
To provide more enhancements and additional big data processing capabilities, Spark can be configured and run on top of existing Hadoop-based clusters. As already stated, although Hadoop provides the Hadoop Distributed File System (HDFS) for efficient and operational storing of large-scale data cheaply; however, MapReduce provides the computation fully disk-based. Another limitation of MapReduce is that; only simple computations can be executed with a high-latency batch model, or static data to be more specific. The core APIs in Spark, on the other hand, are written in Java, Scala, Python, and R. Compared to MapReduce, with the more general and powerful programming model, Spark also provides several libraries that are part of the Spark ecosystems for redundant capabilities in big data analytics, processing, and machine learning areas. The Spark ecosystem consists of the following components, as shown in Figure 5:
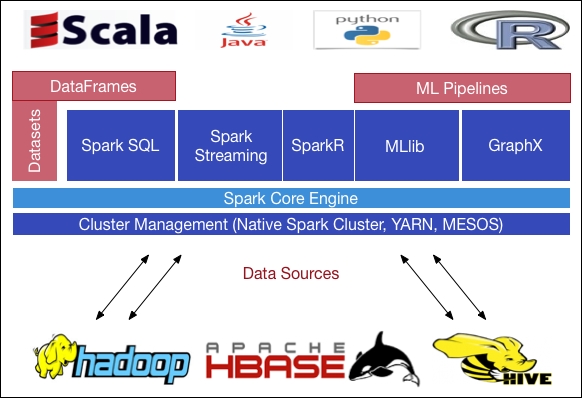
Figure 5: Spark ecosystem (till date up to Spark 1.6.1).
As we have already stated, it is very much possible to combine these APIs seamlessly to develop large-scale machine learning and data analytics applications. Moreover, the job can be executed on various cluster managers such as Hadoop YARN, Mesos, standalone, or in the cloud by accessing data storage and sources such as HDFS, Cassandra, HBase, Amazon S3, or even RDBMs.
Nevertheless, Spark is enriched with other features and APIs. For example, recently Cisco has announced to invest $150M in the Spark ecosystem towards Cisco Spark Hybrid Services (http://www.cisco.com/c/en/us/solutions/collaboration/cloud-collaboration/index.html). So Cisco Spark open APIs could boost its popularity with developers in higher cardinality (highly secure collaboration and connecting smartphone systems to the cloud). Beyond this, Spark has recently integrated Tachyon (http://ampcamp.berkeley.edu/5/exercises/tachyon.html), a distributed in-memory storage system that economically fits in memory to further improve Spark's performance.
Spark itself is written in Scala, which is functional, as well as Object Oriented Programming Language (OOPL) which runs on top of JVM. Moreover, as mentioned in Figure 5, Spark's ecosystem is built on top of the general and core execution engine, which has some extensible API's implemented in different languages. The lower level layer or upper level layer also uses the Spark core engine as a general execution job performing engine and it provides all other functionality on top. The Spark Core is written in Scala as already mentioned, and it runs on Java Virtual Machine (JVM) and the high-level APIs (that is, Spark MLlib, SparkR, Spark SQL, Dataset, DataFrame, Spark Streaming, and GraphX) that use the core in the execution time.
Spark has brought the in-memory computing mode to a great visibility. This concept (in-memory computing) enables the Spark core engine to leverage speed through a generalized execution model to develop diverse applications.
The low-level implementation of general purpose data computing and machine learning algorithms written in Java, Scala, R, and Python are easy to use for big data application development. The Spark framework is built on Scala, so developing ML applications in Scala can provide access to the latest features that might not be available in other Spark languages initially. However, that is not a big problem, open source communities also take care of the necessity of developers around the globe. Therefore, if you do need a particular machine learning algorithm to be developed, and you want to add it to the Spark library, you can contribute it to the Spark community. The source code of Spark is openly available on GitHub at https://github.com/apache/spark as Apache Spark mirror. You can do a pull out request and the open source community will review your changes or algorithm before adding it to the master branch. For more information, please check the Spark Jira confluence site at https://cwiki.apache.org/confluence/display/SPARK/Contributing+to+Spark.
Python was a great arsenal for data scientists previously, and the contribution of Python in Spark is also not different. That means Python also has some excellent libraries for data analysis and processing; however, it is comparatively slower than Scala. R on the other hand, has a rich environment for data manipulation, data pre-processing, graphical analysis, machine learning, and statistical analysis, which can help to increase the developer's productivity. Java is definitely a good choice for developers who are coming from the Java and Hadoop background. However, Java also has the similar problem as Python, since Java is also slower than Scala.
A recent survey presented on the Databricks website at http://go.databricks.com/2015-spark-survey on Spark users (66% users evaluated the Spark languages where 41% were data engineers and 22% were data scientists) shows that 58% are using Python, 71% are using Scala, 31% are using Java, and 18% are using R for developing their Spark applications. However, in this book, we will try to provide the examples mostly in Java and a few in Scala if needed for the simplicity. The reason for this is that many of the readers are very familiar with Java-based MapReduce. Nevertheless, we will provide some hints of using the same examples in Python or R in the appendix at the end.
Spark SQL is a Spark component for querying and structured data processing. The demand was obvious since many data science engineers and business intelligence analysts also rely on interactive SQL queries for exploring data from RDBMS. Previously, MS SQL server, Oracle, and DB2 were used frequently by the enterprise. However, these tools were not scalable or interactive. Therefore, to make it easier, Spark SQL provides a programming abstraction called DataFrames and datasets that work as distributed SQL query engines, which support unmodified Hadoop Hive queries to execute 100 times faster on existing deployments and data. Spark SQL is a powerful integration with the rest of the Spark ecosystem.
Recently, Spark has offered a new experimental interface, commonly referred to as datasets (to be discussed in more details in the next section), which provide the same benefits of RDDs to use the lambda functions strongly. Lambda evolves from the Lambda Calculus (http://en.wikipedia.org/wiki/Lambda_calculus) that refers to anonymous functions in computer programming. It is a flexible concept in modern programming language that allows you to write any function quickly without naming them. In addition, it also provides a nice way to write closures. For example, in Python:
def adder(x):
return lambda y: x + y
add6 = adder(6)
add4(4)
It returns the result as 10. On the other hand, in Java, it can be similarly written if an integer is odd or even:
Subject<Integer> sub = x -> x % 2 = 0; // Tests if the parameter is even. boolean result = sub.test(8);
The previous lambda function checks if the parameter is even and returns either true or false. For example, the preceding snippet would return true since 8 is divisible by 2.
Please note that in Spark 2.0.0, the Spark SQL has substantially been improved with the SQL functionalities with SQL 2003 support. Therefore, Spark SQL can now be executed with all the 99 TPC-DS queries. More importantly, now a native SQL parser supports ANSI_SQL and Hive QL. Native DDL is a command that can also be executed, it also now supports sub querying of SQL and the view of canonicalization support.
In the latest Spark release 2.0.0, in Scala and Java, the DataFrame and dataset have been unified. In other words, the DataFrame is just a type alias for a dataset of rows. However, in Python and R, given the lack of type safety, DataFrame is the main programming interface. And for Java, DataFrame is no longer supported, but only the Dataset and RDD-based computations are supported, and DataFrame has become obsolete (note that it has become obsolete - not depreciated). Although SQLContext and HiveContext are kept for backward compatibility; however, in Spark 2.0.0 release, the new entry point that replaces the old SQLContext and HiveContext for DataFrame and dataset APIs is SparkSession.
You might want your applications to have the ability to process and analyze not only static datasets, but also real-time streams data. To make your wish easier, Spark Streaming provides the facility to integrate your application with popular batch and streaming data sources. The most commonly used data sources include HDFS, Flume, Kafka, and Twitter, and they can be used through their public APIs. This integration allows users to develop powerful interactive and analytical applications on both streaming and historical data. In addition to this, the fault tolerance characteristics are achieved through Spark streaming.
GraphX is a resilient distributed graph computation engine built on top of Spark. GraphX brought a revolution to the users who want to interactively build, transform, and reason graph structured data with millions of nodes and vertices at scale. As a developer you will enjoy the simplicity so that a large-scale graph (social network graph, normal network graph, or astrophysics) could be represented using a small chunk of code written in Scala, Java, or Python. GraphX enables the developers to take the advantages of both data-parallel and graph-parallel systems by efficiently expressing graph computation with ease and speed. Another beauty added in the cabinet of GraphX is that it can be used to build an end-to-end graph analytical pipeline on real-time streaming data, where the graph-space partitioning is used to handle large-scale directed multigraph with properties associated with each vertex and edge. Well, some fundamental graph operators are used to make this happen such as subgraph, joinVertices and aggregateMessages as well as an optimized variant of the Pregel API in particular.
Traditional machine learning applications were used to build using R or Matlab that lacks scalability issues. Spark has brought two emerging APIs, Spark MLlib and Spark ML. These APIs make the machine learning as an actionable insight for engineering big data to remove the scalability constraint. Built on top of Spark, MLlib is a scalable machine learning library that is enriched with numerous high-quality algorithms with a high-accuracy performance that mainly works for RDDs. Spark provides many language options for the developers that are functioning in Java, Scala, R, and Python to develop complete workflows. Spark ML, on the other hand, is an ALPHA component that enhances a new set of machine learning algorithms to let data scientists quickly assemble and configure practical machine learning pipelines on top of DataFrames.
SparkR is an R package specially designed for the data scientists who are familiar with R language and want to analyze large datasets and interactively run jobs from the R shell, which supports all the major Spark DataFrame operations such as aggregation, filtering, grouping, summary statistics, and much more. Similarly, users also can create SparkR DataFrames from local R data frames, or from any Spark supported data sources such as Hive, HDFS, Parquet, or JSON. Technically speaking, the concept of Spark DataFrame is a tabular data object akin to R's native DataFrame (https://cran.r-project.org/web/packages/dplyr/vignettes/data_frames.html), which on the other hand, is syntactically similar to dplyr (an R package, refer to https://cran.rstudio.com/web/packages/dplyr/vignettes/introduction.html), but is stored in the cluster setting instead.