
Chapter 13
Service Design Processes: Service Level Management and Availability Management
THE FOLLOWING ITIL INTERMEDIATE EXAM OBJECTIVES ARE DISCUSSED IN THIS CHAPTER:
- ✓ Service level management and availability management are discussed in terms of
- Purpose
- Objectives
- Scope
- Value
- Policies
- Principles and basic concepts
- Process activities, methods, and techniques
- Triggers, inputs, outputs, and interfaces
- Information management
- Critical success factors and key performance indicators
- Challenges
- Risks
 The ITIL service design core volume covers the managerial and supervisory aspects of service design processes. It excludes the day-to-day operation of each process and the details of the process activities, methods, and techniques and its information management. More detailed process operation guidance is covered in the service capability courses. Each process is considered from the management perspective. That means at the end of this chapter, you should understand those aspects that would be required to understand each process and its interfaces, oversee its implementation, and judge its effectiveness and efficiency.
The ITIL service design core volume covers the managerial and supervisory aspects of service design processes. It excludes the day-to-day operation of each process and the details of the process activities, methods, and techniques and its information management. More detailed process operation guidance is covered in the service capability courses. Each process is considered from the management perspective. That means at the end of this chapter, you should understand those aspects that would be required to understand each process and its interfaces, oversee its implementation, and judge its effectiveness and efficiency.
Service Level Management
The service level management (SLM) process requires a constant cycle of negotiating, agreeing, monitoring, reporting on, and reviewing IT service targets and achievements. Improvements and corrections to service levels will be managed as part of continual service improvement and through instigation of actions to correct or improve the level of service delivered.
Purpose of Service Level Management
We will begin by looking at the purpose of the service level management process according the ITIL framework. ITIL states that the purpose of service level management is to ensure that all current and planned IT services are delivered to agreed achievable targets. The key words here are agreed and targets. Service level management is about discussing, negotiating, and agreeing with the customer about what IT services should be provided and ensuring that objective measures are used to ascertain whether that service has been provided to the agreed level.
Service level management is therefore concerned with defining the services, documenting them in an agreement, and then ensuring that the targets are measured and met, taking action where necessary to improve the level of service delivered. These improvements will often be carried out as part of continual service improvement.
Note also that the definition of service level management talks about current and planned IT services. Service level management’s purpose is not only to ensure that all IT services currently being delivered have a service level agreement (SLA) in place, but also to ensure that discussion and negotiation takes place regarding the requirements for planned services so that an SLA is agreed on and in place when the service becomes operational.
It is for this latter reason that service level management is one of the service design processes; services must be designed to deliver the levels of availability, capacity, and so on that the customer requires and that service level management documents in the SLA. It is a frequent problem that the SLA is not considered until just before (or even after) the go-live date, when it is realized that the customer’s service level requirements are not met by the design. Service level management is concerned primarily with the warranty aspects of the service. The response time, capacity, availability, and so on of the new service will be the subject of the SLA, and it is essential that the service is therefore designed to meet both utility and warranty requirements.
Objectives of Service Level Management
The objectives of service level management are not restricted to “define, document, agree, monitor, measure, report, and review” (how well the IT service is delivered) and undertaking improvement actions when necessary. It also includes working with business relationship management to build a good working relationship with the business customers. The regular meetings held with the business as part of service level management form the basis of a strong communications channel that strengthens the relationship between the customer and IT.
It is an essential feature of service level management that the customer and IT agree on what constitutes an acceptable level of service. Therefore, one of the objectives of SLM is to develop appropriate targets for each IT service. These targets must be specific and measurable so that there is no debate whether they were achieved. The temptation to use expressions such as “as soon as possible” and “reasonable endeavors” should be resisted because the customer and IT may disagree on what constitutes “as soon as possible” or what is “reasonable.” By using such expressions in an SLA, it may be impossible for the IT service provider to fail, but this leads to cynicism from the customer and damages the relationship that the SLM aims to build. Where the IT service provider is an external company, the legal department will inevitably seek to reduce the possibility of the provider being sued for breach of contract, and these phrases may therefore be included; for an internal service provider, there is no such excuse. Using objective success criteria is essential if SLM is to achieve another of its objectives, that of ensuring that both the customer and IT have “clear and unambiguous expectations” regarding the level of service.
A further SLM objective is to ascertain the level of customer satisfaction with the service being provided and to take steps to increase it. There are challenges in this objective, because obtaining an accurate assessment of customer satisfaction is not straightforward. Customer satisfaction surveys may be completed only by a self-selecting minority. Those who are unhappy are more likely to complete such a survey than those who are content. Despite this tendency, the service level manager must still attempt to monitor customer satisfaction as accurately as possible, using whatever methods are appropriate; in addition to surveys, focus groups, and individual interviews, other methods can be employed.
The final objective that ITIL lists for service level management is that of improving the level of service even when the targets are being met. Such improvements must be cost-effective, so an analysis of the return expected for any financial or resource investment must be carried out. SLM actively seeks out opportunities for such cost-effective improvements. Achieving this objective forms part of the continual service improvement that is an essential element in all ITIL processes.
Scope of Service Level Management
The scope of service level management includes the performance of existing services being provided and the definition of required service levels for planned services. It forms a regular communication channel between the business and the IT service provider on all issues concerning the quality of service. SLM therefore has an important role to play in managing customers’ expectations to ensure that the level of service they expect and the level of service they perceive they are receiving match. As stated earlier, SLM is concerned with ensuring that the warranty aspects of a service are provided to the expected level. The level of service expected for planned services is detailed in the service level requirements (SLRs), and the agreed service levels (following negotiation) are documented in the SLA. SLAs should be written to cover all operational services. Through this involvement in the design phase, SLM ensures that the planned services will deliver the warranty levels required by the business.
Service Level Management Value to the Business
Each IT service is composed of a number of elements provided by internal support teams or external third-party suppliers. An essential element of successful service level management is the negotiation and agreement with those who provide each element of the level of service they provide. A failure by these providers will translate to a failure to meet the SLA. These agreements are called operational level agreements (OLAs) in the case of internal teams and underpinning contracts in the case of external suppliers.
Finally, SLM includes measuring and reporting on how all service achievements compare to the agreed targets. The frequency, measurement method, and depth of reporting required is agreed as part of the SLA negotiations.
It is important to understand the relationship between service level management and business relationship management. SLM deals with issues around the quality of service being provided; business relationship management’s role is more strategic. The business relationship manager (BRM) works closely with the business, understanding its current and future IT requirements. It is then the responsibility of the BRM to ensure that the service provider understands these needs and is able to meet them. SLM is concerned more about how to meet the targets by ensuring that agreements are in place with internal and external suppliers to provide elements of the service to the required standard.
Service level management cooperates with and complements business relationship management. Similarly, the improvement actions identified by SLM in a service improvement plan (SIP) are implemented in conjunction with continual service improvement; they are documented in the CSI register, where they are prioritized and reviewed.
Service Level Management Policies
The service provider should establish clear policies for the conduct of the service level management process. Policies typically define such things as the minimum required content of service level agreements and operational level agreements; when and how agreements are to be reviewed, renewed, revised, and/or renegotiated and how frequently; and what methods will be used to provide service level reporting.
Priority should be given to the policies that are between SLM and the supplier’s management because the performance of suppliers can be the critical element in the achievement of end-to-end service level commitments.
Service level management terminology is expressed from the point of view of the IT service provider, particularly as it relates to underpinning contracts and agreements. You should be familiar with this from your Foundation studies.
The term underpinning contract is used here to refer to any kind of agreement or contract between an IT service provider and a supplier that supports the delivery of service to the customer. The term service level agreement (SLA) is used to refer to an agreement between only the IT service provider and the customer(s).
Underpinning agreements is a more generic term used to refer to all OLAs and contracts or other agreements that underpin the customer SLAs.
Service Level Management Process Activities, Methods, and Techniques
We are not going to explore the process in detail, but you should make sure you are familiar with all the aspects of the process and the management requirements for each.
Figure 13.1 shows the full scope of the activities in the service level management process.

Figure 13.1 The service level management process
Copyright © AXELOS Limited 2010. All rights reserved. Material is reproduced under license from AXELOS.
The key activities within the SLM process should include the following:
- Determining, negotiating, documenting, and agreeing on requirements for new or changed services in SLRs, and managing and reviewing them through the service lifecycle to create SLAs for operational services
- Monitoring and measuring service performance achievements of all operational services against targets within SLAs
- Producing service reports
- Conducting service reviews and identifying improvement opportunities
- Collating, measuring, and improving customer satisfaction
- Reviewing and revising SLAs, service scope, and OLAs and contracts
- Providing appropriate management information
- Logging and managing complaints and compliments
These other activities within the SLM process support the successful execution of the key activities:
- Designing SLA frameworks
- Developing, maintaining, and operating SLM procedures, including procedures for logging, actioning, and resolving all complaints and for logging and distributing compliments
- Making available and maintaining up-to-date SLM document templates and standards, including assisting with the service catalog
Service Level Management Triggers, Inputs, and Outputs
Let’s consider the triggers, inputs, and outputs for the service level management process. SLM is a process that has many active connections throughout the organization and its processes. It is important that the triggers, inputs, outputs, and interfaces be clearly defined to avoid duplicated effort or gaps in workflow.
Triggers
The following triggers are among the many that instigate SLM activity:
- Changes in the service portfolio, such as new or changed business requirements or new or changed services
- New or changed agreements, service level requirements, service level agreements, operational level agreements, and contracts
- Service review meetings and actions
- Service breaches or threatened breaches
- Compliments and complaints
- Periodic activities such as reviewing, reporting, and customer satisfaction surveys
- Changes in strategy or policy
Inputs
A number of sources of information are relevant to the service level management process:
- Business information from the organization’s business strategy, plans and financial plans, and information on its current and future requirements
- Business impact analysis providing information on the impact, priority, risk, and number of users associated with each service
- Details of agreed, new, or changed business requirements
- The strategies, policies, and constraints from service strategy
- The service portfolio and service catalog
- Change information (including RFCs) from the change management process, with a change schedule and an assessment of all changes for their impact on all services
- Configuration management system containing information on the relationships between the business services, the supporting services, and the technology
- Customer and user feedback, including complaints and compliments
- Improvement opportunities from the CSI register
Other inputs are advice, information, and input from any of the other processes (e.g., incident management, capacity management, and availability management) together with the existing SLAs, SLRs, OLAs, and past service reports on the quality of service delivered.
Outputs
The outputs of SLM are as follows:
- Service reports that provide details of the service levels achieved in relation to the targets contained within SLAs
- Service improvement opportunities for inclusion in the CSI register and for later review and prioritization in conjunction with the CSI manager
- Service improvement plans that provide an overall program or plan of prioritized improvement actions, encompassing appropriate services and processes together with associated impacts and risks
- The service quality plan, which should document and plan the overall improvement of service quality
- Document templates for service level requirements capture, service level agreements, operational level agreements, and contracts
- Reports on OLAs and underpinning contracts
- Service review meeting minutes and actions
- SLA review and service scope review meeting minutes
- Updated change information, including updates to RFCs
- Revised requirements for underpinning contracts
Service Level Management Interfaces
SLM interfaces with several other processes to ensure that agreed service levels are being met:
- Problem management will address the causes of any failures that impact targets and work to prevent their recurrence, thus improving the delivery of the service against targets.
- Availability management works to remove any single points of failure that could lead to downtime and addresses the causes of such downtime in order to deliver the agreed level of availability to the customer.
- Capacity management plans ahead to ensure that sufficient capacity is provided and therefore prevent service failures that would otherwise have occurred.
- Incident management focuses on resolving incidents and restoring service as quickly as possible. Performance against targets for incident resolution by identifying agreed priorities is usually a major area within an SLA.
- IT service continuity will plan to ensure that service continues to be provided despite major upheavals; where a break in service cannot be prevented, it will work to ensure that the service is restored in line with the business requirements.
- Information security ensures that the customer’s data is protected and will work with the service level manager to educate the customers and users regarding their own responsibilities in this area.
- Supplier management ensures that UCs are in place and are being fulfilled.
- Service catalog management provides information about services to support the SLA.
- Financial management provides cost information.
- Design coordination ensures that the design meets the SLR.
- SLM works with CSI in designing and implementing the SIP.
- SLM works with business relationship management. Business relationship management is more concerned with strategy, identifying customer needs, and ensuring that the objectives are met.
Information Management and Service Level Management
Service level management is a process that provides key information on operational services, their expected targets, and their service achievements and breaches. This means it is an important part of information management across the lifecycle. It assists service catalog management with the management of the service catalog and also provides the information and trends on customer satisfaction, including complaints and compliments.
The service provider organization is reliant on the information that service level management provides on the quality of IT service provided to the customer. This includes information on the customer’s expectation and perception of that quality of service. This information should be widely available to all areas of the service provider organization.
Measures, Metrics, and Critical Success Factors for Service Level Management
Key performance indicators and metrics can be used to judge the efficiency and effectiveness of service level management activities and the progress of the service improvement plan.
These metrics should be developed from the service, customer, and business perspective and should be both subjective (qualitative) and objective (quantitative), such as the following examples.
Objective measures include the following:
- The number or percentage of service targets being met
- The number and severity of service breaches
- The number of services with up-to-date SLAs
- The number of services with timely reports and active service reviews
A subjective measure would be an improvement in customer satisfaction.
The following list includes some sample critical success factors and key performance indicators for SLM:
- Critical success factor: “Managing the overall quality of IT services required both in the number and level of services provided and managed.”
- KPI: Reduction (measured as a percentage) in SLA targets threatened
- KPI: Increase (measured as a percentage) in customer perception and satisfaction of SLA achievements via service reviews and customer satisfaction survey responses
- Critical success factor: “Deliver the service as previously agreed at affordable costs.”
- KPI: Total number and percentage increase in fully documented SLAs in place
- KPI: Reduction (measured as a percentage) in the costs associated with service provision
- KPI: Frequency of service review meetings
- Critical success factor: “Manage the interface with the business and users.”
- KPI: Increased percentage of services covered by SLAs
- KPI: Documented and agreed SLM processes and procedures in place
- KPI: Documentary evidence that issues raised at service and SLA reviews are being followed up and resolved
- KPI: Reduction in the number and severity of SLA breaches
- KPI: Effective review and follow-up of all SLA, OLA, and underpinning contract breaches
Challenges for Service Level Management
There are numerous challenges faced when introducing service level management because it requires alignment and engagement across the whole organization.
One challenge faced by service level management is that of identifying suitable customer representatives with whom to negotiate. Who “owns” the service on the customer side?
Another challenge may arise if there has been no previous experience of service level management. In these cases, it is advisable to start with a draft service level agreement.
One difficulty sometimes encountered is that staff at different levels within the customer community may have different objectives and perceptions.
Risks for Service Level Management
Some of the risks associated with service level management are as follows:
- A lack of accurate input, involvement, and commitment from the business and customers
- Lack of appropriate tools and required resources
- The process becoming a bureaucratic, administrative process
- Access to and support of appropriate and up-to-date CMS and SKMS
- Bypassing the use of the service level management processes
- High customer expectations and low perception
Availability Management
The availability of a service is critical to its value. No matter how clever it is or what functionality it offers (its utility), the service is of no value to the customer unless it delivers the warranty expected. Poor availability is a primary cause of customer dissatisfaction. Availability is one of the four warranty aspects that must be delivered if the service is to be fit for use. Targets for availability are often included in service level agreements, so the IT service provider must understand the factors to be considered when seeking to meet or exceed the availability target. The following sections cover how availability is measured; the purpose, objectives, and scope of availability management; and a number of key concepts.
Defining Availability
ITIL defines availability as the ability of an IT service or other configuration item to perform its agreed function when required. Any unplanned interruption to a service during its agreed service hours (also called the agreed service time, specified in the service level agreement) is defined as downtime. The availability measure is calculated by subtracting the downtime from the agreed service time and converting it to a percentage of the agreed service time.
It is important to note the inclusion of when required in the definition and the word agreed in the calculation. The service may be available when the customer does not require it; including time when the customer does not need the service in the calculation gives a false impression of the availability from the customer perspective. If customer perception does not match the reporting provided, the customer will become cynical and distrust the reports.
Keep in mind that the customer experiences the end-to-end service; the availability delivered depends on all links in the chain being operational when required. The customer will complain that a service is unavailable whether the fault is with the application, the network, or the hardware. The availability management process is therefore concerned with reducing service affecting downtime wherever it occurs. Again, it should be clearly stated in the availability reports whether the calculations are based on the end-to-end service or just the application availability. It is therefore essential to understand the difference between service availability and component availability.
Purpose of Availability Management
The purpose of the availability management process is to take the necessary steps to deliver the availability requirements defined in the SLA. The process should consider both the current requirements and the future needs of the business. All actions taken to improve availability have an accompanying cost, so all improvements made must be assessed for cost-effectiveness.
Availability management considers all aspects of IT service provision to identify possible improvements to availability. Some improvements will be dependent on implementing new technology; others will result from more effective use of staff resources or streamlined processes. Availability management analyzes reasons for downtime and assesses the return on investment for improvements to ensure that the most cost-effective measures are taken. The process ensures that the delivery of the agreed availability is prioritized across all phases of the lifecycle.
Objectives of Availability Management
The objectives of availability management are as follows:
- Producing and maintaining a plan that details how the current and future availability requirements are to be met. This plan should consider requirements 12 to 24 months in advance to ensure that any necessary expenditure is agreed on in the annual budget negotiations and any new equipment is bought and installed before the availability is affected. The plan should be revised regularly to take into account any changes in the business.
- Providing advice throughout the service lifecycle on all availability-related issues to both the business and IT, ensuring that the impact of any decisions on availability is considered.
- Managing the delivery of services to meet the agreed targets. Where downtime has occurred, availability management will assist in resolving the incident by utilizing incident management and, when appropriate, resolving the underlying problem by utilizing the problem management process.
- Assessing all requests for change to ensure that any potential risk to availability has been considered. Any updates to the availability plan required as a result of changes will also be considered and implemented.
- Considering all possible proactive steps that could be taken to improve availability across the end-to-end service, assessing the risk and potential benefits of these improvements, and implementing them where justified.
- Implementing monitoring of availability to ensure that targets are being achieved.
- Optimizing all areas of IT service provision to deliver the required availability consistently to enable the business to use the services provided to achieve its objectives.
Scope of Availability Management
As discussed, the availability management process encompasses all phases of the service lifecycle. It is included in the design phase because the most effective way to deliver availability is to ensure that availability considerations are designed in from the start. Once the service is operational, opportunities are continually sought to remove risks to availability and make the service more robust. The activities for these opportunities are part of proactive availability management. Throughout the live delivery of the service, availability management analyzes any downtime and implements measures to reduce the frequency and length of future occurrences. These are the reactive activities of availability management. Changes to live services are assessed to understand risks to the service, and measurements are put in place to ensure that downtime is measured accurately. This continues throughout the operational phase until the service is retired.
The scope of availability management includes all operational services and technology. Where SLAs are in place, there will be clear, agreed targets. There may be other services, however, where no formal SLA exists but where downtime has a significant business impact. Availability management should not exclude these services from consideration; it should strive to achieve high availability in line with the potential impact of downtime on the business. Service level management should work to negotiate SLAs for all such services in the future because without them, it is the IT service provider who is assessing the level of availability required, but this should be a business decision. Availability management should be applied to all new IT services and for existing services where SLRs or SLAs have been established. Supporting services must be included because the failures of these services impact the customer-facing services. Availability management may also work with supplier management to ensure that the level of service provided by partners does not threaten the overall service availability.
Every aspect of service provision comes within the scope of availability management; poor processes, untrained staff, and ineffective tools can all contribute to causing or unnecessarily prolonging downtime.
The availability management process ensures that the availability of systems and services matches the evolving agreed needs of the business.
The role of IT within businesses is now critical. The availability and reliability of IT services can directly influence customer satisfaction and the reputation of the business. Availability management is essential in ensuring that IT delivers the levels of service availability required by the business to satisfy its business objectives and deliver the quality of service demanded by its customers.
Customer satisfaction is an important factor for all businesses and may provide a competitive edge for the organization. Dissatisfaction with the availability and reliability of IT service can be a key factor in customers taking their business to a competitor.
Availability can also improve the ability of the business to follow an environmentally responsible strategy by using green technologies and techniques in availability management.
Availability Management Policies
The policies of availability management should state that the process is included as part of all lifecycle stages, from service strategy through to continual service improvement. The appropriate availability and resilience should be designed into services and components from the initial design stages. This will ensure not only that the availability of any new or changed service meets the expected targets, but also that all existing services and components continue to meet all of their targets.
Availability policies should be established by the service provider to ensure that availability is considered throughout the lifecycle. Policies should also be established regarding the criteria to be used to define availability and unavailability of a service or component and how each will be measured.
Availability management is completed at two interconnected levels:
- Service availability involves all aspects of service availability and unavailability. This includes the impact of component availability and the potential impact of component unavailability on service.
- Component availability involves all aspects of component availability and unavailability.
Availability Management Principles and Basic Concepts
Availability management must align its activities and priorities to the requirements of the business. This requires a firm understanding of the business processes and how they are underpinned by the IT service. Information regarding the future business plans and priorities and therefore the future requirements of the business with regard to availability is essential input to the availability plan. Only with this understanding of the business requirement can the service provider be sure that its efforts to improve availability are correctly targeted.
The response of the IT service provider to failure can improve the customer’s perception of the service, despite the break in service. The service provider’s actions can show an understanding of the impact of the downtime on the business processes, and an eagerness to overcome the issue and prevent recurrences can reassure the business that IT understands its needs.
Additionally, the process requires a strong technical understanding of the individual components that make up each service, their capabilities, and their current performance. Through this combination of business understanding and technical knowledge, the optimal design can be delivered to produce the required level of availability to meet current and future needs.
When designing a new service and discussing its availability requirements, the service provider and the business must focus on the criticality of the service to the business being able to achieve its aims. Expenditure to provide high availability across every aspect of a service is unlikely to be justified. The business process that the IT service supports may be a vital business function (VBF), and identifying which services or parts of services are the most critical is therefore a business decision. For example, the ability for an Internet-based bookshop to be able to process credit card payments would be a vital business function. The ability to display a “customers who bought this book also bought these other books” feature is not vital. It may encourage some increased sales, but the purchaser is able to complete their purchase without it. Once these VBFs are understood, the design of the service to ensure the required availability can commence. Understanding the VBFs informs decisions regarding where expenditure to protect availability is justified.
Determining what the appropriate availability target of a service should be is a business decision, not an IT decision. However, availability comes at a price, and the service provider must ensure that the customer understands the cost implications of too high a target. Customers may otherwise demand a very high availability target (99.99% or greater) and then find the service unaffordable.
Where the cost of very high availability is justified, the design of the service will include highly reliable components, resilience, and minimal or no planned downtime.
Having considered the importance of availability to the business, in the following sections we examine some of the key availability management activities and concepts that the IT service provider may employ to cut downtime and thus deliver the required availability to the business, enabling it to achieve its business objectives.
Availability Concepts
Availability management comprises both reactive and proactive activities, as shown in Figure 13.2. The reactive activities include regular monitoring of service provisions involving extensive data gathering and reporting of the performance of individual components and processes and the availability delivered by them. Event management is often used to monitor components because this speeds up the identification of any issues through the setting of alert thresholds. It may even be possible to restart the failing service automatically, possibly before the break has been noticed by the customers. Instances of downtime are investigated, and remedial actions are taken to prevent a recurrence. The proactive activities include identifying and managing risks to the availability of the service and implementing measures to protect against such an occurrence. Where protective measures have been put in place to provide resilience in the event of component failure, the measures require regular testing to ensure that they actually work as designed to protect the service availability. All new or changed services should be subject to continual service improvement; countermeasures should be implemented wherever they can be cost justified. This cost justification requires an understanding of the vital business functions and the cost to the business of any downtime. It is ultimately a business decision, not a technical decision. Figure 13.2 also shows the availability management information system (AMIS); this is the repository for all availability management reports, plans, risk registers, and so on, and it forms part of the service knowledge management system (SKMS).

Figure 13.2 The availability management process
Copyright © AXELOS Limited 2010. All rights reserved. Material is reproduced under license from AXELOS.
Reliability
The first availability concept we cover is reliability. This is defined by ITIL as “a measure of how long a service, component, or CI can perform its agreed function without interruption.” We normally describe how reliable an item is by stating how frequently it can be expected to break down within a given time: “My car is very reliable. It has broken down only twice in five years.” We measure reliability by calculating the mean (or average) time between failures (MTBF) or the mean (or average) time between service incidents (MTBSI).
Reliability of a service can be improved first by ensuring that the components specified in the design are of good quality and from a supplier with a good reputation. Even the best components will fail eventually; however, the reliability of the service can be improved by designing the service so that a component failure does not result in downtime. This is another availability concept called resilience. By ensuring that the design includes alternate network routes, for example, a network component failure will not lead to service downtime because the traffic will reroute. Carrying out planned maintenance to ensure that all the components are kept in good working order will also help improve reliability.
Maintainability
However reliable the equipment and resilient the design, not all downtime can be prevented. When a fault occurs and there is insufficient resilience in the design to prevent it from affecting the service, the length of the downtime that results can be affected by how quickly the fault can be overcome. This is called maintainability and is measured as the mean time to restore service (MTRS). It may be more cost-effective to concentrate resilience measures for those items that have a long service restoration time. To calculate MTRS, divide the total downtime by the total number of failures.
Simple measures can be taken to reduce MTRS, such as having common spares available on site, and these measures can have a significant impact on availability.
ITIL recommends the use of MTRS rather than mean time to repair (MTTR) because repair may or may not include the restoration of the service following the repair. From the customer perspective, downtime includes all the time between the fault occurring and the service being fully usable again. MTRS measures this complete time and is therefore a more meaningful measurement.
These concepts are illustrated in Figure 13.3, which shows what ITIL calls the expanded incident lifecycle. This shows periods of uptime with incidents causing periods of downtime. MTRS is shown as the average of the downtime for the incident. MTBF is shown as the average of the uptime for the incident.
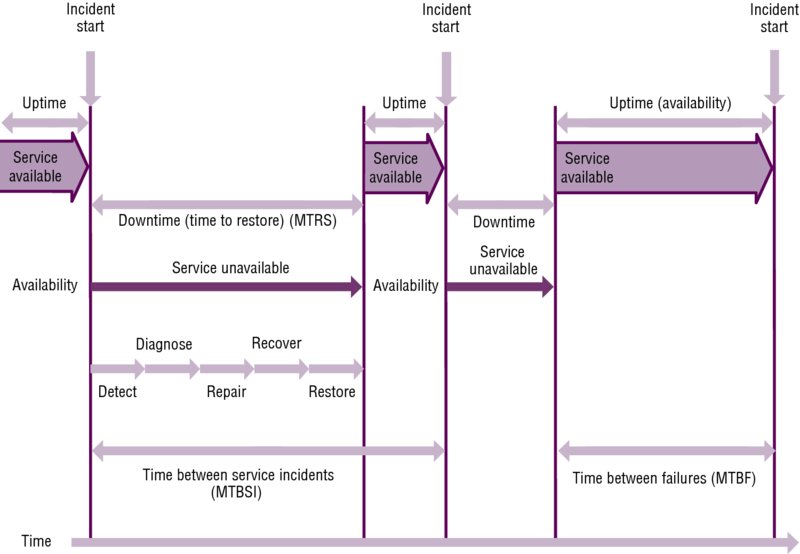
Figure 13.3 The expanded incident lifecycle
Copyright © AXELOS Limited 2010. All rights reserved. Material is reproduced under license from AXELOS.
Each incident needs to be detected, diagnosed, and repaired, and the data needs to be recovered and the service restored. Any method of shortening any of these steps—speeding up detection through event management or speeding up diagnosis by the use of a knowledge base, for example—will shorten the downtime and improve availability. The figure also shows another concept, that of MTBSI; this calculates the average time from the start of one incident to the start of the next.
Serviceability
Serviceability is defined as the ability of a third-party supplier to meet the terms of its contract. This contract will include agreed levels of availability, reliability, and/or maintainability for a supporting service or component.
In Figure 13.4, you can see the terms and measures used in availability management, which are combined when applied to suppliers providing serviceability.

Figure 13.4 Availability terms and measures
Copyright © AXELOS Limited 2010. All rights reserved. Material is reproduced under license from AXELOS.
Measurement of Availability
The term vital business function (VBF) is used to reflect the part of a business process that is critical to the success of the business. The more vital the business function generally, the greater the level of resilience and availability that needs to be incorporated into the design of the supporting IT services. The availability requirements for all services, vital or not, should be determined by the business and not by IT.
Certain vital business functions may need special designs; these commonly include the following functions:
High Availability This is a characteristic of the IT service that minimizes or masks the effects of IT component failure to the users of a service.
Fault Tolerance This is the ability of an IT service, component, or configuration item to continue to operate correctly after failure of a component part.
Continuous Operation This is an approach or design to eliminate planned downtime of an IT service. Individual components or configuration items may be down even though the IT service remains available.
Continuous Availability This is an approach or design to achieve 100 percent availability. A continuously available IT service has no planned or unplanned downtime.
Within the IT industry, many suppliers commit to high availability or continuous availability solutions, but only if specific environmental standards and resilient processes are used. They often agree to such contracts only after additional, sometimes costly, improvements have been made.
The availability management process depends heavily on the measurement of service and component achievements with regard to availability.
The decision on what to measure and how to report it depends on which activity is being supported, who the recipients are, and how the information is to be utilized. It is important to recognize the differing perspectives of availability from the business, users, and service providers to ensure that measurement and reporting satisfies these varied needs.
The business perspective considers IT service availability in terms of its contribution or impact on the vital business functions that drive the business operation.
The user perspective considers IT service availability as a combination of three factors. These are the frequency, the duration, and the scope of impact. For many applications, poor response times for the user are considered at the same level as failures of technology.
The IT service provider perspective considers IT service and component availability with regard to availability, reliability, and maintainability.
It is important to consider the full scope of measures needed to report the same level of availability in different ways to satisfy the differing perspectives of availability. Measurements need to be meaningful and add value. This is influenced strongly by the combination of “what you measure” and “how you report it.”
Availability Management Process, Methods, and Techniques
We have explored the concepts and measures used in the availability management process. The diagram in Figure 13.5 shows the key elements of the process, including the availability management information system.

Figure 13.5 The availability management process
Copyright © AXELOS Limited 2010. All rights reserved. Material is reproduced under license from AXELOS.
There are a number of different techniques that can be used for availability management. These are explored more fully in the capability course material, but the following provides a brief overview of each technique.
Expanded Incident Lifecycle
This technique requires the analysis of the lifecycle of an incident from start to finish and to the next outage. Throughout this analysis, the perspective of the support environment will be considered in terms of how to improve the management of an incident. Consideration of the expanded incident lifecycle provides valuable insight into the management of availability from an operational perspective, as described earlier as part of the exploration of the concepts of availability.
Fault Tree Analysis
This approach uses Boolean logic, the AND and OR statements, to analyze the sequence of events that lead to a failure. This helps in understanding single points of failure.
Component Failure Impact Analysis
As it sounds, this is a technique that considers the importance of an individual component to the provision of service. Combined with other techniques, this approach can provide useful information for the design of future services.
Service Failure Analysis
This technique is used as a proactive approach to the analysis of an interruption. Each time an interruption takes place, full analysis is undertaken to try to identify a preventative action.
Risk Analysis and Management
This provides an analysis of the likelihood of business impact relating to availability risks (the likelihood of something happening). Business impact analysis and the identification of the potential impact of the business is a vital part of risk management. Identification of mitigation against risk is a key part of the design of services.
Availability Management Triggers, Inputs, and Outputs
We will now review the triggers, inputs, and outputs of availability management.
Triggers
Many events may trigger availability management activity, including the following events:
- New or changed business needs or new or changed services
- New or changed targets within agreements, such as service level requirements, service level agreements, operational level agreements, and contracts
- Service or component breaches, availability events, and alerts, including threshold events and exception reports
- Periodic activities such as reviewing, revising, or reporting against services
- Review of availability management forecasts, reports, and plans
- Review and revision of business and IT plans and strategies
- Review and revision of designs and strategies
- Recognition or notification of a change of risk or impact of a business process, a vital business function, an IT service, or a component
- Request from service level management for assistance with availability targets and explanation of achievements
Inputs
A number of sources of information are relevant as inputs to the availability management process. Some of these are as follows:
- Business information from the organization’s business strategy, plans, and financial plans and information on its current and future requirements, including the availability requirements for new or enhanced IT services
- Service information from the service level management process, with details of the services from the service portfolio and the service catalog; from service level targets within service level agreements and service level requirements; and possibly from the monitoring of SLAs, service reviews, and breaches of the SLAs
- Financial information from financial management for IT services, the cost of service provision, and the cost of resources and components
- Change and release information from the change management process with a change schedule, the release schedule from release and deployment management, and an assessment of all changes for their impact on service availability
- Service asset and configuration management containing information on the relationships between the business, the services, the supporting services, and the technology
- Component information on the availability, reliability, and maintainability requirements for the technology components that underpin IT service(s)
- Technology information from the configuration management system
- Past performance from previous measurements, achievements, reports, and the availability management information system (AMIS)
- Unavailability and failure information from incidents and problems
Outputs
Availability management produces the following outputs:
- The availability management information system (AMIS)
- The availability plan for the proactive improvement of IT services and technology
- Availability and recovery design criteria and proposed service targets for new or changed services
- Service availability, reliability, and maintainability reports of achievements against targets, including input for all service reports
- Component availability, reliability, and maintainability reports of achievements against targets
- Revised risk assessment reviews and reports and an updated risk register
- Monitoring, management, and reporting requirements for IT services and components
- An availability management test schedule for testing all availability, resilience, and recovery mechanisms
- The planned and preventive maintenance schedules
- Contributions for the projected service outage (PSO) document to be created by change management in collaboration with release and deployment management
- Details of the proactive availability techniques and measures that will be deployed
- Improvement actions for inclusion within the service improvement plan
Availability Management Interfaces
As you would expect for this process, there are a number of interfaces across the lifecycle. In fact, availability management can be linked to the majority of the service management processes. However, the key interfaces that availability management has with other processes are as follows:
Service Level Management This process relies on availability management to determine and validate availability targets and to investigate and resolve service and component breaches. It links to both the reactive and proactive elements of availability management.
Incident and Problem Management As you have seen from the techniques used in availability measurement and management, these processes are assisted by availability management in the resolution of incidents and problems.
Capacity Management This provides appropriate capacity to support resilience and overall service availability. There are strong connections between the availability of a service and the capacity of the service. Patterns of business activity and user profiles are used to understand business demand for IT for business-aligned availability planning.
Change Management As a result of investigations into outages, or improvements required by the business, change management supports the management of changes. This in turn is used in the creation of the PSO document to project the availability-related issues during a change, with contributions from availability management.
IT Service Continuity Management Availability management works collaboratively with this process on the assessment of business impact and risk and the provision of resilience, fail-over, and recovery mechanisms. A continuity invocation is the result of an availability management issue that cannot be resolved within the agreed time frames without additional resources as described in the recovery plan.
Information Security Management Put simply, if the data becomes unavailable, the service becomes unavailable. Information security management defines the security measures and policies that must be included in the service design for availability and the design for recovery.
Access Management Availability management provides the methods for appropriately granting and revoking access to services as needed. This should be carefully monitored because unauthorized or uncontrolled access can be a significant risk to service availability.
Information Management and Availability Management
The process talks about and stresses the importance of an availability management information system. Although this is shown in the process diagram (Figure 13.2) as a single database or repository, it is unlikely to be the case in the real world. It is far more likely that the information relating to availability is captured and resides in a number of different tools and systems.
The challenge, for an availability manager, is to make sense of these disparate sources and create a unified information source that enables the production of the availability plan.
There are many tools in the marketplace that make claims about being able to manage availability across an enterprise, but it would be surprising if the unique requirements of a customer were met by a generic toolset.
Customization, adaptation, and configuration to meet the customer requirements will always be required, and the information obtained must be managed so that it is fit for use and purpose. This information, covering services, components, and supporting services, provides the basis for regular, ad hoc, and exception availability reporting and the identification of trends within the data for the instigation of improvement activities.
The availability plan should have aims, objectives, and deliverables and should consider the wider issues of people, processes, tools, and techniques as well as have a technology focus. As the availability management process matures, the plan should evolve to cover the following:
- Actual levels of availability versus agreed levels of availability for key IT services. Availability measurements should always be business and customer focused and report availability as experienced by the business and users.
- Activities being progressed to address shortfalls in availability for existing IT services. Where investment decisions are required, options with associated costs and benefits should be included.
- Details of changing availability requirements for existing IT services. The plan should document the options available to meet these changed requirements. Where investment decisions are required, the associated costs of each option should be included.
- Details of the availability requirements for forthcoming new IT services. The plan should document the options available to meet these new requirements. Where investment decisions are required, the associated costs of each option should be included.
- A forward-looking schedule for the planned SFA assignments.
- Regular reviews of SFA assignments. These reviews should be completed to ensure that the availability of technology is being proactively improved in conjunction with the SIP.
- A technology futures section to provide an indication of the potential benefits and exploitation opportunities that exist for planned technology upgrades. Anticipated availability benefits should be detailed, where possible based on business-focused measures, in conjunction with capacity management. The effort required to realize these benefits where possible should also be quantified.
Covering a period of six months to a year, this plan is often produced as a rolling plan, continually updated to meet the changing needs of the business. At a minimum, it is recommended that publication is aligned with the capacity and business budgeting cycle and that the availability plan is considered complementary to the capacity plan and financial plan. Frequency of updates will depend on the nature of the organization and the rate of technological or business change.
The availability management information system can be utilized to record and store selected data and information required to support key activities such as report generation, statistical analysis, and availability forecasting and planning. It should be the main repository for the recording of IT availability metrics, measurements, targets, and documents, including the availability plan, availability measurements, achievement reports, SFA assignment reports, design criteria, action plans, and testing schedules.
Availability Management Critical Success Factors and Key Performance Indicators
This section includes some sample critical success factors for availability management. There are many more, and they can be obtained from the ITIL Service Design publication, or from your own experience within your organization.
- Critical success factor: “Manage availability and reliability of IT service.”
- KPI: Reduction (measured as a percentage) in the unavailability of services and components
- KPI: Increase (measured as a percentage) in the reliability of services and components
- KPI: Effective review and follow-up of all SLA, OLA, and underpinning contract breaches relating to availability and reliability
- Critical success factor: “Satisfy business needs for access to IT services.”
- KPI: Reduction (measured as a percentage) in the unavailability of services
- KPI: Reduction (measured as a percentage) of the cost of business overtime due to unavailable IT
- Critical success factor: “Availability of IT infrastructure and applications, as documented in SLAs, provided at optimum costs.”
- KPI: Reduction (measured as a percentage) in the cost of unavailability
- KPI: Improvement (measured as a percentage) in the service delivery costs
Availability Management Challenges and Risks
We’ll begin with looking at the key challenges for the process.
Challenges
The main challenge is to meet and manage the expectations of the customers and the business. The service levels should be publicized to all customers and areas of the business so that when services do fail, the expectation for their recovery is at the right level. It also means that availability management must have access to the right level of quality information on the current business need for IT services and its plans for the future.
Another challenge facing availability management is the integration of all of the availability data into an integrated set of information (AMIS). This can be analyzed in a consistent manner to provide details on the availability of all services and components. This is particularly challenging when the information from the different technologies is provided by different tools in different formats, which often happens.
Yet another challenge facing availability management is the investment needed in proactive availability measures. Availability management should work closely with ITSCM, information security management, and capacity management in producing the justifications necessary to secure the appropriate investment.
Risks
The following major risks are among those associated with availability management:
- A lack of commitment from the business to the availability management process
- A lack of appropriate information on future plans and strategies from the business
- A lack of senior management commitment to or a lack of resources and/or budget for the availability management process
- Labor-intensive reporting processes
- The processes focus too much on the technology and not enough on the services and the needs of the business.
- The availability management information system is maintained in isolation and is not shared or consistent with other process areas, especially ITSCM, information security management, and capacity management. This interaction is particularly important when considering the necessary service and component backup and recovery tools, technology, and processes to meet the agreed needs.
Summary
This chapter explored the next two processes in the service design stage, service level management and availability management. It covered the purpose, objectives, and scope for both processes.
We also looked at the value of each processes and reviewed their policies, activities, methods, and techniques.
We reviewed triggers, inputs, outputs, and interfaces for the processes and the information management associated with them. We also considered the critical success factors and key performance indicators, the challenges, and the risks for each process.
We examined how each of these processes supports the other and the importance of these processes to the business and to the IT service provider.
Exam Essentials
Understand the purpose and objectives of service level management and availability management. It is important for you to be able to explain the purpose and objectives of the service level management and availability management processes. Service level management should ensure that the services are delivered to the customer’s satisfaction and in line with their requirements. Availability management should ensure that the required availability is delivered to meet the targets in the service level agreement.
Understand the scope of service level management. SLM does not include agreeing on the utility aspects. The negotiation and agreement of requirements for service functionality (utility) are not part of the process, except to the degree that the functionality influences a service level requirement or target.
Explain the different categories of service providers. Providers fall into three categories; they can be embedded in a business unit (Type I), shared across business units (Type II), or external to the organization (Type III). Type III service providers will have an SLA with their external customers that will be a legal contract because they are separate organizations.
Understand the critical success factors and key performance indicators for the processes. Measurement of the processes is an important part of understanding their success. You should be familiar with the CSFs and KPIs for both service level management and availability management.
Understand the definition of availability. ITIL defines availability as the ability of an IT service or other configuration item to perform its agreed function when required. Any unplanned interruption to a service during its agreed service hours (also called the agreed service time, specified in the service level agreement) is defined as downtime. The availability measure is calculated by subtracting the downtime from the agreed service time and converting it to a percentage of the agreed service time.
Explain the different concepts of availability management. You need to be able to differentiate between reliability, maintainability, and serviceability. Reliability is defined by ITIL as “a measure of how long a service, component, or CI can perform its agreed function without interruption.” Maintainability is measured as the mean time to restore service (MTRS). Serviceability is defined as the ability of a third-party supplier to meet the terms of its contract. This contract will include agreed levels of availability, reliability, and/or maintainability for a supporting service or component.
Understand and differentiate between the methods and techniques of availability management. There are a number of different techniques that can be used for availability management. Ensure that you are familiar with each of them and can explain the purpose of each.
Explain the role of information management in availability management. Information is key to the service lifecycle, so you need to understand the content of the availability management information system and its use throughout the lifecycle.
You can find the answers to the review questions in the appendix. Which of these statements provides the best description of the purpose of service level management? Which of these is an objective of service level management? Availability is calculated using the formula AST-DT/AST × 100. What do the abbreviations AST and DT refer to? Which of the following concepts are key to availability management? Service level requirements are related to which of the following? Which of the following would NOT be part of a service level agreement? Which of the following agreements commonly supports the achievement of a service level agreement? Which of the following is the best description of an underpinning contract? Availability management considers VBFs. What does VBF stand for? Which of the following is a common color scheme that’s applied to a service level management monitoring chart?Review Questions