
Chapter 8
An MDP-Based Dynamic Optimization Methodology for Embedded Wireless Sensor Networks*
Embedded wireless sensor networks (EWSNs) are distributed systems consisting of spatially distributed autonomous sensor nodes that span diverse application domains. The EWSN application domains include security and defense systems, industrial monitoring, building automation, logistics, ecology, environment and ambient conditions monitoring, healthcare, home and office applications, vehicle tracking, and so on. However, this wide application diversity combined with increasing embedded sensor nodes complexity, functionality requirements, and highly constrained operating environments makes EWSN design very challenging.
One critical EWSN design challenge involves meeting application requirements such as reliability, lifetime, throughput, and delay (responsiveness) for a myriad of application domains. For example, a vineyard irrigation system may require less responsiveness to environmental stimuli (i.e., decreased irrigation during wet periods), but have a long lifetime requirement. On the other hand, in a disaster relief application, sensor nodes may require high responsiveness but have a short lifetime. Additional requirements may include high adaptability to rapid network changes as sensor nodes are destroyed. Meeting these application-specific requirements is critical to accomplishing the application's assigned function. Nevertheless, satisfying these demands in a scalable and cost-effective way is a challenging task.
Commercial off-the-shelf (COTS) embedded sensor nodes have difficulty meeting application requirements due to inherent manufacturing traits. In order to reduce manufacturing costs, generic COTS embedded sensor nodes capable of implementing nearly any application are produced in large volumes and are not specialized to meet any specific application requirements. In order to meet application requirements, sensor nodes must possess tunable parameters. Fortunately, some COTS have tunable parameters such as processor voltage, processor frequency, sensing frequency, radio transmission power, and radio transmissionfrequency.
Embedded sensor node parameter tuning is the process of determining appropriate parameter values, which meet application requirements. However, determining such values presents several tuning challenges. First, application managers (the individuals responsible for EWSN deployment and management) typically lack sufficient technical expertise [297, 298], as many managers are nonexperts (i.e., biologists, teachers, structural engineers, agriculturists). In addition, parameter value tuning is still a cumbersome and time-consuming task even for expert application managers because of unpredictable EWSN environments and difficulty in creating accurate simulation environments. Second, selected parameter values may not be optimal (suboptimal). Given a highly configurable embedded sensor node with many tunable parameters and with many values for each tunable parameter, choosing the optimal combination is difficult. In addition, unanticipated changes in the sensor node's environment can alter optimal parameter values. For example, an embedded sensor node designed to monitor a short-lived volcanic eruption may need to operate for more months/years than expected if earthquakes alter magma flow.
To ease parameter value selection, dynamic optimizations enable embedded sensor nodes to dynamically tune their parameter values in situ according to application requirements and environmental stimuli. This dynamic tuning of parameters ensures that an EWSN performs the assigned task optimally, enabling the embedded sensor node to constantly conform to the changing environment. In addition, the application manager need not know embedded sensor node and/or dynamic optimization specifics, thus easing parameter tuning for nonexpert application managers.
Unfortunately, there exists little previous work on EWSN dynamic optimizations with respect to the related high-level application requirements to low-level embedded sensor node parameters. Moreover, changes in application requirements over time were not addressed in previous work. Hence, novel dynamic optimization methodologies that respond to changing application requirements and environmental stimuli are essential.
In this chapter, we propose an application-oriented dynamic tuning methodology for embedded sensor nodes in distributed EWSNs based on Markov decision process (MDP). Our MDP-based application-oriented tuning methodology performs dynamic voltage, frequency, and sensing (sampling) frequency scaling (DVFS2). MDP is an appropriate candidate for EWSN dynamic optimizations where dynamic decision making is a requirement in light of changing environmental stimuli and wireless channel condition. We focus on DVFS2 for several reasons. Traditional microprocessor-based systems use dynamic voltage and frequency scaling (DVFS) for energy optimizations. However, sensor nodes are distinct from traditional systems in that they have embedded sensors coupled with an embedded processor. Therefore, DVFS only provides a partial tuning methodology and does not consider sensing frequency. Sensing frequency tuning is essential for sensor nodes to meet application requirements because the sensed data delay (thedelay between the sensor sensing the data and the data's reception by the application manager) depends on the sensor node sensing frequency as it influences the amount of processed and communicated data. Thus, DVFS2 provides enhanced optimization potential as compared to DVFS with respect to EWSNs.
Our main contributions in this chapter are as follows:
- We propose an MDP for dynamic optimization of embedded sensor nodes in EWSNs. MDP is suitable for embedded sensor nodes dynamic optimization because of MDP's inherent ability to perform dynamic decision making. This chapter presents a first step toward MDP-based dynamic optimization.
- Our MDP-based dynamic optimization methodology gives a policy that performs DVFS2 and specifies good quality solution for embedded sensor node parameter tuning for EWSN lifetime.
- Our MDP-based dynamic tuning methodology adapts to changing application requirements and environmental stimuli.
- We provide implementation guidelines for our proposed dynamic tuning methodology in embedded sensor nodes.
We compare our proposed MDP-based application-oriented dynamic tuning methodology with several fixed heuristics. The results show that our proposed methodology outperforms other heuristics for the given application requirements. The broader impacts of our research include facilitating EWSN designers (persons who design EWSNs for an application) to better meet application requirements by selecting suitable tunable parameter values for each sensor node. As this chapter presents a first step toward MDP-based dynamic optimization, our work can potentially spark further research in MDP-based optimizations for embedded sensor nodes in EWSNs.
The remainder of this chapter is organized as follows. A review of related work is given in Section 8.1. Section 8.2 provides an overview of MDP with respect to EWSNs and our proposed MDP-based application-oriented dynamic tuning methodology. Section 8.3 describes the formulation of our proposed methodology as an MDP. Section 8.4 provides implementation guidelines and our proposed methodology's computational complexity. Section 8.5 provides model extensions to our proposed policy. Numerical results are presented in Section 8.6. Section 8.7 concludes our study and outlines future research work directions.
8.1 Related Work
There is a lot of research in the area of dynamic optimizations [187–189, 299], but however, most previous work focuses on the processor or memory (cache) in computer systems. These endeavors can provide valuable insights into embedded sensor nodes' dynamic optimizations, whereas they are not directly applicable to embedded sensor nodes because of different design spaces, platform particulars, and embedded sensor nodes' tight design constraints.
Stevens-Navarro et al. [299] applied MDPs for vertical hands-off decisions in heterogeneous wireless networks. Although our work leverages the reward function idea from their work, our work, for the first time to the best of our knowledge, applies MDPs to dynamic optimizations of embedded sensor nodes in EWSNs.
Little previous work exists in the area of application-specific tuning and dynamic profiling in EWSNs. Sridharan and Lysecky [300] obtained accurate environmental stimuli by dynamically profiling the EWSN's operating environment; however, they did not propose any methodology to leverage these profiling statistics for optimizations. Tilak et al. [301] investigated infrastructure (referred to as sensor node characteristics, number of deployed sensors, and deployment strategy) trade-offs on application requirements. The application requirements considered were accuracy, latency, energy efficiency, fault tolerance, goodput (ratio of total number of packets received to the total number of packets sent), and scalability. However, the authors did not delineate the interdependence between low-level sensor node parameters and high-level application requirements. Kogekar et al. [227] proposed an approach for dynamic software reconfiguration in EWSNs using dynamically adaptive software. Their approach used tasks to detect environmental changes (event occurrences) and adapt the software to the new conditions. Their work did not consider embedded sensor node tunable parameters. Kadayif and Kandemir [302] proposed an automated strategy for data filtering to determine the amount of computation or data filtering to be done at the sensor nodes before transmitting data to the sink node. Unfortunately, the authors only studied the effects of data filtering tuning on energy consumption and did not consider other sensor node parameters and application requirements.
Some previous and current work investigates EWSN operation in changing application (mission) requirements and environmental stimuli. Marrón et al. [303] presented an adaptive cross-layer architecture TinyCubus for TinyOS-based sensor networks that allowed dynamic management of components (e.g., caching, aggregation, broadcast strategies) and reliable code distribution considering EWSN topology. TinyCubus considered optimization parameters (e.g., energy, communication latency, and bandwidth), application requirements (e.g., reliability), and system parameters (e.g., mobility). The system parameters selected the best set of components based on current application requirements and optimization parameters. Vecchio [304] discussed adaptability in EWSNs at three different levels: communication level (by tuning the communication scheme), application level (by software changes), andhardware level (by injecting new sensor nodes). The International Technology Alliance (ITA) in Network and Information Sciences, sponsored by the UK Ministry of Defense (MoD) and US Army Research Laboratory (ARL), investigates task reassignment and reconfiguration (including physical movement of sensor nodes or reprocessing of data) of already deployed sensor nodes in the sensor field in response to current or predicted future conditions to provide the expected sensed information at a sufficient quality [305]. However, ITA current projects, to the best of our knowledge, do not consider sensor node parameter tuning, and our MDP-based parameter tuning can optimize EWSN operation in changing application requirements.
Several papers explored DVFS for reduced energy consumption. Pillai and Shin [306] proposed real-time dynamic voltage scaling (RT-DVS) algorithms capable of modifying the operating systems' real-time scheduler and task management service for reduced energy consumption. Childers et al. [307] proposed a technique for adjusting supply voltage and frequency at runtime to conserve energy. Their technique monitored a program's instruction-level parallelism (ILP) and adjusted processor voltage and speed in response to the current ILP. Their proposed technique allowed users to specify performance constraints, which the hardware maintained while running at the lowest energy consumption.
Liu and Svensson [308] investigated reducing processor speed by varying the supply and threshold voltages for low power consumption in complementary metal-oxide-semiconductor (CMOS) very-large-scale integration (VLSI). Results showed that an optimized threshold voltage revealed an 8![]() power savings without any negative performance impacts. In addition, significantly greater energy savings could be achieved by reducing processor speed in tandem with threshold voltage. Burd et al. [309] presented a microprocessor system that dynamically varied its supply voltage and clock frequency to deliver high throughput during critical high-speed execution periods and extended battery life during low-speed execution periods. Results revealed that dynamic voltage scaling (DVS) could improve energy efficiency by 10
power savings without any negative performance impacts. In addition, significantly greater energy savings could be achieved by reducing processor speed in tandem with threshold voltage. Burd et al. [309] presented a microprocessor system that dynamically varied its supply voltage and clock frequency to deliver high throughput during critical high-speed execution periods and extended battery life during low-speed execution periods. Results revealed that dynamic voltage scaling (DVS) could improve energy efficiency by 10![]() for battery-powered processor systems without sacrificing peak throughput.
for battery-powered processor systems without sacrificing peak throughput.
Min et al. [225] demonstrated that DVS in a sensor node's processor reduced energy consumption. Their technique used a voltage scheduler, running in tandem with the operating system's task scheduler, to adjust voltage and frequency based on a priori knowledge of the predicted sensor node's workload. Yuan and Qu [226] studied a DVFS system for sensor nodes, which required sensor nodes sending data to insert additional information into a transmitted data message's header such as the packet length, expected processing time, and deadline. The receiving sensor node used this message information to select an appropriate processor voltage and frequency to minimize the overall energy consumption.
Some previous works in EWSN optimizations explored greedy andsimulated annealing (SA)-based methods. Lysecky and Vahid [310] proposed an SA-based automated application-specific tuning of parameterized sensor-based embedded systems and found that automated tuning can improve EWSN operation by 40% on average. Verma [311] studied SA and particle swarm optimization (PSO) methods for automated application-specific tuning and observed that SA performed better than PSO because PSO often quickly converged to local minima. In prior work, Munir et al. [312] proposed greedy-based and simulated annealing (SA)-based algorithms for parameter tuning. Greedy- and SA-based algorithms are lightweight, whereas these algorithms do not ensure convergence to an optimal solution.
There exists previous work related to DVFS and several initiatives toward application-specific tuning were taken. Nevertheless, the literature presents no mechanisms to determine a dynamic tuning policy for sensor node parameters in accordance with changing application requirements. To the best of our knowledge, we propose the first methodology to address EWSN dynamic optimizations with the goal of meeting application requirements in a dynamic environment.
8.2 MDP-Based Tuning Overview
In this section, we present our MDP-based tuning methodology along with an MDP overview with respect to EWSNs [137].
8.2.1 MDP-Based Tuning Methodology for Embedded Wireless Sensor Networks
Figure 8.1 depicts the process diagram for our MDP-based application-oriented dynamic tuning methodology. Our methodology consists of three logical domains: the application characterization domain, the communication domain, and the sensor node tuning domain.

Figure 8.1 Process diagram for our MDP-based application-oriented dynamic tuning methodology for embedded wireless sensor networks
The application characterization domain refers to the EWSN application's characterization/specification. In this domain, the application manager defines various application metrics (e.g., tolerable power consumption, tolerable delay), which are calculated from (or based on) application requirements. The application manager also assigns weight factors to application metrics to signify the weightage or importance of each application metric. Weight factors provide application managers with an easy method to relate the relative importance of each application metric. The application manager defines an MDP reward function, which signifies the overall reward (revenue) for given application requirements. The application metrics along with the associated weight factors represents the MDP reward function parameters.
The communication domain contains the sink node (which gathers statistics from the embedded sensor nodes) and encompasses the communication network between the application manager and the sensor nodes. The application manager transmits the MPD reward function parameters to the sink node via the communication domain. The sink node in turn relays reward function parameters to the embedded sensor nodes.
The sensor node tuning domain consists of embedded sensor nodes and performs sensor node tuning. Each sensor node contains an MDP controller module, which implements our MDP-based tuning methodology (summarized here and described in detail in Section 8.3). After an embedded sensor node receives reward function parameters from the sink node through the communication domain, the sensor node invokes the MDP controller module. The MDP controller module calculates the MDP-based policy. The MDP-based policy prescribes the sensor node actions to meet application requirements over the lifetime of the sensor node. An action prescribes the sensor node state (defined by processor voltage, processor frequency, and sensing frequency) to transition from the current state. The sensor node identifies its current operating state, determines an action “![]() ” prescribed by the MDP-based policy (i.e., whether to continue operation in the current state or transition to another state), and subsequently executes action “
” prescribed by the MDP-based policy (i.e., whether to continue operation in the current state or transition to another state), and subsequently executes action “![]() .”
.”
Our proposed MDP-based dynamic tuning methodology can adapt to changes in application requirements (since application requirements may change with time, for example, a defense system initially deployed to monitor enemy troop position for 4 months may later be required to monitor troop activity for an extended period of 6 months). Whenever application requirements change, the application manager updates the reward function (and/or associated parameters) to reflect the new application requirements. Upon receiving the updated reward function, the sensor node reinvokes MDP controller module and determines the new MDP-based policy to meet the new application requirements.
Our MDP-based application-oriented dynamic tuning methodology reacts to environmental stimuli via a dynamic profiler module in the sensor node tuning domain. The dynamic profiler module monitors environmentalchanges over time and captures unanticipated environmental situations not predictable at design time [300]. The dynamic profiler module may be connected to the sensor node and profiles the profiling statistics (e.g., wireless channel condition, number of packets dropped, packet size, radio transmission power) when triggered by the EWSN application. The dynamic profiler module informs the application manager of the profiled statistics via the communication domain. After receiving the profiling statistics, the application manager evaluates the statistics and possibly updates the reward function parameters. This reevaluation process may be automated, thus eliminating the need for continuous application manager input. Based on these received profiling statistics and updated reward function parameters, the sensor node MDP controller module determines whether application requirements are met or not met. If application requirements are not met, the MDP controller module reinvokes the MDP-based policy to determine a new operating state to better meet application requirements. This feedback process continues to ensure that the application requirements are met in the presence of changing environmental stimuli.
Algorithm 3 depicts our MDP-based dynamic tuning methodology in an algorithmic form, which applies to all embedded sensor nodes in the WSN (line 1) and spans the entire lifetime of the embedded sensor nodes (line 2). The algorithm determines an MDP-based policy ![]() according to the application's initial requirements (captured by the MDP reward function parameters) at the time of EWSN deployment (lines 3 and 4). The algorithm determines a new MDP-based policy to adapt to the changing application requirements (lines 6 and 7). After determining
according to the application's initial requirements (captured by the MDP reward function parameters) at the time of EWSN deployment (lines 3 and 4). The algorithm determines a new MDP-based policy to adapt to the changing application requirements (lines 6 and 7). After determining ![]() , the algorithm specifies the action
, the algorithm specifies the action ![]() according to
according to ![]() for each embedded sensor node state
for each embedded sensor node state ![]() , given the total number of states
, given the total number of states ![]() (lines 9–17).
(lines 9–17).
8.2.2 MDP Overview with Respect to Embedded Wireless Sensor Networks
In this section, we define basic MDP terminology in the context of EWSNs and give an overview of our proposed MDP-based dynamic tuning policy formulation for embedded sensor nodes. MDPs, also known as stochastic dynamic programming, are used to model and solve dynamic decision-making problems. We use standard notations as defined in [313] for our MDP-based problem formulation. Table 8.1 presents a summary of key notations used in this chapter.
Table 8.1 Summary of MDP notations
| Notation | Description |
| Sensor node state | |
| State space | |
| Number of decision epochs | |
| Number of sensor node state tuples | |
| Reward at time |
|
| Action to transition from state |
|
| Allowable actions in state |
|
| Transition probability function | |
| Expected reward of policy |
|
| Discount factor | |
| Expected total reward | |
| Expected total discounted reward | |
| Maximum expected total discounted reward | |
| Optimal decision rule | |
| Decision rule at time |
|
| Optimal policy | |
| MDP-based policy |
The basic elements of an MDP model are decision epochs and periods, states, action sets, transition probabilities, and rewards. An MDP is Markovian (memoryless) because the transition probabilities and rewards depend on the past only through the current state and the action selected by the decision maker in that state. The decision epochs refer to the points of time during a sensor node's lifetime at which the sensor node makes a decision. Specifically, a sensor node makes a decision regarding its operating state atthese decision epochs (i.e., whether to continue operating at the current state (processor voltage, frequency, and sensing frequency) or transition to another state). We consider a discrete time process where time is divided into periods and a decision epoch corresponds to the beginning of a period. The set of decision epochs can be denoted as ![]() , where
, where ![]() and denotes the sensor node's lifetime (each individual time period in
and denotes the sensor node's lifetime (each individual time period in ![]() can be denoted as time
can be denoted as time ![]() ). The decision problem is referred to as a finite horizon problem when the decision-making horizon
). The decision problem is referred to as a finite horizon problem when the decision-making horizon ![]() is finite and infinite horizon otherwise. In a finite horizon problem, the final decision is made at decision epoch
is finite and infinite horizon otherwise. In a finite horizon problem, the final decision is made at decision epoch ![]() ; hence, the finite horizon problem is also known as the
; hence, the finite horizon problem is also known as the ![]() period problem.
period problem.

The system (a sensor node) operates in a particular state at each decision epoch, where ![]() denotes the complete set of possible system states. States specify particular sensor node parameter values and each state represents a different combination of these values. An action set represents all allowable actions in all possible states. At each decision epoch, the sensor node decides whether to continue operating in the current state or to switch to another state. The sensor node state (in our problem) represents a tuple consisting of processor voltage (
denotes the complete set of possible system states. States specify particular sensor node parameter values and each state represents a different combination of these values. An action set represents all allowable actions in all possible states. At each decision epoch, the sensor node decides whether to continue operating in the current state or to switch to another state. The sensor node state (in our problem) represents a tuple consisting of processor voltage (![]() ), processor frequency (
), processor frequency (![]() ), and sensing frequency (
), and sensing frequency (![]() ). If the system is in state
). If the system is in state ![]() at a decision epoch, the sensor node can choose an action
at a decision epoch, the sensor node can choose an action ![]() from the set of allowable actions
from the set of allowable actions ![]() in state
in state ![]() . Thus, an action set can be written as
. Thus, an action set can be written as ![]() . We assume that
. We assume that ![]() and
and ![]() do not vary with time
do not vary with time ![]() [313].
[313].
When a sensor node selects action ![]() in state
in state ![]() , the sensor node receives a reward
, the sensor node receives a reward ![]() and the transition probability distribution
and the transition probability distribution ![]() determines the system state at the next decision epoch. The real-valued function
determines the system state at the next decision epoch. The real-valued function ![]() denotes the value of the reward received at time
denotes the value of the reward received at time ![]() in period
in period ![]() . The reward is referred to as income or cost depending on whether or not
. The reward is referred to as income or cost depending on whether or not ![]() is positive or negative, respectively. When the reward depends on the system state at the next decision epoch, we let
is positive or negative, respectively. When the reward depends on the system state at the next decision epoch, we let ![]() denote the value of the reward received at time
denote the value of the reward received at time ![]() when the system state at decision epoch
when the system state at decision epoch ![]() is
is ![]() . The sensor node selects action
. The sensor node selects action ![]() , and the system occupies the state
, and the system occupies the state ![]() at decision epoch
at decision epoch ![]() . The sensor node evaluates
. The sensor node evaluates ![]() using [313]
using [313]
where the nonnegative function ![]() is called a transition probability function.
is called a transition probability function. ![]() denotes the probability that the system occupies state
denotes the probability that the system occupies state ![]() at time
at time ![]() when the sensor node selects action
when the sensor node selects action ![]() in state
in state ![]() at time
at time ![]() and usually
and usually ![]() . Formally, an MDP is defined as the collection of objects
. Formally, an MDP is defined as the collection of objects ![]() .
.
A decision rule prescribes an action in each state at a specified decision epoch. Our decision rule for sensor nodes is a function ![]() , which specifies the action at time
, which specifies the action at time ![]() when the system is in state
when the system is in state ![]() for each
for each ![]() ,
, ![]() . This decision rule is both Markovian and deterministic.
. This decision rule is both Markovian and deterministic.
A policy specifies the decision rule for all decision epochs. In the case of sensor nodes, the policy prescribes action selection under any possible system state. A policy ![]() is a sequence of decision rules, that is,
is a sequence of decision rules, that is, ![]() for
for ![]() . A policy is stationary if
. A policy is stationary if ![]() , that is, for stationary policy
, that is, for stationary policy ![]() .
.
As a result of selecting and implementing a particular policy, the sensor node receives rewards at time periods ![]() . The reward sequence is random because therewards received in different periods are not known prior to policy implementation. The sensor node's optimization objective is to determine a policy that maximizes the corresponding random reward sequence.
. The reward sequence is random because therewards received in different periods are not known prior to policy implementation. The sensor node's optimization objective is to determine a policy that maximizes the corresponding random reward sequence.
8.3 Application-Specific Embedded Sensor Node Tuning Formulation as an MDP
In this section, we describe the formulation of our embedded sensor node application-specific DVFS2 tuning as an MDP. We formulate MDP-based policy constructs (i.e., state space, decision epochs, actions, state dynamics, policy, performance criterion, and reward function) for our system. We also introduce optimality equations and the policy iteration algorithm.
8.3.1 State Space
The state space for our MDP-based tuning methodology is a composite state space containing the Cartesian product of embedded sensor node tunable parameters' state spaces. We define the state space ![]() as
as
where ![]() denotes the Cartesian product,
denotes the Cartesian product, ![]() is the total number of sensor node tunable parameters,
is the total number of sensor node tunable parameters, ![]() denotes the state space for tunable parameter
denotes the state space for tunable parameter ![]() where
where ![]() , and
, and ![]() denotes the state space
denotes the state space ![]() cardinality (the number of states in
cardinality (the number of states in ![]() ).
).
The tunable parameter ![]() 's state space (
's state space (![]() )
) ![]() consists of
consists of ![]() values
values
where ![]() denotes the tunable parameter
denotes the tunable parameter ![]() 's state space cardinality (the number of tunable values in
's state space cardinality (the number of tunable values in ![]() ).
). ![]() is a set of
is a set of ![]() -tuples where each
-tuples where each ![]() -tuple represents a sensor node state
-tuple represents a sensor node state ![]() . Each state
. Each state ![]() is an
is an ![]() -tuple, that is,
-tuple, that is, ![]() . Note that some
. Note that some ![]() -tuples in
-tuples in ![]() may not be feasible (e.g., all processor voltage and frequency pairs are not feasible) and can be regarded as do not care tuples.
may not be feasible (e.g., all processor voltage and frequency pairs are not feasible) and can be regarded as do not care tuples.
Each embedded sensor node state has an associated power consumption, throughput, and delay. The power, throughput, and delay for state ![]() are denoted by
are denoted by ![]() ,
, ![]() , and
, and ![]() , respectively. Since different sensor nodes may have different embedded processors and attached sensors, each node may have node-specific power consumption, throughput, and delay information for each state.
, respectively. Since different sensor nodes may have different embedded processors and attached sensors, each node may have node-specific power consumption, throughput, and delay information for each state.
8.3.2 Decision Epochs and Actions
Embedded sensor nodes make decisions at decision epochs, which occur after fixed time periods. The sequence of decision epochs is represented as
where the random variable ![]() corresponds to the embedded sensor node's lifetime.
corresponds to the embedded sensor node's lifetime.
At each decision epoch, a sensor node's action determines the next state to transition to the given current state. The sensor node action in state ![]() is defined as
is defined as
where ![]() denotes the action taken at time
denotes the action taken at time ![]() that causes the sensor node to transition to state
that causes the sensor node to transition to state ![]() at time
at time ![]() from the current state
from the current state ![]() . A policy determines whether an action is taken or not. If
. A policy determines whether an action is taken or not. If ![]() , the action is taken and if
, the action is taken and if ![]() , the action is not taken. For a given state
, the action is not taken. For a given state ![]() , a selected action cannot result in a transition to a state that is not in
, a selected action cannot result in a transition to a state that is not in ![]() . The action space can be defined as
. The action space can be defined as
8.3.3 State Dynamics
The state dynamics of the system can be delineated by the state transition probabilities of the embedded Markov chain. We formulate our sensor node policy as a deterministic dynamic program (DDP) because the choice of an action determines the subsequent state with certainty. Our sensor node DDP policy formulation uses a transfer function to specify the next state. A transfer function defines a mapping ![]() from
from ![]() , which specifies the system state at time
, which specifies the system state at time ![]() when the sensor node selects action
when the sensor node selects action ![]() in state
in state ![]() at time
at time ![]() . To formulate our DDP as an MDP, we define the transition probability function as
. To formulate our DDP as an MDP, we define the transition probability function as
8.3.4 Policy and Performance Criterion
For each given state ![]() , a sensor node selects an action
, a sensor node selects an action ![]() according to a policy
according to a policy ![]() where
where ![]() is a set of admissible policies defined as
is a set of admissible policies defined as
A performance criterion compares the performance of different policies. The sensor node selects an action prescribed by a policy based on the sensor node's current state. If the random variable ![]() denotes the state at decision epoch
denotes the state at decision epoch ![]() and the random variable
and the random variable ![]() denotes the action selected at decision epoch
denotes the action selected at decision epoch ![]() , then for the deterministic case,
, then for the deterministic case, ![]() .
.
As a result of selecting an action, the sensor node receives a reward ![]() at time
at time ![]() . The expected total reward denotes the expected total reward over the decision-making horizon given a specific policy. Let
. The expected total reward denotes the expected total reward over the decision-making horizon given a specific policy. Let ![]() denote the expected totalreward over the decision-making horizon when the horizon length
denote the expected totalreward over the decision-making horizon when the horizon length ![]() is a random variable, the system is in state
is a random variable, the system is in state ![]() at the first decision epoch, and policy
at the first decision epoch, and policy ![]() is used [300, 314]
is used [300, 314]
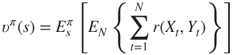
where ![]() represents the expected reward with respect to policy
represents the expected reward with respect to policy ![]() and the initial state
and the initial state ![]() (the system state at the time of the expected reward calculation), and
(the system state at the time of the expected reward calculation), and ![]() denotes the expected reward with respect to the probability distribution of the random variable
denotes the expected reward with respect to the probability distribution of the random variable ![]() . We can write Eq. (8.9) as [313]
. We can write Eq. (8.9) as [313]

which gives the expected total discounted reward. We assume that the random variable ![]() is geometrically distributed with parameter
is geometrically distributed with parameter ![]() , and hence the distribution mean is
, and hence the distribution mean is ![]() [299]. The parameter
[299]. The parameter ![]() can be interpreted as a discount factor, which measures the present value of one unit of reward received for one period in the future. Thus,
can be interpreted as a discount factor, which measures the present value of one unit of reward received for one period in the future. Thus, ![]() represents the expected total present value of the reward (income) stream obtained using policy
represents the expected total present value of the reward (income) stream obtained using policy ![]() [313]. Our objective is to find a policy that maximizes the expected total discounted reward, that is, a policy
[313]. Our objective is to find a policy that maximizes the expected total discounted reward, that is, a policy ![]() is optimal if
is optimal if
8.3.5 Reward Function
The reward function captures application metrics and sensor node characteristics. Our reward function characterization considers the power consumption (which affects the sensor node's lifetime), throughput, and delay application metrics. We define the reward function ![]() , given the current sensor node state
, given the current sensor node state ![]() and the sensor node's selected action
and the sensor node's selected action ![]() as
as
where ![]() denotes the power reward function;
denotes the power reward function; ![]() denotes the throughput reward function;
denotes the throughput reward function; ![]() denotes the delay reward function; and
denotes the delay reward function; and ![]() ,
, ![]() , and
, and ![]() represent the weight factors for power, throughput, and delay, respectively. The weight factors' constraints are given as
represent the weight factors for power, throughput, and delay, respectively. The weight factors' constraints are given as ![]() where
where ![]() such that
such that ![]() ,
, ![]() , and
, and ![]() . The weight factors are selected based on the relative importance of application metrics with respect to each other, for example, a habitat monitoring application taking camera images of the habitat requires a minimum image resolution to provide meaningful analysis that necessitates a minimum throughput, and therefore throughput can be assigned a higher weight factor than the power metric for this application.
. The weight factors are selected based on the relative importance of application metrics with respect to each other, for example, a habitat monitoring application taking camera images of the habitat requires a minimum image resolution to provide meaningful analysis that necessitates a minimum throughput, and therefore throughput can be assigned a higher weight factor than the power metric for this application.
We define linear reward functions for application metrics because an application metric reward (objective function) typically varies linearly, or piecewise linearly, between the minimum and the maximum allowed values of the metric [300, 311]. However, a nonlinear characterization of reward functions is also possible and depends on the particular application. We point out that our methodology works for any characterization of reward function. The reward function characterization only defines the reward obtained from operating in a given state. Our MDP-based policy determines the reward by selecting an optimal/suboptimal operating state, given the sensor node design space and application requirements for any reward function characterization. We consider linear reward functions as a typical example from the space of possible reward functions (e.g., piecewise linear, nonlinear) to illustrate our MDP-based policy. We define the power reward function (Fig. 8.2(a)) in Eq. (8.12) as

where ![]() denotes the power consumption of the current state given action
denotes the power consumption of the current state given action ![]() taken at time
taken at time ![]() , and the constant parameters
, and the constant parameters ![]() and
and ![]() denote the minimum and maximum allowed/tolerated sensor node power consumption, respectively.
denote the minimum and maximum allowed/tolerated sensor node power consumption, respectively.

Figure 8.2 Reward functions: (a) power reward function  ; (b) throughput reward function
; (b) throughput reward function  ; (c) delay reward function
; (c) delay reward function 
We define the throughput reward function (Fig. 8.2(b)) in Eq. (8.12) as

where ![]() denotes the throughput of the current state given action
denotes the throughput of the current state given action ![]() taken at time
taken at time ![]() and the constant parameters
and the constant parameters ![]() and
and ![]() denote the minimum and maximum allowed/tolerated throughput, respectively.
denote the minimum and maximum allowed/tolerated throughput, respectively.
We define the delay reward function (Fig. 8.2(c)) in Eq. (8.12) as

where ![]() denotes the delay in the current state and the constant parameters
denotes the delay in the current state and the constant parameters ![]() and
and ![]() denote the minimum and maximum allowed/tolerated delay, respectively.
denote the minimum and maximum allowed/tolerated delay, respectively.
State transitioning incurs a cost associated with switching parameter values from the current state to the next state (typically in the form of power and/or execution overhead). We define the transition cost function ![]() as
as
where ![]() denotes the transition cost to switch from the current state
denotes the transition cost to switch from the current state ![]() to the next state as determined by action
to the next state as determined by action ![]() . Note that a sensor node incurs no transition cost if action
. Note that a sensor node incurs no transition cost if action ![]() prescribes that the next state is the same as the current state.
prescribes that the next state is the same as the current state.
Hence, the overall reward function ![]() given state
given state ![]() and action
and action ![]() at time
at time ![]() is
is
which accounts for the power, throughput, and delay application metrics as well as state transition cost.
We point out that many other application metrics (e.g., security, reliability, and lifetime) are of immense significance to EWSNs. For example, EWSNs are vulnerable to security attacks such as distributed denial of service and Sybil attacks for which a security reward function can be included. A reliability reward function can encompass the reliability aspect of EWSNs since sensor nodes are often deployed in unattended and hostile environments and are susceptible to failures. Similarly, considering sensor nodes' constrained battery resources, power optimization techniques exist that put sensor nodes in sleep or low-power mode (where communication and/or processing functions are disabled) for power conservation when less activity is observed in the sensed region as determined by previously sensed data. These power optimizations can be captured by a lifetime reward function. These additional metrics incorporation in our model is the focus of our future work.
8.3.6 Optimality Equation
The optimality equation, also known as Bellman's equation, for expected total discounted reward criterion is given as [313]

where ![]() denotes the maximum expected total discounted reward. The following are the salient properties of the optimality equation: the optimality equation has a unique solution; an optimal policy exists in given conditions on states, actions, rewards, and transition probabilities; the value of the discounted MDP satisfies the optimality equation; and the optimality equation characterizes stationary policies.
denotes the maximum expected total discounted reward. The following are the salient properties of the optimality equation: the optimality equation has a unique solution; an optimal policy exists in given conditions on states, actions, rewards, and transition probabilities; the value of the discounted MDP satisfies the optimality equation; and the optimality equation characterizes stationary policies.
The solution of Eq. (8.18) gives the maximum expected total discounted reward ![]() and the MDP-based policy
and the MDP-based policy ![]() , which gives the maximum
, which gives the maximum ![]() .
. ![]() prescribes the action
prescribes the action ![]() from action set
from action set ![]() , given the current state
, given the current state ![]() for all
for all ![]() . There are several methods to solve the optimality equation (8.18) such as value iteration, policy iteration, and linear programming; however, in this work, we use the policy iteration algorithm.
. There are several methods to solve the optimality equation (8.18) such as value iteration, policy iteration, and linear programming; however, in this work, we use the policy iteration algorithm.
8.3.7 Policy Iteration Algorithm
The policy iteration algorithm can be described in four steps:
- 1. Set
 and choose any arbitrary decision rule
and choose any arbitrary decision rule  where
where  is a set of all possible decision rules.
is a set of all possible decision rules. - 2. Policy evaluation—Obtain
 by solving the equations:8.19
by solving the equations:8.19 
- 3. Policy improvement—Select
 to satisfy the equations:
8.20
to satisfy the equations:
8.20
and setting
 if possible.
if possible. - 4. If
 , stop and set
, stop and set  where
where  denotes the optimal decision rule. If
denotes the optimal decision rule. If  , set
, set  and go to step 2.
and go to step 2.
Step 2 is referred to as policy evaluation because, by solving Eq. (8.19), we obtain the expected total discounted reward for decision rule ![]() . Step 3 is referred to as policy improvement because this step selects a
. Step 3 is referred to as policy improvement because this step selects a ![]() -improving decision rule. In step 4,
-improving decision rule. In step 4, ![]() quells cycling because a decision rule is not necessarily unique.
quells cycling because a decision rule is not necessarily unique.
8.4 Implementation Guidelines and Complexity
In this section, we describe the implementation guidelines and computational complexity for our proposed MDP-based policy. The implementation guidelines describe the mapping of MDP specifications (e.g., state space, reward function) in our problem formulation (Section 8.3) to actual sensor node hardware. The computational complexity focuses on the convergence of the policy iteration algorithm and the data memory analysis for our MDP-based dynamic tuning methodology. The prototype implementation of our MDP-based tuning methodology on hardware sensor platforms is the focus of our future work.
8.4.1 Implementation Guidelines
In order to implement our MDP-based policy, particular values must be initially defined. The reward function Eq. (8.17) uses the power, throughput, and delay values offered in an embedded sensor node state ![]() (Section 8.3.1). An application manager specifies the minimum and maximum power, throughput, and delay values required by Eq. (8.13)–(8.15), respectively, and the power, throughput, and delay weight factors required in Eq. (8.12) according to application specifications.
(Section 8.3.1). An application manager specifies the minimum and maximum power, throughput, and delay values required by Eq. (8.13)–(8.15), respectively, and the power, throughput, and delay weight factors required in Eq. (8.12) according to application specifications.
A sensor node's embedded processor defines the transition cost ![]() as required in Eq. (8.16), which is dependent on a particular processor's power management and switching techniques. Processors have a set of available voltage and frequency pairs, which defines the
as required in Eq. (8.16), which is dependent on a particular processor's power management and switching techniques. Processors have a set of available voltage and frequency pairs, which defines the ![]() and
and ![]() values, respectively, in a sensor node state tuple (Section 8.3.1). Embedded sensors can operate at different defined sensing rates, which define the
values, respectively, in a sensor node state tuple (Section 8.3.1). Embedded sensors can operate at different defined sensing rates, which define the ![]() value in a sensor node state tuple (Section 8.3.1). The embedded processor and sensor characteristics determine the value of
value in a sensor node state tuple (Section 8.3.1). The embedded processor and sensor characteristics determine the value of ![]() , which characterizes the state space in Eq. (8.2) (i.e., the number of allowable processor voltage, processor frequency, and sensing frequency values determine the total number of sensor node operating states, and thus the value of
, which characterizes the state space in Eq. (8.2) (i.e., the number of allowable processor voltage, processor frequency, and sensing frequency values determine the total number of sensor node operating states, and thus the value of ![]() ).
).
The sensor nodes perform parameter tuning decisions at decision epochs (Section 8.2.2). The decision epochs can be guided by the dynamic profiler module to adapt to the environmental stimuli. For instance, for a target-tracking application and a fast-moving target, the decision epoch period should be small to better capture the fast-moving target. On the other hand, for stationary or slow-moving targets, decision epoch period should be large to conserve battery energy. However, since the exact decision epoch period is application specific, the period should be adjusted to control the sensor node's lifetime.
Both the MDP controller module (which implements the policy iteration algorithm to calculate the MDP-based policy ![]() ) and the dynamic profiler module (Section 8.2.1) can either be implemented as software running on a sensor node's embedded processor or custom hardware for faster execution.
) and the dynamic profiler module (Section 8.2.1) can either be implemented as software running on a sensor node's embedded processor or custom hardware for faster execution.
One of the drawbacks for MDP-based policy is that computational and storage overhead increases as the number of states increases. Therefore, EWSN designer would like to restrict the embedded sensor states (e.g., 2, 4, or 16) to reduce the computational and storage overhead. If state restriction is not a viable option, the EWSN configuration could be augmented with a back-end base station node to run our MDP-based optimization, and the sensor node operating states would be communicated to the sensor nodes. This communication of operating state information to sensor nodes by the base station node would not consume enough power resources, given that this state information is transmitted periodically and/or aperiodically after some minimum duration determined by the agility of the environmental stimuli (e.g., more frequent communication would be required for a rapidly changing environmental stimuli as opposed to a slow changing environmental stimuli). This EWSN configuration could also consider global optimizations, which are optimizations that take into account sensor node interactions and dependencies and is a focus of our future work. We point out that global optimization storage and processing overhead increases rapidly as the number of sensor nodes in EWSN increases.
8.4.2 Computational Complexity
Since sensor nodes have limited energy reserves and processing resources, it is critical to analyze our proposed MDP-based policy's computational complexity, which is related to the convergence of the policy iteration algorithm. Since our problem formulation (Section 8.3) consists of finite states and actions, Puterman [313] proves a theorem that establishes the convergence of the policy iteration algorithm for finite states and actions in a finite number of iterations. Another important computational complexity factor is the algorithm's convergence rate. Puterman [313] shows that for a finite number of states and actions, the policy iteration algorithm converges to the optimal/suboptimal value function at least quadratically fast. Empirical observations suggest that the policy iteration algorithm can converge in ![]() iterations where each iteration takes
iterations where each iteration takes ![]() time (for policy evaluation); however, no proof yet exists to verify these empirical observations [314]. Based on these empirical observations for convergence, policy iteration algorithm can converge in four iterations for
time (for policy evaluation); however, no proof yet exists to verify these empirical observations [314]. Based on these empirical observations for convergence, policy iteration algorithm can converge in four iterations for ![]() .
.
8.4.3 Data Memory Analysis
We performed data memory analysis using the 8-bit Atmel ATmega128L microprocessor [192] in XSM sensor nodes [315]. The Atmel ATmega128L microprocessor contains 128 KB of on-chip in-system reprogrammable Flash memory for program storage, 4 KB of internal SRAM data memory, and up to 64 KB of external SRAM data memory. Integer and floating-point data types require 2 and 4 B of storage, respectively. Our data memory analysis considers all storage requirements for our MDP-based dynamic tuning formulation (Section 8.3) including state space, action space, state dynamics (transition probability matrix), Bellman's equation (8.18), MDP reward function calculation (reward matrix), and policy iteration algorithm. We estimate data memory size for three sensor node configurations:
- 4 sensor node states with 4 allowable actions in each state (16 actions in the action space) (Fig. 8.4);
- 8 sensor node states with 8 allowable actions in each state (64 actions in the action space);
- 16 sensor node states with 16 allowable actions in each state (256 actions in the action space).

Figure 8.4 Symbolic representation of our MDP model with four sensor node states
Data memory analysis revealed that 4, 8, and 16 sensor node state configurations required approximately 1.55, 14.8, and 178.55 KB, respectively. Thus, currently available sensor node platforms contain enough memory resources to implement our MDP-based dynamic tuning methodology with 16 sensor node states or fewer. However, the memory requirements increase rapidly as the number of states increases due to the transition probability matrix and reward matrix specifications. Therefore, depending on the available memory resources, an application developer could restrict the number of states accordingly or otherwise would have to resort to doing computations on the back-end base station as outlined in Section 8.4 to conserve power and storage.
8.5 Model Extensions
Our proposed MDP-based dynamic tuning methodology for EWSNs is highly adaptive to different EWSN characteristics and particulars, including additional sensor node tunable parameters (e.g., radio transmission power) and application metrics (e.g., reliability). Furthermore, our problem formulation can be extended to form MDP-based stochastic dynamic programs. Our current MDP-based dynamic optimization methodology provides a basis for MDP-based stochastic dynamic optimization that would react to the changing environmental stimuli and wireless channel conditions to autonomously switch to an appropriate operating state. This stochastic dynamic optimization would provide a major incentive to use an MDP-based policy (because of the capability of MDP to formulate stochastic dynamic programs) as opposed to using lightweight heuristic policies (e.g., greedy or simulated annealing based) for parameter tuning that can determine appropriate operating state out of a large state space without requiring large computational and memory resources [316].
To exemplify additional tuning parameters, we consider a sensor node's transceiver (radio) transmission power. The extended state space can be written as
where ![]() denotes the state space for a sensor node's radio transmission power.
denotes the state space for a sensor node's radio transmission power.
We define the sensor node's radio transmission power state space ![]() as
as
where ![]() denotes a radio transmission power,
denotes a radio transmission power, ![]() denotes the number of radio transmission power values, and
denotes the number of radio transmission power values, and ![]() denotes the radio transmission power state space cardinality.
denotes the radio transmission power state space cardinality.
To exemplify the inclusion of additional application metrics, we consider reliability, which measures the reliability of sensed data, such as the total number of sensed data packets received at the sink node without error in an arbitrary time window. The reliability can be interpreted as the packet reception rate, which is the complement of the packet error rate (PER) [24]. The factors that affect reliability include wireless channel condition, network topology, traffic patterns, and the physical phenomenon that triggered the sensor node communication activity [24]. In general, the wireless channel condition has the most affect on the reliability metric because sensed data packets may experience different error rates depending on the channel condition. A sensor node may maintain application-specified reliability in different wireless channel conditions by tuning/changing the error correcting codes, modulation schemes, and/or transmission power. The dynamic profiler module in our proposed tuning methodology helps estimating the reliability metric at runtime by profiling the number of packet transmissions from each sensor node and the number of packet receptions at the sink node.
The sensor node's reliability can be added to the reward function and the extended reward function can be written as
where ![]() denotes the reliability reward function,
denotes the reliability reward function, ![]() represents the weight factor for reliability, and the remainder of the terms in Eq. (8.23) has the same meaning as in Eq. (8.12). The weight factors' constraints are given as
represents the weight factor for reliability, and the remainder of the terms in Eq. (8.23) has the same meaning as in Eq. (8.12). The weight factors' constraints are given as ![]() where
where ![]() such that
such that ![]() ,
, ![]() ,
, ![]() , and
, and ![]() .
.
The reliability reward function (Fig. 8.3(a)) in Eq. (8.23) can be defined as

where ![]() denotes the reliability offered in the current state given action
denotes the reliability offered in the current state given action ![]() taken at time
taken at time ![]() and the constant parameters
and the constant parameters ![]() and
and ![]() denote the minimum and maximum allowed/tolerated reliability, respectively. The reliability may be represented as a multiple of a base reliability unit equal to 0.1, which represents a 10% packet reception rate [24].
denote the minimum and maximum allowed/tolerated reliability, respectively. The reliability may be represented as a multiple of a base reliability unit equal to 0.1, which represents a 10% packet reception rate [24].

Figure 8.3 Reliability reward functions: (a) linear variation; (b) quadratic variation
The reward function capturing an application's metrics can be defined according to particular application requirements, and may vary quadratically (Fig. 8.3(b)) instead of linearly (as defined earlier) over the minimum and maximum allowed parameter values and can be expressed as

Thus, our proposed MDP-based dynamic tuning methodology works with any reward function formulation.
Currently, our problem formulation considers a DDP with fixed states and state transition probabilities equal to 1 (Section 8.3.3); however, our formulation can be extended to form stochastic dynamic programs with different state transition probabilities [317]. One potential extension could include environmental stimuli and wireless channel condition in the state space. The environmental stimuli and wireless channel condition vary with time and have a different probability of being in a certain state at a given point in time. For instance, considering the wireless channel condition along with the sensor node state, the state space vector ![]() can be given as
can be given as

where ![]() and
and ![]() represent sensor state and wireless channel state at time
represent sensor state and wireless channel state at time ![]() assuming that there are
assuming that there are ![]() total sensor states and
total sensor states and ![]() total wireless channel states. The state dynamics could be given by
total wireless channel states. The state dynamics could be given by ![]() , which denotes the probability that the system occupies state
, which denotes the probability that the system occupies state ![]() in
in ![]() time units given
time units given ![]() and
and ![]() . If the wireless channel condition does not change state with time, then
. If the wireless channel condition does not change state with time, then ![]() thus forming a DDP. The determination of
thus forming a DDP. The determination of ![]() requires probabilistic modeling of wireless channel condition over time and is the focus of our future work.
requires probabilistic modeling of wireless channel condition over time and is the focus of our future work.
8.6 Numerical Results
In this section, we compare the performance (based on expected total discounted reward criterion (Section 8.3.6)) of our proposed MDP-based DVFS2 policy ![]() (
(![]() ) with several fixed heuristic policies using a representative EWSN platform. We use the MATLAB MDP tool box [318] implementation of our policy iteration algorithm described in Section 8.3.7 to solve Bellman's equation (8.18) to determine the MDP-based policy. We select sensor node state parameters based on eXtreme Scale Motes (XSM) [315, 319]. The XSM motes have an average lifetime of 1000 h of continuous operation with two AA alkaline batteries, which can deliver 6 W h or an average of 6 mW [315]. The XSM platform integrates an Atmel ATmega128L microcontroller [192], a Chipcon CC1000 radio operating at 433 MHz, and a 4 Mbit serial Flash memory. The XSM motes contain infrared, magnetic, acoustic, photo, and temperature sensors.
) with several fixed heuristic policies using a representative EWSN platform. We use the MATLAB MDP tool box [318] implementation of our policy iteration algorithm described in Section 8.3.7 to solve Bellman's equation (8.18) to determine the MDP-based policy. We select sensor node state parameters based on eXtreme Scale Motes (XSM) [315, 319]. The XSM motes have an average lifetime of 1000 h of continuous operation with two AA alkaline batteries, which can deliver 6 W h or an average of 6 mW [315]. The XSM platform integrates an Atmel ATmega128L microcontroller [192], a Chipcon CC1000 radio operating at 433 MHz, and a 4 Mbit serial Flash memory. The XSM motes contain infrared, magnetic, acoustic, photo, and temperature sensors.
To represent sensor node operation, we analyze sample application domains that represent a typical security system or defense application (henceforth referred to as a security/defense system) [137], healthcare application, and ambient conditions monitoring application. For brevity, we select a single sample EWSN platform configuration and several application domains, but we point out that our proposed MDP model and methodology works equally well for any other EWSN platform and application.
For each application domain, we evaluate the effects of different discount factors, different state transition costs, and different application metric weight factors on the expected total discounted reward for our MDP-based policy and several fixed heuristic policies (Section 8.6.1). The magnitude of difference in the total expected discounted reward for different policies is important as it provides relative comparisons between the different policies.
8.6.1 Fixed Heuristic Policies for Performance Comparisons
Due to the infancy of EWSN dynamic optimizations, there exist no dynamic sensor node tuning methods for comparison with our MDP-based policy. Therefore, we compare to several fixed heuristic policies (heuristic policies have been shown to be a viable comparison method [299]). To provide a consistent comparison, fixed heuristic policies use the same reward function and the associated parameter settings as that of our MDP-based policy. We consider the following four fixed heuristic policies:
- A fixed heuristic policy
 that always selects the state with the lowest power consumption.
that always selects the state with the lowest power consumption. - A fixed heuristic policy
 that always selects the state with the highest throughput.
that always selects the state with the highest throughput. - A fixed heuristic policy
 that spends an equal amount of time in each of the available states.
that spends an equal amount of time in each of the available states. - A fixed heuristic policy
 that spends an unequal amount of time in each of the available states based on a specified preference for each state. For example, given a system with four possible states, the
that spends an unequal amount of time in each of the available states based on a specified preference for each state. For example, given a system with four possible states, the  policy may spend 40% of time in the first state, 20% of time in the second state, 10% of time in the third state, and 30% of time in the fourth state.
policy may spend 40% of time in the first state, 20% of time in the second state, 10% of time in the third state, and 30% of time in the fourth state.
8.6.2 MDP Specifications
We compare different policies using the expected total discounted reward performance criterion (Section 8.3.6). The state transition probability for each sensor node state is given by Eq. (8.7). The sensor node's lifetime and the time between decision epochs are subjective and may be assigned by an application manager according to application requirements. A sensor node's mean lifetime is given by ![]() time units, which is the time between successive decision epochs (which we assume to be 1 h). For instance for
time units, which is the time between successive decision epochs (which we assume to be 1 h). For instance for ![]() , the sensor node's mean lifetime is
, the sensor node's mean lifetime is ![]() h
h ![]() 42 days.
42 days.
For our numerical results, we consider a sensor node capable of operating in four different states (i.e., ![]() in Eq. (8.2)). Figure 8.4 shows the symbolic representation of our MDP model with four sensor node states. Each state has a set of allowed actions prescribing transitions to available states. For each allowed action
in Eq. (8.2)). Figure 8.4 shows the symbolic representation of our MDP model with four sensor node states. Each state has a set of allowed actions prescribing transitions to available states. For each allowed action ![]() in a state, there is a
in a state, there is a ![]() pair where
pair where ![]() specifies the immediate reward obtained by taking action
specifies the immediate reward obtained by taking action ![]() and
and ![]() denotes the probability of taking action
denotes the probability of taking action ![]() .
.
Table 8.2 summarizes state parameter values for each of the four states ![]() –
–![]() . We define each state using a
. We define each state using a ![]() tuple where
tuple where ![]() is specified in volts,
is specified in volts, ![]() in MHz, and
in MHz, and ![]() in kHz. For instance, state one
in kHz. For instance, state one ![]() is defined as
is defined as ![]() , which corresponds to a processor voltage of 2.7 V, a processor frequency of 2 MHz, and a sensing frequency of 2 kHz (2000 samples/s). We represent state
, which corresponds to a processor voltage of 2.7 V, a processor frequency of 2 MHz, and a sensing frequency of 2 kHz (2000 samples/s). We represent state ![]() power consumption, throughput, and delay as multiples of power, throughput, and delay base units, respectively. We assume one base power unit is equal to 1 mW, one base throughput unit is equal to 0.5 MIPS (millions of instructions per second), and one base delay unit is equal to 50 ms. We assign base units such that these units provide a convenient representation of application metrics (power, throughput, delay). We point out, however, that any other feasible base unit values can be assigned [299]. We assume, without loss of generality, that the transition cost for switching from one state to another is
power consumption, throughput, and delay as multiples of power, throughput, and delay base units, respectively. We assume one base power unit is equal to 1 mW, one base throughput unit is equal to 0.5 MIPS (millions of instructions per second), and one base delay unit is equal to 50 ms. We assign base units such that these units provide a convenient representation of application metrics (power, throughput, delay). We point out, however, that any other feasible base unit values can be assigned [299]. We assume, without loss of generality, that the transition cost for switching from one state to another is ![]() . The transition cost could be a function of power, throughput, and delay, but we assume a constant transition cost for simplicity as it is typically constant for different state transitions [192].
. The transition cost could be a function of power, throughput, and delay, but we assume a constant transition cost for simplicity as it is typically constant for different state transitions [192].
Table 8.2 Parameters for wireless sensor node state ![]() (
(![]() is specified in volts,
is specified in volts, ![]() in MHz, and
in MHz, and ![]() in kHz)
in kHz)
| Notation | ||||
| 10 | 15 | 30 | 55 | |
| 4 | 8 | 12 | 16 | |
| 26 | 14 | 8 | 6 |
Parameters are specified as a multiple of a base unit where one power unit is equal to 1 mW, one throughput unit is equal to 0.5 MIPS, and one delay unit is equal to 50 ms. Parameter values are based on the XSM mote (![]() ,
, ![]() , and
, and ![]() denote the power consumption, throughput, and delay, respectively, in state
denote the power consumption, throughput, and delay, respectively, in state ![]() )
)
Our selection of the state parameter values in Table 8.2 corresponds to XSM mote specifications [193, 316]. The XSM mote's Atmel ATmega128L microprocessor has an operating voltage range of 2.7–5.5 V and a processor frequency range of 0–8 MHz. The ATmega128L throughput varies with processor frequency at 1 MIPS/MHz, thus allowing an application manager to optimize power consumption versus processing speed [192]. Our chosen sensing frequency also corresponds with standard sensor node specifications. The Honeywell HMC1002 magnetometer sensor [320] consumes on average 15 mW of power and can be sampled in 0.1 ms on the Atmel ATmega128L microprocessor, which results in a maximum sampling frequency of approximately 10 kHz (10,000 samples/s). The acoustic sensor embedded in the XSM mote has a maximum sensing frequency of approximately 8.192 kHz [315]. Although the power consumption in a state depends not only on the processor voltage and frequency but also on the processor utilization, which also depends on sensing frequency, we report the average power consumption values in a state as derived from the data sheets [193, 322].
Table 8.3 summarizes the minimum ![]() and maximum
and maximum ![]() reward function parameter values for application metrics (power, throughput, and delay) and the associated weight factors for a security/defense system, health care, and ambient conditions monitoring application. Our selected reward function parameter values represent typical application requirements [81]. We describe later the relative importance of these application metrics with respect to our considered applications.
reward function parameter values for application metrics (power, throughput, and delay) and the associated weight factors for a security/defense system, health care, and ambient conditions monitoring application. Our selected reward function parameter values represent typical application requirements [81]. We describe later the relative importance of these application metrics with respect to our considered applications.
Table 8.3 Minimum ![]() and maximum
and maximum ![]() reward function parameter values and application metric weight factors for a security/defense system, health care, and ambient conditions monitoring application
reward function parameter values and application metric weight factors for a security/defense system, health care, and ambient conditions monitoring application
| Notation | Security/defense | Health care | Ambient monitoring |
| 12 units | 8 units | 5 units | |
| 35 units | 20 units | 32 units | |
| 6 units | 3 units | 2 units | |
| 12 units | 9 units | 8 units | |
| 7 units | 8 units | 12 units | |
| 16 units | 20 units | 40 units | |
| 0.45 | 0.5 | 0.65 | |
| 0.2 | 0.3 | 0.15 | |
| 0.35 | 0.2 | 0.2 |
![]() and
and ![]() denote minimum and maximum acceptable power consumption, respectively;
denote minimum and maximum acceptable power consumption, respectively; ![]() and
and ![]() denote minimum and maximum acceptable throughput, respectively;
denote minimum and maximum acceptable throughput, respectively; ![]() and
and ![]() denote minimum and maximum acceptable delay, respectively;
denote minimum and maximum acceptable delay, respectively; ![]() ,
, ![]() , and
, and ![]() denote the weight factors for power, throughput, and delay, respectively.
denote the weight factors for power, throughput, and delay, respectively.
Although power is a primary concern for all EWSN applications and tolerable power consumption values are specified based on the desired EWSN lifetime considering limited battery resources of sensor nodes. However, a relative importance in power for different applications can be delineated mainly by the infeasibility of sensor node's battery replacement due to hostile environments. For example, sensor nodes in a war zone for a security/defense application and an active volcano monitoring application make battery replacement almost impractical. For a healthcare application with sensors attached to a patient to monitor physiological data (e.g., heart rate, glucose level), sensor node's battery may be replaced though power is constrained because excessive heat dissipation could adversely affect a patient's health. Similarly, delay can be an important factor for security/defense in case of enemy target tracking and health care for a patient in intensive health conditions, whereas delay may be relatively less important for a humidity monitoring application. A data-sensitive security/defense system may require a comparatively large minimum throughput in order to obtain a sufficient number of sensed data samples for meaningful analysis. Although relative importance and minimum and maximum values of these application metrics can vary widely with an application domain and between application domains, we pick our parameter values (Table 8.3) for demonstration purposes to provide an insight into our optimization methodology.
We point out that all of our considered application metrics specifically throughput depends on the traffic pattern. EWSN throughput is a complex function of the number of nodes, traffic volume and patterns, and the parameters of the medium access technique. As the number of nodes and traffic volume increases, contention-based medium access methods result in an increased number of packet collisions, which waste energy without transmitting useful data. This contention and packet collision results in saturation, which decreases the effective throughput and increases the delay sharply. We briefly outline the variance in EWSN traffic patterns for our considered applications. The security/defense application would have infrequent bursts of heavy traffic (e.g., when an enemy target appears within the sensor nodes' sensing range), healthcare applications would have a steady flow of medium-to-high traffic, and ambient conditions monitoring applications would have a steady flow of low-to-medium traffic except for emergencies (e.g., volcano eruption). Although modeling of application metrics with respect to traffic patterns would result in a better characterization of these metric values at particular instants/times in WSN, these metric values can still be bounded by a lower minimum value and an upper maximum value as captured by our reward functions (Section 8.3.5).
Given the reward function, sensor node state parameters corresponding to XSM mote, and transition probabilities, our MATLAB MDP tool box [318] implementation of policy iteration algorithm solves Bellman's equation (8.18) to determine the MDP-based policy and determines the expected total discounted reward (Eq. (8.10)).
8.6.3 Results for a Security/Defense System Application
8.6.3.1 The Effects of Different Discount Factors on the Expected Total Discounted Reward
Table 8.4 and Fig. 8.5 depict the effects of different discount factors ![]() on the heuristic policies and
on the heuristic policies and ![]() for a security/defense system when the state transition cost
for a security/defense system when the state transition cost ![]() is held constant at 0.1 for
is held constant at 0.1 for ![]() , and
, and ![]() , and
, and ![]() are equal to 0.45, 0.2, and 0.35, respectively. Since we assume the time between successive decision epochs to be 1 h, the range of
are equal to 0.45, 0.2, and 0.35, respectively. Since we assume the time between successive decision epochs to be 1 h, the range of ![]() from 0.94 to 0.99999 corresponds to a range of average sensor node lifetime from 16.67 to 100,000 h
from 0.94 to 0.99999 corresponds to a range of average sensor node lifetime from 16.67 to 100,000 h ![]() days
days ![]() years. Table 8.4 and Fig. 8.5 show that
years. Table 8.4 and Fig. 8.5 show that ![]() results in the highest expected total discounted reward for all values of
results in the highest expected total discounted reward for all values of ![]() and corresponding average sensor node lifetimes.
and corresponding average sensor node lifetimes.
Table 8.4 The effects of different discount factors ![]() for a security/defense system
for a security/defense system
| Discount factor |
Sensor lifetime (h) | |||||
| 0.94 | 16.67 | 10.0006 | 7.5111 | 9.0778 | 7.2692 | 7.5586 |
| 0.95 | 20 | 12.0302 | 9.0111 | 10.9111 | 8.723 | 9.0687 |
| 0.96 | 25 | 15.0747 | 11.2611 | 13.6611 | 10.9038 | 11.3339 |
| 0.97 | 33.33 | 20.1489 | 15.0111 | 18.2445 | 14.5383 | 15.1091 |
| 0.98 | 50 | 30.2972 | 22.5111 | 27.4111 | 21.8075 | 22.6596 |
| 0.99 | 100 | 60.7422 | 45.0111 | 54.9111 | 43.6150 | 45.3111 |
| 0.999 | 1000 | 608.7522 | 450.0111 | 549.9111 | 436.15 | 453.0381 |
| 0.9999 | 10,000 | |||||
| 0.99999 | 100,000 |
![]() if
if ![]() ,
, ![]()

Figure 8.5 The effects of different discount factors on the expected total discounted reward for a security/defense system.  if
if  ,
, 
Figure 8.6 shows the percentage improvement in expected total discounted reward for ![]() for a security/defense system as compared to the fixed heuristic policies. The percentage improvement is calculated as
for a security/defense system as compared to the fixed heuristic policies. The percentage improvement is calculated as ![]() where
where ![]() denotes the expected total discounted reward for
denotes the expected total discounted reward for ![]() and
and ![]() denotes the expected total discounted reward for the
denotes the expected total discounted reward for the ![]() fixed heuristic policy where
fixed heuristic policy where ![]() = {POW, THP, EQU, PRF}. For instance, when the average sensor node lifetime is 1000 h (
= {POW, THP, EQU, PRF}. For instance, when the average sensor node lifetime is 1000 h (![]() ),
), ![]() results in a 26.08%, 9.67%, 28.35%, and 25.58% increase in expected total discounted reward compared to
results in a 26.08%, 9.67%, 28.35%, and 25.58% increase in expected total discounted reward compared to ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , respectively. Figure 8.6 also depicts that
, respectively. Figure 8.6 also depicts that ![]() shows increased savings as the average sensor node lifetime increases due to an increase in the number of decision epochs and thus prolonged operation of sensor nodes in optimal/suboptimal states as prescribed by
shows increased savings as the average sensor node lifetime increases due to an increase in the number of decision epochs and thus prolonged operation of sensor nodes in optimal/suboptimal states as prescribed by ![]() . On average over all discount factors
. On average over all discount factors ![]() ,
, ![]() results in a 25.57%, 9.48%, 27.91%, and 25.1% increase in expected total discounted reward compared to
results in a 25.57%, 9.48%, 27.91%, and 25.1% increase in expected total discounted reward compared to ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , respectively.
, respectively.

Figure 8.6 Percentage improvement in expected total discounted reward for  for a security/defense system as compared to the fixed heuristic policies.
for a security/defense system as compared to the fixed heuristic policies.  if
if  ,
, 
8.6.3.2 The Effects of Different State Transition Costs on the Expected Total Discounted Reward
Figure 8.7 depicts the effects of different state transition costs on the expected total discounted reward for a security/defense system with a fixed average sensor node lifetime of 1000 h (![]() ) and
) and ![]() , and
, and ![]() equal to 0.45, 0.2, and 0.35, respectively. Figure 8.7 shows that
equal to 0.45, 0.2, and 0.35, respectively. Figure 8.7 shows that ![]() results in the highest expected total discounted reward for all transition cost values.
results in the highest expected total discounted reward for all transition cost values.

Figure 8.7 The effects of different state transition costs on the expected total discounted reward for a security/defense system.  ,
, 
Figure 8.7 also shows that the expected total discounted reward for ![]() is relatively unaffected by state transition cost. This relatively constant behavior can be explained by the fact that our MDP policy does not perform many state transitions. Relatively few state transitions to reach the optimal/suboptimal state according to the specified application metrics may be advantageous for some application managers who consider the number of state transitions prescribed by a policy as a secondary evaluation criteria [299].
is relatively unaffected by state transition cost. This relatively constant behavior can be explained by the fact that our MDP policy does not perform many state transitions. Relatively few state transitions to reach the optimal/suboptimal state according to the specified application metrics may be advantageous for some application managers who consider the number of state transitions prescribed by a policy as a secondary evaluation criteria [299]. ![]() performs state transitions primarily at sensor node deployment or whenever a new MDP-based policy is determined as the result of changes in application requirements.
performs state transitions primarily at sensor node deployment or whenever a new MDP-based policy is determined as the result of changes in application requirements.
We further analyze the effects of different state transition costs on the fixed heuristic policies, which consistently result in a lower expected total discounted reward as compared to ![]() . The expected total discounted rewards for
. The expected total discounted rewards for ![]() and
and ![]() are relatively unaffected by state transition cost. The explanation for this behavior is that these heuristics perform state transitions only at initial sensor node deployment when the sensor node transitions to the lowest power state and the highest throughput state, respectively, and remain in these states for the entire sensor node's lifetime. On the other hand, state transition cost has the largest affect on the expected total discounted reward for
are relatively unaffected by state transition cost. The explanation for this behavior is that these heuristics perform state transitions only at initial sensor node deployment when the sensor node transitions to the lowest power state and the highest throughput state, respectively, and remain in these states for the entire sensor node's lifetime. On the other hand, state transition cost has the largest affect on the expected total discounted reward for ![]() due tohigh state transition rates because the policy spends an equal amount of time in all states. Similarly, high switching costs have a large affect on the expected total discounted reward for
due tohigh state transition rates because the policy spends an equal amount of time in all states. Similarly, high switching costs have a large affect on the expected total discounted reward for ![]() (although less severely than
(although less severely than ![]() ) because
) because ![]() spends a certain percentage of time in each available state (Section 8.6.1), thus requiring comparatively fewer transitions than
spends a certain percentage of time in each available state (Section 8.6.1), thus requiring comparatively fewer transitions than ![]() .
.
8.6.3.3 The Effects of Different Reward Function Weight Factors on the Expected Total Discounted Reward
Figure 8.8 shows the effects of different reward function weight factors on the expected total discounted reward for a security/defense system when the average sensor node lifetime is 1000 h (![]() ) and the state transition cost
) and the state transition cost ![]() is held constant at 0.1 for
is held constant at 0.1 for ![]() . We explore various weight factors that are appropriate for different security/defense system specifics, that is,
. We explore various weight factors that are appropriate for different security/defense system specifics, that is, ![]() . Figure 8.8 reveals that
. Figure 8.8 reveals that ![]() results in the highest expected total discounted reward for all weight factor variations.
results in the highest expected total discounted reward for all weight factor variations.

Figure 8.8 The effects of different reward function weight factors on the expected total discounted reward for a security/defense system.  ,
,  if
if 
8.6.4 Results for a Healthcare Application
8.6.4.1 The Effects of Different Discount Factors on the Expected Total Discounted Reward
Figure 8.9 depicts the effects of different discount factors ![]() for a healthcare application when the state transition cost
for a healthcare application when the state transition cost ![]() is held constant at 0.1 for
is held constant at 0.1 for ![]() , and
, and ![]() , and
, and ![]() are equal to 0.5, 0.3, and 0.2, respectively. Figure 8.9 shows that
are equal to 0.5, 0.3, and 0.2, respectively. Figure 8.9 shows that ![]() results in the highest expected total discounted reward for all values of
results in the highest expected total discounted reward for all values of ![]() and the corresponding average sensor node lifetimes as compared to other fixed heuristic policies.
and the corresponding average sensor node lifetimes as compared to other fixed heuristic policies.

Figure 8.9 The effects of different discount factors on the expected total discounted reward for a healthcare application.  if
if  ,
, 
Figure 8.10 shows the percentage improvement in expected total discounted reward for ![]() for a healthcare application as compared to the fixed heuristic policies. For instance, when the average sensor node lifetime is 1000 h (
for a healthcare application as compared to the fixed heuristic policies. For instance, when the average sensor node lifetime is 1000 h (![]() ),
), ![]() results in a 16.39%, 10.43%, 27.22%, and 21.47% increase in expected total discounted reward compared to
results in a 16.39%, 10.43%, 27.22%, and 21.47% increase in expected total discounted reward compared to ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , respectively. On average over all discount factors
, respectively. On average over all discount factors ![]() ,
, ![]() results in a 16.07%, 10.23%, 26.8%, and 21.04% increase in expected total discounted reward compared to
results in a 16.07%, 10.23%, 26.8%, and 21.04% increase in expected total discounted reward compared to ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , respectively.
, respectively.

Figure 8.10 Percentage improvement in expected total discounted reward for  for a healthcare application as compared to the fixed heuristic policies.
for a healthcare application as compared to the fixed heuristic policies.  if
if  ,
, 
8.6.4.2 The Effects of Different State Transition Costs on the Expected Total Discounted Reward
Figure 8.11 shows the effects of different state transition costs on the expected total discounted reward for a healthcare application with a fixed average sensor node lifetime of 1000 h (![]() ) and
) and ![]() , and
, and ![]() equal to 0.5, 0.3, and 0.2, respectively. Figure 8.11 shows that
equal to 0.5, 0.3, and 0.2, respectively. Figure 8.11 shows that ![]() results in the highest expected total discounted reward for all transition cost values. The fixed heuristic policies consistently result in a lower expected total discounted reward as compared to
results in the highest expected total discounted reward for all transition cost values. The fixed heuristic policies consistently result in a lower expected total discounted reward as compared to ![]() . Comparison of Figs. 8.7 and 8.11 reveals that a security/defense system and a healthcare application have similar trends with respect to different state transition costs on the expected total discounted reward.
. Comparison of Figs. 8.7 and 8.11 reveals that a security/defense system and a healthcare application have similar trends with respect to different state transition costs on the expected total discounted reward.

Figure 8.11 The effects of different state transition costs on the expected total discounted reward for a healthcare application.  ,
, 
8.6.4.3 The Effects of Different Reward Function Weight Factors on the Expected Total Discounted Reward
Figure 8.12 depicts the effects of different reward function weight factors on the expected total discounted reward for a healthcare application when the average sensor node lifetime is 1000 h (![]() ) and the state transition cost
) and the state transition cost ![]() is kept constant at 0.1 for
is kept constant at 0.1 for ![]() . We explore various weight factors that are appropriate for different healthcare application specifics (i.e.,
. We explore various weight factors that are appropriate for different healthcare application specifics (i.e., ![]() ). Figure 8.12 shows that
). Figure 8.12 shows that ![]() results in the highest expected total discounted reward for all weight factor variations.
results in the highest expected total discounted reward for all weight factor variations.

Figure 8.12 The effects of different reward function weight factors on the expected total discounted reward for a healthcare application.  ,
,  if
if 
Figures 8.8 and 8.12 show that the expected total discounted reward of ![]() gradually increases as the power weight factor increases and eventually exceeds that of
gradually increases as the power weight factor increases and eventually exceeds that of ![]() for a security/defense system and a healthcare application, respectively. However, close observation reveals that the expected total discounted reward of
for a security/defense system and a healthcare application, respectively. However, close observation reveals that the expected total discounted reward of ![]() for a security/defense system is affected more sharply than a healthcare application because of the more stringent constraint on maximum acceptable power for a healthcare application (Table 8.3). Figures 8.8 and 8.12 show that
for a security/defense system is affected more sharply than a healthcare application because of the more stringent constraint on maximum acceptable power for a healthcare application (Table 8.3). Figures 8.8 and 8.12 show that ![]() tends to perform better than
tends to perform better than ![]() with increasing power weight factors because
with increasing power weight factors because ![]() spends a greater percentage of time in low power states.
spends a greater percentage of time in low power states.
8.6.5 Results for an Ambient Conditions Monitoring Application
8.6.5.1 The Effects of Different Discount Factors on the Expected Total Discounted Reward
Figure 8.13 demonstrates the effects of different discount factors ![]() for an ambient conditions monitoring application when the state transition cost
for an ambient conditions monitoring application when the state transition cost ![]() is held constant at 0.1 for
is held constant at 0.1 for ![]() , and
, and ![]() , and
, and ![]() are equal to 0.65, 0.15, and 0.2, respectively. Figure 8.13 shows that
are equal to 0.65, 0.15, and 0.2, respectively. Figure 8.13 shows that ![]() results in the highest expected total discounted reward for all values of
results in the highest expected total discounted reward for all values of ![]() .
.

Figure 8.13 The effects of different discount factors on the expected total discounted reward for an ambient conditions monitoring application.  if
if  ,
, 
Figure 8.14 shows the percentage improvement in expected total discounted reward for ![]() for an ambient conditions monitoring application as compared to the fixed heuristic policies. For instance, when the average sensor node lifetime is 1000 h (
for an ambient conditions monitoring application as compared to the fixed heuristic policies. For instance, when the average sensor node lifetime is 1000 h (![]() ),
), ![]() results in a 8.77%, 52.99%, 40.49%, and 32.11% increase in expected total discounted reward as compared to
results in a 8.77%, 52.99%, 40.49%, and 32.11% increase in expected total discounted reward as compared to ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , respectively. On average over all discount factors
, respectively. On average over all discount factors ![]() ,
, ![]() results in a 8.63%, 52.13%, 39.92%, and 31.59% increase in expected total discounted reward as compared to
results in a 8.63%, 52.13%, 39.92%, and 31.59% increase in expected total discounted reward as compared to ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , respectively.
, respectively.

Figure 8.14 Percentage improvement in expected total discounted reward for  for an ambient conditions monitoring application as compared to the fixed heuristic policies.
for an ambient conditions monitoring application as compared to the fixed heuristic policies.  if
if  ,
, 
8.6.5.2 The Effects of Different State Transition Costs on the Expected Total Discounted Reward
Figure 8.15 depicts the effects of different state transition costs on the expected total discounted reward for an ambient conditions monitoring application with a fixed average sensor node lifetime of 1000 h (![]() ) and
) and ![]() , and
, and ![]() equal to 0.65, 0.15, and 0.2, respectively. Figure 8.15 reveals that
equal to 0.65, 0.15, and 0.2, respectively. Figure 8.15 reveals that ![]() results in the highest expected total discounted reward for all transition cost values. The fixed heuristic policies consistently result in a lower expected total discounted reward as compared to
results in the highest expected total discounted reward for all transition cost values. The fixed heuristic policies consistently result in a lower expected total discounted reward as compared to ![]() . Figure 8.15 reveals that the ambient conditions monitoring application has similar trends with respect to different state transition costs as compared to the security/defense system (Fig. 8.7) and healthcare applications (Fig. 8.7).
. Figure 8.15 reveals that the ambient conditions monitoring application has similar trends with respect to different state transition costs as compared to the security/defense system (Fig. 8.7) and healthcare applications (Fig. 8.7).

Figure 8.15 The effects of different state transition costs on the expected total discounted reward for an ambient conditions monitoring application.  ,
, 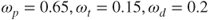
8.6.5.3 The Effects of Different Reward Function Weight Factors on the Expected Total Discounted Reward
Figure 8.16 shows the effects of different reward function weight factors on the expected total discounted reward for an ambient conditions monitoring application when the average sensor node lifetime is 1000 h (![]() ) and the state transition cost
) and the state transition cost ![]() is held constant at 0.1 for
is held constant at 0.1 for ![]() . We explore various weight factors that are appropriate for different ambient conditions monitoring application specifics (i.e.,
. We explore various weight factors that are appropriate for different ambient conditions monitoring application specifics (i.e., ![]() ). Figure 8.16 reveals that
). Figure 8.16 reveals that ![]() results in the highest expected total discounted reward for all weight factor variations.
results in the highest expected total discounted reward for all weight factor variations.

Figure 8.16 The effects of different reward function weight factors on the expected total discounted reward for an ambient conditions monitoring application.  ,
,  if
if 
For an ambient conditions monitoring application, Fig. 8.16 shows that the expected total discounted reward of ![]() becomes closer to
becomes closer to ![]() as the power weight factor increases, because with higher power weight factors,
as the power weight factor increases, because with higher power weight factors, ![]() spends more time in lower power states to meet application requirements. Figure 8.16 shows that
spends more time in lower power states to meet application requirements. Figure 8.16 shows that ![]() tends to perform better than
tends to perform better than ![]() with increasing power weight factors similar to the security/defense system (Fig. 8.8) and healthcare applications (Fig. 8.16).
with increasing power weight factors similar to the security/defense system (Fig. 8.8) and healthcare applications (Fig. 8.16).
8.6.6 Sensitivity Analysis
An application manager can assign values to MDP reward function parameters, such as ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and ![]() , before an EWSN's initial deployment according to projected/anticipated application requirements. However, the average sensor node lifetime (calculated from
, before an EWSN's initial deployment according to projected/anticipated application requirements. However, the average sensor node lifetime (calculated from ![]() ) may not be accurately estimated at the time of initial EWSN deployment, as environmental stimuli and wireless channel conditions vary with time and may not be accurately anticipated. The sensor node's lifetime depends on sensor node activity (both processing and communication), which varies with the changing environmental stimuli and wireless channel conditions. Sensitivity analysis analyzes the effects of changes in average sensor node lifetime after initial deployment on the expected total discounted reward. Thus, if the actual lifetime is different than the estimated lifetime, what is the loss in total expected discounted reward if the actual lifetime had been accurately predicted at deployment.
) may not be accurately estimated at the time of initial EWSN deployment, as environmental stimuli and wireless channel conditions vary with time and may not be accurately anticipated. The sensor node's lifetime depends on sensor node activity (both processing and communication), which varies with the changing environmental stimuli and wireless channel conditions. Sensitivity analysis analyzes the effects of changes in average sensor node lifetime after initial deployment on the expected total discounted reward. Thus, if the actual lifetime is different than the estimated lifetime, what is the loss in total expected discounted reward if the actual lifetime had been accurately predicted at deployment.
EWSN sensitivity analysis can be carried out with the following steps [299]:
- 1. Determine the expected total discounted reward given the actual average sensor node lifetime
 , referred to as the Optimal Reward
, referred to as the Optimal Reward  .
. - 2. Let
 denote the estimated average sensor node lifetime, and
denote the estimated average sensor node lifetime, and  denote the percentage change from the actual average sensor node lifetime (i.e.,
denote the percentage change from the actual average sensor node lifetime (i.e.,  ).
).  results in a suboptimal policy with a corresponding suboptimal total expected discounted reward, referred to as Suboptimal Reward
results in a suboptimal policy with a corresponding suboptimal total expected discounted reward, referred to as Suboptimal Reward  .
. - 3. The Reward Ratio
 is the ratio of the suboptimal reward to the optimal reward (i.e.,
is the ratio of the suboptimal reward to the optimal reward (i.e.,  ), which indicates suboptimal expected total discounted reward variation with the average sensor node lifetime estimation inaccuracy.
), which indicates suboptimal expected total discounted reward variation with the average sensor node lifetime estimation inaccuracy.
It can be shown that the reward ratio varies from (0, 2] as ![]() varies from (
varies from (![]() 100%, 100%]. The reward ratio's ideal value is 1, which occurs when the average sensor node lifetime is accurately estimated/predicted (
100%, 100%]. The reward ratio's ideal value is 1, which occurs when the average sensor node lifetime is accurately estimated/predicted (![]() corresponding to
corresponding to ![]() ). Sensitivity analysis revealed that our MDP-based policy is sensitive to accurate determination of parameters, especially average lifetime, because inaccurate average sensor node lifetime results in a suboptimal expected total discounted reward. The dynamic profiler module (Fig. 8.1) measures/profiles the remaining battery energy (lifetime) and sends this information to the application manager along with other profiled statistics (Section 8.2.1), which helps inaccurate estimation of
). Sensitivity analysis revealed that our MDP-based policy is sensitive to accurate determination of parameters, especially average lifetime, because inaccurate average sensor node lifetime results in a suboptimal expected total discounted reward. The dynamic profiler module (Fig. 8.1) measures/profiles the remaining battery energy (lifetime) and sends this information to the application manager along with other profiled statistics (Section 8.2.1), which helps inaccurate estimation of ![]() . Estimating
. Estimating ![]() using the dynamic profiler's feedback ensures that the estimated average sensor node lifetime differs only slightly from the actual average sensor node lifetime, and thus helps in maintaining a reward ratio close to 1.
using the dynamic profiler's feedback ensures that the estimated average sensor node lifetime differs only slightly from the actual average sensor node lifetime, and thus helps in maintaining a reward ratio close to 1.
8.6.7 Number of Iterations for Convergence
The policy iteration algorithm determines ![]() and the corresponding expected total discounted reward on the order of
and the corresponding expected total discounted reward on the order of ![]() , where
, where ![]() is the total number of states. In our numerical results with four sensor node states, the policy iteration algorithm converges in two iterations on average.
is the total number of states. In our numerical results with four sensor node states, the policy iteration algorithm converges in two iterations on average.
8.7 Chapter Summary
In this chapter, we presented an application-oriented dynamic tuning methodology for embedded sensor nodes in distributed EWSNs based on MDPs. Our MDP-based policy tuned embedded sensor node processor voltage, frequency, and sensing frequency in accordance with application requirements over the lifetime of a sensor node. Our proposed methodology was adaptive and dynamically determined the new MDP-based policy whenever application requirements change (which may be in accordance with changing environmental stimuli). We compared our MDP-based policy with four fixed heuristic policies and concluded that our proposed MDP-based policy outperformed each heuristic policy for all sensor node lifetimes, state transition costs, and application metric weight factors. We provided the implementation guidelines of our proposed policy in embedded sensor nodes. We proved that our proposed policy had fast convergence rate, computationally inexpensive, and thus could be considered for implementation in sensor nodes with limited processing resources.
Extension of this work includes enhancing our MDP model to incorporate additional high-level application metrics (e.g., security, reliability, energy, lifetime) as well as additional embedded sensor node tunable parameters (such as radio transmission power, radio transmission frequency). Furthermore, incorporation of wireless channel condition in the MDP state space, thus formulating a stochastic dynamic program that enables sensor node tuning in accordance with changing wireless channel condition, will be an interesting research. Sensor node tuning automation can be enhanced using profiling statistics by architecting mechanisms that enable the sensor node to automatically react to environmental stimuli without the need for an application manager's feedback. Extension of our MDP-based dynamic optimization methodology for performing global optimization (i.e., selection of sensor node tunable parameter settings to ensure that application requirements are met for EWSN as a whole where different sensor nodes collaborate with each other in optimal/suboptimal tunable parametersettings determination) will be an interesting research problem to explore.