
Model-based collaborative filtering is commonly being used by many companies, such as Netflix, as a recommender system for a real-time movie recommendation. In this section, we will see a complete example of how it works towards recommending movies for new users.
The implementation in Spark MLlib supports the model-based collaborative filtering. In the model based collaborative filtering technique, users and products are described by a small set of factors, also called the latent factors (LFs).The LFs are then used for predicting the missing entries. Spark API provides the implementation of the Alternating Least Squares (also known as the ALS widely) algorithm, which is used to learn these latent factors by considering six parameters, including:
numBlocksrankiterationslambdaimplicitPrefsalpha
To learn more about these parameters, refer to the recommendation system section in Chapter 5, Supervised and Unsupervised Learning by Examples. Note that to construct an ALS instance with default parameters, you can set the value based on your requirements. The default values are as follows: numBlocks: -1, rank: 10, iterations: 10, lambda: 0.01, implicitPrefs: false, alpha: 1.0.
The construction of an ALS instance, in short, is as follows:
- At first, the ALS, which is an iterative algorithm, is used to model the rating matrix as the multiplication of low-ranked users and product factors
- After that, the learning task is done by using these factors by minimizing the reconstruction error of the observed ratings
However, the unknown ratings can successively be calculated by multiplying these factors together.
The approach for a movie recommendation or any other recommendation based on the collaborative filtering technique used in the Spark MLlib has been proven to be a high performer with high prediction accuracy and scalable for the billions of ratings on commodity clusters used by companies such as Netflix. By following this approach, a company such as Netflix can recommend movies to its subscriber based on the predicted ratings. The ultimate target is to increase the sales, and of course, the customer satisfaction.
The movie and the corresponding rating dataset were downloaded from the MovieLens website (https://movielens.org). According to the data description on the MovieLens website, all the ratings are described in the ratings.csv file. Each row of this file followed by the header represents one rating for one movie by one user.
The CSV dataset has the following columns: userId, movieId, rating, and timestamp as shown in Figure 2. The rows are ordered first by the userId within the user, by movieId. Ratings are made on a five-star scale; with half-star increments (0.5 stars up to 5.0 stars). The timestamps represent the seconds since midnight Coordinated Universal Time (UTC) of January 1, 1970, where we have 105,339 ratings from the 668 users on 10,325 movies:

Figure 2: Sample ratings for the top 20 movies.
On the other hand, the movie information is contained in the movies.csv file. Each row apart from the header information represents one movie containing the columns: movieId, title, and genres.
Movie titles are either created or inserted manually or imported from the website of the movie database at https://www.themoviedb.org/. The release year, however, is shown in the bracket.
Since movie titles are inserted manually, some errors or inconsistencies may exist in these titles. Readers are therefore recommended to check the IMDb database (http://www.ibdb.com/) to make sure if there are no inconsistencies or incorrect titles with their corresponding release year.
Genres are a separated list, and are selected from the following genre categories:
- Action, Adventure, Animation, Children's, Comedy, Crime
- Documentary, Drama, Fantasy, Film-Noir, Horror, Musical
- Mystery, Romance, Sci-Fi, Thriller, Western, War

Figure 3: The title and genres for the top 20 movies.
In this subsection, we will show you how to recommend the movie for other users through a step-by-step example from data collection to movie recommendation. Download the movies.csv and ratings.csv files from Packt supplementary documents and place them in your project directory.
Step 1: Configure your Spark environment
Here is the code to configure your Spark environment:
static SparkSession spark = SparkSession
.builder()
.appName("JavaLDAExample")
.master("local[*]")
.config("spark.sql.warehouse.dir", "E:/Exp/").
getOrCreate();
Step 2: Load, parse, and explore the movie and rating Dataset
Here is the code illustrated:
String ratigsFile = "input/ratings.csv";
Dataset<Row> df1 = spark.read().format("com.databricks.spark.csv").option("header", "true").load(ratigsFile);
Dataset<Row> ratingsDF = df1.select(df1.col("userId"), df1.col("movieId"), df1.col("rating"), df1.col("timestamp"));
ratingsDF.show(false);
This code segment should return you the Dataset<Row> of the ratings same as in Figure 2. On the other hand, the following code segment shows you the Dataset<Row> of movies, same as in Figure 3:
String moviesFile = "input/movies.csv";
Dataset<Row> df2 = spark.read().format("com.databricks.spark.csv").option("header", "true").load(moviesFile);
Dataset<Row> moviesDF = df2.select(df2.col("movieId"), df2.col("title"), df2.col("genres"));
moviesDF.show(false);
Step 3: Register both Datasets as temp tables
To register both Datasets, we can use the following code:
ratingsDF.createOrReplaceTempView("ratings");
moviesDF.createOrReplaceTempView("movies");
This will help to make the in-memory querying faster by creating a temporary view as a table in min-memory. The lifetime of the temporary table using the createOrReplaceTempView() method is tied to the [[SparkSession]] that was used to create this Dataset.
Step 4: Explore and query for related statistics
Let's check the ratings related statistics. Just use the following code lines:
long numRatings = ratingsDF.count();
long numUsers = ratingsDF.select(ratingsDF.col("userId")).distinct().count();
long numMovies = ratingsDF.select(ratingsDF.col("movieId")).distinct().count();
System.out.println("Got " + numRatings + " ratings from " + numUsers + " users on " + numMovies + " movies.");
You should find 105,339 ratings from 668 users on 10,325 movies. Now, let's get the maximum and minimum ratings along with the count of users who have rated a movie.
However, you need to perform a SQL query on the rating table we just created in-memory in the previous step. Making a query here is simple, and it is similar to making a query from a MySQL database or RDBMS.
However, if you are not familiar with SQL-based queries, you are suggested to look at the SQL query specification to find out how to perform a selection using SELECT from a particular table, how to perform the ordering using ORDER, and how to perform a joining operation using the JOIN keyword.
Well, if you know the SQL query, you should get a new Dataset by using a complex SQL query as follows:
Dataset<Row> results = spark.sql("select movies.title, movierates.maxr, movierates.minr, movierates.cntu " + "from(SELECT ratings.movieId,max(ratings.rating) as maxr," + "min(ratings.rating) as minr,count(distinct userId) as cntu " + "FROM ratings group by ratings.movieId) movierates " + "join movies on movierates.movieId=movies.movieId " + "order by movierates.cntu desc");
results.show(false);

Figure 4: Maximum and minimum ratings along with the count of users who have rated a movie.
To get an insight, we need to know more about the users and their ratings. Now let's find the top most active users and how many times they rated a movie:
Dataset<Row> mostActiveUsersSchemaRDD = spark.sql("SELECT ratings.userId, count(*) as ct from ratings " + "group by ratings.userId order by ct desc limit 10");
mostActiveUsersSchemaRDD.show(false);

Figure 5: Number of ratings provided by an individual user.
Now let's have a look at a particular user, and find the movies that, say user 668, rated higher than 4:
Dataset<Row> results2 = spark.sql("SELECT ratings.userId, ratings.movieId," + "ratings.rating, movies.title FROM ratings JOIN movies "+ "ON movies.movieId=ratings.movieId " + "where ratings.userId=668 and ratings.rating > 4");
results2.show(false);

Figure 6: The related rating for user 668.
Step 5: Prepare training and test rating data and see the counts
Here is the code illustrated:
Dataset<Row> [] splits = ratingsDF.randomSplit(new double[] { 0.8, 0.2 });
Dataset<Row> trainingData = splits[0];
Dataset<Row> testData = splits[1];
long numTraining = trainingData.count();
long numTest = testData.count();
System.out.println("Training: " + numTraining + " test: " + numTest);
You should find that there are 84,011 ratings in the training and 21,328 ratings in the test Dataset.
Step 6: Prepare the data for building the recommendation model using ALS
The following code illustrates for building the recommendation model using APIs:
JavaRDD<Rating> ratingsRDD = trainingData.toJavaRDD().map(new Function<Row, Rating>() {
@Override
public Rating call(Row r) throws Exception {
// TODO Auto-generated method stub
int userId = Integer.parseInt(r.getString(0));
int movieId = Integer.parseInt(r.getString(1));
double ratings = Double.parseDouble(r.getString(2));
return new Rating(userId, movieId, ratings);
}
});
The ratingsRDD RDD will contain the userId, movieId, and corresponding ratings from the training dataset that we prepared in the previous step. On the other hand, the following testRDD also contains the same information coming from the test Dataset we prepared in the previous step:
JavaRDD<Rating> testRDD = testData.toJavaRDD().map(new Function<Row, Rating>() {
@Override
public Rating call(Row r) throws Exception {
int userId = Integer.parseInt(r.getString(0));
int movieId = Integer.parseInt(r.getString(1));
double ratings = Double.parseDouble(r.getString(2));
return new Rating(userId, movieId, ratings);
}
});
Step 7: Build an ALS user product matrix
Build an ALS user matrix model based on the ratingsRDD by specifying the rank, iterations, and lambda:
int rank = 20; int numIterations = 10; double lambda = 0.01; MatrixFactorizationModel model = ALS.train(JavaRDD.toRDD(ratingsRDD), rank, numIterations, 0.01);
- Note that we have randomly selected the value of rank as
20and have iterated the model for learning for 10 times and the lambda as0.01. With this setting, we got a good prediction accuracy. Readers are suggested to apply the hyper-parameter tuning to get to know the most optimum values for these parameters. - However, readers are suggested to change the value of these two parameters based on their dataset. Moreover, as mentioned earlier, they also can use and specify other parameters such as
numberblock,implicitPrefs, andalphaif the prediction performance is not satisfactory. Furthermore, set the number of blocks for both user blocks and product blocks to parallelize the computation intopass -1for an auto-configured number of blocks. The value is-1.
Step 8: Making predictions
Let's get the top six movie predictions for user 668:
System.out.println("Rating:(UserID, MovieId, Rating)");
Rating[] topRecsForUser = model.recommendProducts(668, 6);
for (Rating rating : topRecsForUser)
System.out.println(rating.toString());
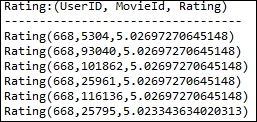
Figure 7: Top six movies rated by the user 668.
Step 9: Get the predicted ratings to compare with the test ratings
Here is the code illustrated:
JavaRDD<Tuple2<Object, Object>> testUserProductRDD = testData.toJavaRDD()
.map(new Function<Row, Tuple2<Object, Object>>() {
@Override
public Tuple2<Object, Object> call(Row r) throws Exception {
int userId = Integer.parseInt(r.getString(0));
int movieId = Integer.parseInt(r.getString(1));
double ratings = Double.parseDouble(r.getString(2));
return new Tuple2<Object, Object>(userId, movieId);
}
});
JavaRDD<Rating> predictionsForTestRDD = model.predict(JavaRDD.toRDD(testUserProductRDD)).toJavaRDD();
Now let's check the top 10 prediction for 10 users:
System.out.println(predictionsForTestRDD.take(10).toString());
Step 10: Prepare predictions
Here we will prepare the predictions related to RDDs in two steps. The first step includes preparing predictions for comparison from the predictionsForTestRDD RDD structure. It goes as follows:
JavaPairRDD<Tuple2<Integer, Integer>, Double> predictionsKeyedByUserProductRDD = JavaPairRDD.fromJavaRDD(
predictionsForTestRDD.map(new Function<Rating, Tuple2<Tuple2<Integer, Integer>, Double>>() {
@Override
public Tuple2<Tuple2<Integer, Integer>, Double> call(Rating r) throws Exception {
return new Tuple2<Tuple2<Integer, Integer>, Double>(
new Tuple2<Integer, Integer>(r.user(), r.product()), r.rating());
}
}));
The second step includes preparing the test for comparison:
JavaPairRDD<Tuple2<Integer, Integer>, Double> testKeyedByUserProductRDD = JavaPairRDD .fromJavaRDD(testRDD.map(new Function<Rating, Tuple2<Tuple2<Integer, Integer>, Double>>() {
@Override
public Tuple2<Tuple2<Integer, Integer>, Double> call(Rating r) throws Exception {
return new Tuple2<Tuple2<Integer, Integer>, Double>(
new Tuple2<Integer, Integer>(r.user(), r.product()), r.rating());
}
}));
Step 11: Join the test with predictions and see the combined ratings
Join testKeyedByUserProductRDD and predictionsKeyedByUserProductRDD RDDs to get the combined test as well as predicted ratings against each user and movieId:
JavaPairRDD<Tuple2<Integer, Integer>, Tuple2<Double, Double>> testAndPredictionsJoinedRDD = testKeyedByUserProductRDD
.join(predictionsKeyedByUserProductRDD);
System.out.println("(UserID, MovieId) => (Test rating, Predicted rating)");
System.out.println("----------------------------------");
for (Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>> t : testAndPredictionsJoinedRDD.take(6)) {
Tuple2<Integer, Integer> userProduct = t._1;
Tuple2<Double, Double> testAndPredictedRating = t._2;
System.out.println("(" + userProduct._1() + "," + userProduct._2() + ") => (" + testAndPredictedRating._1()
+ "," + testAndPredictedRating._2() + ")");
}

Figure 8: Combined test as well as predicted ratings against each user and movieId.
Step 12: Evaluating the model against prediction performance
Let's check the performance of the ALS model by checking the number of true positives and false positives:
JavaPairRDD<Tuple2<Integer, Integer>, Tuple2<Double, Double>> truePositives = testAndPredictionsJoinedRDD
.filter(new Function<Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>>, Boolean>() {
@Override
public Boolean call(Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>> r) throws Exception {
return (r._2._1() <= 1 && r._2._2() < 5);
}
});
Now print the number of true positive predictions. We have considered that a prediction is a true prediction when the predicted rating is less than the highest rating (that is, 5). Consequently, if the predicted rating is more or equal to 5, consider that prediction as a false positive:
for (Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>> t : truePositives.take(2)) {
Tuple2<Integer, Integer> userProduct = t._1;
Tuple2<Double, Double> testAndPredictedRating = t._2;
}
System.out.println("Number of true positive prediction is: "+ truePositives.count());
You should find the value as follows.
The number of true positive prediction is 798. Now it's time to print the statistics for the false positives:
JavaPairRDD<Tuple2<Integer, Integer>, Tuple2<Double, Double>> falsePositives = testAndPredictionsJoinedRDD
.filter(new Function<Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>>, Boolean>() {
@Override
public Boolean call(Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>> r) throws Exception {
return (r._2._1() <= 1 && r._2._2() >= 5);
}
});
for (Tuple2<Tuple2<Integer, Integer>, Tuple2<Double, Double>> t : falsePositives.take(2)) {
Tuple2<Integer, Integer> userProduct = t._1;
Tuple2<Double, Double> testAndPredictedRating = t._2;
}
System.out.println("Number of false positive prediction is: "+ falsePositives.count());
In this particular example, we have got only 14 false positive predictions, which is outstanding. Now let's check the performance of the prediction in terms of mean absolute error calculation between the test and predictions:
double meanAbsoluteError = JavaDoubleRDD .fromRDD(testAndPredictionsJoinedRDD.values().map(new Function<Tuple2<Double, Double>, Object>() {
public Object call(Tuple2<Double, Double> pair) {
Double err = pair._1() - pair._2();
return err * err;
}
}).rdd()).mean();
System.out.printing("Mean Absolute Error: "+meanAbsoluteError);
Which returns the value as follows:
Mean Absolute Error: 1.5800601618477566