system overheads) on an Intel Xeon CPU running at 2.66 GHz [326] using the Linux/Unix time command [327]. We scaled these execution times to the Atmel ATmega1281 microcontroller [77] running at 8 MHz. Although scaling does not provide 100% accuracy for the microcontroller runtime because of different instruction set architectures and memory subsystems, scaling provides reasonable runtime estimates and enables relative comparisons. Results showed that steps 1 and 2 required 1.66 ms and 0.332 ms, respectively, both for ![]() and
and ![]() . For step 3, we compared GD with SA. GD explored 10 states and required 0.887 ms and 1.33 ms on average to converge to the solution for
. For step 3, we compared GD with SA. GD explored 10 states and required 0.887 ms and 1.33 ms on average to converge to the solution for ![]() and
and ![]() , respectively. SA required 2.76 ms and 2.88 ms to explore the first 10 states (to provide a fair comparison with GD) for
, respectively. SA required 2.76 ms and 2.88 ms to explore the first 10 states (to provide a fair comparison with GD) for ![]() and
and ![]() , respectively. The other greedy algorithms required comparatively more time than GD because they required more design state exploration to converge than GD; however, all the greedy algorithms required less execution time than SA.
, respectively. The other greedy algorithms required comparatively more time than GD because they required more design state exploration to converge than GD; however, all the greedy algorithms required less execution time than SA.
To verify that our dynamic optimization methodology is lightweight, we compared the execution time results for all three steps of our dynamic optimization methodology with the exhaustive search. The exhaustive search required 29.526 ms and 2.765 s for ![]() and
and ![]() , respectively, which gives speedups of 10
, respectively, which gives speedups of 10![]() and 832
and 832![]() , respectively, for our dynamic optimization methodology. The execution time analysis reveals that all three steps of our dynamic optimization methodology require execution time on the order of milliseconds, and the one-shot solution requires 138% less execution time on average as compared to all three steps of the dynamic optimization methodology. Execution time savings attained by the one-shot solution as compared to the three steps of our dynamic optimization methodology are 73% and 186% for GD and SA, respectively, when
, respectively, for our dynamic optimization methodology. The execution time analysis reveals that all three steps of our dynamic optimization methodology require execution time on the order of milliseconds, and the one-shot solution requires 138% less execution time on average as compared to all three steps of the dynamic optimization methodology. Execution time savings attained by the one-shot solution as compared to the three steps of our dynamic optimization methodology are 73% and 186% for GD and SA, respectively, when ![]() , and are 100% and 138% for GD and SA, respectively, when
, and are 100% and 138% for GD and SA, respectively, when ![]() . These results indicate that the design space cardinality affects the execution time linearly, and our dynamic optimization methodology's advantage increases as the design space cardinality increases. We verified our execution time analysis using the
. These results indicate that the design space cardinality affects the execution time linearly, and our dynamic optimization methodology's advantage increases as the design space cardinality increases. We verified our execution time analysis using the clock() function [328], which confirmed similar trends.
To further verify that our dynamic optimization methodology is lightweight, we calculate the energy consumption for the two modes of our methodology—the one-shot and the improvement modes with either a GD- or SA-based online algorithm. We calculate the energy consumption ![]() for an Atmel ATmega1281 microcontroller [77] operating at
for an Atmel ATmega1281 microcontroller [77] operating at ![]() V and
V and ![]() MHz as
MHz as ![]() where
where ![]() and
and ![]() denote the processor's active current and the execution time for the methodology's operating mode at
denote the processor's active current and the execution time for the methodology's operating mode at ![]() , respectively (we observed similar trends for other processor voltage and frequency settings). We point out that we consider the execution time for exploring the first 10 states for both the GD- and SA-based online algorithms in our energy calculations as both the GD and SA algorithms attained near-optimal results after exploring 10 states both for
, respectively (we observed similar trends for other processor voltage and frequency settings). We point out that we consider the execution time for exploring the first 10 states for both the GD- and SA-based online algorithms in our energy calculations as both the GD and SA algorithms attained near-optimal results after exploring 10 states both for ![]() and
and ![]() . Table 10.5 summarizes the energy calculations for different modes of our dynamic optimization methodology as well as for the exhaustive search for
. Table 10.5 summarizes the energy calculations for different modes of our dynamic optimization methodology as well as for the exhaustive search for ![]() and
and ![]() . We assume that the sensor node's battery energy in our calculations is
. We assume that the sensor node's battery energy in our calculations is ![]() J (which is computed using our application metrics estimation model). Results indicate that one-shot consumes 1679% and 166,510% less energy as compared to the exhaustive search for
J (which is computed using our application metrics estimation model). Results indicate that one-shot consumes 1679% and 166,510% less energy as compared to the exhaustive search for ![]() and
and ![]() , respectively. Improvement mode using GD as the online algorithm consumes 926% and 83,135% less energy as compared to the exhaustive search for
, respectively. Improvement mode using GD as the online algorithm consumes 926% and 83,135% less energy as compared to the exhaustive search for ![]() and
and ![]() , respectively. Improvement mode using SA as the online algorithm consumes 521% and 56,656% less energy as compared to the exhaustive search for
, respectively. Improvement mode using SA as the online algorithm consumes 521% and 56,656% less energy as compared to the exhaustive search for ![]() and
and ![]() , respectively. Furthermore, our dynamic optimization methodology using GD as the online algorithm can be executed
, respectively. Furthermore, our dynamic optimization methodology using GD as the online algorithm can be executed ![]() more times than the exhaustive search and
more times than the exhaustive search and ![]() more times than when using SA as the online algorithm for
more times than when using SA as the online algorithm for ![]() . These results verify that our dynamic optimization methodology is lightweight and can be theoretically executed on the order of million times even on energy-constrained sensor nodes.
. These results verify that our dynamic optimization methodology is lightweight and can be theoretically executed on the order of million times even on energy-constrained sensor nodes.
Table 10.5 Energy consumption for the one-shot and the improvement mode for our dynamic optimization methodology
| Mode | ||||
| One-shot | 1.66 | 23.75 | |
|
| 2.879 | 41.2 | |||
| 4.752 | 68 | |||
| 29.526 | 422.52 | |||
| 3.322 | 47.54 | |||
| 4.872 | 69.72 | |
||
| 2,765 | 39,570 | |
![]() and
and ![]() denote the improvement mode using GD and SA as the online algorithms, respectively, for
denote the improvement mode using GD and SA as the online algorithms, respectively, for ![]() =
= ![]() where
where ![]() = {729, 31,104}.
= {729, 31,104}. ![]() denotes the exhaustive search for
denotes the exhaustive search for ![]() =
= ![]() where
where ![]() = {729, 31,104}.
= {729, 31,104}. ![]() denotes the fraction of battery energy consumed in an operating mode and
denotes the fraction of battery energy consumed in an operating mode and ![]() denotes the maximum number of times (runs) our dynamic optimization methodology can be executed in a given mode depending on the sensor node's battery energy
denotes the maximum number of times (runs) our dynamic optimization methodology can be executed in a given mode depending on the sensor node's battery energy
10.5 Chapter Summary
In this chapter, we proposed a lightweight dynamic optimization methodology for EWSNs, which provided a high-quality solution in one-shot using an intelligent initial tunable parameter value setting for highly constrained applications. We also proposed an online greedy optimization algorithm that leveraged intelligent design space exploration techniques to iteratively improve on the one-shot solution for less constrained applications. Results showed that our one-shot solution is near-optimal and within 8% of the optimal solution on average. Compared with simulating annealing (SA) and different greedy algorithm variations, results showed that the one-shot solution yielded improvements as high as 155% over other arbitrary initial parameter settings. Results indicated that our greedy algorithm converged to the optimal or near-optimal solution after exploring only 1% and 0.04% of the design space, whereas SA explored 55% and 1.3% of the design space for design space cardinalities of 729 and 31,104, respectively. Data memory and execution time analysis revealed that our one-shot solution (step 1) required 361% and 85% less data memory and execution time, respectively, when compared to using all the three steps of our dynamic optimization methodology. Furthermore, one-shot consumed 1679% and 166,510% less energy as compared to the exhaustive search for ![]() and
and ![]() , respectively. Improvement mode using GD as the online algorithm consumed 926% and 83,135% less energy as compared to the exhaustive search for
, respectively. Improvement mode using GD as the online algorithm consumed 926% and 83,135% less energy as compared to the exhaustive search for ![]() and
and ![]() , respectively. Computational complexity along with the execution time, data memory analysis, and energy consumption confirmed that our methodology is lightweight and thus feasible for sensor nodes with limited resources.
, respectively. Computational complexity along with the execution time, data memory analysis, and energy consumption confirmed that our methodology is lightweight and thus feasible for sensor nodes with limited resources.