
4
Data Storage
Data storage in the cloud has become very common, not just for personal usage but also for business, computational, and application purposes as well. On the personal side, cloud storage is provided by well-known companies, ranging from a free usage tier of a few Gigabytes (GBs), to pay monthly or yearly plans for Terabytes (TBs) of data. These services are well integrated with applications on mobile devices, enabling users to store thousands of pictures, videos, songs, and other types of files.
For applications requiring high-performance computations, cloud data storage plays an even bigger role. For example, training Machine Learning (ML) models over large datasets generally requires algorithms to run in a distributed fashion. If data is stored on the cloud, then it makes it much easier and more efficient for the ML platform to partition the data stored in the cloud and make these separate partitions available to the distributed components of the model training job. Similarly, for several other applications requiring large data amounts and high throughput, it makes much more sense to use cloud data storage to avoid throttling local storage. In addition, cloud data storage almost always has built-in redundancy to avoid hardware failures, accidental deletes, and hence loss of data. There are also several security and governance tools and features that are always provided with cloud data storage services. Furthermore, the true cost of ownership of data storage in the cloud is significantly reduced due to scale and infrastructure maintenance being managed by the storage service provider.
AWS provides several options for cloud data storage. In this chapter, we will learn about the various AWS data storage services, along with the security, access management, and governance aspects of these services. In addition, we will also learn about the tiered storage options to save cloud data storage costs.
We will cover the following topics in this chapter:
- AWS services for storing data
- Data security and governance
- Tiered storage for cost optimization
- Choosing the right storage option for High-Performance Computing (HPC) workloads
Technical requirements
The main technical requirements for being able to work with the various AWS storage options in this chapter are to have an AWS account and the appropriate permissions to use these storage services.
AWS services for storing data
AWS offers three different types of data storage services: object, file, and block. Depending on the need for the application, one or more of these types of services can be used. We will go through the AWS services spanning these storage categories in this section. The various AWS data storage services are shown in Figure 4.1.

Figure 4.1 – AWS data storage services
In the next section, we will discuss the various storage options provided by AWS.
Amazon Simple Storage Service (S3)
Amazon S3 is one of the most commonly used cloud data storage services for web applications, and high-performance compute use cases. It is Amazon’s object storage service providing virtually unlimited data storage. Some of the advantages of using Amazon S3 include very high scalability, durability, data availability, security, and performance. Amazon S3 can be used for a variety of cloud-native applications, ranging from simple data storage to very large data lakes to web hosting and high-performance applications, such as training very advanced and compute-intensive ML models. Amazon S3 offers several classes of storage options with differences in terms of data access, resiliency, archival needs, and cost. We can choose the storage class that best suits our use case and business needs. There is also an option for cost saving when the access pattern is unknown or changes over time (S3 Intelligent-Tiering). We will discuss these different S3 storage classes in detail in the Tiered storage for cost optimization section of this chapter.
Key capabilities and features of Amazon S3
In Amazon S3, data is stored as objects in buckets. An object is a file and any metadata that describes the file, and buckets are the resources (containers) for the objects. Some of the key capabilities of Amazon S3 are discussed next.
Data durability
Amazon S3 is designed to provide very high levels of durability to the data, up to 99.999999999%. This means that the chances of data objects stored in Amazon S3 getting lost are extremely low (average expected loss of approximately 0.000000001% of objects, or 1 out of 10,000 objects every 10 million years). For HPC applications, data durability is of the utmost importance. For example, for training an ML model, data scientists need to carry out various experiments on the same dataset in order to fine-tune the model parameters to get the best performance. If the data storage from which training and validation data is read is not durable for these experiments, then the results of the trained model will not be consistent and hence can lead to incorrect insights, as well as bad inference results. For this reason, Amazon S3 is used in many ML and other data-dependent HPC applications for storing very large amounts of data.
Object size
In Amazon S3, we can store objects up to 5 TB in size. This is especially useful for applications that require processing large files, such as videos (for example, high-definition movies or security footage), large logs, or other similar files. Many high-performance compute applications, such as training ML models for a video classification example, require processing thousands of such large files to come up with a model that makes inferences on unseen data well. A deep learning model can read these large files from Amazon S3 one (or more) at a time, store them temporarily on the model training virtual machine, compute and optimize model parameters, and then move on to the next object (file). This way, even machines with smaller disk space and memory can be used to train these computationally intensive models over large data files. Similarly, at the time of model inference, if there is a need to store the data, it can be stored in Amazon S3 for up to 5 TB of object size.
Storage classes
Amazon S3 has various storage classes. We can store data in any of these classes and can also move the data across the classes. The right storage class to pick for storing data depends on our data storage, cost, and retention needs. The different S3 storage classes are as follows:
- S3 Standard
- S3 Standard-Infrequent Access
- S3 One Zone-Infrequent Access
- S3 Intelligent-Tiering
- S3 Glacier Instant Retrieval
- S3 Glacier Flexible Retrieval
- S3 Glacier Deep Archive
- S3 Outposts
We will learn about these storage classes in the Tiered storage for cost optimization section of this chapter.
Storage management
Amazon S3 also has various advanced storage management options, such as data replication, prevention of accidental deletion of data, and data version control. Data in Amazon S3 can be replicated into destination buckets in the same or different AWS Regions. This can be done to add redundancy and hence reliability and also improve performance and latency. This is quite important for HPC applications as well since real-time HPC applications that need access to data stored in Amazon S3 will benefit from accessing data from a geographically closer AWS Region. Performance is generally accelerated by up to 60% when datasets are replicated across multiple AWS Regions. Amazon S3 also supports batch operations for data access, enabling various S3 operations to be carried out on billions of objects with a single API call. In addition, lifecycle policies can be configured for objects stored in Amazon S3. Using these policies, S3 objects can be moved automatically to different storage classes depending on access need, resulting in cost optimization.
Storage monitoring
Amazon S3 also has several monitoring capabilities. For example, tags can be assigned to S3 buckets, and AWS cost allocation reports can be used to view aggregated usage and cost using these tags. Amazon CloudWatch can also be used to view the health of S3 buckets. In addition, bucket- and object-level activities can also be tracked using AWS CloudTrail. Figure 4.2 shows an example of various storage monitoring tools working with an Amazon S3 bucket:

Figure 4.2 – S3 storage monitoring and management
The preceding figure shows that we can also configure Amazon Simple Notification Service (SNS) to trigger AWS Lambda to carry out various tasks in the case of certain events, such as new file uploads and so on.
Data transfer
For any application built upon large amounts of data and using S3, the data first needs to be transferred to S3. There are various services provided by AWS that work with S3 for different data transfer needs, including hybrid (premises/cloud) storage and online and offline data transfer. For example, if we want to extend our on-premise storage with cloud AWS storage, we can use AWS Storage Gateway (Figure 4.3). Some of the commonly implemented use cases for AWS Storage Gateway are the replacement of tape libraries, cloud storage backend file shares, and low-latency caching of data for on-premise applications.

Figure 4.3 – Data transfer example using AWS Storage Gateway
For use cases requiring online data transfer, AWS DataSync can be used to efficiently transfer hundreds of terabytes into Amazon S3. In addition, AWS Transfer Family can also be used to transfer data to S3 using SFTP, FTPS, and FTP. For offline data transfer use cases, AWS Snow Family has a few options available, including AWS Snowcone, AWS Snowball, and AWS Snowmobile. For more details about the AWS Snow Family, refer to the Further reading section.
Performance
One big advantage of S3 for HPC applications is that it supports parallel requests. Each S3 prefix supports 3,500 requests per second to add data and 5,500 requests per second to retrieve data. Prefixes are used to organize data in S3 buckets. These are a sequence of characters at the beginning of an object’s key name. We can have as many prefixes as we need in parallel, and each prefix will support this throughput. This way, we can achieve the desired throughput for our application by adding prefixes. In addition, if there is a long geographic separation between the client and the S3 bucket, we can use Amazon S3 Transfer Acceleration to transfer data. Amazon CloudFront is a globally distributed network of edge locations.
Using S3 Transfer Allocation, data is first transferred to an edge location in Amazon CloudFront. From the edge location, an optimized high-bandwidth and low-latency network path is then used to transfer the data to the S3 bucket. Furthermore, data can also be cached in CloudFront edge locations for frequently accessed requests, further optimizing performance. These performance-related features help in improving throughput and reducing latency for data access, especially suited to various HPC applications.
Consistency
Data storage requests to Amazon S3 have strong read-after-write consistency. This means that any data written (new or an overwrite) to S3 is available immediately.
Analytics
Amazon S3 also has analytics capabilities, including S3 Storage Lens and S3 Storage Class Analysis. S3 Storage Lens can be used to improve storage cost efficiency, as well as to provide best practices for data protection. In addition, it can be used to look into object storage usage and activity trends. It can provide a single view across thousands of accounts in an organization and can generate insights on various levels, such as account, bucket, and prefix. Using S3 Storage Class, we can optimize cost by deciding on when to move data to the right storage class. This information can be used to configure the lifecycle policy to make the data transfer for the S3 bucket. Amazon S3 Inventory is another S3 feature that generates daily or weekly reports, including bucket names, key names, last modification dates, object size, class, replication, encryption status, and a few additional properties.
Data security
Amazon S3 has various security measures and features. These features include blocking unauthorized users from accessing data, locking objects to prevent deletions, modifying object ownership for access control, identity and access management, discovery and protection of sensitive data, server-side and client-side encryption, the inspection of an AWS environment, and connection to S3 from on-premise or in the cloud using private IP addresses. We will learn about these data security and access management features in detail in the Data security and governance section.
Amazon S3 example
To be able to store data in an S3 bucket, we first need to create the bucket. Once the bucket is created, we can upload objects to the bucket. After uploading the object, we can download, move, open, or delete it. In order to create an S3 bucket, there are certain prerequisites listed as follows:
- Signing up for an AWS account
- Creating an Identity and Access Management (IAM) user or a federated user assuming an IAM role
- Signing in as an IAM user
Details of how to carry out these prerequisite steps can be found on Amazon S3’s documentation web page (see the Further reading section).
S3 bucket creation
We can create an S3 bucket by logging into the AWS management console and selecting S3 in the services. Once in the S3 console, we will see a screen like that shown in Figure 4.4:

Figure 4.4 – Amazon S3 console
As Figure 4.4 shows, we do not have any S3 buckets so far in our account. To create an S3 bucket, perform the following steps:
- Click on one of the Create bucket buttons shown on this page. Figure 4.5 shows the Create bucket page on the S3 console.
- Next, we need to specify Bucket name and AWS Region. Note that the S3 bucket name needs to be globally unique:
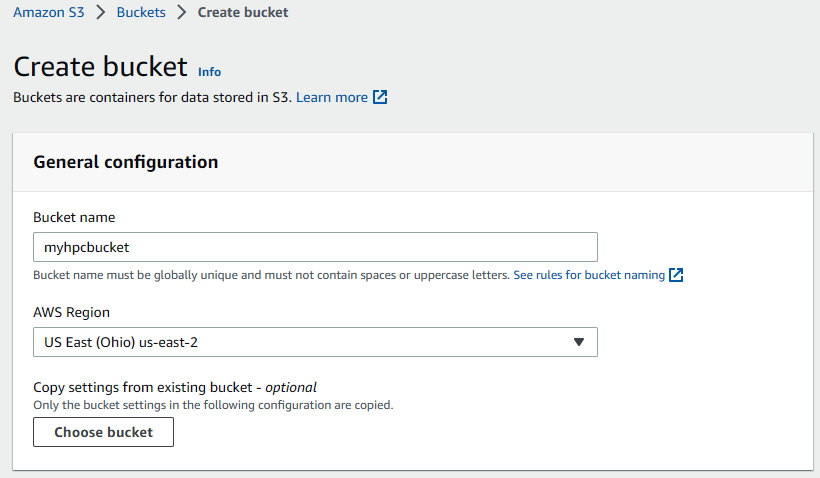
Figure 4.5 – Amazon S3 bucket creation
- We can also select certain bucket settings from one of our existing S3 buckets. On the S3 Create bucket page, we can also define whether the objects in the bucket are owned by the account creating the bucket or not, as other AWS accounts can also own the objects in the bucket. In addition, we can also select whether we want to block all public access to the bucket (as shown in Figure 4.6). There are also other options that we can select on the S3 bucket creation page, such as versioning, tags, encryption, and object locking:

Figure 4.6 – Public access options for the S3 bucket
- Once the bucket has been created, it will show up in the S3 console as shown in Figure 4.7, where we have created a bucket named myhpcbucket. We can add objects to it using the console, AWS Command Line Interface (CLI), AWS SDK, or Amazon S3 Rest API:

Figure 4.7 – Amazon S3 console showing myhpcbucket
We can click on the bucket name and view objects stored in it along with bucket properties, permissions, metrics, management options, and access points.
In this section, we have learned about the Amazon S3 storage class, its key features and capabilities, and how to create an Amazon S3 bucket. In the next section, we are going to discuss Amazon Elastic File System, which is the file system for Amazon Elastic Compute Cloud instances.
Amazon Elastic File System (EFS)
Amazon Elastic File System (EFS) is a fully managed serverless elastic NFS file system specifically designed for Linux workloads. It can quickly scale up to petabytes of data automatically and is well suited to work with on-premise resources as well as with various AWS services. Amazon EFS is designed such that thousands of Amazon Elastic Compute Cloud (EC2) instances can be provided with parallel shared access. In addition to EC2, EFS file systems can also be accessed by Amazon Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS), AWS Fargate, and AWS Lambda functions through a file system interface. The following are some of the common EFS use cases:
- High-performance compute: Since Amazon EFS is a shared file system, it is ideal for applications that require distributed workload across many instances. Applications and use cases requiring high-performance computes, such as image and video processing, content management, and ML applications, such as feature engineering, data processing, model training, numerical optimization, big data analytics, and similar applications, can benefit from Amazon EFS.
- Containerized applications: Amazon EFS is a very good fit for containerized applications because of its durability, which is a very important requirement of these applications. EFS integrates with Amazon container-based services such as Amazon ECS, Amazon EKS, and AWS Fargate.
- DevOps: Amazon EFS can be used for DevOps because of its capability to share code. This helps with code modification and the application of bug fixes and enhancements in a fast, agile, and secure manner, resulting in quick turnaround time based on customer feedback.
- Database backup: Amazon EFS is also often used as a database backup. This is because of the very high durability and reliability of EFS, and its low cost, along with being a POSIX-compliant file storage system – all of these often being requirements for a database backup from which the main database can be restored quickly in case of a loss or emergency.
In the next section, we will discuss the key capabilities of Amazon EFS.
Key capabilities and features of Amazon EFS
In this section, we will discuss some of the key capabilities and features of Amazon EFS. Some of the key capabilities of Amazon S3 also apply to Amazon EFS.
Durability
Like Amazon S3, Amazon EFS is also very highly durable and reliable, offering 99.999999999% durability. EFS achieves this high level of durability and redundancy by storing everything across multiple Availability Zones (AZs) within the same AWS Region (unless we select EFS One Zone storage class for the EFS storage). Because data is available across multiple AZs, EFS has the ability to recover and repair very quickly from concurrent device failures.
Storage classes
Amazon EFS also offers multiple options for storage via storage classes. These storage classes are as follows:
- Amazon EFS Standard
- Amazon EFS One Zone
- Amazon EFS Standard-Infrequent Access
- Amazon EFS One Zone-Infrequent Access
We will discuss these classes in the Tiered storage for cost optimization section. We can easily move files between storage classes for cost and performance optimization using policies.
Performance and throughput
Amazon EFS has two modes each for performance and throughput. For performance modes, it has General Purpose and Max I/O. General Purpose mode provides low latency for random as well as sequential input-output file system operations. Max I/O, on the other hand, is designed for very high throughput and operations per second. It is, therefore, very well suited for high-performance and highly parallelized compute applications.
For throughput, EFS has Bursting (default) and Provisioned modes. In Bursting mode, the throughput scales with the size of the file system and can burst dynamically depending on the nature of the workload. In Provisioned mode, throughput can be provisioned depending on the dedicated throughput needed by the application. It does not depend on the size of the file system.
Scalability
Amazon EFS is highly elastic and scalable. It grows up and down in size as more data is added or removed and is designed for high throughput, Input/Output Operations Per Second (IOPS), and low latency for a wide variety of workloads and use cases. It also has the capability to provide very high burst throughput for unpredictable and spiky workloads, supporting up to 10 GB/second and 500,000 IOPS at the time of writing.
AWS Backup
Amazon EFS works with AWS Backup, which is a fully managed backup service. It automates and enables us to centrally manage the EFS file systems, removing costly and tedious manual processes.
Data transfer
Like Amazon S3, Amazon EFS also works with various AWS data transfer services, such as AWS DataSync and AWS Transfer Family, for transferring data in and out of EFS for one-time migration, as well as for periodic synchronization, replication, and data recovery.
An Amazon EFS example
We can create an Amazon EFS file system either using the AWS Management Console or the AWS CLI. In this section, we will see an example of creating an EFS file system using the AWS Management Console:
- When we log into AWS Management Console and browse to Amazon EFS service, we will see the main page like the one shown in Figure 4.8. It also lists all the EFS file systems that we have created in the AWS Region that we are looking at:

Figure 4.8 – Amazon EFS landing page
- To create an Amazon EFS file system, we click on the Create file system button. When we click this button, we are shown a screen as shown in Figure 4.9. Here, we can pick any name for our file system.
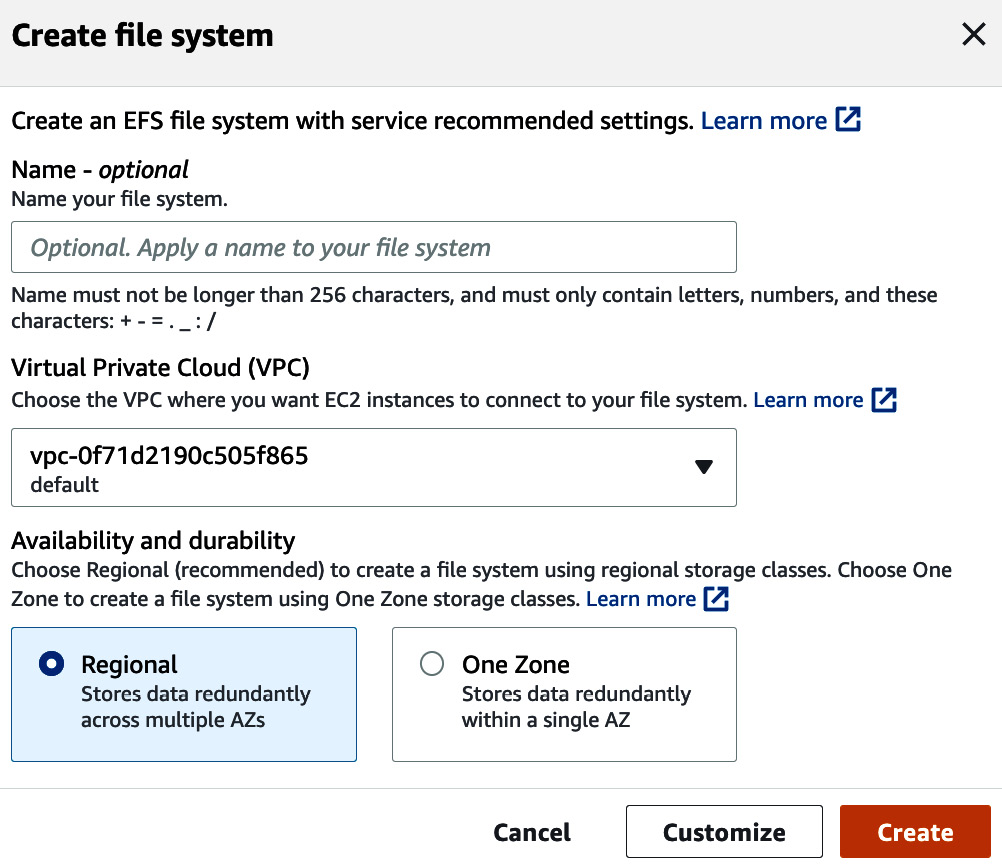
Figure 4.9 – Creating an Amazon EFS file system
- For the file system, select a Virtual Private Cloud (VPC), and also select whether we want it across all AZs in our region or just one AZ.
- We can also click on the Customize button to configure other options, such as Lifecycle management (Figure 4.10), Performance mode and Throughput mode (Figure 4.11), Encryption, Tags, network options, and the File system policy.
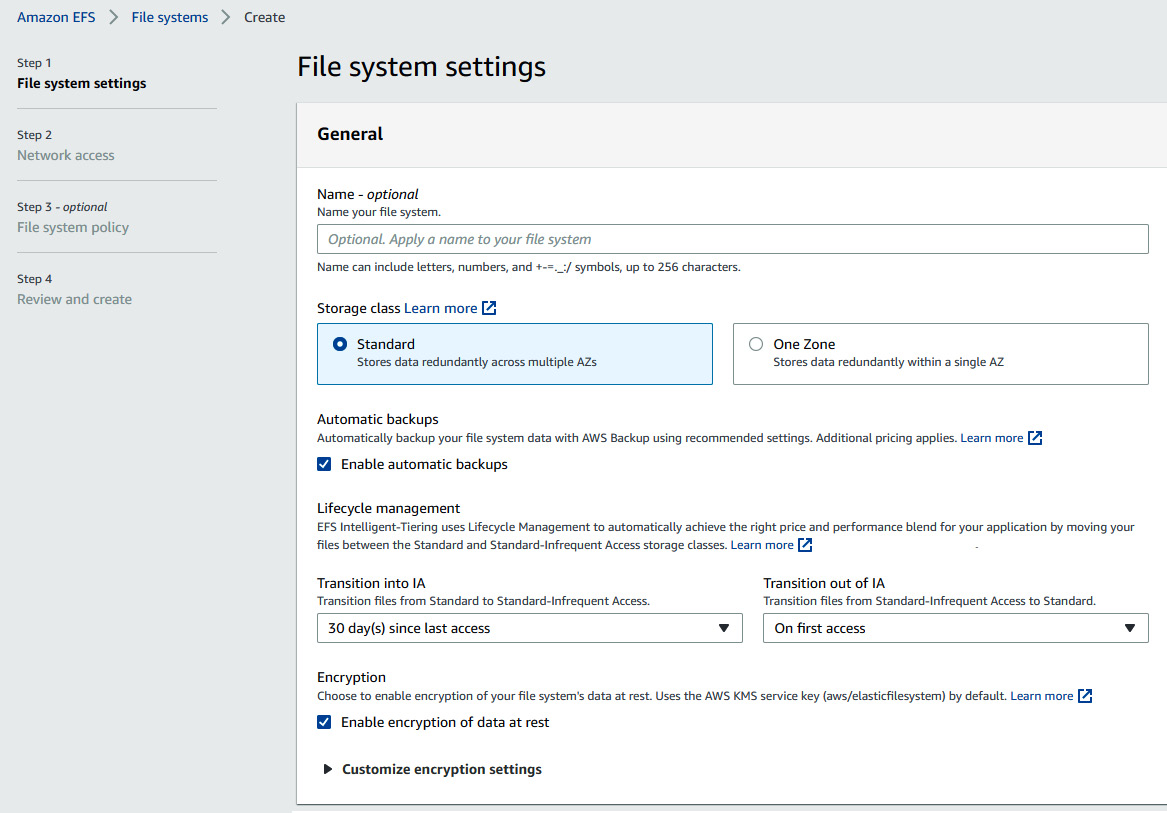
Figure 4.10 – Selecting options for an Amazon EFS file system

Figure 4.11 – Selecting additional options for Amazon EFS
- Clicking on Next and then Create will create the Amazon EFS file system. The EFS file system we have created is shown in Figure 4.12.

Figure 4.12 – Created EFS file system
- We can click on the file system to view its various properties as well as to get the command to mount it to a Linux instance as shown in Figure 4.13. Once the EFS file system is mounted, we can use it just like a regular file system.
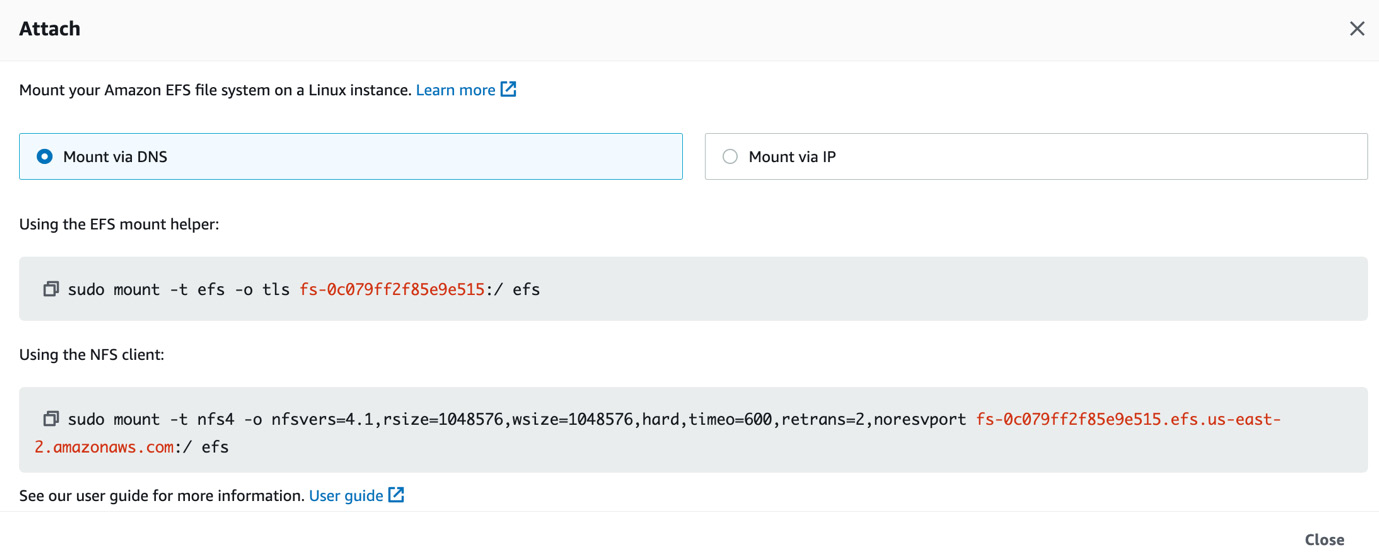
Figure 4.13 – Mounting options and commands for the EFS file system
Let’s discuss Amazon Elastic Block Store (EBS) and its key features and capabilities in the next section.
Amazon EBS
Amazon EBS is a scalable, high-performance block storage service that can be used to create storage volumes that attach to EC2 instances. These volumes can be used for various purposes, such as a regular block storage volume, creating file systems on top of these, or even running databases. The following are some of the common use cases where Amazon EBS is used:
- EBS can be used for big data analytics, where frequent resizing of clusters is needed, especially for Hadoop and Spark.
- Several types of databases can be deployed using Amazon EBS. Some examples include MySQL, Oracle, Microsoft SQL Server, Cassandra, and MongoDB.
- If we are running a computation job on an EC2 instance and need storage volume attached to it to read the data and write results without the need to scale across multiple instances, then EBS serves as a good option.
Next, let’s look at some of the key features and capabilities of Amazon EBS.
Key features and capabilities of Amazon EBS
In this section, we discuss the key features and capabilities of Amazon EBS, such as volume types, snapshots, elastic volumes, EBS-optimized instances, and durability.
Volume types
EBS volumes are divided into two main categories: SSD-backed storage and HDD-backed storage. We discuss these categories here:
- SSD-backed storage: In SSD-backed storage, performance depends mostly on IOPS and is best suited for transactional workloads, for example, databases and boot volumes. There are two main types of SSD-backed storage volumes:
- Provisioned IOPS SSD volumes: They are very high throughput volumes and are designed to provide single-digit millisecond latencies while delivering the provisioned performance 99.9% of the time. They are especially suited for critical applications that require very high uptime.
- General purpose SSD volumes: These storage volumes also offer single-digit millisecond latency while delivering the provisioned performance 99% of the time. They are especially suited for transactional workloads, virtual desktops, boot volumes, and similar applications.
- HDD-backed storage: In HDD-backed storage, performance depends mostly on MB/s and is best suited for throughput-intensive workloads, for example, MapReduce and log processing. There are also two main types of HDD-backed storage volumes:
- Throughput optimized HDD volumes: These volumes deliver performance measured in MB/s and are best suited for applications such as MapReduce, Kafka, log processing, and ETL workloads.
- Cold HDD volumes: They provide the lowest cost of all EBS volumes and are backed by hard disk drives. These volumes are best suited for infrequently accessed workloads, such as cold datasets.
The option of picking the appropriate category for EBS volume provides user flexibility depending on the use case.
Snapshots
Amazon EBS has the ability to store the volume snapshots to Amazon S3. This is done incrementally, adding only the blocks of data that have been changed since the last snapshot. The data life cycle for EBS snapshots can be used to schedule the automated creation and deletion of EBS. These snapshots can be used not just for data recovery but also for initiating new volumes, expanding volume sizes, and moving EBS volumes across AZs in an AWS Region.
Elastic volumes
Using Amazon EBS Elastic Volumes, we can increase the capacity of the volume dynamically at a later point and can also change the type of volume without any downtime.
EBS-optimized instances
To fully utilize the IOPS configured for an EBS volume and provide maximum performance, some EC2 instances can be launched as EBS-optimized instances. This ensures dedicated throughput between Amazon EC2 instance and Amazon EBS volume.
Durability
Like Amazon S3 and Amazon EFS, Amazon EBS is also highly durable and reliable. Data in Amazon EBS is replicated on multiple servers in an AZ to provide redundancy and recovery in case any single component in the volume storage fails.
EBS volume creation
When creating an EC2 instance, we can add additional EBS volumes to it, as shown in Figure 4.14 in the Add Storage step. In addition, we can also add new volumes from the EC2 management console after the instance has been launched. In the EC2 management console, we can review our existing volumes and snapshots along with lifecycle management policies.
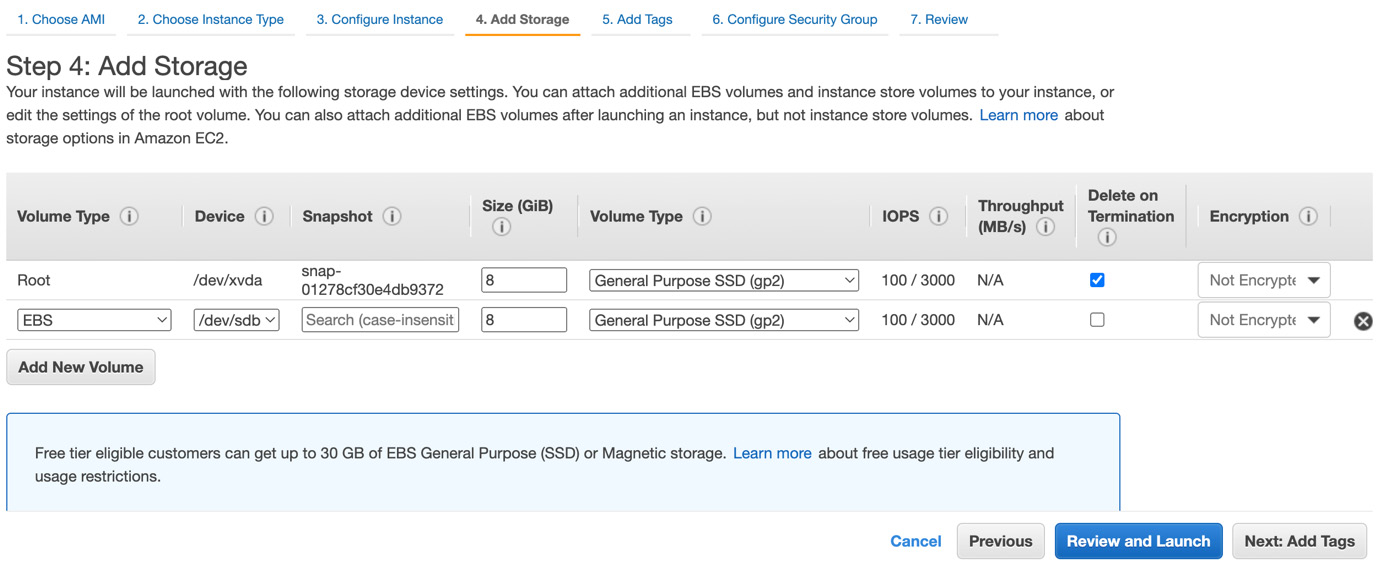
Figure 4.14 – Adding an EBS volume during the EC2 instance creation process
Figure 4.15 shows an example where we have two EBS volumes, along with their various configuration parameters:

Figure 4.15 – Volumes page in EC2 management console showing two EBS volumes that were created
So far, in this chapter, we have learned about Amazon S3, Amazon EFS, and Amazon EBS. In the next section, we discuss the Amazon FSx family of file systems.
Amazon FSx
Amazon FSx is a feature-rich, scalable, high-performance, and cost-effective family of file systems. It consists of the following commonly used four file systems:
- Amazon FSx for NetApp ONTAP
- Amazon FSx for Windows File Server
- Amazon FSx for Lustre
- Amazon FSx for OpenZFS
Some of the common examples where the FSx family of file systems is used are the following:
- FSx can deliver very low latency (sub-millisecond) and millions of IOPS and is highly scalable, making it ideal for high-performance compute applications, such as ML, numerical optimization, big data analytics, and similar applications
- Data can be migrated without breaking or modifying existing code and workflows to FSx by matching the FSx file system to that of the on-premise one
- Media and entertainment is another example where FSx is very commonly used because of it being a high-performance file system
Key features of Amazon FSx
In this section, we will discuss the key features of Amazon FSx, such as management, durability, and cost.
Fully managed
Amazon FSx is fully managed, making it very easy to migrate applications built on commonly used file systems in the industry to AWS. Linux, Windows, and macOS applications requiring very low latency and high performance work very well with Amazon FSx because of its sub-millisecond latencies.
Durability
The data in Amazon FSx is replicated across or within AZs, in addition to having the option to replicate data across AWS Regions. It also integrates with AWS Backup for backup management and protection. These features make Amazon FSx a highly available and durable family of file systems.
Cost
The cost and performance of Amazon FSx can be optimized depending on the need. It can be used for small as well as very compute-intensive workloads, such as ML and big data analytics. Like Amazon EBS, it also offers SSD and HDD storage options that can be configured for performance and storage capacity separately.
Creating an FSx file system
We can create an FSx file system by logging into the AWS management console. In the console, upon pressing the Create file system button, we get the option of selecting the type of FSx file system (Figure 4.16).

Figure 4.16 – FSx file system types
Upon selecting the type that we want to create, we are also prompted with additional options, some of which are specific to that particular FSx system being created. Some of these options, such as deployment and storage types, network and security, and Windows authentication, are shown in Figures 4.17–4.19 for FSx for Windows File Server. These options will vary depending on the type of file system that we are creating. After creating the file system, we can mount it to our EC2 instance.

Figure 4.17 – Creating FSx for Windows File Server

Figure 4.18 – Network and security options for FSx for Windows File Server
Figure 4.19 – Authentication and encryption options for FSx for Windows File Server
This concludes our discussion on the various data storage options provided by AWS. We have learned about Amazon S3, Amazon EFS, Amazon EBS, and the Amazon FSx family, along with their key capabilities and features. In the next section, we will learn about the data security and governance aspects of cloud data storage on AWS.
Data security and governance
Data security and governance are very important aspects of cloud storage solutions and applications, whether they are web pages, file storage, ML applications, or any other application utilizing cloud data storage. It is of absolute importance that the data is protected while being at rest in storage or in transit. In addition, access controls should be applied to different users based on the privileges needed for data access. All the AWS data storage services mentioned previously have various security, protection, access management, and governance features. We will discuss these features in the following sections.
IAM
In order to be able to access AWS resources, we need an AWS account and to authenticate every time we log in. Once we have logged into AWS, we need permission to access the AWS resources. AWS IAM is used to attach permission policies to users, groups, and roles. These permission policies govern and control the access to AWS resources. We can specify who can access which resource and what actions they can take for that resource (for example, creating an S3 bucket, adding objects, listing objects, deleting objects, and so on). All AWS data storage services described in the previous section are integrated with AWS IAM, and access to these services and associated resources can be governed and controlled using IAM.
Data protection
All AWS data storage and file system services have various data protection features. We should always protect AWS account credentials and create individual user accounts using AWS IAM, giving each user the least privileges to access AWS resources that are needed for their job duties. A few additional security recommendations that help with data protection in AWS are the use of Multi-Factor Authentication (MFA), Secure Socket Layer (SSL), Transport Layer Security (TLS), activity logging via AWS CloudTrail, AWS encryption solutions, and Amazon Macie for Amazon S3 for securing personal and sensitive data.
The various tiers of Amazon S3 (except One Zone-IA) store all data objects across at least three AZs in an AWS Region. The One Zone-IA storage class provides redundancy and protection by storing data on multiple devices within the same AZ. In addition, with the help of versioning, different versions of data objects can be preserved and recovered as needed.
Data encryption
AWS provides data encryption at rest as well as in transit. Encryption in transit can be carried out by enabling SSL/TLS. Also, all data across AWS Regions flowing over the AWS global network is automatically encrypted. In Amazon S3, data can also be encrypted using client-side encryption. Data at rest on Amazon S3 can be encrypted using either server-side encryption or client-side encryption. For server-side encryption, we can either use AWS Key Management Service (KMS) or Amazon S3-managed encryption. For client-side encryption, we need to take care of the encryption process and upload objects to S3 after encrypting them. We can also create encrypted Amazon EFS file systems, Amazon EBS volumes, and the Amazon FSx family of file systems.
Logging and monitoring
Logging and monitoring are two very essential components of any storage solution since we need to keep track of who is accessing the data and what they are doing with it. Often this logging is also necessary to satisfy audits and build analytics and reports for usage and threat analysis. AWS data storage services have several logging and monitoring tools available. Amazon CloudWatch alarms can be used to monitor metrics, triggering alarms to Amazon SNS to send notifications. We can also use Amazon CloudTrail to view actions taken by a user, IAM roles, and AWS services in our data storage and file systems. In addition, there are other logging and monitoring features, such as Amazon CloudWatch Logs to access log files and Amazon CloudWatch Events to capture state information and take corrective actions.
Resilience
AWS infrastructure consists of AWS Regions, which in turn consist of multiple physically separated AZs. These AZs have high throughput and low latency connectivity. By default, S3, EFS, EBS, and FSx resources are backed up and replicated either across multiple AZs across an AWS Region or within the same AZ, depending on the configuration picked by the user. In addition, there are also several other resilience features specific to these data storage and file systems, such as lifecycle configuration, versioning, S3 object lock, EBS snapshots, and so on. All these features make the data stored on AWS highly resilient to failures and loss.
In addition to the aforementioned mentioned security and governance features of data storage services on AWS, there are several other options available as well, such as the configuration of VPCs, network isolation, and a few additional options. With the combination of these tools and resources, AWS data storage services are among the most secure cloud storage services available.
AWS provides the option of using tiered storage for Amazon S3 and Amazon EFS. This helps with optimizing the data storage cost for the user.
Tiered storage for cost optimization
AWS provides options for configuring its data storage services with various different tiers of storage types. This significantly helps with optimizing cost and performance depending on the use case requirements. In this section, we will discuss the tiered storage options for Amazon S3 and Amazon EFS.
Amazon S3 storage classes
As mentioned in the Amazon Simple Storage Service (S3) section, there are various storage classes depending on the use case, access pattern, and cost requirements. We can configure S3 storage classes at the object level. We will discuss these storage classes in the following sections.
Amazon S3 Standard
Amazon S3 Standard is the general-purpose S3 object storage commonly used for frequently accessed data. It provides high throughput and low latency. Some of the common applications of S3 Standard are online gaming, big data analytics, ML model training and data storage, an offline feature store for ML applications, content storage, and distribution, and websites with dynamic content.
Amazon S3 Intelligent-Tiering
Amazon S3 Intelligent-Tiering is the storage class for unknown, unpredictable, and changing access patterns. There are three access tiers in S3 Intelligent-Tiering – frequent, infrequent, and archive tiers. S3 Intelligent-Tiering monitors access patterns and moves data to the appropriate tiers accordingly in order to save costs without impacting performance, retrieval fees, or creating operational overhead. In addition, we can also set up S3 Intelligent-Tiering to move data to the Deep Archive Access tier for data that is accessed very rarely (180 days or more). This can result in further additional cost savings.
Amazon S3 Standard-Infrequent Access
Amazon S3 Standard-Infrequent Access is for use cases where data is generally accessed less frequently, but rapid access may be required. It offers a low per GB storage price and retrieval charge but the same performance and durability as S3 Standard. Some of the common use cases for this tier are backups, a data store for disaster recovery, and long-term storage. For high-performance compute applications, such as ML, this storage tier can be used to store historical data on which models have already been trained or analytics have already been carried out and is not needed for model retraining for a while.
Amazon S3 One Zone-Infrequent Access
Amazon S3 One Zone-Infrequent Access is very similar to Amazon S3 Standard-Infrequent Access, but the data is stored in only one AZ (multiple devices) instead of the default three AZs within the same AWS Region as for other S3 storage classes. This is even more cost-effective than the S3 Standard-Infrequent Access storage class and is commonly used for storing secondary backups or easily re-creatable data, for example, engineered features no longer used for active ML model training.
Amazon S3 Glacier
Amazon S3 Glacier storage classes are highly flexible, low-cost, and high-performance data archival storage classes. In Amazon S3 Glacier, there are three storage classes. Amazon S3 Glacier Instant Retrieval is generally used where data is accessed very rarely, but the retrieval is required with latency in milliseconds, for example, news media assets and genomics data. Amazon S3 Flexible Retrieval is for use cases where large datasets such as backup recovery data need to be retrieved at no additional cost, but instant retrieval is not a requirement. The usual retrieval times for such use cases are a few minutes to a few hours. Amazon S3 Glacier Deep Archive is for use cases that require very infrequent retrieval, such as preserved digital media and compliance archives, for example. It is the lowest-cost storage of all the options discussed previously, and the typical retrieval time is 12 hours to 2 days.
S3 on Outposts
For on-premise AWS Outposts environments, object storage can be configured using Amazon S3 on Outposts. It stores data reliably and redundantly across multiple devices and servers on AWS Outposts, especially suited for use cases with local data residency requirements.
In the following section, we will discuss the different storage classes for Amazon EFS.
Amazon EFS storage classes
Amazon EFS provides the option of different storage classes for access based on how frequently the data needs to be accessed, as discussed here.
Amazon EFS Standard and EFS Standard-Infrequent Access classes
Amazon EFS Standard and EFS Standard-Infrequent Access classes are highly available, durable, and elastic file system storage classes. They are both replicated across multiple geographically separated AZs within an AWS Region. EFS Standard is for use cases where our data needs frequent access, whereas the EFS Standard-Infrequent Access class is for use cases where frequent data access is not required. Using EFS Standard-Infrequent Access, we can reduce the storage cost significantly.
Amazon EFS One Zone and EFS One Zone-Infrequent Access classes
Amazon EFS One Zone and EFS One Zone-Infrequent Access classes store data within a single AZ across multiple devices, reducing the storage cost compared to Amazon EFS Standard and EFS Standard-Infrequent Access classes, respectively. For frequently accessed files, EFS One Zone is recommended, whereas for infrequently accessed files, EFS One Zone-Infrequent Access class is recommended.
With multiple options available for Amazon S3 and Amazon EFS, the right approach is to first determine performance, access, and retrieval needs for a use case and then pick the storage class that satisfies these requirements while minimizing the total cost. Significant amounts of savings can be achieved if we pick the right storage class, especially for very big datasets and use cases where data scales significantly over time.
So far, we have discussed various AWS storage options for HPC along with their capabilities and cost optimization options. In the next section, we will learn about how to pick the right storage option for our HPC use cases.
Choosing the right storage option for HPC workloads
With so many choices available for cloud data storage, it becomes challenging to decide which storage option to pick for HPC workloads. The choice of data storage depends heavily on the use case and performance, throughput, latency, scaling, archival, and retrieval requirements.
For use cases where we need to archive our object data for a very long time, Amazon S3 should be considered. In addition, Amazon S3 can be very well suited to several HPC applications since it can be accessed by other AWS services. For example, in Amazon SageMaker, we can carry out feature engineering using data stored in Amazon S3 and then ingest those features in the SageMaker offline feature store, which is, again, stored in Amazon S3. Amazon SageMaker uses Amazon S3 for ML model training. It reads data from Amazon S3 and carries out model fitting, hyperparameter optimization, and validation using this data. The model artifacts created as a result are then stored in Amazon S3 as well, which can be used for real-time or batch inference. In addition to ML, Amazon S3 is also a good choice of storage for carrying out data analytics, for storing data on which we want to run complex queries, data archiving, and backups.
Amazon EFS is a shared file system for Amazon EC2 instances. Thousands of EC2 instances can share the same EFS file system. This makes it ideal for applications where high-performance scaling is needed. High-performance compute applications such as content management systems, distributed applications running on various instances needing access to the same data in the file system, and very large-scale data analysis are a few examples where EFS should be used.
Amazon EBS is a block storage service for single EC2 instances (except EBS Multi-Attach), so the main use case for EBS is when we need high-performance storage for an EC2 instance. For high-performance compute applications such as ML and numerical optimization, often we need to access data for training and tuning our algorithms. The size of the data is often very large to be stored in memory during the process (for example, several thousand videos). In such cases, we may store data temporarily on EBS drives attached to the EC2 instances on which we are running our algorithms, making it much faster to swap and read between data files to carry out the compute operations.
Amazon FSx should be used when we have a similar file system running on-premise and we want to migrate our applications to the cloud while also designing new applications on a similar file system without worrying about underlying infrastructure and tools and process changes.
These are some of the examples we have discussed here where high-performance compute applications can benefit from various AWS data storage options. At the time of designing the architecture, it is very important that we pick the right selection of storage options to make our application give the best performance while also making sure that we do not incur unneeded costs.
Summary
In this chapter, we have discussed the different data storage options available on AWS, along with their main features and capabilities. We have introduced Amazon S3 – a highly scalable and reliable object storage service, Amazon EFS – a shared file system for EC2 instances, Amazon EBS – block storage for EC2 instances, and the Amazon FSx family of file systems. We have also talked about the data protection and governance capabilities of these services and how they integrate with various other data protection, access management, encryption, logging, and monitoring services. We have also explored the various tiers of storage available for Amazon S3 and Amazon EFS and how we can use these tiers to optimize cost for our use cases. Finally, we have discussed a few examples of when to use which data storage service for high-performance compute applications.
Now that we have a good understanding of various AWS data storage services, we are ready to move on to the next part of the book, Chapter 5, Data Analysis, which begins with how to carry out data analysis using AWS services.
Further reading
For further reading on the material we learned in this chapter, please refer to the following articles:
- Amazon S3 Features: https://aws.amazon.com/s3/features/
- Amazon Regions and Availability Zones: https://aws.amazon.com/about-aws/global-infrastructure/regions_az/
- AWS Snow Family: https://aws.amazon.com/snow/
- Getting started with Amazon S3: https://docs.aws.amazon.com/AmazonS3/latest/userguide/GetStartedWithS3.html
- Prerequisite: Setting up Amazon S3: https://docs.aws.amazon.com/AmazonS3/latest/userguide/setting-up-s3.html
- AWS EFS Deep Dive: What is it and when to use it: https://www.learnaws.org/2021/01/23/aws-efs-deep-dive/
- Achieve highly available and durable database backup workflows with Amazon EFS: https://aws.amazon.com/blogs/storage/using-amazon-efs-to-cost-optimize-highly-available-durable-database-backup-workflows/
- Amazon EFS features: https://aws.amazon.com/efs/features/
- AWS Backup: https://aws.amazon.com/backup/
- Amazon EBS features: https://aws.amazon.com/ebs/features/
- Amazon FSx Documentation: https://docs.aws.amazon.com/fsx/index.html
- Amazon S3 Glacier storage classes: https://aws.amazon.com/s3/storage-classes/glacier/