
C H A P T E R 10
![]()
Unicode, Internationalization, and Currency Codes
The Java platform provides a rich set of internationalization features to help you create applications that can be used across the world. The platform provides the means to localize your applications, format dates and numbers in a variety of culturally-sensitive formats, and display characters used in dozens of writing systems.
This chapter describes only some of the most frequent and common tasks that programmers must perform when developing internationalized applications. Because Java 7 adds new features around its abstraction of languages and regions, this chapter describes some of the new ways you might use the Locale class.
![]() NOTE: The source code for this chapter's examples is available in the
NOTE: The source code for this chapter's examples is available in the org.java7recipes.chapter10 package. Please see the introductory chapters for instructions on how to find and download sample source code.
10-1. Converting Unicode Characters to Digits
Problem
You want to convert a Unicode digit character to its respective integer value. For example, you have a string containing the Thai digit for the value 8 and you wish to generate an integer with that value.
Solution
The java.lang.Character class has several static methods to convert characters to integer digit values:
public static intdigit(char ch, int radix)public static intdigit(intch, int radix)
The following code snippet iterates through the entire range of Unicode code points from 0x0000 through 0x10FFFF. For each code point that is also a digit, it displays the character and its digit value 0 through 9. You can find this example in the org.java7recipes.chapter10.DigitConversion class.
int x = 0;
for (int c=0; c <= 0x10FFFF; c++) {
if (Character.isDigit(c)) {
++x;
System.out.printf("Codepoint: 0x%04X Character: %c Digit: %d Name: %s
", c, c,
Character.digit(c, 10), Character.getName(c));
}
}
System.out.printf("Total digits: %d
", x);
Some of the output follows:

![]() NOTE: The sample code prints to the console. Your console may not print all the character glyphs shown in this example because of font or platform differences. However, the characters will be converted to integers correctly.
NOTE: The sample code prints to the console. Your console may not print all the character glyphs shown in this example because of font or platform differences. However, the characters will be converted to integers correctly.
How It Works
The Unicode character set is large, containing more than a million unique code points with integer values ranging from 0x0000 through 0x10FFFF. Each character value has a set of properties. One of the properties is the isDigit property. If this property is true, the character represents a numeric digit from 0 through 9. For example, the characters with code point values 0x30 through 0x39 have the character glyphs 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. If you simply convert these code values to their corresponding integer values, you would get the hexadecimal values 0x30 through 0x39. The corresponding decimal values are 48 through 57. However, these characters also represent numeric digits. When using them in calculations, we expect these characters to represent the values 0 through 9.
When a character has the digit property, use the Character.digit() static method to convert it to its corresponding integer digit value. Note that the digit() method is overloaded to accept either char or int arguments. Additionally, the method requires a radix. Common values for radix are 2, 10, and 16. Interestingly, although the characters a-f and A-F do not have the digit property, they can be used as digits using radix 16. For these characters, the digit() method returns the expected integer values 10 through 15.
A complete understanding of the Unicode character set and Java's implementation requires familiarity with several new terms: character, code point, char, encoding, serialization encoding, UTF-8, UTF-16. These terms are beyond the scope of this recipe, but you can learn more about these and other Unicode concepts from the Unicode web site at http://unicode.org or from the Character class Java API documentation.
10-2. Creating and Working with Locales
Problem
You want to display numbers, dates, and time in a user-friendly way that conforms to the language and cultural expectations of your customers.
Solution
The display format for numbers, dates, and time varies across the world and depends upon your user's language and cultural region. Additionally, text collation rules vary by language. The java.util.Locale class represents a specific language and region of the world. By determining and using your customer's locale, you can apply that locale to a variety of format classes that create user-visible data in expected forms. Classes that use Locale instances to modify their behavior for a particular language or region are called locale-sensitive classes. You can learn more about locale-sensitive classes in the “Numbers and Dates” chapter. That chapter shows you how to use Locale instances in the NumberFormat and DateFormat classes. In this recipe, however, you will learn options for creating these Locale instances.
Create a Locale instance in any of the following ways:
- Use the
Locale.Builderclass to configure and build aLocaleobject. - Use the static
Locale.forLanguageTag()method. - Use the
Localeconstructors to create an object. - Use preconfigured static
Localeobjects.
The Java 7 Locale.Builder class has setter methods that allow you to create locales that can be transformed into well-formed Best Common Practices (BCP) 47 language tags. The “How It Works” section will describe the BCP 47 standard in more detail. For now, you should simply understand that a Builder creates Locale instances that comply with that standard.
The following code snippet from the org.java7recipes.chapter10.LocaleCreator class demonstrates how to create Builder and Locale instances. You use the created locales in locale-sensitive classes to produce culturally correct display formats:
private static final long number = 123456789L;
private static final Date now = new Date();
private void createFromBuilder() {
System.out.printf("Creating from Builder...
");
String[][] langRegions = {{"fr", "FR"}, {"ja", "JP"}, {"en", "US"}};
Builder builder = new Builder();
Locale l = null;
NumberFormat nf = null;
DateFormat df = null;
for (String[] lr: langRegions) {
builder.clear();
builder.setLanguage(lr[0]).setRegion(lr[1]);
l = builder.build();
nf = NumberFormat.getInstance(l);
df = DateFormat.getDateTimeInstance(DateFormat.LONG, DateFormat.LONG, l);
System.out.printf("Locale: %s
Number: %s
Date: %s
",
l.getDisplayName(),
nf.format(number),
df.format(now));
}
The previous code prints the following to the standard console:
Creating from Builder...
Locale: French (France)
Number: 123 456 789
Date: 14 septembre 2011 00:08:06 PDT
Locale: Japanese (Japan)
Number: 123,456,789
Date: 2011/09/14 0:08:06 PDT
Locale: English (United States)
Number: 123,456,789
Date: September 14, 2011 12:08:06 AM PDT
Another way to create locale instances is by using the static Locale.forLanguageTag() method. This method allows you to use BCP 47 language tag arguments.The following code uses the forLanguageTag() method to create three locales from their corresponding language tags:
…
System.out.printf("Creating from BCP 47 language tags...
");
String[] bcp47LangTags= {"fr-FR", "ja-JP", "en-US"};
Locale l = null;
NumberFormat nf = null;
DateFormat df = null;
for (String langTag: bcp47LangTags) {
l = Locale.forLanguageTag(langTag);
nf = NumberFormat.getInstance(l);
df = DateFormat.getDateTimeInstance(DateFormat.LONG, DateFormat.LONG, l);
System.out.printf("Locale: %s
Number: %s
Date: %s
",
l.getDisplayName(),
nf.format(number),
df.format(now));
}
…
The output is similar to the results created from the Builder-generated locale instance:
Creating from BCP 47 language tags...
Locale: French (France)
Number: 123 456 789
Date: 14 septembre 2011 01:07:22 PDT
…
You can also use constructors to create instances. The following code shows how to do this:
Locale l = new Locale("fr", "FR");
Other constructors allow you to pass fewer or more arguments. The argument parameters can include language, region, and optional variant codes.
Finally, the Locale class has many predefined static instances for some commonly used cases. Because the instances are predefined, your code needs to reference only the static instances. For example, the following example shows how to reference existing static instances representing fr-FR, ja-JP, and en-US locales:
Locale frenchInFrance = Locale.FRANCE;
Locale japaneseInJapan = Locale.JAPAN;
Locale englishInUS = Locale.US;
Refer to the Locale Java API documentation for examples of other static instances.
How It Works
The Locale class gives locale-sensitive classes the context they need to perform culture-sensitive data formatting and parsing. Some of the locale-sensitive classes include the following:
java.text.NumberFormatjava.text.DateFormatjava.util.Calendar
A Locale instance identifies a specific language, and can be finely tuned to identify languages written in a particular script or spoken in a specific world region. Locale is an important and necessary element for creating anything thathas dependencies on language or regional influences.
The Java 7 Locale class introduces a few significant changes that give it support for modern BCP 47 language tags. BCP 47 defines Best Common Practices for using ISO standards for language, region, script, and variant identifiers. Although the existing Locale constructors continue to be compatible with prior versions of the Java platform, the constructors do not support the additional script tags. For example, only the new Locale.Builder class and Locale.forLanguageTag() method support the new functionality that identifies scripts. This new class and method were introduced in Java 7. Because the Locale constructors do not enforce strict BCP 47 compliance, you should avoid the constructors in any new code. Instead, developers should migrate their code to use the new Builder class and the forLanguageTag() method.
A Locale.Builder instance has a variety of setter methods that help you configure it to create a valid, BCP 47–compliant Locale instance:
public Locale.BuildersetLanguage(String language)public Locale.BuildersetRegion(String region)public Locale.BuildersetScript(String script)
Each of these methods throws a java.util.IllFormedLocaleException if its argument is not a well-formed element of the BCP 47 standard. The language parameter must be a valid two or three-letter ISO 639 language identifier. The region parameter must be a valid two-letter ISO 3166 region code or a three-digit M.49 United Nations “area” code. Finally, the script parameter must be a valid four-letter ISO 15924 script code.
The Builder lets you configure it to create a specific BCP 47–compliant Locale. Once you set all the configurations, the build() method creates and returns a Locale instance. Notice that all the setters can be chained together for a single statement. The Builder pattern works by having each configuration method return a reference to the current instance, on which further configuration methods may be called.
Locale aLocale = new Builder().setLanguage("fr").setRegion("FR").build();
The BCP 47 document and the standards that comprise it can be found at the following locations:
- BCP 47 (language tags):
http://www.rfc-editor.org/rfc/bcp/bcp47.txt - ISO 639 (language identifiers):
http://www.loc.gov/standards/iso639-2/php/code_list.php - ISO 3166 (region identifiers):
http://www.iso.org/iso/country_codes/iso_3166_code_lists/country_names_and_code_elements.htm - ISO 15924 (script identifiers):
http://unicode.org/iso15924/ - United Nations M.49 (Area identifiers):
http://unstats.un.org/unsd/methods/m49/m49.htm
10-3. Setting the Default Locale
Problem
You want to set the default locale for all locale-sensitive classes.
Solution
Use the Locale.setDefault() method to set a Locale instance that all locale-sensitive classes will use by default. This method is overloaded with two forms:
Locale.setDefault(Locale aLocale)Locale.setDefault(Locale.Category c, Locale aLocale)
This example code demonstrates how to set the default locale for all locale-sensitive classes:
Locale.setDefault(Locale.FRANCE);
You can also set the default for two additional locale categories, DISPLAY and FORMAT:
Locale.setDefault(Locale.Category.DISPLAY, Locale.US);
Locale.setDefault(Locale.Category.FORMAT, Locale.FR);
You can create code that uses these specific locale categories within your application to mix locale choices for different purposes. For example, you may choose to use the DISPLAY locale for ResourceBundle text while using the FORMAT locale for date and time formats. The example code from the org.java7recipes.chapter10.DefaultLocale class demonstrates this more complex usage:
public class DefaultLocale {
private static final Date NOW = new Date();
public void run() {
// Set ALL locales to fr-FR
Locale.setDefault(Locale.FRANCE);
demoDefaultLocaleSettings();
// System default is still fr-FR
// DISPLAY default is es-MX
// FORMAT default is en-US
Locale.setDefault(Locale.Category.DISPLAY, Locale.forLanguageTag("es-MX"));
Locale.setDefault(Locale.Category.FORMAT, Locale.US);
demoDefaultLocaleSettings();
// System default is still fr-FR
// DISPLAY default is en-US
// FORMAT default is es-MX
Locale.setDefault(Locale.Category.DISPLAY, Locale.US);
Locale.setDefault(Locale.Category.FORMAT, Locale.forLanguageTag("es-MX"));
demoDefaultLocaleSettings();
// Reset system, DISPLAY, and FORMAT locales to en-US.
Locale.setDefault(Locale.US);
demoDefaultLocaleSettings();
}
public void demoDefaultLocaleSettings() {
DateFormat df = DateFormat.getDateTimeInstance(DateFormat.SHORT, DateFormat.SHORT);
ResourceBundle resource =
ResourceBundle.getBundle("org.java7recipes.chapter10.recipe10_1.resource.
SimpleResources",
Locale.getDefault(Locale.Category.DISPLAY));
String greeting = resource.getString("GOOD_MORNING");
String date = df.format(NOW);
System.out.printf("DEFAULT LOCALE: %s
", Locale.getDefault());
System.out.printf("DISPLAY LOCALE: %s
", Locale.getDefault(Locale.Category.DISPLAY));
System.out.printf("FORMAT LOCALE: %s
", Locale.getDefault(Locale.Category.FORMAT));
System.out.printf("%s, %s
", greeting, date );
}
public static void main(String[] args) {
DefaultLocale app = new DefaultLocale();
app.run();
}
}
This code produces the following output:
DEFAULT LOCALE: fr_FR
DISPLAY LOCALE: fr_FR
FORMAT LOCALE: fr_FR
Bonjour!, 19/09/11 20:31
DEFAULT LOCALE: fr_FR
DISPLAY LOCALE: es_MX
FORMAT LOCALE: en_US
¡Buenos días!, 9/19/11 8:31 PM
DEFAULT LOCALE: fr_FR
DISPLAY LOCALE: en_US
FORMAT LOCALE: es_MX
Good morning!, 19/09/11 08:31 PM
DEFAULT LOCALE: en_US
DISPLAY LOCALE: en_US
FORMAT LOCALE: en_US
Good morning!, 9/19/11 8:31 PM
How It Works
The Locale class allows you to set the default Locale for two different categories. The categories are represented by the Locale.Category enumeration:
Locale.Category.DISPLAYLocale.Category.FORMAT
Use the DISPLAY category for your application's user interface. Setting the default DISPLAY locale means that the ResourceBundle class can load user interface resources for that particular locale independently from the FORMAT locale. Setting the FORMAT default locale affects how the various Format subclasses behave. For example, a default DateFormat instance will use the FORMAT default locale to create a locale-sensitive output format. Again, these two categories are independent, so you can use different Locale instances for different needs.
In this recipe's sample code, the Locale.setDefault(Locale.FRANCE) method call sets the default system, DISPLAY, and FORMAT locales to fr-FR (French in France). This method always resets both DISPLAY and FORMAT locales to match the system locale. When creating a new resource bundle, the ResourceBundle class uses the system locale by default. However, by providing a locale instance argument, you tell the bundle to load resources for a specific locale. For example, even though the system locale is Locale.FRANCE, you can specify a DISPLAY default locale and use that DISPLAY locale in your ResourceBundle.getBundle() method call. For example, this code attempts to load a language bundle for es-MX even though the system locale is still Locale.FRANCE:
Locale.setDefault(Locale.Category.DISPLAY, Locale.forLanguageTag("es-MX"));
Locale.setDefault(Locale.Category.FORMAT, Locale.US);
DateFormat df = DateFormat.getDateTimeInstance(DateFormat.SHORT, DateFormat.SHORT);
ResourceBundle resource =
ResourceBundle.getBundle("org.java7recipes.chapter10..resource.SimpleResources",
Locale.getDefault(Locale.Category.DISPLAY));
String greeting = resource.getString("GOOD_MORNING");
In this case, it finds a GOOD_MORNING resource with the “¡Buenos días!” value because the DISPLAY default locale is an argument. The resource bundle is a file with translated property strings for various locales. The file named SimpleResources_en.properties (English) has a GOOD_MORNING property that is written “Good morning!” Note that translations of each property in the resource bundle must exist in the locale-specific resource files in order to be displayed. The Java code does not translate these strings. Instead, it just selects an appropriate translation of the desired property based on the selected locale.
![]() NOTE: Although
NOTE: Although DateFormat and NumberFormat classes will automatically use the default FORMAT locale if you do not provide a locale argument in their creation method, the ResourceBundle.getBundle() method always uses the system locale by default. To use the DISPLAY default locale in a ResourceBundle(), you must explicitly provide it as an argument.
10-4. Searching Unicode with Regular Expressions
Problem
You want to find or match Unicode characters in a String. You want to do that using regular expression syntax.
Solution 1
The easiest way to find or match characters is to use the String class itself. String instances store Unicode character sequences and provide relatively simple operations for finding, replacing, and tokenizing characters using regular expressions.
To determine whether a String matches a regular expression, use the matches() method. The matches() method returns true if the entire string exactly matches the regular expression.
The following code from the org.java7recipes.chapter10.Regex class uses two different expressions with two strings. The regular expression matches simply confirm that the strings match a particular pattern as defined in the variables enRegEx and jaRegEx.
private String enText = "The fat cat sat on the mat with a brown rat.";
private String jaText = "Fight 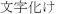 !";
!";
boolean found = false;
String enRegEx = "^The \w+ cat.*";
String jaRegEx = ".*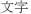 .*";
.*";
String jaRegExEscaped = ".*u6587u5B57.*";
found = enText.matches(enRegEx);
if (found) {
System.out.printf("Matches %s.
", enRegEx);
}
found = jaText.matches(jaRegEx);
if (found) {
System.out.printf("Matches %s.
", jaRegEx);
}
found = jaText.matches(jaRegExEscaped);
if (found) {
System.out.printf("Matches %s.
", jaRegExEscaped);
}
This code prints the following:
Matches ^The w+ cat.*.
Matches .*.*.
Matches .*.*.
Use the replaceFirst() method to create a new String instance in which the first occurrence of the regular expression in the target text is replaced with the replacement text. The code demonstrates how to use this method:
String replaced = jaText.replaceFirst("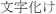 ", "mojibake");
", "mojibake");
System.out.printf("Replaced: %s
", replaced);
The replacement text is shown in the output:
Replaced: Fight mojibake!
The replaceAll() method replaces all occurrences of the expression with the replacement text.
Finally, the split() method creates a String[] that contains text that is separated by the matched expression. In other words, it returns text that is delimited by the expression. Optionally, you can provide a limit argument that constrains the number of times the delimiter will be applied in the source text. The following code demonstrates the split() method splitting on space characters:
String[] matches = enText.split("\s", 3);
for(String match: matches) {
System.out.printf("Split: %s
",match);
}
The code's output is as follows:
Split: The
Split: fat
Split: cat sat on the mat with a brown rat.
Solution 2
When the simple String methods aren't sufficient, you can use the more powerful java.util.regex package to work with regular expressions. Create a regular expression using the Pattern class. A Matcher works on a String instance using the pattern. All Matcher operations perform their functions using Pattern and String instances.
The following code demonstrates how to search for both ASCII and non-ASCII text in two separate strings. See the org.java7recipes.chapter10.Regex class for the complete source code. The demoSimple() method finds text with any character followed by ".at". The demoComplex() method finds two Japanese symbols in a string:
public void demoSimple() {
Pattern p = Pattern.compile(".at");
Matcher m = p.matcher(enText);
while(m.find()) {
System.out.printf("%s
", m.group());
}
}
public void demoComplex() {
Pattern p = Pattern.compile("");
Matcher m = p.matcher(jaText);
if (m.find()) {
System.out.println(m.group());
}
}
Running these two methods on the previously defined English and Japanese text shows the following:
fat
cat
sat
mat
rat
How It Works
The String methods that work with regular expressions are the following:
public boolean matches(String regex)public String replaceFirst(String regex, String replacement)public String replaceAll(String regex, String replacement)public String[] split(String regex, int limit)public String[] split(String regex)
The String methods are limited and relatively simple wrappers around the more powerful functionality of the java.util.regex classes:
java.util.regex.Patternjava.util.regex.Matcherjava.util.regex.PatternSyntaxException
The Java regular expressions are similar to those used in the Perl language. Although there is a lot to learn about Java regular expressions, probably the most important points to understand from this recipe are these:
- Your regular expressions can definitely contain non-ASCII characters from the full range of Unicode characters.
- Because of a peculiarity of how the Java language compiler understands the backslash character, you will have to use two backslashes in your code instead of one for the predefined character class expressions.
The most convenient and readable way to use non-ASCII characters in regular expressions is to type them directly into your source files using your keyboard input methods. Operating systems and editors differ in how they allow you to enter complex text outside of ASCII. Regardless of operating system, you should save the file in the UTF-8 encoding if your editor allows. As an alternate but more difficult way to use non-ASCII regular expressions, you can encode characters using the uXXXX notation. Using this notation, instead of directly typing the character using your keyboard, you enter "u" or "U", followed by the hexadecimal representation of the Unicode code point. This recipe's code sample uses the Japanese word “![]() ” (pronounced mo-ji). As the example shows, you can use the actual characters in the regular expression or you can look up the Unicode code point values instead. For this particular Japanese word, the encoding will be “u6587u5B57”.
” (pronounced mo-ji). As the example shows, you can use the actual characters in the regular expression or you can look up the Unicode code point values instead. For this particular Japanese word, the encoding will be “u6587u5B57”.
The Java language's regular expression support includes special character classes. For example, d and w are shortcut notations for the regular expressions [0-9] and [a-zA-Z_0-9], respectively. However, because of the Java compiler's special handling of the backslash character, you must use an extra backslash when using predefined character classes such as d (digits), w (word characters), and s (space characters). To use them in source code, for example, you would enter "\d", "\w", and "\s", respectively. The sample code used the double backslash in Solution 1 to represent the w character class:
String enRegEx = "^The \w+ cat.*";
10-5. Overriding the Default Currency
Problem
You want to display a number value using a currency that is not associated with the default locale.
Solution
Take control of what currency is printed with a formatted currency value by explicitly setting the currency used in a NumberFormat instance. The following example assumes that the default locale is Locale.JAPAN. It changes the currency by calling the setCurrency(Currency c) method of its NumberFormat instance. This example comes from the org.java7recipes.chapter10.CurrencyOverride class
BigDecimal value = new BigDecimal(12345);
System.out.printf("Default locale: %s
", Locale.getDefault().getDisplayName());
NumberFormat nf = NumberFormat.getCurrencyInstance();
String formattedCurrency = nf.format(value);
System.out.printf("%s
", formattedCurrency);
Currency c = Currency.getInstance(Locale.US);
nf.setCurrency(c);
formattedCurrency = nf.format(value);
System.out.printf("%s
", formattedCurrency);
The previous code prints out the following:
Default locale: 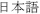 (
(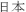 )
)
¥12,345
USD12,345
How It Works
You will use a NumberFormat instance to format currency values. You should explicitly call the getCurrencyInstance() method to create a formatter for currencies:
NumberFormat nf = NumberFormat.getCurrencyInstance();
The previous formatter will use your default locale's preferences for formatting numbers as currency values. Also, it will use a currency symbol that is associated with the locale's region. However, one very common use case involves formatting a value for a different region's currency.
Use the setCurrency() method to explicitly set the currency in the number formatter:
nf.setCurrency(aCurrencyInstance); // requires a Currency instance
Note that the java.util.Currency class is a factory. It allows you to create currency objects in two ways:
Currency.getInstance(Locale locale)Currency.getInstance(String currencyCode)
The first getInstance call uses a Locale instance to retrieve a currency object. The Java platform associates a default currency with the locale's region. In this case, the default currency currently associated with the United States is the U.S. dollar:
Currency c1 = Currency.getInstance(Locale.US);
The second getInstance call uses a valid ISO 4217 currency code. The currency code for the U.S. dollar is USD:
Currency c2 = Currency.getInstance("USD");
Once you have a currency instance, you simply have to use that instance in your formatter:
nf.setCurrency(c2);
This formatter now is configured to use the default locale's number format symbols and patterns to format the number value, but it will display the targeted currency code as part of the displayable text. This allows you to mix the default number format patterns with other currency codes.
![]() Note Currencies have both symbols and codes. A currency code always refers to the three-letter ISO 4217 code. A currency symbol is often different from the code. For example, the U.S. dollar has the code
Note Currencies have both symbols and codes. A currency code always refers to the three-letter ISO 4217 code. A currency symbol is often different from the code. For example, the U.S. dollar has the code USD and the symbol $. A currency formatter will typically use a symbol when formatting a number in the default locale using the currency of that locale's region. However, when you explicitly change the currency of a formatter, the formatter doesn't always have knowledge of a localized symbol for the target currency. In that case, the format instance will often use the currency code in the displayed text.
10-6. Converting Byte Arrays to and from Strings
Problem
You need to convert characters in a byte array from a legacy character set encoding to a Unicode String.
Solution
Convert legacy character encodings from a byte array to a Unicode String using the String class. The following code snippet from the org.java7recipes.CharacterEncodingConversion class demonstrates how to convert a legacy Shift-JIS encoded byte array to a String. Later in this same example, the code demonstrates how to convert from Unicode back into the Shift-JIS byte array.
byte[] legacySJIS = {(byte)0x82,(byte)0xB1,(byte)0x82,(byte)0xF1,
(byte)0x82,(byte)0xC9,(byte)0x82,(byte)0xBF,
(byte)0x82,(byte)0xCD,(byte)0x81,(byte)0x41,
(byte)0x90,(byte)0xA2,(byte)0x8A,(byte)0x45,
(byte)0x81,(byte)0x49};
// Convert a byte[] to a String
Charset cs =Charset.forName("SJIS");
String greeting = new String(legacySJIS, cs);
System.out.printf("Greeting: %s
", greeting);
The previous code prints out the converted text, which is “Hello, world!” in Japanese:
Greeting: 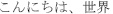 !
!
Use the getBytes() method to convert characters from a String to a byte array. Building upon the previous code, convert back to the original encoding with the following code, and compare the results:
// Convert a String to a byte[]
byte[] toSJIS = greeting.getBytes(cs);
// Confirm that the original array and newly converted array are same
Boolean same = false;
if (legacySJIS.length == toSJIS.length) {
for (int x=0; x< legacySJIS.length; x++) {
if(legacySJIS[x] != toSJIS[x]) break;
}
same = true;
}
System.out.printf("Same: %s
", same.toString());
As expected, the output indicates that the round-trip conversion back to the legacy encoding was successful. The original byte array and the converted byte array contain the same bytes:
Same: true
How It Works
The Java platform provides conversion support for many legacy character set encodings. When you create a String instance from a byte array, you must provide a Charset argument to the String constructor so that the platform knows how to perform the mapping from the legacy encoding to Unicode. All Java Strings use Unicode as their native encoding.
The number of bytes in the original array does not usually equal the number of characters in the result string. In this recipe's example, the original array contains 18 bytes. The 18 bytes are needed by the Shift-JIS encoding to represent the Japanese text. However, after conversion, the result string contains nine characters. There is not a 1:1 relationship between bytes and characters. In this example, each character requires two bytes in the original Shift-JIS encoding.
There are literally hundreds of different charset encodings. The number of encodings is dependent upon your Java platform implementation. However, you are guaranteed support of several of the most common encodings, and your platform most likely contains many more than this minimal set:
- US-ASCII
- ISO-8859-1
- UTF-8
- UTF-16BE
- UTF-16LE
- UTF-16
When constructing a Charset, you should be prepared to handle the possible exceptions that can occur when the character set is not supported:
java.nio.charset.IllegalCharsetNameException, thrown when the charset name is illegaljava.lang.IllegalArgumentException, thrown if charset name isnulljava.nio.charset.UnsupportedCharsetException, thrown if your JVM doesn't support the targeted charset
10-7. Converting Character Streams and Buffers
Problem
You need to convert large blocks of Unicode character text to and from an arbitrary byte-oriented encoding. Large blocks of text may come from streams or files.
Solution 1
Use the java.io.InputStreamReader to decode a byte stream to Unicode characters. Use java.io.OutputStreamWriter to encode Unicode characters to a byte stream.
The following code uses an InputStreamReader to read and convert a potentially large block of text bytes from a file in the classpath. The org.java7reciptes.chapter10.StreamConversion class provides the complete code for this example:
public String readStream() throws IOException {
InputStream is = getClass().getResourceAsStream("resource/helloworld.sjis.txt");
InputStreamReader reader = null;
StringBuilder sb = new StringBuilder();
if (is != null){
reader = new InputStreamReader(is, Charset.forName("SJIS"));
int ch = reader.read();
while(ch != -1) {
sb.append((char)ch);
ch = reader.read();
}
reader.close();
}
return sb.toString();
}
Similarly, you can use an OutputStreamWriter to write text to a byte stream. The following code writes a String to a UTF-8 encoded byte stream:
public void writeStream(String text) throws IOException {
OutputStreamWriter writer = null;
FileOutputStream fos = new FileOutputStream("helloworld.utf8.txt");
writer = new OutputStreamWriter(fos, Charset.forName("UTF-8"));
writer.write(text);
writer.close();
}
Solution 2
Use a java.nio.charset.CharsetEncoder and java.nio.charset.CharsetDecoder to convert Unicode character buffers to and from byte buffers. Retrieve an encoder or decoder from a Charset instance with the newEncoder() or newDecoder() method. Then use the encoder's encode() method to create byte buffers. Use the decoder's decode() method to create character buffers. The following code from the org.java7recipes.BufferConversion class encodes and decodes character sets from buffers:
public ByteBuffer encodeBuffer(String charsetName, CharBuffer charBuffer)
throws CharacterCodingException {
Charset charset = Charset.forName(charsetName);
CharsetEncoder encoder = charset.newEncoder();
ByteBuffer targetBuffer = encoder.encode(charBuffer);
return targetBuffer;
}
public CharBuffer decodeBuffer(String charsetName, ByteBuffer srcBuffer)
throws CharacterCodingException {
Charset charset = Charset.forName(charsetName);
CharsetDecoder decoder = charset.newDecoder();
CharBuffer charBuffer = decoder.decode(srcBuffer);
return charBuffer;
}
How It Works
The java.io and java.nio.charset packages contain several classes that can help you perform encoding conversions on large text streams or buffers. Streams are convenient abstractions that can assist you in converting text using a variety of sources and targets. A stream can represent incoming or outgoing text in an HTTP connection or even a file.
If you use an InputStream to represent the underlying source text, you will wrap that stream in an InputStreamReader to perform conversions from a byte stream. The reader instance performs the conversion from bytes to Unicode characters.
Using an OutputStream instance to represent the target text, wrap the stream in an OutputStreamWriter. A writer will convert your Unicode text to a byte-oriented encoding in the target stream.
To effectively use either an OutputStreamWriter or an InputStreamReader, you must know the character encoding of your target or source text. When you use an OutputStreamWriter, the source text is always Unicode, and you must supply a Charset argument to tell the writer how to convert to the target byte-oriented text encoding. When you use an InputStreamReader, the target encoding is always Unicode. You must supply the source text encoding as an argument so that the reader understands how to convert the text.
![]() Note The Java platform's
Note The Java platform's String represents characters in the UTF-16 encoding of Unicode. Unicode can have several encodings, including UTF-16, UTF-8, and even UTF-32. Converting to Unicode in this discussion always means converting to UTF-16. Converting to a byte-oriented encoding usually means to a legacy non–Unicode charset encoding. However, a common byte-oriented encoding is UTF-8, and it is entirely reasonable to convert Java's “native” UTF-16 Unicode characters to or from UTF-8 using the InputStreamReader or OutputStreamWriter classes.
Yet another way to perform encoding conversions is to use the CharsetEncoder and CharsetDecoder classes. A CharsetEncoder will encode your Unicode CharBuffer instances to ByteBuffer instances. A CharsetDecoder will decode ByteBuffer instances into CharBuffer instances. In either case, you must provide a Charset argument.
A Charset represents a character set encoding in defined in the IANA Charset Registry. When creating a Charset instance, you should use the canonical or alias names of the charset as defined by the registry. You can find the registry at http://www.iana.org/assignments/character-sets.
Remember that your Java implementation will not necessarily support all the IANA charset names. However, all implementations are required to support at least those shown in recipe 10-6 of this chapter.