


Full text search
In this chapter, we describe the full text search (FTS) feature of IBM Content Manager OnDemand (Content Manager OnDemand), which enables users to build an index of the document content and to search within this full text.
In this chapter, we cover the following topics:
15.1 Introduction to full text search in Content Manager OnDemand
Content Manager OnDemand users primarily search on the metadata that is associated with documents. Using FTS, you can intelligently search through actual document content. To enable FTS, the documents are parsed and an index is built and queried by a full text engine.
The FTS feature in Content Manager OnDemand comes with a new server, the Full Text Search Server (FTS Server), which handles the text extraction, indexing, and searching of data. This allows the processing of full text data to be offloaded to a machine other than your Content Manager OnDemand library and object servers.
The full text engine is the same search services engine that is used by other IBM products, such as DB2 or FileNet P8. It is based on the Lucene engine and allows for advanced and flexible queries. Users can do wildcard searches, fuzzy (or similar) searches, proximity searches, Boolean searches, and other
complex queries.
complex queries.
The full text feature can handle many formats, including Microsoft Office documents, XML files, and typical Content Manager OnDemand formats, such as AFP, line data, and PDF.
The FTS feature supports full text indexing of both legacy and new data. Although configuring FTS for automatic full text indexing can be done through the Administrator Client, indexing legacy data must be done through the Content Manager OnDemand command-line utilities or the Content Manager OnDemand Web Enablement Kit (ODWEK) Java API.
FTS is enabled through the Content Manager OnDemand folder and allows all clients to take advantage of full text queries after the server configuration is complete. Several new Content Manager OnDemand folder field types are defined in support of FTS. Search score, highlight, and summary are returned, aiding the user in determining whether the document is a good match.
|
Note: Before the release of the FTS option in Content Manager OnDemand, a document content based search was possible by using the server-based text search functionality. However, this functionality is limited to AFP, Line, SCS, and PDF documents. It does not use an index, but instead the server works through all documents ad hoc. This limits the functions’ capabilities to exact matches of a query string and might cause workload problems on the Content Manager OnDemand server. FTS eliminates these issues and limitations by introducing new components.
|
15.2 Full text search architecture in Content Manager OnDemand
The process of full text indexing can be lengthy in terms of time and processor consumption. Therefore, an integration architecture is required, which decouples the full text engine from the Content Manager OnDemand server and keeps the different workloads separate.
The components and their basic communication are shown in Figure 15-1.
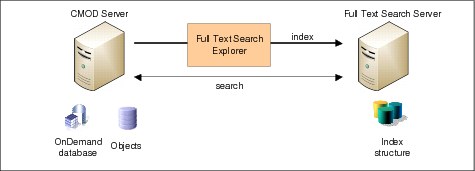
Figure 15-1 Full text search components and communication
15.2.1 Full Text Search Server
The Full Text Search Server (FTS Server) provides a full document processing pipeline that includes text extraction from binary formats, a wide range of encoding support, and language processing in various languages. The flow of data during indexing depends on the configuration and environment. In a single server configuration, document contents and properties are sent from the repository through FTS Exporter to the FTS Server. It then runs preprocessing, including text extraction, language identification, tokenization, and language analysis on the documents. After preprocessing, the document content is stored in the index.
Although the FTS Server comes with text extractors for many varied document types, including Microsoft Office formats and XML, AFP and Line are not included. For these two data types, text extraction occurs within the FTS Exporter. Images do not contain text and are not supported in FTS.
15.2.2 Index structure
FTS Server creates a binary Lucene index that is stored on the FTS Server. The index is segmented by logical groupings called Collections. The segmentation model is similar to the data table segmentation done in Content Manager OnDemand. For each Application Group data table, which has data that is indexed in the FTS Server, one Collection is created on the FTS Server. This means FTS Collections maintain a one to one relationship with Content Manager OnDemand data tables. Collections are created with the following
naming convention:
naming convention:
InstanceName_TableName.
This naming convention allows the FTS index to scale horizontally. During a query operation, you can narrow the scope of documents that must be searched. If the user specifies a date range in addition to the FTS criteria, the Content Manager OnDemand segment tables are referenced to determine which Collections must be queried.
As the full text index contains the processed text of each indexed document, the index can become large. For more information about size calculation, see 15.3.6, “Index considerations” on page 415.
15.2.3 Indexing document through FTS Exporter
New documents that are full text indexed are retrieved from Content Manager OnDemand by the FTS Exporter component, which comes with the Content Manager OnDemand server, and are pushed into the full text engine of the FTS Server. The detailed process is shown in Figure 15-2.

Figure 15-2 The role of the FTS Exporter in full text indexing
With the introduction of FTS in Content Manager OnDemand, a new table (arsftiwork) is created in the Content Manager OnDemand database, which is used to hold full text indexing work items. Whenever a document must be indexed, a work item record is created in the arsftiwork table. This is done in the Content Manager OnDemand load process for new data in Application Groups with full text support or explicitly for existing data by using the command-line tools or the ODWEK Java API.
The FTS Exporter connects to the arsftiwork table and works through the records, retrieving the associated documents from Content Manager OnDemand and pushing them into the FTS Server for new documents. For documents that are removed from the full text index, the same process applies. The FTS Exporter handles all tasks that are related to adding, updating, and deleting documents to and from the full text index. The FTS Exporter application is a Java application that communicates with the Content Manager OnDemand server to retrieve the documents.
15.2.4 Searching
Search queries are handled by the Content Manager OnDemand server directly communicating with the FTS Server. When an FTS string is specified during a query in a Content Manager OnDemand folder, a query is issued to the FTS Server for all applicable collections that match the date range. If no date range is specified in the query, then all collections for the specified application group
are queried.
are queried.
15.3 Planning and installing FTS
The following section describes the main aspects of the FTS component installation and configuration.
15.3.1 Component overview
FTS in Content Manager OnDemand consists of the FTS Server, the Full Text Search Exporter (FTS Exporter), and a Content Manager OnDemand server that uses both components to provide FTS to the users.
Full Text Search Server
The FTS feature in Content Manager OnDemand is a separate component that must be downloaded and installed separately. It contains the FTS Server. For the FTS feature, you may require a separate license in addition to your Content Manager OnDemand license.
The FTS Server runs on Multiplatforms systems only. The FTS Server can and is typically installed on a different system than the Content Manager OnDemand server because of the difference in workload types and the amount of processing that is required for high performance and throughput. The ability of the FTS Server to run on a separate system allows it to be used with all Content Manager OnDemand servers that are supported (z/OS, System i, and Multiplatforms).
Full Text Search Exporter
The FTS Exporter is a Java application, which is available as a JAR file (ODFTIExporter.jar), that comes with the Content Manager OnDemand server installation (starting with Version 9.0). It can be found in the jars subdirectory.
The FTS Exporter relies on the following components:
•JDBC database drivers for your Content Manager OnDemand database (DB2, Oracle, or SQL server on Windows)
•A Java runtime environment. JRE (Java 1.6.0) or later can be used to run the ODFTIExporter.jar file.
The FTS Exporter communicates with the Content Manager OnDemand server to retrieve the documents that are sent to the FTS Server. It uses a JDBC connection to the Content Manager OnDemand database to read the
arsftiwork table.
arsftiwork table.
The FTS Exporter can be run from the Content Manager OnDemand server system or from any other TCP/IP connected system. The FTS Exporter does not require the existence of the Content Manager OnDemand database on the same system. The FTS Exporter obtains the instance configuration from the Content Manager OnDemand server.
For more information, see 15.4.2, “Configuration of the Full Text Search Exporter” on page 419.
|
Note: Make sure that you apply the latest Content Manager OnDemand fix pack to the Content Manager OnDemand server and the FTS Server component before using FTS. Specifically, the FTS Exporter tool changed between Content Manager OnDemand Version 9.0.0.0 and Version 9.0.0.1.
|
15.3.2 Installing FTS Server
The FTS Server is installed on a Multiplatforms system by running its setup program. Use the command-line parameter -i console for a console
mode setup.
mode setup.
The setup creates a set of directories under the FTS_Home (Installation target) directory. Most of these directories are not modified after the installation. Special attention must be taken regarding the following directories:
•bin: Contains all the executable files.
•config: Contains the configuration and the index structures.
•log: The log files of the FTS Server.
Ensure that the target location has sufficient free disk space for the log files (at least 100 MB). Otherwise, the text search server stops logging and returns an error code. For more information about capacity planning for the config directory and the index size, see 15.3.6, “Index considerations” on page 415.
15.3.3 Operating system resources
For better throughput results on the index on AIX, Linux, and Solaris servers, ensure that the operating system resource limits are set correctly.
The values of the fsize (maximum file size) and nofiles (maximum number of files that are allowed for a process) parameters must be set to unlimited (-1) or 65536 to ensure correct system operation. The FTS Server startup script checks these settings and tries to correct them for the session. They can be set permanently by modifying the /etc/security/limits or /etc/security/limits.conf files.
15.3.4 Workload
Processor consumption depends on the following items:
•The number of collections
•The number of documents per collection
•The number of concurrently indexed collections
•The required indexing throughput
•The query load
For more information, see the capacity planning topics in the introduction and planning guides for Multiplatforms and z/OS, which can be found in the information center found at:
A minimum of one processor, 2 GB of RAM, and 8 GB of swap space should be assigned to the FTS Server. For more information, see the Hardware and Software Requirements, found at:
15.3.5 Memory heap size
During indexing and searching, FTS Server consumes heap memory for storing the indexed documents, preprocessing and indexing queues, and indexing memory structures. To optimize the performance of FTS Server, it is important that the maximum heap memory size in the JVM, the queue size, and file size limits are configured correctly. You can configure the maximum heap size by using the configuration tool.
The maxHeapSize parameter sets the maximum heap size for the FTS Server. The default is 1.5 GB. This value must be a number between 1.5 GB and the amount of available memory.
When you set the maximum heap size to a value greater than 2 GB, file size limits for text, XML, and binary documents must be increased for new collections. For each 8.3 MB of heap memory over 2 GB, the values of the file size limits (60 MB by default) must be increased by 1 MB (up to 400 MB), as demonstrated by the following formula:
60 MB + (heap memory - 2 GB) / 8.3
For example, a 2 GB maximum heap size result in 60 MB as the maximum size of a file that can be processed.
15.3.6 Index considerations
The most significant sizing option for the FTS Server system is the hard disk requirements for the full text index. The FTS Server requires a fast disk subsystem, and as the textual representation of each indexed document is stored there, a considerable amount of disk space might be needed.
Index size calculation
Although the disk space usage depends on the text in each document, this usage is linear to the original size of the indexed data. Typically, the size of the index on the disk is 50 - 150% of the original text size.
For example, 100,000 documents of 20 KB each can require about (100,000 x 20 KB x 75%) = 1500 MB of disk space.
|
Tip: To determine the text size for AFP and Line data documents, extract a sample document and use the arsview server command to determine the
text size. |
The size of the index is not limited. However, when much data is added to or removed from a text index, the text index structure is merged to improve query performance. The time for completion depends on the size of the index. Together with absolute throughput, which depends on data type and index format, this results in practical limits on the total text index size. For query performance, the biggest impact is the number of matching results, not the size of the text index.
During the indexing process, the server requires additional disk space for temporary storage. The maximum required disk space is approximately four times the total size of the text of the documents that are indexed.
Index location
The full text index is stored within the installation directories of the FTS Server. The default directory is the following one:
<FTS_Home>/config/collections/<collection_name>/data/text
If you want to place the configuration and the index structures into a different file system path, use the configTool command-line utility in the FTS_Home/bin directory. You must perform this action right after the installation, that is, before you start the FTS Server and create any full text indexes using Content Manager OnDemand. After an index is created, the index structures cannot
be changed.
be changed.
The configuration and index location is stored in the defaultDataDirectory parameter. First, show the current value of the parameter by running the following command:
configTool.sh list -system -defaultDataDirectory
Then, you can change the value by running the following command:
configTool.sh set -system -defaultDataDirectory <new value>
On Windows platforms, configTool.sh is available as configTool.cmd.
After changing defaultDataDirectory, you must restart the FTS Server.
15.4 Configuring and operating full text search
The FTS Server can be operated by the startup and shutdown scripts in the FTS_Home/bin subdirectory. The FTS Server must be running to perform indexing and full text searches.
After the FTS Server is started, by default it listens on TCP port 8191. Content Manager OnDemand and the FTS Exporter must know this port to communicate with the FTS Server. The port can be changed by using the port parameter with the configTool. For more information about how to use this command, see “Index location” on page 416.
The following command-line tools are installed in the bin directory, and are used to manage the FTS Server:
•adminTool: Used to manage collections, set trace options, and
check statuses.
check statuses.
•configTool: Used to review and change most system and
collection parameters.
collection parameters.
•startup and shutdown scripts.
•stopwordTool: Used to add or modify the list of stop words (common words that are not indexed).
•synonymTool: Used to add or remove synonym dictionaries from the index.
•dumpIndex: Used to dump documents from the index.
15.4.1 Base configuration in Content Manager OnDemand
To enable FTS in Content Manager OnDemand, it must be enabled for each of your Content Manager OnDemand instances. In Windows, this is done in the Content Manager OnDemand Configurator by selecting the Enable Full Text Index and Search check box on the Server (Advanced Options) window.
On all other platforms, the ars.cfg file of your Content Manager OnDemand instance must be edited. You must add the following line:
ARS_SUPPORT_FULL_TEXT_INDEX=1
You must restart the instance after this configuration. It enables the FTS option in the Content Manager OnDemand Administrator and enables you to configure FTS options on the Application Groups and Folders.
Configuring Application Groups for full text search
FTS support must be configured for each Application Group in which you plan to perform full text index and search.
To FTS index an application group, configure the Application Group for FTS by completing the following steps:
1. Click Application Group → General tab → Advanced and select Yes under Full Text Index. Specify the FTS Server name and port. The default port is 8191. Choose whether to automatically index all new loads. Figure 15-3 shows these settings. The setting Full Text Index documents automatically automatically indexes new documents after they are loaded.

Figure 15-3 Enable full text indexing in an application group
2. Add an FTS field to the Application Group in the Field Definition tab (its name does not matter). On the Field information tab, set the field data type to Small Int (2) and select the Full Text Index attribute option.
3. Modify the permissions and add the Full Text Index permission to users and groups who must be able to index documents (users who perform loading and running a full text indexing request through arsdoc or the API).
Configuring a folder for full text search
The Content Manager OnDemand folders must be configured before any full text searching can occur. Four new folder field types were added in support of FTS:
•Full Text Index Search
This field is required. It is the field that the users use to specify their FTS criteria. This field can only be queried.
•Full Text Index Score
This field is optional. It represents the score of the hit, relative to the other matching hits. It can be queried and displayed in the hit list.
•Full Text Index Highlight
This field is optional. It returns the text surrounding the matching text. It represents the context in which the text was found. This field can be only displayed in the hit list. Highlighting is not supported for XML documents.
•Full Text Index Summary
This field is optional. It returns the first 80 characters of the document. This might be useful depending on the data. For example, bills and statements typically have identical text for headers and therefore this information cannot be used to distinguish hits.
15.4.2 Configuration of the Full Text Search Exporter
FTS Exporter requires configuration parameters for connecting to Content Manager OnDemand, its database, and the FTS Server. These parameters can either be specified on the command line or written into a config file. The usage of the config file is recommended, as your JDBC connection password is part of the required parameters and is stored encrypted in the config file.
To create the config file, run the FTS Exporter with the configure parameter:
Java -jar ODFTIExporter.jar configure -configFile <file>
<all configuration parameters>
<all configuration parameters>
The following parameters are required:
-dbEngine <db engine> DB engine (DB2, MSSQL, or ORACLE)
-dbHostname <server> Database server host name
-dbPort <port> Database port
-dbUser <user> Database user ID
-dbPassword <passwd> Database password
-dbName <db name> Database name
-dbOwner <db owner> Database owner
-odInstance <instance>
-odUser <user> OnDemand user ID
-odPassword <password> OnDemand user password
-odInstallDir <path> Where OnDemand is installed
-pollDelay <seconds> Number of seconds between polling (optional)
-ftiToken <FTI authentication token> Optional
-tempDir <path> Temporary work directory (optional)
-traceDir <path> Directory to store trace files (optional)
-traceLevel <export trace level>
Table 15-1 describes the purpose of each parameter.
Table 15-1 FTS Exporter parameters
|
Parameter
|
Purpose
|
|
dbEngine
|
The engine of the database that is being used. Defines the JDBC class that is used by the FTS Exporter. It must be either DB2, MSSQL, or ORACLE.
|
|
dbHostname
|
The host name of the database server that runs the Content Manager OnDemand instance database.
|
|
dbUser, dbPassword
|
The user and password that is used to connect to the database.
|
|
dbName
|
For Multiplatform systems, this is the database name of the instance database to connect to. For DB2 on z/OS, this is the database location.
|
|
dbOwner
|
The database owner (used to open the correct arsftiwork table).
|
|
odInstance
|
The Content Manager OnDemand instance to connect to. This parameter must match the Content Manager OnDemand instance name that is found in the ars.ini file (or registry in Windows).
|
|
odUser, odPassword
|
User and password of a Content Manager OnDemand user. This user is used to retrieve the documents for full text indexing.
|
|
odInstallDir
|
Installation directory of the Content Manager OnDemand server. This server contains the ars.cfg file, which is used to look up the instance name.
|
|
pollDelay
|
Optional. A polling interval in seconds in which the FTS Exporter checks the arsftiwork table for new work items.
|
|
ftiToken
|
Optional. The FTI authentication token that is used to communicate with the FTS Server. If it is not specified, it is extracted from the Content Manager OnDemand instance configuration.
|
|
tempDir
|
Temporary directory.
|
|
traceDir, traceLevel
|
The location of trace files and tracing level. If it is specified, it should be any of the following tokens:
SEVERE, WARNING, INFO, FINE, FINER, or FINEST.
|
A call to configure the FTS Exporter is similar to the one shown in Example 15-1.
Example 15-1 Configuring the FTS Exporter
java -jar ODFTIExporter.jar configure -configFile odfts.cfg -dbEngine DB2 -dbHostname localhost -dbPort 60004 -dbUser ondemand -dbPassword ondemand -dbName ondemand -dbUser ondemand -odInstallDir /opt/ibm/ondemand/V9.0 -pollDelay 60 -tempDir /tmp -traceDir /tmp -ftiToken "fIqBxTQ=" -odUser admin -odPassword ondemand -dbOwner ondemand -odInstance ONDEMAND
Example 15-1 writes the configuration file odfts.cfg and configures a connection to the Content Manager OnDemand instance ONDEMAND with the user admin and to the Content Manager OnDemand instance DB2 database ondemand. The FTS Exporter polls for work items in the arsftiwork table every 60 seconds and processes them against the FTS Server that is configured with this Content Manager OnDemand instance.
Content Manager OnDemand supports running the FTS Exporter on a machine other than your library and object server. In some instances, this is highly recommend. When run in this way, the Content Manager OnDemand server code must be installed on this other machine because the FTS Exporter requires some of the binary and supporting files from the Content Manager OnDemand server installation. The FTS Exporter also gets some of its connection information (your reference text) from the ars.ini file that is installed with the Content Manager OnDemand server or, for Windows, the registry.
The JDBC connection user that is used by the FTS Exporter must have the SELECT, UPDATE, and DELETE authority on the arsftiwork table and the SELECT authority on the arsseg table of each Content Manager OnDemand instance it is working with.
To connect to your Content Manager OnDemand database using JDBC, additional driver JAR files are required. The FTS Exporter is built to reference two additional JAR files in its directory by default: jdbc1.jar and jdbc2.jar. To use JAR file execution capability, you should link (or copy) your required JDBC driver JAR files to these locations so that they are automatically loaded by the FTS Exporter.
For example, when using DB2 on AIX or Linux, the following commands can be issued in the jars subdirectory of the server to create these two links:
ln -s /opt/IBM/db2/V9.7/java/db2jcc.jar jdbc1.jar
ln -s /opt/IBM/db2/V9.7/java/db2jcc_license_cu.jar jdbc2.jar
For the connection with Content Manager OnDemand, the FTS Exporter automatically references the Java API ODApi.jar.
|
Note: Each instance of the FTS Exporter can connect to one Content Manager OnDemand instance. Only a single instance of the FTS Exporter per Content Manager OnDemand database is supported.
|
15.5 Running full text indexing process
Although both legacy and new data can be full text indexed, the processes for accomplishing each are different. In either case, both the FTS Server and the FTS Exporter must be running to have the indexing requests carried out.
If the FTS Exporter and the FTS Server are not running, all full text indexing requests are written to the arsftiwork table, but not processed until FTS Exporter processes them and hands the documents over to a running FTS Server.
15.5.1 Automatically indexing new data during load
Indexing new data is simple with Content Manager OnDemand and FTS. When FTS is configured correctly, the result of an arsload operation automatically creates work items in arsftiwork. The Application Group must be configured correct. For more information, see “Configuring Application Groups for full text search” on page 417.
15.5.2 Indexing existing data through arsdoc
The arsdoc command is enhanced with two new options. The first new option is fti_add. Parameters for this option control whether the resulting documents are queried through SQL (the -i parameter) or if an entire load is to be full text indexed (the -X parameter).
The second new option added to arsdoc is fti_release. This option takes the same parameters as fti_add to determine which documents should have their indexes removed from the full text index.
Both of these options result in work items being created in the arsftiwork table. Example 15-2 shows an example of the command that is used with Bank1.
Example 15-2 Full text indexing all (SQL WHERE 1=1) documents of Bank1
arsdoc fti_add -f "Bank1" -h localhost -i "where 1=1" -u admin -v -G Bank1
15.5.3 Indexing existing data through ODWEK
The ODWEK Java API contains two new methods that support FTS. The first is ODFolder.FTIAddHits(). This method has a single parameter, which is a Vector of ODHits. The Vector of ODHit objects can be produced by using the search() methods of the ODFolder. All hits that are contained in the Vector parameter to FTIAddHits() are sent to FTS Exporter for full text indexing.
The second new method of the ODFolder object is FTIReleaseHits(). This method also takes a Vector of ODHit objects as a parameter and is used to remove the indexes from the FTS Server.
Both of these calls produce work items in the arsftiwork table.
For more information about the ODWEK Java API, see IBM Content Manager OnDemand Web Enablement Kit Java APIs: The Basics and Beyond, SG24-7646.
15.5.4 Running the FTS Exporter
Processing of the work items in the arsftiwork table is done by the FTS Exporter. The FTS Exporter begins processing work items, starting with the oldest items. It continues to process these work items until the table is empty. Then, it goes to sleep for a specified amount of time before waking up and looking for more
work items.
work items.
After successfully configuring the FTS Exporter, as described in 15.4.2, “Configuration of the Full Text Search Exporter” on page 419, you must run it with the config file as a parameter. The FTS Exporter requires a reference to the ODWEK native libraries that are shipped with Content Manager OnDemand to work correctly. The easiest way of achieving this task is to add this reference to the start command line when running Java with the FTS Exporter JAR file.
Example 15-3 shows how to start the exporter with odfts.cfg as the configuration file and /opt/ibm/ondemand/V9.0/lib64 as the directory where the native library is installed.
Example 15-3 Running the FTS Exporter
java -Djava.library.path=/opt/ibm/ondemand/V9.0/lib64 -jar ODFTIExporter.jar index -configFile odfts.cfg
In Windows environments, make sure to enclose the ODWEK path with quotation marks if it contains spaces.
15.6 Using full text search in Content Manager OnDemand Clients
All Content Manager OnDemand Clients use the same process and procedure when searching the full text index. The query is first sent to the Content Manager OnDemand server for processing. If the Application Group being searched contains a segment date, and if the search criteria specified a date range, that range is used to narrow down which collections on the FTS Server must
be searched.
be searched.
15.6.1 Syntax
The FTS Server supports a rich query language that enables fuzzy searches, proximity searches, weighted searches, and Boolean searches.
Queries can contain terms and operators. A term is a single word, such as “united”. A phrase is a group of words that are contained in quotation marks, such as “computer software”. Phrases are searched as exact expressions; stop words are not removed, no lemmatization is done, and Boolean operators (such as AND) or wildcards (such as * or ?) are treated as literal characters.
Without quotation marks, the query is parsed and the syntactical options that are described in the following sections are allowed.
15.6.2 Boolean searches
Boolean operators allow terms to be combined through logical operators. The following Boolean operators are supported: AND, OR, NOT, and “-”.
Boolean operators must be specified in all uppercase characters. For example, when searching for documents about dogs or cats while specifying the OR Boolean operators, specify the query as dogs OR cats, not dogs or cats.
Precede a term with a minus sign (-) to indicate that the term must be absent from a document for a match to occur. For example, the following query returns documents that include the term computer and not the term hardware:
computer -hardware
Use parentheses to control the Boolean logic in a query. For example, the following query finds documents that contain either WebSphere or IBM Lotus® and website:
(WebSphere OR Lotus) AND website
15.6.3 Wildcard searches and optional terms
FTS supports wildcard searches. You can place wildcard characters before, within, or after a term.
Use a question mark (?) to perform a single character wildcard search. For example, the following query finds documents that contain the terms mare, mere, mire, and more:
m?re
Use an asterisk (*) to perform a multiple character wildcard search. A multiple character wildcard search looks for zero or more alphanumeric characters.
Use a percent sign (%) to indicate that a search term is optional. For example, the following query finds documents that include the term log and optionally include the term file:
log %file
15.6.4 Fuzzy and proximity searches
A fuzzy search query searches for character sequences that are not only the same but similar to the query term. Use the tilde symbol (~) at the end of a term to do a fuzzy search. For example, the following query finds documents that include the terms analytics, analyze, and analysis:
analytics~
An optional parameter can be used to specify the required similarity. Specify a value greater than 0 and less than 1. The value must be preceded by a 0 and decimal point, for example, 0.8:
analytics~0.8
A value closer to 1 matches terms with a higher similarity. If the parameter is not specified, the default is 0.5.
A proximity search finds documents that contain terms within a specified number of words of each other. Use the tilde symbol (~) to do a proximity search. For example, the following query finds documents that contain “IBM” and “WebSphere” within seven words of each other:
"IBM WebSphere"~7
Proximity search is supported for individual terms, not phrases. Also, a word after a sentence break is considered 10 positions apart from the last word of the previous sentence.
15.6.5 Weighted searches (boosting terms)
Follow a search term by a boost value to influence how documents that contain a specified term are ranked in the search results. Use the caret symbol (^) with a number (the boost factor) at the end of the term. For example, the following query finds documents that include the terms IBM and Germany and increases the relevance of these documents by a factor of five in the search results:
ibm Germany^5.0
|
Note: Special character, such as punctuation marks, are not alphanumeric characters and are not supported in fuzzy or proximity searches, or are not hit by a wildcard (*) operator.
|
15.7 Troubleshooting tips
If you encounter any problems during full text indexing and searching, you should investigate the issue by looking at the different logs or by using the trace options.
15.7.1 Content Manager OnDemand server log
Each full text indexing operation is registered at the Content Manager OnDemand system log. Example 15-4 lists a few message numbers with
their text.
their text.
Example 15-4 Content Manager OnDemand system log messages that are related to full text search
Message 397: Document Full Text Index Add: ApplGroupName(Adobe PDFs) Agid(5021) Full Text Index Notified(1) Count(16) Time(0.069)
Message 398: Document Full Text Index Add Failed: ApplGroupName(Adobe PDFs) Agid(5021) Full Text Index Notified(0) Count(16) Time(0.001)
Message 399: Document Full Text Index Delete: ApplGroupName(Adobe PDFs) Agid(5021) Full Text Index Notified(1) Count(16) Time(0.025)
Message 226: Application Group Query: Name(BaxterBayBank) Agid(5025) Time(0.120) Hits(2) Count() Sql(WHERE ODDAT_Sdate BETWEEN '1996-06-22' AND '2013-06-22' ) SqlR() FullTextSearch(lunch* newark) FullTextScore() ServerTextSearch() AnnColor() AnnText() OrderBy()
Message 439: FTS Error: IQQS0032E The query lunch~x cannot be processed because it has incorrect syntax. Causes of the problem: IQQP9014E The query [lunch~x] cannot be parsed because there is a syntax error at position 7. The fuzzy argument value [x] is not valid because its data type is not float or double. -- File=arsfti.cpp, Line=394
Messages 397, 398, and 399 are viewable and contain the list of documents (their metadata) that are affected by this operation. In the case of message 398 (fail), the failure reason is documented as well.
Each time the FTS Server reports an error, message 439 is issued, and contains the error message that returned by the FTS Server. In the above case, the query that is entered by the user contained a wrong syntax for a proximity or fuzzy search.
15.7.2 Full Text Search Server log
You can troubleshoot the FTS Server by configuring and viewing logs. FTS Server generates logging information during server startup, indexing, and searching. The log files contain configuration information, warnings, errors, and debugging information that can be useful for monitoring the server and troubleshooting specific issues. The command-line tools also generate log files. By default, log files are stored in the FTS_Home/log directory. You can run the configTool with the list -logFolder command to see your log directory.
Every message in the log file has an associated level that indicates the message type. Logging levels, in descending order of severity, are defined as follows:
•SEVERE: Errors and exceptions that occur during the running of the server. Typically, SEVERE messages include detailed information with the
stack trace.
stack trace.
•WARNING: Mild problems that might require the attention of an administrator, such as a missing value for a setting with a default value, or the truncation of a document during indexing.
•INFO: Informational messages that are generated during system operation
•FINE: Detailed messages for debugging purposes. Includes parsed queries.
•FINER: More details, for example, results of document parsing.
•FINEST: The most detailed level.
The default logging level is INFO, which means that messages of levels SEVERE, WARNING, and INFO are generated. To view the current logging level, run the adminTool with the printLogLevel command. To change the logging level at run time, run the adminTool with the configureTrace
-logLevel command.
-logLevel command.
15.7.3 Full Text Search Exporter trace
When you have issues with the FTS Exporter, enable tracing by using the -traceDir and -traceLevel parameters. Set the -traceLevel parameter to FINE when troubleshooting a problem. A trace file is created and named ftiexport_0.0_DDMMYYHHMM.log in the directory that is specified by the
-traceDir parameter.
-traceDir parameter.
Enabling trace within the FTS Exporter also enables trace in ODWEK. This results in the creation of an ODWEK trace files named arswww.trace. This trace file is also written to the traceDir directory. The FTS Exporter trace files can be read with any text editor, but the ODWEK trace files are viewable only by using the Content Manager OnDemand arstfmt command.
If you are running the FTS Exporter by using a configuration file, you must create a separate configuration file with the trace level set to a different level because the command-line parameter is ignored when you use a configuration file.
15.7.4 Authentication and FTS Exporter errors
Here are some tips to help you to troubleshoot authentication and FTS Exporter-related errors.
Authentication errors
If you are encountering any errors about authentication in the FTS Exporter trace, FTS Server log, or message 439 in the Content Manager OnDemand system log with the following message text, you might be using the wrong authentication token:
FTS Error: IQQD0040E The client specified the wrong authentication token. -- File=arsfti.cpp, Line=394
The default authentication token of fIqBxTQ= can change because of a reinstallation of the FTS Server or other severe incidents. You can discover the current authentication token by running the configTool of FTS Server with the parameter printToken. See Example 15-5.
Example 15-5 Displaying the currently active token
# /opt/ibm/odfts/V9.0/bin/configTool.sh printToken
The authentication token is printed below. This token is used to communicate with the server. Store the token if applicable.
fIqBxTQ=
You can configure the authentication token that is used by Content Manager OnDemand through a configuration setting in the ars.cfg file of your instance:
ARS_FULL_TEXT_INDEX_TOKEN=fIqBxTQ=
The same applies to the configuration parameter and the parameter file of the FTS Exporter application.
If you are writing down the default token (for example, as a parameter to FTS Exporter), be aware that the second character of the token value is an upper-case letter I, as in like in IBM.
Exporter errors
If you are encountering issues with the FTS Exporter, increase the trace level as described in 15.7.3, “Full Text Search Exporter trace” on page 428. Also, make sure to review the configuration file by opening it in a text editor. Check whether all settings are reflected correctly.
If you are encountering errors about ars3wapi in the FTS Exporter output or trace, the FTS Exporter cannot find the native library reference to the ODWEK system libraries. To see how the -D parameter of Java can be used to include the native library path upon application start, see 15.5.4, “Running the FTS Exporter” on page 423.
If the error is related to a java.lang.UnsatisfiedLinkError error not finding the ars3wapi32, you are running on a 32-bit JVM. The Java classes of the FTS Exporter try to load the libars3wapi64, which is found in the lib64 subdirectory of your Content Manager OnDemand installation. If they cannot load these, a 32-bit version is searched (which is not present in the lib64 folder) and if both fail, it fails with the respective error message.
Make sure that you are running the FTS Exporter with a 64-bit JVM that can load the 64-bit share library libars3wapi64.
For more information about ODWEK native libraries, see “Accessing the native libraries” on page 229.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.